Développer du code de pipeline avec Python
Delta Live Tables introduit plusieurs nouvelles constructions de code Python pour définir des vues matérialisées et des tables de diffusion en continu dans des pipelines. La prise en charge de Python pour le développement de pipelines s’appuie sur les bases des API PySpark DataFrame et Structured Streaming.
Pour les utilisateurs qui ne connaissent pas Python et les DataFrames, Databricks recommande d’utiliser l’interface SQL. Consultez Développer du code de pipeline avec SQL.
Pour obtenir une référence complète de la syntaxe Python Delta Live Tables, consultez la référence du langage Python Delta Live Tables.
Notions de base de Python pour le développement de pipelines
Le code Python qui crée des jeux de données Delta Live Tables doit retourner des DataFrames.
Toutes les API Python Delta Live Tables sont implémentées dans le module dlt. Votre code de pipeline Delta Live Tables implémenté avec Python doit importer explicitement le module dlt en haut des notebooks et fichiers Python.
Les lectures et écritures par défaut se font dans le catalogue et le schéma spécifiés lors de la configuration du pipeline. Voir définir le catalogue cible et le schéma.
Le code Python spécifique à Delta Live Tables diffère d’autres types de code Python de manière critique : le code de pipeline Python n’appelle pas directement les fonctions qui effectuent l’ingestion et la transformation des données pour créer des jeux de données Delta Live Tables. Au lieu de cela, Delta Live Tables interprète les fonctions de décorateur du module dans tous les fichiers de dlt code source configurés dans un pipeline et génère un graphe de flux de données.
Important
Pour éviter un comportement inattendu lors de l’exécution de votre pipeline, n’incluez pas de code susceptible d’avoir des effets secondaires dans vos fonctions qui définissent des jeux de données. Pour en savoir plus, consultez les informations de référence Python.
Créer une vue matérialisée ou une table de streaming avec Python
Le @dlt.table décorateur indique à Delta Live Tables de créer une vue matérialisée ou une table de diffusion en continu en fonction des résultats retournés par une fonction. Les résultats d’une lecture par lot créent une vue matérialisée, tandis que les résultats d’une lecture en continu créent une table de diffusion en continu.
Par défaut, les noms de table de diffusion en continu et d’affichage matérialisé sont déduits des noms de fonction. L’exemple de code suivant montre la syntaxe de base pour la création d’une vue matérialisée et d’une table de diffusion en continu :
Remarque
Les deux fonctions référencent la même table dans le samples catalogue et utilisent la même fonction de décorateur. Ces exemples mettent en évidence que la seule différence dans la syntaxe de base pour les vues matérialisées et les tables de diffusion en continu utilise spark.read plutôt spark.readStreamque .
Toutes les sources de données ne prennent pas en charge les lectures de diffusion en continu. Certaines sources de données doivent toujours être traitées avec la sémantique de diffusion en continu.
import dlt
@dlt.table()
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dlt.table()
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
Si vous le souhaitez, vous pouvez spécifier le nom de la table à l’aide de l’argument name dans le @dlt.table décorateur. L’exemple suivant illustre ce modèle pour une vue matérialisée et une table de diffusion en continu :
import dlt
@dlt.table(name = "trips_mv")
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dlt.table(name = "trips_st")
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
Charger des données à partir du stockage d’objets
Delta Live Tables prend en charge le chargement de données à partir de tous les formats pris en charge par Azure Databricks. Consultez Options de format de données.
Remarque
Ces exemples utilisent des données disponibles sous le /databricks-datasets montage automatique de votre espace de travail. Databricks recommande d’utiliser des chemins de volume ou des URI cloud pour référencer les données stockées dans le stockage d’objets cloud. Consultez Présentation des volumes Unity Catalog.
Databricks recommande d’utiliser le chargeur automatique et les tables de diffusion en continu lors de la configuration de charges de travail d’ingestion incrémentielles sur les données stockées dans le stockage d’objets cloud. Consultez Qu’est-ce que Auto Loader ?.
L’exemple suivant crée une table de streaming à partir de fichiers JSON à l’aide du chargeur automatique :
import dlt
@dlt.table()
def ingestion_st():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
L’exemple suivant utilise la sémantique de traitement par lots pour lire un répertoire JSON et créer une vue matérialisée :
import dlt
@dlt.table()
def batch_mv():
return spark.read.format("json").load("/databricks-datasets/retail-org/sales_orders")
Valider les données avec des attentes
Vous pouvez utiliser des attentes pour définir et appliquer des contraintes de qualité des données. Voir Gérer la qualité des données avec les attentes de la chaîne de traitement.
Le code suivant utilise @dlt.expect_or_drop pour définir une attente nommée valid_data qui supprime les enregistrements null lors de l’ingestion des données :
import dlt
@dlt.table()
@dlt.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders_valid():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
Interroger des vues matérialisées et des tables de diffusion en continu définies dans votre pipeline
L’exemple suivant définit quatre jeux de données :
- Table de diffusion en continu nommée
ordersqui charge des données JSON. - Vue matérialisée nommée
customersqui charge les données CSV. - Vue matérialisée nommée
customer_ordersqui joint des enregistrements à partir des jeux de données etordersdescustomersjeux de données, convertit l’horodatage de l’ordre en date, puis sélectionne les champs ,customer_idetorder_numberstatelesorder_datechamps. - Vue matérialisée nommée
daily_orders_by_statequi agrège le nombre quotidien de commandes pour chaque état.
Remarque
Lorsque vous interrogez des vues ou des tables dans votre pipeline, vous pouvez spécifier le catalogue et le schéma directement, ou vous pouvez utiliser les valeurs par défaut configurées dans votre pipeline. Dans cet exemple, les tables orders, customerset customer_orders sont écrites et lues à partir du catalogue et du schéma par défaut configurés pour votre pipeline.
Le mode de publication hérité utilise le schéma LIVE pour interroger d’autres vues matérialisées et tables de streaming définies dans votre pipeline. Dans les nouveaux pipelines, la syntaxe de schéma LIVE est ignorée sans avertissement. Consultez le schéma en direct (hérité).
import dlt
from pyspark.sql.functions import col
@dlt.table()
@dlt.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
@dlt.table()
def customers():
return spark.read.format("csv").option("header", True).load("/databricks-datasets/retail-org/customers")
@dlt.table()
def customer_orders():
return (spark.read.table("orders")
.join(spark.read.table("customers"), "customer_id")
.select("customer_id",
"order_number",
"state",
col("order_datetime").cast("int").cast("timestamp").cast("date").alias("order_date"),
)
)
@dlt.table()
def daily_orders_by_state():
return (spark.read.table("customer_orders")
.groupBy("state", "order_date")
.count().withColumnRenamed("count", "order_count")
)
Créer des tables dans une boucle de for
Vous pouvez utiliser des boucles Python for pour créer plusieurs tables par programmation. Cela peut être utile lorsque vous avez de nombreuses sources de données ou jeux de données cibles qui varient en fonction de quelques paramètres uniquement, ce qui entraîne moins de code total pour maintenir et réduire la redondance du code.
La for boucle évalue la logique dans l’ordre série, mais une fois la planification terminée pour les jeux de données, le pipeline exécute la logique en parallèle.
Important
Lorsque vous utilisez ce modèle pour définir des jeux de données, assurez-vous que la liste des valeurs passées à la for boucle est toujours additive. Si un jeu de données précédemment défini dans un pipeline est omis d’une prochaine exécution de pipeline, ce jeu de données est supprimé automatiquement du schéma cible.
L’exemple suivant crée cinq tables qui filtrent les commandes des clients par région. Ici, le nom de la région est utilisé pour définir le nom des vues matérialisées cibles et pour filtrer les données sources. Les vues temporaires sont utilisées pour définir des jointures à partir des tables sources utilisées pour construire les vues matérialisées finales.
import dlt
from pyspark.sql.functions import collect_list, col
@dlt.view()
def customer_orders():
orders = spark.read.table("samples.tpch.orders")
customer = spark.read.table("samples.tpch.customer")
return (orders.join(customer, orders.o_custkey == customer.c_custkey)
.select(
col("c_custkey").alias("custkey"),
col("c_name").alias("name"),
col("c_nationkey").alias("nationkey"),
col("c_phone").alias("phone"),
col("o_orderkey").alias("orderkey"),
col("o_orderstatus").alias("orderstatus"),
col("o_totalprice").alias("totalprice"),
col("o_orderdate").alias("orderdate"))
)
@dlt.view()
def nation_region():
nation = spark.read.table("samples.tpch.nation")
region = spark.read.table("samples.tpch.region")
return (nation.join(region, nation.n_regionkey == region.r_regionkey)
.select(
col("n_name").alias("nation"),
col("r_name").alias("region"),
col("n_nationkey").alias("nationkey")
)
)
# Extract region names from region table
region_list = spark.read.table("samples.tpch.region").select(collect_list("r_name")).collect()[0][0]
# Iterate through region names to create new region-specific materialized views
for region in region_list:
@dlt.table(name=f"{region.lower().replace(' ', '_')}_customer_orders")
def regional_customer_orders(region_filter=region):
customer_orders = spark.read.table("customer_orders")
nation_region = spark.read.table("nation_region")
return (customer_orders.join(nation_region, customer_orders.nationkey == nation_region.nationkey)
.select(
col("custkey"),
col("name"),
col("phone"),
col("nation"),
col("region"),
col("orderkey"),
col("orderstatus"),
col("totalprice"),
col("orderdate")
).filter(f"region = '{region_filter}'")
)
Voici un exemple de graphique de flux de données pour ce pipeline :
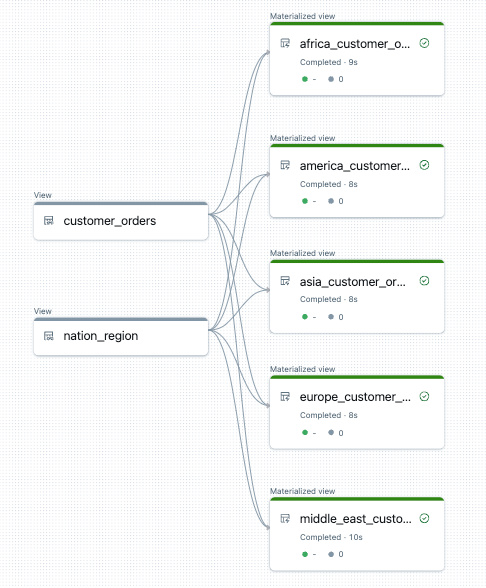
Résolution des problèmes : for la boucle crée de nombreuses tables avec les mêmes valeurs
Le modèle d’exécution différé que les pipelines utilisent pour évaluer le code Python nécessite que votre logique référence directement des valeurs individuelles lorsque la fonction décorée par @dlt.table() est appelée.
L’exemple suivant illustre deux approches correctes pour définir des tables avec une for boucle. Dans les deux exemples, chaque nom de table de la tables liste est explicitement référencé dans la fonction décorée par @dlt.table().
import dlt
# Create a parent function to set local variables
def create_table(table_name):
@dlt.table(name=table_name)
def t():
return spark.read.table(table_name)
tables = ["t1", "t2", "t3"]
for t_name in tables:
create_table(t_name)
# Call `@dlt.table()` within a for loop and pass values as variables
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dlt.table(name=t_name)
def create_table(table_name=t_name):
return spark.read.table(table_name)
L’exemple suivant ne référence pas correctement les valeurs. Cet exemple crée des tables avec des noms distincts, mais toutes les tables chargent des données à partir de la dernière valeur de la for boucle :
import dlt
# Don't do this!
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dlt.table(name=t_name)
def create_table():
return spark.read.table(t_name)