Récupération d'urgence
Un modèle de récupération d’urgence clair est essentiel pour une plateforme d’analyse de données Native Cloud, par exemple Azure Databricks. Il est essentiel que vos équipes de données puissent utiliser la plateforme Azure Databricks, même dans les rares cas de panne d’un fournisseur de service Cloud régional, que ce soit en raison d’un sinistre régional comme un ouragan ou un tremblement de terre, ou pour une autre raison.
Azure Databricks est souvent un élément central d’un écosystème de données global qui inclut de nombreux services, notamment les services d’ingestion de données en amont (traitement par lots/diffusion en continu), le stockage natif cloud tel qu’ADLS gen2 (pour les espaces de travail créés avant le 6 mars 2023, stockage Blob Azure), les outils et services en aval tels que les applications décisionnelles d’affaires et les outils d’orchestration. Certains de vos cas d’utilisation peuvent être particulièrement sensibles à une panne à l’échelle du service régional.
Cet article décrit les concepts et les meilleures pratiques pour une solution réussie de reprise après sinistre interrégionale pour la plateforme Databricks.
Garanties de haute disponibilité au sein d’une région
Bien que le reste de cette rubrique se concentre sur la réalisation de la récupération d’urgence interrégionale, il est important de comprendre les garanties de haute disponibilité qu’Azure Databricks fournit au sein de la seule région. Les garanties de haute disponibilité au sein de la région concernent les composants suivants :
Disponibilité du plan de contrôle Azure Databricks
- La plupart des services de plan de contrôle s’exécutent sur des clusters Kubernetes et gèrent automatiquement la perte de machines virtuelles dans la zone de disponibilité spécifique.
- Les données de l’espace de travail sont stockées dans des bases de données avec stockage premium qui sont répliquées dans toute la région. Le stockage de la base de données (serveur unique) n’est pas répliqué dans différentes zones de disponibilité ou régions. Si la panne de zone a un impact sur le stockage de la base de données, cette dernière est récupérée en mettant en place une nouvelle instance à partir de la sauvegarde.
- Les comptes de stockage utilisés pour servir des images DBR sont également redondants au sein de la région. Toutes les régions ont des comptes de stockage secondaires qui sont utilisés lorsque le compte principal est hors service. Voir les régions Azure Databricks.
- La fonctionnalité du plan de contrôle doit en général être restaurée dans un délai d’environ 15 minutes après la récupération de la zone de disponibilité.
Disponibilité du plan de calcul
- La disponibilité de l’espace de travail dépend de la disponibilité du plan de contrôle (telle que décrite ci-dessus).
- Les données sur la racine DBFS ne sont pas affectées si le compte de stockage pour la racine DBFS est configuré avec ZRS ou GZRS (GRS par défaut).
- Les nœuds des clusters sont extraits des différentes zones de disponibilité en demandant des nœuds au fournisseur de calcul Azure (supposant une capacité suffisante dans les zones restantes pour répondre à la requête). Si un nœud est perdu, le gestionnaire de cluster demande des nœuds de remplacement au fournisseur de calcul Azure, qui les tire des zones de disponibilité accessibles. La seule exception concerne la perte du nœud de pilote. Dans ce cas, le gestionnaire de tâche ou de cluster les redémarre.
Présentation de la récupération d’urgence
La récupération d’urgence implique un ensemble de stratégies, d’outils et de procédures qui permettent la récupération ou la poursuite de l’infrastructure et des systèmes de la technologie vitale suite à une catastrophe naturelle ou humaine. Un service Cloud de grande taille, comme Azure, est utilisé par de nombreux clients et intègre des protections contre une défaillance unique. Par exemple, une région est un groupe de bâtiments connectés à différentes sources d’alimentation pour garantir qu’une seule perte d’alimentation n’arrête pas une région. Toutefois, les défaillances de la région Cloud peuvent se produire et le degré d’interruption et son impact sur votre organisation peuvent varier.
Avant d’implémenter un plan de récupération d’urgence, il est important de comprendre la différence entre la récupération d’urgence (DR) et la haute disponibilité (HA).
La haute disponibilité est une caractéristique de résilience d’un système. La haute disponibilité garantit un niveau minimal de performances opérationnelles qui est généralement défini en termes de temps de fonctionnement cohérent ou de pourcentage de temps d’activité. La haute disponibilité est implémentée sur place (dans la même région que votre système principal) en la concevant en tant que fonctionnalité du système principal. Par exemple, les services cloud comme Azure disposent de services à haute disponibilité tels qu’ADLS gen2 (pour les espaces de travail créés avant le 6 mars 2023, stockage Blob Azure). La haute disponibilité ne nécessite pas de préparation explicite significative du client Azure Databricks.
En revanche, un plan de récupération d’urgence nécessite des décisions et des solutions qui fonctionnent pour votre organisation pour gérer une panne régionale plus importante pour les systèmes critiques. Cet article décrit la terminologie courante de la récupération d’urgence, les solutions courantes et les meilleures pratiques pour les plans de récupération à l’aide de Azure Databricks.
Terminologie
Terminologie des régions
Cet article utilise les définitions suivantes pour les régions :
Région primaire: région géographique dans laquelle les utilisateurs exécutent des charges de travail d’analyse de données quotidiennes interactives et automatisées.
Région secondaire: région géographique dans laquelle les équipes informatiques déplacent temporairement les charges de travail d’analyse des données au cours d’une panne dans la région primaire.
Stockage géoredondant: Azure possède lestockage géoredondant entre les régionspour le stockage persistant à l’aide d’un processus de réplication de stockage asynchrone.
Important
Pour les processus de récupération d'urgence, Databricks vous recommande de ne pas dépendre d’un stockage géoredondant pour la duplication interrégionale des données, comme votre ADLS gen2 (pour les espaces de travail créés avant le 6 mars 2023, stockage Blob Azure) qu’Azure Databricks crée pour chaque espace de travail dans votre abonnement Azure. En général, utilisez le clone profond pour les tables delta et convertissez les données au format Delta pour utiliser le clone profond si possible pour d’autres formats de données.
Terminologie de l’état du déploiement
Cet article utilise les définitions suivantes de l’état du déploiement :
Déploiement actif : les utilisateurs peuvent se connecter à un déploiement actif d’un espace de travail Azure Databricks et exécuter des charges de travail. Les travaux sont planifiés régulièrement à l’aide de Azure Databricks Scheduler ou d’un autre mécanisme. Les flux de données peuvent également être exécutés sur ce déploiement. Certains documents peuvent faire référence à un déploiement actif comme un déploiement à chaud.
Déploiement passif: les processus ne s’exécutent pas sur un déploiement passif. Les équipes informatiques peuvent configurer des procédures automatisées pour déployer le code, la configuration et d’autres objets de Azure Databricks dans le déploiement passif. Un déploiement devient actif uniquement si un déploiement actif est en cours. Certains documents peuvent faire référence à un déploiement actif comme un déploiement à chaud.
Important
Un projet peut éventuellement inclure plusieurs déploiements passifs dans différentes régions pour fournir des options supplémentaires pour la résolution des pannes régionales.
En règle générale, une équipe n’a qu’un seul déploiement actif à la fois, dans ce qu’on appelle une stratégie de récupération d’urgence active/passive . Il existe une stratégie de solution de récupération d’urgence moins courante appelée active-active, dans laquelle deux déploiements actifs sont simultanés.
Terminologie du secteur d’activité de récupération d’urgence
Il existe deux termes importants que vous devez comprendre et définir pour votre équipe :
Objectif de point de récupération: un objectif de point de récupération (RPO) est la période ciblée maximale pendant laquelle les données (transactions) peuvent être perdues d’un service informatique en raison d’un incident majeur. Votre déploiement Azure Databricks ne stocke pas vos données client principales. Il est stocké dans des systèmes distincts, tels qu’ADLS gen2 (pour les espaces de travail créés avant le 6 mars 2023, stockage Blob Azure) ou d’autres sources de données sous votre contrôle. Le plan de contrôle Azure Databricks stocke certains objets en partie ou en totalité, tels que des travaux et des blocs-notes. Par Azure Databricks, le RPO est défini comme la période ciblée maximale dans laquelle les objets tels que les modifications de travail et de bloc-notes peuvent être perdus. En outre, vous êtes responsable de la définition de l’objectif de point de récupération (RPO, Recovery Point Objective) pour vos propres données client dans ADLS gen2 (pour les espaces de travail créés avant le 6 mars 2023, stockage Blob Azure) ou d’autres sources de données sous votre contrôle.
Objectif de délai de récupération: l'objectif de délai de récupération (RTO, Recovery Time Objective) est la durée ciblée et un niveau de service dans lequel un processus d’entreprise doit être restauré après un incident.
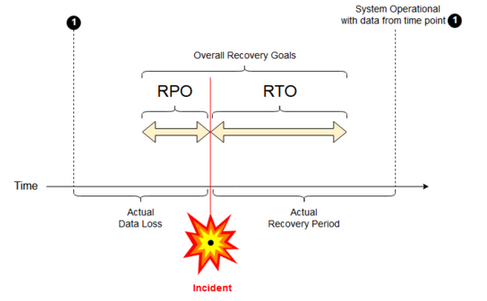
Récupération d’urgence et corruption des données
Une solution de récupération d’urgence n’atténue pas les données endommagées. Les données endommagées dans la région primaire sont répliquées de la région primaire vers une région secondaire et sont endommagées dans les deux régions. Il existe d’autres façons d’atténuer ce type d’échec, par exemple, le trajet d’heure Delta.
Flux de travail de récupération standard
Un scénario de récupération d’urgence Azure Databricks s’exécute généralement de la façon suivante :
Une défaillance se produit dans un service critique que vous utilisez dans votre région primaire. Il peut s’agir d’un service de source de données ou d’un réseau qui a un impact sur le déploiement de Azure Databricks.
Vous examinez la situation avec le fournisseur de Cloud.
Si vous concluez que votre entreprise ne peut pas attendre que le problème soit corrigé dans la région primaire, vous pouvez décider de basculer vers une région secondaire.
Vérifiez que le même problème n’affecte pas non plus votre région secondaire.
Basculer vers un site secondaire
- Arrêtez toutes les activités dans l’espace de travail. Les utilisateurs arrêtent les charges de travail. Les utilisateurs ou les administrateurs sont invités à effectuer une sauvegarde des modifications récentes si possible. Les travaux sont arrêtés s’ils n’ont pas déjà échoué en raison de la panne.
- Démarrez la procédure de récupération dans la région secondaire. La procédure de récupération met à jour le routage et le changement de nom des connexions et du trafic réseau vers la région secondaire.
- Après le test, déclarez la région secondaire opérationnelle. Les charges de travail de production peuvent maintenant reprendre. Les utilisateurs peuvent se connecter au déploiement maintenant actif. Vous pouvez redéclencher les tâches planifiées ou différées.
Pour obtenir des instructions détaillées dans un contexte Azure Databricks, consultez le test de basculement.
À un moment donné, le problème de la région primaire est atténué et vous confirmez ce fait.
Restore (restauration automatique) dans votre région primaire.
- Arrêtez tout le travail sur la région secondaire.
- Démarrez la procédure de récupération dans la région primaire. La procédure de récupération gère le routage et le renommage de la connexion et du trafic réseau vers la région primaire.
- Réplication des données dans la région primaire en fonction des besoins. Pour réduire la complexité, peut-être réduire la quantité de données à répliquer. Par exemple, si certains travaux sont en lecture seule lorsqu’ils sont exécutés dans le déploiement secondaire, vous n’aurez peut-être pas besoin de répliquer ces données dans votre déploiement principal dans la région primaire. Toutefois, vous pouvez avoir un travail de production qui doit s’exécuter et qui peut nécessiter la réplication des données dans la région primaire.
- Testez le déploiement dans la région primaire.
- Déclarez votre région principale opérationnelle et qu’il s’agit de votre déploiement actif. Reprendre les charges de travail de production.
Pour plus d’informations sur la restauration de votre région principale, consultez tester la restauration (restauration automatique).
Important
Au cours de ces étapes, une perte de données peut se produire. Votre organisation doit définir la quantité de données pouvant être perdues et ce que vous pouvez faire pour atténuer cette perte.
Étape 1 : comprendre les besoins de votre entreprise
La première étape consiste à définir et à comprendre les besoins de votre entreprise. Définissez les services de données critiques et le RPO et le RTOattendus.
Recherchez la tolérance du monde réel de chaque système et rappelez-vous que le basculement et la restauration d’urgence peuvent être coûteux et qu’il y a d’autres risques. D’autres risques peuvent inclure l’altération des données, les données dupliquées si vous écrivez dans un emplacement de stockage incorrect et les utilisateurs qui se connectent et apportent des modifications à des emplacements incorrects.
Mappez tous les points d’intégration Azure Databricks qui affectent votre activité :
- Votre solution de récupération d’urgence doit-elle prendre en charge les processus interactifs, les processus automatisés ou les deux ?
- Quels services de données utilisez-vous ? Certains peuvent être locaux.
- Comment les données d’entrée sont-elles dans le Cloud ?
- Qui utilise-t-il ces données ? Quels sont les processus qui le consomment en aval ?
- Existe-t-il des intégrations tierces qui doivent être conscientes des modifications de la récupération d’urgence ?
Déterminez les outils ou les stratégies de communication qui peuvent prendre en charge votre plan de récupération d’urgence :
- Quels outils allez-vous utiliser pour modifier rapidement les configurations réseau ?
- Pouvez-vous prédéfinir votre configuration et la rendre modulaire pour prendre en charge les solutions de récupération d’urgence de manière naturelle et facile à gérer ?
- Quels sont les outils de communication et les canaux qui informeront les équipes internes et les tiers (intégrations, consommateurs en aval) du basculement de récupération d’urgence et des changements de restauration automatique ? Et comment confirmerez-vous leur accusé de réception ?
- Quels outils ou support spécial seront nécessaires ?
- Quels services s’arrêteront, jusqu’à ce que la récupération complète soit en place ?
Étape 2 : choisir un processus qui répond aux besoins de votre entreprise
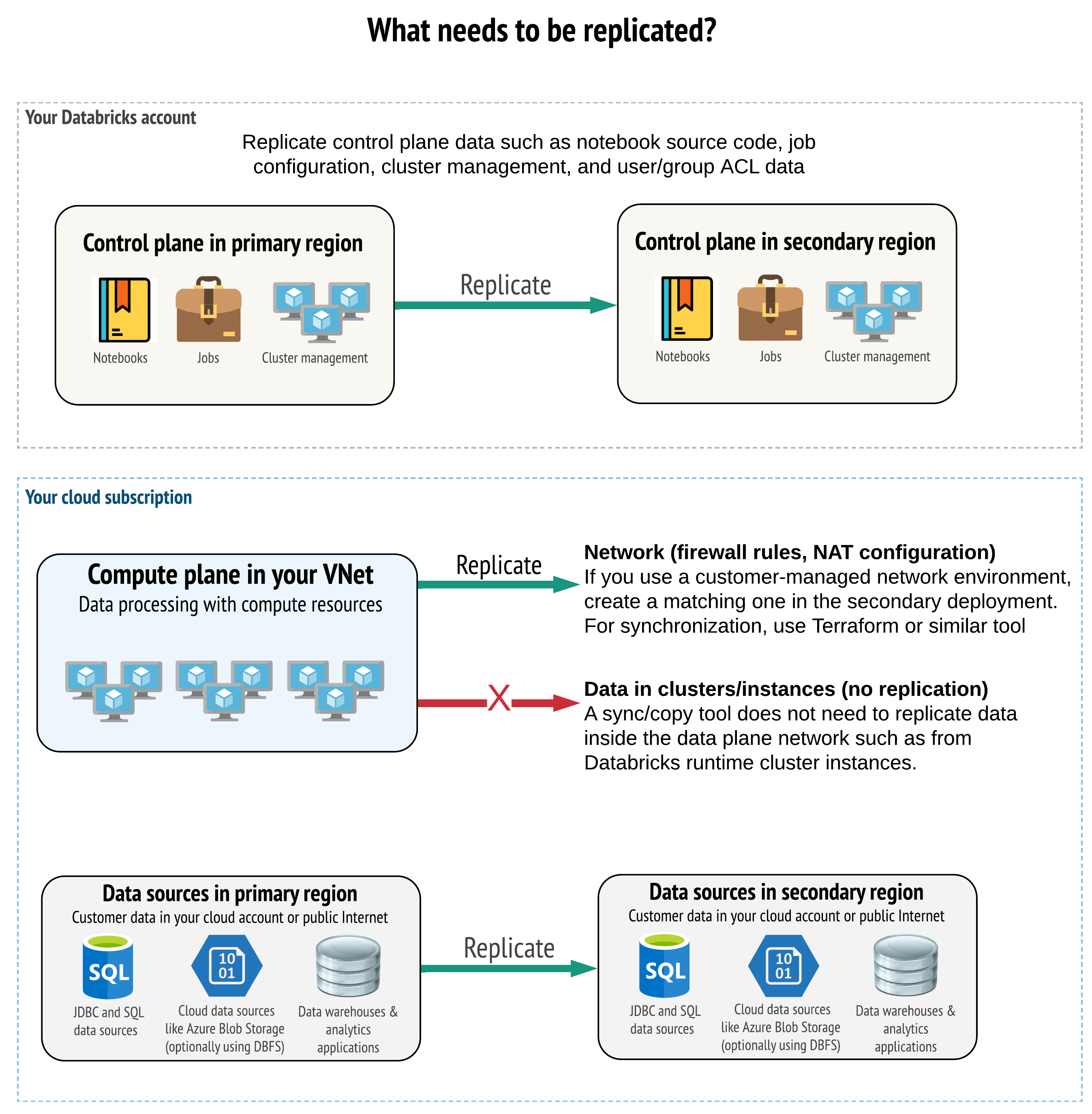
Votre solution doit répliquer les données correctes dans le plan de contrôle, le plan de calcul et les sources de données. Les espaces de travail redondants pour la récupération d’urgence doivent être mappés à différents plans de contrôle dans différentes régions. Vous devez régulièrement synchroniser ces données à l’aide d’une solution basée sur des scripts, soit un outil de synchronisation, soit un flux de travail ci/CD. Il n’est pas nécessaire de synchroniser les données à partir du réseau du plan de données lui-même, comme depuis Databricks Runtime Workers par exemple.
Si vous utilisez la fonctionnalité d’injection de réseau virtuel (non disponible avec tous les types d’abonnements et de déploiements), vous pouvez déployer régulièrement ces réseaux dans les deux régions à l’aide d’outils basés sur des modèles tels que Terraform.
En outre, vous devez vous assurer que vos sources de données sont répliquées selon les besoins dans les régions.
Bonnes pratiques générales
Les bonnes pratiques générales pour un plan de récupération d’urgence réussi sont les suivantes :
Identifiez les processus essentiels pour l’entreprise et devez exécuter la récupération d’urgence.
Identifiez clairement les services impliqués, les données en cours de traitement, le type de données et leur emplacement de stockage.
Isolez autant que possible les services et les données. Par exemple, créez un conteneur de stockage cloud spécial pour les données pour la récupération d’urgence ou déplacez Azure Databricks objets qui sont nécessaires pendant un sinistre vers un espace de travail distinct.
Il vous incombe de maintenir l’intégrité entre les déploiements principaux et secondaires pour les autres objets qui ne sont pas stockés dans le plan de contrôle Databricks.
Avertissement
Il est recommandé de ne pas stocker des données dans le dossier ADLS gen2 racine (pour les espaces de travail créés avant le 6 mars 2023, Stockage Blob Azure) utilisé pour l’accès DBFS racine de l’espace de travail. Ce stockage racine DBFS n’est pas pris en charge pour les données de production cliente. Databricks recommande également de ne pas stocker de bibliothèques, de fichiers config ou de scripts d’initialisation dans cet emplacement.
Pour les sources de données, dans la mesure du possible, il est recommandé d’utiliser Azure Tools natif pour la réplication et la redondance pour répliquer les données dans les régions de récupération d’urgence.
Choisir une stratégie de solution de récupération
Les solutions de récupération d’urgence classiques impliquent deux espaces de travail (voire plus). Vous pouvez choisir plusieurs stratégies. Prenez en compte la durée potentielle de l’interruption (heures ou peut-être même un jour), l’effort pour s’assurer que l’espace de travail est entièrement opérationnel et l’effort de restauration (restauration automatique) dans la région primaire.
Stratégie de solution active-passive
Une solution active/passive est la solution la plus courante et la plus simple, et ce type de solution est l’objectif de cet article. Une solution active/passive synchronise les modifications de données et d’objets de votre déploiement actif vers votre déploiement passif. Si vous préférez, vous pouvez avoir plusieurs déploiements passifs dans différentes régions, mais cet article se concentre sur l’approche de déploiement passif unique. Pendant un événement de récupération d’urgence, le déploiement passif dans la région secondaire devient votre déploiement actif.
Il existe deux variantes principales de cette stratégie :
- Solution unifiée (entreprise) : exactement un ensemble de déploiements actifs et passifs qui prennent en charge l’ensemble de l’organisation.
- Solution par service ou projet : chaque service ou domaine de projet gère une solution de récupération d’urgence distincte. Certaines organisations souhaitent découpler les détails de la récupération d’urgence entre les départements et utiliser différentes régions principales et secondaires pour chaque équipe en fonction des besoins uniques de chaque équipe.
Il existe d’autres variantes, telles que l’utilisation d’un déploiement passif pour des cas d’usage en lecture seule. Si vous avez des charges de travail en lecture seule, par exemple des requêtes d’utilisateur, elles peuvent s’exécuter sur une solution passive à tout moment si elles ne modifient pas les données ou les objets Azure Databricks tels que les blocs-notes ou les travaux.
Stratégie de solution active-active
Dans une solution active-active, vous exécutez tous les processus de données dans les deux régions en parallèle. Votre équipe d’exploitation doit s’assurer qu’un processus de données tel qu’un travail est marqué comme terminé uniquement lorsqu’il se termine correctement dans les deux régions. Les objets ne peuvent pas être modifiés en production et doivent suivre une promotion stricte d’intégration continue/de CD entre le développement et la mise en production.
Une solution active-active est la stratégie la plus complexe, et étant donné que les tâches s’exécutent dans les deux régions, il existe des frais financiers supplémentaires.
Tout comme avec la stratégie active-passive, vous pouvez implémenter ceci en tant que solution d’organisation unifiée ou par service.
Vous n’avez peut-être pas besoin d’un espace de travail équivalent dans le système secondaire pour tous les espaces de travail, en fonction de votre flux de travail. Par exemple, un espace de travail de développement ou de mise en lots peut ne pas avoir besoin d’un doublon. Avec un pipeline de développement bien conçu, vous pourrez peut-être reconstruire facilement ces espaces de travail, si nécessaire.
Choisir vos outils
Il existe deux approches principales pour que les outils maintiennent les données aussi similaires que possible entre les espaces de travail dans les régions principales et secondaires :
- Client de synchronisation qui copie de principal à secondaire: un client de synchronisation pousse les données de production et les ressources de la région primaire vers la région secondaire. En général, cette opération s’exécute de manière planifiée.
- Outils CI/CD pour le déploiement parallèle: pour le code et les ressources de production, utilisez les outils CICD qui poussent les modifications des systèmes de production simultanément dans les deux régions. Par exemple, lors de l’envoi de code et de ressources de l’environnement intermédiaire/développement à la production, un système d’intégration continue/de livraison continue le rend disponible dans les deux régions en même temps. L’idée principale est de traiter tous les artefacts dans un espace de travail Azure Databricks en tant qu’infrastructure-comme-code. La plupart des artefacts peuvent être co-déployés sur les espaces de travail principaux et secondaires, tandis que certains artefacts doivent être déployés uniquement après un événement de récupération d’urgence. Pour obtenir des outils, consultez scripts d’automatisation, exemples et prototypes.
Le diagramme suivant compare ces deux approches.
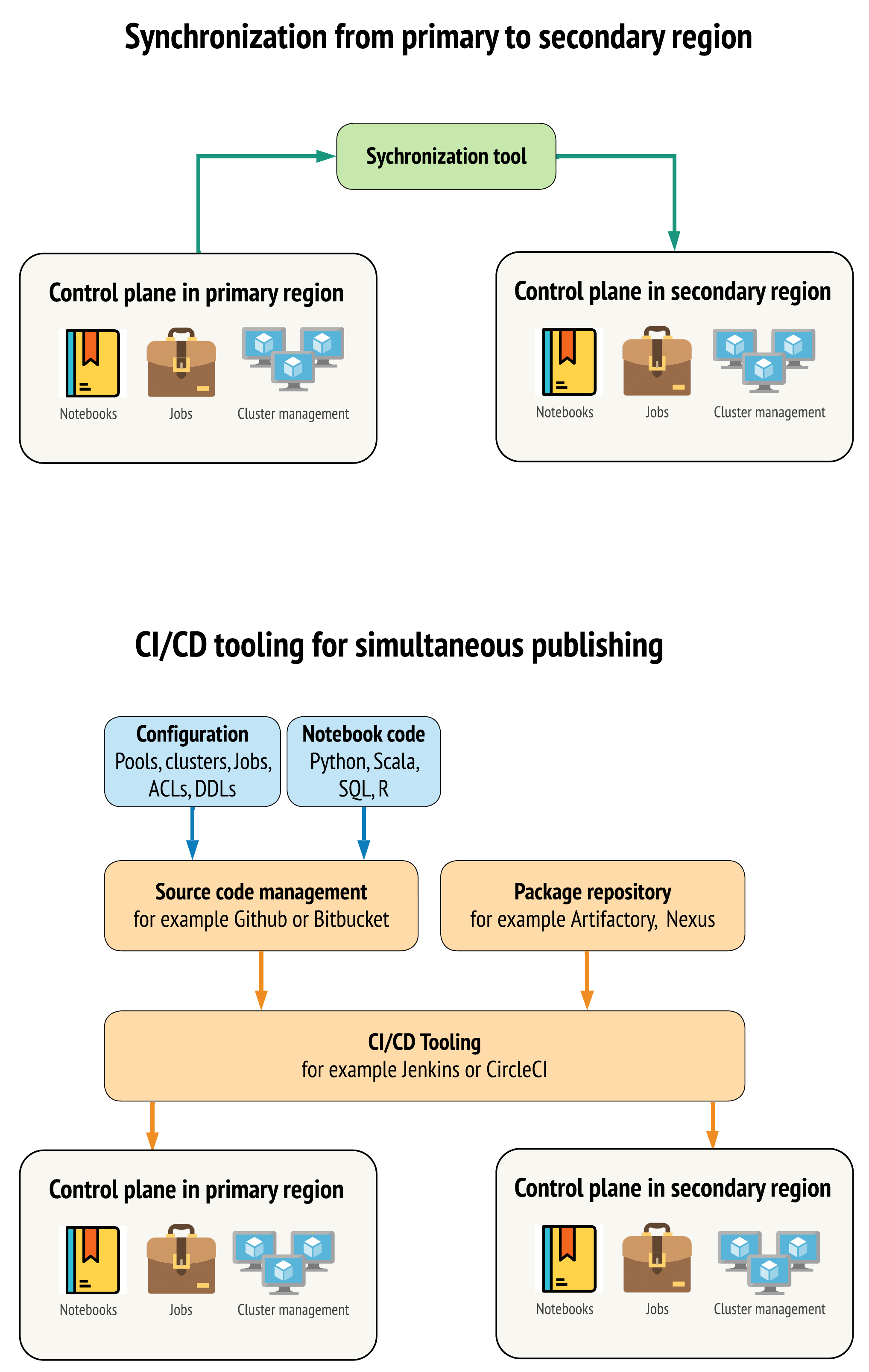
En fonction de vos besoins, vous pouvez combiner les approches. Par exemple, utilisez CI/CD pour le code source du bloc-notes, mais utilisez la synchronisation pour la configuration, comme les pools et les contrôles d’accès.
Le tableau suivant décrit comment gérer différents types de données avec chaque option d’outils.
| Description | Comment gérer avec les outils d’intégration continue/de CD | Comment gérer avec l’outil de synchronisation |
|---|---|---|
| Code source : exportations de la source notebook et code source pour les bibliothèques empaquetées | Co-déployez à la fois sur le serveur principal et le serveur secondaire. | Synchronisez le code source du serveur principal vers le serveur secondaire. |
| Utilisateurs et groupes | Gérez les métadonnées en tant que configuration dans Git. Vous pouvez également utiliser le même fournisseur d’identité (IdP) pour les deux espaces de travail. Co-déployez des données d’utilisateur et de groupe dans des déploiements principaux et secondaires. | Utilisez SCIM ou une autre automatisation pour les deux régions. La création manuelle n’est pas recommandée, mais si elle est utilisée, elle doit être effectuée pour les deux en même temps. Si vous utilisez une installation manuelle, créez un processus automatisé planifié pour comparer la liste des utilisateurs et des groupes entre les deux déploiements. |
| Configurations de pool | Il peut s’agir de modèles dans Git. Co-déployez à la fois sur le serveur principal et le serveur secondaire. Toutefois, min_idle_instances dans la base de données secondaire doit être égal à zéro jusqu’à l’événement de récupération d’urgence. |
Pools créés avec n’importe lequel min_idle_instances lorsqu’ils sont synchronisés avec l’espace de travail secondaire à l’aide de l’API ou de l’interface CLI. |
| Configurations du travail | Il peut s’agir de modèles dans Git. Pour le déploiement principal, déployez la définition de travail telle quelle. Pour le déploiement secondaire, déployez le travail et définissez les conversions sur zéro. Cela désactive la tâche dans ce déploiement et empêche les exécutions supplémentaires. Modifiez la valeur des conversions une fois que le déploiement secondaire devient actif. | Si les travaux s’exécutent sur des clusters existants <interactive> pour une raison quelconque, le client de synchronisation doit mapper à l’espace de travail secondaire correspondant cluster_id . |
| Listes ACL | Il peut s’agir de modèles dans Git. Co-déployez sur des déploiements principaux et secondaires pour les blocs-notes, les dossiers et les clusters. Toutefois, conservez les données des tâches jusqu’à l’événement de récupération d’urgence. | L’API Permissions peut définir des contrôles d’accès pour les clusters, les travaux, les pools, les notebooks et les dossiers. Un client de synchronisation doit mapper à des ID d’objet correspondants pour chaque objet dans l’espace de travail secondaire. Databricks recommande de créer une carte d’ID d’objet de l’espace de travail principal vers l’espace de travail secondaire tout en synchronisant ces objets avant de répliquer les contrôles d’accès. |
| Bibliothèques | Inclure dans le code source et les modèles de cluster/travail. | Synchroniser les bibliothèques personnalisées à partir de référentiels centralisés, DBFS ou le stockage cloud (peut être monté). |
| Scripts d’initialisation de cluster | Incluez dans le code source si vous préférez. | Pour une synchronisation plus simple, stockez les scripts init dans l’espace de travail principal dans un dossier commun ou dans un petit ensemble de dossiers, si possible. |
| Points de montage | Inclure dans le code source s’il est créé uniquement par le biais de travaux basés sur un bloc-notes ou d’une API de commande. | Utilisez des travaux, qui peuvent être exécutés en tant qu’activités Azure Data Factory (ADF). Notez que les points de terminaison de stockage peuvent changer, étant donné que les espaces de travail se trouvent dans des régions différentes. Cela dépend également de la stratégie de récupération d’urgence de vos données. |
| Métadonnées de table | Inclure dans le code source s’il est créé uniquement par le biais de travaux basés sur un bloc-notes ou d’une API de commande. Cela s’applique à la fois au magasin de Azure Databricks interne ou au magasin de clés externe configuré. | Comparez les définitions de métadonnées entre les méta-magasins à l’aide de l' API de catalogue Spark ou affichez créer table via un Notebook ou des scripts. Notez que les tables pour le stockage sous-jacent peuvent être basées sur une région et sont différentes entre les instances de la table de stockage. |
| Secrets | Inclure dans le code source s’il est créé uniquement par le biais de l' API de commande. Notez que certains contenus secrets peuvent être amenés à changer entre le serveur principal et le serveur secondaire. | Les secrets sont créés dans les deux espaces de travail par le biais de l’API. Notez que certains contenus secrets peuvent être amenés à changer entre le serveur principal et le serveur secondaire. |
| Configurations de cluster | Il peut s’agir de modèles dans Git. Co-déployez sur des déploiements principaux et secondaires, bien que ceux qui se trouvent dans le déploiement secondaire doivent être terminés jusqu’à l’événement de récupération d’urgence. | Les clusters sont créés une fois qu’ils sont synchronisés avec l’espace de travail secondaire à l’aide de l’API ou de l’interface CLI. Celles-ci peuvent être arrêtées explicitement si vous le souhaitez, en fonction des paramètres de terminaison automatique. |
| Autorisations pour le bloc-notes, le travail et le dossier | Il peut s’agir de modèles dans Git. Co-déploiement vers les déploiements primaires et secondaires. | Réplication à l’aide de l’API Permissions. |
Choisir des régions et plusieurs espaces de travail secondaires
Vous avez besoin d’un contrôle total sur votre déclencheur de récupération d’urgence. Vous pouvez décider de déclencher cette opération à tout moment ou pour une raison quelconque. Vous devez assumer la responsabilité de la stabilisation de la récupération d’urgence avant de pouvoir redémarrer le mode de restauration automatique de l’opération (production normale). En général, cela signifie que vous devez créer plusieurs espaces de travail Azure Databricks pour répondre à vos besoins en matière de production et de récupération d’urgence, et choisir votre région de basculement secondaire.
Dans Azure, Vérifiez la disponibilité de vos données , ainsi que la disponibilité des types de produits et de machines virtuelles.
Étape 3 : préparer les espaces de travail et effectuer une copie unique
Si un espace de travail est déjà en production, il est courant d’exécuter une opération de copie unique pour synchroniser votre déploiement passif avec votre déploiement actif. Cette copie unique gère les éléments suivants :
- Réplication des données: répliquer à l’aide d’une solution de réplication Cloud ou d’une opération de clonage profond Delta.
- Génération de jetons: utilisez la génération de jetons pour automatiser la réplication et les charges de travail futures.
- Réplication d'espace de travail: utilisez la réplication d’espace de travail à l’aide des méthodes décrites à l’étape 4 : préparer vos sources de données.
- Validation de l’espace de travail:-test pour vérifier que l’espace de travail et le processus peuvent s’exécuter correctement et fournir les résultats attendus.
Après votre première opération de copie unique, les actions de copie et de synchronisation suivantes sont plus rapides et toute journalisation à partir de vos outils est également un journal de ce qui a changé et de quel moment.
Étape 4 : préparer vos sources de données
Azure Databricks pouvez traiter une grande variété de sources de données à l’aide du traitement par lots ou des flux de données.
Traitement par lots à partir de sources de données
Lorsque les données sont traitées par lot, elles se trouvent généralement dans une source de données qui peut être répliquée facilement ou distribuée dans une autre région.
Par exemple, les données peuvent être téléchargées régulièrement vers un emplacement de stockage cloud. En mode de récupération d’urgence pour votre région secondaire, vous devez vous assurer que les fichiers sont chargés dans votre stockage de région secondaire. Les charges de travail doivent lire le stockage de la région secondaire et écrire dans le stockage de la région secondaire.
Flux de données
Le traitement d’un flux de données est un défi plus important. Les données de streaming peuvent être ingérées à partir de différentes sources et être traitées et envoyées à une solution de diffusion en continu :
- File d’attente de messages telle que Kafka
- Flux de données de capture de données modifiées
- Traitement continu basé sur les fichiers
- Traitement planifié basé sur des fichiers, également connu sous le nom de déclencheur une fois
Dans tous ces cas, vous devez configurer vos sources de données pour gérer le mode de récupération d’urgence et utiliser votre déploiement secondaire dans votre région secondaire.
Un writer de flux stocke un point de contrôle avec des informations sur les données qui ont été traitées. Ce point de contrôle peut contenir un emplacement de données (généralement le stockage cloud) qui doit être modifié vers un nouvel emplacement pour garantir le redémarrage réussi du flux. Par exemple, le sous-dossier source sous le point de contrôle peut stocker le dossier du Cloud basé sur des fichiers.
Ce point de contrôle doit être répliqué en temps opportun. Envisagez de synchroniser l’intervalle de point de contrôle avec toute nouvelle solution de réplication Cloud.
La mise à jour du point de contrôle est une fonction du writer et s’applique donc à l’ingestion du flux de données ou au traitement et au stockage sur une autre source de streaming.
Pour les charges de travail de diffusion en continu, assurez-vous que les points de contrôle sont configurés dans le stockage géré par le client afin qu’ils puissent être répliqués dans la région secondaire pour la reprise de la charge de travail à partir du point de dernier échec. Vous pouvez également choisir d’exécuter le processus de diffusion en continu secondaire en parallèle au processus principal.
Étape 5 : implémenter et tester votre solution
Testez régulièrement la configuration de la récupération d’urgence pour vous assurer qu’elle fonctionne correctement. Il n’y a aucune valeur dans le maintien d’une solution de récupération d’urgence si vous ne pouvez pas l’utiliser lorsque vous en avez besoin. Certaines entreprises basculent entre les régions tous les quelques mois. Le changement de régions selon une planification régulière teste vos hypothèses et vos processus et s’assure qu’ils répondent à vos besoins de récupération. Cela garantit également que votre organisation connaît les stratégies et les procédures relatives aux situations d’urgence.
Important
Testez régulièrement votre solution de récupération d’urgence dans des conditions réelles.
Si vous découvrez que vous ne disposez pas d’un objet ou d’un modèle et que vous devez toujours vous reposer sur les informations stockées dans votre espace de travail principal, modifiez votre plan pour supprimer ces obstacles, répliquez ces informations dans le système secondaire ou rendez-les disponibles d’une autre façon.
Testez toutes les modifications organisationnelles nécessaires à vos processus et à la configuration en général. Votre plan de récupération d’urgence a un impact sur votre pipeline de déploiement et il est important que votre équipe sache ce qui doit rester synchronisé. Une fois que vous avez configuré vos espaces de travail de récupération d’urgence, vous devez vous assurer que votre infrastructure (manuelle ou code), les travaux, les blocs-notes, les bibliothèques et d’autres objets d’espace de travail sont disponibles dans votre région secondaire.
Contactez votre équipe pour savoir comment développer des processus de travail standard et des pipelines de configuration pour déployer des modifications dans tous les espaces de travail. Gérer les identités des utilisateurs dans tous les espaces de travail. N’oubliez pas de configurer des outils tels que l’automatisation des travaux et la surveillance pour les nouveaux espaces de travail.
Planifiez et testez les modifications apportées aux outils de configuration :
- Ingestion : comprenez où se trouvent vos sources de données et où ces sources obtiennent leurs données. Dans la mesure du possible, paramétrez la source et vérifiez que vous disposez d’un modèle de configuration distinct pour travailler avec vos déploiements secondaires et régions secondaires. Préparez un plan de basculement et testez toutes les hypothèses.
- Modifications de l’exécution : Si vous avez un planificateur pour déclencher des travaux ou d’autres actions, vous devrez peut-être configurer un planificateur distinct qui fonctionne avec le déploiement secondaire ou ses sources de données. Préparez un plan de basculement et testez toutes les hypothèses.
- Connectivité interactive : réfléchissez à la façon dont la configuration, l’authentification et les connexions réseau peuvent être affectées par des interruptions régionales pour toute utilisation d’API REST, d’outils CLI ou d’autres services tels que JDBC/ODBC. Préparez un plan de basculement et testez toutes les hypothèses.
- Modifications de l’automatisation : pour tous les outils d’automatisation, préparez un plan de basculement et testez toutes les hypothèses.
- Sorties : pour tous les outils qui génèrent des données de sortie ou des journaux, préparez un plan de basculement et testez toutes les hypothèses.
Test de basculement
La récupération d’urgence peut être déclenchée par de nombreux scénarios différents. Il peut être déclenché par une interruption inattendue. Certaines fonctionnalités principales peuvent être inactives, notamment le réseau Cloud, le stockage cloud ou un autre service de base. Vous n’avez pas accès pour arrêter le système normalement et vous devez essayer de le récupérer. Toutefois, le processus peut être déclenché par un arrêt ou une panne planifiée, ou même par un basculement régulier de vos déploiements actifs entre deux régions.
Lorsque vous testez le basculement, connectez-vous au système et exécutez un processus d’arrêt. Assurez-vous que toutes les tâches sont terminées et que les clusters sont terminés.
Un client de synchronisation (ou des outils CI/CD) peut répliquer les objets et les ressources Azure Databricks pertinents dans l’espace de travail secondaire. Pour activer votre espace de travail secondaire, votre processus peut inclure une partie ou la totalité des éléments suivants :
- Exécutez les tests pour confirmer que la plateforme est à jour.
- Désactivez les pools et les clusters de la région primaire de sorte que si le service défaillant retourne en ligne, la région primaire ne commence pas à traiter les nouvelles données.
- Processus de récupération
- Vérifiez la date des dernières données synchronisées. Voir Terminologie de la récupération d’urgence du secteur d’activité. Les détails de cette étape varient en fonction de la façon dont vous synchronisez les données et des besoins spécifiques de votre entreprise.
- Stabilisez vos sources de données et assurez-vous qu’elles sont toutes disponibles. incluez toutes les sources de données externes, telles que le Cloud Azure SQL, ainsi que vos fichiers Delta Lake, Parquet ou autres.
- Recherchez votre point de récupération de streaming. Configurez le processus de redémarrage à partir de là et disposez d’un processus prêt à identifier et à éliminer les doublons potentiels (Delta Lake Lake facilite cette tâche).
- Terminez le processus de transmission de données et informez les utilisateurs.
- Démarrez les pools appropriés (ou augmentez le
min_idle_instancesau nombre correspondant). - Démarrez les clusters appropriés (s’ils ne sont pas arrêtés).
- Modifiez l’exécution simultanée des travaux et exécutez les tâches appropriées. Il peut s’agir d’exécutions ponctuelles ou périodiques.
- Pour tout outil externe qui utilise une URL ou un nom de domaine pour votre espace de travail Azure Databricks, mettez à jour les configurations pour tenir compte du nouveau plan de contrôle. Par exemple, mettez à jour les URL des API REST et des connexions JDBC/ODBC. L’URL du client de Azure Databricks application Web change lorsque le plan de contrôle change, avertissez les utilisateurs de votre organisation de la nouvelle URL.
Restauration de test (restauration automatique)
La restauration automatique est plus facile à contrôler et peut être effectuée dans une fenêtre de maintenance. Ce plan peut inclure tout ou partie des éléments suivants :
- Demandez confirmation que la région primaire est restaurée.
- Désactivez les pools et les clusters sur la région secondaire pour qu’elle ne commence pas à traiter les nouvelles données.
- Synchronisez les ressources nouvelles ou modifiées dans l’espace de travail secondaire dans le déploiement principal. Selon la conception de vos scripts de basculement, vous pouvez exécuter les mêmes scripts pour synchroniser les objets de la région secondaire (récupération d’urgence) vers la région principale (production).
- Synchronisez toutes les nouvelles mises à jour de données dans le déploiement principal. Vous pouvez utiliser les pistes d’audit des journaux et des tables delta pour garantir l’absence de perte de données.
- Arrêtez toutes les charges de travail dans la région de récupération d’urgence.
- Modifiez l’URL des travaux et des utilisateurs en la région primaire.
- Exécutez les tests pour confirmer que la plateforme est à jour.
- Démarrez les pools appropriés (ou augmentez le
min_idle_instancesau nombre correspondant). - Démarrez les clusters appropriés (s’ils ne sont pas arrêtés).
- Modifiez l’exécution simultanée des travaux et exécutez les tâches appropriées. Il peut s’agir d’exécutions ponctuelles ou périodiques.
- Si nécessaire, configurez à nouveau votre région secondaire pour la récupération d’urgence ultérieure.
Scripts d’automatisation, exemples et prototypes
Scripts d’automatisation à prendre en compte pour vos projets de récupération d’urgence :
- Databricks vous recommande d’utiliser le fournisseur Databricks Terraform pour vous aider à développer votre propre processus de synchronisation.
- Voir aussi outils de migration de l’espace de travail Databricks pour les exemples et les scripts de prototype. En plus des objets Azure Databricks, répliquez les pipelines de Azure Data Factory appropriés afin qu’ils fassent référence à un service lié qui est mappé à l’espace de travail secondaire.
- Le projet Databricks Sync (DBSync) est un outil de synchronisation d’objets qui sauvegarde, restaure et synchronise les espaces de travail Databricks.