Exécuter une instance Databricks Notebook avec l’activité Databricks Notebook dans Azure Data Factory
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Dans ce tutoriel, vous allez utiliser le portail Azure pour créer un pipeline Azure Data Factory qui exécute une instance Databricks Notebook sur le cluster de travaux Databricks. Il transmet également les paramètres Azure Data Factory à l’instance Databricks Notebook pendant l’exécution.
Dans ce tutoriel, vous allez effectuer les étapes suivantes :
Créer une fabrique de données.
Créer un pipeline qui utilise l’activité Databricks Notebook.
Déclencher une exécution du pipeline.
Surveiller l’exécution du pipeline.
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Remarque
Pour plus d’informations sur l’utilisation de l’activité de notebook Databricks, notamment l’utilisation de bibliothèques et la transmission de paramètres d’entrée et de sortie, reportez-vous à la documentation de l’activité de notebook Databricks.
Prérequis
- Espace de travail Azure Databricks. Créez un espace de travail Databricks ou utilisez-en un existant. Créez une instance Python Notebook dans votre espace de travail Azure Databricks. Exécutez ensuite l’instance Notebook et transmettez-lui les paramètres via Azure Data Factory.
Créer une fabrique de données
Lancez le navigateur web Microsoft Edge ou Google Chrome. L’interface utilisateur de Data Factory n’est actuellement prise en charge que par les navigateurs web Microsoft Edge et Google Chrome.
Dans le menu du portail Azure, sélectionnez Créer une ressource, Intégration, puis Data Factory.
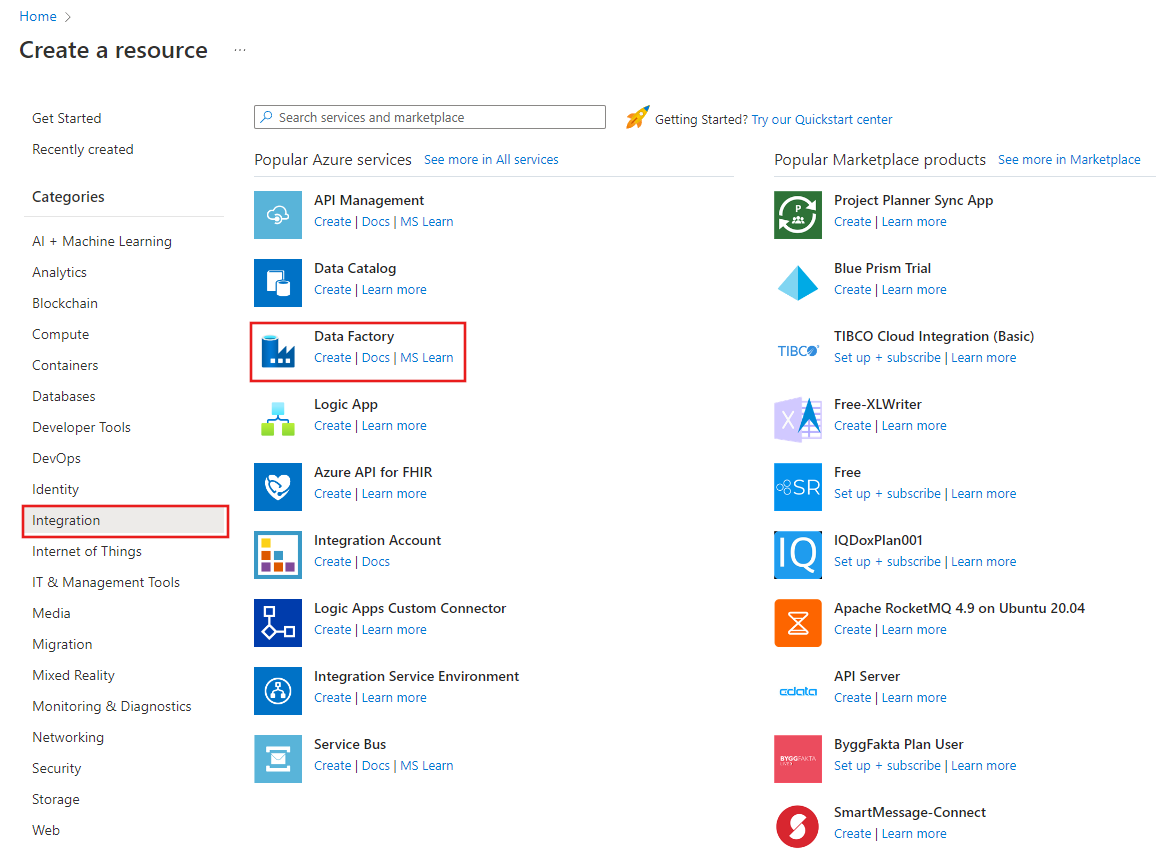
Dans la page Créer une fabrique de données, sous l’onglet De base, sélectionnez l’Abonnement Azure dans lequel vous voulez créer la fabrique de données.
Pour Groupe de ressources, réalisez l’une des opérations suivantes :
Sélectionnez un groupe de ressources existant dans la liste déroulante.
Sélectionnez Créer, puis entrez le nom d’un nouveau groupe de ressources.
Pour plus d’informations sur les groupes de ressources, consultez Utilisation des groupes de ressources pour gérer vos ressources Azure.
Pour Région, sélectionnez l’emplacement de la fabrique de données.
La liste n’affiche que les emplacements pris en charge par Data Factory et où vos métadonnées Azure Data Factory sont stockées. Les magasins de données associés (tels que Stockage Azure et Azure SQL Database) et les services de calcul (comme Azure HDInsight) utilisés par Data Factory peuvent s’exécuter dans d’autres régions.
Pour Nom, entrez ADFTutorialDataFactory.
Le nom de la fabrique de données Azure doit être un nom global unique. Si l’erreur suivante s’affiche, changez le nom de la fabrique de données (par exemple, utilisez <votrenom>ADFTutorialDataFactory). Consultez l’article Data Factory - Règles d’affectation des noms pour en savoir plus sur les règles d’affectation des noms d’artefacts Data Factory.
Pour Version, sélectionnez V2.
Sélectionnez Suivant : Configuration Git, puis cochez la case Configurer Git plus tard.
Sélectionnez Vérifier + créer, puis sélectionnez Créer une fois la validation passée.
Une fois la ressource créée, sélectionnez Accéder à la ressource pour ouvrir la page Data Factory. Sélectionnez la vignette Ouvrir Azure Data Factory Studio pour démarrer l’interface utilisateur d’Azure Data Factory sous un onglet de navigateur distinct.

Créez des services liés
Dans cette section, vous allez créer un service Databricks lié. Ce service lié contient les informations de connexion au cluster Databricks :
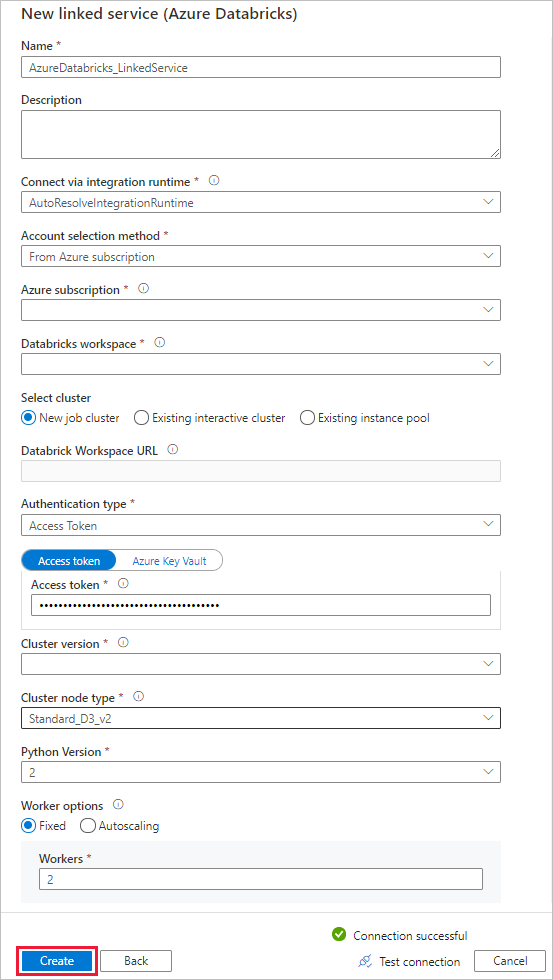
Créer un service Azure Databricks lié
Dans la page d’accueil, basculez vers l’onglet Gérer dans le volet gauche.
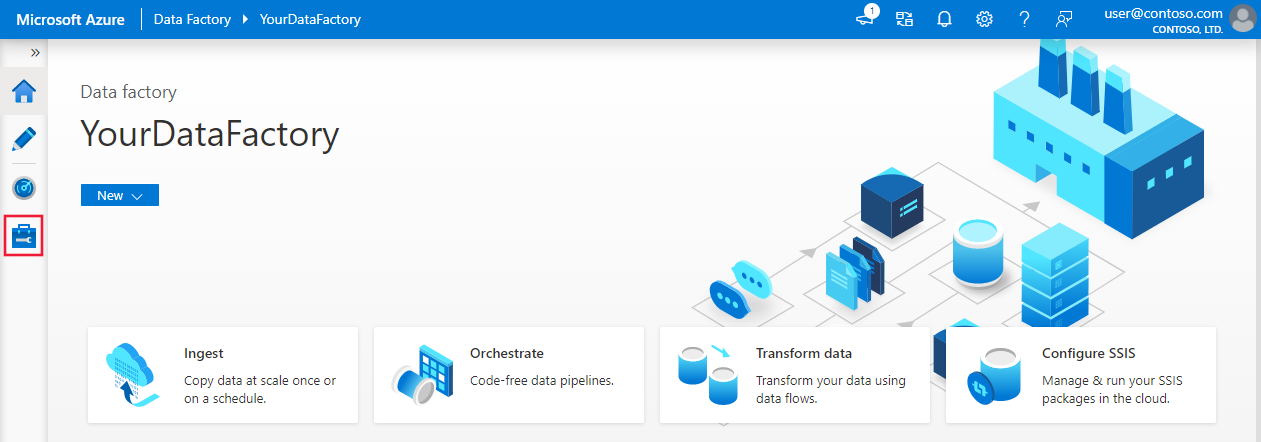
Sélectionnez Services liés sous Connexions, puis + Nouveau.
Dans la fenêtre Nouveau service lié, sélectionnez Calcul>Azure Databricks, puis Continuer.

Dans la fenêtre Nouveau service lié, effectuez les étapes suivantes :
Dans Nom, entrez AzureDatabricks_LinkedService.
Sélectionnez l’espace de travail Databricks approprié dans lequel vous exécuterez votre notebook.
Dans Sélectionner un cluster, sélectionnez Nouveau cluster de travail.
Pour URL de l’espace de travail Databricks, les informations devraient être renseignées automatiquement.
Pour Type d’authentification, si vous sélectionnez Jeton d’accès, générez-le à partir de l’espace de travail Azure Databricks. Vous trouverez la procédure ici. Pour Identité MSI (Managed Service Identity) et Identité managée affectée par l’utilisateur, accordez le rôle Contributeur aux deux identités dans le menu Contrôle d’accès de la ressource Azure Databricks.
Pour Version de cluster, sélectionnez la version que vous souhaitez utiliser.
Dans Cluster node type (Type de nœud de cluster), sélectionnez Standard_D3_v2 sous la catégorie General Purpose (HDD) (Usage général (HDD)) pour ce didacticiel.
Dans Rôles de travail, entrez 2.
Sélectionnez Create (Créer).
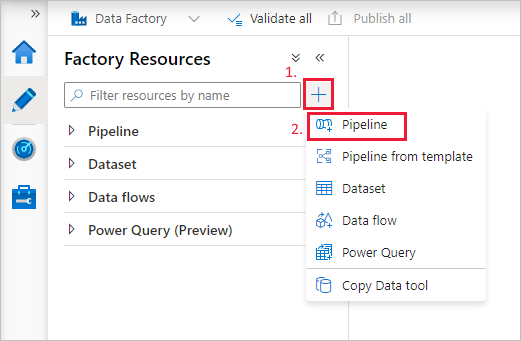
Créer un pipeline
Cliquez sur le bouton + (plus), puis sélectionnez Pipeline dans le menu.
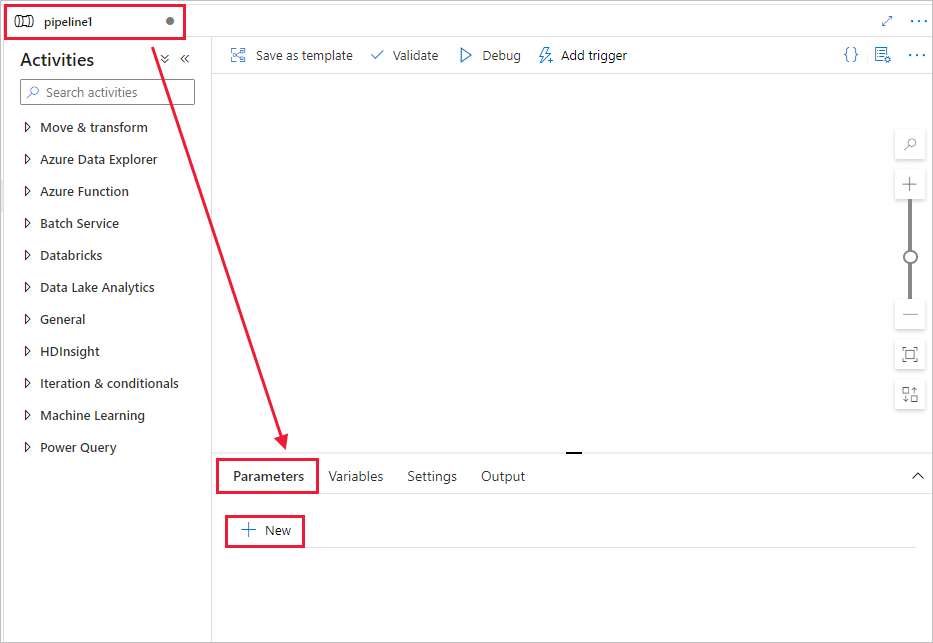
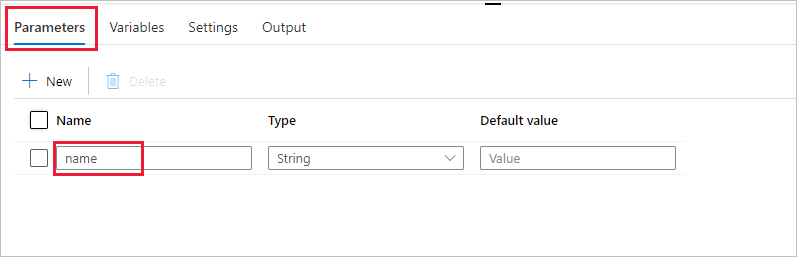
Créez un paramètre à utiliser dans le pipeline. Vous pourrez ensuite le transmettre à l’activité Databricks Notebook. Dans le pipeline vide, sélectionnez l’onglet Paramètres, puis sélectionnez + Nouveau et entrez « name » comme nom.
Dans la boîte à outils Activités, étendez Databricks. Faites glisser l’activité Notebook depuis la boîte à outils Activités vers la surface du concepteur de pipeline.
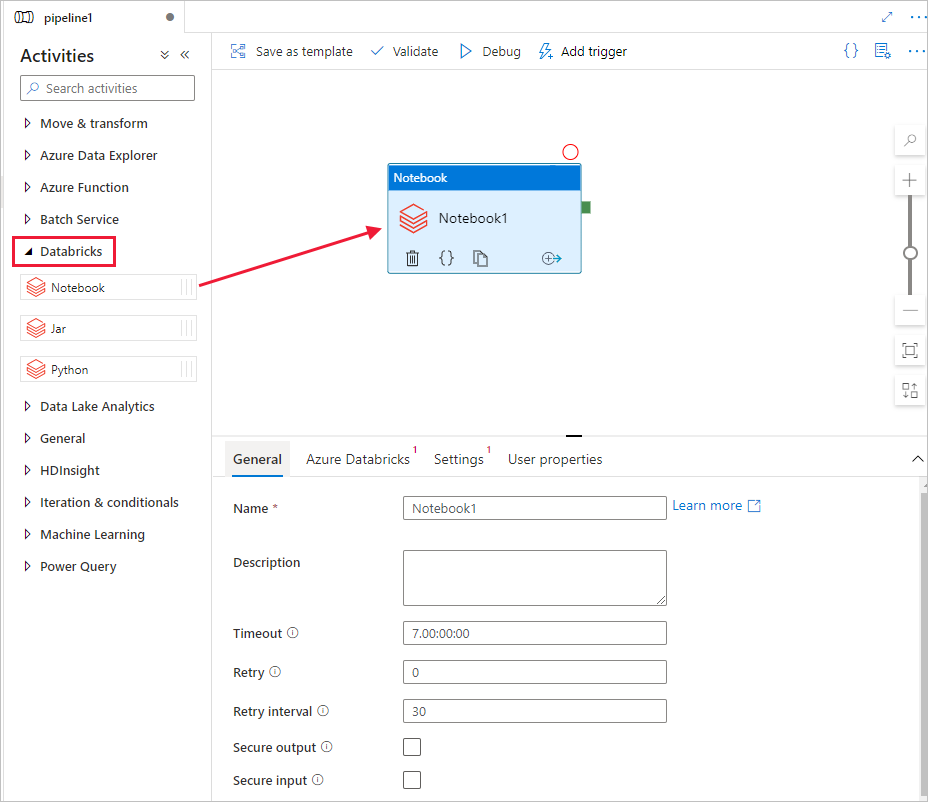
Dans les propriétés de la fenêtre d’activité DatabricksNotebook en bas, effectuez les étapes suivantes :
Basculez vers l’onglet Azure Databricks.
Sélectionnez AzureDatabricks_LinkedService (créé lors de la procédure précédente).
Basculez vers l’onglet Paramètres .
Parcourez pour sélectionner un chemin d’accès à Notebook Databricks. Créez une instance Notebook et spécifiez le chemin d’accès ici. Vous obtenez le chemin d’accès de l’instance Notebook en procédant comme suit.
Lancez votre espace de travail Azure Databricks.
Créez un nouveau dossier dans l’espace de travail et nommez-le adftutorial.
Créez un notebook et appelez-le mynotebook. Cliquez avec le bouton droit sur le dossier adftutorial et sélectionnez Créer.
Dans l’instance Notebook récemment créée, mynotebook, ajoutez le code suivant :
# Creating widgets for leveraging parameters, and printing the parameters dbutils.widgets.text("input", "","") y = dbutils.widgets.get("input") print ("Param -\'input':") print (y)Le chemin du notebook dans ce cas est /adftutorial/mynotebook.
Revenez à la l’outil de création de l’interface utilisateur de la fabrique de données. Accédez à l’onglet Paramètres sous l’activité Notebook1.
a. Ajoutez un paramètre à l’activité Notebook. Utilisez le même paramètre que celui ajouté précédemment au pipeline.
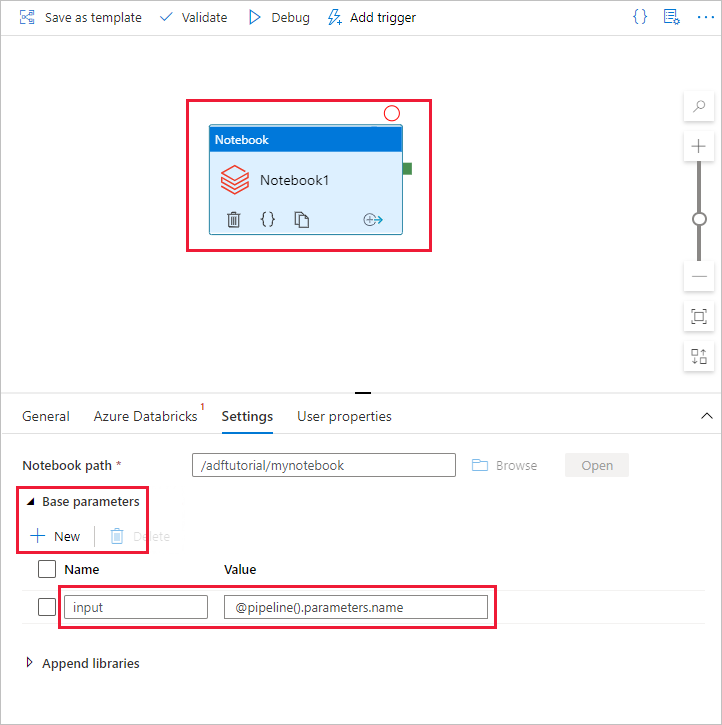
b. Nommez le paramètre input et indiquez la valeur sous la forme de l’expression @pipeline().parameters.name.
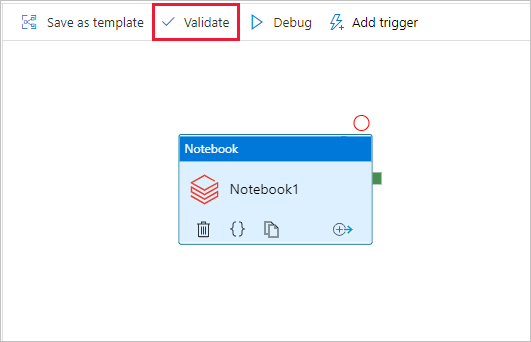
Pour valider le pipeline, cliquez sur le bouton Valider dans la barre d’outils. Pour fermer la fenêtre de validation, sélectionnez le bouton Fermer.
Sélectionnez Tout publier. L’interface utilisateur de Data Factory publie des entités (services liés et pipelines) sur le service Azure Data Factory.
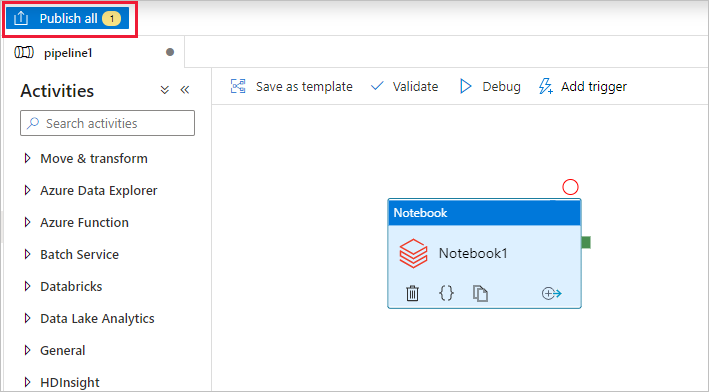
Déclencher une exécution du pipeline
Sélectionnez Ajouter un déclencheur dans la barre d’outils, puis Déclencher maintenant.
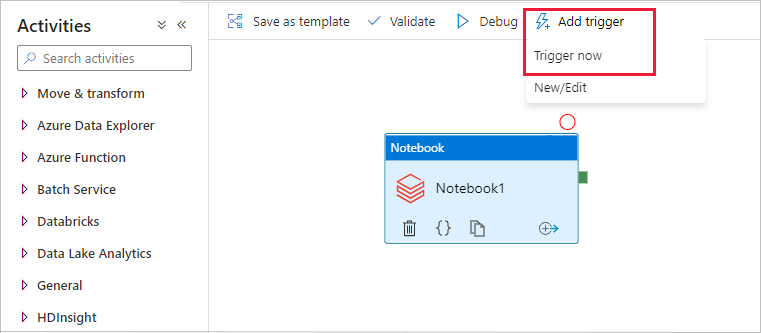
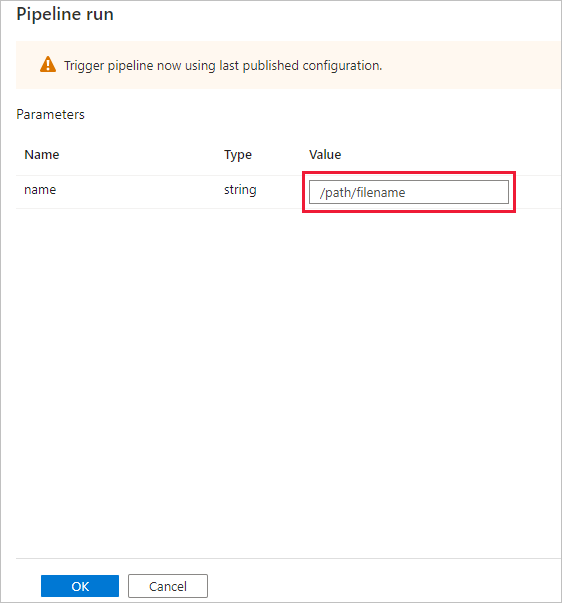
La boîte de dialogue Exécution de pipeline invite à saisir le paramètre name. Utilisez ici /path/filename comme paramètre. Sélectionnez OK.
Surveiller l’exécution du pipeline.
Basculez vers l’onglet Surveiller. Vérifiez qu’un pipeline est exécuté. Il faut compter environ 5 à 8 minutes pour créer un cluster de travaux Databricks, où s’exécute l’instance Notebook.
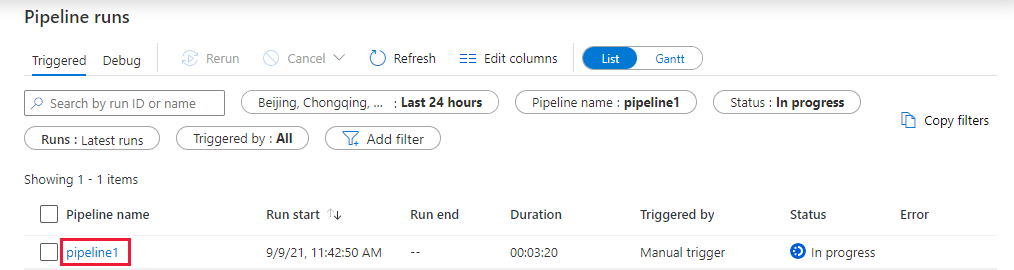
Cliquez régulièrement sur Actualiser pour vérifier l’état de l’exécution des pipelines.
Pour voir les exécutions d’activités associées à l’exécution du pipeline, sélectionnez le lien pipeline1 sous la colonne Nom du pipeline.
Dans la page Exécutions de l’activité, sélectionnez Sortie dans la colonne Nom de l’activité pour afficher la sortie de chaque activité ; le lien vers les journaux Databricks dans le volet Sortie vous donne accès à des journaux Spark plus détaillés.
Vous pouvez revenir à l’affichage des exécutions de pipeline en sélectionnant le lien Toutes les exécutions de pipeline dans le menu de navigation en haut.
Vérifier la sortie
Vous pouvez vous connecter à l’espace de travail Azure Databricks, accéder à Exécutions du travail et voir l’état du Travail : en attente d’exécution, en cours d’exécution ou terminé.
Vous pouvez sélectionner le Nom du travail et naviguer pour voir plus de détails. Une fois l’exécution réussie, vous pouvez valider les paramètres transmis et la sortie de l’instance Notebook Python.
Résumé
Le pipeline dans cet exemple déclenche une activité Databricks Notebook et lui transmet un paramètre. Vous avez appris à :
Créer une fabrique de données.
Créer un pipeline qui utilise l’activité Databricks Notebook.
Déclencher une exécution du pipeline.
Surveiller l’exécution du pipeline.