Copier des données à partir de Google BigQuery à l’aide d’Azure Data Factory ou de Synapse Analytics (hérité)
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article décrit comment utiliser l’activité de copie dans des pipelines Azure Data Factory et Azure Synapse Analytics pour copier des données à partir de Google BigQuery. Il s’appuie sur l’article Vue d’ensemble de l’activité de copie.
Important
Le connecteur Google BigQuery V2 offre une meilleure prise en charge native de Google BigQuery. Si vous utilisez le connecteur Google BigQuery V1 dans votre solution, veuillez mettre à jour votre connecteur Google BigQuery car la V1 est en phase de fin de prise en charge. Pour plus de détails sur les différences entre la V2 et la V1, reportez-vous à cette section.
Fonctionnalités prises en charge
Ce connecteur Google BigQuery est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR |
|---|---|
| Activité de copie (source/-) | ① ② |
| Activité de recherche | ① ② |
① Runtime d’intégration Azure ② Runtime d’intégration auto-hébergé
Pour obtenir la liste des banques de données prises en charge en tant que sources ou récepteurs par l’activité de copie, consultez le tableau banques de données prises en charge.
Le service fournit un pilote intégré pour permettre la connectivité. Vous n’avez donc pas besoin d’installer manuellement un pilote pour utiliser ce connecteur.
Le connecteur prend en charge les versions Windows de cet article.
Remarque
Ce connecteur Google BigQuery repose sur les API BigQuery. N’oubliez pas que BigQuery limite le taux maximal de requêtes entrantes et applique des quotas appropriés sur une base par projet. Reportez-vous à Quotas et limites - requêtes d’API. Assurez-vous que vous ne déclenchez pas trop de demandes simultanées pour le compte.
Prérequis
Pour utiliser ce connecteur, vous avez besoin des autorisations minimales suivantes de Google BigQuery :
- bigquery.connections.*
- bigquery.datasets.*
- bigquery.jobs.*
- bigquery.readsessions.*
- bigquery.routines.*
- bigquery.tables.*
Démarrage
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
Créer un service lié à Google BigQuery à l’aide de l’interface utilisateur
Suivez les étapes suivantes pour créer un service lié à Google BigQuery dans l’interface utilisateur du portail Azure.
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse, sélectionnez Services liés, puis cliquez sur Nouveau :
Recherchez Google et sélectionnez le connecteur Google BigQuery.
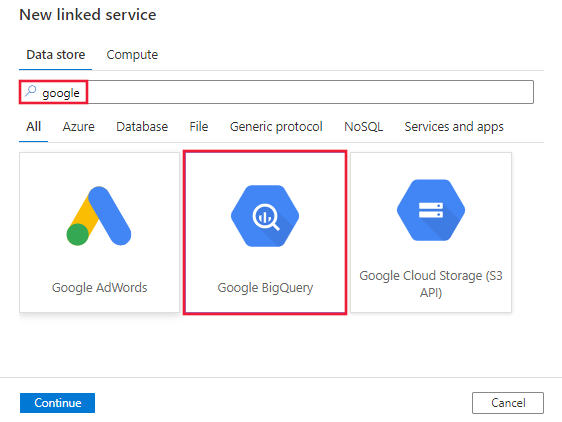
Configurez les informations du service, testez la connexion et créez le nouveau service lié.
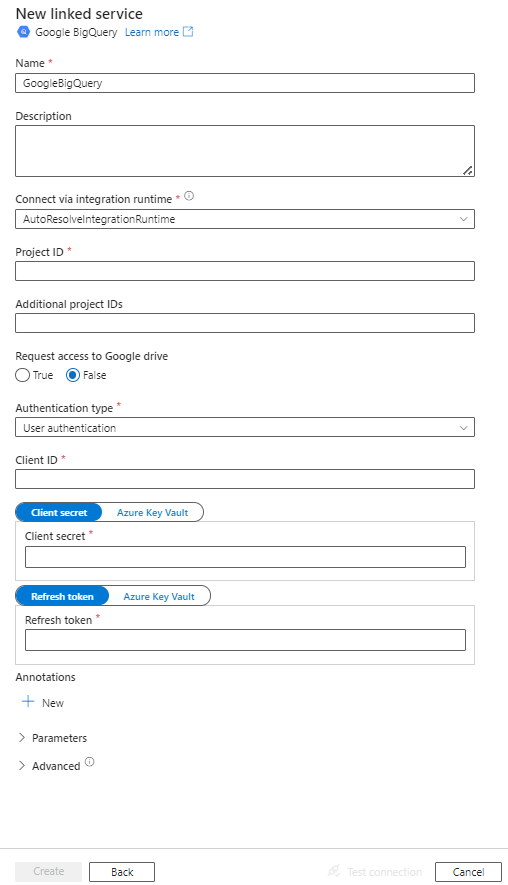
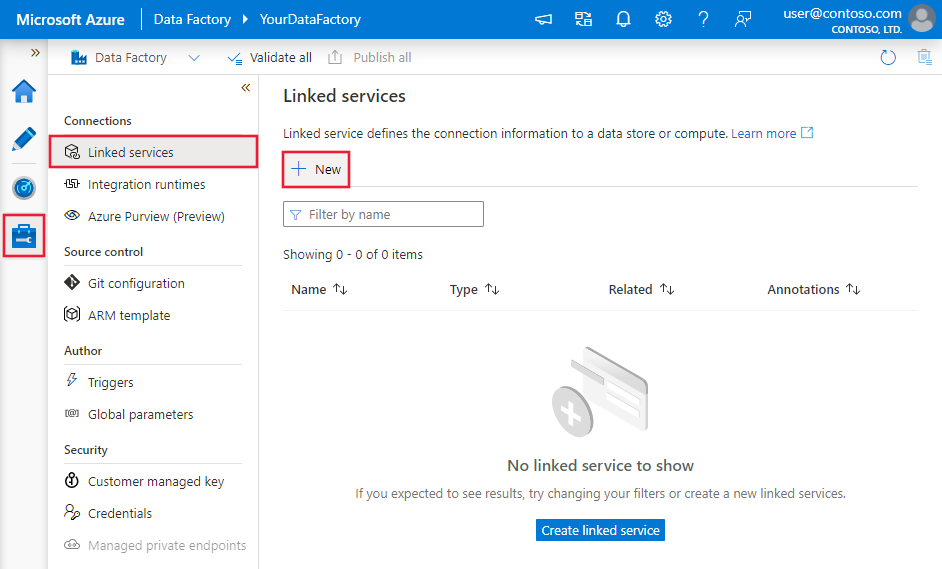
Informations de configuration du connecteur
Les sections suivantes fournissent des informations détaillées sur les propriétés utilisées pour définir les entités spécifiques du connecteur Google BigQuery.
Propriétés du service lié
Les propriétés prises en charge pour le service lié Google BigQuery sont les suivantes.
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur GoogleBigQuery. | Oui |
| project | L’ID du projet BigQuery par défaut sur lequel exécuter la requête. | Oui |
| additionalProjects | Liste séparée par des virgules des ID de projets BigQuery publics accessibles. | Non |
| requestGoogleDriveScope | Pour demander l’accès à Google Drive. Autoriser l’accès à Google Drive active la prise en charge des tables fédérées qui combinent les données BigQuery avec les données issues de Google Drive. La valeur par défaut est false. | Non |
| authenticationType | Mécanisme d’authentification OAuth 2.0 utilisé pour l’authentification. ServiceAuthentication ne peut être utilisé que sur un runtime d’intégration auto-hébergé. Les valeurs autorisées sont UserAuthentication et ServiceAuthentication. Reportez-vous aux sections suivant ce tableau pour accéder à d’autres propriétés et à des exemples JSON sur ces types d’authentification. |
Oui |
Utiliser l’authentification utilisateur
Définissez la valeur de la propriété « authenticationType » sur UserAuthentication et spécifiez les propriétés suivantes ainsi que les propriétés génériques décrites dans la section précédente :
| Propriété | Description | Obligatoire |
|---|---|---|
| clientId | ID de l’application utilisée pour générer le jeton d’actualisation. | Oui |
| clientSecret | Secret de l’application utilisée pour générer le jeton d’actualisation. Marquez ce champ en tant que SecureString afin de le stocker en toute sécurité, ou référencez un secret stocké dans Azure Key Vault. | Oui |
| refreshToken | Le jeton d’actualisation obtenu de Google servant à autoriser l’accès à BigQuery. Découvrez comment en obtenir un en consultant Obtention de jetons d’accès OAuth 2.0 et ce blog de communauté. Marquez ce champ en tant que SecureString afin de le stocker en toute sécurité, ou référencez un secret stocké dans Azure Key Vault. | Oui |
L’étendue minimale requise pour obtenir un jeton d’actualisation OAuth 2.0 est https://www.googleapis.com/auth/bigquery.readonly. Si vous envisagez d’exécuter une requête qui peut retourner des résultats volumineux, d’autres étendues peuvent être requises. Pour plus d’informations, reportez-vous à cet article.
Exemple :
{
"name": "GoogleBigQueryLinkedService",
"properties": {
"type": "GoogleBigQuery",
"typeProperties": {
"project" : "<project ID>",
"additionalProjects" : "<additional project IDs>",
"requestGoogleDriveScope" : true,
"authenticationType" : "UserAuthentication",
"clientId": "<id of the application used to generate the refresh token>",
"clientSecret": {
"type": "SecureString",
"value":"<secret of the application used to generate the refresh token>"
},
"refreshToken": {
"type": "SecureString",
"value": "<refresh token>"
}
}
}
}
Utiliser l’authentification du service
Définissez la valeur de la propriété « authenticationType » sur ServiceAuthentication et spécifiez les propriétés suivantes ainsi que les propriétés génériques décrites dans la section précédente. Ce type d’authentification ne peut être utilisé que sur un runtime d’intégration auto-hébergé.
| Propriété | Description | Obligatoire |
|---|---|---|
| ID d’e-mail du compte de service utilisé pour ServiceAuthentication. Il ne peut être utilisé que sur un runtime d’intégration auto-hébergé. | Non | |
| keyFilePath | Le chemin complet vers le fichier clé .json utilisé pour authentifier l'adresse e-mail du compte de service. |
Oui |
| trustedCertPath | Chemin complet du fichier .pem qui contient les certificats d'autorité de certification approuvés utilisés pour vérifier le serveur lorsque vous vous connectez via TLS. Cette propriété ne peut être définie que lorsque vous utilisez TLS sur le runtime d'intégration auto-hébergé. Valeur par défaut : le fichier cacerts.pem installé avec le runtime d’intégration. | Non |
| useSystemTrustStore | Indique s’il faut utiliser un certificat d’autorité de certification provenant du magasin de confiance du système ou d’un fichier .pem spécifié. La valeur par défaut est false. | Non |
Remarque
Le connecteur ne prend plus en charge les fichiers de clé P12. Si vous utilisez des comptes de service, il est recommandé d’utiliser plutôt des fichiers de clés JSON. La propriété P12CustomPwd utilisée pour prendre en charge le fichier de clé P12 est également obsolète. Pour plus d’informations, consultez cet article.
Exemple :
{
"name": "GoogleBigQueryLinkedService",
"properties": {
"type": "GoogleBigQuery",
"typeProperties": {
"project" : "<project id>",
"requestGoogleDriveScope" : true,
"authenticationType" : "ServiceAuthentication",
"email": "<email>",
"keyFilePath": "<.json key path on the IR machine>"
},
"connectVia": {
"referenceName": "<name of Self-hosted Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article Jeux de données. Cette section fournit la liste des propriétés prises en charge par le jeu de données Google BigQuery.
Pour copier des données à partir de Google BigQuery, définissez la propriété type du jeu de données sur GoogleBigQueryObject. Les propriétés prises en charge sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur : GoogleBigQueryObject | Oui |
| dataset | Nom du jeu de données Google BigQuery. | Non (si « query » dans la source de l’activité est spécifié) |
| table | Nom de la table. | Non (si « query » dans la source de l’activité est spécifié) |
| tableName | Nom de la table. Cette propriété est prise en charge pour la compatibilité descendante. Pour les nouvelles charges de travail, utilisez dataset et table. |
Non (si « query » dans la source de l’activité est spécifié) |
Exemple
{
"name": "GoogleBigQueryDataset",
"properties": {
"type": "GoogleBigQueryObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<GoogleBigQuery linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propriétés de l’activité de copie
Pour obtenir la liste complète des sections et des propriétés disponibles pour la définition des activités, consultez l’article Pipelines. Cette section fournit la liste des propriétés prises en charge par le type de source Google BigQuery.
GoogleBigQuerySource en tant que type de source
Pour copier des données à partir de Google BigQuery, définissez le type de source sur GoogleBigQuerySource dans l’activité de copie. Les propriétés suivantes sont prises en charge dans la section source de l’activité de copie.
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source d’activité de copie doit être définie sur GoogleBigQuerySource. | Oui |
| query | Utiliser la requête SQL personnalisée pour lire les données. par exemple "SELECT * FROM MyTable". |
Non (si « tableName » est spécifié dans dataset) |
Exemple :
"activities":[
{
"name": "CopyFromGoogleBigQuery",
"type": "Copy",
"inputs": [
{
"referenceName": "<GoogleBigQuery input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "GoogleBigQuerySource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Propriétés de l’activité Lookup
Pour en savoir plus sur les propriétés, consultez Activité Lookup.
Contenu connexe
Consultez les magasins de données pris en charge pour obtenir la liste des sources et magasins de données pris en charge en tant que récepteurs par l’activité de copie.