Surveillance de l’ingestion en file d’attente avec des métriques
Dans le processus d’ingestion mis en file d’attente, Azure Data Explorer optimise l’ingestion des données pour un débit élevé en lot en lot en lots en fonction d’une stratégie de traitement par lots d’ingestion configurable. La stratégie de traitement par lot vous permet de définir les conditions du déclencheur pour sceller un lot (taille des données, nombre d’objets blob ou temps écoulé). Ces lots sont ensuite ingérés de manière optimale afin d’accélérer les résultats de requête.
Dans cet article, vous allez apprendre à utiliser des métriques pour surveiller l’ingestion en file d’attente dans Azure Data Explorer dans Portail Azure.
Étapes de traitement par lot
Les étapes décrites dans cette section s’appliquent à toutes les ingestions par lot. Pour Les ingestions Azure Event Grid, Azure Event Hubs, Azure IoT Hub et Cosmos DB, avant que les données ne sont mises en file d’attente pour l’ingestion, une connexion de données obtient les données provenant de sources externes et effectue une réorganisation initiale des données.
L’ingestion mise en file d’attente se produit en phases :
- Batching Manager écoute la file d’attente pour les messages d’ingestion et traite les demandes.
- Batching Manager optimise le débit d’ingestion en prenant les petits segments de données d’entrée qu’il reçoit et en lot les URL en fonction de la stratégie de traitement par lots d’ingestion.
- Le Gestionnaire d’ingestion envoie les commandes d’ingestion au Moteur de stockage Azure Data Explorer
- Le Moteur de stockage Azure Data Explorer stocke les données ingérées, ce qui les rend disponibles pour la requête
Azure Data Explorer fournit un ensemble de métriques d’ingestion Azure Monitor afin de pouvoir surveiller l’ingestion des données à travers toutes les étapes et composants du processus d’ingestion mis en file d’attente.
Les métriques d’ingestion Azure Data Explorer fournissent des informations détaillées sur les éléments suivants :
- Résultat de l’ingestion mise en file d’attente.
- La quantité de données ingérées
- Latence de l’ingestion mise en file d’attente et de son emplacement.
- Le processus de traitement par lot lui-même
- Pour les ingestions Event Hubs, Event Grid et IoT Hub : nombre d’événements reçus.
Dans cet article, vous allez apprendre à utiliser des métriques d’ingestion dans le Portail Azure pour surveiller l’ingestion en file d’attente dans Azure Data Explorer.
Prérequis
- Un abonnement Azure. Créez un compte Azure gratuit.
- Un cluster et une base de données Azure Data Explorer. Créez un cluster et une base de données.
- Ingestion en file d’attente active, telle qu’Event Hubs, IoT Hub ou Event Grid.
Créer des graphiques de métriques avec l’explorateur de métriques Azure Monitor
Vous trouverez ci-dessous une explication générale de l’utilisation des métriques Azure Monitor qui seront ensuite implémentées dans les sections suivantes. Suivez les étapes ci-dessous pour créer des graphiques de métriques avec l’explorateur de métriques Azure Monitor dans le portail Azure :
Connectez-vous au portail Azure et accédez à la page de vue d’ensemble de votre cluster Azure Data Explorer.
Sélectionnez Métriques dans la barre de navigation gauche pour ouvrir le volet de métriques.
Ouvrez le panneau de sélection d’heure en haut à droite du volet de métriques et définissez l’Intervalle de temps sur l’heure que vous souhaitez analyser. Dans cet article, nous analysons l’ingestion des données dans Azure Data Explorer au cours des dernières 48 heures.
Sélectionnez une Étendue et un Espace de noms de métriques :
- L’Étendue est le nom de votre cluster Azure Data Explorer. Dans l’exemple suivant, nous utiliserons un cluster nommé demo11.
- L’Espace de noms de métriques doit être défini sur Métriques standard de cluster Kusto. Il s’agit de l’espace de noms qui contient les métriques Azure Data Explorer.

Sélectionnez le nom de la Métrique et la valeur d’Agrégation appropriée.

Pour certains exemples de cet article, nous sélectionnerons Ajouter un filtre et Appliquer la division pour les métriques qui ont des dimensions. Nous utiliserons également Ajouter une métrique pour tracer d’autres métriques dans le même graphique et + Nouveau graphique pour afficher plusieurs graphiques dans une vue unique.
Chaque fois que vous ajoutez une nouvelle métrique, répétez les étapes quatre et cinq.
Remarque
Pour en savoir plus sur l’utilisation des métriques pour superviser Azure Data Explorer en général et comment utiliser le volet de métriques, consultez Superviser les performances, l’intégrité et l’utilisation d’Azure Data Explorer avec des métriques.
Dans cet article, vous allez découvrir quelles métriques peuvent être utilisées pour suivre l’ingestion mise en file d’attente et comment utiliser ces métriques.
Afficher le résultat de l’ingestion
La métrique Résultat de l’ingestion fournit des informations sur le nombre total de sources qui ont été ingérées avec succès et celles qui n’ont pas pu être ingérées.
Dans cet exemple, nous allons utiliser cette métrique pour afficher le résultat de nos tentatives d’ingestion, et utiliser les informations d’état pour aider à corriger les tentatives ayant échoué.
- Dans le volet Métriques d’Azure Monitor, sélectionnez Ajouter une métrique.
- Sélectionnez Résultat de l’ingestion comme valeur de Métrique et Somme comme valeur d’Agrégation. Cette sélection vous montre les résultats de l’ingestion dans le temps sur une ligne de graphique.
- Sélectionnez le bouton Appliquer la division au-dessus du graphique, puis choisissez État pour segmenter votre graphique d’après l’état des résultats de l’ingestion. Après avoir sélectionné les valeurs de division, cliquez en dehors du sélecteur de division pour le fermer.
Les informations sur les métriques sont maintenant divisées par état, et nous pouvons voir les informations sur l’état des résultats de l’ingestion répartis sur trois lignes :
- Bleue pour les opérations d’ingestion réussies.
- Orange pour les opérations d’ingestion qui ont échoué car l’entité était introuvable.
- Violette pour les opérations d’ingestion qui ont échoué car la requête était incorrecte.

Tenez compte des éléments suivants lorsque vous examinez le graphique des résultats d’ingestion :
- Quand vous utilisez l’ingestion de hub d’événements ou de hub IoT, il existe une pré-agrégation d’événements dans le composant Connexion de données. Durant cette phase de l’ingestion, les événements sont traités comme une source unique à ingérer. Ainsi, quelques événements apparaissent sous la forme d’un seul résultat d’ingestion après la pré-agrégation.
- Les échecs temporaires font l’objet d’un nombre limité de nouvelles tentatives de manière interne. Chaque échec temporaire est signalé en tant que résultat d’ingestion temporaire. C’est pourquoi une ingestion unique peut aboutir à plusieurs résultats d’ingestion.
- Les erreurs d’ingestion dans le graphique sont listées par catégorie du code d’erreur. Pour voir la liste complète des codes d’erreur d’ingestion par catégorie et essayer de mieux comprendre la raison possible de l’erreur, consultez Codes d’erreur d’ingestion dans Azure Data Explorer.
- Pour obtenir plus de détails sur une erreur d’ingestion, vous pouvez définir des journaux de diagnostic d’ingestion ayant échoué. Toutefois, il est important de savoir que la génération de journaux entraîne la création de ressources supplémentaires et, par conséquent, une augmentation du coût des marchandises vendues.
Afficher la quantité de données ingérées
Les métriques blob traitées, reçues et blobs supprimées fournissent des informations sur le nombre d’objets blob traités, reçus et supprimés par les composants d’ingestion pendant les étapes de l’ingestion en file d’attente.
Dans cet exemple, nous allons utiliser ces métriques pour déterminer la quantité de données transmises par le pipeline d’ingestion, la quantité de données reçues par les composants d’ingestion et la quantité de données ignorées.
Objets blob traités
- Dans le volet Métriques d’Azure Monitor, sélectionnez Ajouter une métrique.
- Sélectionnez Objets blob traités comme valeur de Métrique et Somme comme valeur d’Agrégation.
- Sélectionnez le bouton Appliquer la division et choisissez Type de composant pour segmenter le graphique d’après les différents composants d’ingestion.
- Pour vous concentrer sur une base de données spécifique dans votre cluster, sélectionnez le bouton Ajouter un filtre au-dessus du graphique, puis choisissez les valeurs de base de données à inclure lors du traçage du graphique. Dans cet exemple, nous filtrons les objets blob envoyés à la base de données GitHub en sélectionnant Base de données comme Propriété, = comme Opérateur, et GitHub dans la liste déroulante Valeurs. Après avoir sélectionné les valeurs de filtre, cliquez en dehors du sélecteur de filtre pour le fermer.
À présent, le graphique affiche le nombre d’objets blob envoyés à la base de données GitHub qui ont été traités dans chacun des composants d’ingestion au fil du temps.

- Notez que le 13 février, il y a une baisse du nombre d’objets blob ingérés dans la base de données GitHub au fil du temps. Notez également que le nombre d’objets blob qui ont été traités dans chacun des composants est similaire, ce qui signifie que toutes les données traitées dans le composant Connexion de données ont également été traitées correctement par les composants Gestionnaire de traitement par lot, Gestionnaire d’ingestion et Moteur de stockage Azure Data Explorer. Ces données sont prêtes pour la requête.
Objets blob reçus
Pour mieux comprendre la relation entre le nombre d’objets blob qui ont été reçus au niveau de chaque composant et le nombre d’objets blob qui ont été traités avec succès par chaque composant, nous allons ajouter un nouveau graphique :
- Sélectionnez + Nouveau graphique.
- Choisissez les mêmes valeurs que ci-dessus pour l’Étendue, l’Espace de noms métrique et l’Agrégation, puis sélectionnez la métrique Objets blob reçus.
- Sélectionnez le bouton Appliquer la division et choisissez Type de composant pour diviser la métrique Objets blob reçus par type de composant.
- sélectionnez le bouton Ajouter un filtre et définissez les mêmes valeurs que précédemment pour filtrer uniquement les objets blob envoyés à la base de données GitHub.

- En comparant les graphiques, vous remarquerez que le nombre d’objets blob reçus par chaque composant correspond étroitement au nombre d’objets blob traités par chaque composant. Cette comparaison indique qu’aucun objet blob n’a été ignoré lors de l’ingestion.
Objets blob supprimés
Pour déterminer si des objets blob ont été ignorés lors de l’ingestion, vous devez analyser la métrique Objets blob ignorés. Cette métrique indique le nombre d’objets blob qui ont été ignorés lors de l’ingestion, et vous aide à détecter s’il y a un problème de traitement au niveau d’un composant d’ingestion spécifique. Pour chaque objet blob ignoré, vous obtiendrez également une métrique Résultat de l’ingestion contenant plus d’informations sur la raison de l’échec.
Afficher la latence d’ingestion
Les métriques Latence de phase et Latence de détection supervisent la latence dans le processus d’ingestion, et vous indiquent l’éventuelle présence de latences longues dans Azure Data Explorer ou avant l’arrivée des données dans Azure Data Explorer pour l’ingestion.
- Latence de phase indique la durée écoulée entre le moment où un message est détecté par Azure Data Explorer et celui où son contenu est reçu par un composant d’ingestion pour traitement.
- La latence de découverte est utilisée pour les pipelines d’ingestion avec des connexions de données (par exemple, Event Hub, IoT Hub et Event Grid). Cette métrique fournit des informations sur la durée écoulée entre la mise en file d’attente des données et la détection par les connexions de données Azure Data Explorer. Ce laps de temps étant en amont d’Azure Data Explorer, il n’est pas inclus dans la métrique Latence de phase, qui mesure uniquement la latence dans Azure Data Explorer.
Remarque
D’après la stratégie de traitement par lot par défaut, la durée de traitement par lot par défaut est de cinq minutes. Par conséquent, si le lot n’est pas scellé par d’autres déclencheurs, il est scellé au bout de cinq minutes.
Lorsque vous constatez que la latence est élevée avant que les données soient prêtes pour la requête, l’analyse de la Latence de phase et de la Latence de détection peut vous aider à comprendre si cette latence est due à une latence élevée dans Azure Data Explorer, ou est en amont d’Azure Data Explorer. Lorsque la latence est au-niveau d’Azure Data Explorer lui-même, vous pouvez également détecter le composant spécifique responsable de la latence élevée.
Latence de phase (préversion)
Examinons d’abord la latence intermédiaire de notre ingestion mise en file d’attente. Pour obtenir une explication de chaque phase, consultez Phases de traitement par lot.
- Dans le volet Métriques d’Azure Monitor, sélectionnez Ajouter une métrique.
- Sélectionnez Latence de phase comme valeur de Métrique et Moy comme valeur d’Agrégation.
- Sélectionnez le bouton Appliquer la division et choisissez Type de composant pour segmenter le graphique d’après les différents composants d’ingestion.
- Sélectionnez le bouton Ajouter un filtre et filtrez sur les données envoyées à la base de données GitHub. Après avoir sélectionné les valeurs de filtre, cliquez en dehors du sélecteur de filtre pour le fermer. À présent, le graphique affiche la latence des opérations d’ingestion envoyées à la base de données GitHub au niveau de chacun des composants par le biais de l’ingestion dans le temps :

Nous pouvons déduire ce qui suit de ce graphique :
- La latence au niveau du composant Connexion de données Event Hubs est d’environ 0 secondes. Ceci est logique, car la Latence de phase mesure uniquement la latence à partir du moment où un message est détecté par Azure Data Explorer.
- La durée la plus longue durant le processus d’ingestion (environ cinq minutes) est celle entre le moment où le composant Gestionnaire de traitement par lot a reçu des données et celui où le composant Gestionnaire d’ingestion a reçu des données. Dans cet exemple, nous utilisons la stratégie de traitement par lot par défaut pour la base de données GitHub. Comme indiqué, la limite de temps de latence pour la stratégie de traitement par lots par défaut est de 5 minutes. Par conséquent, cela indique probablement que presque toutes les données ont été traitées par lot par temps, et la plupart du temps de latence pour l’ingestion mise en file d’attente était due au traitement par lot lui-même.
- La latence du moteur de stockage dans le graphique représente la latence jusqu’à ce que les données soient stockées dans le Moteur de stockage Azure Data Explorer et soient prêtes à être interrogées. Vous pouvez observer que la latence totale moyenne entre le moment où les données sont détectées par Azure Data Explorer et celui où elles sont prêtes à être interrogées est de 5,2 minutes.
Latence de découverte
Si vous utilisez l’ingestion avec des connexions de données, vous souhaiterez peut-être estimer la latence en amont d’Azure Data Explorer au fil du temps, car une latence élevée peut également se produire avant qu’Azure Data Explorer récupère les données pour l’ingestion. À cet effet, vous pouvez utiliser la métrique Latence de détection.
- Sélectionnez + Nouveau graphique.
- Sélectionnez Latence de détection comme valeur de Métrique et Moy comme valeur d’Agrégation.
- Sélectionnez le bouton Appliquer la division et choisissez Type de composant pour segmenter le graphique d’après les différents types de composants de connexion de données. Après avoir sélectionné les valeurs de division, cliquez en dehors du sélecteur de division pour le fermer.

- Vous pouvez observer que, la plupart du temps, la latence de détection est proche de zéro seconde, ce qui indique qu’Azure Data Explorer a obtenu les données juste après leur mise en file d’attente. Le pic le plus élevé d’environ 300 millisecondes est aux alentours du 13 février à 14:00, ce qui indique que, à ce moment, le cluster Azure Data Explorer a reçu les données environ 300 millisecondes après leur mise en file d’attente.
Comprendre le processus de traitement par lot
Dans la deuxième étape du flux d’ingestion mis en file d’attente, le composant Batching Manager optimise le débit d’ingestion en lotant les données qu’il reçoit en fonction de la stratégie de traitement par lots d’ingestion.
L’ensemble de métriques suivant vous aide à comprendre comment vos données sont traitées par lot lors de l’ingestion :
- Lots traités : nombre de lots traités en vue de l’ingestion.
- Taille du lot : estimation de la taille des données non compressées dans un lot agrégé pour l’ingestion.
- Durée du lot : durée de chaque lot, du moment où il est ouvert jusqu’au moment où il est scellé.
- Nombre d’objets blob de lot : nombre d’objets blob dans un lot traité en vue de l’ingestion.
Lots traités
Commençons par une vue d’ensemble du processus de traitement par lot et examinons la métrique Lots traités.
- Dans le volet Métriques d’Azure Monitor, sélectionnez Ajouter une métrique.
- Sélectionnez Lots traités comme valeur de Métrique et Somme comme valeur d’Agrégation.
- Sélectionnez le bouton Appliquer la division et choisissez Type de traitement par lot pour segmenter le graphique en fonction de la raison pour laquelle le lot a été scellé. Pour obtenir la liste complète des types de traitement par lot, consultez Types de traitement par lot.
- Sélectionnez le bouton Ajouter un filtre et filtrez sur les lots envoyés à la base de données GitHub. Après avoir sélectionné les valeurs de filtre, cliquez en dehors du sélecteur de filtre pour le fermer.
Le graphique montre le nombre de lots scellés avec des données qui ont été envoyés à la base de données GitHub au fil du temps, divisés par Type de traitement par lot.

- Observez qu’il y a entre deux et quatre lots par unité de temps au fil du temps, et que tous les lots sont scellés à temps comme estimé dans la section Latence de phase, où vous pouvez constater qu’il faut environ cinq minutes pour traiter les données par lot conformément à la stratégie de traitement par lot par défaut.
Durée, taille et nombre d’objets blob de lot
Maintenant, caractérisons encore davantage les lots traités.
- Sélectionnez le bouton + Ajouter un graphique pour chaque graphique afin de créer d’autres graphiques pour les valeurs de MétriqueDurée du lot, Taille du lot et Nombre d’objets blob de lot.
- Utilisez Moy comme valeur d’Agrégation.
- Comme dans l’exemple précédent, sélectionnez le bouton Ajouter un filtre et filtrez sur les données envoyées à la base de données GitHub.

D’après les graphiques Durée du lot, Taille du lot et Nombre d’objets blob de lot, nous pouvons déduire ce qui suit :
La durée moyenne des lots est de cinq minutes (conformément à la stratégie de traitement par lot par défaut). Vous devez prendre cela en compte lorsque vous examinez la latence d’ingestion totale.
Dans le graphique Taille du lot, vous pouvez constater que la taille moyenne des lots est d’environ 200-500 Mo au fil du temps. La taille optimale des données à ingérer est de 1 Go de données non compressées, et cette taille est également définie en tant que condition de scellement par la stratégie de traitement par lot par défaut. Comme il n’y a pas 1 Go de données à traiter dans le temps, nous ne voyons aucun lot scellé par taille.
Le nombre moyen d’objets blob dans les lots dans le temps est d’environ 160, qui diminue ensuite à 60-120 objets blob. Conformément à la stratégie de traitement par lot par défaut, un lot peut être scellé quand le nombre d’objets blob est égal à 1000. Comme nous n’arrivons pas à ce nombre, nous ne voyons pas de lots scellés par nombre.
Comparer les événements reçus aux événements envoyés pour l’ingestion
Lors de l’application d’event hub, d’IoT Hub ou d’ingestion Event Grid, il peut être utile de comparer le nombre d’événements reçus par Azure Data Explorer au nombre d’événements envoyés de la source d’événements à Azure Data Explorer. Les métriques Événements reçus, Événements traités et Événements ignorés vous permettent d’effectuer cette comparaison.
Événements reçus
- Dans le volet Métriques d’Azure Monitor, sélectionnez Ajouter une métrique.
- Sélectionnez Événements reçus comme valeur de Métrique et Somme comme valeur d’Agrégation.
- Sélectionnez le bouton Ajouter un filtre au-dessus du graphique, puis choisissez la valeur de PropriétéNom du composant pour filtrer les événements reçus d’après une connexion de données spécifique définie sur votre cluster. Dans cet exemple, nous filtrons sur la connexion de données GitHubStreamingEvents. Après avoir sélectionné les valeurs de filtre, cliquez en dehors du sélecteur de filtre pour le fermer.
À présent, le graphique montre le nombre d’événements reçus par la connexion de données sélectionnée au fil du temps :

- Dans ce graphique, la connexion de données GitHubStreamingEvents reçoit environ 200-500 événements par unité de temps.
Événements traités et événements ignorés
Pour voir si des événements ont été ignorés par Azure Data Explorer, utilisez les métriques Événements traités et Événements ignorés.
- Sur le graphique que vous avez déjà créé, sélectionnez Ajouter une métrique.
- Sélectionnez Événements traités comme valeur de Métrique et Somme comme valeur d’Agrégation.
- Sélectionnez à nouveau Ajouter une métrique et sélectionnez Événements ignorés comme valeur de Métrique et Somme comme valeur d’Agrégation.
Le graphique affiche maintenant le nombre d’événements reçus, traités et ignorés par la connexion de données GitHubStreamingEvents dans le temps.

- Presque tous les événements reçus ont été traités avec succès par la connexion de données. Il y a un événement ignoré, ce qui est compatible avec le résultat d’échec d’ingestion dû à une demande incorrecte que nous avons constaté lors de l’affichage de la métrique de résultat d’ingestion.
Comparer les événements reçus dans Azure Data Explorer aux messages sortants provenant du hub d’événements
Vous pouvez également comparer le nombre d’événements reçus au nombre d’événements qui ont été envoyés depuis le hub d’événements à Azure Data Explorer, en comparant les métriques Événements reçus et Messages sortants.
Sur le graphique que vous avez déjà créé pour Événements reçus, sélectionnez Ajouter une métrique.
Sélectionnez Étendue puis, dans la boîte de dialogue Sélectionner une étendue, recherchez et sélectionnez l’espace de noms du hub d’événements qui envoie des données à votre connexion de données.
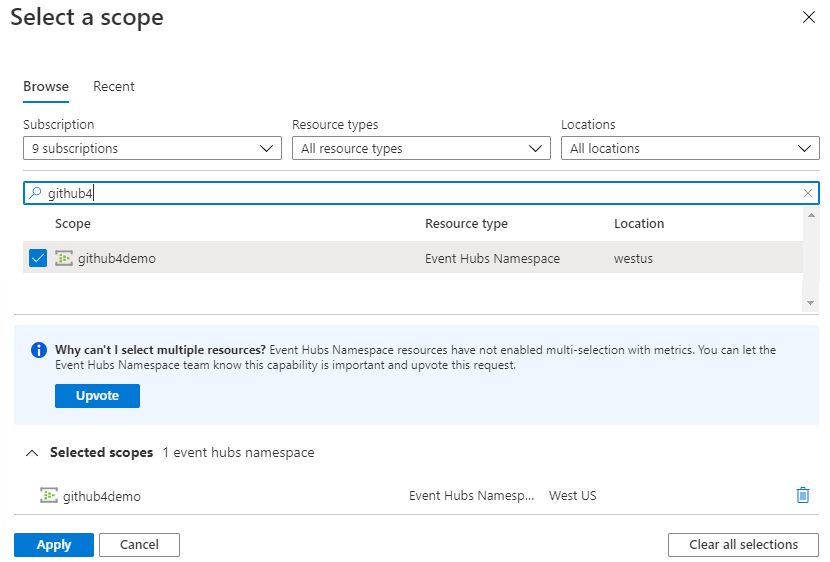
Sélectionnez Appliquer
Sélectionnez Messages sortants comme valeur de Métrique et Somme comme valeur d’Agrégation.

Cliquez en dehors des paramètres pour afficher le graphique complet qui compare le nombre d’événements traités par la connexion de données Azure Data Explorer au nombre d’événements envoyés depuis le hub d’événements.

- Notez que tous les événements envoyés depuis le hub d’événements ont été traités avec succès par la connexion de données Azure Data Explorer.
- Si vous avez plusieurs hubs d’événements dans l’espace de noms Event Hubs, vous devez filtrer la métrique Messages sortants par la dimension Nom de l’entité afin d’obtenir seulement les données du hub d’événements souhaité de votre espace de noms Event Hubs.
Remarque
Il n’est pas possible de superviser les messages sortants par groupe de consommateurs. La métrique Messages sortants compte le nombre total de messages consommés par tous les groupes de consommateurs. Par conséquent, si vous avez quelques groupes de consommateurs dans votre hub d’événements, vous êtes susceptible d’obtenir un plus grand nombre de Messages sortants que d’Événements reçus.