Ingérer des données de Splunk vers Azure Data Explorer
Important
Ce connecteur peut être utilisé dans Real-Time Intelligence dans Microsoft Fabric. Utilisez les instructions contenues dans cet article, à l’exception des points suivants :
- Si nécessaire, créez des bases de données en suivant les instructions fournies dans Créer une base de données KQL.
- Si nécessaire, créez des tables en suivant les instructions fournies dans Créer une table vide.
- Obtenez les URI de requête ou d’ingestion en suivant les instructions fournies dans Copier l’URI.
- Exécutez des requêtes dans un ensemble de requêtes KQL.
Splunk Enterprise est une plateforme logicielle qui vous permet d’ingérer des données de nombreuses sources simultanément. L’indexeur Splunk traite les données et les stocke par défaut dans l’index principal ou dans un index personnalisé spécifié. La recherche dans Splunk utilise les données indexées pour créer des métriques, des tableaux de bord et des alertes. L’Explorateur de données Azure est un service d’exploration de données rapide et hautement évolutive pour les données des journaux et les données de télémétrie.
Dans cet article, vous allez apprendre à utiliser le module complémentaire Splunk Azure Data Explorer pour envoyer des données de Splunk vers une table dans votre cluster. Vous créez initialement une table et un mappage de données, vous demandez à Splunk d’envoyer des données dans la table, puis vous validez les résultats.
Les scénarios suivants conviennent le mieux à l’ingestion de données dans Azure Data Explorer :
- Données volumineuses : Azure Data Explorer est conçu pour gérer efficacement de grandes quantités de données. Si votre organisation génère un volume important de données nécessitant une analyse en temps réel, Azure Data Explorer est un choix approprié.
- Données de série chronologique : Azure Data Explorer excelle lors de la gestion des données de série chronologique, telles que les journaux, les données de télémétrie et les lectures de capteur. Il organise les données dans des partitions temporelles, ce qui facilite l’exécution d’analyses et d’agrégations basées sur le temps.
- Analytique en temps réel : si votre organisation a besoin d’insights en temps réel à partir des données entrantes, les fonctionnalités en quasi-temps réel d’Azure Data Explorer peuvent être utiles.
Prérequis
- Un compte Microsoft ou une identité utilisateur Microsoft Entra. Un abonnement Azure n’est pas requis.
- Un cluster et une base de données Azure Data Explorer. Créez un cluster et une base de données.
- Splunk Enterprise 9 ou version ultérieure.
- Un principal de service Microsoft Entra. Créer un principal de service Microsoft Entra.
Créer une table et un objet de mappage
Une fois que vous avez un cluster et une base de données, créez une table avec un schéma qui correspond à vos données Splunk. Vous créez également un objet de mappage utilisé pour transformer les données entrantes en schéma de table cible.
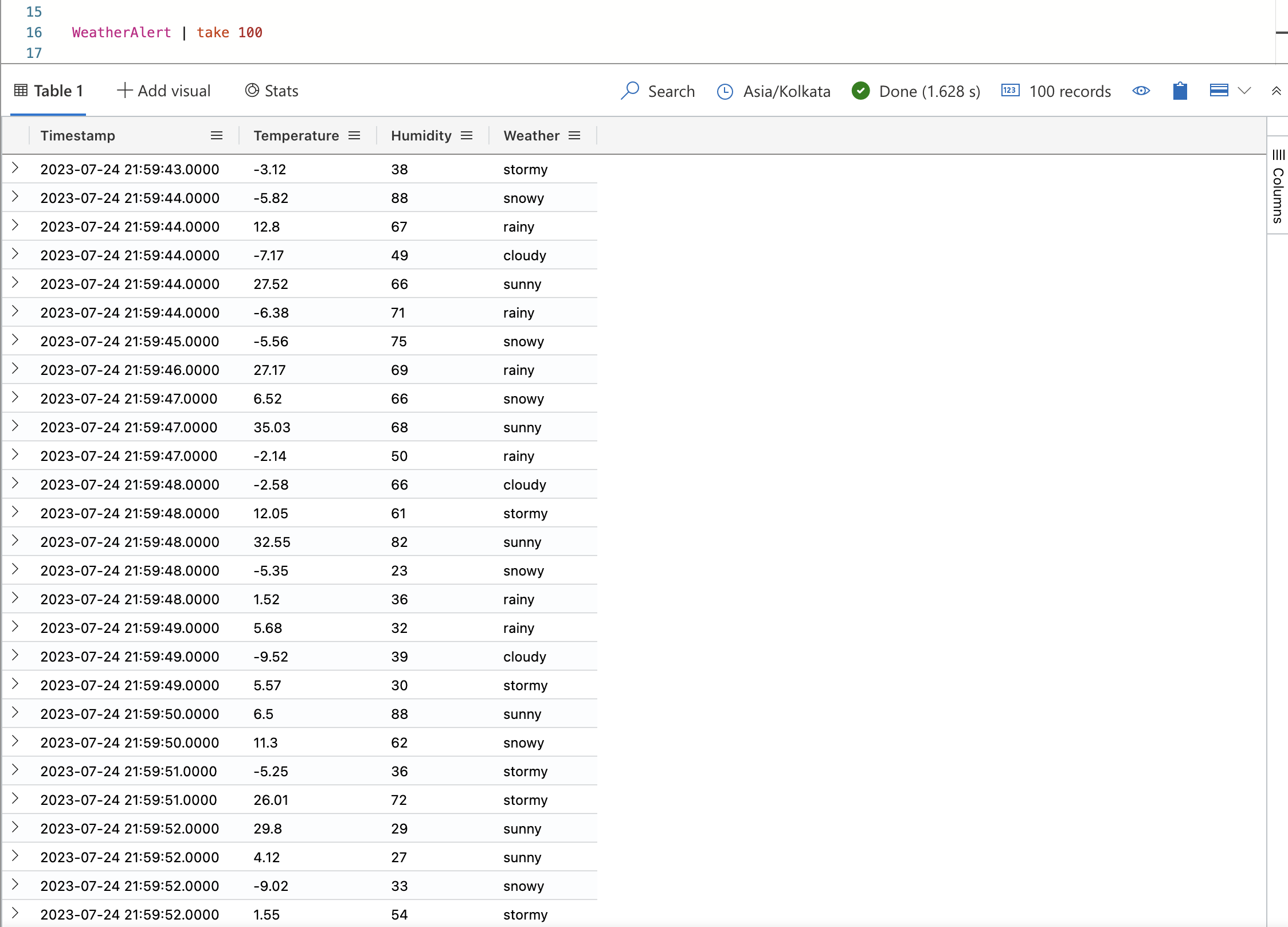
Dans l’exemple suivant, vous créez une table nommée WeatherAlert avec quatre colonnes : Timestamp, Temperature, Humidity et Weather. Vous créez également un mappage nommé WeatherAlert_Json_Mapping qui extrait les propriétés du json entrant comme indiqué par path et les génère dans le column spécifié.
Dans l’éditeur de requête de l’interface utilisateur web, exécutez les commandes suivantes pour créer la table et le mappage :
Créer une table :
.create table WeatherAlert (Timestamp: datetime, Temperature: string, Humidity: string, Weather: string)Vérifiez que la table
WeatherAlerta été créée, et qu’elle est vide :WeatherAlert | countCréez un objet de mappage :
.create table WeatherAlert ingestion json mapping "WeatherAlert_Json_Mapping" ```[{ "column" : "Timestamp", "datatype" : "datetime", "Properties":{"Path":"$.timestamp"}}, { "column" : "Temperature", "datatype" : "string", "Properties":{"Path":"$.temperature"}}, { "column" : "Humidity", "datatype" : "string", "Properties":{"Path":"$.humidity"}}, { "column" : "Weather", "datatype" : "string", "Properties":{"Path":"$.weather_condition"}} ]```Utilisez le principal de service des Prérequis pour accorder l’autorisation d’utiliser la base de données.
.add database YOUR_DATABASE_NAME admins ('aadapp=YOUR_APP_ID;YOUR_TENANT_ID') 'Entra App'
Installer le module complémentaire Splunk Azure Data Explorer
Le module complémentaire Splunk communique avec Azure Data Explorer et envoie les données à la table spécifiée.
Téléchargez le module complémentaire Azure Data Explorer.
Connectez-vous à votre instance Splunk en tant qu’administrateur.
Accédez à Applications>Gérer les applications.
Sélectionnez Installer l’application à partir d’un fichier, puis sélectionnez le fichier de module complémentaire Azure Data Explorer que vous avez téléchargé.
Suivez les instructions pour terminer l'installation.
Sélectionnez Redémarrer maintenant.
Vérifiez que le module complémentaire est installé en accédant à Tableau de bord>Actions d’alerte et en recherchant le module complémentaire Azure Data Explorer.

Créer un index dans Splunk
Créez un index dans Splunk en spécifiant les critères des données que vous souhaitez envoyer à Azure Data Explorer.
- Connectez-vous à votre instance Splunk en tant qu’administrateur.
- Accédez à Paramètres>Index.
- Spécifiez un nom pour l’index et configurez les critères des données que vous souhaitez envoyer à Azure Data Explorer.
- Configurez les propriétés restantes en fonction des besoins, puis enregistrez l’index.
Configurer le module complémentaire Splunk pour envoyer des données à Azure Data Explorer
Connectez-vous à votre instance Splunk en tant qu’administrateur.
Accédez au tableau de bord et recherchez à l’aide de l’index que vous avez créé précédemment. Par exemple, si vous avez créé un index nommé
WeatherAlerts, recherchezindex="WeatherAlerts".Sélectionnez Enregistrer sous>Alerte.
Spécifiez le nom, l’intervalle et les conditions requises pour l’alerte.
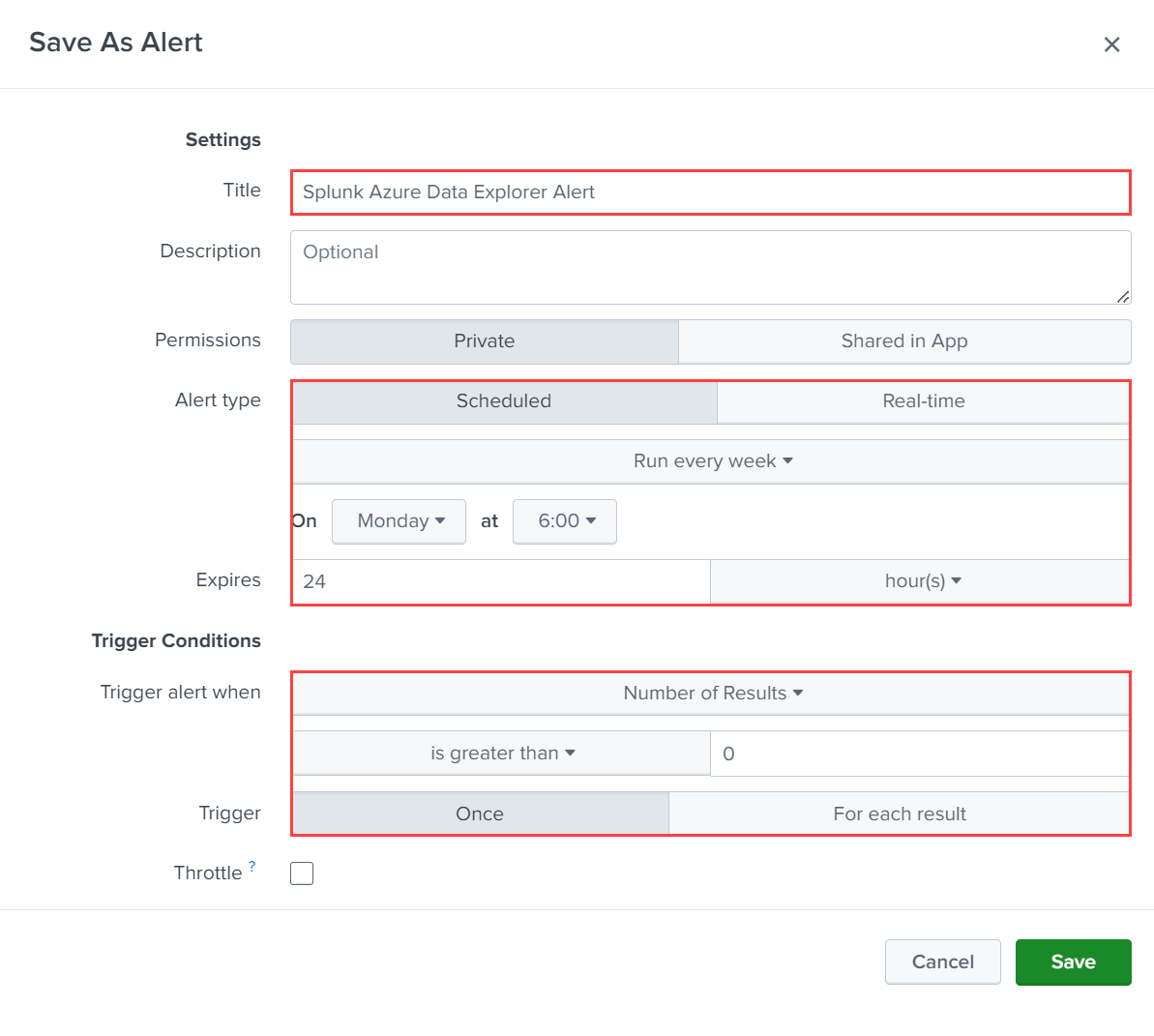
Sous Actions de déclencheur, sélectionnez Ajouter des actions>Envoyer à Microsoft Azure Data Explorer.
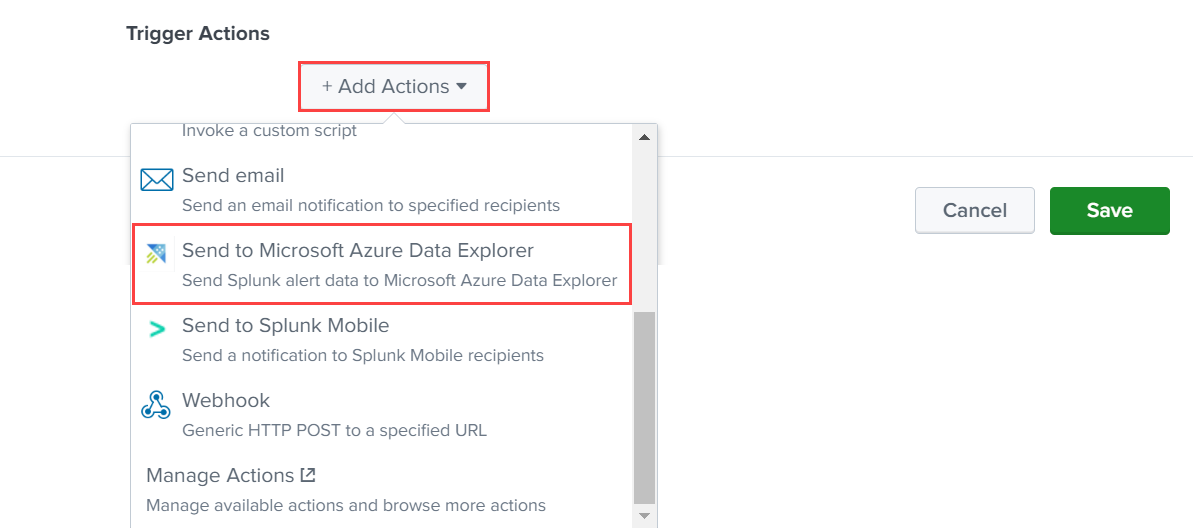
Configurez les détails des connexions comme suit :
Setting Description URL d’ingestion de cluster Spécifiez l’URL d’ingestion de votre cluster Azure Data Explorer. Par exemple : https://ingest-<mycluster>.<myregion>.kusto.windows.net.ID client Spécifiez l’ID client de l’application Microsoft Entra que vous avez créée précédemment. Clé secrète client Spécifiez la clé secrète client de l’application Microsoft Entra que vous avez créée précédemment. Tenant ID Spécifiez l’ID de locataire de l’application Microsoft Entra que vous avez créée précédemment. Sauvegarde de la base de données Spécifiez le nom de la base de données vers laquelle vous souhaitez envoyer les données. Enregistrement Spécifiez le nom de la table vers laquelle vous souhaitez envoyer les données. Mappage Spécifiez le nom de l’objet de mappage que vous avez créé précédemment. Supprimer les champs supplémentaires Sélectionnez cette option pour supprimer les champs vides des données envoyées à votre cluster. Mode durable Sélectionnez cette option pour activer le mode de durabilité pendant l’ingestion. Lorsque cette option a la valeur true, le débit d’ingestion est affecté. 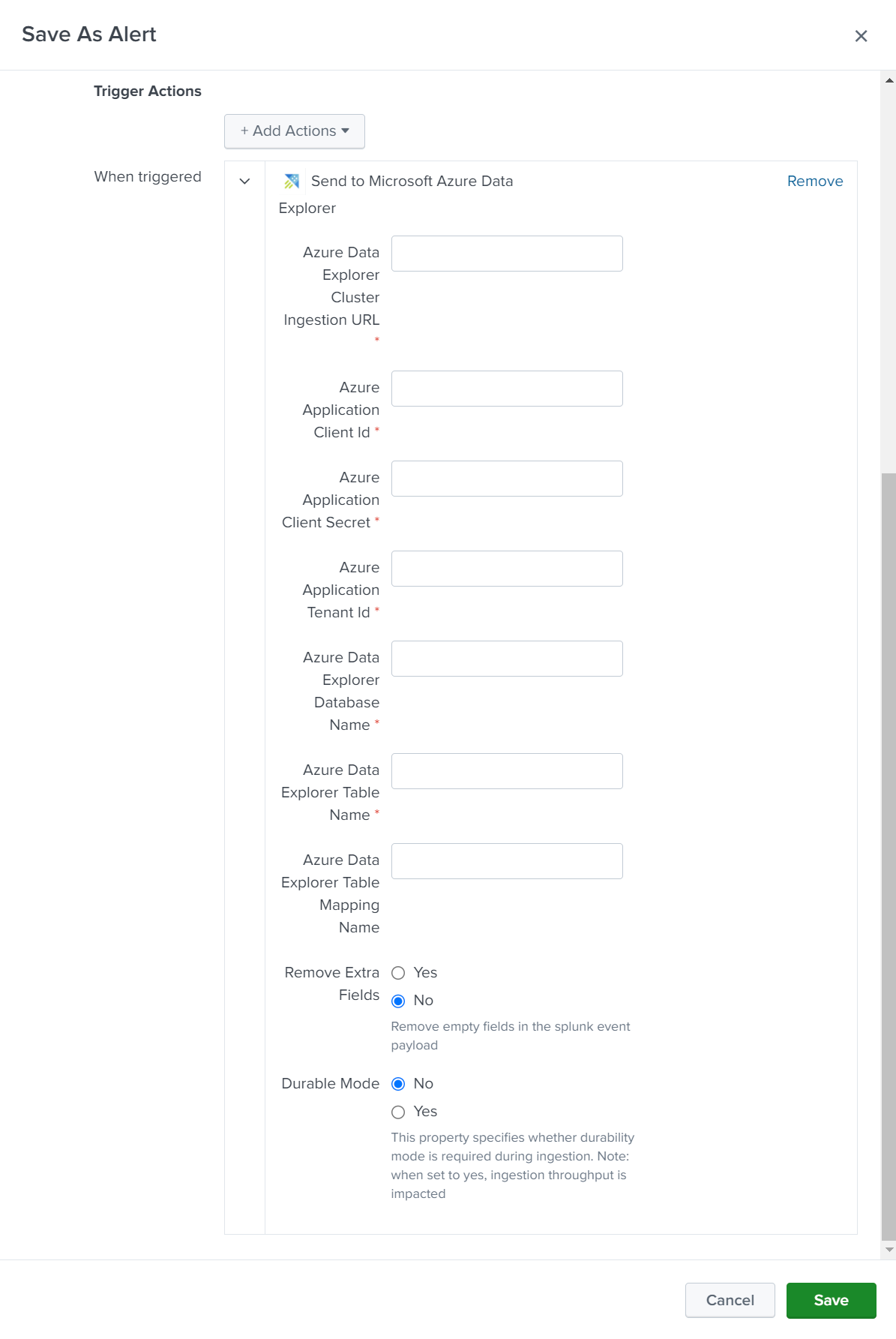
Sélectionnez Enregistrer pour enregistrer l’alerte.
Accédez à la page Alertes et vérifiez que votre alerte apparaît dans la liste des alertes.
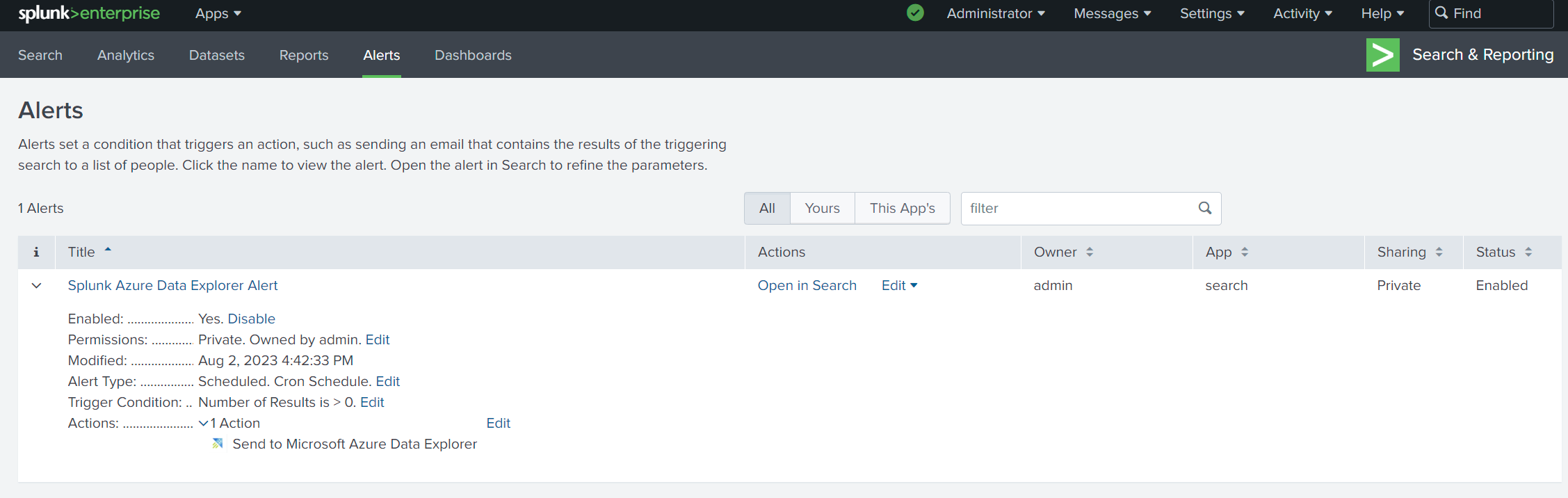




Vérifier que les données sont ingérées dans Azure Data Explorer
Une fois l’alerte déclenchée, les données sont envoyées vers votre table Azure Data Explorer. Vous pouvez vérifier que les données sont ingérées en exécutant une requête dans l’éditeur de requête de l’interface utilisateur web.
Exécutez la requête suivante pour vérifier que les données sont ingérées dans la table :
WeatherAlert | countExécutez la requête suivante pour afficher les données :
WeatherAlert | take 100