Meilleures pratiques pour la mise à l’échelle du débit approvisionné (unités de requête par seconde)
S’APPLIQUE À : ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
Cet article décrit les meilleures pratiques et les stratégies pour la mise à l’échelle du débit, exprimé en unités de requête par seconde (RU/s), de votre base de données ou conteneur (collection, table ou graphique). Les concepts s’appliquent lorsque vous augmentez le nombre de RU/s manuelles approvisionnées ou le nombre maximal de RU/s de mise à l’échelle automatique d’une ressource pour l’une des API Azure Cosmos DB.
Configuration requise
- Si vous êtes novice en matière de partitionnement et de mise à l’échelle dans Azure Cosmos DB, nous vous recommandons de commencer par lire l’article Partitionnement et mise à l’échelle horizontale dans Azure Cosmos DB.
- Si vous envisagez de mettre à l’échelle vos RU/s en raison d’exceptions 429, consultez Diagnostiquer et résoudre des problèmes liés aux exceptions Taux de requêtes Azure Cosmos DB trop élevé (429). Avant d’incrémenter le taux de RU/s, identifiez la cause racine du problème afin de déterminer si l’extension de RU/s est la bonne solution.
Contexte de la mise à l’échelle des RU/s
Lorsque vous envoyez une demande d’augmentation des RU/s de votre base de données ou conteneur, selon les RU/s demandées et la disposition de votre partition physique actuelle, l’augmentation de l’échelle (montée en puissance) est accomplie instantanément ou de manière asynchrone (généralement après 4 à 6 heures).
- Augmentation d’échelle (montée en puissance) instantanée
- Lorsque votre demande de RU/s peut être prise en charge par la disposition de partition physique actuelle, Azure Cosmos DB n’a pas besoin d’opérer un fractionnement ou d’ajouter des partitions.
- Par conséquent, l’opération est accomplie et les RU/s sont disponibles pour utilisation immédiatement.
- Augmentation d’échelle (montée en puissance) asynchrone
- Lorsque la demande de RU/s est supérieure à ce que la disposition de partition physique peut prendre en charge, Azure Cosmos DB fractionne les partitions physiques existantes. Cela se produit jusqu’à ce que la ressource ait le nombre minimal de partitions requis pour prendre en charge les RU/s demandées.
- Par conséquent, l’opération peut prendre un certain temps, généralement de 4 à 6 heures. Chaque partition physique peut prendre en charge un maximum de 10 000 RU/s (s’applique à toutes les API) de débit et de 50 Go de stockage (s’applique à toutes les API, à l’exception de Cassandra qui dispose de 30 Go de stockage).
Notes
Si vous effectuez une opération manuelle de basculement de région ou si vous ajoutez/supprimez une région alors qu’une opération de montée en puissance (scale-up) asynchrone est en cours, celle-ci est suspendue. Elle reprend automatiquement une fois l’opération de basculement ou d’ajout/de suppression de région terminée.
- Scale-down instantané
- Pour les opérations de scale-down, Azure Cosmos DB n’a pas besoin de fractionner des partitions ni d’en ajouter de nouvelles.
- Par conséquent, l’opération se termine immédiatement et les RU/s sont immédiatement disponibles pour utilisation.
- Le principal résultat de cette opération est que les unités de requête par partition physique sont réduites.
Comment augmenter l’échelle des RU/s sans modifier la disposition de partition
Étape 1 : déterminer le nombre actuel de partitions physiques.
Accédez à Insights>Débit>Consommation normalisée de RU (%) par PartitionKeyRangeID. Comptez le nombre de PartitionKeyRangeIds.
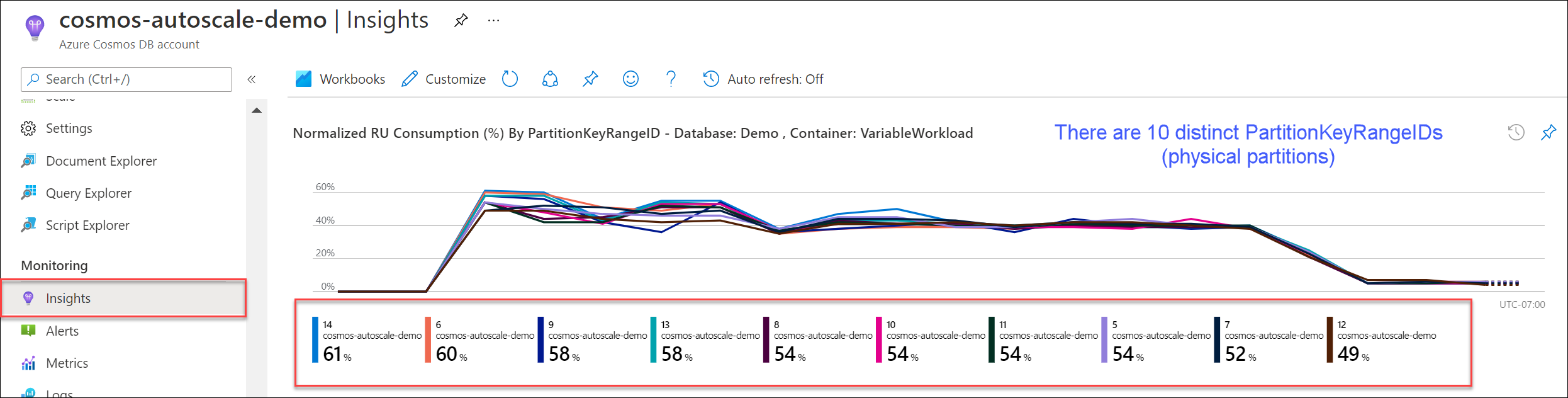
Notes
Le graphique affiche uniquement un maximum de 50 PartitionKeyRangeIds. Si votre ressource en compte plus de 50, vous pouvez utiliser l’API REST Azure Cosmos DB pour compter le nombre total de partitions.
Chaque PartitionKeyRangeId correspond à une partition physique et est assigné pour contenir des données pour une plage de valeurs de hachage possibles.
Azure Cosmos DB distribue vos données sur des partitions logiques et physiques en fonction de votre clé de partition pour permettre une mise à l’échelle horizontale. À mesure que des données sont écrites, Azure Cosmos DB utilise le hachage de la valeur de clé de partition pour déterminer la partition logique et physique sur laquelle les données résident.
Étape 2 : calculer le débit maximal par défaut
Le débit de RU/s maximal que la mise à l’échelle peut atteindre sans déclencher de fractionnement des partitions par Azure Cosmos DB est égal à Current number of physical partitions * 10,000 RU/s. Vous pouvez obtenir cette valeur auprès du fournisseur de ressources Azure Cosmos DB. Effectuez une requête GET sur vos objets de paramètre de débit de base de données ou de conteneur et récupérez la propriété instantMaximumThroughput. Cette valeur est également disponible dans la page Échelle et paramètres de votre base de données ou conteneur dans le portail.
Exemple
Supposons que nous avons un conteneur avec cinq partitions physiques et 30 000 RU/s de débit approvisionné manuellement. Nous pouvons augmenter le nombre de RU/s à 5 * 10 000 RU/s = 50 000 RU/s instantanément. De même, si nous avions un conteneur avec une mise à l’échelle automatique maximale de 30 000 RU/s (échelles de 3 000 à 30 000 RU/s), nous pourrions porter le nombre maximal de RU/s à 50 000 RU/s (échelles de 5 000 à 50 000 RU/s).
Conseil
Si vous augmentez l’échelle des RU/s en réponse à des exceptions Taux de requêtes trop élevé (429), nous vous recommandons de commencer par augmenter les RU/s au nombre de RU/s le plus élevé pris en charge par la disposition de votre partition physique actuelle et d’évaluer si le nouveau nombre de RU/s est suffisant avant d’augmenter davantage.
Comment garantir une distribution uniforme des données lors d’une mise à l’échelle asynchrone
Arrière-plan
Lorsque vous augmentez le nombre de RU/s au-delà du nombre actuel de partitions physiques * 10 000 RU/s, Azure Cosmos DB fractionne les partitions existantes jusqu’à ce que le nouveau nombre de partitions soit égal à ROUNDUP(requested RU/s / 10,000 RU/s). Au cours d’un fractionnement, les partitions parents sont fractionnées en deux partitions enfants.
Par exemple, supposons que nous avons un conteneur avec trois partitions physiques et 30 000 RU/s de débit approvisionné manuellement. Si nous augmentons le débit à 45 000 RU/s, Azure Cosmos DB fractionne deux des partitions physiques existantes pour obtenir un total de ROUNDUP(45,000 RU/s / 10,000 RU/s) = 5 partitions physiques.
Notes
Les applications peuvent toujours ingérer ou interroger des données au cours d’une division. Les kits de développement logiciel (SDK) et le service clients Azure Cosmos DB gérant automatiquement ce scénario et veillant à ce que les demandes soient acheminées vers la partition physique appropriée, aucune action supplémentaire de l’utilisateur n’est requise.
Si vous disposez d’une charge de travail distribuée de manière très uniforme en ce qui concerne le volume de stockage et de demandes (résultant généralement d’un partitionnement par champs de cardinalité élevée tels que /id), il est recommandé, lors de l’augmentation d’échelle, de définir le nombre de RU/s de manière à ce que toutes les partitions soient fractionnées uniformément.
Pour illustrer cela, prenons l’exemple d’un conteneur avec 2 partitions physiques, 20 000 RU/s et 80 Go de données.
En choisissant une clé de partition appropriée avec une cardinalité élevée, les données sont distribuées de manière uniforme dans les deux partitions physiques. Chaque partition physique est assignée à environ 50 % de l’espace de clés qui est défini comme la plage totale des valeurs de hachage possibles.
En outre, Azure Cosmos DB distribue les RU/s uniformément entre toutes les partitions physiques. Par conséquent, chaque partition physique a 10 000 RU/s et 50 % (40 Go) du volume total des données. Le diagramme suivant montre notre état actuel.

Supposons maintenant que nous voulons augmenter le nombre de RU/s de 20 000 à 30 000.
Si nous portions simplement le nombre de RU/s à 30 000, une seule des partitions serait fractionnée. Après le fractionnement, nous obtiendrions :
- une partition contenant 50 % des données (la partition non fractionnée) ;
- deux partitions contenant chacune 25 % des données (partitions enfants résultants du fractionnement de la partition parent).
Étant donné qu’Azure Cosmos DB distribue les RU/s uniformément entre toutes les partitions physiques, chaque partition physique obtiendrait toujours 10 000 RU/s. Toutefois, nous aurions une asymétrie dans la distribution du stockage et des demandes.
Le diagramme suivant montre que les partitions 3 et 4 (partitions enfants de la partition 2) disposent chacune de 10 000 RU/s pour servir les demandes d’un volume de données de 20 Go, tandis que la partition 1 dispose de 10 000 RU/s pour servir les demandes du double de ce volume de données (40 Go).

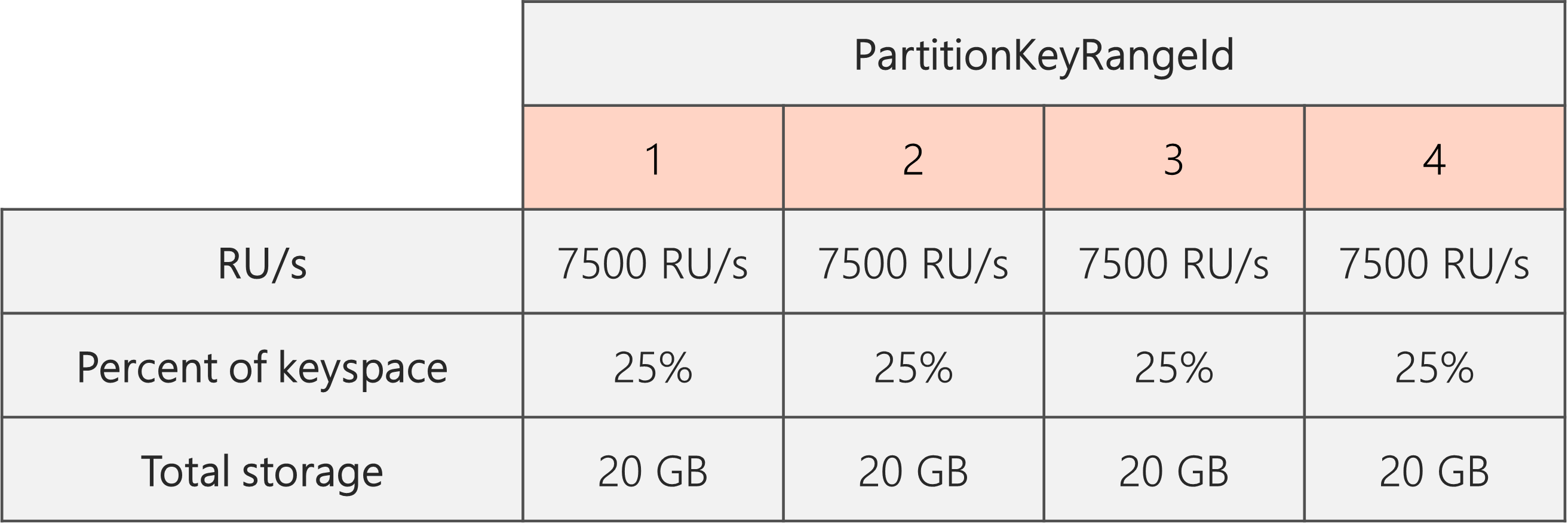
Pour maintenir une distribution de stockage uniforme, nous pouvons commencer par augmenter l’échelle de nos RU/s de façon à ce que chaque partition soit fractionnée. Ensuite, nous pouvons réduire le nombre de RU/s afin d’obtenir l’état souhaité.
Par conséquent, si nous commençons avec deux partitions physiques, pour garantir l’uniformité des partitions après fractionnement, nous devons définir les RU/s de façon à obtenir quatre partitions physiques. Pour ce faire, nous allons commencer par définir le nombre de RU/s comme égal à 4 * 10 000 RU/s par partition = 40 000 RU/s. Ensuite, une fois le fractionnement effectué, nous pouvons réduire le nombre de RU/s à 30 000.
Le diagramme suivant montre ainsi que chaque partition physique obtient 30 000 RU/s/4 = 7 500 RU/s pour servir les demandes d’un volume de données de 20 Go. Globalement, nous maintenons une distribution uniforme du stockage et des demandes sur les partitions.
Formule générale
Étape 1 : augmenter le nombre de RU/s pour garantir un fractionnement uniforme des partitions
En général, si vous disposez d’un nombre initial de partitions physiques égal à P, et voulez définir un nombre souhaité de RU/s égal à S :
Augmentez le nombre de RU/s à : 10,000 * P * (2 ^ (ROUNDUP(LOG_2 (S/(10,000 * P)))). Cela donne le nombre de RU/s le plus proche de la valeur souhaitée, garantissant que toutes les partitions sont fractionnées uniformément.
Notes
Lorsque vous augmentez le nombre de RU/s d’une base de données ou d’un conteneur, cela peut avoir une incidence sur le nombre minimal de RU/s que vous pouvez atteindre dans le futur. En règle générale, le nombre minimal de RU/s est égal à MAX (400 RU/s, stockage actuel en Go * 1 RU/s, nombre de RU/s le plus élevé jamais approvisionné /100). Par exemple, si le nombre le plus élevé de RU/s que vous avez jamais mis à l’échelle est égal à 100 000, le nombre le plus bas de RU/s que vous pourrez définir à l’avenir sera de 1000 RU/s. Apprenez-en davantage sur le nombre minimal de RU/s.
Étape 2 : réduire le nombre de RU/s au nombre de RU/s souhaité
Par exemple, supposons que nous avons cinq partitions physiques, avec 50 000 RU/s, et que nous souhaitons augmenter l’échelle à 150 000 RU/s. Nous devons commencer par définir 10,000 * 5 * (2 ^ (ROUND(LOG_2(150,000/(10,000 * 5)))) = 200 000 RU/s, puis réduire le nombre de RU/s à 150 000.
Après avoir augmenté l’échelle à 200 000 RU/s, le nombre le plus bas de RU/s manuelles que nous pourrons définir à l’avenir sera de 2 000. Le nombre maximal de RU/s de mise à l’échelle automatique le plus bas que nous pouvons définir est de 20 000 (échelles de 2 000 à 20 000 RU/s). Notre nombre de RU/s cible étant de 150 000, nous ne sommes pas affectés par le nombre minimal de RU/s.
Comment optimiser le nombre de RU/s pour une ingestion de données volumineuse
Lorsque vous envisagez de migrer ou d’ingérer une grande quantité de données dans Azure Cosmos DB, nous vous recommandons de définir les RU/s du conteneur de façon à ce qu’Azure Cosmos DB pré-approvisionne les partitions physiques nécessaires pour stocker la quantité totale de données que vous envisagez d’ingérer initialement. Autrement, durant l’ingestion des données, il se peut qu’Azure Cosmos DB doive fractionner les partitions, ce qui aura pour effet d’allonger le temps nécessaire pour effectuer l’opération.
Nous pouvons tirer parti du fait que, lors de la création du conteneur, Azure Cosmos DB utilise la formule heuristique des RU/s de départ pour calculer le nombre de partitions physiques avec lesquelles commencer.
Étape 1 : réfléchir au choix de la clé de partition
Suivez les meilleures pratiques pour le choix d’une clé de partition appropriée pour vous assurer d’obtenir une distribution uniforme du volume de demandes et du stockage après la migration.
Étape 2 : calculer le nombre de partitions physiques dont vous avez besoin
Number of physical partitions = Total data size in GB / Target data per physical partition in GB
Chaque partition physique peut contenir au maximum 50 Go de stockage (30 Go pour l’API pour Cassandra). La valeur à choisir pour Target data per physical partition in GB dépend du degré de remplissage des partitions physiques que vous souhaitez et de la croissance du stockage que vous prévoyez après la migration.
Par exemple, si vous pensez que le stockage va continuer à croître, vous pouvez choisir de définir la valeur sur 30 Go. En supposant que vous avez choisi une clé de partition appropriée qui distribue le stockage uniformément, chaque partition sera remplie à environ 60 % (30 Go sur 50). À mesure que les données seront écrites, elles pourront être stockées sur l’ensemble existant de partitions physiques, sans que le service doive ajouter des partitions.
En revanche, si vous pensez que le stockage n’augmentera pas sensiblement après la migration, vous pouvez choisir de définir une valeur supérieure, par exemple, 45 Go. Chaque partition sera alors remplie à environ 90 % (45 Go sur 50). Cela aura pour effet de réduire le nombre de partitions physiques sur lesquelles vos données seront réparties, de sorte que chaque partition physique pourra accueillir une fraction plus importante du nombre total de RU/s approvisionnées.
Étape 3 : calculer le nombre de RU/s avec lesquelles commencer pour toutes les partitions
Starting RU/s for all partitions = Number of physical partitions * Initial throughput per physical partition.
Commençons par un exemple avec un nombre arbitraire de RU/s cibles par partition physique.
Initial throughput per physical partition= 10 000 RU/s par partition physique lors de l’utilisation de bases de données avec mise à l’échelle automatique ou débit partagéInitial throughput per physical partition= 6000 RU/s par partition physique lorsque vous utilisez un débit manuel
Exemple
Supposons que nous avons 1 To (1 000 Go) de données que nous envisageons d’ingérer et que nous voulons utiliser un débit manuel. Chaque partition physique dans Azure Cosmos DB a une capacité de 50 Go. Supposons que notre objectif est de remplir les partitions à 80 % (40 Go), en ménageant de la place pour une croissance future.
Cela signifie que, pour 1 To de données, nous aurons besoin de 1 000 Go/40 Go = 25 partitions physiques. Pour nous assurer d’obtenir 25 partitions physiques, si nous utilisons un débit manuel, nous commençons par approvisionner 25 * 6 000 RU/s = 150 000 RU/s. Ensuite, une fois le conteneur créé, pour accélérer l’ingestion, nous augmentons le nombre de RU/s à 250 000 avant le début de l’ingestion (augmentation effectuée instantanément parce que nous disposons déjà de 25 partitions physiques). Chaque partition peut ainsi obtenir le maximum de 10 000 RU/s.
Si nous utilisons une base de données avec mise à l’échelle automatique ou débit partagé, pour obtenir 25 partitions physiques, nous commençons par approvisionner 25 * 10 000 RU/s = 250 000 RU/s. Étant donné que nous sommes déjà au nombre le plus élevé de RU/s qui peuvent être prises en charge avec 25 partitions physiques, nous n’augmenterons pas le nombre de RU/s approvisionnées avant l’ingestion.
En théorie, avec 250 000 RU/s et 1 To de données, en supposant des documents de 1 Ko et 10 RU requises pour leur écriture, l’ingestion peut théoriquement prendre : 1 000 Go * (1 000 000 Ko/1 Go) * (1 document/1 Ko) * (10 RU/document) * (1 s/250 000 RU) * (1 heure/3 600 secondes) = 11,1 heures.
Ce calcul est une estimation basée sur l’hypothèse que le client effectuant l’ingestion peut saturer entièrement le débit et distribuer les écritures sur toutes les partitions physiques. En guise de meilleure pratique, nous vous recommandons d’opter pour une répartition « aléatoire » de vos données côté client. Cela garantit qu’à chaque seconde, le client écrit dans un grand nombre de partitions logiques (et donc physiques) distinctes.
Une fois la migration terminée, nous pouvons réduire le nombre de RU/s ou activer la mise à l’échelle automatique en fonction des besoins.
Étapes suivantes
- Surveiller la consommation normalisée de RU/s de votre base de données ou de votre conteneur.
- Diagnostiquer et résoudre des problèmes liés aux exceptions Taux de requêtes trop élevé (429).
- Activer la mise à l’échelle automatique sur une base de données ou un conteneur.