Performances et résolution des problèmes pour l’extraction de données SAP
Cet article fait partie de la série d’articles « Étendre et innover des données SAP : bonnes pratiques ».
- Identifier des sources de données SAP
- Choisir le meilleur connecteur SAP
- Performances et résolution des problèmes d’extraction de données SAP
- Sécurité d’intégration des données pour SAP sur Azure
- Architecture générique d’intégration des données SAP
Il existe de nombreuses façons de se connecter au système SAP pour l’intégration des données. Les sections suivantes décrivent des considérations et des recommandations générales et spécifiques au connecteur.
Performances
Il est important de configurer des paramètres optimaux pour la source et la cible afin d’obtenir les meilleures performances lors de l’extraction et du traitement des données.
Considérations d’ordre général
- Vérifiez que les paramètres SAP corrects sont définis pour un maximum de connexions simultanées.
- Envisagez d’utiliser le type de connexion SAP « Groupe » pour une meilleure distribution des performances et de la charge.
- Vérifiez que la machine virtuelle avec runtime d’intégration auto-hébergé (SHIR) est correctement dimensionnée avec une haute disponibilité.
- Quand vous travaillez avec de grands jeux de données, vérifiez si le connecteur que vous utilisez fournit une fonctionnalité de partitionnement. De nombreux connecteurs SAP prennent en charge des fonctionnalités de partitionnement et de parallélisation pour accélérer les chargements de données. Quand vous utilisez cette méthode, les données sont empaquetées en blocs plus petits qui peuvent être chargés en utilisant plusieurs processus parallèles. Pour plus d’informations, consultez la documentation spécifique au connecteur.
Recommandations générales
Utilisez la transaction SAP RZ12 pour modifier les valeurs du nombre maximal de connexions simultanées.
Paramètres SAP pour RFC - RZ12 : le paramètre suivant peut limiter le nombre d’appels RFC autorisés pour un utilisateur ou une application : vérifiez donc que cette restriction ne provoque pas de goulot d’étranglement.
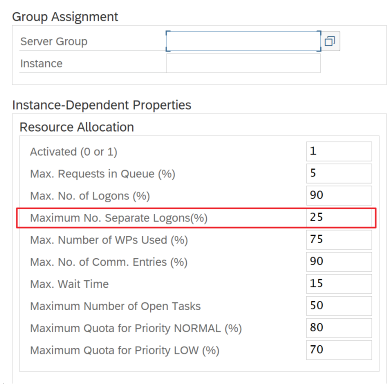
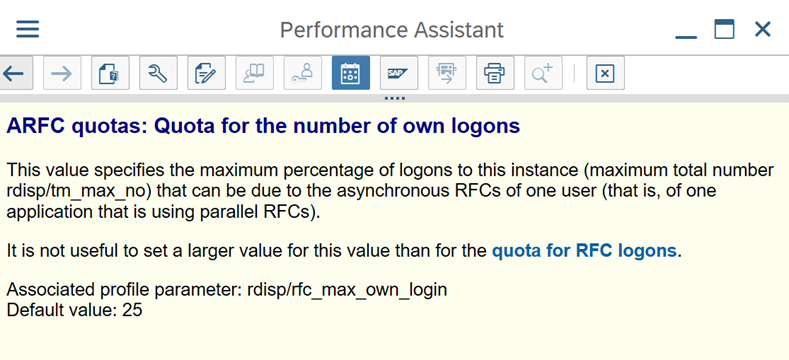
Connexion à SAP en utilisant une connexion « Groupe » : le runtime d’intégration auto-hébergé (SHIR) doit se connecter à SAP en utilisant une connexion SAP « Groupe » (via un serveur de messages) et non pas à un serveur d’applications spécifique, pour garantir une distribution des charges de travail entre tous les serveurs d’applications disponibles.
Notes
Le cluster Spark de flux de données et le runtime d’intégration auto-hébergé sont puissants. De nombreuses activités de copie SAP internes, par exemple 16, peuvent être déclenchées et exécutées. Cependant, si le nombre de connexions simultanées du serveur SAP est petit, par exemple 8, le perf lit les données du côté SAP.
Commencez par des machines virtuelles avec 4 processeurs virtuels et 16 Go pour le runtime d’intégration auto-hébergé. Les étapes suivantes montrent la connexion du processus de travail de dialogue dans SAP avec le runtime d’intégration auto-hébergé.
- Vérifiez si le client utilise une machine physique peu puissante pour configurer et installer le runtime d’intégration auto-hébergé afin d’exécuter une copie SAP interne.
- Accédez au portail Azure Data Factory et recherchez le service lié SAP CDC associé qui est utilisé dans le flux de données. Vérifiez le nom du runtime d’intégration auto-hébergé référencé.
- Vérifiez les paramètres pour la processeur, la mémoire, le réseau et le disque de la machine physique sur laquelle le runtime d’intégration auto-hébergé est installé.
- Vérifiez le nombre de
diawp.exeen cours d’exécution sur l’ordinateur du runtime d’intégration auto-hébergé. Undiawp.exepeut exécuter une activité de copie. Le nombre dediawp.exeest basé sur les paramètres pour le processeur, la mémoire, le réseau et le disque de la machine.
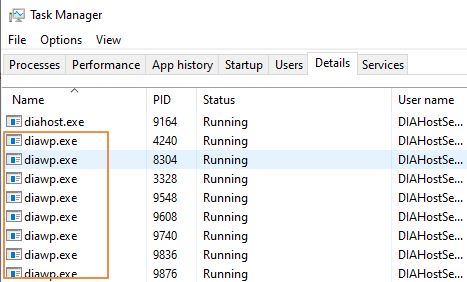
Si vous voulez exécuter plusieurs partitions en parallèle sur le en même temps, utilisez une machine virtuelle puissante pour configurer le runtime d’intégration auto-hébergé. Vous pouvez aussi utiliser un scale-out avec les fonctionnalités de haute disponibilité et de scalabilité du runtime d’intégration auto-hébergé pour avoir plusieurs nœuds. Pour plus d'informations, consultez Haute disponibilité et scalabilité.
Partitions
La section suivante décrit le processus de partitionnement d’un connecteur SAP CDC. Le processus est le même pour un connecteur SAP Table et SAP BW Open Hub.

La mise à l’échelle peut être effectuée sur le runtime d’intégration auto-hébergé ou sur Azure IR en fonction de vos exigences en matière de performances. Passez en revue la consommation du processeur du runtime d’intégration auto-hébergé pour voir les métriques et décider ainsi de votre approche de mise à l’échelle. Le runtime d’intégration auto-hébergé peut être mis à l’échelle verticalement ou horizontalement en fonction de vos besoins. Nous vous recommandons de déployer Azure IR sur une référence SKU inférieure. Effectuez un scale-up pour satisfaire vos exigences en matière de performances, telles que déterminées par les tests de charge, au lieu de commencer inutilement à un niveau plus élevé.
Notes
Si vous atteignez 70 % de capacité, effectuez un scale-up ou un scale-out pour le runtime d’intégration auto-hébergé.

Le partitionnement est utile pour les chargements complets initiaux ou de grande taille et n’est généralement pas nécessaire pour les chargements delta. Si vous ne spécifiez pas la partition, par défaut, 1 « producteur » dans le système SAP (généralement un processus par lots) extrait les données sources dans la file d’attente de données opérationnelles (ODQ, Operational Data Queue) et le runtime d’intégration auto-hébergé extrait les données de l’ODQ. Par défaut, le runtime d’intégration auto-hébergé utilise quatre threads pour extraire les données de l’ODQ : quatre processus de dialogue sont donc potentiellement occupés dans SAP à ce moment-là.
L’idée du partitionnement est de diviser un grand jeu de données initial en plusieurs sous-ensembles disjoints plus petits qui sont idéalement de taille égale et qui peuvent être traités en parallèle. Cette méthode réduit le temps nécessaire pour produire les données de la table source dans l’ODQ de façon linéaire. Cette méthode suppose qu’il existe suffisamment de ressources du côté SAP pour gérer le chargement.
Notes
- Le nombre de partitions exécutées en parallèle est limité par le nombre de cœurs du pilote dans Azure IR. Une résolution pour cette limitation est en cours de développement.
- Chaque unité ou package dans la transaction SAP ODQMON est un fichier unique dans le dossier de préparation.
Considérations relatives à la conception lors de l’exécution des pipelines en utilisant CDC
Vérifiez la durée de « SAP vers préparation ».
Vérifiez les performances du runtime dans le récepteur.
Envisagez d’utiliser la fonctionnalité de partitionnement pour améliorer les performances pour obtenir un meilleur débit.
Si la durée de la phase « SAP à préparation » est lente, envisagez de redimensionner le runtime d’intégration auto-hébergé selon des spécifications plus élevées.
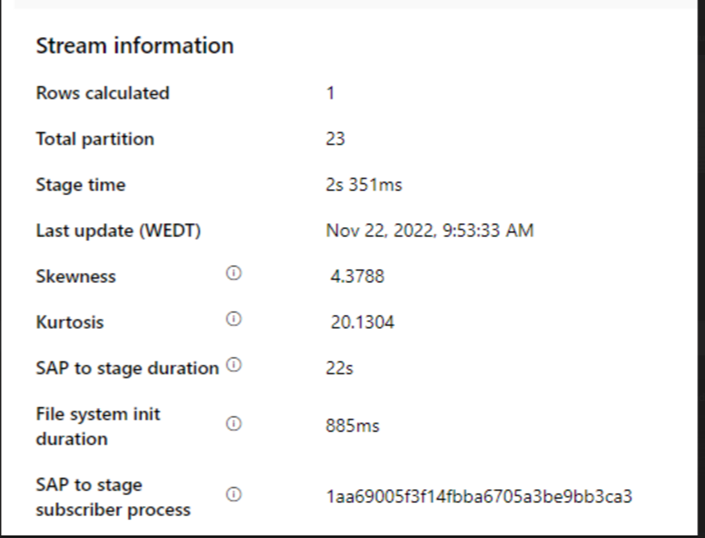
Vérifiez si le temps de traitement du récepteur n’est trop long.
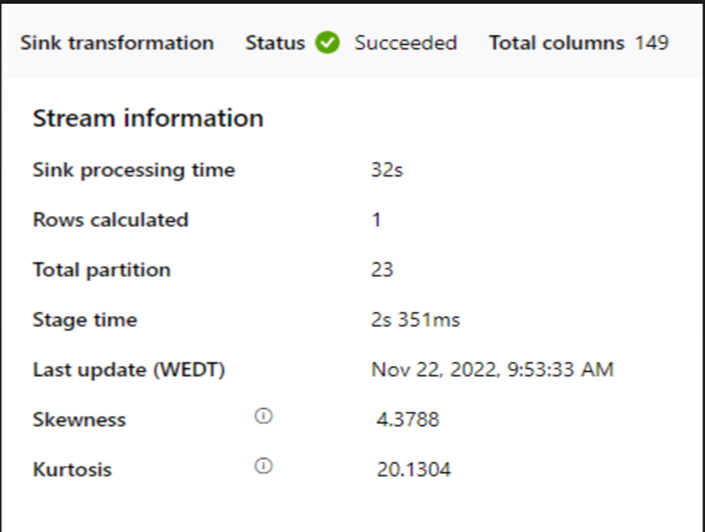
Si un petit cluster est utilisé pour exécuter le flux de données de mappage, il peut affecter les performances au niveau du récepteur. Utilisez un cluster de grande taille, par exemple 16 + 256 cœurs, afin que le perf lise les données de la phase de préparation et les écrive dans le récepteur.
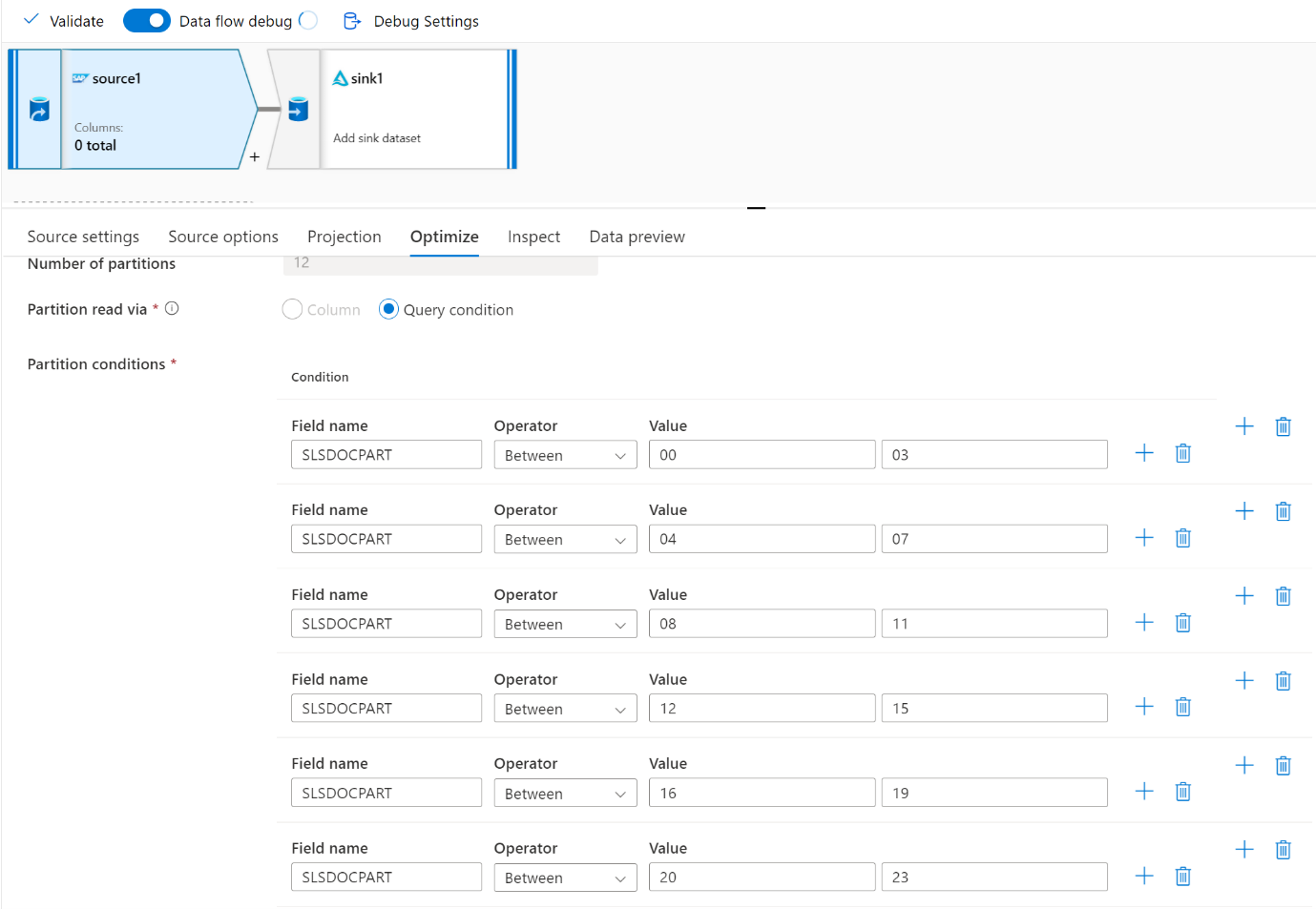
Pour les grands volumes de données, nous vous recommandons de partitionner le chargement pour exécuter des travaux en parallèle, mais de conserver le nombre de partitions inférieur ou égal à la base Azure IR, également appelée base du cluster Spark.
Utilisez l’onglet Optimiser pour définir les partitions. Vous pouvez utiliser le partitionnement de la source dans le connecteur CDC.
Notes
- Il existe une corrélation directe entre le nombre de partitions avec des cœurs de runtime d’intégration auto-hébergé et les nœuds Azure IR.
- Le connecteur SAP CDC est listé comme type d’abonné Odata « Accès Odata pour le provisionnement de données opérationnelles » sous ODQMON dans le système SAP.
Considérations relatives à la conception lors de l’utilisation d’un connecteur Table
- Optimisez le partitionnement pour de meilleures performances.
- Tenez compte du degré de parallélisme de SAP Table.
- Envisagez une conception avec un fichier unique pour le récepteur cible.
- Établissez un point de référence du débit quand vous utilisez de grands volumes de données.
Recommandations de conception lors de l’utilisation d’un connecteur Table
Partitionnement : lorsque vous partitionnez dans le connecteur SAP Table, il divise une instruction Select sous-jacente en plusieurs instructions en utilisant des clauses Where sur un champ approprié, par exemple un champ avec une cardinalité élevée. Si votre table SAP contient un grand volume de données, activez le partitionnement pour diviser les données en partitions plus petites. Essayez d’optimiser le nombre de partitions (paramètre
maxPartitionsNumber) afin que les partitions soient suffisamment petites pour éviter les vidages de mémoire dans SAP, mais suffisamment grandes pour accélérer l’extraction.Parallélisme : le degré de parallélisme de la copie (paramètre
parallelCopies) fonctionne en tandem avec le partitionnement et indique au runtime d’intégration auto-hébergé d’effectuer des appels RFC parallèles au système SAP. Par exemple, si vous définissez ce paramètre sur 4, le service génère et exécute simultanément quatre requêtes basées sur l’option de partitionnement et les paramètres que vous avez spécifiés. Chaque requête récupère une partie des données auprès de votre table SAP.Pour des résultats optimaux, le nombre de partitions doit être un multiple du nombre spécifié pour le degré de parallélisme de la copie.
Quand vous copiez des données depuis une table SAP vers des récepteurs binaires, le nombre réel de processus parallèles est ajusté automatiquement en fonction de la quantité de mémoire disponible dans le runtime d’intégration auto-hébergé. Prenez note de la taille de machine virtuelle du runtime d’intégration auto-hébergé pour chaque cycle de test, du degré de parallélisme de la copie et du nombre de partitions. Observez les performances de la machine virtuelle du runtime d’intégration auto-hébergé, les performances du système SAP source et le degré de parallélisme souhaité par rapport au degré réel de parallélisme. Utilisez un processus itératif pour identifier les paramètres optimaux et la taille idéale pour la machine virtuelle du runtime d’intégration auto-hébergé. Considérez tous les pipelines d’ingestion qui chargent simultanément des données depuis un ou plusieurs systèmes SAP.
Prenez note du nombre observé d’appels RFC à SAP par rapport au degré configuré de parallélisme. Si le nombre d’appels RFC à SAP est inférieur au degré de parallélisme, vérifiez que la machine virtuelle du runtime d’intégration auto-hébergé dispose de suffisamment de ressources mémoire et processeur. Choisissez si nécessaire une machine virtuelle plus grande. Le système SAP source est configuré pour limiter le nombre de connexions parallèles. Pour plus d’informations, consultez la section Recommandations générales de cet article.
Nombre de fichiers : quand vous copiez des données dans un magasin de données basé sur des fichiers et que le récepteur ciblé est configuré pour être un dossier, plusieurs fichiers sont générés par défaut. Si vous définissez la propriété
fileNamedans le récepteur, les données sont écrites dans un seul fichier. Il est recommandé d’écrire dans un dossier en utilisant plusieurs fichiers, car vous obtenez ainsi un débit d’écriture plus élevé en comparaison de l’écriture dans un seul fichier.Analyse comparative des performances : nous recommandons d’utiliser l’exercice d’analyse comparative des performances pour ingérer de grandes quantités de données. Cette méthode fait varier les paramètres, comme le partitionnement, le degré de parallélisme et le nombre de fichiers, pour déterminer le paramétrage optimal pour l’architecture, le volume et le type de données concernés. Collectez les données des tests au format suivant.


Dépannage
Lorsque l’extraction depuis le système SAP est lente ou échoue, utilisez les journaux SAP de SM37 et mettez-les en correspondance avec les lectures dans Data Factory.
Si un seul travail par lots est déclenché, définissez les partitions sources SAP de façon à améliorer les performances du flux de données de mappage dans Data Factory. Pour plus d’informations, reportez-vous à l’étape 6 dans Propriétés des flux de données de mappage.
Si plusieurs travaux par lots sont déclenchés dans le système SAP et qu’il existe une différence significative entre l’heure de début de chaque travail par lots, changez la taille d’Azure IR. Quand vous augmentez le nombre de nœuds de pilote dans Azure IR, le parallélisme des travaux par lots côté SAP augmente.
Notes
Le nombre maximal de nœuds de pilote pour Azure IR est de 16. Chaque nœud de pilote ne peut déclencher qu’un seul traitement par lots.
Vérifiez les journaux dans le runtime d’intégration auto-hébergé. Pour voir les journaux, accédez à machine virtuelle du runtime d’intégration auto-hébergé. Ouvrez Observateur d’événements > Applications et journaux de service > Connecteurs > Runtime d’intégration.
Pour envoyer des journaux au support, accédez à la machine virtuelle avec SHIR. Ouvrez le Gestionnaire de configuration du runtime d’intégration > Diagnostic > Envoyer les journaux. Cette action envoie les journaux des sept derniers jours et vous fournit un ID de rapport. Vous avez besoin de cet ID de rapport et du RunId de votre exécution. Documentez l’ID de rapport pour pouvoir vous y référer plus tard.
Quand vous utilisez le connecteur SAP CDC dans un scénario SLT :
Vérifiez que les prérequis sont satisfaits. Des rôles sont nécessaires pour l’utilisateur SAP Landscape Transformation (SLT), par exemple ADFSLTUSER, ou ECC dans les systèmes OLTP, pour que la réplication SLT fonctionne. Pour plus d’informations, consultez la section Autorisations et rôles nécessaires.
Si des erreurs se produisent dans un scénario SLT, consultez les recommandations pour en faire l’analyse. Isolez et testez d’abord le scénario dans la solution SAP. Par exemple, testez-le en dehors de Data Factory en exécutant le programme de test
RODPS_REPL_TESTfourni par SAP dans SE38. Si le problème est du côté SAP, vous obtenez la même erreur quand vous utilisez le rapport. Vous pouvez analyser l’extraction des données dans SAP en utilisant le code de transactionODQMON.Si la réplication fonctionne quand vous utilisez ce rapport de test, mais pas avec Data Factory, contactez le support Azure ou Data Factory.
L’exemple suivant présente un rapport pour
RODPS_REPL_TESTdans SE38 :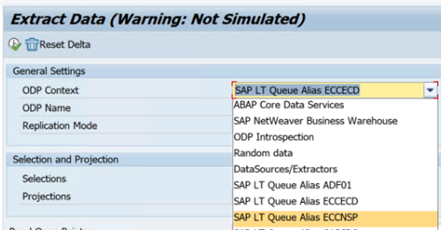
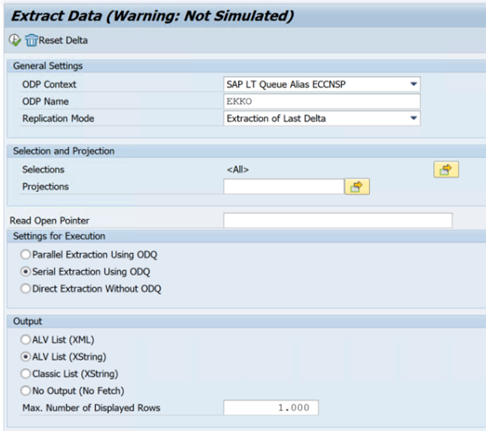

L’exemple suivant présente le code de transaction
ODQMON: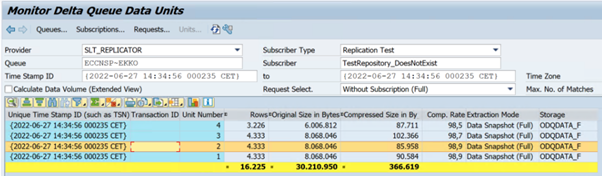
Quand le service lié Data Factory se connecte au système SLT, il n’affiche pas les ID de transfert de masse SLT quand vous actualisez le champ Contexte.
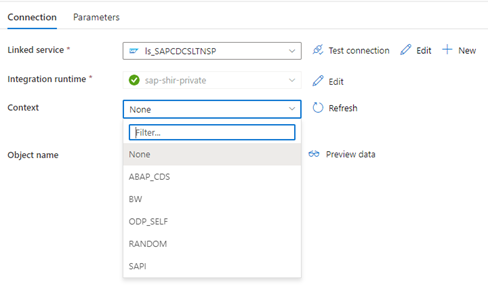
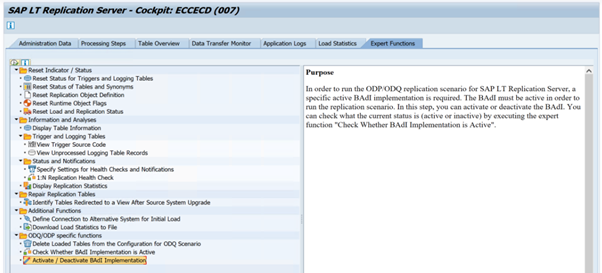
Pour exécuter le scénario de réplication ODP/ODQ pour serveur de réplication SAP SLT, activez l’implémentation du complément métier (BAdI) suivant.
BAdI :
BADI_ODQ_QUEUE_MODELImplémentation de l’amélioration :
ODQ_ENH_SLT_REPLICATIONDans la transaction LTRC, accédez à l’onglet Fonction d’expert et sélectionnez Activer/Désactiver l’implémentation de BAdI pour activer l’implémentation.
Sélectionnez Oui.
Dans le dossier Fonctions spécifiques ODQ/ODP, sélectionnez Vérifier si l’implémentation de BAdI est active.

La boîte de dialogue montre l’activité du programme.
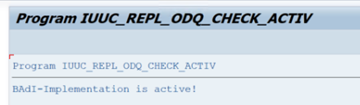
Réinitialisez les abonnements. Pour commencer par une nouvelle extraction ou arrêter les données de réplication, supprimez l’abonnement dans ODQMON. Cette action supprime également les entrées de LTRC. Après réinitialisation de l’abonnement, quelques minutes peuvent être nécessaires avant que vous l’effet n’apparaisse dans LTRC. Planifier les tâches de nettoyage ODP (Operational Data Provisioning) pour que les files d’attente delta restent propres (comme
ODQ_CLEANUP_CLIENT_004)CDS_VIEW (transaction DHCDCMON). Depuis S/4HANA 1909, SAP réplique les données à partir de vues CDS qui utilisent des déclencheurs basés sur des données (au lieu de colonnes de date). Le concept est similaire à celui de SLT, sauf qu’il utilise la transaction DHCDCMON à la place de la transaction LTRC pour la surveillance.
Résolution des problèmes SLT
Le serveur de réplication SLT fournit une réplication des données en temps réel depuis des sources SAP et/ou non-SAP vers des cibles SAP et/ou non-SAP. Trois types d’ensembles d’outils permettent de surveiller l’extraction de SLT vers Azure.
- ODQMON est l’outil de surveillance global pour l’extraction de données. Démarrez l’analyse avec ODQMON pour suivre les incohérences de données, procéder à l’analyse initiale des performances et ouvrir les requêtes d’abonnement et d’extraction.
- LTRC est la transaction à utiliser pour vérifier l’analyse des performances. Elle est utile si vous rencontrez des problèmes de réplication de données du système source vers ODP, car elle permet de surveiller le flux de données et de rechercher des incohérences.
- SM37 assurer une surveillance détaillée à chaque étape d’extraction SLT.
Les tâches de nettoyage ordinaires doivent être réalisées avec ODQMON, qui permet de gérer directement l’abonnement sans utiliser LTRC aux mêmes fins.
Vous pouvez rencontrer des problèmes lors de l’extraction de données depuis SLT, par exemple :
L’extraction ne s’exécute pas. Vérifiez si la connexion SAP CDC a créé une connexion dans ODQMON et si l’abonnement existe.
Incohérences de données. Accédez à ODQMON pour afficher la requête individuelle de données et valider que les données y sont affichées. Si vous pouvez consulter les données dans ODQMON, mais pas dans Azure Synapse ou Data Factory, vous devez pousser l’investigation du côté d’Azure. Si vous ne pouvez pas consulter les données dans ODQMON, effectuez une analyse de l’infrastructure SLT avec LTRC.
Problèmes de performances. L’extraction de données est une approche en deux étapes. Tout d’abord, SLT lit les données du système source et les transfère à ODP. Deuxièmement, le connecteur SAP CDC récupère les données depuis ODP et les transfère au magasin de données choisi. La transaction LTRC permet d’analyser la première partie du processus d’extraction. Pour analyser l’extraction de données d’ODP vers Azure, utilisez les outils de supervision ODQMON et Data Factory ou Synapse.
Notes
Pour plus d’informations, consultez ces ressources :
Performances SLT
En mode de chargement initial (ODPSLT), trois étapes permettent d’extraire des données de SLT dans ODP :
- Créez des objets de migration. Ce processus ne prend que quelques secondes.
- Accédez au calcul du plan qui fractionne la table source en blocs plus petits. Cette étape dépend du mode de chargement initial sélectionné pendant la configuration SLT et de la taille de la table. L’option « Optimisé pour les ressources » est recommandée.
- Le chargement de données transfère les données du système source vers ODP.
Chaque étape est contrôlée par les tâches en arrière-plan. Vous pouvez utiliser les transactions SM37 et LTRC pour surveiller la durée. Si le système est surutilisé, les tâches en arrière-plan peuvent démarrer plus tard, car le nombre de processus de travail par lots libres est insuffisant. Lorsque les tâches sont inactives, les performances en pâtissent.
Si le calcul du plan d’accès prend beaucoup de temps et que le mode de chargement initial est défini sur « Optimisé pour les performances », remplacez-le par « Optimisé pour les ressources » et réexécutez l’extraction. Si le chargement de données prend beaucoup de temps, augmentez le nombre de threads parallèles dans la configuration.
Si vous utilisez une architecture autonome pour la réplication SLT (serveur de réplication SLT dédié), le débit réseau entre le système source et le serveur de réplication peut affecter les performances d’extraction.
Pour la réplication :
- Assurez-vous de disposer d’un nombre suffisant de tâches de transfert de données qui ne sont pas réservées pour le chargement initial.
- Vérifiez que les statistiques de charge ne comportent pas d’enregistrement de table de journalisation non traité.
- Vérifiez que l’option de réplication est définie sur « en temps réel ».
Les paramètres de réplication avancés sont disponibles dans LTRS. Pour plus d’informations, consultez le SLT troubleshooting guide (guide de résolution des problèmes SLT) (seulement disponible en anglais).
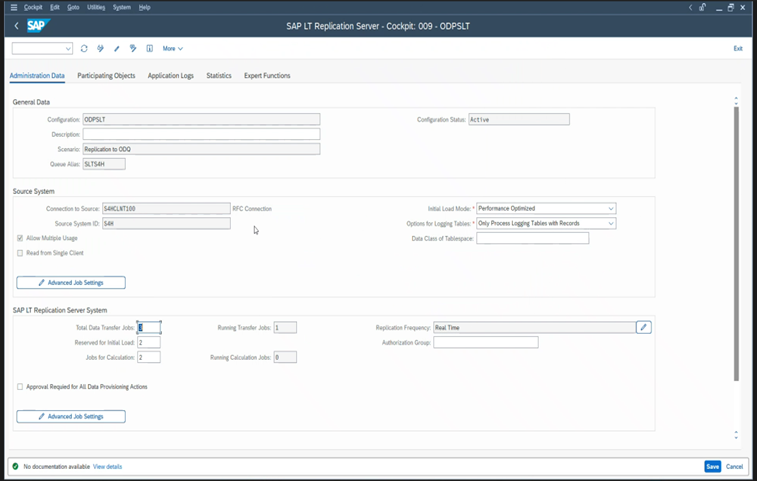
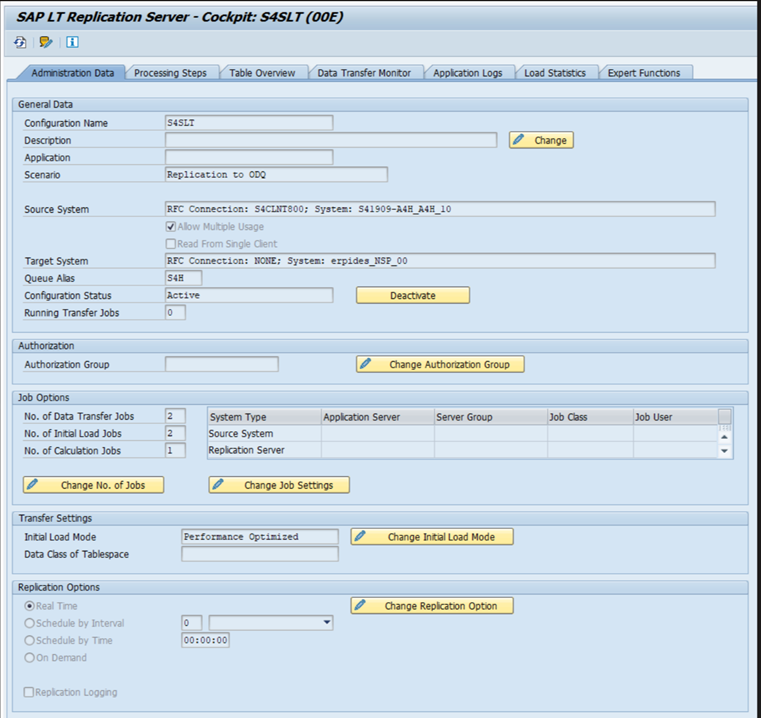
Les différentes versions SAP comportent différentes interfaces utilisateur LTRC. Les captures d’écran suivantes représentent la même page dans deux versions différentes.
SAP S/4HANA :
SAP ECC :


Monitor
Pour plus d’informations sur la surveillance de l’extraction de données SAP, consultez les ressources suivantes :
- Surveiller visuellement Azure Data Factory
- Monitoring Delta Queues (Surveiller les files d’attente delta) (seulement disponible en anglais)