Zones d’atterrissage des données
Les zones d’atterrissage des données sont connectées à votre zone d’atterrissage de gestion des données via l’appairage de réseaux virtuels (VNET Peering). Chaque zone d’atterrissage de données est considérée comme une zone d’atterrissage liée à l’architecture de zone d’atterrissage Azure.
Important
Avant de provisionner une zone d’atterrissage des données, assurez-vous de disposer d’un modèle de fonctionnement DevOps et CI/CD (intégration/déploiement continus) et une zone d’atterrissage de gestion des données doit être déployée.
Chaque zone d’atterrissage des données possède plusieurs couches pour permettre l’agilité des intégrations des données de service et des produits de données qu’elle contient. Vous pouvez déployer une nouvelle zone d’atterrissage des données avec un ensemble standard de services pour permettre à la zone d’atterrissage des données de commencer à ingérer et à analyser les données.
Votre abonnement Azure associé à votre zone d’atterrissage de données a la structure suivante :
Remarque
Une application de données produit un ou plusieurs produits de données.
Architecture de la zone d’atterrissage des données
Une architecture de zone d’atterrissage des données illustre les couches, les groupes de ressources, ainsi que les services contenus dans chaque groupe de ressources. Cette architecture fournit également une vue d’ensemble de tous les groupes et les rôles associés à votre zone d’atterrissage des données, ainsi que de l’étendue de leur accès aux plans de contrôle et de données.

Conseil
Avant de déployer une zone de destination des données, assurez-vous de prendre en compte le nombre de zones de destination des données initiales que vous souhaitez déployer.
Utilisez cette architecture comme point de départ. Téléchargez le fichier Visio et modifiez-le en fonction de vos besoins métier et techniques spécifiques lors de la planification de l’implémentation de votre zone d’atterrissage de données.
Couche de services de base
La couche de services principaux inclut tous les services nécessaires pour activer votre zone d’atterrissage des données dans le contexte de l’analytique à l’échelle du cloud. Le tableau suivant répertorie les groupes de ressources qui fournissent la suite standard de services disponibles dans chaque zone d’atterrissage de données que vous déployez.
| Groupe de ressources | Obligatoire | Description |
|---|---|---|
network-rg |
Oui | Mise en réseau |
databricks-monitoring-rg |
Facultatif | Surveillance pour vos espaces de travail Azure Databricks |
hive-rg |
Facultatif | Metastore Hive pour Azure Databricks |
storage-rg |
Oui | Services des lacs de données |
external-data-rg |
Oui | Charger le stockage d’ingestion |
runtimes-rg |
Oui | Runtimes d'intégration partagés |
mgmt-rg |
Oui | Agents CI/CD |
metadata-ingestion-rg |
Facultatif | Ingestion agnostique de données |
databricks-monitoring-rg |
Facultatif | Espace de travail Log Analytics pour les espaces de travail Databricks dans la zone d’atterrissage |
shared-synapse-rg |
Facultatif | Azure Synapse partagé |
shared-databricks-rg |
Facultatif | Espace de travail Azure Databricks partagé |
Mise en réseau
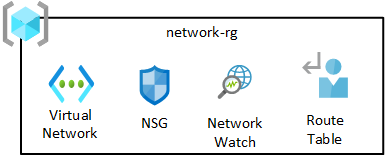
Le groupe de ressources réseau contient les principaux composants, y compris Azure Network Watcher, les groupes de sécurité réseau (NSG) et un réseau virtuel. Tous ces services sont déployés dans un groupe de ressource unique.
Le réseau virtuel d’une zone d’atterrissage des données est automatiquement appairé au réseau virtuel de la zone d’atterrissage de gestion des données et à votre réseau virtuel de l’abonnement de connectivité.
Surveillance des espaces de travail Azure Databricks
Ce groupe de ressources est facultatif et se déploie uniquement avec Azure Databricks.
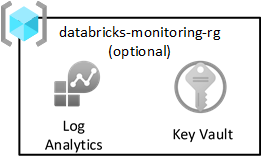
Le modèle de zone d’atterrissage Azure vous recommande d’envoyer tous les journaux à un espace de travail Log Analytics central. Toutefois, chaque zone d'atterrissage de données comprend également un groupe de ressources de supervision pour capturer les journaux Spark à partir de Databricks. Chaque groupe de ressources contient un espace de travail Log Analytics partagé et un coffre Azure Key Vault pour stocker les clés de Log Analytics.
Important
Utilisez uniquement l’espace de travail Log Analytics dans votre groupe de ressources de surveillance Databricks pour capturer les journaux Azure Databricks Spark.
Pour plus d'informations, consultez Supervision d'Azure Databricks.
Metastore Hive pour Azure Databricks
Ce groupe de ressources est facultatif et ne doit être déployé qu’avec Azure Databricks.
Le metastore Hive pour Azure Databricks provisionne une base de données Azure Database pour MySQL et un coffre de clés. Tous les espaces de travail Azure Databricks de votre zone d’atterrissage de données utilisent ce metastore comme metastore Apache Hive externe.
Pour plus d’informations, consultez Metastore Apache Hive externe.
Services de lac de données
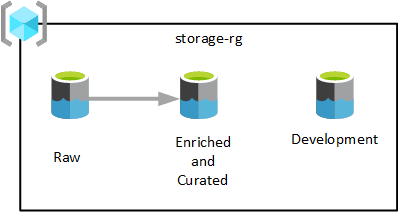
Comme indiqué dans le diagramme précédent, trois comptes Azure Data Lake Storage Gen2 sont provisionnés dans le groupe de ressources de services de lac de données unique. Les données transformées à différentes étapes sont enregistrées dans l’un des lacs de données de votre zone d’atterrissage de données. Les données sont disponibles pour la consommation par vos équipes d’analyse, de science des données et de visualisation.
Les couches Data Lake utilisent une terminologie différente en fonction de la technologie et du fournisseur. Ce tableau fournit des conseils sur la façon d’appliquer des conditions pour l’analytique à l’échelle du cloud :
| Analyse de niveau cloud | Delta Lake | Autres termes | Description |
|---|---|---|---|
| Brut | Bronze | Atterrissage et conformité | Tables d’ingestion |
| Enrichie | Argent | Zone de standardisation | Tables affinées. Entités complètes stockées, jeux d’enregistrements prêts pour la consommation à partir de systèmes d’enregistrement. |
| Organisé | Or | Zone de produit | Fonctionnalités ou tables agrégées. Zone principale pour les applications, les équipes et les utilisateurs pour consommer des produits de données. |
| Développement | -- | Zone de développement | Emplacement pour les ingénieurs de données et les scientifiques, comprenant à la fois un bac à sable analytique et une zone de développement de produit. |
Remarque
Dans le diagramme précédent, chaque zone d’atterrissage de données a trois lacs de données. Toutefois, selon vos besoins, vous pouvez consolider vos couches brutes, enrichies et organisées dans un compte de stockage, et conserver un autre compte de stockage appelé « développement » pour que les consommateurs de données apportent d’autres produits de données utiles.
Pour plus d'informations, consultez les pages suivantes :
- Vue d'ensemble d'Azure Data Lake Storage pour l'analyse à l'échelle du cloud
- Standardisation des données
- Provisionner des comptes Azure Data Lake Storage Gen2 pour chaque zone d’atterrissage des données
- Considérations importantes pour Azure Data Lake Storage
- Contrôle d’accès et configurations de lacs de données dans Azure Data Lake Storage
Charger le stockage d’ingestion
Les éditeurs de données tiers doivent atterrir des données dans votre plateforme afin que vos équipes d’applications de données puissent les extraire dans leurs lacs de données. Comme illustré dans le diagramme suivant, votre groupe de ressources de stockage d’ingestion de chargement vous permet de provisionner des magasins d’objets blob pour des tiers.
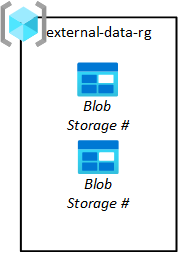
Vos équipes d’application de données demandent ces objets blob de stockage. Leurs demandes sont ensuite approuvées par votre équipe chargée des opérations de zone d’atterrissage des données. Les données doivent être supprimées de son objet blob de stockage source une fois qu’elles ont été extraites de l’objet blob de stockage en données brutes.
Important
Étant donné que le provisionnement des objets blob de Stockage Azure s’effectue en fonction des besoins, vous devriez déployer initialement un groupe de ressources de services de stockage vide dans chaque zone d’atterrissage des données.
Runtimes d'intégration partagés
Déployez une machine virtuelle avec des runtimes d’intégration auto-hébergés dans votre zone d’atterrissage de données. Hébergez-le dans le groupe de ressources d’intégration partagée. Ce déploiement vous permet d’intégrer rapidement des produits de données à votre zone d’atterrissage des données.
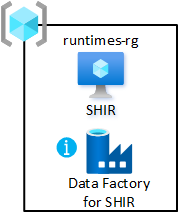
Pour activer le groupe de ressources :
- Créez au moins une fabrique Azure Data Factory dans le groupe de ressources d’intégration partagée de la zone d’atterrissage des données. Utilisez-la uniquement pour lier le runtime d’intégration auto-hébergé partagé et pas pour les pipelines de données.
- Créez et configurez un runtime d’intégration auto-hébergé sur la machine virtuelle.
- Associez le runtime d’intégration auto-hébergé avec des fabriques de données Azure dans votre zone ou vos zones d’atterrissage de données.
- Configurez Azure Automation pour mettre à jour périodiquement le runtime d’intégration auto-hébergé.
Remarque
Le déploiement ci-dessus fournit un déploiement de machine virtuelle unique avec des runtimes d’intégration auto-hébergés. Vous pouvez associer un runtime d’intégration auto-hébergé à plusieurs machines locales ou machines virtuelles dans Azure. Ces ordinateurs sont appelés nœuds. Vous pouvez associer jusqu’à quatre nœuds à un runtime d’intégration auto-hébergé. La présence de plusieurs nœuds sur des machines locales avec une passerelle installée présente les avantages suivants pour une passerelle logique :
- La haute disponibilité du runtime d’intégration auto-hébergé supprime le point de défaillance unique dans votre solution Big Data ou dans l’intégration de vos données cloud. Cette disponibilité contribue à garantir une continuité lorsque vous utilisez jusqu'à quatre nœuds.
- Les performances et le débit lors du déplacement des données entre les magasins de données locaux et dans le cloud ont été améliorés. Plus d’informations sur les comparaisons des performances.
Vous pouvez associer plusieurs nœuds en installant le logiciel du runtime d’intégration auto-hébergé à partir du Centre de téléchargement. Ensuite, inscrivez-le à l’aide des clés d’authentification obtenues par le biais de la cmdlet New-AzDataFactoryV2IntegrationRuntimeKey, comme décrit dans le tutoriel.
Pour plus d’information, consultez Haute disponibilité et scalabilité d’Azure Datafactory.
Important
Déployez des runtimes d’intégration partagés aussi près de la source de données que possible. Ce déploiement ne limite pas votre déploiement de runtimes d’intégration au sein d’une zone d’atterrissage des données ou dans des clouds tiers. Au lieu de cela, il fournit un secours pour les sources de données natives dans le cloud, dans la région.
Agents CI/CD
Les agents CI/CD vous aident à déployer des applications de données et des modifications dans la zone d’atterrissage des données.
Pour plus d’informations, consultez Agents Azure Pipelines.
Ingestion agnostique de données
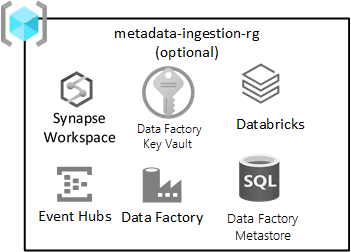
Ce groupe de ressources est facultatif et ne vous empêche pas de déployer votre zone d’atterrissage.
Ce groupe de ressources s’applique si vous avez (ou développez) un moteur d’ingestion indépendant des données pour l’ingestion automatique des données en fonction de l’inscription des métadonnées (y compris les chaînes de connexion, le chemin d’accès à partir duquel copier des données et vers, et la planification d’ingestion). Le groupe de ressources d’ingestion et de traitement a des services clés pour ce type d’infrastructure.
Déployez une instance Azure SQL Database pour contenir les métadonnées utilisées par Azure Data Factory. Provisionnez un coffre Azure Key Vault pour stocker les secrets relatifs aux services d’ingestion automatisés. Ces secrets peuvent inclure :
- Informations de connexion de metastore Azure Data Factory
- Informations d’identification du principal de service pour votre processus d’ingestion automatisé
Pour en savoir plus, consultez Comment les infrastructures d'ingestion automatisée prennent en charge l'analyse à l'échelle du cloud dans Azure.
Les services inclus dans ce groupe de ressources comprennent :
| Service | Obligatoire | Consignes |
|---|---|---|
| Azure Data Factory | Oui | Azure Data Factory est votre moteur d’orchestration pour l’ingestion indépendante des données. |
| Azure SQL DB | Oui | Azure SQL DB est le metastore pour Azure Data Factory. |
| Event Hubs ou IoT Hub | Facultatif | Event Hubs ou IoT Hub peuvent fournir un streaming en temps réel vers Event Hubs, en plus d’un traitement des lots et du streaming via un espace de travail Engineering Databricks. |
| Azure Databricks | Facultatif | Vous pouvez déployer Azure Databricks ou Azure Synapse Spark à utiliser avec votre moteur d’ingestion indépendant des données. |
| Azure Synapse | Facultatif | Vous pouvez déployer Azure Databricks ou Azure Synapse Spark pour utiliser avec le moteur d’ingestion indépendant des données. |
Databricks partagés
Ce groupe de ressources est facultatif et se déploie uniquement avec Azure Databricks. Tout le monde dans votre zone d’atterrissage de données peut utiliser un espace de travail Databricks.
Azure Databricks est un consommateur clé du service Azure Data Lake Storage. Les opérations atomiques de fichiers sont optimisées pour les moteurs d’analytique Spark. Cette optimisation accélère l'achèvement des travaux Spark qui posent problème au service Azure Databricks.
Important
Un espace de travail Azure Databricks appelé espace de travail Azure Databricks Analytics est configuré pour tous les scientifiques des données et DataOps, comme indiqué dans le groupe de ressources de produits partagés.
Vous pouvez configurer cet espace de travail pour vous connecter à votre Azure Data Lake à l’aide du relais Microsoft Entra ou du contrôle d’accès aux tables. Selon votre cas d’usage, vous pouvez configurer l’accès conditionnel en tant que mesure de sécurité supplémentaire.
Suivez les bonnes pratiques d’analytique à l’échelle du cloud pour intégrer Azure Databricks :
- Sécuriser l’accès à Azure Data Lake 2e génération à partir d’Azure Databricks
- Meilleures pratiques Azure Databricks
Le modèle de zone d’atterrissage Azure vous recommande d’envoyer tous les journaux à un espace de travail Log Analytics central. Toutefois, chaque zone d'atterrissage de données comprend également un groupe de ressources de supervision pour capturer les journaux Spark à partir de Databricks.
Azure Synapse Analytics partagé
Ce groupe de ressources est facultatif.
Lors de votre configuration initiale d’une zone atterrissage des données, un espace de travail Azure Synapse Analytics unique est déployé pour être utilisé par l’ensemble des analystes de données et des scientifiques de données dans votre groupe de ressources de produits partagés.
Vous pouvez configurer davantage d’espaces de travail Synapse pour les produits de données si la gestion des coûts et la recharge sont nécessaires. Vos équipes chargées de l’application des données peuvent utiliser des espaces de travail Azure Synapse Analytics dédiés pour créer des pools de base de données Azure SQL dédiés, en tant que magasin de données en lecture utilisé par la couche de visualisation.
Important
Empêchez l’utilisation de votre espace de travail de Azure Synapse partagé pour la création du produit de données en verrouillant l’espace de travail pour autoriser uniquement des requêtes SQL à la demande. C’est là à des fins exploitatives uniquement.
Application des données
Chaque zone d’atterrissage des données peut avoir plusieurs produits de données. Vous pouvez créer ces produits de données en ingérant des données à partir de la source. Vous pouvez également créer des produits de données à partir d'autres produits de données dans la même zone d’atterrissage des données ou à partir d'autres zones d’atterrissage des données. La création des produits de données est soumise à l’approbation de l’administrateur de données.
Groupe de ressources de produit de données
Votre groupe de ressources de produits de données comprend tous les services requis pour fabriquer ce produit de données. Par exemple, une base de données Azure est requise pour MySQL, qui est utilisée par un outil de visualisation. Les données doivent être ingérées et transformées avant d’être placées dans la base de données MySQL. Dans ce cas, vous pouvez déployer Azure Database pour MySQL et Azure Data Factory dans le groupe de ressources de produits de données.
Conseil
Si vous choisissez de ne pas implémenter un moteur indépendant des données pour l’ingestion d’une seule fois à partir de sources opérationnelles, ou si des connexions complexes ne sont pas facilitées dans votre moteur d’agnostique de données, créez une application de données alignée sur la source. Pour plus d'informations, voir Applications de données (alignées sur la source)
Pour plus d’informations sur l’intégration de produits de données, consultez Produits de données de l’analytique à l’échelle du cloud dans Azure.
Visualisation
Pour chaque zone d’atterrissage de données, un groupe de ressources de visualisation vide est créé. Remplissez ce groupe de ressources avec les services dont vous avez besoin pour implémenter votre solution de visualisation. L'utilisation de votre réseau virtuel existant permet à votre solution de se connecter aux produits de données.
Ce groupe de ressources peut héberger des machines virtuelles hôtes pour les services de visualisation tiers.
Conseil
Il peut être plus économique de déployer des produits de visualisation tiers dans votre zone d’atterrissage de gestion des données en raison des coûts de licences, ainsi que de connecter des produits dans des zones d’atterrissage des données pour récupérer (pull) les données.