Tutoriel : Copier des données d’une base de données SQL Server vers un stockage Blob Azure
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Dans ce tutoriel, vous allez utiliser Azure PowerShell pour créer un pipeline Data Factory qui copie les données d’une base de données SQL Server dans un stockage Blob Azure. Vous allez créer et utiliser un runtime d’intégration auto-hébergé, qui déplace les données entre les banques de données locales et cloud.
Notes
Cet article ne fournit pas de présentation détaillée du service Data Factory. Pour plus d’informations, consultez Présentation d’Azure Data Factory.
Dans ce tutoriel, vous effectuerez les étapes suivantes :
- Créer une fabrique de données.
- Créez un runtime d’intégration auto-hébergé.
- Créer des services liés SQL Server et au Stockage Azure.
- Créer des jeux de données SQL Server et Blob Azure.
- Créer un pipeline avec une activité de copie pour déplacer les données.
- Démarrer une exécution de pipeline.
- Surveiller l’exécution du pipeline.
Prérequis
Abonnement Azure
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Rôles Azure
Pour créer des instances de fabrique de données, le compte d’utilisateur que vous utilisez pour vous connecter à Azure doit avoir le rôle de Contributeur ou de Propriétaire, ou être administrateur de l’abonnement Azure.
Dans le portail Azure, cliquez sur votre nom d’utilisateur dans le coin supérieur droit, puis sélectionnez Autorisations pour afficher les autorisations dont vous disposez dans l’abonnement. Si vous avez accès à plusieurs abonnements, sélectionnez l’abonnement approprié. Pour obtenir des exemples d’instructions sur l’ajout d’un utilisateur à un rôle, consultez l’article Attribuer des rôles Azure à l’aide du portail Azure.
SQL Server 2014, 2016 et 2017
Dans le cadre de ce tutoriel, vous allez utiliser une base de données SQL Server comme magasin de données source. Le pipeline de la fabrique de données que vous allez créer dans ce tutoriel copie les données de cette base de données SQL Server (source) dans un stockage Blob Azure (récepteur). Créez ensuite une table nommée emp dans votre base de données SQL Server, puis insérez quelques exemples d’entrées dans la table.
Exécutez SQL Server Management Studio. S’il n’est pas déjà installé sur votre machine, accédez à Télécharger SQL Server Management Studio.
Connectez-vous à votre instance SQL Server à l’aide de vos informations d’identification.
Créez un exemple de base de données. Dans l’arborescence, cliquez avec le bouton droit sur Bases de données, puis sur Nouvelle base de données.
Dans la fenêtre Nouvelle base de données, entrez un nom pour la base de données, puis cliquez sur OK.
Pour créer la table emp et y insérer quelques données d’exemple, exécutez le script de requête suivant sur la base de données. Dans l’arborescence, cliquez avec le bouton droit sur la base de données créée, puis sur Nouvelle requête.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
Compte de Stockage Azure
Dans ce tutoriel, vous utilisez un compte Stockage Azure à usage général (stockage d’objets Blob Azure spécifiquement) comme banque de données réceptrice/de destination. Si vous ne possédez pas de compte Stockage Azure à usage général, consultez Créer un compte de stockage. Le pipeline de la fabrique de données que vous allez créer dans ce tutoriel copie les données de la base de données SQL Server (source) dans ce stockage Blob Azure (récepteur).
Obtenir le nom de compte de stockage et la clé de compte
Dans ce tutoriel, vous spécifiez le nom et la clé de votre compte Stockage Azure. Procédez comme suit pour obtenir le nom et la clé de votre compte de stockage :
Connectez-vous au portail Azure avec vos nom d’utilisateur et mot de passe Azure.
Dans le volet gauche, sélectionnez Plus de services, filtrez à l’aide du mot-clé Stockage, puis sélectionnez Comptes de stockage.
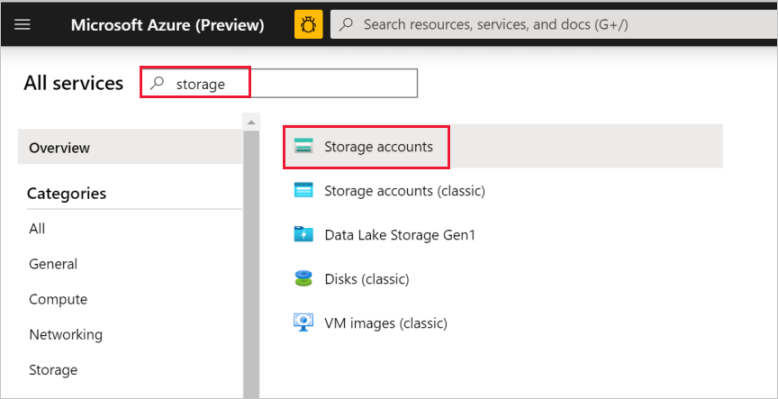
Dans la liste des comptes de stockage, appliquez un filtre pour votre compte de stockage (si nécessaire), puis sélectionnez votre compte de stockage.
Dans la fenêtre Compte de stockage, sélectionnez Clés d’accès.
Dans les zones Nom du compte de stockage et key1, copiez les valeurs, puis collez-les dans le bloc-notes ou un autre éditeur pour une utilisation ultérieure dans le tutoriel.
Créer le conteneur adftutorial
Dans cette section, vous allez créer un conteneur d’objets blob nommé adftutorial dans votre stockage Blob Azure.
Dans la fenêtre Compte de stockage, basculez vers Vue d’ensemble, puis sélectionnez Objets blob.
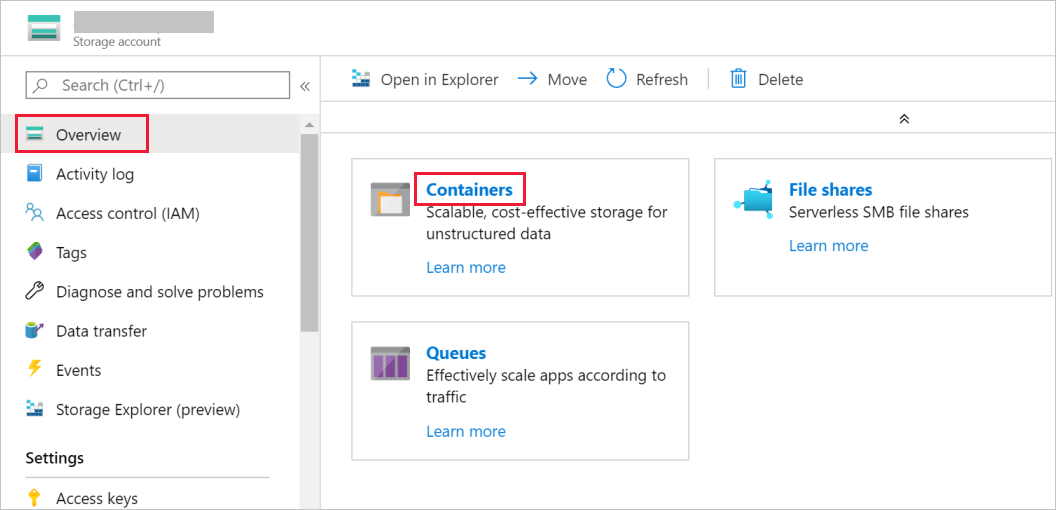
Dans la fenêtre Service Blob, sélectionnez Conteneur.
Dans la fenêtre Nouveau conteneur, dans la zone Nom , entrez adftutorial, puis sélectionnez OK.
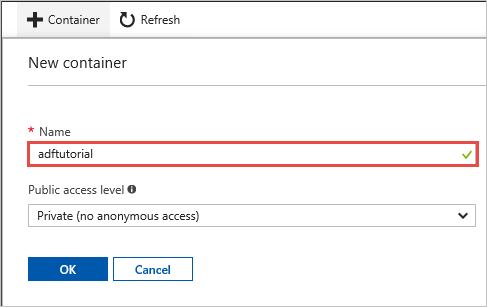
Cliquez sur adftutorial dans la liste des conteneurs.
Gardez la fenêtre conteneur de adftutorial ouverte. Elle vous permet de vérifier la sortie à la fin du tutoriel. Data Factory crée automatiquement le dossier de sortie de ce conteneur, de sorte que vous n’avez pas besoin d’en créer.
Windows PowerShell
Installation d’Azure PowerShell
Notes
Nous vous recommandons d’utiliser le module Azure Az PowerShell pour interagir avec Azure. Pour bien démarrer, consultez Installer Azure PowerShell. Pour savoir comment migrer vers le module Az PowerShell, consultez Migrer Azure PowerShell depuis AzureRM vers Az.
Installez la dernière version d’Azure PowerShell, si elle n’est pas installée sur votre machine. Pour des instructions détaillées, consultez Installation et configuration d’Azure PowerShell.
Se connecter à PowerShell
Démarrez PowerShell sur votre machine et laissez-le ouvert jusqu’à la fin de ce tutoriel de démarrage rapide. Si vous le fermez, puis le rouvrez, vous devez réexécuter ces commandes.
Exécutez la commande suivante, puis saisissez le nom d’utilisateur et le mot de passe Azure que vous utilisez pour la connexion au portail Azure :
Connect-AzAccountSi vous avez plusieurs abonnements Azure, exécutez la commande suivante pour sélectionner l’abonnement avec lequel vous souhaitez travailler. Remplacez SubscriptionId par l’ID de votre abonnement Azure :
Select-AzSubscription -SubscriptionId "<SubscriptionId>"
Créer une fabrique de données
Définissez une variable pour le nom du groupe de ressources que vous utiliserez ultérieurement dans les commandes PowerShell. Copiez la commande suivante dans PowerShell, spécifiez un nom pour le groupe de ressources Azure (entre guillemets doubles, par exemple
"adfrg"), puis exécutez la commande.$resourceGroupName = "ADFTutorialResourceGroup"Pour créer le groupe de ressources Azure, exécutez la commande suivante :
New-AzResourceGroup $resourceGroupName -location 'East US'Si le groupe de ressources existe déjà, vous pouvez ne pas le remplacer. Affectez une valeur différente à la variable
$resourceGroupNameet exécutez à nouveau la commande.Définissez une variable pour le nom de la fabrique de données que vous pourrez utiliser dans les commandes PowerShell plus tard. Les noms doivent commencer par une lettre ou un chiffre, et peuvent comporter uniquement des lettres, des chiffres et des tirets (-).
Important
Mettez à jour le nom de la fabrique de données afin qu’il soit globalement unique. Par exemple, ADFTutorialFactorySP1127.
$dataFactoryName = "ADFTutorialFactory"Définissez une variable pour l’emplacement de la fabrique de données :
$location = "East US"Exécutez l’applet de commande
Set-AzDataFactoryV2suivante pour créer la fabrique de données :Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Notes
- Le nom de la fabrique de données doit être un nom global unique. Si vous recevez l’erreur suivante, changez le nom, puis réessayez.
The specified data factory name 'ADFv2TutorialDataFactory' is already in use. Data factory names must be globally unique. - Pour créer des instances de fabrique de données, le compte d’utilisateur que vous utilisez pour vous connecter à Azure doit être un membre des rôles contributeur ou propriétaire, ou un administrateur de l’abonnement Azure.
- Pour obtenir la liste des régions Azure dans lesquelles Data Factory est actuellement disponible, sélectionnez les régions qui vous intéressent dans la page suivante, puis développez Analytique pour localiser Data Factory : Disponibilité des produits par région. Les magasins de données (Stockage Azure, Azure SQL Database, etc.) et les services de calcul (Azure HDInsight, etc.) utilisés par la fabrique de données peuvent se trouver dans d’autres régions.
Créer un runtime d’intégration auto-hébergé
Dans cette section, vous allez créer un runtime d’intégration auto-hébergé et l’associer à un ordinateur local avec la base de données SQL Server. Le runtime d’intégration auto-hébergé est le composant qui copie les données de la base de données SQL Server sur votre machine dans le stockage Blob Azure.
Créez une variable pour le nom du runtime d’intégration. Utilisez un nom unique, et notez-le. Vous l’utiliserez ultérieurement dans ce tutoriel.
$integrationRuntimeName = "ADFTutorialIR"Créez un runtime d’intégration auto-hébergé.
Set-AzDataFactoryV2IntegrationRuntime -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $integrationRuntimeName -Type SelfHosted -Description "selfhosted IR description"Voici l'exemple de sortie :
Name : ADFTutorialIR Type : SelfHosted ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Description : selfhosted IR description Id : /subscriptions/<subscription ID>/resourceGroups/<resourceGroupName>/providers/Microsoft.DataFactory/factories/<dataFactoryName>/integrationruntimes/<integrationRuntimeName>Exécutez la commande suivante pour récupérer l’état du runtime d’intégration créé :
Get-AzDataFactoryV2IntegrationRuntime -name $integrationRuntimeName -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -StatusVoici l'exemple de sortie :
State : NeedRegistration Version : CreateTime : 9/10/2019 3:24:09 AM AutoUpdate : On ScheduledUpdateDate : UpdateDelayOffset : LocalTimeZoneOffset : InternalChannelEncryption : Capabilities : {} ServiceUrls : {eu.frontend.clouddatahub.net} Nodes : {} Links : {} Name : <Integration Runtime name> Type : SelfHosted ResourceGroupName : <resourceGroup name> DataFactoryName : <dataFactory name> Description : selfhosted IR description Id : /subscriptions/<subscription ID>/resourceGroups/<resourceGroupName>/providers/Microsoft.DataFactory/factories/<dataFactoryName>/integrationruntimes/<integrationRuntimeName>Exécutez la commande suivante pour récupérer les clés d’authentification permettant d’enregistrer le runtime d’intégration auto-hébergé auprès du service de fabrique de données dans le cloud. Copiez l’une des clés (sans les guillemets) pour enregistrer le runtime d’intégration auto-hébergé que vous allez installer sur votre ordinateur à l’étape suivante.
Get-AzDataFactoryV2IntegrationRuntimeKey -Name $integrationRuntimeName -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName | ConvertTo-JsonVoici l'exemple de sortie :
{ "AuthKey1": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=", "AuthKey2": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy=" }
Installer le runtime d’intégration
Téléchargez le runtime d’intégration Azure Data Factory sur un ordinateur Windows local, puis exécutez l’installation.
Sur la page Bienvenue dans l’assistant Installation de Microsoft Integration Runtime, cliquez sur Suivant.
Dans la fenêtre Contrat de licence utilisateur final, acceptez les conditions et le contrat de licence, puis cliquez sur Suivant.
Dans la fenêtre Dossier de destination, cliquez sur Suivant.
Dans la fenêtre Prêt à installer Microsoft Integration Runtime, cliquez sur Installer.
Dans l’Assistant Installation de Microsoft Integration Runtime terminé, cliquez sur Terminer.
Dans la fenêtre Inscrire Microsoft Integration Runtime (auto-hébergé) , collez la clé que vous avez enregistrée dans la section précédente, puis cliquez sur Inscrire.
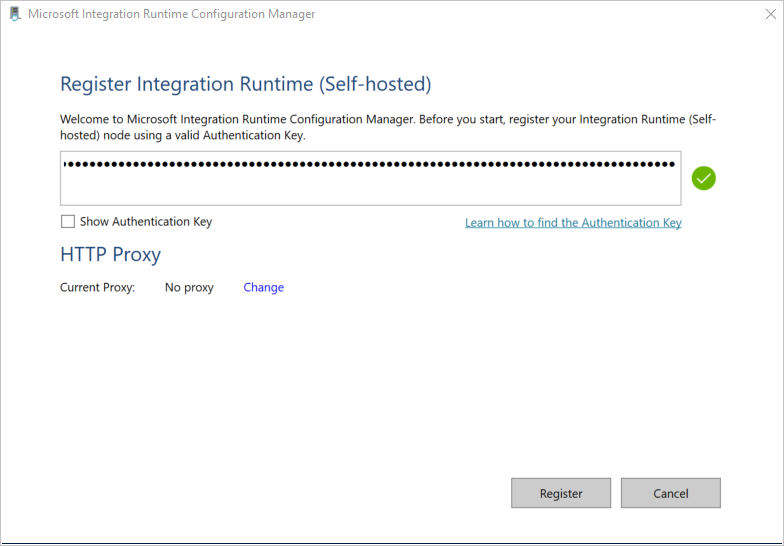
Dans la fenêtre Nouveau nœud Runtime d’intégration (autohébergé) , sélectionnez Terminer.
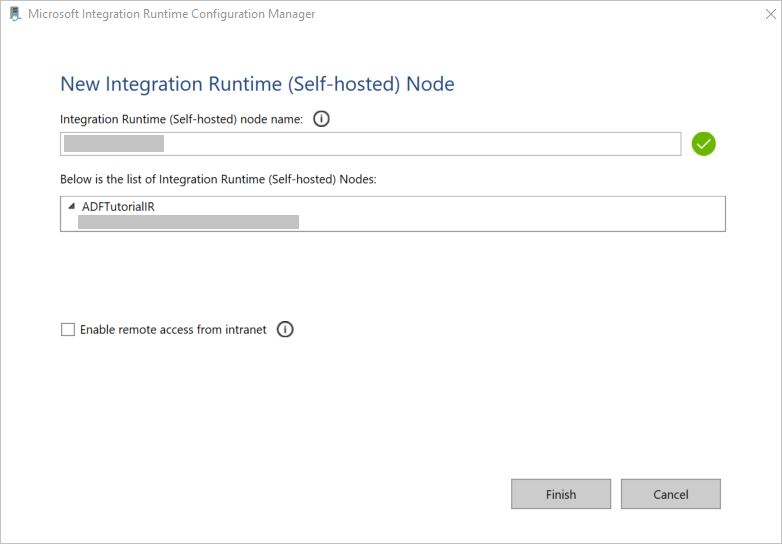
Le message suivant s’affiche une fois que le runtime d’intégration auto-hébergé est bien inscrit :
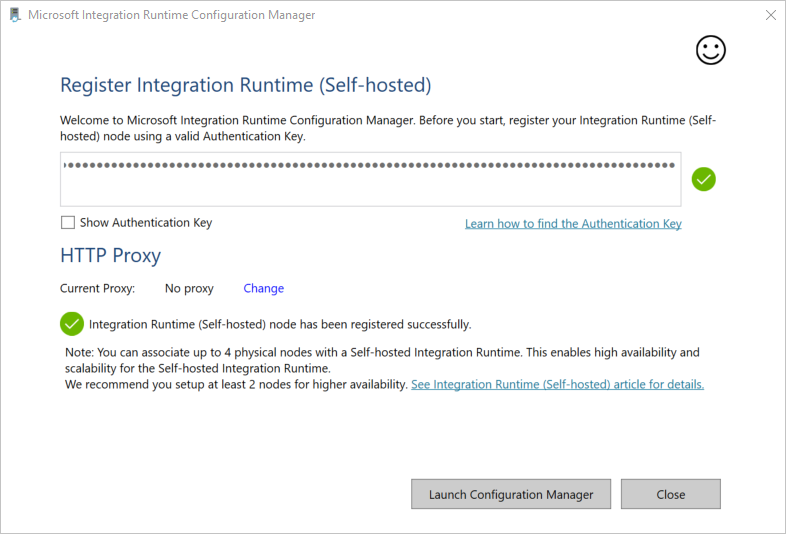
Dans la fenêtre Inscrire Microsoft Integration Runtime (auto-hébergé) , cliquez sur Lancer Configuration Manager.
Le message suivant apparaît une fois que le nœud est connecté au service cloud :
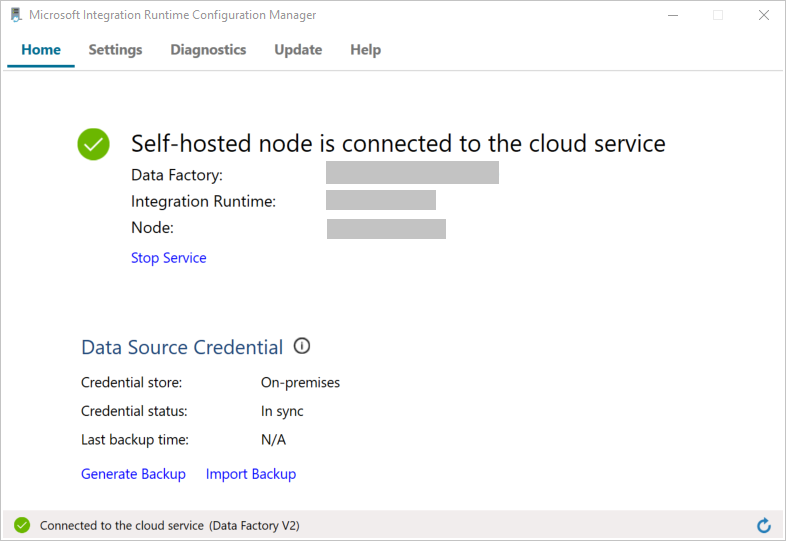
Testez la connectivité à votre base de données SQL Server en procédant comme suit :
a. Dans la fenêtre Gestionnaire de configuration, basculez vers l’onglet Diagnostics.
b. Dans la zone Type de source de données, sélectionnez SqlServer.
c. Saisissez le nom du serveur.
d. Saisissez le nom de la base de données.
e. Sélectionnez le mode d’authentification.
f. Saisissez le nom d’utilisateur.
g. Entrez le mot de passe associé au nom d’utilisateur.
h. Cliquez sur Tester pour vérifier que le runtime d’intégration se connecte à SQL Server.
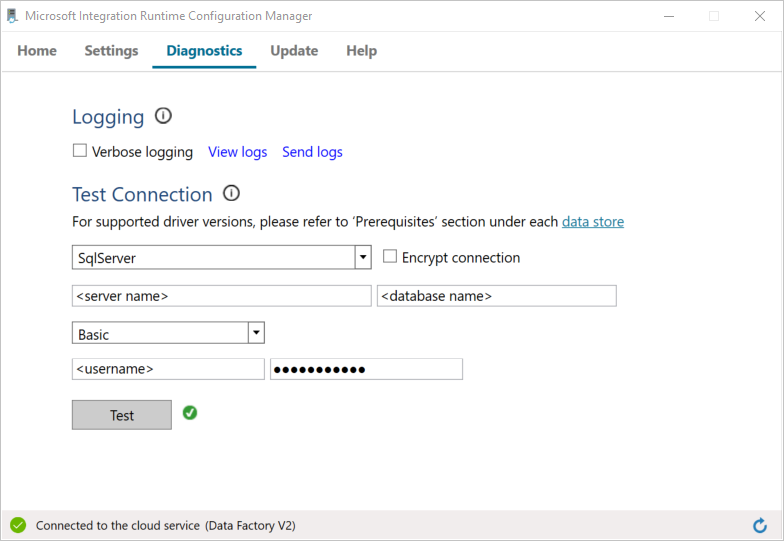
Une coche verte apparaît si la connexion est établie. Sinon, c’est un message d’erreur concernant l’échec qui apparaît. Corrigez les problèmes et assurez-vous que le runtime d’intégration peut se connecter à votre instance SQL Server.
Notez toutes les valeurs précédentes pour une utilisation ultérieure dans ce tutoriel.
Créez des services liés
Créez des services liés dans la fabrique de données pour lier vos magasins de données et vos services de calcul à la fabrique de données. Dans ce tutoriel, vous liez votre compte Stockage Azure et votre instance SQL Server au magasin de données. Les services liés comportent les informations de connexion utilisées par le service de fabrique de données lors de l’exécution pour s’y connecter.
Créer un service lié Stockage Azure (destination/réception)
Dans cette étape, vous liez votre compte Stockage Azure à la fabrique de données.
Créez un fichier JSON sous le nom AzureSqlDWLinkedService.json dans le dossier C:\ADFv2Tutorial avec le code suivant. Créez le dossier ADFv2Tutorial s’il n’existe pas déjà.
Important
Remplacez <accountName> et <accountKey> par le nom et la clé de votre compte de stockage Azure avant d’enregistrer le fichier. Vous les avez notées dans la section Conditions préalables.
{ "name": "AzureStorageLinkedService", "properties": { "annotations": [], "type": "AzureBlobStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>;EndpointSuffix=core.windows.net" } } }Dans PowerShell, accédez au dossier C:\ADFv2Tutorial.
Set-Location 'C:\ADFv2Tutorial'Exécutez l’applet de commande
Set-AzDataFactoryV2LinkedServicesuivante pour créer le service lié AzureStorageLinkedService :Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -Name "AzureStorageLinkedService" -File ".\AzureStorageLinkedService.json"Voici un exemple de sortie :
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : <resourceGroup name> DataFactoryName : <dataFactory name> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobStorageLinkedServiceSi vous recevez une erreur indiquant « fichier introuvable », vérifiez que le fichier existe en exécutant la commande
dir. Si le nom du fichier a l’extension .txt (par exemple, AzureStorageLinkedService.json.txt), supprimez-la puis exécutez la commande PowerShell à nouveau.
Créer et chiffrer un service lié SQL Server (source)
Dans cette étape, vous liez votre instance SQL Server à la fabrique de données.
Créez un fichier JSON sous le nom SqlServerLinkedService.json dans le dossier C:\ADFv2Tutorial avec le code suivant :
Important
Sélectionnez la section en fonction de l’authentification utilisée pour établir la connexion à SQL Server.
Utilisation de l’authentification SQL :
{ "name":"SqlServerLinkedService", "type":"Microsoft.DataFactory/factories/linkedservices", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=False;data source=<serverName>;initial catalog=<databaseName>;user id=<userName>;password=<password>" }, "connectVia":{ "referenceName":"<integration runtime name> ", "type":"IntegrationRuntimeReference" } } }Avec l’authentification Windows :
{ "name":"SqlServerLinkedService", "type":"Microsoft.DataFactory/factories/linkedservices", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=True;data source=<serverName>;initial catalog=<databaseName>", "userName":"<username> or <domain>\\<username>", "password":{ "type":"SecureString", "value":"<password>" } }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Important
- Sélectionnez la section en fonction de l’authentification utilisée pour établir la connexion à votre instance SQL Server.
- Remplacez <integration runtime name> par le nom de votre runtime d’intégration.
- Remplacez <servername>, <databasename>, <username> et <password> par les valeurs de votre instance SQL Server avant d’enregistrer le fichier.
- Si vous avez besoin d’utiliser une barre oblique (\) dans votre nom de serveur ou de compte d’utilisateur, faites-la précéder d’un caractère d’échappement (\). Par exemple, utilisez mydomain\\myuser.
Pour chiffrer les données sensibles (nom d’utilisateur, mot de passe etc.) exécutez l’applet de commande
New-AzDataFactoryV2LinkedServiceEncryptedCredential.
Les informations d’identification sont alors chiffrées à l’aide de l’API de protection des données (DPAPI). Les informations d’identification chiffrées sont stockées localement sur le nœud de runtime d’intégration auto-hébergé (ordinateur local). La charge utile de sortie peut être redirigée vers un autre fichier JSON (dans ce cas, encryptedLinkedService.json) qui contient les informations d’identification chiffrées.New-AzDataFactoryV2LinkedServiceEncryptedCredential -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -IntegrationRuntimeName $integrationRuntimeName -File ".\SQLServerLinkedService.json" > encryptedSQLServerLinkedService.jsonExécutez la commande suivante, qui crée EncryptedSqlServerLinkedService :
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -Name "EncryptedSqlServerLinkedService" -File ".\encryptedSqlServerLinkedService.json"
Créez les jeux de données
Dans cette étape, vous allez créer des jeux de données d’entrée et de sortie. Ils représentent les données d’entrée et de sortie pour l’opération de copie, qui copie les données depuis la base de données SQL Server vers le stockage Blob Azure.
Créer un jeu de données pour la base de données SQL Server source
Dans cette étape, vous définissez un jeu de données qui représente les données dans l’instance de la base de données SQL Server. Le jeu de données est de type SqlServerTable. Il fait référence au service lié SQL Server que vous avez créé à l’étape précédente. Le service lié comporte les informations de connexion utilisées par le service de fabrique de données pour établir la connexion à l’instance SQL Server lors de l’exécution. Ce jeu de données spécifie la table SQL dans la base de données qui contient les données. Dans ce didacticiel, c’est la table emp qui contient les données source.
Créez un fichier JSON sous le nom SqlServerDataset.json dans le dossier C:\ADFv2Tutorial avec le code suivant :
{ "name":"SqlServerDataset", "properties":{ "linkedServiceName":{ "referenceName":"EncryptedSqlServerLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"SqlServerTable", "schema":[ ], "typeProperties":{ "schema":"dbo", "table":"emp" } } }Pour créer le jeu de données SqlServerDataset, exécutez l’applet de commande
Set-AzDataFactoryV2Dataset.Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SqlServerDataset" -File ".\SqlServerDataset.json"Voici l'exemple de sortie :
DatasetName : SqlServerDataset ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerTableDataset
Créer un jeu de données pour le stockage Blob Azure (récepteur)
Dans cette étape, vous définissez un jeu de données qui représente les données devant être copiées dans le stockage Blob Azure. Le jeu de données est de type AzureBlob. Il fait référence au service lié Stockage Azure que vous avez créé précédemment dans ce didacticiel.
Le service lié comporte les informations de connexion utilisées par le service de fabrique de données lors de l’exécution pour établir la connexion à votre compte Stockage Azure. Ce jeu de données spécifie le dossier du stockage Azure dans lequel les données sont copiées à partir de la base de données SQL Server. Dans ce didacticiel, le dossier est : adftutorial/fromonprem où adftutorial est le conteneur d’objets blob et fromonprem le dossier.
Créez un fichier JSON sous le nom AzureBlobDataset.json dans le dossier C:\ADFv2Tutorial avec le code suivant :
{ "name":"AzureBlobDataset", "properties":{ "linkedServiceName":{ "referenceName":"AzureStorageLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"DelimitedText", "typeProperties":{ "location":{ "type":"AzureBlobStorageLocation", "folderPath":"fromonprem", "container":"adftutorial" }, "columnDelimiter":",", "escapeChar":"\\", "quoteChar":"\"" }, "schema":[ ] }, "type":"Microsoft.DataFactory/factories/datasets" }Pour créer le jeu de données AzureBlobDataset, exécutez l’applet de commande
Set-AzDataFactoryV2Dataset.Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureBlobDataset" -File ".\AzureBlobDataset.json"Voici l'exemple de sortie :
DatasetName : AzureBlobDataset ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.DelimitedTextDataset
Créer un pipeline
Dans ce tutoriel, vous allez créer un pipeline avec une activité de copie. L’activité de copie utilise SqlServerDataset en tant que jeu de données d’entrée et AzureBlobDataset en tant que jeu de données de sortie. Le type de source est défini sur SqlSource et le type de récepteur sur BlobSink.
Créez un fichier JSON sous le nom SqlServerToBlobPipeline.json dans le dossier C:\ADFv2Tutorial avec le code suivant :
{ "name":"SqlServerToBlobPipeline", "properties":{ "activities":[ { "name":"CopySqlServerToAzureBlobActivity", "type":"Copy", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource" }, "sink":{ "type":"DelimitedTextSink", "storeSettings":{ "type":"AzureBlobStorageWriteSettings" }, "formatSettings":{ "type":"DelimitedTextWriteSettings", "quoteAllText":true, "fileExtension":".txt" } }, "enableStaging":false }, "inputs":[ { "referenceName":"SqlServerDataset", "type":"DatasetReference" } ], "outputs":[ { "referenceName":"AzureBlobDataset", "type":"DatasetReference" } ] } ], "annotations":[ ] } }Pour créer le pipeline SqlServerToBlobPipeline, exécutez l’applet de commande
Set-AzDataFactoryV2Pipeline.Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SQLServerToBlobPipeline" -File ".\SQLServerToBlobPipeline.json"Voici l'exemple de sortie :
PipelineName : SQLServerToBlobPipeline ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Activities : {CopySqlServerToAzureBlobActivity} Parameters :
Créer une exécution du pipeline
Démarrez l’exécution du pipeline SQLServerToBlobPipeline et capturez l’ID d’exécution du pipeline pour une surveillance ultérieure.
$runId = Invoke-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineName 'SQLServerToBlobPipeline'
Surveiller l’exécution du pipeline.
Pour vérifier en permanence l’état d’exécution du pipeline SQLServerToBlobPipeline, exécutez le script suivant dans PowerShell et imprimez le résultat final :
while ($True) { $result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineRunId $runId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) if (($result | Where-Object { $_.Status -eq "InProgress" } | Measure-Object).count -ne 0) { Write-Host "Pipeline run status: In Progress" -foregroundcolor "Yellow" Start-Sleep -Seconds 30 } else { Write-Host "Pipeline 'SQLServerToBlobPipeline' run finished. Result:" -foregroundcolor "Yellow" $result break } }Voici la sortie de l’exemple d’exécution :
ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> ActivityRunId : 24af7cf6-efca-4a95-931d-067c5c921c25 ActivityName : CopySqlServerToAzureBlobActivity ActivityType : Copy PipelineRunId : 7b538846-fd4e-409c-99ef-2475329f5729 PipelineName : SQLServerToBlobPipeline Input : {source, sink, enableStaging} Output : {dataRead, dataWritten, filesWritten, sourcePeakConnections...} LinkedServiceName : ActivityRunStart : 9/11/2019 7:10:37 AM ActivityRunEnd : 9/11/2019 7:10:58 AM DurationInMs : 21094 Status : Succeeded Error : {errorCode, message, failureType, target} AdditionalProperties : {[retryAttempt, ], [iterationHash, ], [userProperties, {}], [recoveryStatus, None]...}Vous pouvez obtenir l’ID d’exécution du pipeline SQLServerToBlobPipeline, puis vérifiez le résultat détaillé de l’exécution d’activité en exécutant la commande suivante :
Write-Host "Pipeline 'SQLServerToBlobPipeline' run result:" -foregroundcolor "Yellow" ($result | Where-Object {$_.ActivityName -eq "CopySqlServerToAzureBlobActivity"}).Output.ToString()Voici la sortie de l’exemple d’exécution :
{ "dataRead":36, "dataWritten":32, "filesWritten":1, "sourcePeakConnections":1, "sinkPeakConnections":1, "rowsRead":2, "rowsCopied":2, "copyDuration":18, "throughput":0.01, "errors":[ ], "effectiveIntegrationRuntime":"ADFTutorialIR", "usedParallelCopies":1, "executionDetails":[ { "source":{ "type":"SqlServer" }, "sink":{ "type":"AzureBlobStorage", "region":"CentralUS" }, "status":"Succeeded", "start":"2019-09-11T07:10:38.2342905Z", "duration":18, "usedParallelCopies":1, "detailedDurations":{ "queuingDuration":6, "timeToFirstByte":0, "transferDuration":5 } } ] }
Vérifier la sortie
Le pipeline crée automatiquement le dossier de sortie nommé fromonprem dans le conteneur d’objets blob adftutorial. Vérifiez que le fichier dbo.emp.txt se trouve dans le dossier de sortie.
Dans le portail Azure, dans la fenêtre du conteneur adftutorial, cliquez sur Actualiser pour afficher le dossier de sortie.
Sélectionnez
fromonpremdans la liste des dossiers.Vérifiez que le fichier nommé
dbo.emp.txts’affiche.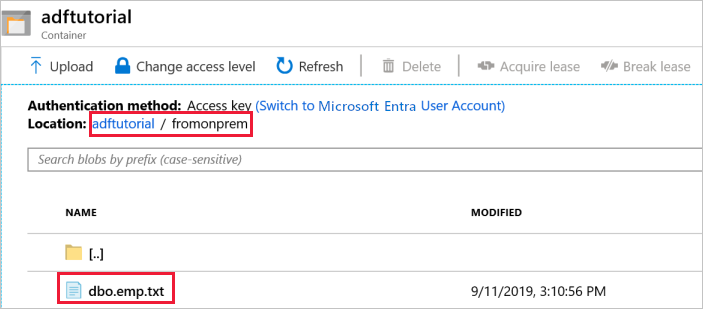
Contenu connexe
Dans cet exemple, le pipeline copie les données d’un emplacement vers un autre dans un stockage Blob Azure. Vous avez appris à :
- Créer une fabrique de données.
- Créez un runtime d’intégration auto-hébergé.
- Créer des services liés SQL Server et au Stockage Azure.
- Créer des jeux de données SQL Server et Blob Azure.
- Créer un pipeline avec une activité de copie pour déplacer les données.
- Démarrer une exécution de pipeline.
- Surveiller l’exécution du pipeline.
Pour obtenir la liste des magasins de données pris en charge par Data Factory, consultez l’article Magasins de données pris en charge.
Passez au tutoriel suivant pour découvrir comment copier des données en bloc d’une source vers une destination :