Didacticiel : Utiliser Azure Cache pour Redis comme cache sémantique
Dans ce didacticiel, vous utiliserez Azure Cache pour Redis comme cache sémantique avec un grand modèle de langage (LLM) basé sur l’IA. Vous utiliserez Azure OpenAI Service pour générer des réponses LLM aux requêtes et mettre en cache ces réponses à l’aide d’Azure Cache pour Redis, fournissant des réponses plus rapides et réduisant les coûts.
Étant donné qu’Azure Cache pour Redis fournit une fonctionnalité de recherche vectorielle intégrée, vous pouvez également effectuer une mise en cache sémantique. Vous pouvez retourner des réponses mises en cache pour des requêtes identiques, ainsi que des requêtes similaires, même si le texte n’est pas le même.
Dans ce tutoriel, vous allez apprendre à :
- Créer une instance Azure Cache pour Redis configurée pour la mise en cache sémantique
- Utilisez LangChain et d’autres bibliothèques Python populaires.
- Utilisez le service Azure OpenAI pour générer du texte à partir de modèles IA et de résultats mis en cache.
- Consultez les gains de performances de l’utilisation de la mise en cache à l’aide de LLM.
Important
Ce didacticiel vous guide tout au long de la création d’un Jupyter Notebook. Vous pouvez suivre ce didacticiel avec un fichier de code Python (.py) et obtenir des résultats similaires, mais vous devez ajouter tous les blocs de code de ce didacticiel dans le fichier .py et exécuter une fois pour afficher les résultats. En d’autres termes, Jupyter Notebooks fournit des résultats intermédiaires lorsque vous exécutez des cellules, mais ce n’est pas un comportement à attendre lorsque vous travaillez dans un fichier de code Python.
Important
Si vous souhaitez effectuer un suivi dans un notebook Jupyter terminé à la place, téléchargez le fichier de notebook Jupyter nommé semanticcache.ipynb et enregistrez-le dans le nouveau dossier semanticcache.
Prérequis
Un abonnement Azure - En créer un gratuitement
Accès accordé à Azure OpenAI dans l’abonnement Azure souhaité. Actuellement, vous devez demander l’accès à Azure OpenAI. Vous pouvez demander l’accès à Azure OpenAI en complétant le formulaire à l’adresse https://aka.ms/oai/access.
Jupyter Notebooks (facultatif)
Ressource Azure OpenAI avec les modèles text-embedding-ada-002 (version 2) et gpt-35-turbo-instruct déployés. Ces modèles sont actuellement disponibles uniquement dans certaines régions. Consultez le guide de déploiement des ressources pour obtenir des instructions sur le déploiement des modèles.
Créer une instance Cache Redis Azure
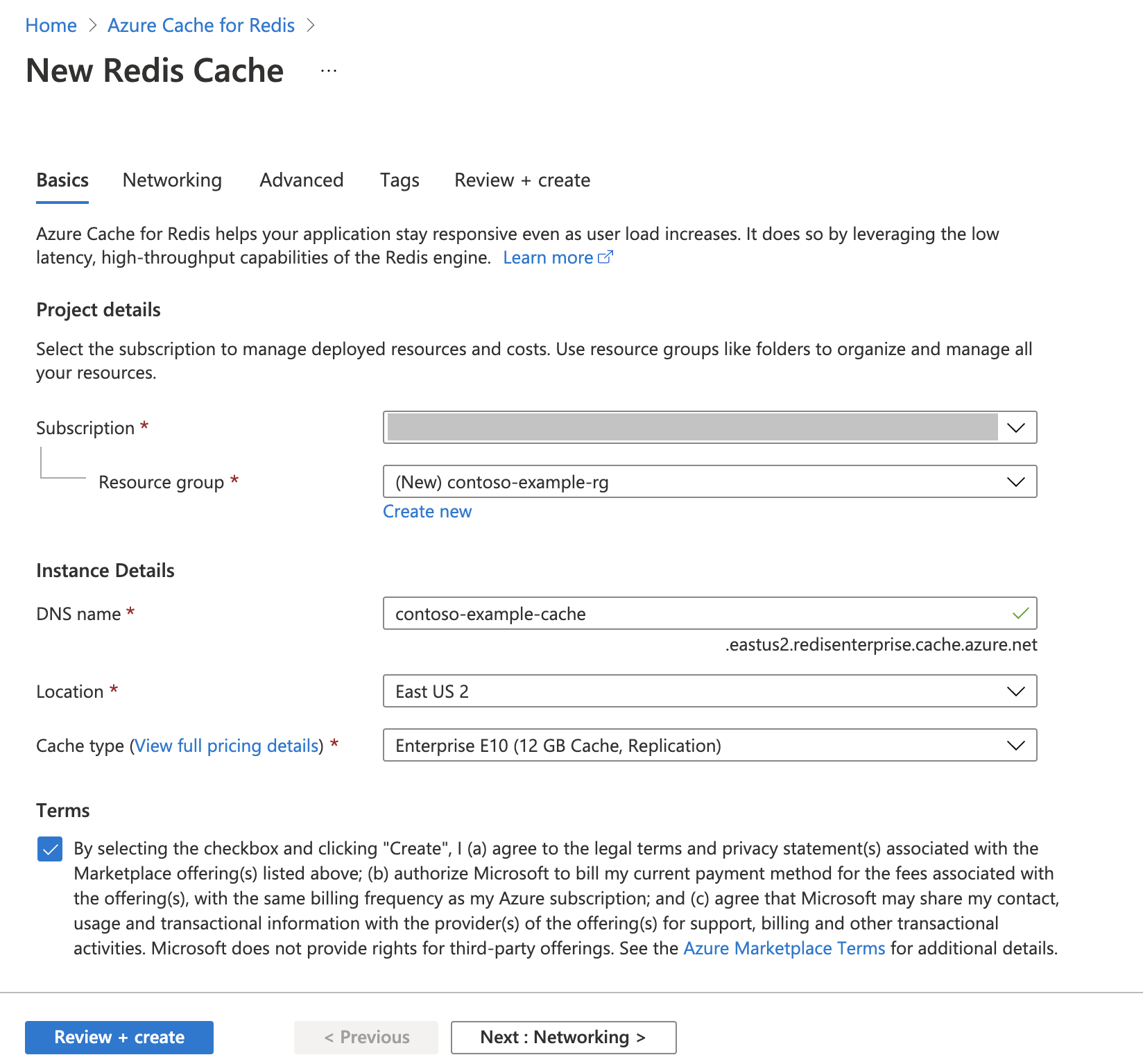
Suivez le guide de démarrage rapide : Créer un cache Redis Enterprise. Dans la page Avancé, vérifiez que vous avez ajouté le module RediSearch et que vous choisissez la stratégie de cluster d’entreprise. Tous les autres paramètres peuvent correspondre à la valeur par défaut décrite dans le démarrage rapide.
La création du cache nécessite que quelques minutes. Vous pouvez passer à l’étape suivante dans l’intervalle.
Configurer votre environnement de développement
Créez un dossier sur votre ordinateur local nommé semanticcache à l’emplacement où vous enregistrez généralement vos projets.
Créez un fichier Python (tutorial.py) ou un notebook Jupyter (tutorial.ipynb) dans le dossier.
Installez les packages Python requis :
pip install openai langchain redis tiktoken
Créer des modèles Azure OpenAI
Vérifiez que vous disposez de deux modèles déployés sur votre ressource Azure OpenAI :
LLM qui fournit des réponses de texte. Pour ce didacticiel, nous utilisons le modèle GPT-3.5-turbo-instruct.
Modèle d’incorporation qui convertit les requêtes en vecteurs pour les comparer aux requêtes passées. Pour ce didacticiel, nous utilisons le modèle text-embedding-ada-002 (version 2).
Pour obtenir des instructions plus détaillées, consultez Déployer un modèle. Enregistrez le nom que vous avez choisi pour chaque déploiement de modèle.
Importez des bibliothèques et configurez les informations de connexion
Pour effectuer correctement un appel sur Azure OpenAI, vous avez besoin d’un point de terminaison et d’une clé. Vous avez également besoin d’un point de terminaison et d’une clé pour vous connecter à Azure Cache pour Redis.
Accédez à votre ressource Azure OpenAI dans le portail Azure.
Recherchez Point de terminaison et clés dans la section Gestion des ressources de votre ressource Azure OpenAI. Copiez votre point de terminaison et votre clé d’accès, car vous avez besoin de l’authentification de vos appels d’API. Voici un exemple de point de terminaison :
https://docs-test-001.openai.azure.com. Vous pouvez utiliser soitKEY1, soitKEY2.Accédez à la page Vue d’ensemble de votre ressource Azure Cache pour Redis dans le Portail Azure. Copiez votre point de terminaison.
Localisez Clés d’accès dans la section Paramètres. Copiez votre clé d’accès. Vous pouvez utiliser soit
Primary, soitSecondary.Ajoutez le code suivant à une nouvelle cellule de code :
# Code cell 2 import openai import redis import os import langchain from langchain.llms import AzureOpenAI from langchain.embeddings import AzureOpenAIEmbeddings from langchain.globals import set_llm_cache from langchain.cache import RedisSemanticCache import time AZURE_ENDPOINT=<your-openai-endpoint> API_KEY=<your-openai-key> API_VERSION="2023-05-15" LLM_DEPLOYMENT_NAME=<your-llm-model-name> LLM_MODEL_NAME="gpt-35-turbo-instruct" EMBEDDINGS_DEPLOYMENT_NAME=<your-embeddings-model-name> EMBEDDINGS_MODEL_NAME="text-embedding-ada-002" REDIS_ENDPOINT = <your-redis-endpoint> REDIS_PASSWORD = <your-redis-password>Mettez à jour la valeur de
API_KEYetRESOURCE_ENDPOINTavec les valeurs de clé et de point de terminaison de votre déploiement Azure OpenAI.Définissez
LLM_DEPLOYMENT_NAMEetEMBEDDINGS_DEPLOYMENT_NAMEsur le nom de vos deux modèles déployés dans Azure OpenAI Service.Mettez à jour
REDIS_ENDPOINTetREDIS_PASSWORDavec la valeur de point de terminaison et de clé de votre instance Azure Cache pour Redis.Important
Nous vous recommandons vivement d’utiliser des variables d’environnement ou un gestionnaire de secrets comme Azure Key Vault pour transmettre les informations sur la clé API, le point de terminaison et le nom de déploiement. Ces variables sont définies en texte en clair ici par souci de simplicité.
Exécutez la cellule de code 2.
Initialiser des modèles IA
Ensuite, vous initialisez les modèles LLM et d’incorporations.
Ajoutez le code suivant à une nouvelle cellule de code :
# Code cell 3 llm = AzureOpenAI( deployment_name=LLM_DEPLOYMENT_NAME, model_name="gpt-35-turbo-instruct", openai_api_key=API_KEY, azure_endpoint=AZURE_ENDPOINT, openai_api_version=API_VERSION, ) embeddings = AzureOpenAIEmbeddings( azure_deployment=EMBEDDINGS_DEPLOYMENT_NAME, model="text-embedding-ada-002", openai_api_key=API_KEY, azure_endpoint=AZURE_ENDPOINT, openai_api_version=API_VERSION )Exécutez la cellule de code 3.
Configurer Redis en tant que cache sémantique
Ensuite, spécifiez Redis comme cache sémantique pour votre LLM.
Ajoutez le code suivant à une nouvelle cellule de code :
# Code cell 4 redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT set_llm_cache(RedisSemanticCache(redis_url = redis_url, embedding=embeddings, score_threshold=0.05))Important
La valeur du paramètre
score_thresholddétermine la façon dont deux requêtes similaires doivent être afin de retourner un résultat mis en cache. Plus le nombre est faible, plus les requêtes doivent être similaires. Vous pouvez ajuster cette valeur en fonction de votre application.Exécutez la cellule de code 4.
Interroger et obtenir des réponses à partir du LLM
Enfin, interrogez le LLM pour obtenir une réponse générée par l’IA. Si vous utilisez un notebook Jupyter, vous pouvez ajouter %%time en haut de la cellule pour générer le temps nécessaire pour exécuter le code.
Ajoutez le code suivant à une nouvelle cellule de code et exécutez-le :
# Code cell 5 %%time response = llm("Please write a poem about cute kittens.") print(response)Vous devez voir une sortie similaire à la suivante :
Fluffy balls of fur, With eyes so bright and pure, Kittens are a true delight, Bringing joy into our sight. With tiny paws and playful hearts, They chase and pounce, a work of art, Their innocence and curiosity, Fills our hearts with such serenity. Their soft meows and gentle purrs, Are like music to our ears, They curl up in our laps, And take the stress away in a snap. Their whiskers twitch, they're always ready, To explore and be adventurous and steady, With their tails held high, They're a sight to make us sigh. Their tiny faces, oh so sweet, With button noses and paw-sized feet, They're the epitome of cuteness, ... Cute kittens, a true blessing, In our hearts, they'll always be reigning. CPU times: total: 0 ns Wall time: 2.67 sLa valeur
Wall timeindique 2,67 secondes. Cela correspond au temps réel nécessaire pour interroger le LLM et pour que le LLM génère une réponse.Réexécutez la cellule 5. Vous devez voir exactement la même sortie, mais avec une valeur Wall time plus basse :
Fluffy balls of fur, With eyes so bright and pure, Kittens are a true delight, Bringing joy into our sight. With tiny paws and playful hearts, They chase and pounce, a work of art, Their innocence and curiosity, Fills our hearts with such serenity. Their soft meows and gentle purrs, Are like music to our ears, They curl up in our laps, And take the stress away in a snap. Their whiskers twitch, they're always ready, To explore and be adventurous and steady, With their tails held high, They're a sight to make us sigh. Their tiny faces, oh so sweet, With button noses and paw-sized feet, They're the epitome of cuteness, ... Cute kittens, a true blessing, In our hearts, they'll always be reigning. CPU times: total: 0 ns Wall time: 575 msLa valeur Wall time semble raccourcir d’un facteur de cinq, soit jusqu’à 575 millisecondes.
Modifiez la requête
Please write a poem about cute kittenspourWrite a poem about cute kittens, puis réexécutez la cellule 5. Vous devez voir exactement la même sortie et une valeur Wall time inférieure à la requête d’origine. Même si la requête a changé, la signification sémantique de la requête est restée la même, de sorte que la même sortie mise en cache a été retournée. C’est l’avantage de la mise en cache sémantique !
Modifier le seuil de similarité
Essayez d’exécuter une requête similaire avec une signification différente, comme
Please write a poem about cute puppies. Notez que le résultat mis en cache est également retourné ici. La signification sémantique du motpuppiesest assez proche du motkittensretourné par le résultat mis en cache.Le seuil de similarité peut être modifié pour déterminer quand le cache sémantique doit retourner un résultat mis en cache et quand il doit retourner une nouvelle sortie à partir du LLM. Dans la cellule de code 4, remplacez la valeur
score_thresholdde0.05par0.01:# Code cell 4 redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT set_llm_cache(RedisSemanticCache(redis_url = redis_url, embedding=embeddings, score_threshold=0.01))Essayez à nouveau la requête
Please write a poem about cute puppies. Vous devez recevoir une nouvelle sortie spécifique aux chiots :Oh, little balls of fluff and fur With wagging tails and tiny paws Puppies, oh puppies, so pure The epitome of cuteness, no flaws With big round eyes that melt our hearts And floppy ears that bounce with glee Their playful antics, like works of art They bring joy to all they see Their soft, warm bodies, so cuddly As they curl up in our laps Their gentle kisses, so lovingly Like tiny, wet, puppy taps Their clumsy steps and wobbly walks As they explore the world anew Their curiosity, like a ticking clock Always eager to learn and pursue Their little barks and yips so sweet Fill our days with endless delight Their unconditional love, so complete ... For they bring us love and laughter, year after year Our cute little pups, in every way. CPU times: total: 15.6 ms Wall time: 4.3 sVous devrez probablement affiner le seuil de similarité en fonction de votre application pour vous assurer que la sensibilité appropriée est utilisée lors de la détermination des requêtes à mettre en cache.
Nettoyer les ressources
Si vous souhaitez continuer à utiliser les ressources que vous avez créées dans cet article, conservez le groupe de ressources.
Sinon, si vous avez terminé avec les ressources, vous pouvez supprimer le groupe de ressources Azure que vous avez créé pour éviter les frais.
Important
La suppression d’un groupe de ressources est irréversible. Quand vous supprimez un groupe de ressources, toutes les ressources qu’il contient sont supprimées définitivement. Veillez à ne pas supprimer accidentellement des ressources ou un groupe de ressources incorrects. Si vous avez créé les ressources dans un groupe de ressources existant contenant des ressources que vous souhaitez conserver, vous pouvez supprimer chaque ressource individuellement, au lieu de supprimer l’intégralité du groupe de ressources.
Pour supprimer un groupe de ressources
Connectez-vous au Portail Azure, puis sélectionnez Groupes de ressources.
Recherchez le groupe de ressources à supprimer.
S’il existe de nombreux groupes de ressources, utilisez la zone Filtrer pour n’importe quel champ..., tapez le nom du groupe de ressources que vous avez créé pour cet article. Sélectionnez le groupe de ressources dans la liste des résultats.
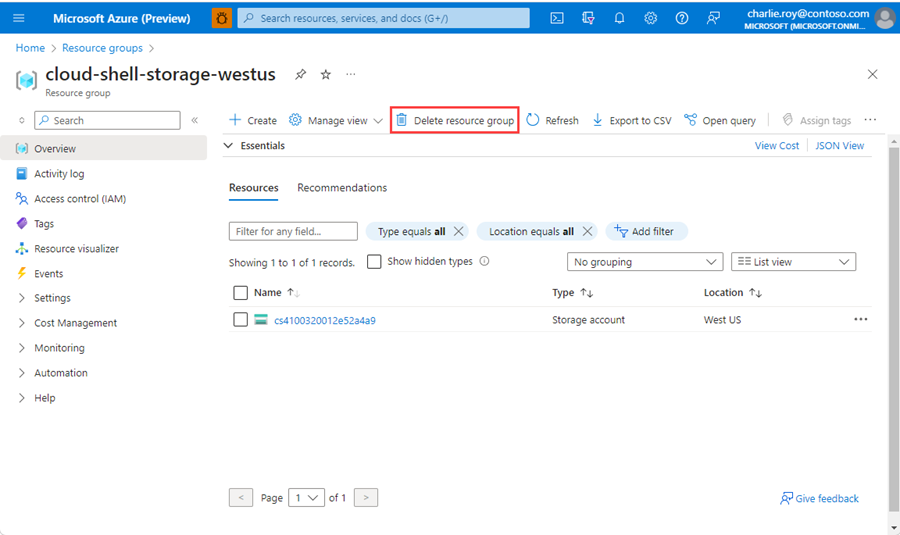
Sélectionnez Supprimer le groupe de ressources.
Vous êtes invité à confirmer la suppression du groupe de ressources. Saisissez le nom de votre groupe de ressources pour confirmer, puis sélectionnez Supprimer.
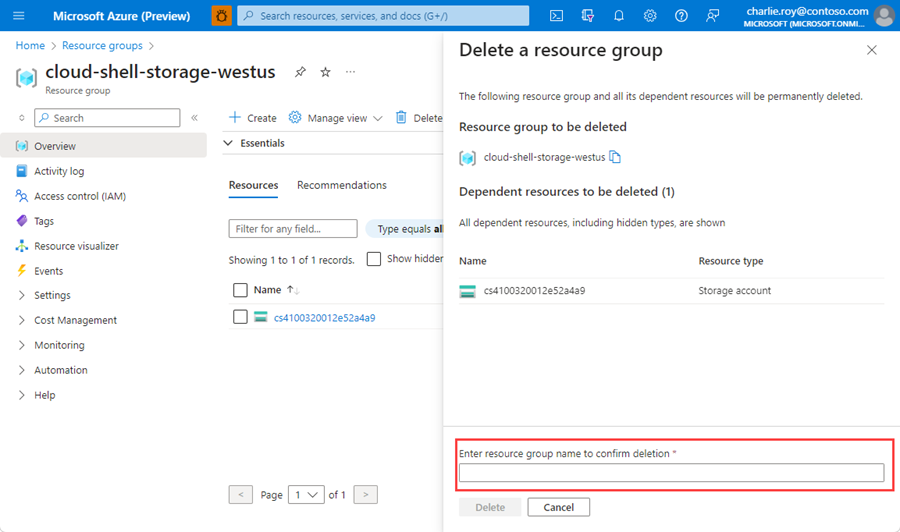
Après quelques instants, le groupe de ressources et toutes ses ressources sont supprimés.
Contenu connexe
- En savoir plus sur Azure Cache pour Redis
- En savoir plus sur les fonctionnalités de recherche vectorielle Azure Cache pour Redis
- Didacticiel : Utiliser la recherche de similarité vectorielle sur Azure Cache pour Redis
- Découvrez comment créer une application basée sur l’IA avec OpenAI et Redis
- Créer une application Q&A avec des réponses sémantiques