Tutoriel : effectuer une recherche de similarité vectorielle sur les incorporations Azure OpenAI à l’aide de Azure Cache pour Redis
Dans ce tutoriel, vous découvrirez un cas d'utilisation basique de la recherche de similarité vectorielle. Vous utiliserez les incorporations générées par Azure OpenAI Service et les capacités de recherche vectorielle intégrées du niveau Enterprise de Azure Cache pour Redis pour interroger un jeu de données de films afin de trouver la correspondance la plus pertinente.
Le tutoriel utilise le jeu de données Wikipédia Movie Plots qui contient des descriptions de plus de 35 000 films de Wikipédia couvrant les années 1901 à 2017. Le jeu de données comprend un résumé de l'intrigue pour chaque film, ainsi que des métadonnées telles que l'année de sortie du film, le ou les réalisateurs, les principaux acteurs et le genre. Vous suivrez les étapes du tutoriel pour générer des incorporations basées sur le résumé de l'intrigue et utiliser les autres métadonnées pour exécuter des requêtes hybrides.
Dans ce tutoriel, vous allez apprendre à :
- Créer une instance Azure Cache pour Redis configurée pour la recherche vectorielle
- Installez Azure OpenAI et d’autres bibliothèques Python requises.
- Téléchargez le jeu de données du film et préparez-le pour l’analyse.
- Utilisez le modèle text-embedding-ada-002 (version 2) pour générer des incorporations.
- Créez un index vectoriel dans Azure Cache pour Redis
- Utilisez la similarité cosinus pour classer les résultats de la recherche.
- Utilisez la fonctionnalité de requête hybride via RediSearch pour pré-filtrer les données et rendre la recherche vectorielle encore plus puissante.
Important
Ce tutoriel vous guide tout au long de la création d’un Jupyter Notebook. Vous pouvez suivre ce tutoriel avec un fichier de code Python (.py) et obtenir des résultats similaires, mais vous devez ajouter tous les blocs de code de ce tutoriel dans le fichier .py et exécuter une fois pour afficher les résultats. En d’autres termes, Jupyter Notebooks fournit des résultats intermédiaires lorsque vous exécutez des cellules, mais ce n’est pas un comportement à attendre lorsque vous travaillez dans un fichier de code Python.
Important
Si vous souhaitez suivre dans un notebook Jupyter terminé à la place, téléchargez le fichier de notebook Jupyter nommé tutorial.ipynb et enregistrez-le dans le nouveau dossier redis-vector.
Prérequis
- Un abonnement Azure - En créer un gratuitement
- Accès accordé à Azure OpenAI dans l’abonnement Azure souhaité. Actuellement, vous devez demander l’accès à Azure OpenAI. Vous pouvez demander l’accès à Azure OpenAI en complétant le formulaire à l’adresse https://aka.ms/oai/access.
- Python version 3.7.1 ou ultérieure
- Jupyter Notebooks (facultatif)
- Une ressource Azure OpenAI avec le modèle text-embedding-ada-002 (version 2) déployé. Ce modèle n’est actuellement disponible que dans certaines régions. Consultez le guide de déploiement des ressources pour obtenir des instructions sur le déploiement du modèle.
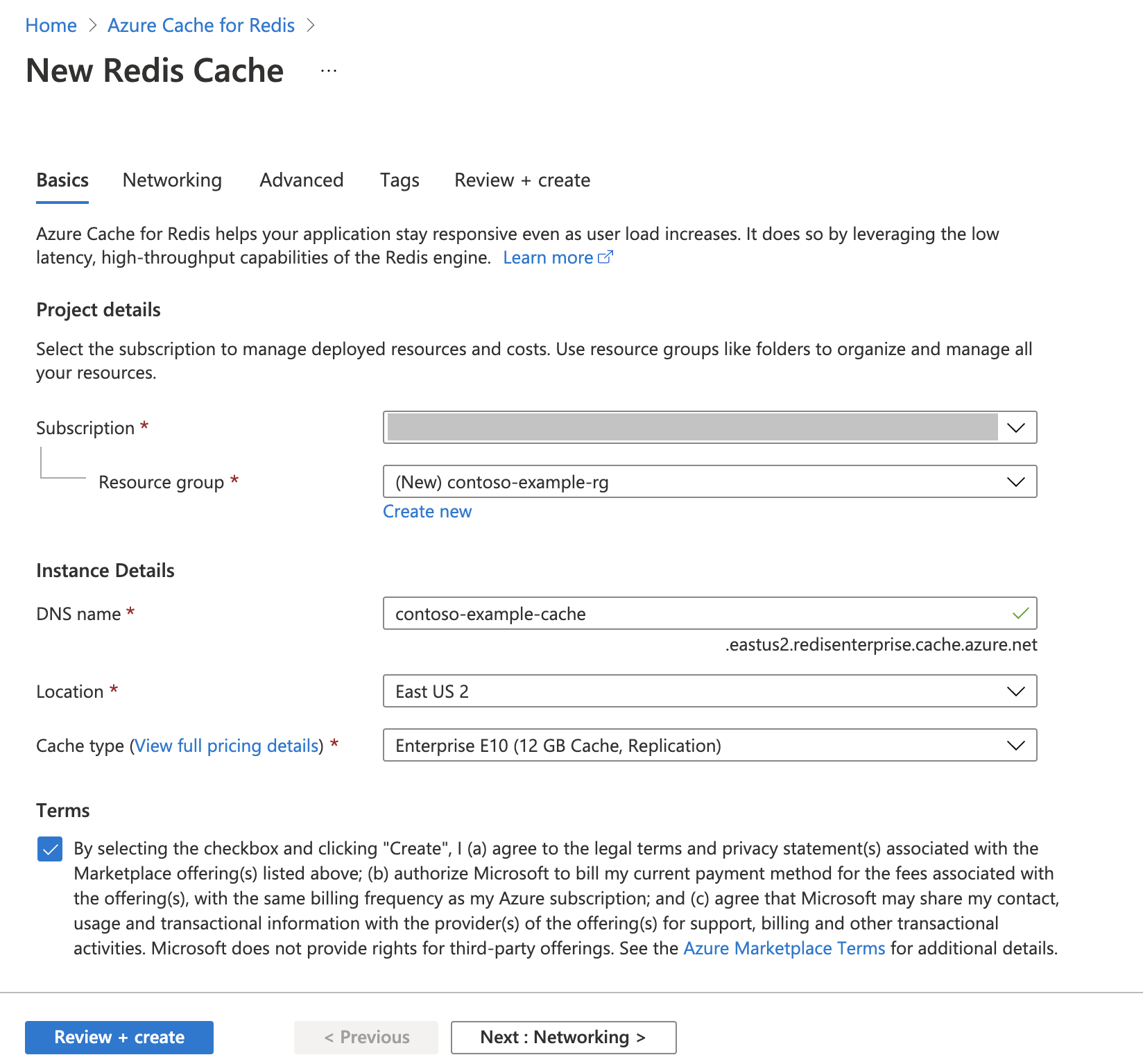
Créez une instance Azure Cache pour Redis
Suivez le guide de démarrage rapide : Créer un cache Redis Enterprise. Dans la page Avancé, vérifiez que vous avez ajouté le module RediSearch et que vous avez choisi la stratégie de cluster d’entreprise. Tous les autres paramètres peuvent correspondre à la valeur par défaut décrite dans le démarrage rapide.
La création du cache nécessite que quelques minutes. Vous pouvez passer à l’étape suivante dans l’intervalle.
Configurer votre environnement de développement
Créez un dossier sur votre ordinateur local nommé redis-vector à l’emplacement où vous enregistrez généralement vos projets.
Créez un fichier Python (tutorial.py) ou un notebook Jupyter (tutorial.ipynb) dans le dossier.
Installez les packages Python requis :
pip install "openai==1.6.1" num2words matplotlib plotly scipy scikit-learn pandas tiktoken redis langchain
Télécharger le jeu de données
Dans un navigateur web, accédez à https://www.kaggle.com/datasets/jrobischon/wikipedia-movie-plots.
Connectez-vous ou inscrivez-vous avec Kaggle. L’inscription est nécessaire pour télécharger le fichier.
Sélectionnez le lien Télécharger sur Kaggle pour télécharger le fichier archive.zip.
Extrayez le fichier archive.zip et déplacez le wiki_movie_plots_deduped.csv dans le dossier redis-vector.
Importez des bibliothèques et configurez les informations de connexion
Pour effectuer correctement un appel sur Azure OpenAI, vous avez besoin d’un point de terminaison et d’une clé. Vous avez également besoin d’un point de terminaison et d’une clé pour vous connecter à Azure Cache pour Redis.
Accédez à votre ressource Azure OpenAI dans le portail Azure.
Localisez le Point de terminaison et les Clés dans la section Gestion des ressources. Copiez votre point de terminaison et votre clé d’accès, car vous aurez besoin de l’authentification de vos appels d’API. Voici un exemple de point de terminaison :
https://docs-test-001.openai.azure.com. Vous pouvez utiliser soitKEY1, soitKEY2.Accédez à la page Vue d’ensemble de votre ressource Azure Cache pour Redis dans le Portail Azure. Copiez votre point de terminaison.
Localisez Clés d’accès dans la section Paramètres. Copiez votre clé d’accès. Vous pouvez utiliser soit
Primary, soitSecondary.Ajoutez le code suivant à une nouvelle cellule de code :
# Code cell 2 import re from num2words import num2words import os import pandas as pd import tiktoken from typing import List from langchain.embeddings import AzureOpenAIEmbeddings from langchain.vectorstores.redis import Redis as RedisVectorStore from langchain.document_loaders import DataFrameLoader API_KEY = "<your-azure-openai-key>" RESOURCE_ENDPOINT = "<your-azure-openai-endpoint>" DEPLOYMENT_NAME = "<name-of-your-model-deployment>" MODEL_NAME = "text-embedding-ada-002" REDIS_ENDPOINT = "<your-azure-redis-endpoint>" REDIS_PASSWORD = "<your-azure-redis-password>"Mettez à jour la valeur de
API_KEYetRESOURCE_ENDPOINTavec les valeurs de clé et de point de terminaison de votre déploiement Azure OpenAI.DEPLOYMENT_NAMEdoit être défini sur le nom de votre déploiement à l’aide du modèle d’incorporationstext-embedding-ada-002 (Version 2)etMODEL_NAMEdoit être le modèle d’incorporations spécifique utilisé.Mettez à jour
REDIS_ENDPOINTetREDIS_PASSWORDavec la valeur de point de terminaison et de clé de votre instance Azure Cache pour Redis.Important
Nous vous recommandons vivement d’utiliser des variables d’environnement ou un gestionnaire de secrets comme Azure Key Vault pour transmettre les informations sur la clé API, le point de terminaison et le nom de déploiement. Ces variables sont définies en texte en clair ici par souci de simplicité.
Exécutez la cellule de code 2.
Importez un jeu de données dans pandas et traitez des données
Ensuite, vous allez lire le fichier csv dans un DataFrame pandas.
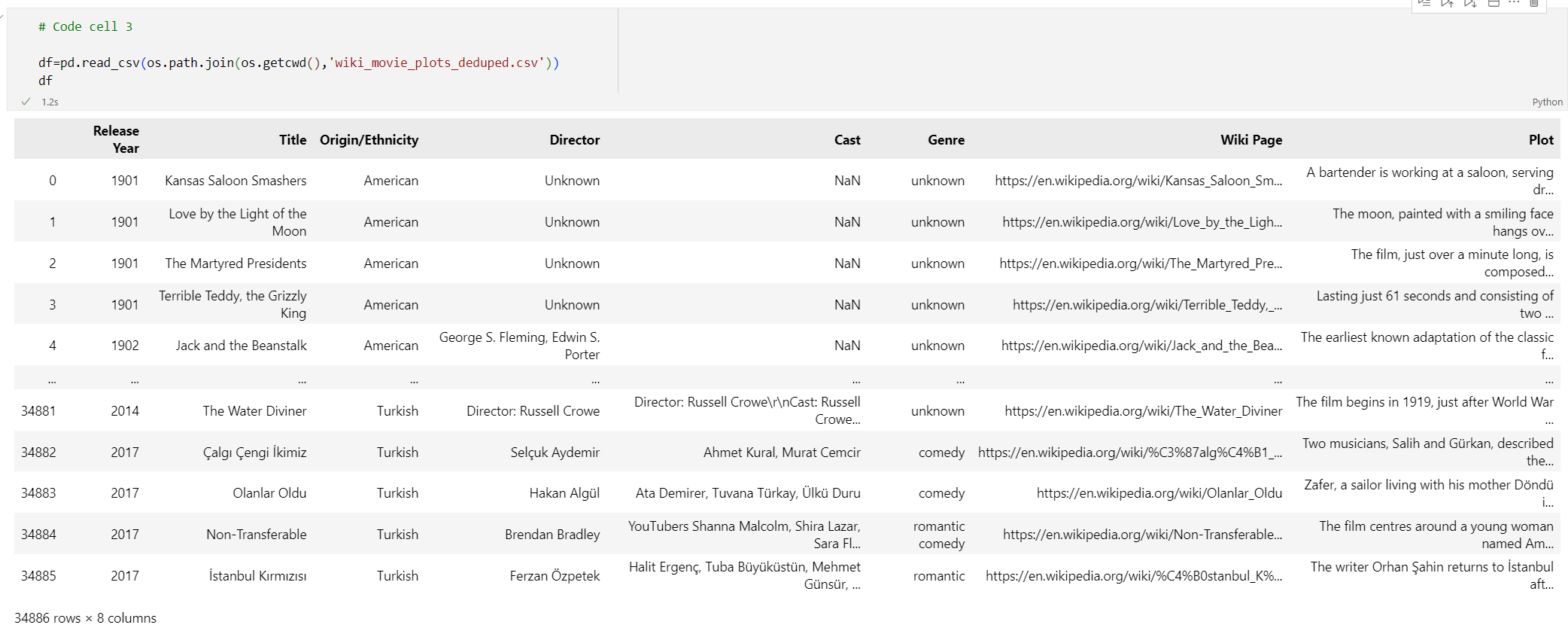
Ajoutez le code suivant à une nouvelle cellule de code :
# Code cell 3 df=pd.read_csv(os.path.join(os.getcwd(),'wiki_movie_plots_deduped.csv')) dfExécutez la cellule de code 3. Vous devez normalement voir la sortie suivante :
Ensuite, traitez les données en ajoutant un index
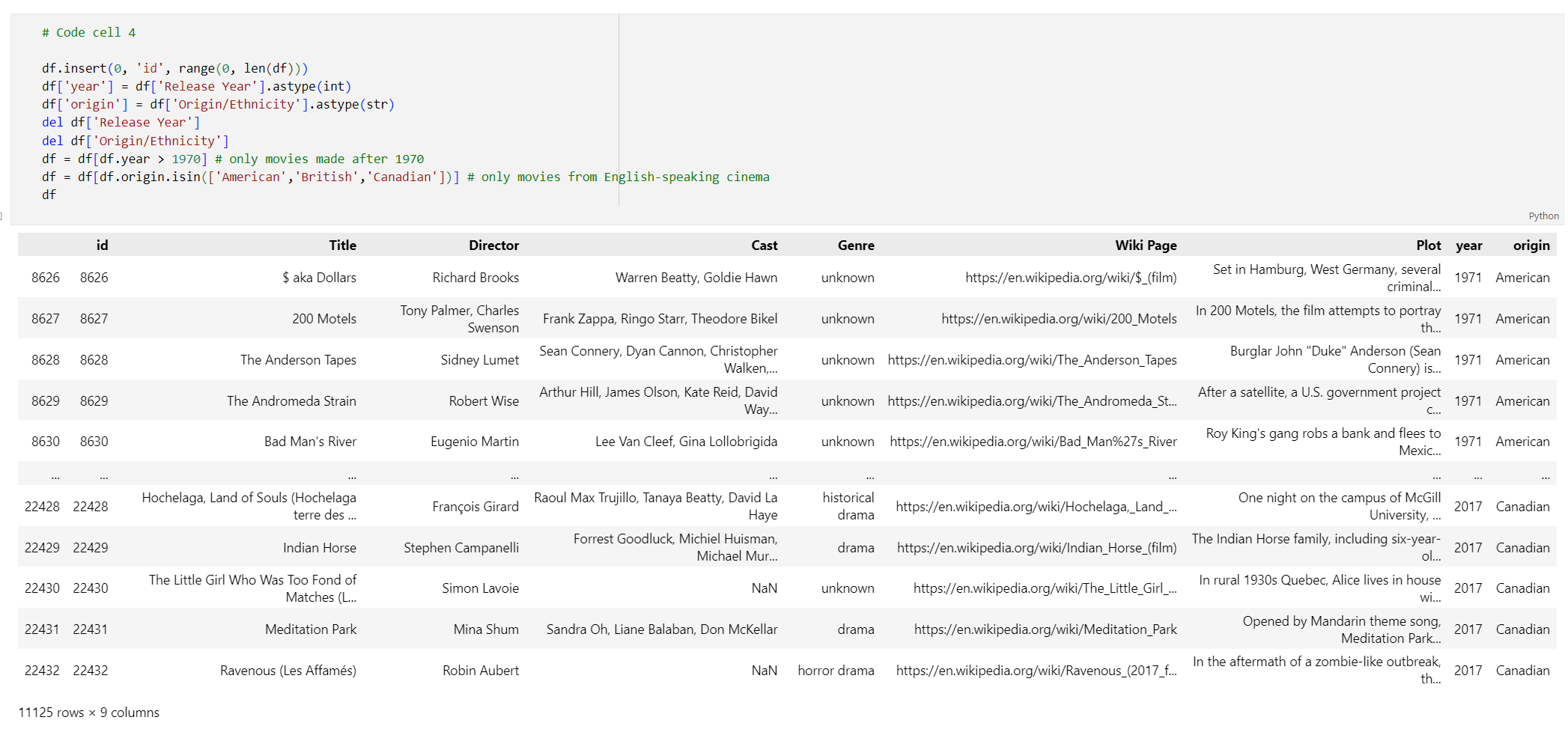
id, en supprimant les espaces des titres des colonnes et en filtrant les films pour ne prendre que les films réalisés après 1970 et dans des pays ou régions anglophones. Cette étape de filtrage réduit le nombre de films dans le jeu de données, ce qui réduit le coût et le temps requis pour générer des incorporations. Vous êtes libre de modifier ou de supprimer les paramètres de filtre en fonction de vos préférences.Pour filtrer les données, ajoutez le code suivant à une nouvelle cellule de code :
# Code cell 4 df.insert(0, 'id', range(0, len(df))) df['year'] = df['Release Year'].astype(int) df['origin'] = df['Origin/Ethnicity'].astype(str) del df['Release Year'] del df['Origin/Ethnicity'] df = df[df.year > 1970] # only movies made after 1970 df = df[df.origin.isin(['American','British','Canadian'])] # only movies from English-speaking cinema dfExécutez la cellule de code 4. Les résultats suivants doivent s’afficher :
Créez une fonction pour propre les données en supprimant les espaces blancs et la ponctuation, puis utilisez-la sur la trame de données contenant le tracé.
Ajoutez le code suivant à une nouvelle cellule de code et exécutez-le :
# Code cell 5 pd.options.mode.chained_assignment = None # s is input text def normalize_text(s, sep_token = " \n "): s = re.sub(r'\s+', ' ', s).strip() s = re.sub(r". ,","",s) # remove all instances of multiple spaces s = s.replace("..",".") s = s.replace(". .",".") s = s.replace("\n", "") s = s.strip() return s df['Plot']= df['Plot'].apply(lambda x : normalize_text(x))Enfin, supprimez toutes les entrées qui contiennent des descriptions de tracé trop longues pour le modèle d’incorporations. (En d’autres termes, ils nécessitent plus de jetons que la limite de 8192 jetons.) puis calculez le nombre de jetons requis pour générer des incorporations. Cela a également un impact sur la tarification de la génération d’incorporation.
Ajoutez le code suivant à une nouvelle cellule de code :
# Code cell 6 tokenizer = tiktoken.get_encoding("cl100k_base") df['n_tokens'] = df["Plot"].apply(lambda x: len(tokenizer.encode(x))) df = df[df.n_tokens<8192] print('Number of movies: ' + str(len(df))) print('Number of tokens required:' + str(df['n_tokens'].sum()))Exécutez la cellule de code 6. Cette sortie doit s’afficher :
Number of movies: 11125 Number of tokens required:7044844Important
Pour calculer le coût de génération des incorporations en fonction du nombre de jetons requis, reportez-vous à la tarification d’Azure OpenAI Service.


Charger DataFrame dans LangChain
Chargez le DataFrame dans LangChain à l’aide de la classe DataFrameLoader. Une fois les données contenues dans des documents LangChain, il est beaucoup plus facile d’utiliser les bibliothèques LangChain pour générer des incorporations et effectuer des recherches de similarité. Définissez Intrigue comme le page_content_column afin que les incorporations soient générées sur cette colonne.
Ajoutez le code suivant à une nouvelle cellule de code et exécutez-le :
# Code cell 7 loader = DataFrameLoader(df, page_content_column="Plot" ) movie_list = loader.load()
Générez des incorporations et les charger dans Redis
Maintenant que les données ont été filtrées et chargées dans LangChain, vous allez créer des incorporations afin que vous puissiez interroger sur l’intrigue pour chaque film. Le code suivant configure Azure OpenAI, génère des incorporations et charge les vecteurs d’incorporation dans Azure Cache pour Redis.
Ajoutez le code suivant dans une nouvelle cellule de code :
# Code cell 8 embedding = AzureOpenAIEmbeddings( deployment=DEPLOYMENT_NAME, model=MODEL_NAME, azure_endpoint=RESOURCE_ENDPOINT, openai_api_type="azure", openai_api_key=API_KEY, openai_api_version="2023-05-15", show_progress_bar=True, chunk_size=16 # current limit with Azure OpenAI service. This will likely increase in the future. ) # name of the Redis search index to create index_name = "movieindex" # create a connection string for the Redis Vector Store. Uses Redis-py format: https://redis-py.readthedocs.io/en/stable/connections.html#redis.Redis.from_url # This example assumes TLS is enabled. If not, use "redis://" instead of "rediss:// redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT # create and load redis with documents vectorstore = RedisVectorStore.from_documents( documents=movie_list, embedding=embedding, index_name=index_name, redis_url=redis_url ) # save index schema so you can reload in the future without re-generating embeddings vectorstore.write_schema("redis_schema.yaml")Exécutez la cellule de code 8. Cette opération peut prendre plus de 30 minutes. Un fichier
redis_schema.yamlest également généré. Ce fichier est utile si vous souhaitez vous connecter à votre index dans Azure Cache pour Redis instance sans regénérer des incorporations.
Important
Le temps de génération des incorporations dépend du quota disponible pour le modèle Azure OpenAI. Avec un quota de 240 000 jetons par minute, il faut environ 30 minutes pour traiter les 7 millions de jetons dans le jeu de données.
Exécutez des requêtes de recherche vectorielle
Maintenant que votre jeu de données, l’API du service Azure OpenAI et l’instance Redis sont configurés, vous pouvez effectuer une recherche à l’aide de vecteurs. Dans cet exemple, les 10 premiers résultats d’une requête donnée sont retournés.
Ajoutez le code suivant à votre fichier de code Python :
# Code cell 9 query = "Spaceships, aliens, and heroes saving America" results = vectorstore.similarity_search_with_score(query, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Exécutez la cellule de code 9. La sortie suivante s’affiche :
Independence Day (Score: 0.8348) The Flying Machine (Score: 0.8332) Remote Control (Score: 0.8301) Bravestarr: The Legend (Score: 0.83) Xenogenesis (Score: 0.8291) Invaders from Mars (Score: 0.8291) Apocalypse Earth (Score: 0.8287) Invasion from Inner Earth (Score: 0.8287) Thru the Moebius Strip (Score: 0.8283) Solar Crisis (Score: 0.828)Le score de similarité est retourné avec le classement ordinal des films par similarité. On remarque que les scores de similarité des requêtes plus spécifiques diminuent plus rapidement dans la liste.
Recherches hybrides
Étant donné que RediSearch offre également des fonctionnalités de recherche enrichies en plus de la recherche vectorielle, il est possible de filtrer les résultats en fonction des métadonnées du jeu de données, telles que le genre de film, le casting, l’année de sortie ou le réalisateur. Dans ce cas, filtrez en fonction du genre
comedy.Ajoutez le code suivant à une nouvelle cellule de code :
# Code cell 10 from langchain.vectorstores.redis import RedisText query = "Spaceships, aliens, and heroes saving America" genre_filter = RedisText("Genre") == "comedy" results = vectorstore.similarity_search_with_score(query, filter=genre_filter, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Exécutez la cellule de code 10. La sortie suivante s’affiche :
Remote Control (Score: 0.8301) Meet Dave (Score: 0.8236) Elf-Man (Score: 0.8208) Fifty/Fifty (Score: 0.8167) Mars Attacks! (Score: 0.8165) Strange Invaders (Score: 0.8143) Amanda and the Alien (Score: 0.8136) Suburban Commando (Score: 0.8129) Coneheads (Score: 0.8129) Morons from Outer Space (Score: 0.8121)
Avec Azure Cache pour Redis et Azure OpenAI Service, vous pouvez utiliser les incorporations et la recherche vectorielle pour ajouter de puissantes fonctionnalités de recherche à votre application.
Nettoyer les ressources
Si vous souhaitez continuer à utiliser les ressources que vous avez créées dans cet article, conservez le groupe de ressources.
Sinon, si vous avez terminé avec les ressources, vous pouvez supprimer le groupe de ressources Azure que vous avez créé pour éviter les frais.
Important
La suppression d’un groupe de ressources est irréversible. Quand vous supprimez un groupe de ressources, toutes les ressources qu’il contient sont supprimées définitivement. Veillez à ne pas supprimer accidentellement des ressources ou un groupe de ressources incorrects. Si vous avez créé les ressources dans un groupe de ressources existant contenant des ressources que vous souhaitez conserver, vous pouvez supprimer chaque ressource individuellement, au lieu de supprimer l’intégralité du groupe de ressources.
Pour supprimer un groupe de ressources
Connectez-vous au Portail Azure, puis sélectionnez Groupes de ressources.
Recherchez le groupe de ressources à supprimer.
S’il existe de nombreux groupes de ressources, utilisez la zone Filtrer pour n’importe quel champ..., tapez le nom du groupe de ressources que vous avez créé pour cet article. Sélectionnez le groupe de ressources dans la liste des résultats.
Sélectionnez Supprimer le groupe de ressources.
Vous êtes invité à confirmer la suppression du groupe de ressources. Saisissez le nom de votre groupe de ressources pour confirmer, puis sélectionnez Supprimer.
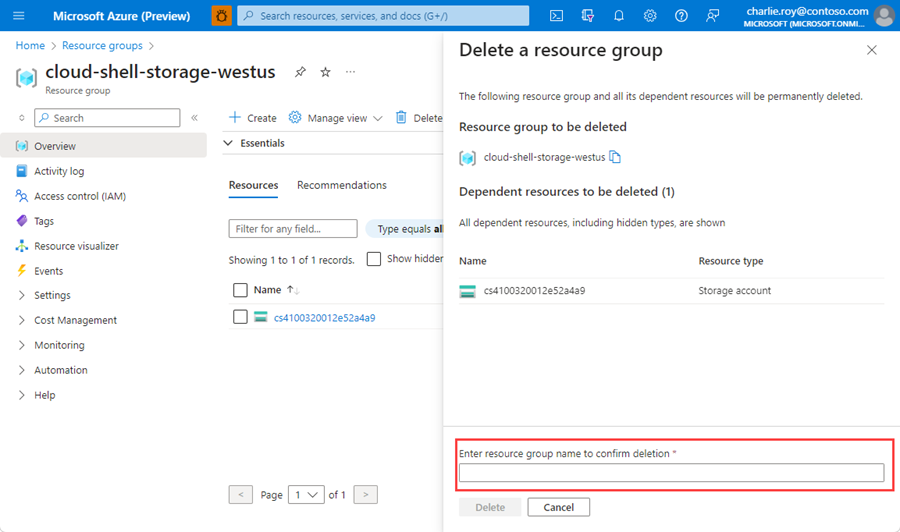
Après quelques instants, le groupe de ressources et toutes ses ressources sont supprimés.
Contenu associé
- En savoir plus sur Azure Cache pour Redis
- En savoir plus sur les fonctionnalités de recherche vectorielle Azure Cache pour Redis
- En savoir plus sur les incorporations générées par Azure OpenAI Service
- En savoir plus sur la similarité cosinus
- Découvrez comment créer une application basée sur l’IA avec OpenAI et Redis
- Créer une application Q&A avec des réponses sémantiques