Au lieu de stocker uniquement l’état actuel des données dans un domaine, utilisez un magasin d’ajout uniquement pour enregistrer la série complète d’actions exécutées sur ces données. Le magasin joue le rôle de système d’enregistrement et peut être utilisé pour matérialiser les objets du domaine. Cela peut simplifier les tâches dans les domaines complexes, en évitant d’avoir à synchroniser le modèle de données et le domaine de l’entreprise, tout en améliorant les performances, l’évolutivité et la réactivité. Il peut également assurer la cohérence des données transactionnelles et conserver un historique et des journaux d’audit complets qui peuvent activer des actions de compensation.
Contexte et problème
La plupart des applications utilisent des données et l’approche habituelle consiste à ce que l’application les mette à jour lorsque les utilisateurs les utilisent. Par exemple, dans le modèle traditionnel de création, lecture, mise à jour et suppression (CRUD), le traitement type des données consiste à lire les données depuis le magasin, y apporter des modifications et mettre à jour l’état actuel des données avec les nouvelles valeurs, souvent au moyen de transactions qui verrouillent les données.
L’approche CRUD présente certaines limites :
Les systèmes CRUD effectuent les opérations de mise à jour directement sur un magasin de données. Celles-ci peuvent ralentir les performances et la réactivité, et limiter l’extensibilité, en raison de la charge de traitement requise.
Dans un domaine de collaboration comportant plusieurs utilisateurs simultanés, des conflits de mise à jour des données sont possibles, car les opérations de mise à jour s’effectuent sur un seul élément des données.
À moins qu’il n’y ait un autre mécanisme d’audit qui enregistre les détails de chaque opération dans un journal séparé, l’historique est perdu.
Solution
Le modèle d’approvisionnement en événements définit une approche de gestion des opérations sur les données qui est guidée par une séquence d’événements, dont chacun est enregistré dans un magasin d’ajout uniquement. Le code applicatif envoie une série d’événements qui décrivent de manière impérative chaque action se produisant sur les données du magasin d’événements, où elles sont conservées. Chaque événement représente un ensemble de modifications des données (comme AddedItemToOrder).
Les événements sont conservés dans un magasin d’événements qui joue le rôle de système d’enregistrement (la source de données faisant autorité) sur l’état actuel des données. Le magasin d’événements publie généralement ces événements afin que les consommateurs puissent être avertis et les traiter si nécessaire. Les consommateurs pourraient, par exemple, initier des tâches qui appliquent les opérations des événements à d’autres systèmes, ou effectuer toute autre action associée nécessaire pour terminer l’opération. Notez que le code applicatif qui génère les événements est découplé des systèmes qui s’abonnent aux événements.
Les événements publiés par le magasin d’événements servent généralement à conserver les vues matérialisées des entités car les actions dans l’application les modifient, ainsi que pour l’intégration avec les systèmes externes. Par exemple, un système peut conserver une vue matérialisée de toutes les commandes client utilisée pour remplir des parties de l’interface utilisateur. L’application ajoute de nouvelles commandes, ajoute ou supprime des articles sur la commande et ajoute des informations d’expédition. Les événements qui décrivent ces modifications peuvent être gérés et utilisés pour mettre à jour la vue matérialisée.
Les applications peuvent, à tout moment, lire l’historique des événements. Vous pouvez ensuite l’utiliser pour matérialiser l’état actuel d’une entité en relisant et exploitant tous les événements liés à cette entité. Ce processus peut être effectué à la demande pour matérialiser un objet de domaine lors du traitement d’une requête. Il peut aussi être effectué par le biais d’une tâche planifiée afin que l’état de l’entité puisse être conservé sous la forme d’une vue matérialisée pour prendre en charge la couche de présentation.
La figure montre une vue d’ensemble du modèle, y compris certaines des options d’utilisation du flux d’événements telles que la création d’une vue matérialisée, l’intégration des événements avec des systèmes et applications externes et la relecture des événements pour créer des projections de l’état actuel d’entités spécifiques.
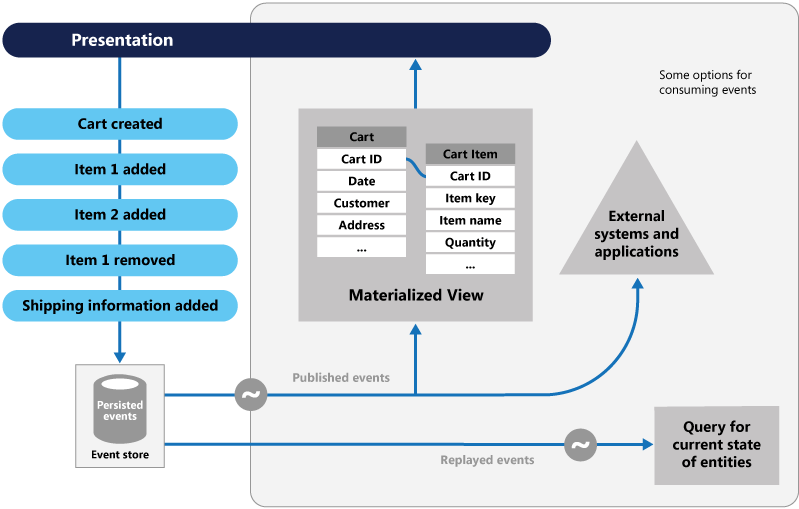
Le modèle d'approvisionnement en événements offre les avantages suivants :
Les événements sont immuables et peuvent être conservés au moyen d’une opération d’ajout uniquement. L’interface utilisateur, le flux de travail ou le processus qui a déclenché un événement peut continuer, et les tâches qui gèrent les événements peuvent s’exécuter en arrière-plan. Celui-ci, associé à l’absence de contention lors du traitement des transactions, peut considérablement améliorer les performances et l’évolutivité des applications, surtout pour le niveau de présentation ou l’interface utilisateur.
Les événements sont des objets simples qui décrivent certaines actions qui se sont produites, ainsi que toutes les données associées nécessaires pour décrire l’action représentée par l’événement. Les événements ne mettent pas directement à jour un magasin de données. Ils sont simplement enregistrés afin d’être traités au moment opportun. L’utilisation d’événements permet de simplifier la mise en œuvre et la gestion.
Les événements ont généralement un sens pour les experts de domaine, tandis que l’anomalie d’impédance objet-relationnel peut rendre difficile à comprendre les tables de base de données complexes. Les tables sont des constructions artificielles qui représentent l’état actuel du système, et non les événements qui se sont produits.
L’approvisionnement en événements peut permettre d’éviter que les mises à jour simultanées ne provoquent des conflits car cela évite d’avoir mettre à jour directement des objets dans le magasin de données. Toutefois, le modèle de domaine doit toujours être conçu de manière à se protéger lui-même contre les requêtes pouvant entraîner un état incohérent.
Le stockage d’ajout uniquement des événements fournit une piste d’audit pouvant être utilisée pour surveiller les actions effectuées sur un magasin de données. Il peut régénérer l’état actuel sous forme de vues matérialisées ou de projections en relisant les événements à tout moment, et aider à tester et déboguer le système. En outre, la nécessité d’utiliser des événements de compensation pour annuler les modifications peut fournir un historique des modifications qui ont été annulées, ce qui ne serait pas possible si le modèle stockait simplement l’état actuel. La liste des événements peut également être utilisée pour analyser les performances applicatives et détecter les tendances de comportement des utilisateurs, ou pour obtenir d’autres informations utiles.
Le magasin d’événements déclenche des événements et les tâches effectuent des opérations en réponse à ces événements. Ce découplage des tâches à partir des événements favorise la flexibilité et l’extensibilité. Les tâches connaissent le type d’événement et ses données, mais pas l’opération qui a déclenché l’événement. En outre, plusieurs tâches peuvent gérer chaque événement. Cela facilite l’intégration avec d’autres services et systèmes qui écoutent uniquement les nouveaux événements déclenchés par le magasin d’événements. Toutefois, les événements d’approvisionnement en événements ont tendance à être à un très bas niveau et il peut être nécessaire de générer à la place des événements d’intégration spécifiques.
L’approvisionnement en événements est couramment associé au modèle CQRS en effectuant les tâches de gestion des données en réponse aux événements et en matérialisant les vues à partir des événements stockés.
Problèmes et considérations
Prenez en compte les points suivants lorsque vous choisissez comment implémenter ce modèle :
Le système sera finalement cohérent uniquement lors de la création de vues matérialisées ou de la génération de projections de données par la relecture d’événements. Il existe une certaine latence entre le moment où une application ajoute des événements au magasin d’événements suite au traitement d’une requête, la publication des événements et leur traitement par les consommateurs des événements. Pendant ce temps, les nouveaux événements qui décrivent les modifications supplémentaires apportées aux entités peuvent être parvenus au magasin d’événements. Le système doit être conçu pour tenir compte de la cohérence éventuelle de ces scénarios.
Notes
Pour plus d’informations sur la cohérence éventuelle, consultez Data Consistency Primer(Manuel d’introduction à la cohérence des données).
Le magasin d’événements est la source permanente d’informations et les données d’événement ne doivent donc jamais être actualisées. La seule façon de mettre à jour une entité pour annuler une modification est d’ajouter un événement de compensation au magasin d’événements. Si le format (plutôt que les données) des événements persistants doit être modifié, lors d’une migration par exemple, il peut être difficile de combiner dans le magasin des événements existants avec la nouvelle version. Il peut être nécessaire d’itérer sur tous les événements en effectuant des modifications afin qu’ils soient compatibles avec le nouveau format, ou d’ajouter de nouveaux événements qui utilisent le nouveau format. Pensez à utiliser une étampe de version sur chaque version du schéma d’événement pour conserver à la fois l’ancien et le nouveau format d’événement.
Les applications multithread et plusieurs instances d’applications peuvent stocker des événements dans le magasin d’événements. La cohérence des événements dans le magasin d’événements est indispensable, tout comme l’ordre des événements qui affectent une entité spécifique (l’ordre dans lequel les modifications s’appliquent à une entité affecte son état actuel). L’ajout d’un horodatage à chaque événement peut permettre d’éviter les problèmes. Une autre pratique courante consiste à annoter chaque événement issu d’une requête avec un identificateur incrémentiel. Si deux personnes tentent d’ajouter des événements à la même entité au même moment, le magasin d’événements peut rejeter un événement correspondant à un identificateur d’entité existant et à un identificateur d’événement.
Il n’existe aucune approche standard ou mécanismes existants (comme des requêtes SQL) pour lire les événements afin d’obtenir des informations. Un flux d’événements constitue les seules données pouvant être extraites en utilisant comme critère un identificateur d’événement. L’ID d’événement correspond généralement à des entités individuelles. L’état actuel d’une entité peut être déterminé uniquement en relisant tous les événements s’y rapportant par rapport à l’état d’origine de cette entité.
La longueur de chaque flux d’événements a une incidence sur la gestion et la mise à jour du système. Si les flux de données sont volumineux, pensez à créer des instantanés à intervalles réguliers (un nombre spécifié d’événements, par exemple). L’état actuel de l’entité peut être obtenu à partir de l’instantané et en relisant les événements qui se sont produits après ce moment précis. Pour plus d’informations sur la création d’instantanés de données, consultez Réplication de capture instantanée principale-subordonnée.
Même si l’approvisionnement en événements réduit le risque de mises à jour conflictuelles des données, l’application doit rester en mesure de traiter les incohérences résultant de la cohérence éventuelle et de l’absence de transactions. Par exemple, un événement indiquant une réduction dans l’inventaire du stock peut arriver dans le magasin de données alors même qu’une commande pour cet élément est en train d’être passée. Il est alors nécessaire de procéder au rapprochement des deux opérations, soit en en informant le client ou bien en créant une commande différée.
La publication de l’événement peut avoir lieu au moins une fois, c’est pourquoi les consommateurs des événements doivent être idempotents. Ils ne doivent pas réappliquer la mise à jour décrite dans un événement si celui-ci est traité plusieurs fois. Plusieurs instances d’un consommateur peuvent conserver et agréger la propriété d’une entité, comme le nombre total de commandes passées. Seule une instance doit réussir à incrémenter l’agrégat lorsqu’un événement de passage de commande se produit. Même si ce résultat n’est pas une caractéristique majeure de l’approvisionnement en événements, c’est la décision de mise en œuvre habituelle.
Le stockage d’événements sélectionné doit prendre en charge la charge d’événements que génère votre application.
Gardez à l’esprit les scénarios dans lesquels le traitement d’un événement occasionne la création d’un ou plusieurs événements, cela peut ainsi provoquer une boucle infinie.
Quand utiliser ce modèle
Utilisez ce modèle dans les situations suivantes :
Lorsque vous souhaitez capturer l’intention, l’objectif ou le motif des données. Par exemple, les modifications apportées à une entité client peuvent être capturées sous la forme d’une série de types d’événements spécifiques comme A déménagé, Compte clôturé ou Décédé.
Lorsqu’il est essentiel de limiter ou de prévenir complètement le risque de mises à jour conflictuelles des données.
Lorsque vous souhaitez enregistrer les événements qui se produisent pour pouvoir les relire afin de restaurer l’état d’un système, restaurer les modifications ou conserver un historique et un journal d’audit. Par exemple, lorsqu’une tâche implique plusieurs étapes, vous devrez peut-être exécuter certaines actions pour restaurer les mises à jour, puis relire certaines étapes afin de rétablir les données à un état cohérent.
Lorsque vous utilisez des événements. Il s’agit d’une caractéristique naturelle du fonctionnement de l’application qui nécessite peu d’effort supplémentaire de développement ou de mise en œuvre.
Lorsque vous devez découpler le processus de saisie ou de mise à jour des données des tâches nécessaires à l’application de ces actions. Cette modification peut servir à améliorer les performances de l’interface utilisateur ou distribuer les événements à d’autres écouteurs qui agissent lorsque les événements se produisent. Par exemple, vous pouvez intégrer un système de paie à un site web de soumission des dépenses. Les événements déclenchés par le magasin d’événements en réponse aux mises à jour des données effectuées sur le site web seraient consommés par le site web et le système de paie.
Lorsque vous souhaitez disposer de la flexibilité nécessaire pour modifier le format des modèles matérialisés et des données d’entité si les besoins changent, ou en cas d’utilisation avec CQRS, si vous devez adapter un modèle de lecture ou les vues qui exposent les données.
Lorsqu’il est utilisé avec CQRS et que la cohérence éventuelle est acceptable lorsqu’un modèle de lecture est mis à jour, ou que l’impact sur les performances de la réalimentation des entités et des données à partir d’un flux d’événements est acceptable.
Ce modèle peut s’avérer inutile dans les situations suivantes :
Domaines simples ou de petite taille, systèmes ayant peu ou aucune logique d’entreprise, ou systèmes non domaine fonctionnant naturellement bien avec les mécanismes de gestion de données CRUD traditionnels.
Systèmes où la cohérence et les mises à jour en temps réel des vues des données sont requises.
Systèmes où les pistes d’audit, l’historique et les fonctionnalités de restauration et de relecture des actions ne sont pas requis.
Systèmes présentant uniquement un faible nombre d’occurrences de mises à jour conflictuelles des données sous-jacentes. Par exemple, les systèmes qui ajoutent surtout des données au lieu de les mettre à jour.
Conception de la charge de travail
Un architecte doit évaluer la façon dont le modèle d’approvisionnement en événements peut être utilisé dans la conception de leurs charges de travail pour se conformer aux objectifs et principes abordés dans les piliers d’Azure Well-Architected Framework. Par exemple :
| Pilier | Comment ce modèle soutient les objectifs des piliers. |
|---|---|
| Les décisions relatives à la fiabilité contribuent à rendre votre charge de travail résiliente aux dysfonctionnements et à s’assurer qu’elle retrouve un état de fonctionnement optimal après une défaillance. | Grâce à la capture d’un historique des changements dans un processus d’entreprise complexe, il peut faciliter la reconstruction de l’état si vous avez besoin de récupérer des magasins d’états. - RE :06Partitionnement des données - RE :09 reprise d’activité après sinistre |
| L’efficacité des performances permet à votre charge de travail de répondre efficacement aux demandes grâce à des optimisations de la mise à l’échelle, des données, du code. | Ce modèle, généralement combiné au CQRS, à une conception appropriée du domaine et à une capture instantanée stratégique, peut améliorer les performances de la charge de travail grâce aux opérations atomiques de type avec ajout seulement et à l’absence de verrouillage de la base de données pour les écritures et les lectures. - PE :08 Performance des données |
Comme pour toute autre décision de conception, il convient de prendre en compte les compromis par rapport aux objectifs des autres piliers qui pourraient être introduits avec ce modèle.
Exemple
Un système de gestion de conférences doit suivre le nombre de réservations effectuées afin de pouvoir vérifier s’il reste des places disponibles lorsqu’un participant potentiel tente d’effectuer une réservation. Le système peut stocker le nombre total de réservations pour une conférence d’au moins deux façons possibles :
Il peut stocker les informations sur le nombre total de réservations sous la forme d’une entité distincte dans une base de données contenant des informations de réservation. Lorsque des réservations sont effectuées ou annulées, le système peut incrémenter ou décrémenter ce nombre comme il convient. Cette approche est simple en théorie, mais peut entraîner des problèmes d’extensibilité si un grand nombre de participants tente de réserver des places sur une courte période de temps. Par exemple, dans les derniers jours avant la clôture des réservations.
Le système peut stocker des informations sur les réservations et les annulations sous la forme d’événements conservés dans un magasin d’événements. Il peut ensuite calculer le nombre de places disponibles en relisant ces événements. Cette approche peut être plus évolutive en raison de l’immuabilité des événements. Le système doit seulement être en mesure de lire les données du magasin d’événements, ou d’ajouter des données au magasin d’événements. Les informations d’événement sur les réservations et les annulations ne sont jamais modifiées.
Le diagramme suivant illustre la façon dont le sous-système de réservation de places du système de gestion de conférences peut être implémenté grâce à l’approvisionnement en événements.
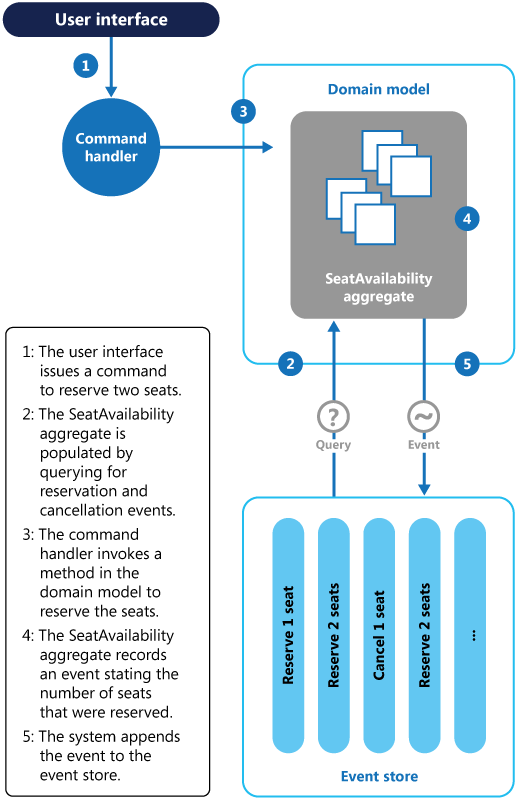
Voici la séquence d’actions permettant de réserver deux places :
L’interface utilisateur émet une commande pour réserver des places pour deux participants. La commande est traitée par un gestionnaire de commandes distinct. Logique qui est dissociée de l’interface utilisateur et est responsable du traitement des requêtes publiées sous forme de commandes.
Un agrégat contenant des informations sur toutes les réservations pour la conférence est élaboré en interrogeant les événements qui décrivent les réservations et les annulations. Cet agrégat est appelé
SeatAvailabilityet est contenu dans un modèle de domaine qui présente les méthodes d’interrogation et de modification des données dans l’agrégat.Pour optimiser les opérations, vous pouvez envisager d’utiliser des captures instantanées (afin de ne pas avoir à interroger et relire la liste complète des événements pour obtenir l’état actuel de l’agrégat) et de conserver une copie mise en cache de l’agrégat dans la mémoire.
Le gestionnaire de commandes appelle une méthode exposée par le modèle de domaine pour effectuer les réservations.
L’agrégat
SeatAvailabilityenregistre un événement qui contient le nombre de places réservées. La prochaine fois que l’agrégat appliquera des événements, toutes les réservations seront utilisées pour calculer le nombre de places restantes.Le système ajoute le nouvel événement à la liste des événements dans le magasin d’événements.
Si un utilisateur annule une place, le système suit un processus similaire, sauf que le gestionnaire de commandes émet une commande qui génère un événement d’annulation de place et l’ajoute dans le magasin d’événements.
En plus d’accroître l’extensibilité, l’utilisation d’un magasin d’événements fournit également un historique complet, ou piste d’audit, des réservations et annulations d’une conférence. Les événements du magasin d’événements constituent l’enregistrement le plus précis. Il n’est pas nécessaire de conserver les agrégats d’une autre manière, car le système peut facilement relire les événements et restaurer l’état à n’importe quel instant donné.
Vous trouverez plus d’informations sur cet exemple dans Présentation de l’approvisionnement en événements.
Étapes suivantes
Data Consistency Primer (Manuel d’introduction à la cohérence des données). Si vous utilisez l’approvisionnement en événements avec un magasin de lecture distinct ou des vues matérialisées, les données de lecture ne seront pas immédiatement cohérentes. Au lieu de cela, les données ne seront cohérentes qu’à la fin. Cet article résume les problèmes se rapportant au maintien de la cohérence des données distribuées.
Conseils sur le partitionnement des données. Les données sont souvent partitionnées lorsque l’approvisionnement en événements est utilisé afin d’améliorer l’évolutivité, de réduire la contention et d’optimiser les performances. Cet article décrit comment diviser les données en partitions distinctes, et les problèmes pouvant survenir.
Billet de blog de Martin Fowler :
Ressources associées
Les modèles et les conseils suivants peuvent aussi présenter un intérêt quand il s’agit d’implémenter ce modèle :
Modèle de séparation des responsabilités en matière de commande et de requête (CQRS). Le magasin d’écriture qui fournit la source permanente d’informations relatives à une implémentation CQRS est souvent basé sur une implémentation du modèle d’approvisionnement en événements. Décrit comment séparer les opérations qui lisent les données dans une application des opérations qui mettent à jour les données en utilisant des interfaces distinctes.
Modèle de vue matérialisée. Le magasin de données utilisé dans un système basé sur l’approvisionnement en événements n’est généralement pas adaptée pour assurer une interrogation efficace. L’approche courante consiste à générer des vues préremplies des données à intervalles réguliers, ou lorsque les données changent.
Modèle de transaction de compensation. Les données existantes dans un magasin d’approvisionnement en événements ne sont pas mises à jour. À la place, de nouvelles entrées sont ajoutées pour assurer la transition de l’état des entités vers les nouvelles valeurs. Pour annuler une modification, on utilise les entrées de compensation car il n’est pas possible d’annuler la modification précédente. Décrit comment annuler le travail qui a été effectué par une opération précédente.