La séparation des responsabilités des requêtes de commande (CQRS) est un modèle de conception qui sépare les opérations de lecture et d’écriture d’un magasin de données dans des modèles de données distincts. Cela permet à chaque modèle d’être optimisé indépendamment et peut améliorer les performances, l’extensibilité et la sécurité d’une application.
Contexte et problème
Dans les architectures traditionnelles, un modèle de données unique est souvent utilisé pour les opérations de lecture et d’écriture. Cette approche est simple et fonctionne bien pour les opérations CRUD de base (voir la figure 1).
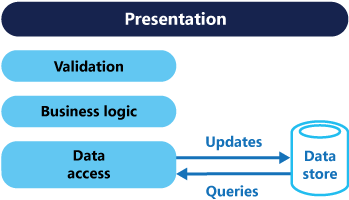
Figure 1. Architecture CRUD traditionnelle.
Toutefois, à mesure que les applications augmentent, l’optimisation des opérations de lecture et d’écriture sur un modèle de données unique devient de plus en plus difficile. Les opérations de lecture et d’écriture ont souvent des besoins de performances et de mise à l’échelle différents. Une architecture CRUD traditionnelle ne tient pas compte de cette asymétrie. Il conduit à plusieurs défis :
incompatibilité des données : Les représentations de lecture et d’écriture des données diffèrent souvent. Certains champs requis pendant les mises à jour peuvent être inutiles pendant les lectures.
contention de verrou : opérations parallèles sur le même jeu de données peuvent entraîner une contention de verrou.
problèmes de performances : L’approche traditionnelle peut avoir un effet négatif sur les performances en raison de la charge sur la couche d’accès aux données et du magasin de données, ainsi que la complexité des requêtes requises pour récupérer des informations.
Problèmes de sécurité : La gestion de la sécurité devient difficile lorsque les entités sont soumises à des opérations de lecture et d’écriture. Ce chevauchement peut exposer des données dans des contextes inattendus.
La combinaison de ces responsabilités peut entraîner un modèle trop compliqué qui tente de faire trop.
Solution
Utilisez le modèle CQRS pour séparer les opérations d’écriture (commandes) des opérations de lecture (requêtes). Les commandes sont responsables de la mise à jour des données. Les requêtes sont responsables de la récupération des données.
Comprendre les commandes. Les commandes doivent représenter des tâches métier spécifiques plutôt que des mises à jour de données de bas niveau. Par exemple, dans une application de réservation d’hôtel, utilisez « Réserver une chambre d’hôtel » au lieu de « Définir ReservationStatus sur Réservé ». Cette approche reflète mieux l’intention derrière les actions utilisateur et aligne les commandes avec les processus métier. Pour vous assurer que les commandes réussissent, vous devrez peut-être affiner le flux d’interaction utilisateur, la logique côté serveur et envisager un traitement asynchrone.
| Zone d’affinement | Recommandation |
|---|---|
| Validation côté client | Validez certaines conditions avant d’envoyer la commande pour éviter les échecs évidents. Par exemple, si aucune salle n’est disponible, désactivez le bouton « Réserver » et fournissez un message clair et convivial dans l’interface utilisateur expliquant pourquoi la réservation n’est pas possible. Cette configuration réduit les demandes de serveur inutiles et fournit des commentaires immédiats aux utilisateurs, ce qui améliore leur expérience. |
| Logique côté serveur | Améliorez la logique métier pour gérer correctement les cas de périphérie et les défaillances. Par exemple, pour résoudre les conditions de concurrence (plusieurs utilisateurs tentant de réserver la dernière salle disponible), envisagez d’ajouter des utilisateurs à une liste d’attente ou de suggérer d’autres options. |
| Traitement asynchrone | Vous pouvez également des commandes de processus de manière asynchrone en les plaçant sur une file d’attente, plutôt que de les gérer de manière synchrone. |
Comprendre les requêtes. Les requêtes ne modifient jamais les données. Au lieu de cela, ils retournent des objets de transfert de données (DTO) qui présentent les données requises dans un format pratique, sans logique de domaine. Cette séparation claire des préoccupations simplifie la conception et l’implémentation du système.
Comprendre la séparation des modèles de lecture et d’écriture
La séparation du modèle de lecture du modèle d’écriture simplifie la conception et l’implémentation du système en répondant à des préoccupations distinctes pour les écritures de données et les lectures. Cette séparation améliore la clarté, la scalabilité et les performances, mais introduit des compromis. Par exemple, les outils de génération automatique comme les frameworks O/RM ne peuvent pas générer automatiquement du code CQRS à partir d’un schéma de base de données, nécessitant une logique personnalisée pour combler l’écart.
Les sections suivantes explorent deux approches principales pour implémenter la séparation des modèles de lecture et d’écriture dans CQRS. Chaque approche présente des avantages et des défis uniques, tels que la synchronisation et la gestion de la cohérence.
Séparation des modèles dans un magasin de données unique
Cette approche représente le niveau fondamental de CQRS, où les modèles de lecture et d’écriture partagent une base de données sous-jacente unique, mais conservent une logique distincte pour leurs opérations. En définissant des préoccupations distinctes, cette stratégie améliore la simplicité tout en offrant des avantages en matière d’extensibilité et de performances pour les cas d’usage classiques. Une architecture CQRS de base vous permet de délimiter le modèle d’écriture à partir du modèle de lecture tout en s’appuyant sur un magasin de données partagé (voir la figure 2).
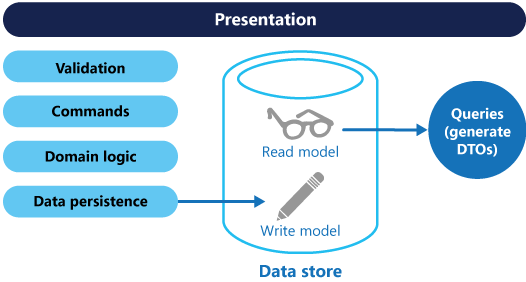
Figure 2. Architecture CQRS de base avec un magasin de données unique.
Cette approche améliore la clarté, les performances et l’extensibilité en définissant des modèles distincts pour la gestion des problèmes d’écriture et de lecture :
modèle d’écriture : conçu pour gérer les commandes qui mettent à jour ou conservent des données. Il inclut la validation, la logique de domaine et garantit la cohérence des données en optimisant l’intégrité transactionnelle et les processus métier.
modèle de lecture : conçu pour traiter des requêtes pour récupérer des données. Il se concentre sur la génération d’objets DTO (objets de transfert de données) ou de projections optimisées pour la couche de présentation. Elle améliore les performances et la réactivité des requêtes en évitant la logique de domaine.
Séparation physique des modèles dans des magasins de données distincts
Une implémentation CQRS plus avancée utilise des magasins de données distincts pour les modèles de lecture et d’écriture. La séparation des magasins de données de lecture et d’écriture vous permet de mettre à l’échelle chacune pour qu’elle corresponde à la charge. Il vous permet également d’utiliser une technologie de stockage différente pour chaque magasin de données. Vous pouvez utiliser une base de données de documents pour le magasin de données de lecture et une base de données relationnelle pour le magasin de données d’écriture (voir la figure 3).
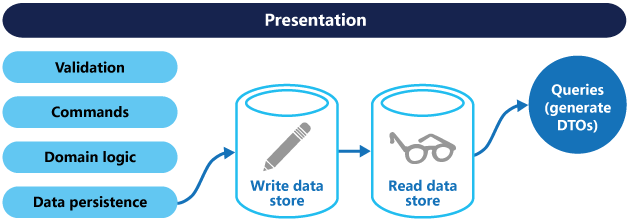
Figure 3. Architecture CQRS avec des magasins de données de lecture et d’écriture distincts.
Synchronisation des magasins de données distincts : Lors de l’utilisation de magasins distincts, vous devez vous assurer que les deux restent synchronisés. Un modèle courant consiste à avoir les événements de publication du modèle d’écriture chaque fois qu’il met à jour la base de données, que le modèle de lecture utilise pour actualiser ses données. Pour plus d’informations sur l’utilisation d’événements, consultez style d’architecture piloté par les événements. Toutefois, vous ne pouvez généralement pas inscrire de répartiteurs de messages et de bases de données dans une seule transaction distribuée. Par conséquent, il peut y avoir des difficultés à garantir la cohérence lors de la mise à jour de la base de données et de la publication d’événements. Pour plus d’informations, consultez traitement des messages idempotent.
Lire le magasin de données : le magasin de données de lecture peut utiliser son propre schéma de données optimisé pour les requêtes. Par exemple, il peut stocker une vue matérialisée des données pour éviter les jointures complexes ou les mappages O/RM. Le magasin de lectures peut être un réplica en lecture seule du magasin d’écritures ou avoir une structure différente. Le déploiement de plusieurs réplicas en lecture seule peut améliorer les performances en réduisant la latence et en augmentant la disponibilité, en particulier dans les scénarios distribués.
Avantages de CQRS
Mise à l’échelle indépendante. CQRS permet aux modèles de lecture et d’écriture de s’adapter indépendamment, ce qui peut aider à réduire la contention de verrouillage et à améliorer les performances du système sous charge.
Schémas de données optimisés. Les opérations de lecture peuvent utiliser un schéma optimisé pour les requêtes. Les opérations d’écriture utilisent un schéma optimisé pour les mises à jour.
Sécurité. En séparant les lectures et les écritures, vous pouvez vous assurer que seules les entités de domaine ou opérations appropriées sont autorisées à effectuer des actions d’écriture sur les données.
Séparation des problèmes. Le fractionnement des responsabilités de lecture et d’écriture entraîne des modèles plus propres et plus gérables. Le côté écriture gère généralement une logique métier complexe, tandis que le côté lecture peut rester simple et axé sur l’efficacité des requêtes.
Requêtes simplifiées. Lorsque vous stockez une vue matérialisée dans la base de données de lecture, l’application peut éviter des jointures complexes lors de l’interrogation.
Considérations et problèmes d’implémentation
Voici quelques-uns des défis liés à l’implémentation de ce modèle :
complexité accrue. Bien que le concept de base de CQRS soit simple, il peut introduire une complexité significative dans la conception de l’application, en particulier lorsqu’il est combiné avec le modèle d’approvisionnement en événements .
problèmes de messagerie. Bien que la messagerie ne soit pas requise pour CQRS, vous l’utilisez souvent pour traiter les commandes et publier des événements de mise à jour. Lorsque la messagerie est impliquée, le système doit tenir compte des problèmes potentiels tels que les échecs de message, les doublons et les nouvelles tentatives. Consultez les instructions sur files d’attente prioritaires pour les stratégies de gestion des commandes avec des priorités variables.
Cohérence finale. Lorsque les bases de données de lecture et d’écriture sont séparées, les données de lecture peuvent ne pas refléter immédiatement les modifications les plus récentes, ce qui entraîne des données obsolètes. S’assurer que le magasin de modèles de lecture reste up-to-date avec des modifications dans le magasin de modèles d’écriture peut être difficile. En outre, la détection et la gestion des scénarios où un utilisateur agit sur des données obsolètes nécessite une considération minutieuse.
Quand utiliser le modèle CQRS
Le modèle CQRS est utile dans les scénarios qui nécessitent une séparation claire entre les modifications de données (commandes) et les requêtes de données (lectures). Envisagez d’utiliser CQRS dans les situations suivantes :
domaines collaboratifs : dans les environnements où plusieurs utilisateurs accèdent et modifient simultanément les mêmes données, CQRS permet de réduire les conflits de fusion. Les commandes peuvent inclure suffisamment de granularité pour éviter les conflits, et le système peut résoudre tout problème qui se produit dans la logique de commande.
interfaces utilisateur basées sur des tâches : applications qui guident les utilisateurs par le biais de processus complexes en tant que série d’étapes ou avec des modèles de domaine complexes bénéficient de CQRS.
Le modèle d’écriture a une pile de traitement de commandes complète avec une logique métier, une validation d’entrée et une validation métier. Le modèle d’écriture peut traiter un ensemble d’objets associés comme une unité unique pour les modifications de données, connu sous la forme d’une dans la terminologie de conception pilotée par le domaine. Le modèle d’écriture peut également s’assurer que ces objets sont toujours dans un état cohérent.
Le modèle de lecture n’a pas de logique métier ni de pile de validation. Elle retourne un DTO à utiliser dans un modèle d’affichage. Le modèle de lecture est cohérent de manière éventuelle avec le modèle d’écriture.
Réglage des performances : Systèmes où les performances des lectures de données doivent être ajustées séparément des performances des écritures de données, en particulier lorsque le nombre de lectures est supérieur au nombre d’écritures, bénéficiez de CQRS. Le modèle de lecture est mis à l’échelle horizontalement pour gérer de grands volumes de requêtes, tandis que le modèle d’écriture s’exécute sur moins d’instances pour réduire les conflits de fusion et maintenir la cohérence.
Séparation des problèmes de développement : CQRS permet aux équipes de travailler indépendamment. Une équipe se concentre sur l’implémentation de la logique métier complexe dans le modèle d’écriture, tandis qu’une autre développe les composants du modèle de lecture et de l’interface utilisateur.
systèmes en évolution : CQRS prend en charge les systèmes qui évoluent au fil du temps. Il s’adapte aux nouvelles versions de modèle, aux modifications fréquentes apportées aux règles d’entreprise ou à d’autres modifications sans affecter les fonctionnalités existantes.
Intégration du système : Systèmes qui s’intègrent à d’autres sous-systèmes, en particulier ceux qui utilisent l’approvisionnement en événements, restent disponibles même si un sous-système échoue temporairement. CQRS isole les défaillances, ce qui empêche un composant unique d’affecter l’ensemble du système.
Quand ne pas utiliser CQRS
Évitez CQRS dans les situations suivantes :
Le domaine ou les règles d’entreprise sont simples.
Une interface utilisateur simple de style CRUD et les opérations d’accès aux données sont suffisantes.
Conception de la charge de travail
Un architecte doit évaluer comment utiliser le modèle CQRS dans la conception de leur charge de travail pour répondre aux objectifs et principes abordés dans les piliers Azure Well-Architected Framework. Par exemple :
| Pilier | Comment ce modèle soutient les objectifs des piliers. |
|---|---|
| L’efficacité des performances permet à votre charge de travail de répondre efficacement aux demandes grâce à des optimisations de la mise à l’échelle, des données, du code. | La séparation des opérations de lecture et d’écriture dans des charges de travail en lecture-écriture intensives permet d’optimiser les performances et la mise à l’échelle ciblées pour l’objectif spécifique de chaque opération. - PE :05 Mise à l’échelle et partitionnement - PE :08 Performance des données |
Comme pour toute autre décision de conception, il convient de prendre en compte les compromis par rapport aux objectifs des autres piliers qui pourraient être introduits avec ce modèle.
Combinaison d’approvisionnement d’événements et de CQRS
Certaines implémentations de CQRS incorporent le modèle d’approvisionnement en événements , qui stocke l’état du système sous la forme d’une série chronologique d’événements. Chaque événement capture les modifications apportées aux données à un moment donné. Pour déterminer l’état actuel, le système relit ces événements dans l’ordre. Dans cette combinaison :
Le magasin d’événements est le modèle d’écriture et la source unique de vérité.
Le modèle de lecture génère des vues matérialisées à partir de ces événements, généralement sous une forme hautement dénormalisée. Ces vues optimisent la récupération des données en personnalisant les structures pour interroger et afficher les exigences.
Avantages de la combinaison de l’approvisionnement en événements et du CQRS
Les mêmes événements que ceux qui mettent à jour le modèle d’écriture peuvent servir d’entrées au modèle de lecture. Le modèle de lecture peut ensuite générer un instantané en temps réel de l’état actuel. Ces instantanés optimisent les requêtes en fournissant des vues efficaces et précomputées des données.
Au lieu de stocker directement l’état actuel, le système utilise un flux d’événements comme magasin d’écriture. Cette approche réduit les conflits de mise à jour sur les agrégats et améliore les performances et l’extensibilité. Le système peut traiter ces événements de manière asynchrone pour générer ou mettre à jour des vues matérialisées pour le magasin de lecture.
Étant donné que le magasin d’événements agit comme source unique de vérité, vous pouvez facilement régénérer des vues matérialisées ou s’adapter aux modifications du modèle de lecture en relectant les événements historiques. En essence, les vues matérialisées fonctionnent comme un cache durable et en lecture seule optimisé pour les requêtes rapides et efficaces.
Considérations relatives à la combinaison de l’approvisionnement en événements et du CQRS
Avant de combiner le modèle CQRS avec le modèle d’approvisionnement en événements , évaluez les considérations suivantes :
Cohérence éventuelle : Étant donné que les magasins d’écriture et de lecture sont séparés, les mises à jour du magasin de lecture peuvent se retarder derrière la génération d’événements, ce qui entraîne une cohérence éventuelle.
Complexité accrue : combinaison de CQRS avec l’approvisionnement en événements nécessite une approche de conception différente, ce qui peut rendre l’implémentation réussie plus difficile. Vous devez écrire du code pour générer, traiter et gérer des événements, et assembler ou mettre à jour des vues pour le modèle de lecture. Toutefois, l’approvisionnement en événements simplifie la modélisation de domaine et vous permet de reconstruire ou de créer facilement de nouvelles vues en préservant l’historique et l’intention de toutes les modifications de données.
Performances de génération d’affichage : génération de vues matérialisées pour le modèle de lecture peut consommer beaucoup de temps et de ressources. Il en va de même pour projeter des données en relectant et en traitant des événements pour des entités ou des collections spécifiques. Cet effet augmente lorsque les calculs impliquent l’analyse ou la somme de valeurs sur de longues périodes, car tous les événements connexes doivent être examinés. Implémentez des instantanés des données à intervalles réguliers. Par exemple, stockez des instantanés périodiques de totaux agrégés (le nombre de fois où une action spécifique se produit) ou l’état actuel d’une entité. Les instantanés réduisent la nécessité de traiter l’historique complet des événements à plusieurs reprises, ce qui améliore les performances.
Exemple de modèle CQRS
Le code suivant présente certains extraits d’un exemple d’implémentation CQRS qui utilise diverses définitions pour les modèles de lecture et d’écriture. Les interfaces du modèle n’imposent pas de fonctionnalités des magasins de données sous-jacents ; elles peuvent également évoluer et être ajustées de façon indépendante car elles sont séparées.
Le code suivant montre la définition du modèle de lecture.
// Query interface
namespace ReadModel
{
public interface ProductsDao
{
ProductDisplay FindById(int productId);
ICollection<ProductDisplay> FindByName(string name);
ICollection<ProductInventory> FindOutOfStockProducts();
ICollection<ProductDisplay> FindRelatedProducts(int productId);
}
public class ProductDisplay
{
public int Id { get; set; }
public string Name { get; set; }
public string Description { get; set; }
public decimal UnitPrice { get; set; }
public bool IsOutOfStock { get; set; }
public double UserRating { get; set; }
}
public class ProductInventory
{
public int Id { get; set; }
public string Name { get; set; }
public int CurrentStock { get; set; }
}
}
Le système permet aux utilisateurs d’évaluer des produits. Le code d’application effectue cette opération à l’aide de la commande RateProduct indiquée dans le code suivant.
public interface ICommand
{
Guid Id { get; }
}
public class RateProduct : ICommand
{
public RateProduct()
{
this.Id = Guid.NewGuid();
}
public Guid Id { get; set; }
public int ProductId { get; set; }
public int Rating { get; set; }
public int UserId {get; set; }
}
Le système utilise la classe ProductsCommandHandler pour gérer les commandes envoyées par l’application. En règle générale, les clients envoient des commandes au domaine via un système de messagerie comme une file d’attente. Le gestionnaire de commandes accepte ces commandes et appelle les méthodes de l’interface du domaine. La granularité de chaque commande est conçue pour réduire le risque de requêtes en conflit. Le code suivant montre une description de la classe ProductsCommandHandler.
public class ProductsCommandHandler :
ICommandHandler<AddNewProduct>,
ICommandHandler<RateProduct>,
ICommandHandler<AddToInventory>,
ICommandHandler<ConfirmItemShipped>,
ICommandHandler<UpdateStockFromInventoryRecount>
{
private readonly IRepository<Product> repository;
public ProductsCommandHandler (IRepository<Product> repository)
{
this.repository = repository;
}
void Handle (AddNewProduct command)
{
...
}
void Handle (RateProduct command)
{
var product = repository.Find(command.ProductId);
if (product != null)
{
product.RateProduct(command.UserId, command.Rating);
repository.Save(product);
}
}
void Handle (AddToInventory command)
{
...
}
void Handle (ConfirmItemsShipped command)
{
...
}
void Handle (UpdateStockFromInventoryRecount command)
{
...
}
}
Étapes suivantes
Les modèles et les conseils suivants peuvent être utiles quand il s’agit d’implémenter ce modèle :
- Partitionnement des données horizontales, verticales et fonctionnelles. Cet article les meilleures pratiques pour diviser les données en partitions gérées et accessibles de façon distincte pour améliorer l’extensibilité, réduire la contention et optimiser les performances.
Ressources associées
Modèle d’approvisionnement en événements. Décrit comment utiliser l’approvisionnement en événements avec le modèle CQRS. Il vous montre comment simplifier les tâches dans des domaines complexes tout en améliorant les performances, l’extensibilité et la réactivité. Il explique également comment fournir une cohérence pour les données transactionnelles tout en conservant des pistes d’audit complètes et l’historique qui peuvent activer les actions de compensation.
Modèle de vue matérialisée. Le mode de lecture d’une implémentation CQRS peut contenir des vues matérialisées des données du modèle d’écriture, ou le modèle de lecture peut être utilisé pour générer des vues matérialisées.