Azure Virtual Desktop est un service complet de virtualisation de bureau et d’application s’exécutant dans Microsoft Azure. Virtual Desktop permet d’activer une expérience bureau à distance sécurisée qui aide les organisations à renforcer la résilience de l’entreprise. Il offre une gestion simplifiée, Windows 10 et 11 Enterprise multisession et des optimisations pour Microsoft 365 Apps for enterprise. Avec Virtual Desktop, vous pouvez déployer et mettre à l’échelle vos bureaux et applications Windows sur Azure en quelques minutes, en fournissant des fonctionnalités de sécurité et de conformité intégrées pour vous aider à sécuriser vos applications et vos données.
Si vous continuez à autoriser le télétravail pour votre organisation avec Virtual Desktop, il est important de comprendre ses fonctionnalités de reprise d'activité après sinistre et ses meilleures pratiques. Ces pratiques renforcent la fiabilité entre les régions pour aider à assurer la sécurité des données et la productivité des employés. Cet article vous fournit des considérations sur les prérequis de continuité d’activité et de reprise d’activité (BCDR), les étapes de déploiement et les meilleures pratiques. Vous découvrirez les options, les stratégies et les conseils en matière d'architecture. Le contenu de ce document vous permet de préparer un plan BCDR réussi et peut vous aider à renforcer la résilience de votre entreprise pendant les événements d’arrêt planifiés et non planifiés.
Il existe plusieurs types de sinistres et de pannes, et chacun peut avoir un impact différent. La résilience et la récupération sont abordées en profondeur pour les événements locaux et régionaux, notamment la récupération du service dans une autre région Azure distante. Ce type de récupération est appelé géo-reprise d'activité après sinistre. Il est essentiel de créer votre architecture Virtual Desktop pour la résilience et la disponibilité. Vous devez fournir une résilience locale maximale pour réduire l’impact des événements d’échec. Cette résilience réduit également les exigences d’exécution des procédures de récupération. Cet article fournit également des informations sur la haute disponibilité et les meilleures pratiques.
Objectifs et étendue
Ce guide a pour objectifs de :
- Assurer de la disponibilité maximale, de la résilience et de la fonctionnalité de géo-reprise d'activité après sinistre tout en réduisant la perte de données pour les données utilisateur sélectionnées importantes.
- Réduire le temps de récupération.
Ces objectifs sont également appelés objectifs de point de récupération (RPO) et objectifs de temps de récupération (RTO).
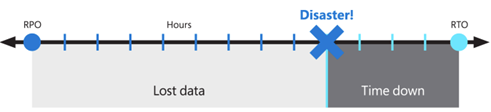
La solution proposée offre une haute disponibilité locale, une protection contre la défaillance d'une seule zone de disponibilité et une protection contre la défaillance de toute une région Azure. Elle s’appuie sur un déploiement redondant dans une région Azure différente ou secondaire pour récupérer le service. Même s’il s’agit toujours d’une bonne pratique, Virtual Desktop et la technologie utilisée pour créer BCDR n’exigent pas que les régions Azure soient jumelées. Les emplacements principaux et secondaires peuvent être n’importe quelle combinaison de régions Azure si la latence réseau l’autorise. L'exploitation de pools d'hôtes AVD dans plusieurs régions géographiques peut offrir d'autres avantages qui ne se limitent pas au BCDR.
Pour réduire l’impact d’un échec de zone de disponibilité unique, utilisez la résilience pour améliorer la haute disponibilité :
- Au niveau de la couche de calcul, répartissez les hôtes de session Virtual Desktop sur différentes zones de disponibilité.
- Au niveau de la couche de stockage, utilisez la résilience de zone chaque fois que possible.
- Au niveau de la couche réseau, déployez des passerelles Azure ExpressRoute et de réseau privé virtuel (VPN) résilientes à la zone.
- Pour chaque dépendance, passez en revue l’impact d’une panne de zone unique et des atténuations de plan. Par exemple, déployez des contrôleurs de domaine Active Directory et d'autres ressources externes auxquelles accèdent les utilisateurs de Virtual Desktop dans plusieurs zones de disponibilité.
Selon le nombre de zones de disponibilité que vous utilisez, évaluez le surapprovisionnement du nombre d’hôtes de session pour compenser la perte d’une zone. Par exemple, même avec (n-1) zones disponibles, vous pouvez garantir l’expérience utilisateur et les performances.
Notes
Les zones de disponibilité Azure sont une fonctionnalité de haute disponibilité qui peut améliorer la résilience. Toutefois, ne les considérez pas comme une solution de reprise d'activité après sinistre capable de protéger contre les sinistres à l’échelle de la région.

En raison des combinaisons possibles de types, d'options de réplication, de capacités de service et de restrictions de disponibilité dans certaines régions, il est recommandé d'utiliser le composant Cloud Cache de FSLogix plutôt que des mécanismes de réplication spécifiques au stockage.
OneDrive n’est pas abordé dans cet article. Pour plus d’informations sur la redondance et la haute disponibilité, consultez Résilience des données OneDrive et SharePoint dans Microsoft 365.
Pour le reste de cet article, vous allez découvrir les solutions pour les deux types de pool d’hôtes Virtual Desktop différents. Il existe également des observations fournies afin de pouvoir comparer cette architecture à d’autres solutions :
- Personnelle : Dans ce type de pool d’hôtes, un utilisateur a un hôte de session affecté définitivement, qui ne doit jamais changer. Étant donné qu’elle est personnelle, cette machine virtuelle peut stocker les données utilisateur. L’hypothèse consiste à utiliser des techniques de réplication et de sauvegarde pour préserver et protéger l’état.
- Regroupées : Les utilisateurs sont temporairement affectés à l’une des machines virtuelles hôtes de session disponibles à partir du pool, directement via un groupe d’applications de bureau ou à l’aide d’applications distantes. Les machines virtuelles sont sans état, et les données et profils utilisateur sont stockés dans un stockage externe ou OneDrive.
Les implications sur les coûts sont abordées, mais l’objectif principal est de fournir un déploiement de géo-reprise d'activité après sinistre efficace avec une perte de données minimale. Pour plus de détails sur la BCDR, consultez les ressources suivantes :
Prérequis
Déployez l’infrastructure principale et assurez-vous qu’elle est disponible dans la région primaire et secondaire Azure. Pour obtenir de l’aide sur votre topologie réseau, vous pouvez utiliser les modèles de topologie et de connectivité réseau Azure Cloud Adoption Framework :
Dans les deux modèles, déployez le pool d’hôtes Virtual Desktop principal et l’environnement de reprise d'activité après sinistre secondaire à l’intérieur de différents réseaux virtuels spoke et connectez-les à chaque hub dans la même région. Placez un hub à l’emplacement principal, un hub à l’emplacement secondaire, puis établissez la connectivité entre les deux.
Le hub fournit finalement une connectivité hybride aux ressources locales, aux services de pare-feu, aux ressources d’identité comme les contrôleurs de domaine Active Directory et aux ressources de gestion telles que Log Analytics.
Vous devez prendre en compte toutes les applications métier et la disponibilité des ressources dépendantes lors du basculement vers l’emplacement secondaire.
Continuité d'activité et reprise après sinistre au niveau du plan de contrôle
Virtual Desktop offre une continuité d'activité et une reprise après sinistre pour son plan de contrôle afin de préserver les métadonnées des clients pendant les pannes. La plateforme Azure gère ces données et ces processus, et les utilisateurs n'ont pas besoin de configurer ou d'exécuter quoi que ce soit.

Virtual Desktop est conçu pour résister aux défaillances des composants individuels et pour pouvoir récupérer rapidement après une panne. Lorsqu’une panne se produit dans une région, les composants de l’infrastructure de service basculent vers l’emplacement secondaire et continuent de fonctionner normalement. Vous pouvez toujours accéder aux métadonnées relatives au service, et les utilisateurs peuvent toujours se connecter aux hôtes disponibles. Les connexions de l’utilisateur final restent en ligne tant que l’environnement ou les hôtes du locataire restent accessibles. L'emplacement des données pour Virtual Desktop est différent de l'emplacement du déploiement des machines virtuelles (VM) de la session du pool hôte. Il est possible de localiser les métadonnées Virtual Desktop dans l’une des régions prises en charge, puis de déployer des machines virtuelles dans un autre emplacement. Vous trouverez plus de détails dans l'article sur l'architecture et la résilience du service Virtual Desktop.
Actif-actif ou actif-passif
Si des ensembles distincts d’utilisateurs ont des exigences BCDR différentes, Microsoft vous recommande d’utiliser plusieurs pools d’hôtes avec différentes configurations. Par exemple, les utilisateurs disposant d’une application stratégique peuvent affecter un pool d’hôtes entièrement redondant avec des fonctionnalités de géo-reprise d'activité après sinistre. Toutefois, les utilisateurs de développement et de test peuvent utiliser un pool hôte distinct sans reprise d'activité après sinistre.
Pour chaque pool d’hôtes Virtual Desktop unique, vous pouvez baser votre stratégie BCDR sur un modèle actif-actif ou actif-passif. Ce scénario suppose que le même ensemble d'utilisateurs dans un emplacement géographique est desservi par un pool d'hôtes spécifique.
-
Active-Active
Pour chaque pool d’hôtes de la région primaire, vous déployez un deuxième pool d’hôtes dans la région secondaire.
Cette configuration fournit un RTO presque à zéro, et le RPO a un coût supplémentaire.
Vous n’avez pas besoin qu’un administrateur intervienne ou effectue le basculement. Pendant les opérations normales, le pool d’hôtes secondaire fournit à l’utilisateur des ressources Virtual Desktop.
Chaque pool d'hôtes dispose de ses propres comptes de stockage (au moins un) pour les profils utilisateurs persistants.
Vous devez évaluer la latence en fonction de l’emplacement physique et de la connectivité de l’utilisateur disponibles. Pour certaines régions Azure, telles que Europe Ouest et Europe Nord, la différence peut être négligeable lors de l’accès aux régions primaires ou secondaires. Vous pouvez valider ce scénario à l’aide de l’outil Estimateur d’expérience Azure Virtual Desktop.
Les utilisateurs sont affectés à différents groupes d'applications, comme le groupe d'applications de bureau (DAG) et le groupe d'applications RemoteApp (RAG), dans les pools d'hôtes principal et secondaire. Dans ce cas, ils voient des entrées en double dans leur flux client Virtual Desktop. Pour éviter toute confusion, utilisez des espaces de travail Virtual Desktop distincts avec des noms et des étiquettes clairs qui reflètent l’objectif de chaque ressource. Informez vos utilisateurs sur l’utilisation de ces ressources.
Si vous avez besoin de stockage pour gérer séparément les conteneurs FSLogix Profile et ODFC, utilisez Cloud Cache pour garantir un RPO quasi nul.
- Pour éviter les conflits de profils, n’autorisez pas les utilisateurs à accéder aux deux pools hôtes en même temps.
- En raison de la nature active-active de ce scénario, vous devez apprendre à vos utilisateurs la façon d’utiliser ces ressources de manière appropriée.
Notes
L'utilisation de conteneurs ODFC séparés est un scénario avancé plus complexe. Ce déploiement n'est recommandé que dans certains scénarios spécifiques.
-
Actif-passif
- Comme avec le modèle actif-actif, pour chaque pool d’hôtes de la région primaire, vous déployez un deuxième pool d’hôtes dans la région secondaire.
- La quantité de ressources de calcul actives dans la région secondaire est réduite par rapport à la région primaire, selon le budget disponible. Vous pouvez utiliser la mise à l’échelle automatique pour fournir une capacité de calcul plus importante, mais elle nécessite plus de temps et la capacité Azure n’est pas garantie.
- Cette configuration fournit un RTO plus élevé par rapport à l’approche active-active, mais elle est moins coûteuse.
- Vous avez besoin de l’intervention d’un administrateur pour exécuter une procédure de basculement en cas de panne Azure. Le pool d'hôtes secondaire ne permet normalement pas à l'utilisateur d'accéder aux ressources de Virtual Desktop.
- Chaque pool d’hôtes possède son propre compte de stockage pour les profils utilisateur persistants.
- Les utilisateurs qui consomment des services Virtual Desktop avec une latence et des performances optimales sont affectés uniquement en cas de panne Azure. Vous devez valider ce scénario à l’aide de l’outil Estimateur d’expérience Azure Virtual Desktop. Les performances doivent être acceptables, même si elles sont dégradées, pour l’environnement de reprise d’activité après sinistre secondaire.
- Les utilisateurs ne sont affectés qu’à un seul ensemble de groupes d’applications, tels que les applications de bureau et distantes. Pendant les opérations normales, ces applications se trouvent dans le pool d’hôtes principal. En cas de panne et après un basculement, les utilisateurs sont affectés aux groupes d’applications dans le pool d’hôtes secondaire. Aucune entrée en double n’est affichée dans le flux client Virtual Desktop de l’utilisateur, ils peuvent utiliser le même espace de travail et tout est transparent pour eux.
- Si vous avez besoin de stockage pour gérer les conteneurs FSLogix Profile et Office, utilisez le Cache cloud pour garantir un RPO presque à zéro.
- Pour éviter les conflits de profils, n’autorisez pas les utilisateurs à accéder aux deux pools hôtes en même temps. Étant donné que ce scénario est actif-passif, les administrateurs peuvent appliquer ce comportement au niveau du groupe d’applications. Ce n’est qu’après une procédure de basculement que l’utilisateur est en mesure d’accéder à chaque groupe d’applications dans le pool d’hôtes secondaire. L’accès est révoqué dans le groupe d’applications du pool hôte principal et réaffecté à un groupe d’applications dans le pool d’hôtes secondaire.
- Exécutez un basculement pour tous les groupes d’applications, sinon les utilisateurs utilisant des groupes d’applications différents dans différents pools d’hôtes peuvent entraîner des conflits de profils s’ils ne sont pas gérés efficacement.
- Il est possible d’autoriser un sous-ensemble spécifique d’utilisateurs pour basculer sélectivement vers le pool d’hôtes secondaire, et fournir un comportement actif-actif limité et tester la fonctionnalité de basculement. Il est également possible de basculer des groupes d’applications spécifiques, mais vous devez apprendre à vos utilisateurs à ne pas utiliser de ressources de différents pools d’hôtes en même temps.
Dans des circonstances spécifiques, vous pouvez créer un pool d’hôtes unique avec un mélange d’hôtes de session situés dans différentes régions. L’avantage de cette solution est que si vous disposez d’un pool d’hôtes unique, il n’est pas nécessaire de dupliquer les définitions et les affectations pour les applications de bureau et distantes. Malheureusement, la reprise après sinistre pour les pools d'hôtes partagés présente plusieurs inconvénients :
- Pour les pools d’hôtes mis en pool, il n’est pas possible de forcer un utilisateur à utiliser un hôte de session dans la même région.
- Un utilisateur peut rencontrer une latence plus élevée et des performances sous-optimales lors de la connexion à un hôte de session dans une région distante.
- Si vous avez besoin de stockage pour les profils utilisateur, vous avez besoin d’une configuration complexe pour gérer les affectations pour les hôtes de session dans les régions primaires et secondaires.
- Vous pouvez utiliser le mode de drainage pour désactiver temporairement l’accès aux hôtes de session situés dans la région secondaire. Mais cette méthode introduit une plus grande complexité, une surcharge de gestion et une utilisation inefficace des ressources.
- Vous pouvez gérer les hôtes de session dans un état hors connexion dans les régions secondaires, mais cela introduit une plus grande complexité et une surcharge de gestion.
Remarques et recommandations
Général
Pour déployer une configuration active/active ou active/passive à l’aide de plusieurs pools d’hôtes et d’un mécanisme de cache cloud FSLogix, vous pouvez créer le pool d’hôtes dans le même espace de travail ou un autre, selon le modèle. Cette approche vous oblige à maintenir l’alignement et les mises à jour, en conservant les deux pools d’hôtes synchronisés et au même niveau de configuration. Outre un nouveau pool d’hôtes pour la région de reprise d’activité après sinistre secondaire, vous devez :
- créer des groupes d’applications distincts et des applications associées pour le nouveau pool d’hôtes ;
- révoquer les affectations d’utilisateurs au pool d’hôtes principal, puis les réaffecter manuellement au nouveau pool d’hôtes pendant le basculement.
Passez en revue l’article Option de continuité d’activité et reprise d’activité pour FSLogix.
- La reprise sans profil n'est pas abordée dans ce document.
- Un cache cloud (actif/passif) est inclus dans ce document, mais il est implémenté en tirant parti du même pool d’hôtes.
- Le cache cloud (actif/actif) est évoqué dans la partie restante du présent document.
Il existe des limites pour les ressources de bureau virtuel qui doivent être prises en compte lors de la conception d'une architecture de bureau virtuel. Validez votre conception en fonction des limites du service Virtual Desktop.
Pour les diagnostics et la surveillance, une bonne pratique consiste à utiliser le même espace de travail Log Analytics pour le pool d'hôtes principal et secondaire. En utilisant cette configuration, Azure Virtual Desktop Insights offre un aperçu unifié du déploiement dans les deux régions.
Cependant, l'utilisation d'une seule destination de journal peut poser des problèmes si l'ensemble de la région primaire est indisponible. La région secondaire ne pourra pas utiliser l'espace de travail Log Analytics dans la région indisponible. Si cette situation est inacceptable, les solutions suivantes peuvent être adoptées :
- Utilisez un espace de travail Log Analytics distinct pour chaque région, puis orientez les composants du bureau virtuel pour qu'ils se connectent vers son espace de travail local.
- Testez et examinez les capacités de réplication et de basculement de l'espace de travail de Logs Analytics.
Compute
Pour le déploiement des deux pools d'hôtes dans les régions de reprise d'activité principale et secondaire, vous devez répartir votre parc de machines virtuelles hôtes de session sur plusieurs zones de disponibilité. Si les zones de disponibilité ne sont pas disponibles dans la région locale, vous pouvez utiliser un ensemble de disponibilité pour rendre votre solution plus résiliente qu'avec un déploiement par défaut.
L’image de référence que vous utilisez pour le déploiement du pool d’hôtes dans la région de reprise après sinistre secondaire doit être la même que celle que vous utilisez pour la principale. Vous devez stocker les images dans Azure Compute Gallery et configurer plusieurs réplicas d’image dans les emplacements principaux et secondaires. Chaque réplica d’image peut maintenir un déploiement parallèle d’un nombre maximal de machines virtuelles, et vous pouvez nécessiter plusieurs machines virtuelles en fonction de votre taille de lot de déploiement souhaitée. Pour plus d’informations, consultez Stocker et partager des images dans une galerie Azure Compute Gallery.
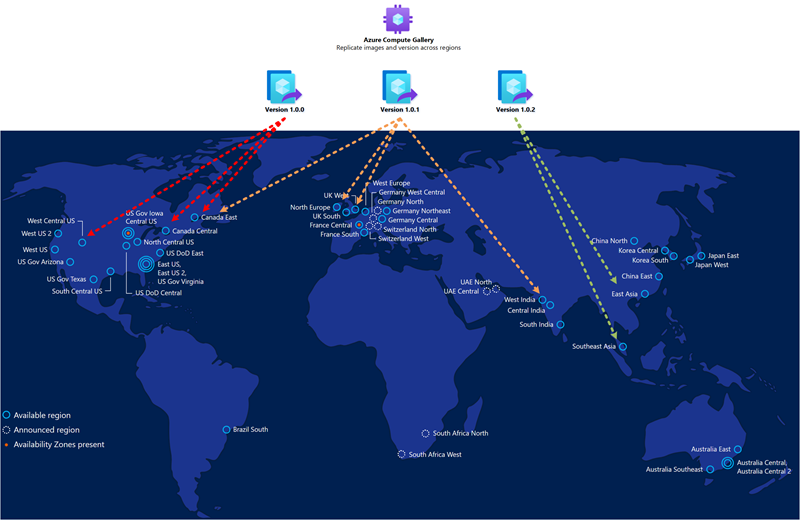
La galerie Azure Compute n'est pas une ressource mondiale. Il est recommandé d'avoir au moins une galerie secondaire dans la région secondaire. Dans votre région principale, créez une galerie, une définition d'image virtuelle et une version d'image virtuelle. Ensuite, créez les mêmes objets dans la région secondaire. Lors de la création de la version de l'image virtuelle, il est possible de copier la version de l'image virtuelle créée dans la région primaire en spécifiant la galerie, la définition de l'image virtuelle et la version de l'image virtuelle utilisées dans la région primaire. Azure copie l'image et crée une version locale de la machine virtuelle. Il est possible d’exécuter cette opération à l’aide du portail Azure ou de la commande Azure CLI, comme indiqué ci-dessous :
Toutes les machines virtuelles hôtes de session dans les emplacements de reprise d’activité après sinistre secondaires ne doivent pas être actives ni exécutées en permanence. Vous devez initialement créer un nombre suffisant de machines virtuelles et, par la suite, utiliser un mécanisme d’autoscale comme les plans de mise à l’échelle. Avec ces mécanismes, il est possible de maintenir la plupart des ressources de calcul dans un état hors connexion ou désaffecté pour réduire les coûts.
Il est également possible d’utiliser l’automatisation pour créer des hôtes de session dans la région secondaire uniquement si nécessaire. Cette méthode optimise les coûts, mais selon le mécanisme que vous utilisez, peut nécessiter un RTO plus long. Cette approche ne permet pas d'effectuer des tests de basculement sans un nouveau déploiement, ni de procéder à un basculement sélectif pour des groupes d'utilisateurs spécifiques.

Notes
Vous devez mettre sous tension chaque machine virtuelle hôte de session pendant quelques heures au moins une fois tous les 90 jours pour actualiser le jeton d'authentification nécessaire à la connexion au plan de contrôle de Virtual Desktop. Vous devez également appliquer régulièrement des correctifs de sécurité et des mises à jour d’application.
- Le fait que les hôtes de session soient hors ligne ou désalloués dans la région secondaire ne garantit pas la disponibilité de la capacité en cas de sinistre dans la région principale. Cela s'applique également si de nouveaux hôtes de session sont déployés à la demande en cas de besoin, et avec l'utilisation de Site Recovery. La capacité de calcul ne peut être garantie que si les ressources connexes sont déjà allouées et actives.
Important
Azure Reservations ne fournit pas de capacité garantie dans la région.
Pour les scénarios d’utilisation de Cloud Cache, nous vous recommandons d’utiliser le niveau premium pour les disques gérés.
Stockage
Dans ce guide, vous utilisez au moins deux comptes de stockage distincts pour chaque pool d’hôtes Virtual Desktop, l’un pour le conteneur FSLogix Profile et l’autre pour les données de conteneur Office. Vous avez également besoin d’un compte de stockage supplémentaire pour les packages MSIX. Les considérations suivantes s'appliquent :
- Vous pouvez utiliser le partage Azure Files et Azure NetApp Files comme alternatives de stockage. Pour comparer les options, consultez les options de stockage des conteneurs FSLogix.
- Azure Files share peut fournir une résilience de zone en utilisant l’option de résilience ZRS (zone-replicated storage), si elle est disponible dans la région.
- Vous ne pouvez pas utiliser la fonctionnalité de stockage géoredondant dans les situations suivantes :
- Vous avez besoin d'une région qui n'a pas d'appairage. Les paires de régions pour le stockage géoredondant sont fixes et ne peuvent pas être modifiées.
- Vous utilisez le niveau Premium.
- Le RPO et le RTO sont plus élevés par rapport au mécanisme de cache cloud FSLogix.
- Il n’est pas facile de tester le basculement et la restauration automatique dans un environnement de production.
- Azure NetApp Files requiert davantage de considérations :
- La redondance de zone n'est pas encore disponible. Si l’exigence de résilience est plus importante que les performances, utilisez le partage Azure Files.
- Azure NetApp Files peut être zonale, c’est-à-dire que les clients peuvent décider dans quelle (seule) zone de disponibilité Azure allouer.
- La réplication interzone peut être établie au niveau du volume pour fournir une résilience de zone, mais la réplication se produit de manière asynchrone et nécessite un basculement manuel. Ce processus nécessite un objectif de point de récupération (RPO) et un objectif de temps de récupération (RTO) supérieurs à zéro. Avant d'utiliser cette fonctionnalité, passez en revue les exigences et les considérations relatives à la réplication interzone.
- Vous pouvez utiliser Azure NetApp Files avec des passerelles VPN et ExpressRoute redondantes par zone, si la fonctionnalité de mise en réseau standard est utilisée, que vous pourriez utiliser pour la résilience de la mise en réseau. Pour en savoir plus, consultez Topologies de réseau prises en charge.
- Azure Virtual WAN est pris en charge lorsqu'il est utilisé avec le réseau standard d'Azure NetApp Files. Pour en savoir plus, consultez Topologies de réseau prises en charge.
- Azure NetApp Files dispose d'un mécanisme de réplication interrégionale. Les considérations suivantes s'appliquent :
- Il n’est pas disponible dans toutes les régions.
- La réplication interrégionale des paires de régions de volumes Azure NetApp Files peut être différente des paires de régions de stockage Azure.
- Elle ne peut pas être utilisée en même temps que la réplication interzone
- Le basculement n'est pas transparent et le retour à la normale nécessite une reconfiguration du stockage.
- limites
- Il existe des limites dans la taille, les opérations d’entrée/sortie par seconde (IOPS), les Mo/s de bande passante pour les comptes de stockage et volumes de partage Azure Files et Azure NetApp Files. Si nécessaire, il est possible d’en utiliser plusieurs pour le même pool d’hôtes dans Virtual Desktop à l’aide de paramètres par groupe dans FSLogix. Toutefois, cette configuration nécessite davantage de planification et de configuration.
Le compte de stockage que vous utilisez pour les packages d’applications MSIX doit être distinct des autres comptes pour les conteneurs Profile et Office. Les options de géo-reprise d'activité après sinistre suivantes sont disponibles :
-
Un compte de stockage avec stockage géoredondant activé, dans la région primaire
- La région secondaire est fixe. Cette option ne convient pas pour l’accès local en cas de basculement de compte de stockage.
-
Deux comptes de stockage distincts, l’un dans la région primaire et l’autre dans la région secondaire (recommandé)
- Utilisez le stockage redondant interzone pour au moins la région primaire.
- Chaque pool d’hôtes de chaque région dispose d’un accès au stockage local aux packages MSIX avec une faible latence.
- Copiez deux fois les packages MSIX dans les deux emplacements et inscrivez les packages deux fois dans les deux pools hôtes. Affectez des utilisateurs aux groupes d’applications à deux reprises.
FSLogix
Microsoft vous recommande d’utiliser la configuration et les fonctionnalités FSLogix suivantes :
Si le contenu du conteneur Profile doit avoir une gestion BCDR distincte et a des exigences différentes par rapport au conteneur Office, vous devez les fractionner.
- Le conteneur Office contient uniquement du contenu mis en cache qui peut être reconstruit ou rempli à nouveau à partir de la source en cas de sinistre. Avec le conteneur Office, vous n’avez peut-être pas besoin de conserver des sauvegardes, ce qui peut réduire les coûts.
- Lorsque vous utilisez différents comptes de stockage, vous pouvez uniquement activer les sauvegardes sur le conteneur Profile. Vous devez également disposer de différents paramètres tels que la période de rétention, le stockage utilisé, la fréquence et le RTO/RPO.
Cache cloud est un composant FSLogix dans lequel vous pouvez spécifier plusieurs emplacements de stockage de profil et répliquer de manière asynchrone les données de profil, sans compter sur des mécanismes de réplication de stockage sous-jacents. Si le premier emplacement de stockage tombe en panne ou n'est pas accessible, Cloud Cache bascule automatiquement vers l'utilisation de l'emplacement secondaire et ajoute ainsi une couche de résilience. Utilisez Cache cloud pour répliquer les conteneurs Profile et Office entre différents comptes de stockage dans les régions primaires et secondaires.
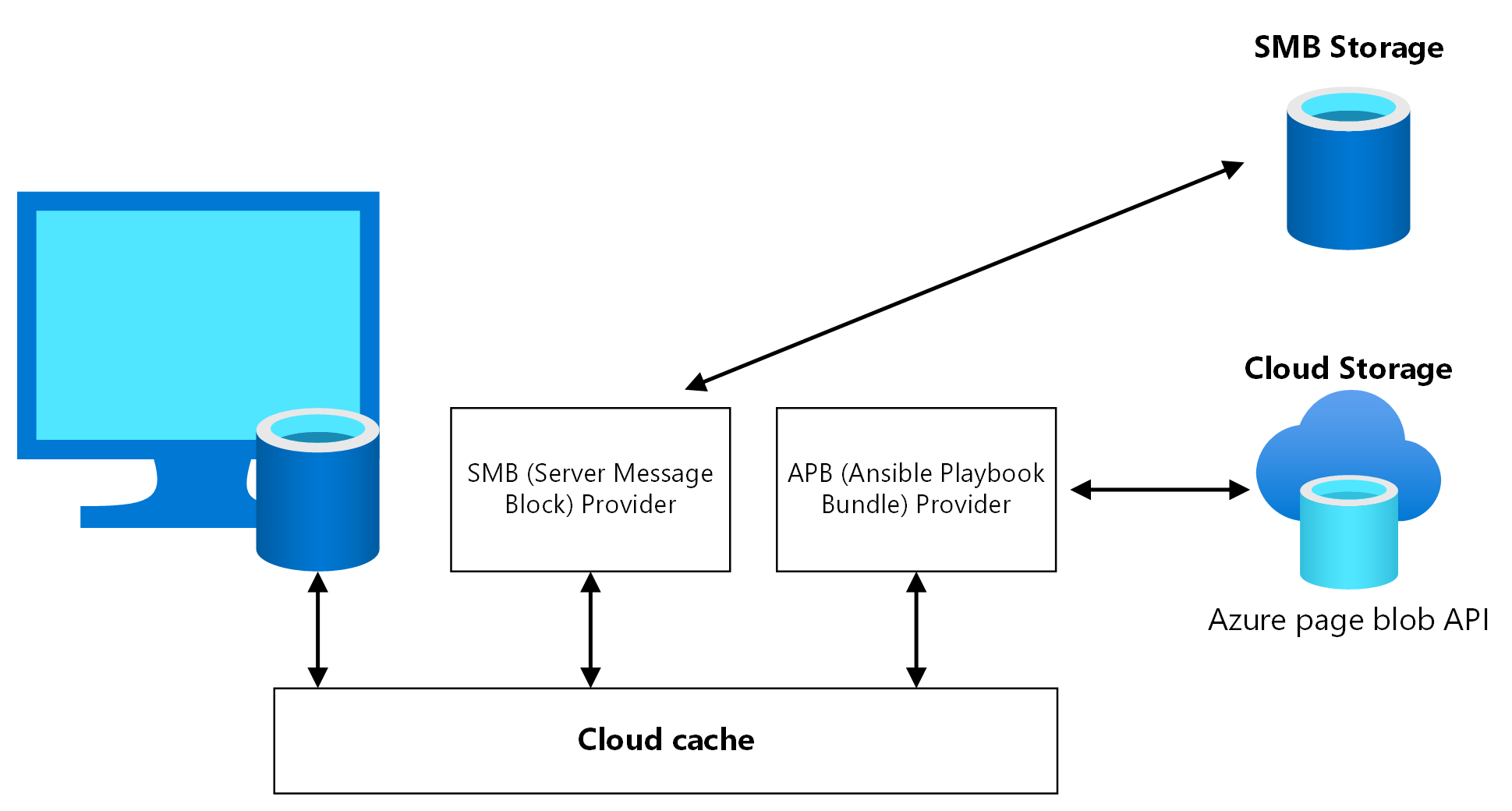
Vous devez activer Cache cloud deux fois dans le registre de machines virtuelles hôte de la session, une fois pour le conteneur Profile et une fois pour le conteneur Office. Il est possible de ne pas activer Cache cloud pour le conteneur Office, mais ne pas l’activer peut entraîner une erreur d’alignement des données entre la région de reprise d'activité après sinistre primaire et la région secondaire en cas de basculement et de restauration automatique. Testez attentivement ce scénario avant de l’utiliser en production.
Cache cloud est compatible avec les paramètres de fractionnement de profil et par groupe. Les paramètres par groupe nécessitent une conception et une planification minutieuses des groupes active directory et de l’appartenance. Vous devez vous assurer que chaque utilisateur fait partie d’un groupe exactement et que ce groupe est utilisé pour accorder l’accès aux pools d’hôtes.
Le paramètre CCDLocations spécifié dans le registre pour le pool d'hôtes dans la région de reprise après sinistre secondaire est inversé dans l'ordre, par rapport aux paramètres de la région principale. Pour plus d’informations, consultez Tutoriel : Configurer Cache cloud pour rediriger des conteneurs Profile ou un conteneur Office vers plusieurs fournisseurs.
Conseil
Cet article se concentre sur un scénario spécifique. D'autres scénarios sont décrits dans les articles Options de haute disponibilité pour FSLogix et Options de continuité des activités et de reprise après sinistre pour FSLogix.

L’exemple suivant montre une configuration de Cache cloud et des clés de Registre associées :
Région primaire = Europe Nord
URI du compte de stockage du conteneur Profile = \northeustg1\profiles
- Chemin d’accès à la clé de Registre = HKEY_LOCAL_MACHINE > SOFTWARE > FSLogix > Profiles
- Valeur de CCDLocations = type=smb,connectionString=\northeustg1\profiles;type=smb,connectionString=\westeustg1\profiles
Notes
Si vous avez précédemment téléchargé les modèles FSLogix, vous pouvez effectuer les mêmes configurations via la console de gestion des stratégies de groupe Active Directory. Pour plus d’informations sur la configuration de l’objet stratégie de groupe pour FSLogix, reportez-vous au guide, Utiliser des fichiers de modèle de stratégie de groupe FSLogix.
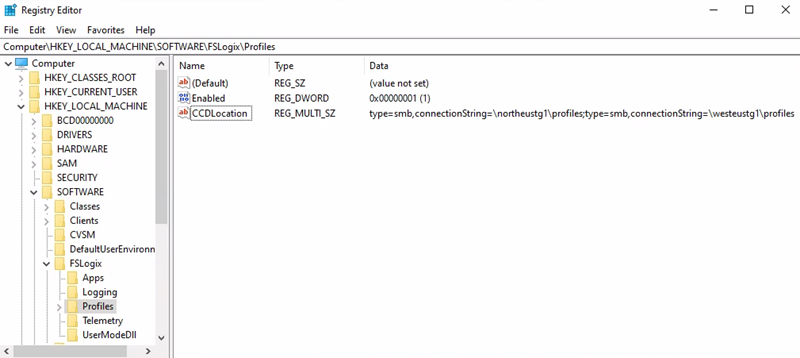
URI du compte de stockage du conteneur Office = \northeustg2\odcf
Chemin d’accès à la clé de Registre = HKEY_LOCAL_MACHINE > SOFTWARE >Policy > FSLogix > ODFC
Valeur de CCDLocations = type=smb,connectionString=\northeustg2\odfc;type=smb,connectionString=\westeustg2\odfc
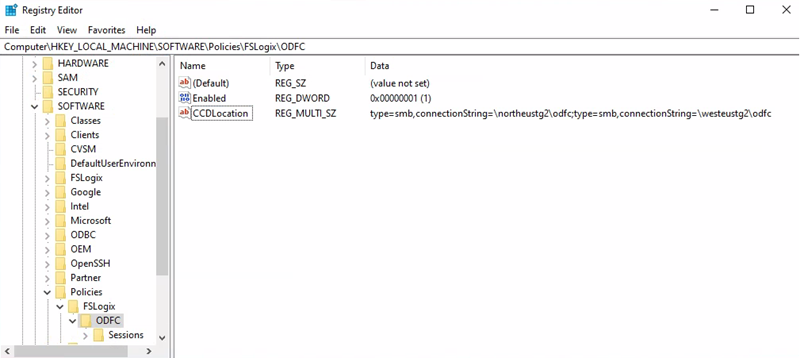


Notes
Dans les captures d’écran ci-dessus, toutes les clés de Registre recommandées pour FSLogix et Cache cloud sont signalées par souci de concision et de simplicité. Si vous souhaitez obtenir plus d’informations, consultez Exemples de configuration FSLogix.
Région secondaire = Europe Ouest
- URI du compte de stockage du conteneur Profile = \westeustg1\profiles
- Chemin d’accès à la clé de Registre = HKEY_LOCAL_MACHINE > SOFTWARE > FSLogix > Profiles
- Valeur de CCDLocations = type=smb,connectionString=\westeustg1\profiles;type=smb,connectionString=\northeustg1\profiles
- URI du compte de stockage du conteneur Office = \westeustg2\odcf
- Chemin d’accès à la clé de Registre = HKEY_LOCAL_MACHINE > SOFTWARE >Policy > FSLogix > ODFC
- Valeur de CCDLocations = type=smb,connectionString=\westeustg2\odfc;type=smb,connectionString=\northeustg2\odfc
Réplication de Cache cloud
La configuration de Cache cloud et les mécanismes de réplication garantissent la réplication des données de profil entre différentes régions avec une perte de données minimale. Étant donné que le même fichier de profil utilisateur peut être ouvert en mode ReadWrite par un seul processus, l’accès simultané doit être évité, de sorte que les utilisateurs ne doivent pas ouvrir de connexion aux deux pools d’hôtes en même temps.

Téléchargez un fichier Visio de cette architecture.
Dataflow
Un utilisateur de Virtual Desktop lance le client Virtual Desktop, puis ouvre un bureau publié ou une application Remote App attribuée au pool d'hôtes de la région primaire.
FSLogix récupère les conteneurs Profile et Office de l’utilisateur, puis monte le VHD/X de stockage sous-jacent à partir du compte de stockage situé dans la région primaire.
En même temps, le composant Cache cloud initialise la réplication entre les fichiers de la région primaire et les fichiers de la région secondaire. Pour ce processus, Cache cloud dans la région primaire acquiert un verrou exclusif en lecture-écriture sur ces fichiers.
Le même utilisateur Virtual Desktop souhaite maintenant lancer une autre application publiée affectée sur le pool d’hôtes de la région secondaire.
Le composant FSLogix s’exécutant sur l’hôte de session Virtual Desktop dans la région secondaire tente de monter les fichiers VHD/X du profil utilisateur à partir du compte de stockage local. Toutefois, le montage échoue, car ces fichiers sont verrouillés par le composant Cache cloud s’exécutant sur l’hôte de session Virtual Desktop dans la région primaire.
Dans la configuration FSLogix et Cache cloud par défaut, l’utilisateur ne peut pas se connecter et une erreur est suivie dans les journaux de diagnostic FSLogix, ERROR_LOCK_VIOLATION 33 (0x21).


Identité
L’une des dépendances les plus importantes pour Virtual Desktop est la disponibilité de l’identité utilisateur. Pour accéder à des bureaux virtuels distants complets et à des applications distantes à partir de vos hôtes de session, vos utilisateurs doivent pouvoir s'authentifier. Microsoft Entra ID est le service d’identité cloud centralisé de Microsoft qui permet de le faire. Microsoft Entra ID est toujours utilisé pour authentifier les utilisateurs pour Virtual Desktop. Les hôtes de la session peuvent rejoindre le même locataire Microsoft Entra ou un domaine Active Directory en utilisant Active Directory Domain Services (AD DS) ou Microsoft Entra Domain Services, ce qui vous offre un choix d’options de configuration flexibles.
Microsoft Entra ID
- Il s’agit d’un service multirégion et résilient global avec une haute disponibilité. Aucune autre action n’est nécessaire dans ce contexte dans le cadre d’un plan BCDR Virtual Desktop.
Services de domaine Active Directory
- Pour qu’Active Directory Domain Services soit résilient et hautement disponible, même en cas de sinistre à l’échelle de la région, vous devez déployer au moins deux contrôleurs de domaine dans la région Azure principale. Ces contrôleurs de domaine doivent se trouver dans différentes zones de disponibilité si possible et vous devez garantir une réplication appropriée avec l’infrastructure dans la région secondaire et éventuellement localement. Vous devez créer au moins un contrôleur de domaine dans la région secondaire avec un catalogue global et des rôles DNS. Pour plus d’informations, consultez Déployer des services de domaine Active Directory (AD DS) dans un réseau virtuel Azure.
Microsoft Entra Connect
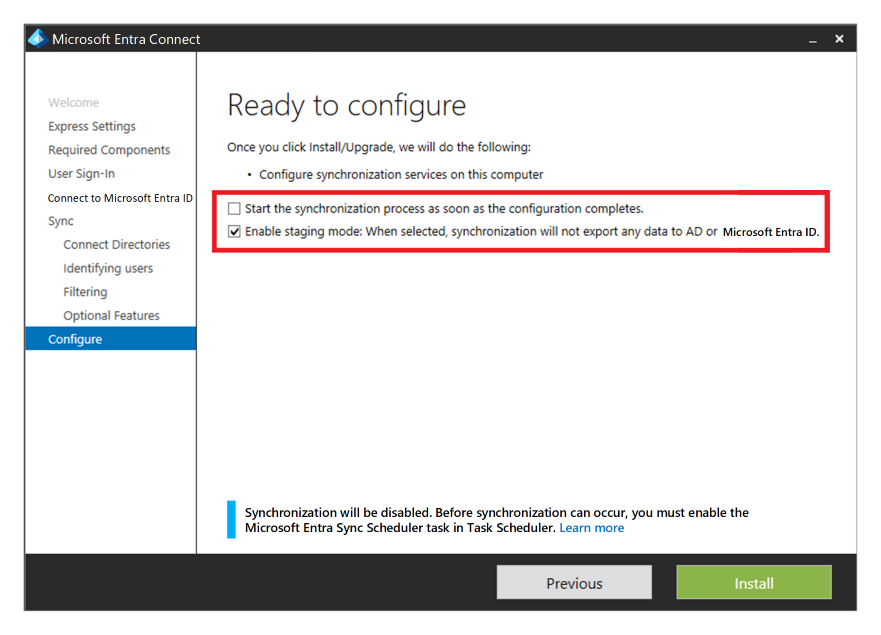
Si vous utilisez Microsoft Entra ID avec Active Directory Domain Services, puis Microsoft Entra Connect pour synchroniser les données d’identité utilisateur entre Active Directory Domain Services et Microsoft Entra ID, vous devez prendre en compte la résilience et la récupération de ce service pour la protection contre un sinistre permanent.
Vous pouvez fournir une haute disponibilité et une reprise d’activité après sinistre en installant une deuxième instance du service dans la région secondaire et en activant le mode intermédiaire.
En cas de reprise, l’administrateur est tenu de promouvoir l’instance secondaire en la supprimant du mode intermédiaire. Il doit suivre la même procédure que pour placer un serveur en mode intermédiaire. Les informations d’identification de l’administrateur général Microsoft Entra sont nécessaires pour effectuer cette configuration.
Microsoft Entra Domain Services
- Vous pouvez utiliser Microsoft Entra Domain Services dans certains scénarios comme alternative à Active Directory Domain Services.
- Il offre une haute disponibilité.
- Si la géo-reprise d'activité après sinistre est dans l’étendue de votre scénario, vous devez déployer un autre réplica dans la région Azure secondaire à l’aide d’un jeu de réplicas. Vous pouvez également utiliser cette fonctionnalité pour augmenter la haute disponibilité dans la région primaire.
Diagrammes d’architecture
Pool d’hôtes personnel

Téléchargez un fichier Visio de cette architecture.
Pool d’hôtes groupé

Téléchargez un fichier Visio de cette architecture.
Basculement et restauration automatique
Scénario de pool d’hôtes personnel
Notes
Seul le modèle actif-passif est couvert dans cette section : un modèle actif-actif ne nécessite aucun basculement ni aucune intervention de l’administrateur.
Le basculement et la restauration automatique pour un pool d’hôtes personnel sont différents, car il n’y a pas de Cache cloud ni de stockage externe utilisé pour les conteneurs Profile et Office. Vous pouvez toujours utiliser la technologie FSLogix pour enregistrer les données dans un conteneur à partir de l’hôte de la session. Il n’existe aucun pool d’hôtes secondaire dans la région de reprise d’activité après sinistre. Il n’est donc pas nécessaire de créer davantage d’espaces de travail et de ressources Virtual Desktop pour répliquer et aligner. Vous pouvez utiliser Site Recovery pour répliquer des machines virtuelles hôtes de la session.
Vous pouvez utiliser Site Recovery dans plusieurs scénarios différents. Pour Virtual Desktop, utilisez l’architecture de la reprise d’activité après sinistre Azure vers Azure dans Azure Site Recovery.
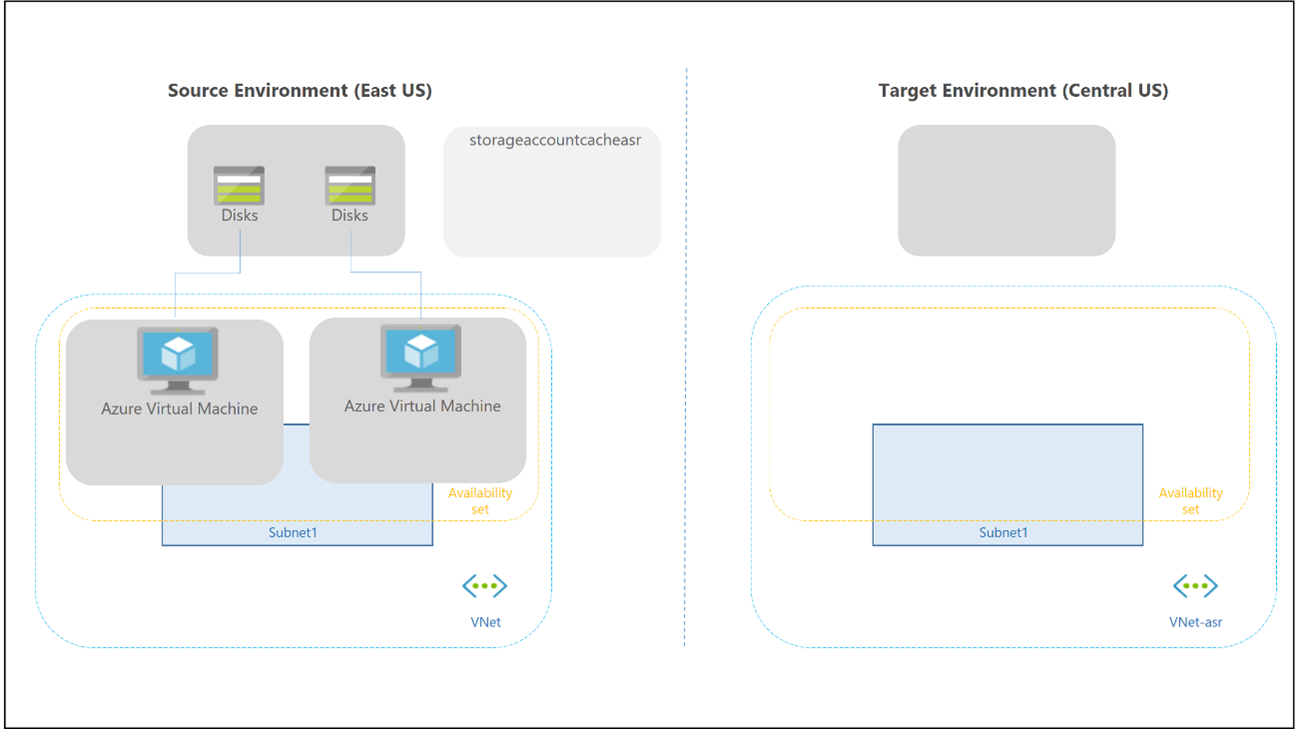
Les considérations et recommandations suivantes s’appliquent :
- Le basculement Site Recovery n’est pas automatique : un administrateur doit le déclencher à l’aide du portail Azure ou powerShell/API.
- Vous pouvez créer un script et automatiser l’ensemble de la configuration et des opérations de Site Recovery à l’aide de PowerShell.
- Site Recovery a un RTO déclaré dans son Contrat de niveau de service (SLA). La plupart du temps, Site Recovery peut basculer des machines virtuelles en quelques minutes.
- Vous pouvez utiliser Site Recovery avec Sauvegarde Azure. Pour plus d’informations, consultez Prise en charge de l’utilisation de Site Recovery avec Sauvegarde Azure.
- Vous devez activer Site Recovery au niveau de la machine virtuelle, car il n’existe aucune intégration directe dans l’expérience du portail Virtual Desktop. Vous devez également déclencher le basculement et la restauration automatique au niveau de la machine virtuelle unique.
- Site Recovery fournit une fonctionnalité de test de basculement dans un sous-réseau distinct pour les machines virtuelles Azure générales. N'utilisez pas cette fonctionnalité pour les machines virtuelles Virtual Desktop, car vous auriez deux hôtes de session Virtual Desktop identiques appelant le plan de contrôle du service en même temps.
- Site Recovery ne gère pas les extensions de machine virtuelle pendant la réplication. Si vous activez les extensions personnalisées pour les machines virtuelles hôtes de la session Virtual Desktop, vous devez réactiver les extensions après le basculement ou la restauration automatique. Les extensions intégrées Virtual Desktop joindomain et Microsoft.PowerShell.DSC sont utilisées uniquement lorsqu’une machine virtuelle hôte de la session est créée. Cela ne pose aucun problème de les perdre après un premier basculement.
- Veillez à consulter Matrice de prise en charge pour la reprise d’activité après sinistre de machines virtuelles Azure entre des régions Azure et vérifiez les exigences, les limitations et la matrice de compatibilité pour le scénario de reprise d’activité après sinistre de Site Recovery Azure vers Azure, en particulier les versions de système d’exploitation prises en charge.
- Lorsque vous basculez une machine virtuelle d’une région vers une autre, la machine virtuelle démarre dans la région de reprise d’activité après sinistre cible dans un état non protégé. La restauration automatique est possible, mais l’utilisateur doit reprotéger des machines virtuelles dans la région secondaire, puis réactiver la réplication vers la région primaire.
- Exécutez des tests périodiques des procédures de basculement et de restauration automatique. Documentez ensuite une liste exacte des étapes et des actions de récupération en fonction de votre environnement Virtual Desktop spécifique.
Scénario de pool d’hôtes groupé
L’une des caractéristiques souhaitées d’un modèle de reprise d’activité après sinistre actif-actif est que l’intervention de l’administrateur n’est pas nécessaire pour récupérer le service en cas de panne. Les procédures de basculement doivent être nécessaires uniquement dans une architecture active-passive.
Dans un modèle actif-passif, la région de reprise après sinistre secondaire doit être inactive, avec un minimum de ressources configurées, et active. La configuration doit être alignée sur la région primaire. En cas de basculement, les réaffectations pour tous les utilisateurs à tous les groupes de bureaux et d’applications pour les applications distantes dans le pool d’hôtes de reprise d’activité après sinistre secondaire se produisent en même temps.
Il est possible d’avoir un modèle actif-actif et un basculement partiel. Si le pool d'hôtes n'est utilisé que pour fournir des groupes de postes de travail et d'applications, vous pouvez répartir les utilisateurs dans plusieurs groupes Active Directory qui ne se chevauchent pas et les réaffecter à des groupes de postes de travail et d'applications dans les pools d'hôtes de reprise après sinistre primaire ou secondaire. Un utilisateur ne doit pas avoir accès aux deux pools d’hôtes en même temps. S’il existe plusieurs groupes d’applications et applications, les groupes d’utilisateurs que vous utilisez pour affecter des utilisateurs peuvent se chevaucher. Dans ce cas, il est difficile d’implémenter une stratégie active/active. Chaque fois qu’un utilisateur démarre une application distante dans le pool d’hôtes principal, le profil utilisateur est chargé par FSLogix sur une machine virtuelle hôte de la session. La tentative de faire de même sur le pool d’hôtes secondaire peut entraîner un conflit sur le disque de profil sous-jacent.
Avertissement
Par défaut, les paramètres de Registre FSLogix interdisent l’accès simultané au même profil utilisateur à partir de plusieurs sessions. Dans ce scénario BCDR, vous ne devez pas modifier ce comportement et laisser la valeur 0 pour la clé de Registre ProfileType.
Voici la situation initiale et les hypothèses de configuration :
- Les pools d’hôtes dans la région primaire et les régions de reprise d’activité après sinistre secondaires sont alignés pendant la configuration, y compris Cache cloud.
- Dans les pools d’hôtes, les groupes d’applications de bureau DAG1 et d’applications distantes APPG2 et APPG3 sont proposés aux utilisateurs.
- Dans le pool d’hôtes de la région primaire, les groupes d’utilisateurs Active Directory GRP1, GRP2 et GRP3 sont utilisés pour affecter des utilisateurs à DAG1, APPG2 et APPG3. Ces groupes peuvent avoir des appartenances utilisateur qui se chevauchent, mais étant donné que le modèle utilise ici le modèle actif-passif avec basculement complet, ce n’est pas un problème.
Les étapes suivantes décrivent le moment où un basculement se produit, après une reprise d’activité après sinistre planifiée ou non planifiée.
- Dans le pool d’hôtes principal, supprimez les affectations d’utilisateurs par les groupes GRP1, GRP2 et GRP3 pour les groupes d’applications DAG1, APPG2 et APPG3.
- Il existe une déconnexion forcée pour tous les utilisateurs connectés du pool d’hôtes principal.
- Dans le pool d’hôtes secondaire, où les mêmes groupes d’applications sont configurés, vous devez accorder à l’utilisateur l’accès à DAG1, APPG2 et APPG3 à l’aide des groupes GRP1, GRP2 et GRP3.
- Examinez et ajustez la capacité du pool d’hôtes dans la région secondaire. Dans ce cas, vous pouvez vous appuyer sur un plan d'autoscale pour mettre automatiquement sous tension les hôtes de session. Vous pouvez également démarrer manuellement les ressources nécessaires.
Les étapes et le flux de restauration automatique sont similaires et vous pouvez exécuter l’intégralité du processus plusieurs fois. Cache cloud et la configuration des comptes de stockage garantissent que les données des conteneurs Profile et Office sont répliquées. Avant la reprise sur incident, assurez-vous que la configuration du pool d'hôtes et les ressources de calcul sont récupérées. Pour la partie stockage, s'il y a une perte de données dans la région primaire, Cloud Cache réplique les données des conteneurs Profile et Office à partir du stockage de la région secondaire.
Il est également possible d’implémenter un plan de test de basculement avec quelques modifications de configuration, sans affecter l’environnement de production.
- Créez quelques comptes d’utilisateur dans Active Directory pour la production.
- Créez un groupe Active Directory nommé GRP-TEST et attribuez des utilisateurs.
- Attribuez l’accès à DAG1, APPG2 et APPG3 à l’aide du groupe GRP-TEST.
- Donnez des instructions aux utilisateurs du groupe GRP-TEST pour tester les applications.
- Testez la procédure de basculement à l’aide du groupe GRP-TEST pour supprimer l’accès du pool d’hôtes principal et accorder l’accès au pool de reprise d’activité après sinistre secondaire.
Recommandations importantes :
- Automatisez le processus de basculement à l’aide de PowerShell, d’Azure CLI ou de tout autre API ou outil disponible.
- Testez régulièrement l’intégralité de la procédure de basculement et de restauration automatique.
- Effectuez une vérification régulière de l’alignement de la configuration pour vous assurer que les pools hôtes dans la région de sinistre principale et secondaire sont synchronisés.
Sauvegarde
Ce guide suppose qu’il existe une distinction des profils et une séparation des données entre les conteneurs Profile et les conteneurs Office. FSLogix autorise cette configuration et l’utilisation de comptes de stockage distincts. Une fois dans des comptes de stockage distincts, vous pouvez utiliser différentes stratégies de sauvegarde.
Pour ODFC Container, si le contenu ne représente que des données mises en cache qui peuvent être reconstruites à partir d’un magasin de données en ligne comme Microsoft 365, il n’est pas nécessaire de sauvegarder les données.
S’il est nécessaire de sauvegarder des données de conteneur Office, vous pouvez utiliser un stockage moins coûteux ou une autre fréquence de sauvegarde et période de rétention.
Pour un type de pool d’hôtes personnel, vous devez exécuter la sauvegarde au niveau de la machine virtuelle hôte de la session. Cette méthode s’applique uniquement si les données sont stockées localement.
Si vous utilisez OneDrive et la redirection de dossiers connus, la nécessité d’enregistrer des données dans le conteneur peut disparaître.
Notes
La sauvegarde OneDrive n’est pas prise en compte dans cet article et ce scénario.
Sauf s’il existe une autre exigence, la sauvegarde du stockage dans la région primaire doit être suffisante. La sauvegarde de l’environnement de reprise d’activité après sinistre n’est normalement pas utilisée.
Pour le partage Azure Files, utilisez Sauvegarde Azure.
- Pour le type de résilience du coffre, utilisez le stockage redondant interzone si le stockage de sauvegarde hors site ou région n’est pas requis. Si ces sauvegardes sont requises, utilisez le stockage géoredondant.
Azure NetApp Files fournit sa propre solution de sauvegarde intégrée.
- Veillez à vérifier la disponibilité des fonctionnalités de la région, ainsi que les exigences et les limitations.
Les comptes de stockage distincts utilisés pour MSIX doivent également être couverts par une sauvegarde si les référentiels de packages d’application ne peuvent pas être facilement reconstruits.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteurs principaux :
- Ben Martin Baur | Architecte de solution cloud
- Igor Pagliai | Ingénieur principal FastTrack for Azure (FTA)
Autres contributeurs :
- Nelson Del Villar | Architecte Solution cloud, Infrastructure Azure Core
- Jason Martinez | Technical Writer
Étapes suivantes
- Plan de reprise après sinistre pour les postes de travail virtuels
- BCDR pour Virtual Desktop - Cadre d'adoption du cloud
- Cache cloud pour créer résilience et disponibilité