Améliorer la résilience en répliquant votre espace de travail Log Analytics entre différentes régions (préversion)
La réplication de votre espace de travail Log Analytics entre différentes régions améliore la résilience en vous permettant d’effectuer un basculement manuel vers l’espace de travail répliqué, et de poursuivre les opérations en cas de défaillance régionale. Cet article explique comment fonctionne la réplication d’un espace de travail Log Analytics, comment répliquer votre espace de travail, comment alterner entre le basculement manuel et la restauration manuelle de vos espaces de travail répliqués, et comment décider du moment où l’opération doit être effectuée.
Voici une vidéo qui fournit une vue d’ensemble rapide du fonctionnement de la réplication d’un espace de travail Log Analytics :
Important
Bien que nous utilisions parfois le terme basculement, par exemple dans l’appel d’API, le basculement est également couramment utilisé pour décrire un processus automatique. Cet article utilise donc l’expression « basculement manuel » pour souligner le fait que le basculement vers l’espace de travail répliqué est une action que vous déclenchez manuellement.
Fonctionnement de la réplication d’espace de travail Log Analytics
Votre espace de travail et votre région d’origine sont appelés espace de travail principal et région primaire. L’espace de travail répliqué et la région de remplacement sont appelés espace de travail et région secondaires.
Le processus de réplication d’espace de travail crée une instance de votre espace de travail dans la région secondaire. Le processus crée l’espace de travail secondaire avec la même configuration que votre espace de travail principal. Azure Monitor mettra automatiquement à jour l’espace de travail secondaire en fonction des changements que vous apporterez à la configuration de votre espace de travail principal.
L’espace de travail secondaire est un espace de travail « fantôme » utilisé uniquement à des fins de résilience. Vous ne pouvez pas voir l’espace de travail secondaire dans le portail Azure, ni le gérer ou y accéder directement.
Quand vous activez la réplication d’espace de travail, Azure Monitor envoie également les nouveaux journaux ingérés dans votre espace de travail principal à votre région secondaire. Les journaux que vous ingérez dans l’espace de travail avant d’activer la réplication de l’espace de travail ne sont pas copiés.
Si une panne affecte votre région primaire, vous pouvez basculer manuellement vers votre région secondaire, et rerouter toutes les requêtes d’ingestion et d’interrogation vers votre région secondaire. Une fois qu’Azure a atténué la panne et que votre espace de travail principal est à nouveau sain, vous pouvez effectuer une restauration manuelle vers votre région primaire.
Quand vous effectuez un basculement manuel, l’espace de travail secondaire devient actif, et votre espace de travail principal devient inactif. Azure Monitor ingère ensuite les nouvelles données via le pipeline d’ingestion de votre région secondaire, et non celui de la région primaire. Quand vous effectuez un basculement manuel vers votre région secondaire, Azure Monitor réplique toutes les données que vous ingérez de la région secondaire vers la région primaire. Le processus est asynchrone et n’affecte pas la latence d’ingestion.
Remarque
Une fois que vous avez effectué un basculement manuel vers la région secondaire, si la région primaire ne peut pas traiter les données de journal entrantes, Azure Monitor met en mémoire tampon les données dans la région secondaire pendant 11 jours au maximum. Au cours des quatre premiers jours, Azure Monitor retente automatiquement de répliquer les données à intervalles réguliers.

Protection contre la perte de données en transit lors d’une panne régionale
Azure Monitor dispose de plusieurs mécanismes pour garantir que les données en transit ne sont pas perdues en cas de défaillance de la région primaire.
Azure Monitor protège les données qui atteignent le point de terminaison d’ingestion de la région principale lorsque le pipeline de la région principale n’est pas disponible pour traiter les données. Lorsque le pipeline devient disponible, il continue de traiter les données en transit, et Azure Monitor ingère et réplique les données dans la région secondaire.
Si le point de terminaison d’ingestion de la région principale n’est pas disponible, Azure Monitor Agent retente régulièrement d’envoyer les données de journal au point de terminaison. Le point de terminaison d’ingestion des données dans la région secondaire commence à recevoir les données des agents quelques minutes après le déclenchement du basculement.
Si vous écrivez votre propre client pour envoyer des données de journal à votre espace de travail Log Analytics, assurez-vous que le client gère les demandes d’ingestion qui échouent.
Points à prendre en considération pour le déploiement
La réplication des espaces de travail Log Analytics liés à un cluster dédié n’est pas prise en charge pour le moment.
L’opération de vidage, qui supprime les enregistrements d’un espace de travail, permet de supprimer définitivement les enregistrements appropriés des espaces de travail principal et secondaire. Si l’une des instances de l’espace de travail n’est pas disponible, l’opération de vidage échoue.
Azure Monitor prend en charge l’interrogation de la région inactive. Les alertes basées sur des requêtes continuent de fonctionner lorsque vous basculez entre les régions, sauf si le service Alertes de la région active ne fonctionne pas correctement ou si les règles d'alerte ne sont pas disponibles. La réplication des règles d’alerte entre les régions n’est pas prise en charge pour le moment.
Quand vous activez la réplication des espaces de travail qui interagissent avec Sentinel, la réplication complète des données Watchlist et Threat Intelligence vers l’espace de travail secondaire peut prendre jusqu’à 12 jours.
Les opérations de gestion de l'espace de travail ne peuvent pas être lancées pendant le basculement, notamment :
- Changer les paramètres pour la conservation des données de l’espace de travail, le niveau tarifaire, la limite quotidienne, etc.
- Changer les paramètres réseau
- Changer de schéma en utilisant de nouveaux journaux personnalisés, ou en connectant des journaux de plateforme issus de nouveaux fournisseurs de ressources, par exemple en envoyant des journaux de diagnostic à partir d’un nouveau type de ressource
La capacité de ciblage de solution de l’agent Log Analytics hérité n’est pas prise en charge durant le basculement manuel. Lors du basculement, les données de solution sont ingérées à partir de tous les agents.
Le processus de basculement met à jour vos enregistrements DNS (Domain Name System) pour rerouter toutes les requêtes d’ingestion vers votre région secondaire à des fins de traitement. Certains clients HTTP ont des « connexions persistantes », et peuvent prendre plus de temps pour récupérer le DNS mis à jour. Durant le basculement manuel, ces clients peuvent tenter d’ingérer des journaux via la région primaire pendant un certain temps. Vous pouvez ingérer des journaux dans votre espace de travail principal à l’aide de divers clients, notamment l’agent Log Analytics hérité, l’agent Azure Monitor, le code (à l’aide de l’API d’ingestion de journaux ou de l’API de collecte de données HTTP héritée) et d’autres services, tels que Microsoft Sentinel.
Ces fonctionnalités ne sont prises en charge actuellement ou sont uniquement prises en charge :
Fonctionnalité Support Plans de table Auxiliaire Non pris en charge. Azure Monitor ne réplique pas les données dans les tables ayant le plan de journaux Auxiliaire vers votre espace de travail secondaire. Par conséquent, ces données ne sont pas protégées contre la perte de données en cas de défaillance régionale. Elles ne sont pas non plus disponibles lorsque vous basculez vers votre espace de travail secondaire. Travaux de recherche, restauration Prise en charge partielle - Les opérations liées aux travaux de recherche et les opérations de restauration créent des tables, et les remplissent avec les résultats de la recherche ou les données restaurées. Une fois que vous avez activé la réplication d’espace de travail, les tables créées pour ces opérations sont répliquées vers votre espace de travail secondaire. Les tables remplies avant que vous n’activiez la réplication ne sont pas répliquées. Si ces opérations sont en cours d’exécution quand vous effectuez un basculement manuel, le résultat est inattendu. Elles peuvent s’exécuter correctement mais sans que la réplication ait lieu, ou elles peuvent échouer, en fonction de l’intégrité de votre espace de travail et du moment précis où le basculement manuel a lieu. Application Insights sur les espaces de travail Log Analytics Non pris en charge Insights de machine virtuelle Non pris en charge Container Insights Non pris en charge Liaisons privées Non pris en charge durant le basculement
Régions prises en charge
La réplication d’espace de travail est prise en charge pour les espaces de travail situés dans un ensemble limité de régions, organisées par groupes de régions (groupes de régions géographiquement adjacentes). Quand vous activez la réplication, sélectionnez une localisation secondaire dans la liste des régions prises en charge au sein du même groupe de régions que la localisation principale de l’espace de travail. Par exemple, un espace de travail situé dans la région Europe Ouest peut être répliqué vers Europe Nord, mais pas vers USA Ouest 2, car ces régions se trouvent dans des groupes de régions distincts.
Voici les groupes de régions et les régions pris en charge :
| Groupe de régions | Régions | Notes | ||
|---|---|---|---|---|
| Amérique du Nord | USA Est | La région USA Est ne peut pas répliquer vers ou depuis les régions USA Est 2 et USA Centre Sud. | ||
| USA Est 2 | La région USA Est 2 ne peut pas répliquer vers ou depuis les régions USA Est et USA Centre Sud. | |||
| USA Ouest | ||||
| USA Ouest 2 | ||||
| USA Centre | ||||
| États-Unis - partie centrale méridionale | La région USA Centre Sud ne peut pas répliquer vers ou depuis les régions USA Est et USA Est 2. | |||
| Canada central | ||||
| Europe | Europe Ouest | |||
| Europe Nord | ||||
| Sud du Royaume-Uni | ||||
| Ouest du Royaume-Uni | ||||
| Allemagne Centre-Ouest | ||||
| France Centre |
Exigences de résidence des données
Des clients différents ont des impératifs distincts pour la résidence des données. Il est donc important que vous contrôliez le lieu de stockage de vos données. Azure Monitor traite et stocke les journaux dans les régions primaire et secondaire de votre choix. Pour plus d’informations, consultez Régions prises en charge.
Prise en charge de Microsoft Sentinel et d'autres services
Divers services et fonctionnalités qui utilisent les espaces de travail Log Analytics sont compatibles avec la réplication d’espace de travail et le basculement manuel. Ces services et fonctionnalités continuent de fonctionner quand vous effectuez un basculement manuel vers l’espace de travail secondaire.
Par exemple, les problèmes de réseau régional qui entraînent une latence d’ingestion des journaux peuvent avoir un impact sur les clients Microsoft Sentinel. Les clients qui utilisent des espaces de travail répliqués peuvent effectuer un basculement manuel vers leur région secondaire pour continuer à utiliser leur espace de travail Log Analytics et Sentinel. Toutefois, si le problème réseau impacte l’intégrité du service Sentinel, le basculement manuel vers une autre région n’atténue pas le problème.
Certaines expériences Azure Monitor, notamment Application Insights et VM Insights, ne sont que partiellement compatibles avec la réplication d’espace de travail et le basculement manuel. Pour la liste complète, voir Considérations relatives au déploiement.
Modèle de tarification
Lorsque vous activez la réplication de l'espace de travail, vous êtes facturé pour la réplication de toutes les données que vous ingérez dans votre espace de travail.
Important
Si vous envoyez des données à votre espace de travail à l’aide de l’agent Azure Monitor, de l’API d’ingestion de journaux, d’Azure Event Hubs ou d’autres sources de données qui utilisent des règles de collecte de données, assurez-vous d’associer vos règles de collecte de données au point de terminaison de collecte de données de votre espace de travail. Cette association garantit que les données que vous ingérez sont répliquées vers votre espace de travail secondaire. Si vous n'associez pas vos règles de collecte de données au point de terminaison de collecte de données de l'espace de travail, vous êtes toujours facturé pour toutes les données que vous ingérez dans votre espace de travail, même si les données ne sont pas répliquées.
Autorisations requises
| Action | Autorisations requises |
|---|---|
| Activer la réplication d’espace de travail | Autorisations Microsoft.OperationalInsights/workspaces/write et Microsoft.Insights/dataCollectionEndpoints/write, telles que fournies par le rôle intégré Contributeur de monitoring, par exemple |
| Effectuer un basculement manuel et une restauration manuelle (déclencher un basculement et une restauration automatique) | les autorisations Microsoft.OperationalInsights/locations/workspaces/failover, Microsoft.OperationalInsights/workspaces/failback, Microsoft.Insights/dataCollectionEndpoints/triggerFailover/action et Microsoft.Insights/dataCollectionEndpoints/triggerFailback/action, telles qu’elles sont fournies par le rôle intégré de Contributeur de surveillance, par exemple |
| Vérifier l’état de l’espace de travail | Autorisations Microsoft.OperationalInsights/workspaces/read d’accès aux espaces de travail Log Analytics, telles que fournies par le rôle intégré Contributeur de monitoring, par exemple |
Activer et désactiver la réplication d’espace de travail
Vous activez et désactivez la réplication d’espace de travail à l’aide d’une commande REST. La commande déclenche une opération durable, ce qui signifie que l’application des nouveaux paramètres peut prendre quelques minutes. Une fois que vous avez activé la réplication, il peut s’écouler jusqu’à une heure avant le début de la réplication de toutes les tables (types de données). Ainsi, certains types de données peuvent commencer à se répliquer avant d’autres. Il peut s’écouler jusqu’à une heure avant le début de la réplication des changements que vous apportez aux schémas de table, une fois que vous avez activé la réplication d’espace de travail (par exemple les nouvelles tables de journaux personnalisés ou les champs personnalisés créés, ou les journaux de diagnostic configurés pour les nouveaux types de ressources).
Activer la réplication d’espace de travail
Pour activer la réplication sur votre espace de travail Log Analytics, utilisez la commande PUT suivante :
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": true,
"location": "<secondary_region>"
}
},
"location": "<primary_region>"
}
Où :
-
<subscription_id>: ID d’abonnement lié à votre espace de travail. -
<resourcegroup_name>: groupe de ressources qui contient votre ressource d’espace de travail Log Analytics. -
<workspace_name>: le nom de votre espace de travail. -
<primary_region>: région primaire de votre espace de travail Log Analytics. -
<secondary_region>: région dans laquelle Azure Monitor crée l’espace de travail secondaire.
Pour connaître les valeurs location prises en charge, consultez Régions prises en charge.
La commande PUT est une opération durable qui peut prendre un certain temps pour s’effectuer. Un appel réussi retourne un code d’état 200. Vous pouvez suivre l’état d’approvisionnement de votre requête, comme indiqué dans Vérifier l’état d’approvisionnement de la requête.
Vérifier l’état d’approvisionnement de la requête
Pour vérifier l’état d’approvisionnement de votre requête, exécutez la commande GET suivante :
GET
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
Où :
-
<subscription_id>: ID d’abonnement lié à votre espace de travail. -
<resourcegroup_name>: groupe de ressources qui contient votre ressource d’espace de travail Log Analytics. -
<workspace_name>: nom de votre espace de travail Log Analytics.
Utilisez la commande GET pour vérifier que l’état d’approvisionnement de l’espace de travail passe de Updating à Succeeded, et que la région secondaire est définie comme prévu.
Remarque
Quand vous activez la réplication des espaces de travail qui interagissent avec Sentinel, la réplication complète des données Watchlist et Threat Intelligence vers l’espace de travail secondaire peut prendre jusqu’à 12 jours.
Associer les règles de collecte de données au point de terminaison de collecte de données de l'espace de travail
L’agent Azure Monitor, l’API d’ingestion de journaux et Azure Event Hubs collectent des données et les envoient à la destination que vous spécifiez en fonction de la façon dont vous avez configuré vos règles de collecte de données (DCR).
Si vous avez des règles de collecte de données qui envoient des données à votre espace de travail principal, vous devez associer les règles à un point de terminaison de collecte de données (DCE) système, qu’Azure Monitor crée quand vous activez la réplication d’espace de travail. Le nom du point de terminaison de collecte de données de l’espace de travail est identique à votre ID d’espace de travail. Seules les règles de collecte de données que vous associez au point de terminaison de collecte de données de l'espace de travail activent la réplication et le basculement. Ce comportement vous permet de spécifier l’ensemble des flux de journaux à répliquer, ce qui vous permet de contrôler les coûts de réplication.
Pour répliquer les données que vous collectez à l'aide de règles de collecte de données, associez vos règles de collecte de données au point de terminaison de collecte de données de l'espace de travail :
Dans le portail Azure, sélectionnez Règles de collecte de données.
Dans l’écran Règles de collecte de données, sélectionnez une règle de collecte de données qui envoie les données à votre espace de travail Log Analytics principal.
Sur la page Présentation de la règle de collecte de données, sélectionnez Configurer DCE et sélectionnez le point de terminaison de collecte de données de l'espace de travail dans la liste disponible :
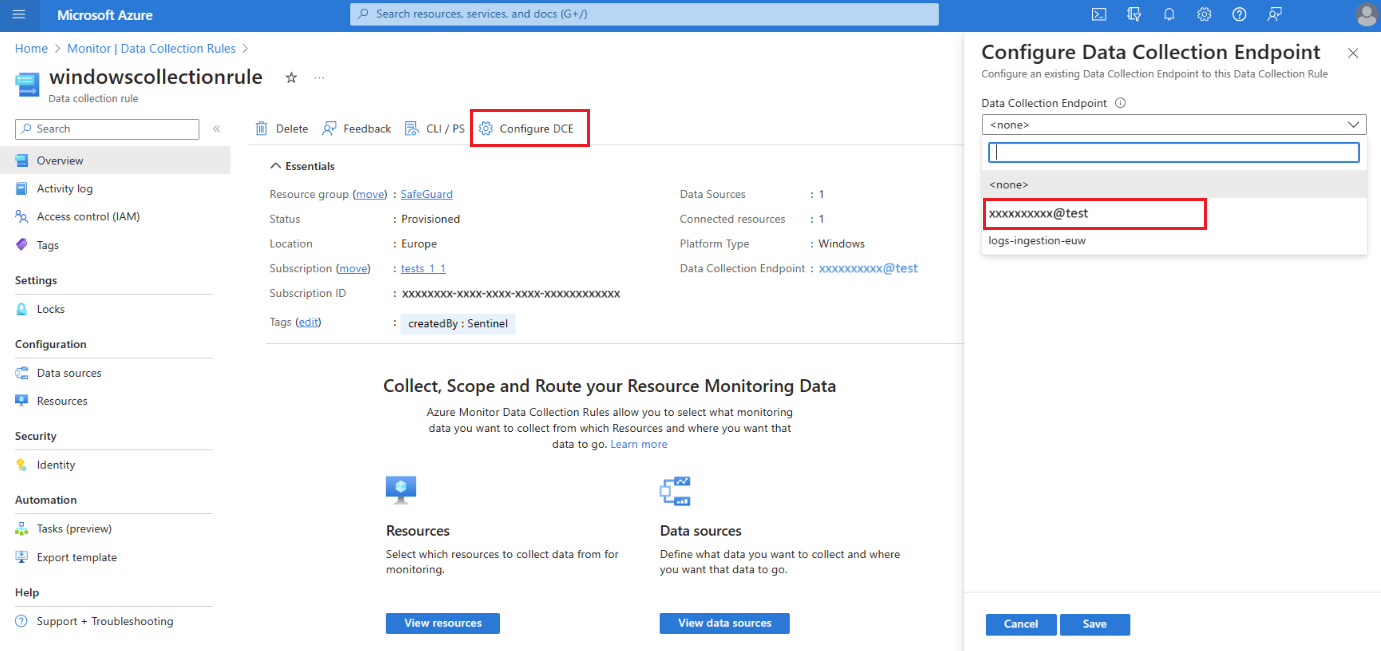 Pour plus d’informations sur le point de terminaison de collecte de données (DCE) système, consultez les propriétés de l’objet d’espace de travail.
Pour plus d’informations sur le point de terminaison de collecte de données (DCE) système, consultez les propriétés de l’objet d’espace de travail.

Important
Les règles de collecte de données connectées à un point de terminaison de collecte de données d'espace de travail peuvent cibler uniquement cet espace de travail spécifique. Les règles de collecte de données ne doivent pas cibler d’autres destinations, par exemple d’autres espaces de travail ou comptes Stockage Azure.
Désactiver la réplication d’espace de travail
Pour désactiver la réplication d’un espace de travail, utilisez la commande PUT suivante :
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": false
}
},
"location": "<primary_region>"
}
Où :
-
<subscription_id>: ID d’abonnement lié à votre espace de travail. -
<resourcegroup_name>: groupe de ressources qui contient votre ressource d’espace de travail. -
<workspace_name>: le nom de votre espace de travail. -
<primary_region>: région primaire de votre espace de travail.
La commande PUT est une opération durable qui peut prendre un certain temps pour s’effectuer. Un appel réussi retourne un code d’état 200. Vous pouvez suivre l’état d’approvisionnement de votre requête, comme indiqué dans Vérifier l’état d’approvisionnement de la requête.
Effectuer un monitoring de l’intégrité de l’espace de travail et des services
La latence d’ingestion ou les échecs de requête sont des exemples de problèmes qui peuvent souvent être gérés par un basculement vers votre région secondaire. Ces problèmes peuvent être détectés à l’aide des notifications Service Health et des requêtes de journal.
Les notifications Service Health sont utiles pour les problèmes liés au service. Pour identifier les problèmes ayant un impact sur votre espace de travail spécifique (mais peut-être pas sur l’ensemble du service), vous pouvez utiliser d’autres mesures :
- Créer des alertes basées sur l’intégrité de la ressource d’espace de travail
- Définir vos propres seuils pour les métriques d’intégrité de l’espace de travail
- Créez vos propres requêtes de monitoring servant d’indicateurs d’intégrité personnalisés pour votre espace de travail, comme indiqué dans Effectuer un monitoring des performances de l’espace de travail à l’aide de requêtes, pour :
- Mesurer la latence d’ingestion par table
- Déterminer si la source de la latence provient des agents de collecte ou du pipeline d’ingestion
- Effectuer un monitoring des anomalies liées au volume d’ingestion par table et par ressource
- Effectuer un monitoring du taux de réussite des requêtes par table, par utilisateur ou par ressource
- Créer des alertes basées sur vos requêtes
Remarque
Vous pouvez également utiliser des requêtes de journal pour effectuer un monitoring de votre espace de travail secondaire. Toutefois, n’oubliez pas que la réplication des journaux s’effectue dans le cadre d’opérations par lots. La latence mesurée peut fluctuer, et n’indique aucun problème d’intégrité au niveau de votre espace de travail secondaire. Pour plus d’informations, consultez Auditer l’espace de travail inactif.
Basculer manuellement vers votre espace de travail secondaire
Durant le basculement manuel, la plupart des opérations fonctionnent de la même manière que quand vous utilisez l’espace de travail principal et la région primaire. Toutefois, certaines opérations ont un comportement légèrement différent ou sont bloquées. Pour plus d’informations, consultez Considérations relatives au déploiement.
Quand dois-je effectuer un basculement manuel ?
Vous décidez quand effectuer un basculement manuel vers votre espace de travail secondaire, et quand effectuer une restauration manuelle vers votre espace de travail principal en fonction du monitoring continu des performances et de l’intégrité ainsi que des standards et de la configuration requise de votre système.
Il existe plusieurs points à prendre en compte dans votre plan de basculement manuel, comme indiqué dans les sous-sections suivantes.
Type et étendue du problème
Le processus de basculement manuel route les requêtes d’ingestion et d’interrogation vers votre région secondaire, ce qui permet généralement de contourner les composants défectueux à l’origine de la latence ou d’une défaillance dans votre région primaire. Ainsi, le basculement manuel n’est probablement pas utile dans les cas suivants :
- Il existe un problème interrégional avec une ressource sous-jacente. Par exemple, si les mêmes types de ressources ont des défaillances dans vos régions primaire et secondaire.
- Vous rencontrez un problème lié à la gestion de l’espace de travail, par exemple le changement des paramètres de conservation des données de l’espace de travail. Les opérations de gestion de l’espace de travail sont toujours effectuées dans votre région primaire. Durant le basculement manuel, les opérations de gestion de l’espace de travail sont bloquées.
Durée du problème
Le basculement manuel n’est pas instantané. Le processus de reroutage des requêtes repose sur des mises à jour DNS, que certains clients prennent en compte en quelques minutes, contrairement à d’autres clients, qui peuvent avoir besoin de plus de temps. Il est donc utile de comprendre si le problème peut être résolu en quelques minutes. Si le problème observé est constant ou continu, n’attendez pas pour effectuer le basculement manuel. Voici quelques exemples :
Ingestion : les problèmes de pipeline d’ingestion dans votre région primaire peuvent affecter la réplication des données vers votre espace de travail secondaire. Durant le basculement manuel, les journaux sont envoyés plutôt au pipeline d’ingestion de la région secondaire.
Requête : en cas d’échec ou d’expiration du délai d’exécution des requêtes de votre espace de travail principal, les alertes de recherche dans les journaux peuvent être affectées. Dans ce scénario, effectuez un basculement manuel vers votre espace de travail secondaire pour vérifier si toutes vos alertes se déclenchent correctement.
Données d’espace de travail secondaire
Les journaux ingérés dans votre espace de travail principal avant l’activation de la réplication ne sont pas copiés dans l’espace de travail secondaire. Si vous avez activé la réplication d’espace de travail trois heures auparavant, et si vous effectuez à présent un basculement manuel vers votre espace de travail secondaire, vos requêtes retournent uniquement les données des trois dernières heures.
Avant le changement de région durant le basculement manuel, votre espace de travail secondaire doit contenir un volume utile de journaux. Nous vous recommandons d’attendre au moins une semaine après l’activation de la réplication, avant de déclencher le basculement manuel. Ce délai de sept jours vous permet de disposer de suffisamment de données dans votre région secondaire.
Déclencher le basculement manuel
Avant d’effectuer le basculement manuel, vérifiez que l’opération de réplication d’espace de travail a réussi. Le basculement manuel réussit uniquement quand l’espace de travail secondaire est correctement configuré.
Pour basculer manuellement vers votre espace de travail secondaire, utilisez la commande POST suivante :
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/locations/<secondary_region>/workspaces/<workspace_name>/failover?api-version=2023-01-01-preview
Où :
-
<subscription_id>: ID d’abonnement lié à votre espace de travail. -
<resourcegroup_name>: groupe de ressources qui contient votre ressource d’espace de travail. -
<secondary_region>: région vers laquelle effectuer le basculement manuel. -
<workspace_name>: nom de l’espace de travail vers lequel effectuer le basculement manuel.
La commande POST est une opération durable qui peut prendre un certain temps pour s’effectuer. Un appel réussi retourne un code d’état 202. Vous pouvez suivre l’état d’approvisionnement de votre requête, comme indiqué dans Vérifier l’état d’approvisionnement de la requête.
Effectuer une restauration manuelle vers votre espace de travail principal
Le processus de restauration manuelle annule le reroutage des requêtes et des demandes d’ingestion de journaux vers l’espace de travail secondaire. Quand vous effectuez une restauration manuelle, Azure Monitor reprend le routage des requêtes et des demandes d’ingestion de journaux vers votre espace de travail principal.
Quand vous effectuez un basculement manuel vers votre région secondaire, Azure Monitor réplique les journaux de votre espace de travail secondaire vers votre espace de travail principal. Si une panne impacte le processus d’ingestion de journaux dans la région primaire, Azure Monitor peut mettre du temps à effectuer l’ingestion des journaux répliqués dans votre espace de travail principal.
Quand dois-je effectuer une restauration manuelle ?
Il existe plusieurs points à prendre en compte dans votre plan de restauration manuelle, comme indiqué dans les sous-sections suivantes.
État de la réplication des journaux
Avant de rebasculer, vérifiez qu’Azure Monitor a terminé la réplication de tous les journaux ingérés durant le basculement vers la région primaire. Si vous effectuez une restauration manuelle avant que tous les journaux ne soient répliqués vers l’espace de travail principal, vos requêtes risquent de retourner des résultats partiels tant que l’ingestion des journaux ne sera pas terminée.
Vous pouvez interroger votre espace de travail principal dans le portail Azure pour la région inactive, comme indiqué dans Auditer l’espace de travail inactif.
Intégrité de l’espace de travail principal
Il existe deux éléments d’intégrité importants à vérifier pour préparer la restauration manuelle vers votre espace de travail principal :
- Vérifiez qu’il n’existe aucune notification Service Health en attente pour l’espace de travail principal et la région primaire.
- Vérifiez que votre espace de travail principal ingère les journaux, et traite les requêtes comme prévu.
Pour obtenir des exemples montrant comment interroger votre espace de travail principal quand votre espace de travail secondaire est actif, et comment contourner le reroutage des requêtes vers votre espace de travail secondaire, consultez Auditer l’espace de travail inactif.
Déclencher la restauration manuelle
Avant d’effectuer une restauration manuelle, vérifiez l’intégrité de l’espace de travail principal, et terminez la réplication des journaux.
Le processus de restauration manuelle met à jour vos enregistrements DNS. Une fois la mise à jour des enregistrements DNS effectuée, il peut s’écouler un certain temps avant que tous les clients reçoivent les paramètres DNS mis à jour, et reprennent le routage vers l’espace de travail principal.
Pour effectuer une restauration manuelle vers votre espace de travail principal, utilisez la commande POST suivante :
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>/failback?api-version=2023-01-01-preview
Où :
-
<subscription_id>: ID d’abonnement lié à votre espace de travail. -
<resourcegroup_name>: groupe de ressources qui contient votre ressource d’espace de travail. -
<workspace_name>: nom de l’espace de travail vers lequel effectuer la restauration manuelle.
La commande POST est une opération durable qui peut prendre un certain temps pour s’effectuer. Un appel réussi retourne un code d’état 202. Vous pouvez suivre l’état d’approvisionnement de votre requête, comme indiqué dans Vérifier l’état d’approvisionnement de la requête.
Auditer l’espace de travail inactif
Par défaut, la région active de votre espace de travail est la région où vous créez l’espace de travail, et la région inactive est la région secondaire, où Azure Monitor crée l’espace de travail répliqué.
Lorsque vous déclenchez un basculement, cela change : la région secondaire est activée et la région primaire devient inactive. Elle est dite inactive, car il ne s’agit pas de la cible directe des demandes d’ingestion de journal et de requête.
Il est utile d’interroger la région inactive avant de basculer entre des régions pour vérifier que l’espace de travail dans la région inactive contient les journaux que vous prévoyez de voir.
Interroger la région inactive
Pour interroger les données du journal dans la région inactive, utilisez cette commande GET :
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=<query>×pan=<timespan-in-ISO8601-format>&overrideWorkspaceRegion=<primary|secondary>
Par exemple, pour exécuter une requête simple comme Perf | count pour le dernier jour de votre région secondaire, utilisez :
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=Perf%20|%20count×pan=P1D&overrideWorkspaceRegion=secondary
Vous pouvez vérifier qu’Azure Monitor exécute votre requête dans la région prévue en cochant les champs suivants dans la table LAQueryLogs, qui est créée quand vous activez l’audit des requêtes dans votre espace de travail Log Analytics :
-
isWorkspaceInFailover: indique si l’espace de travail était en mode de basculement manuel durant l’exécution de la requête. Le type de données est booléen (True, False). -
workspaceRegion: région de l’espace de travail ciblée par la requête. Le type de données est String.
Effectuer un monitoring des performances de l’espace de travail à l’aide de requêtes
Nous vous recommandons d’utiliser les requêtes de cette section pour créer des règles d’alerte qui vous notifient les problèmes potentiels d’intégrité ou de performances de l’espace de travail. Toutefois, la décision d’effectuer un basculement manuel nécessite une réflexion approfondie, et ne doit pas être prise de manière automatique.
Dans la règle de requête, vous pouvez définir une condition pour effectuer un basculement manuel vers votre espace de travail secondaire après le nombre spécifié de violations. Pour plus d’informations, consultez Créer ou modifier une règle d’alerte de recherche dans les journaux.
La latence d’ingestion et le volume d’ingestion sont deux mesures importantes des performances d’un espace de travail. Les sections suivantes vous permettent de découvrir ces options de monitoring.
Effectuer le monitoring de la latence d’ingestion de bout en bout
La latence d’ingestion mesure le temps nécessaire pour ingérer les journaux dans l’espace de travail. La mesure du temps commence au moment où l’événement journalisé initial se produit, et s’achève quand le journal est stocké dans votre espace de travail. La latence d’ingestion totale se compose de deux parties :
- Latence de l’agent : temps nécessaire à l’agent pour signaler un événement.
- Latence du pipeline d’ingestion (back-end) : temps nécessaire au pipeline d’ingestion pour traiter les journaux, et les écrire dans votre espace de travail.
Les différents types de données ont une latence d’ingestion distincte. Vous pouvez mesurer l’ingestion pour chaque type de données séparément, ou créer une requête générique pour tous les types, et une requête plus précise pour les types spécifiques les plus importants à vos yeux. Nous vous suggérons de mesurer le 90e centile de la latence d’ingestion, qui est plus sensible aux changements que la moyenne ou le 50e centile (médiane).
Les sections suivantes montrent comment utiliser des requêtes pour vérifier la latence d’ingestion de votre espace de travail.
Évaluer la latence d’ingestion de référence de tables spécifiques
Commencez par déterminer la latence de référence de tables spécifiques sur plusieurs jours.
Cet exemple de requête crée un graphique du 90e centile de latence d’ingestion dans la table Perf :
// Assess the ingestion latency baseline for a specific data type
Perf
| where TimeGenerated > ago(3d)
| project TimeGenerated,
IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize LatencyIngestion90Percentile=percentile(IngestionDurationSeconds, 90) by bin(TimeGenerated, 1h)
| render timechart
Une fois que vous avez exécuté la requête, passez en revue les résultats ainsi que le graphique affiché afin de déterminer la latence attendue pour cette table.
Effectuer un monitoring et émettre des alertes sur la latence d’ingestion actuelle
Une fois que vous avez établi la latence d’ingestion de référence d’une table spécifique, créez une règle d’alerte de recherche dans les journaux pour la table en fonction des changements de latence sur une courte période.
Cette requête calcule la latence d’ingestion au cours des 20 dernières minutes :
// Track the recent ingestion latency (in seconds) of a specific table
Perf
| where TimeGenerated > ago(20m)
| extend IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize Ingestion90Percent_seconds=percentile(IngestionDurationSeconds, 90)
Dans la mesure où certaines fluctuations sont à prévoir, créez une condition de règle d’alerte pour vérifier si la requête retourne une valeur nettement supérieure à la base de référence.
Déterminer la source de la latence d’ingestion
Quand vous remarquez que la latence d’ingestion totale augmente, vous pouvez utiliser des requêtes pour déterminer si la source de la latence provient des agents ou du pipeline d’ingestion.
Cette requête génère un graphique qui affiche de manière distincte la latence du 90e centile des agents et du pipeline :
// Assess agent and pipeline (backend) latency
Perf
| where TimeGenerated > ago(1h)
| extend AgentLatencySeconds = (_TimeReceived-TimeGenerated)/1s,
PipelineLatencySeconds=(ingestion_time()-_TimeReceived)/1s
| summarize percentile(AgentLatencySeconds,90), percentile(PipelineLatencySeconds,90) by bin(TimeGenerated,5m)
| render columnchart
Remarque
Bien que le graphique affiche les données du 90e centile sous forme de colonnes empilées, la somme des données des deux graphiques n’est pas égale au 90e centile de l’ingestion totale.
Effectuer un monitoring du volume d’ingestion
Les mesures du volume d’ingestion peuvent vous permettre d’identifier les changements inattendus du volume d’ingestion total ou spécifique à une table pour votre espace de travail. Les mesures du volume de requêtes peuvent vous aider à identifier les problèmes de performances liés à l’ingestion des journaux. Voici certaines mesures de volume utiles :
- Volume total d’ingestion par table
- Volume constant d’ingestion (inchangé)
- Anomalies d’ingestion : pics et creux du volume d’ingestion
Les sections suivantes montrent comment utiliser des requêtes pour vérifier le volume d’ingestion de votre espace de travail.
Effectuer un monitoring du volume d’ingestion total par table
Vous pouvez définir une requête pour effectuer un monitoring du volume d’ingestion par table dans votre espace de travail. La requête peut inclure une alerte qui recherche les changements inattendus liés au volume total ou au volume spécifique à une table.
Cette requête calcule le volume d’ingestion total au cours de la dernière heure par table, en mégaoctets par seconde (Mo) :
// Calculate total ingestion volume over the past hour per table
Usage
| where TimeGenerated > ago(1h)
| summarize BillableDataMB = sum(_BilledSize)/1.E6 by bin(TimeGenerated,1h), DataType
Vérifier l’arrêt de l’ingestion
Si vous ingérez des journaux via des agents, vous pouvez utiliser la pulsation de l’agent pour détecter la connectivité. Une pulsation inchangée peut révéler un arrêt de l’ingestion des journaux dans votre espace de travail. Quand les données de requête révèlent un arrêt de l’ingestion, vous pouvez définir une condition pour déclencher la réponse souhaitée.
La requête suivante vérifie la pulsation de l’agent pour détecter les problèmes de connectivité :
// Count agent heartbeats in the last ten minutes
Heartbeat
| where TimeGenerated>ago(10m)
| count
Effectuer un monitoring des anomalies d’ingestion
Vous pouvez identifier les pics et les creux au sein des données de volume d’ingestion de votre espace de travail de différentes manières. Utilisez la fonction series_decompose_anomalies() pour extraire les anomalies des volumes d’ingestion faisant l’objet d’un monitoring dans votre espace de travail, ou créez votre propre détecteur d’anomalies pour prendre en charge les scénarios uniques de votre espace de travail.
Identifier les anomalies à l’aide de series_decompose_anomalies
La fonction series_decompose_anomalies() identifie les anomalies dans une série de valeurs de données. Cette requête calcule le volume d’ingestion horaire de chaque table de votre espace de travail Log Analytics, et utilise series_decompose_anomalies() pour identifier les anomalies :
// Calculate hourly ingestion volume per table and identify anomalies
Usage
| where TimeGenerated > ago(24h)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| summarize
Timestamp=make_list(TimeGenerated),
IngestionVolumeMB=make_list(IngestionVolumeMB)
by DataType
| extend series_decompose_anomalies(IngestionVolumeMB)
| mv-expand
Timestamp,
IngestionVolumeMB,
series_decompose_anomalies_IngestionVolumeMB_ad_flag,
series_decompose_anomalies_IngestionVolumeMB_ad_score,
series_decompose_anomalies_IngestionVolumeMB_baseline
| where series_decompose_anomalies_IngestionVolumeMB_ad_flag != 0
Pour plus d’informations sur l’utilisation de series_decompose_anomalies() afin de détecter des anomalies dans les données de journal, consultez Détecter et analyser des anomalies à l’aide des fonctionnalités de Machine Learning KQL dans Azure Monitor.
Créer votre propre détecteur d’anomalies
Vous pouvez créer un détecteur d’anomalies personnalisé afin de prendre en charge les impératifs du scénario pour la configuration de votre espace de travail. Cette section fournit un exemple illustrant le processus.
La requête suivante effectue le calcul ci-dessous :
- Volume d’ingestion attendu : par heure, par table (basé sur la médiane des médianes, mais vous pouvez personnaliser la logique)
- Volume d’ingestion réel : par heure, par table
Pour filtrer les différences non significatives entre le volume d’ingestion attendu et le volume d’ingestion réel, la requête applique deux filtres :
- Taux de variation : plus de 150 % ou moins de 66 % du volume attendu, par table
- Volume de variation : indique si l’augmentation ou la diminution du volume représente plus de 0,1 % du volume mensuel de la table
// Calculate expected vs actual hourly ingestion per table
let TimeRange=24h;
let MonthlyIngestionByType=
Usage
| where TimeGenerated > ago(30d)
| summarize MonthlyIngestionMB=sum(Quantity) by DataType;
// Calculate the expected ingestion volume by median of hourly medians
let ExpectedIngestionVolumeByType=
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionMedian=percentile(Quantity, 50) by bin(TimeGenerated, 1h), DataType
| summarize ExpectedIngestionVolumeMB=percentile(IngestionMedian, 50) by DataType;
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| join kind=inner (ExpectedIngestionVolumeByType) on DataType
| extend GapVolumeMB = round(IngestionVolumeMB-ExpectedIngestionVolumeMB,2)
| where GapVolumeMB != 0
| extend Trend=iff(GapVolumeMB > 0, "Up", "Down")
| extend IngestedVsExpectedAsPercent = round(IngestionVolumeMB * 100 / ExpectedIngestionVolumeMB, 2)
| join kind=inner (MonthlyIngestionByType) on DataType
| extend GapAsPercentOfMonthlyIngestion = round(abs(GapVolumeMB) * 100 / MonthlyIngestionMB, 2)
| project-away DataType1, DataType2
// Determine whether the spike/deep is substantial: over 150% or under 66% of the expected volume for this data type
| where IngestedVsExpectedAsPercent > 150 or IngestedVsExpectedAsPercent < 66
// Determine whether the gap volume is significant: over 0.1% of the total monthly ingestion volume to this workspace
| where GapAsPercentOfMonthlyIngestion > 0.1
| project
Timestamp=format_datetime(todatetime(TimeGenerated), 'yyyy-MM-dd HH:mm:ss'),
Trend,
IngestionVolumeMB,
ExpectedIngestionVolumeMB,
IngestedVsExpectedAsPercent,
GapAsPercentOfMonthlyIngestion
Effectuer un monitoring de la réussite et de l’échec des requêtes
Chaque requête retourne un code de réponse qui indique la réussite ou l’échec. En cas d’échec de la requête, la réponse inclut également les types d’erreurs. Un nombre élevé d’erreurs peut indiquer un problème de disponibilité de l’espace de travail ou de performances du service.
Cette requête compte le nombre de requêtes qui ont retourné un code d’erreur de serveur :
// Count query errors
LAQueryLogs
| where ResponseCode>=500 and ResponseCode<600
| count