Conteneurs de reconnaissance vocale personnalisée avec Docker
Le conteneur de reconnaissance vocale personnalisée transcrit les messages en temps réel ou les enregistrements audio par lots avec des résultats intermédiaires. Vous pouvez utiliser un modèle personnalisé créé dans le portail de reconnaissance vocale personnalisée (Custom Speech). Dans cet article, vous apprenez à télécharger, à installer et à exécuter un conteneur de reconnaissance vocale personnalisée.
Pour plus d’informations sur les prérequis, la vérification de l’exécution d’un conteneur, l’exécution de plusieurs conteneurs sur le même hôte et l’exécution de conteneurs déconnectés, consultez l’article Installer et exécuter des conteneurs Speech avec Docker.
Images de conteneur
L’image conteneur de reconnaissance vocale personnalisée pour toutes les versions et paramètres régionaux pris en charge se trouve sur le syndicat Microsoft Container Registry (MCR). Elle réside dans le référentiel azure-cognitive-services/speechservices/ et se nomme custom-speech-to-text.

Le nom complet de l’image conteneur est mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text. Ajoutez une version spécifique ou ajoutez :latest pour obtenir la version la plus récente.
| Version | Path |
|---|---|
| Latest | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest |
| 4.10.0 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:4.10.0-amd64 |
Toutes les étiquettes, à l’exception de latest, respectent le format suivant et sont sensibles à la casse :
<major>.<minor>.<patch>-<platform>-<prerelease>
Remarque
Les éléments locale et voice des conteneurs de reconnaissance vocale personnalisée sont déterminés par le modèle personnalisé ingéré par le conteneur.
Les balises sont également disponibles au format JSON pour votre commodité. Le corps inclut le chemin d’accès du conteneur et la liste des balises. Les balises ne sont pas triées par version, mais "latest" est toujours inclus à la fin de la liste, comme indiqué dans l’extrait de code suivant :
{
"name": "azure-cognitive-services/speechservices/custom-speech-to-text",
"tags": [
<--redacted for brevity-->
"4.4.0-amd64",
"4.5.0-amd64",
"4.6.0-amd64",
"4.7.0-amd64",
"4.8.0-amd64",
"4.9.0-amd64",
"4.10.0-amd64",
"latest"
]
}
Obtenir l’image conteneur avec docker pull
Vous avez besoin des prérequis, notamment le matériel requis. Consultez également l’allocation de ressources recommandée pour chaque conteneur Speech.
Utilisez la commande docker pull pour télécharger une image conteneur à partir du registre de conteneurs Microsoft :
docker pull mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest
Notes
Les locale et voice des conteneurs Speech personnalisés sont déterminés par le modèle personnalisé ingéré par le conteneur.
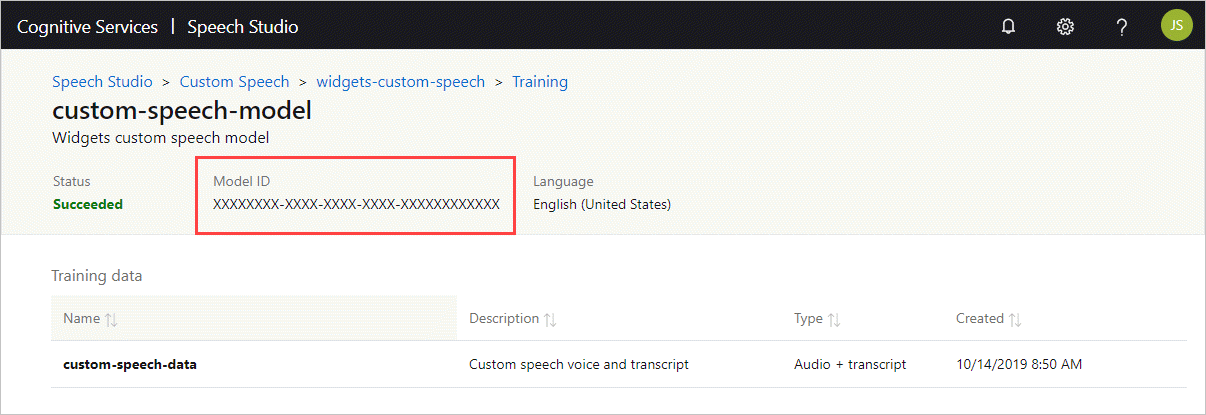
Obtenir l’ID de modèle
Avant de pouvoir exécuter le conteneur, vous devez connaître l’ID de votre modèle personnalisé ou d’un modèle de base. Quand vous exécutez le conteneur, vous spécifiez l’un des ID de modèle à télécharger et à utiliser.
L’apprentissage du modèle personnalisé doit être effectué à l’aide de Speech Studio. Pour plus d’informations sur l’obtention de l’ID de modèle, consultez l’article Cycle de vie des modèles de reconnaissance vocale personnalisée.
Obtenez l’ID du modèle pour l’utiliser comme argument du paramètre ModelId de la commande docker run.
Téléchargement des modèles d’affichage
Avant d’exécuter le conteneur, vous pouvez éventuellement obtenir les informations sur les modèles d’affichage disponibles et choisir de télécharger ces modèles dans votre conteneur de reconnaissance vocale pour obtenir une sortie d’affichage finale grandement améliorée. Le téléchargement des modèles d’affichage est disponible avec le conteneur de reconnaissance vocale personnalisée version 3.1.0 ou ultérieure.
Notes
Bien que vous utilisiez la commande docker run, le conteneur n’est pas démarré pour le service.
Vous pouvez interroger ou télécharger tout ou partie de ces types de modèles d’affichage : rescoring (Rescore), ponctuation (Punct), resegmentation (Resegment) et wfstitn (Wfstitn). Autrement, vous pouvez utiliser l’option FullDisplay (avec ou sans les autres types) pour interroger ou télécharger tous les types de modèles d’affichage.
Définissez BaseModelLocale pour demander le dernier modèle d’affichage disponible sur les paramètres régionaux cibles. Si vous incluez plusieurs types de modèles d’affichage, la commande retourne les derniers modèles d’affichage disponibles pour chaque type. Par exemple :
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
BaseModelLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Définissez DisplayLocale pour télécharger le dernier modèle d’affichage disponible sur les paramètres régionaux cibles. Quand vous définissez DisplayLocale, vous devez aussi spécifier FullDisplay ou un sous-ensemble de modèles d’affichage séparés par des espaces. La commande télécharge alors le dernier modèle d’affichage disponible pour chaque type spécifié. Par exemple :
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
DisplayLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Définissez un paramètre d’ID de modèle pour télécharger un modèle d’affichage spécifique : rescoring (RescoreId), ponctuation (PunctId), resegmentation (ResegmentId) ou wfstitn (WfstitnId). Cela ressemble à la façon dont vous téléchargez un modèle de base via le paramètre ModelId. Par exemple, pour télécharger un modèle d’affichage de rescoring, vous pouvez utiliser la commande suivante avec le paramètre RescoreId :
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
RescoreId={RESCORE_MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Notes
Si vous définissez plusieurs paramètres de requête ou de téléchargement, la commande établit l’ordre de priorité suivant : BaseModelLocale, ID de modèle, puis DisplayLocale (cela vaut uniquement pour les modèles d’affichage).
Exécuter le conteneur avec docker run
Utilisez la commande docker run pour exécuter le conteneur pour le service.
- Conteneur de reconnaissance vocale personnalisée
- Conteneur de reconnaissance vocale personnalisée déconnecté
Le tableau suivant présente les différents paramètres docker run et leurs descriptions correspondantes :
| Paramètre | Description |
|---|---|
{VOLUME_MOUNT} |
Montage de volume de l’ordinateur hôte, que Docker utilise pour rendre le modèle personnalisé persistant. Par exemple, c:\CustomSpeech, où le lecteur c:\ se trouve sur l’ordinateur hôte. |
{MODEL_ID} |
ID de modèle vocal personnalisé ou de base. Pour plus d’informations, consultez la section Obtenir l’ID de modèle. |
{ENDPOINT_URI} |
Le point de terminaison est nécessaire pour le comptage et la facturation. Pour plus d’informations, consultez la section Arguments de facturation. |
{API_KEY} |
La clé API est obligatoire. Pour plus d’informations, consultez la section Arguments de facturation. |
Quand vous exécutez le conteneur de reconnaissance vocale personnalisée, configurez le port, la mémoire et le processeur en fonction des exigences et recommandations relatives au conteneur de reconnaissance vocale personnalisée.
Voici un exemple de commande docker run avec des valeurs d’espace réservé. Vous devez spécifier les valeurs VOLUME_MOUNTMODEL_ID, ENDPOINT_URI et API_KEY :
docker run --rm -it -p 5000:5000 --memory 8g --cpus 4 \
-v {VOLUME_MOUNT}:/usr/local/models \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
ModelId={MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Cette commande :
- Exécute un conteneur de reconnaissance vocale personnalisée à partir de l’image conteneur.
- Alloue 4 cœurs de processeur et 8 Go de mémoire.
- Charge le modèle de reconnaissance vocale personnalisée à partir du montage d’entrée de volume, par exemple C:\CustomSpeech.
- Expose le port TCP 5000 et alloue un pseudo-TTY pour le conteneur.
- Télécharge le modèle selon
ModelId(s’il est introuvable sur le montage de volume). - Si le modèle personnalisé a été téléchargé auparavant,
ModelIdest ignoré. - Supprime automatiquement le conteneur après sa fermeture. L’image conteneur est toujours disponible sur l’ordinateur hôte.
Pour plus d’informations sur docker run avec des conteneurs Speech, consultez la section Installer et exécuter des conteneurs Speech avec Docker.
Utiliser le conteneur
Les conteneurs Speech fournissent des API de point de terminaison de requête basées sur WebSocket, accessibles via le Kit de développement logiciel (SDK) Speech et l’interface CLI Speech. Par défaut, le kit de développement logiciel (SDK) Speech et l’interface CLI Speech utilisent le service Speech public. Pour utiliser le conteneur, vous devez changer la méthode d’initialisation.
Important
Quand vous utilisez le service Speech avec des conteneurs, veillez à utiliser l’authentification de l’hôte. Si vous configurez la clé et la région, les demandes sont envoyées au service Speech public. Les résultats du service Speech peuvent ne pas correspondre à ce que vous attendez. Les demandes provenant des conteneurs déconnectés échouent.
Au lieu d’utiliser cette configuration d’initialisation du cloud Azure :
var config = SpeechConfig.FromSubscription(...);
Utilisez cette configuration avec l’hôte de conteneur :
var config = SpeechConfig.FromHost(
new Uri("ws://localhost:5000"));
Au lieu d’utiliser cette configuration d’initialisation du cloud Azure :
auto speechConfig = SpeechConfig::FromSubscription(...);
Utilisez cette configuration avec l’hôte de conteneur :
auto speechConfig = SpeechConfig::FromHost("ws://localhost:5000");
Au lieu d’utiliser cette configuration d’initialisation du cloud Azure :
speechConfig, err := speech.NewSpeechConfigFromSubscription(...)
Utilisez cette configuration avec l’hôte de conteneur :
speechConfig, err := speech.NewSpeechConfigFromHost("ws://localhost:5000")
Au lieu d’utiliser cette configuration d’initialisation du cloud Azure :
SpeechConfig speechConfig = SpeechConfig.fromSubscription(...);
Utilisez cette configuration avec l’hôte de conteneur :
SpeechConfig speechConfig = SpeechConfig.fromHost("ws://localhost:5000");
Au lieu d’utiliser cette configuration d’initialisation du cloud Azure :
const speechConfig = sdk.SpeechConfig.fromSubscription(...);
Utilisez cette configuration avec l’hôte de conteneur :
const speechConfig = sdk.SpeechConfig.fromHost("ws://localhost:5000");
Au lieu d’utiliser cette configuration d’initialisation du cloud Azure :
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithSubscription:...];
Utilisez cette configuration avec l’hôte de conteneur :
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithHost:"ws://localhost:5000"];
Au lieu d’utiliser cette configuration d’initialisation du cloud Azure :
let speechConfig = SPXSpeechConfiguration(subscription: "", region: "");
Utilisez cette configuration avec l’hôte de conteneur :
let speechConfig = SPXSpeechConfiguration(host: "ws://localhost:5000");
Au lieu d’utiliser cette configuration d’initialisation du cloud Azure :
speech_config = speechsdk.SpeechConfig(
subscription=speech_key, region=service_region)
Utilisez cette configuration avec le point de terminaison de conteneur :
speech_config = speechsdk.SpeechConfig(
host="ws://localhost:5000")
Lorsque vous utilisez l’interface CLI Speech dans un conteneur, incluez l’option --host ws://localhost:5000/. Vous devez également spécifier --key none pour vous assurer que l’interface de ligne de commande n’essaie pas d’utiliser une clé Speech pour l’authentification. Pour plus d’informations sur la configuration de l’interface CLI Speech, consultez l’article Bien démarrer avec l’interface CLI Azure AI Speech.
Essayez le guide de démarrage rapide de la reconnaissance vocale en utilisant l’authentification de l’hôte au lieu de la clé et de la région.
Étapes suivantes
- Consulter l’article Vue d’ensemble des conteneurs Speech
- Passer en revue Configurer des conteneurs pour découvrir les paramètres de configuration
- Utiliser plus de conteneurs Azure AI