Démarrage rapide : Reconnaître et convertir la parole en texte
Important
Les éléments marqués (préversion) dans cet article sont actuellement en préversion publique. Cette préversion est fournie sans contrat de niveau de service, nous la déconseillons dans des charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Dans ce guide de démarrage rapide, vous essayez la reconnaissance vocale en temps réel dans Azure AI Foundry.
Prérequis
- Abonnement Azure : créez-en un gratuitement.
- Vous pouvez essayer gratuitement certaines fonctionnalités d’Azure AI services dans le portail Azure AI Foundry. Pour accéder à toutes les fonctionnalités décrites dans cet article, vous devez connecter des services IA dans Azure AI Foundry.
Essayer la reconnaissance vocale en temps réel
Accédez à votre projet Azure AI Foundry. Si vous devez créer un projet, consultez Créer un projet Azure AI Foundry.
Sélectionnez Terrains de jeu dans le volet gauche, puis sélectionnez un terrain de jeu à utiliser. Dans cet exemple, sélectionnez Essayer le terrain de jeu Speech.
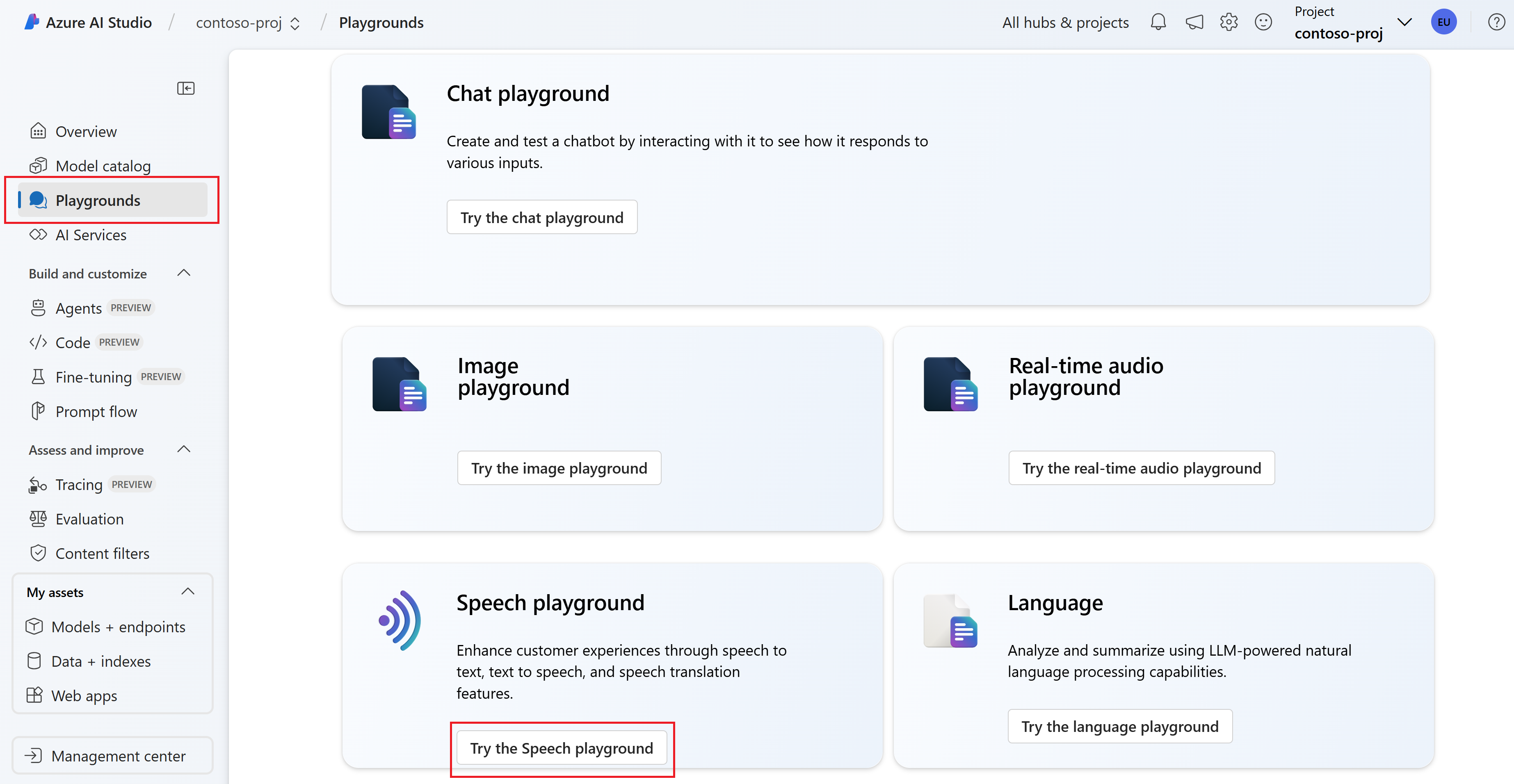
Si vous le souhaitez, vous pouvez sélectionner une autre connexion à utiliser dans le terrain de jeu. Dans le terrain de jeu Speech, vous pouvez vous connecter à des ressources multiservices Azure AI Services ou à des ressources de service Speech.
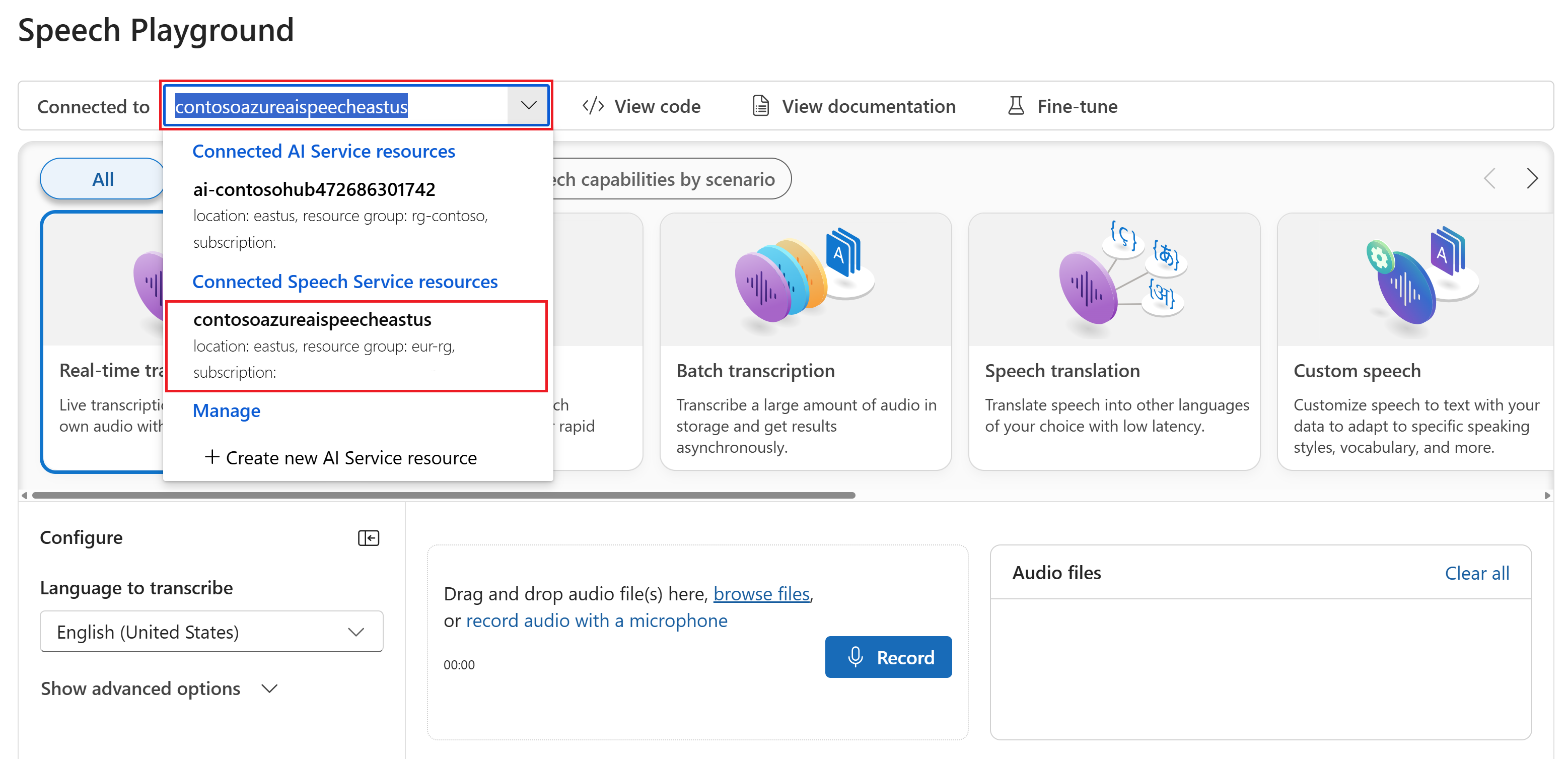
Sélectionnez Transcription en temps réel.
Sélectionnez Afficher les options avancées pour configurer des options de la reconnaissance vocale, comme :
- Identification de la langue : utilisée pour identifier les langues parlées dans l’audio par comparaison à la liste des langues prises en charge. Pour plus d’informations sur les options d’identification de la langue, comme la reconnaissance au démarrage et la reconnaissance continue, consultez Identification de la langue.
- Diarisation du locuteur : utilisée pour identifier et séparer les locuteurs dans l’audio. La diarisation fait la distinction entre les différents intervenants qui participent à la conversation. Le service Speech fournit des informations sur l’orateur qui parlait une partie particulière de la parole transcrite. Pour plus d’informations sur la diarisation du locuteur, consultez le guide de démarrage rapide Reconnaissance vocale en temps réel avec diarisation du locuteur.
- Point de terminaison personnalisé : utilisez un modèle déployé à partir de la reconnaissance vocale personnalisée pour améliorer la précision de la reconnaissance. Pour utiliser le modèle de référence de Microsoft, laissez cette valeur définie sur Aucun. Pour plus d’informations sur Custom Speech, consultez Custom Speech.
- Format de sortie : choisissez entre les formats de sortie simples ou détaillés. La sortie simple comprend un format d’affichage et des horodatages. La sortie détaillée comprend d’autres formats (comme affichage, lexical, ITN et ITN masqué), des horodatages et des listes N-meilleurs.
- Liste d’expressions : améliorez la précision de la transcription en fournissant une liste d’expressions connues, comme des noms de personnes ou des emplacements spécifiques. Utilisez des virgules ou des points-virgules pour séparer chaque valeur de la liste d’expressions. Pour plus d’informations sur les listes d’expressions, consultez Listes d’expressions.
Sélectionnez un fichier audio à charger ou enregistrez l’audio en temps réel. Dans cet exemple, nous utilisons le fichier
Call1_separated_16k_health_insurance.wav, qui est disponible dans le référentiel Speech SDK sur GitHub. Vous pouvez télécharger le fichier ou utiliser votre propre fichier audio.
Vous pouvez afficher la transcription en temps réel en bas de la page.

Vous pouvez sélectionner l’onglet JSON pour afficher la sortie JSON de la transcription. Les propriétés incluent notamment
Offset,Duration,RecognitionStatus,Display,Lexical, etITN.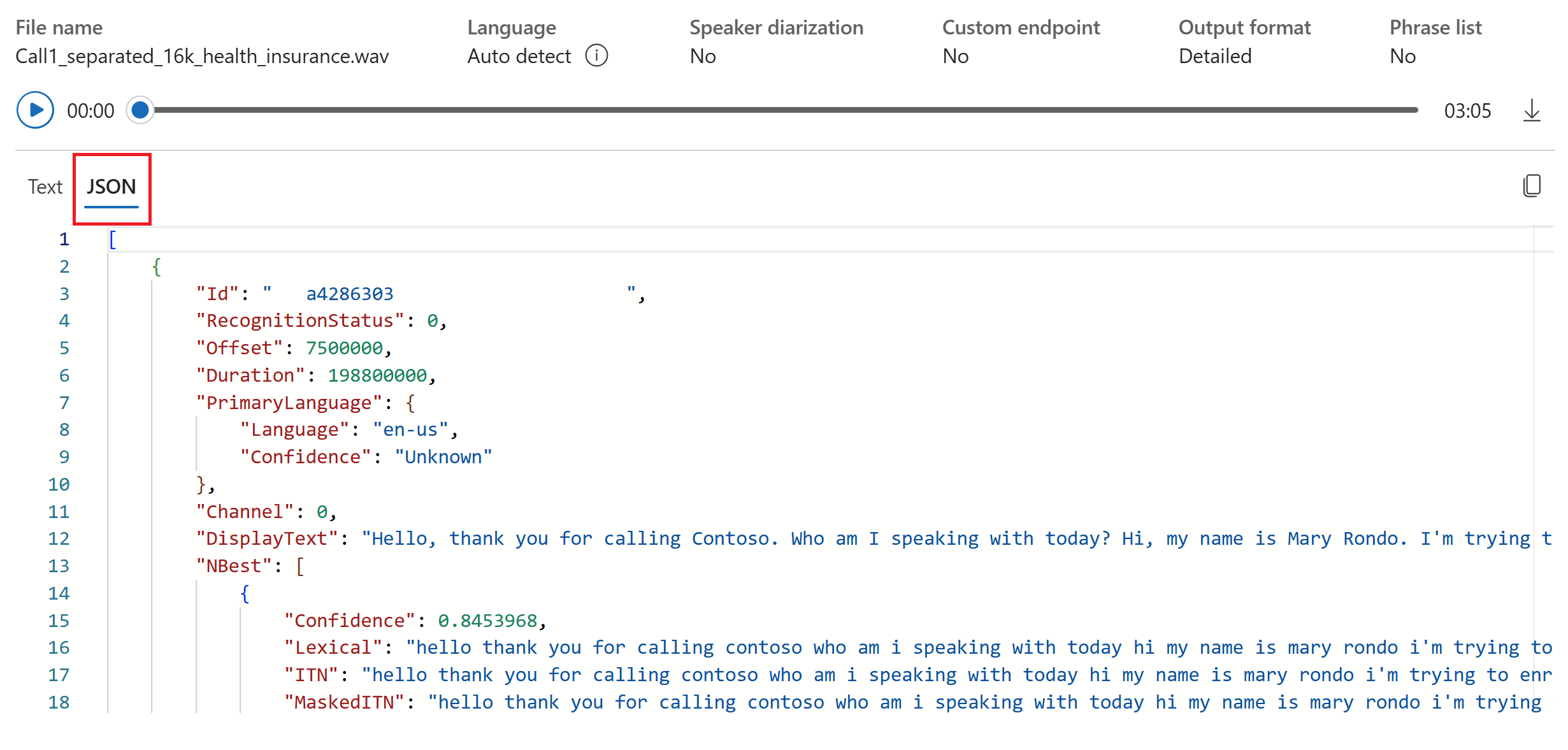





Documentation de référence | Package (NuGet) | Exemples supplémentaires sur GitHub
Dans ce guide de démarrage rapide, vous créez et exécutez une application pour reconnaître et transcrire la reconnaissance vocale en temps réel.
Pour transcrire des fichiers audio de manière asynchrone, consultez Qu’est-ce que la transcription par lots ?. Si vous ne savez pas quelle solution de reconnaissance vocale est la plus adaptée pour vous, consultez Qu’est-ce que la reconnaissance vocale ?
Prérequis
- Un abonnement Azure. Vous pouvez en créer un gratuitement.
- Créer une ressource Speech dans le portail Azure.
- Obtenez la clé de ressource et la région Speech. Une fois votre ressource vocale déployée, sélectionnez Accéder à la ressource pour afficher et gérer les clés.
Configurer l’environnement
Le kit de développement logiciel (SDK) Speech est disponible en tant que package NuGet et implémente .NET Standard 2.0. Vous installez le Kit SDK Speech plus loin dans ce guide. Pour toute autre exigence, consultez Installer le Kit de développement logiciel (SDK) Speech.
Définir des variables d’environnement
Vous devez authentifier votre application pour accéder à Azure AI services. Cet article vous montre comment utiliser des variables d’environnement pour stocker vos informations d’identification. Vous pouvez ensuite accéder aux variables d’environnement à partir de votre code pour authentifier votre application. Pour la production, utilisez un moyen plus sécurisé pour stocker vos informations d’identification et y accéder.
Important
Nous vous recommandons l’authentification Microsoft Entra ID avec les identités managées pour les ressources Azure pour éviter de stocker des informations d’identification avec vos applications qui s’exécutent dans le cloud.
Si vous utilisez une clé API, stockez-la en toute sécurité dans un autre emplacement, par exemple dans Azure Key Vault. N'incluez pas la clé API directement dans votre code et ne la diffusez jamais publiquement.
Pour plus d’informations sur la sécurité des services IA, consultez Authentifier les demandes auprès d’Azure AI services.
Pour définir les variables d'environnement de votre clé de ressource Speech et de votre région, ouvrez une fenêtre de console et suivez les instructions de votre système d'exploitation et de votre environnement de développement.
- Pour définir la variable d’environnement
SPEECH_KEY, remplacez your-key par l’une des clés de votre ressource. - Pour définir la variable d’environnement
SPEECH_REGION, remplacez your-region par l’une des régions de votre ressource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Remarque
Si vous avez uniquement besoin d’accéder aux variables d’environnement dans la console en cours d’exécution, vous pouvez la définir avec set au lieu de setx.
Après avoir ajouté les variables d'environnement, vous devrez éventuellement redémarrer tous les programmes qui ont besoin de lire les variables d'environnement, y compris la fenêtre de console. Par exemple, si vous utilisez Visual Studio comme éditeur, redémarrez Visual Studio avant d’exécuter l’exemple.
Reconnaître la voix provenant d’un micro
Conseil
Essayez la boîte à outils Azure AI Speech Toolkit pour générer et exécuter facilement des exemples sur Visual Studio Code.
Effectuez ces étapes pour créer une application console et installer le SDK Speech.
Ouvrez une fenêtre d’invite de commandes dans le dossier où vous souhaitez placer le nouveau projet. Exécutez cette commande pour créer une application console avec l’interface CLI .NET.
dotnet new consoleCette commande crée un fichier Program.cs dans le répertoire de votre projet.
Installez le kit de développement logiciel (SDK) Speech dans votre nouveau projet avec l’interface CLI .NET.
dotnet add package Microsoft.CognitiveServices.SpeechRemplacez le contenu du fichier Program.cs par le code suivant :
using System; using System.IO; using System.Threading.Tasks; using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; class Program { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); static void OutputSpeechRecognitionResult(SpeechRecognitionResult speechRecognitionResult) { switch (speechRecognitionResult.Reason) { case ResultReason.RecognizedSpeech: Console.WriteLine($"RECOGNIZED: Text={speechRecognitionResult.Text}"); break; case ResultReason.NoMatch: Console.WriteLine($"NOMATCH: Speech could not be recognized."); break; case ResultReason.Canceled: var cancellation = CancellationDetails.FromResult(speechRecognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?"); } break; } } async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); using var speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); Console.WriteLine("Speak into your microphone."); var speechRecognitionResult = await speechRecognizer.RecognizeOnceAsync(); OutputSpeechRecognitionResult(speechRecognitionResult); } }Pour modifier la langue de la reconnaissance vocale, remplacez
en-USpar une autre langue prise en charge. Par exemple, utilisezes-ESpour l’espagnol (Espagne). Si vous ne spécifiez pas de langue, la valeur par défaut esten-US. Pour plus d’informations sur l’identification de l’une des nombreuses langues qui peuvent être parlées, consultez Identification de la langue.Exécutez votre nouvelle application console pour démarrer la reconnaissance vocale à partir d’un microphone :
dotnet runImportant
N’oubliez pas de définir les variables d’environnement
SPEECH_KEYetSPEECH_REGION. Si vous ne définissez pas ces variables, l’exemple échoue avec un message d’erreur.Parlez dans votre microphone lorsque vous y êtes invité. Ce que vous dites doit apparaître sous forme de texte :
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Notes
Voici quelques autres éléments à prendre en compte :
Cet exemple utilise l’opération
RecognizeOnceAsyncpour transcrire les énoncés de jusqu’à 30 secondes ou jusqu’à ce que le silence soit détecté. Pour plus d’informations sur la reconnaissance continue des données audio plus longues, y compris les conversations multilingues, consultez Comment effectuer la reconnaissance vocale.Pour reconnaître la parole à partir d’un fichier audio, utilisez
FromWavFileInputau lieu deFromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav");Pour les fichiers audio compressés tels que les fichiers MP4, installez GStreamer et utilisez
PullAudioInputStreamouPushAudioInputStream. Pour plus d’informations, consultez Utilisation de l’audio d’entrée compressée.
Nettoyer les ressources
Vous pouvez utiliser le portail Azure ou l’interface de ligne de commande (CLI) Azure pour supprimer la ressource Speech que vous avez créée.
Documentation de référence | Package (NuGet) | Exemples supplémentaires sur GitHub
Dans ce guide de démarrage rapide, vous créez et exécutez une application pour reconnaître et transcrire la reconnaissance vocale en temps réel.
Pour transcrire des fichiers audio de manière asynchrone, consultez Qu’est-ce que la transcription par lots ?. Si vous ne savez pas quelle solution de reconnaissance vocale est la plus adaptée pour vous, consultez Qu’est-ce que la reconnaissance vocale ?
Prérequis
- Un abonnement Azure. Vous pouvez en créer un gratuitement.
- Créer une ressource Speech dans le portail Azure.
- Obtenez la clé de ressource et la région Speech. Une fois votre ressource vocale déployée, sélectionnez Accéder à la ressource pour afficher et gérer les clés.
Configurer l’environnement
Le kit de développement logiciel (SDK) Speech est disponible en tant que package NuGet et implémente .NET Standard 2.0. Vous installez le Kit SDK Speech plus loin dans ce guide. Pour d’autres exigences, consultez Installer le Kit de développement logiciel (SDK) Speech.
Définir des variables d’environnement
Vous devez authentifier votre application pour accéder à Azure AI services. Cet article vous montre comment utiliser des variables d’environnement pour stocker vos informations d’identification. Vous pouvez ensuite accéder aux variables d’environnement à partir de votre code pour authentifier votre application. Pour la production, utilisez un moyen plus sécurisé pour stocker vos informations d’identification et y accéder.
Important
Nous vous recommandons l’authentification Microsoft Entra ID avec les identités managées pour les ressources Azure pour éviter de stocker des informations d’identification avec vos applications qui s’exécutent dans le cloud.
Si vous utilisez une clé API, stockez-la en toute sécurité dans un autre emplacement, par exemple dans Azure Key Vault. N'incluez pas la clé API directement dans votre code et ne la diffusez jamais publiquement.
Pour plus d’informations sur la sécurité des services IA, consultez Authentifier les demandes auprès d’Azure AI services.
Pour définir les variables d'environnement de votre clé de ressource Speech et de votre région, ouvrez une fenêtre de console et suivez les instructions de votre système d'exploitation et de votre environnement de développement.
- Pour définir la variable d’environnement
SPEECH_KEY, remplacez your-key par l’une des clés de votre ressource. - Pour définir la variable d’environnement
SPEECH_REGION, remplacez your-region par l’une des régions de votre ressource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Remarque
Si vous avez uniquement besoin d’accéder aux variables d’environnement dans la console en cours d’exécution, vous pouvez la définir avec set au lieu de setx.
Après avoir ajouté les variables d'environnement, vous devrez éventuellement redémarrer tous les programmes qui ont besoin de lire les variables d'environnement, y compris la fenêtre de console. Par exemple, si vous utilisez Visual Studio comme éditeur, redémarrez Visual Studio avant d’exécuter l’exemple.
Reconnaître la voix provenant d’un micro
Conseil
Essayez la boîte à outils Azure AI Speech Toolkit pour générer et exécuter facilement des exemples sur Visual Studio Code.
Effectuez ces étapes pour créer une application console et installer le SDK Speech.
Créez un projet console en C++ dans Visual Studio Community, nommé
SpeechRecognition.Sélectionnez Outils>Gestionnaire de package NuGet>Console du Gestionnaire de package. Dans la Console du Gestionnaire de package, exécutez cette commande :
Install-Package Microsoft.CognitiveServices.SpeechRemplacez le contenu de
SpeechRecognition.cpppar le code suivant :#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); if ((size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set both SPEECH_KEY and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto speechRecognizer = SpeechRecognizer::FromConfig(speechConfig, audioConfig); std::cout << "Speak into your microphone.\n"; auto result = speechRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }Pour modifier la langue de la reconnaissance vocale, remplacez
en-USpar une autre langue prise en charge. Par exemple, utilisezes-ESpour l’espagnol (Espagne). Si vous ne spécifiez pas de langue, la valeur par défaut esten-US. Pour plus d’informations sur l’identification de l’une des nombreuses langues qui peuvent être parlées, consultez Identification de la langue.Générez et exécutez votre nouvelle application console pour démarrer la reconnaissance vocale à partir d’un microphone.
Important
N’oubliez pas de définir les variables d’environnement
SPEECH_KEYetSPEECH_REGION. Si vous ne définissez pas ces variables, l’exemple échoue avec un message d’erreur.Parlez dans votre microphone lorsque vous y êtes invité. Ce que vous dites doit apparaître sous forme de texte :
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Notes
Voici quelques autres éléments à prendre en compte :
Cet exemple utilise l’opération
RecognizeOnceAsyncpour transcrire les énoncés de jusqu’à 30 secondes ou jusqu’à ce que le silence soit détecté. Pour plus d’informations sur la reconnaissance continue des données audio plus longues, y compris les conversations multilingues, consultez Comment effectuer la reconnaissance vocale.Pour reconnaître la parole à partir d’un fichier audio, utilisez
FromWavFileInputau lieu deFromDefaultMicrophoneInput:auto audioConfig = AudioConfig::FromWavFileInput("YourAudioFile.wav");Pour les fichiers audio compressés tels que les fichiers MP4, installez GStreamer et utilisez
PullAudioInputStreamouPushAudioInputStream. Pour plus d’informations, consultez Utilisation de l’audio d’entrée compressée.
Nettoyer les ressources
Vous pouvez utiliser le portail Azure ou l’interface de ligne de commande (CLI) Azure pour supprimer la ressource Speech que vous avez créée.
Documentation de référence | Package (Go) | Exemples supplémentaires sur GitHub
Dans ce guide de démarrage rapide, vous créez et exécutez une application pour reconnaître et transcrire la reconnaissance vocale en temps réel.
Pour transcrire des fichiers audio de manière asynchrone, consultez Qu’est-ce que la transcription par lots ?. Si vous ne savez pas quelle solution de reconnaissance vocale est la plus adaptée pour vous, consultez Qu’est-ce que la reconnaissance vocale ?
Prérequis
- Un abonnement Azure. Vous pouvez en créer un gratuitement.
- Créer une ressource Speech dans le portail Azure.
- Obtenez la clé de ressource et la région Speech. Une fois votre ressource vocale déployée, sélectionnez Accéder à la ressource pour afficher et gérer les clés.
Configurer l’environnement
Installer le Kit SDK Speech pour Go. Pour connaître la configuration requise et les instructions, consultez Installer le kit de développement logiciel (SDK) Speech.
Définir des variables d’environnement
Vous devez authentifier votre application pour accéder à Azure AI services. Cet article vous montre comment utiliser des variables d’environnement pour stocker vos informations d’identification. Vous pouvez ensuite accéder aux variables d’environnement à partir de votre code pour authentifier votre application. Pour la production, utilisez un moyen plus sécurisé pour stocker vos informations d’identification et y accéder.
Important
Nous vous recommandons l’authentification Microsoft Entra ID avec les identités managées pour les ressources Azure pour éviter de stocker des informations d’identification avec vos applications qui s’exécutent dans le cloud.
Si vous utilisez une clé API, stockez-la en toute sécurité dans un autre emplacement, par exemple dans Azure Key Vault. N'incluez pas la clé API directement dans votre code et ne la diffusez jamais publiquement.
Pour plus d’informations sur la sécurité des services IA, consultez Authentifier les demandes auprès d’Azure AI services.
Pour définir les variables d'environnement de votre clé de ressource Speech et de votre région, ouvrez une fenêtre de console et suivez les instructions de votre système d'exploitation et de votre environnement de développement.
- Pour définir la variable d’environnement
SPEECH_KEY, remplacez your-key par l’une des clés de votre ressource. - Pour définir la variable d’environnement
SPEECH_REGION, remplacez your-region par l’une des régions de votre ressource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Remarque
Si vous avez uniquement besoin d’accéder aux variables d’environnement dans la console en cours d’exécution, vous pouvez la définir avec set au lieu de setx.
Après avoir ajouté les variables d'environnement, vous devrez éventuellement redémarrer tous les programmes qui ont besoin de lire les variables d'environnement, y compris la fenêtre de console. Par exemple, si vous utilisez Visual Studio comme éditeur, redémarrez Visual Studio avant d’exécuter l’exemple.
Reconnaître la voix provenant d’un micro
Suivez ces étapes pour créer un module GO.
Ouvrez une fenêtre d’invite de commandes dans le dossier où vous souhaitez placer le nouveau projet. Créez un fichier nommé speech-recognition.go.
Copiez le code suivant dans le fichier speech-recognition.go :
package main import ( "bufio" "fmt" "os" "github.com/Microsoft/cognitive-services-speech-sdk-go/audio" "github.com/Microsoft/cognitive-services-speech-sdk-go/speech" ) func sessionStartedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Started (ID=", event.SessionID, ")") } func sessionStoppedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Stopped (ID=", event.SessionID, ")") } func recognizingHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognizing:", event.Result.Text) } func recognizedHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognized:", event.Result.Text) } func cancelledHandler(event speech.SpeechRecognitionCanceledEventArgs) { defer event.Close() fmt.Println("Received a cancellation: ", event.ErrorDetails) fmt.Println("Did you set the speech resource key and region values?") } func main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speechKey := os.Getenv("SPEECH_KEY") speechRegion := os.Getenv("SPEECH_REGION") audioConfig, err := audio.NewAudioConfigFromDefaultMicrophoneInput() if err != nil { fmt.Println("Got an error: ", err) return } defer audioConfig.Close() speechConfig, err := speech.NewSpeechConfigFromSubscription(speechKey, speechRegion) if err != nil { fmt.Println("Got an error: ", err) return } defer speechConfig.Close() speechRecognizer, err := speech.NewSpeechRecognizerFromConfig(speechConfig, audioConfig) if err != nil { fmt.Println("Got an error: ", err) return } defer speechRecognizer.Close() speechRecognizer.SessionStarted(sessionStartedHandler) speechRecognizer.SessionStopped(sessionStoppedHandler) speechRecognizer.Recognizing(recognizingHandler) speechRecognizer.Recognized(recognizedHandler) speechRecognizer.Canceled(cancelledHandler) speechRecognizer.StartContinuousRecognitionAsync() defer speechRecognizer.StopContinuousRecognitionAsync() bufio.NewReader(os.Stdin).ReadBytes('\n') }Exécutez les commandes suivantes pour créer un fichier go.mod lié aux composants hébergés sur GitHub :
go mod init speech-recognition go get github.com/Microsoft/cognitive-services-speech-sdk-goImportant
N’oubliez pas de définir les variables d’environnement
SPEECH_KEYetSPEECH_REGION. Si vous ne définissez pas ces variables, l’exemple échoue avec un message d’erreur.Générez et exécutez le code :
go build go run speech-recognition
Nettoyer les ressources
Vous pouvez utiliser le portail Azure ou l’interface de ligne de commande (CLI) Azure pour supprimer la ressource Speech que vous avez créée.
Documentation de référence | Exemples supplémentaires sur GitHub
Dans ce guide de démarrage rapide, vous créez et exécutez une application pour reconnaître et transcrire la reconnaissance vocale en temps réel.
Pour transcrire des fichiers audio de manière asynchrone, consultez Qu’est-ce que la transcription par lots ?. Si vous ne savez pas quelle solution de reconnaissance vocale est la plus adaptée pour vous, consultez Qu’est-ce que la reconnaissance vocale ?
Prérequis
- Un abonnement Azure. Vous pouvez en créer un gratuitement.
- Créer une ressource Speech dans le portail Azure.
- Obtenez la clé de ressource et la région Speech. Une fois votre ressource vocale déployée, sélectionnez Accéder à la ressource pour afficher et gérer les clés.
Configurer l’environnement
Pour configurer votre environnement, installez le SDK Speech. L’exemple de ce guide de démarrage rapide fonctionne avec le runtime Java.
Installez Apache Maven. Exécutez ensuite
mvn -vpour confirmer la réussite de l’installation.Créez un fichier
pom.xmlà la racine de votre projet, puis copiez-y le code suivant :<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.microsoft.cognitiveservices.speech.samples</groupId> <artifactId>quickstart-eclipse</artifactId> <version>1.0.0-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>com.microsoft.cognitiveservices.speech</groupId> <artifactId>client-sdk</artifactId> <version>1.42.0</version> </dependency> </dependencies> </project>Installez le SDK Speech et les dépendances.
mvn clean dependency:copy-dependencies
Définir des variables d’environnement
Vous devez authentifier votre application pour accéder à Azure AI services. Cet article vous montre comment utiliser des variables d’environnement pour stocker vos informations d’identification. Vous pouvez ensuite accéder aux variables d’environnement à partir de votre code pour authentifier votre application. Pour la production, utilisez un moyen plus sécurisé pour stocker vos informations d’identification et y accéder.
Important
Nous vous recommandons l’authentification Microsoft Entra ID avec les identités managées pour les ressources Azure pour éviter de stocker des informations d’identification avec vos applications qui s’exécutent dans le cloud.
Si vous utilisez une clé API, stockez-la en toute sécurité dans un autre emplacement, par exemple dans Azure Key Vault. N'incluez pas la clé API directement dans votre code et ne la diffusez jamais publiquement.
Pour plus d’informations sur la sécurité des services IA, consultez Authentifier les demandes auprès d’Azure AI services.
Pour définir les variables d'environnement de votre clé de ressource Speech et de votre région, ouvrez une fenêtre de console et suivez les instructions de votre système d'exploitation et de votre environnement de développement.
- Pour définir la variable d’environnement
SPEECH_KEY, remplacez your-key par l’une des clés de votre ressource. - Pour définir la variable d’environnement
SPEECH_REGION, remplacez your-region par l’une des régions de votre ressource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Remarque
Si vous avez uniquement besoin d’accéder aux variables d’environnement dans la console en cours d’exécution, vous pouvez la définir avec set au lieu de setx.
Après avoir ajouté les variables d'environnement, vous devrez éventuellement redémarrer tous les programmes qui ont besoin de lire les variables d'environnement, y compris la fenêtre de console. Par exemple, si vous utilisez Visual Studio comme éditeur, redémarrez Visual Studio avant d’exécuter l’exemple.
Reconnaître la voix provenant d’un micro
Suivez ces étapes pour créer une application console pour la reconnaissance vocale.
Créez un fichier nommé SpeechRecognition.java dans le même répertoire racine du projet.
Copiez le code suivant dans SpeechRecognition.java :
import com.microsoft.cognitiveservices.speech.*; import com.microsoft.cognitiveservices.speech.audio.AudioConfig; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; public class SpeechRecognition { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" private static String speechKey = System.getenv("SPEECH_KEY"); private static String speechRegion = System.getenv("SPEECH_REGION"); public static void main(String[] args) throws InterruptedException, ExecutionException { SpeechConfig speechConfig = SpeechConfig.fromSubscription(speechKey, speechRegion); speechConfig.setSpeechRecognitionLanguage("en-US"); recognizeFromMicrophone(speechConfig); } public static void recognizeFromMicrophone(SpeechConfig speechConfig) throws InterruptedException, ExecutionException { AudioConfig audioConfig = AudioConfig.fromDefaultMicrophoneInput(); SpeechRecognizer speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); System.out.println("Speak into your microphone."); Future<SpeechRecognitionResult> task = speechRecognizer.recognizeOnceAsync(); SpeechRecognitionResult speechRecognitionResult = task.get(); if (speechRecognitionResult.getReason() == ResultReason.RecognizedSpeech) { System.out.println("RECOGNIZED: Text=" + speechRecognitionResult.getText()); } else if (speechRecognitionResult.getReason() == ResultReason.NoMatch) { System.out.println("NOMATCH: Speech could not be recognized."); } else if (speechRecognitionResult.getReason() == ResultReason.Canceled) { CancellationDetails cancellation = CancellationDetails.fromResult(speechRecognitionResult); System.out.println("CANCELED: Reason=" + cancellation.getReason()); if (cancellation.getReason() == CancellationReason.Error) { System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode()); System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails()); System.out.println("CANCELED: Did you set the speech resource key and region values?"); } } System.exit(0); } }Pour modifier la langue de la reconnaissance vocale, remplacez
en-USpar une autre langue prise en charge. Par exemple, utilisezes-ESpour l’espagnol (Espagne). Si vous ne spécifiez pas de langue, la valeur par défaut esten-US. Pour plus d’informations sur l’identification de l’une des nombreuses langues qui peuvent être parlées, consultez Identification de la langue.Exécutez votre nouvelle application console pour démarrer la reconnaissance vocale à partir d’un microphone :
javac SpeechRecognition.java -cp ".;target\dependency\*" java -cp ".;target\dependency\*" SpeechRecognitionImportant
N’oubliez pas de définir les variables d’environnement
SPEECH_KEYetSPEECH_REGION. Si vous ne définissez pas ces variables, l’exemple échoue avec un message d’erreur.Parlez dans votre microphone lorsque vous y êtes invité. Ce que vous dites doit apparaître sous forme de texte :
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Notes
Voici quelques autres éléments à prendre en compte :
Cet exemple utilise l’opération
RecognizeOnceAsyncpour transcrire les énoncés de jusqu’à 30 secondes ou jusqu’à ce que le silence soit détecté. Pour plus d’informations sur la reconnaissance continue des données audio plus longues, y compris les conversations multilingues, consultez Comment effectuer la reconnaissance vocale.Pour reconnaître la parole à partir d’un fichier audio, utilisez
fromWavFileInputau lieu defromDefaultMicrophoneInput:AudioConfig audioConfig = AudioConfig.fromWavFileInput("YourAudioFile.wav");Pour les fichiers audio compressés tels que les fichiers MP4, installez GStreamer et utilisez
PullAudioInputStreamouPushAudioInputStream. Pour plus d’informations, consultez Utilisation de l’audio d’entrée compressée.
Nettoyer les ressources
Vous pouvez utiliser le portail Azure ou l’interface de ligne de commande (CLI) Azure pour supprimer la ressource Speech que vous avez créée.
Documentation de référence | Package (npm) | Exemples supplémentaires sur GitHub | Code source de la bibliothèque
Dans ce guide de démarrage rapide, vous créez et exécutez une application pour reconnaître et transcrire la reconnaissance vocale en temps réel.
Pour transcrire des fichiers audio de manière asynchrone, consultez Qu’est-ce que la transcription par lots ?. Si vous ne savez pas quelle solution de reconnaissance vocale est la plus adaptée pour vous, consultez Qu’est-ce que la reconnaissance vocale ?
Prérequis
- Un abonnement Azure. Vous pouvez en créer un gratuitement.
- Créer une ressource Speech dans le portail Azure.
- Obtenez la clé de ressource et la région Speech. Une fois votre ressource vocale déployée, sélectionnez Accéder à la ressource pour afficher et gérer les clés.
Vous avez également besoin d’un fichier audio .wav sur votre ordinateur local. Vous pouvez utiliser votre propre fichier .wav (jusqu’à 30 secondes) ou télécharger l’exemple de fichier https://crbn.us/whatstheweatherlike.wav.
Configurer l’environnement
Pour configurer votre environnement, installez le SDK Speech pour JavaScript. Exécutez la commande suivante : npm install microsoft-cognitiveservices-speech-sdk. Pour obtenir des instructions d’installation, consultez Installer le Kit de développement logiciel (SDK) Speech.
Définir des variables d’environnement
Vous devez authentifier votre application pour accéder à Azure AI services. Cet article vous montre comment utiliser des variables d’environnement pour stocker vos informations d’identification. Vous pouvez ensuite accéder aux variables d’environnement à partir de votre code pour authentifier votre application. Pour la production, utilisez un moyen plus sécurisé pour stocker vos informations d’identification et y accéder.
Important
Nous vous recommandons l’authentification Microsoft Entra ID avec les identités managées pour les ressources Azure pour éviter de stocker des informations d’identification avec vos applications qui s’exécutent dans le cloud.
Si vous utilisez une clé API, stockez-la en toute sécurité dans un autre emplacement, par exemple dans Azure Key Vault. N'incluez pas la clé API directement dans votre code et ne la diffusez jamais publiquement.
Pour plus d’informations sur la sécurité des services IA, consultez Authentifier les demandes auprès d’Azure AI services.
Pour définir les variables d'environnement de votre clé de ressource Speech et de votre région, ouvrez une fenêtre de console et suivez les instructions de votre système d'exploitation et de votre environnement de développement.
- Pour définir la variable d’environnement
SPEECH_KEY, remplacez your-key par l’une des clés de votre ressource. - Pour définir la variable d’environnement
SPEECH_REGION, remplacez your-region par l’une des régions de votre ressource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Remarque
Si vous avez uniquement besoin d’accéder aux variables d’environnement dans la console en cours d’exécution, vous pouvez la définir avec set au lieu de setx.
Après avoir ajouté les variables d'environnement, vous devrez éventuellement redémarrer tous les programmes qui ont besoin de lire les variables d'environnement, y compris la fenêtre de console. Par exemple, si vous utilisez Visual Studio comme éditeur, redémarrez Visual Studio avant d’exécuter l’exemple.
Utiliser la reconnaissance vocale à partir d’un fichier
Conseil
Essayez la boîte à outils Azure AI Speech Toolkit pour générer et exécuter facilement des exemples sur Visual Studio Code.
Suivez ces étapes pour créer une application console Node.js à des fins de reconnaissance vocale.
Ouvrez une fenêtre d’invite de commandes à l’emplacement où vous souhaitez placer le nouveau projet, puis créez un fichier nommé SpeechRecognition.js.
Installez le SDK Speech pour JavaScript :
npm install microsoft-cognitiveservices-speech-sdkCopiez le code suivant dans SpeechRecognition.js :
const fs = require("fs"); const sdk = require("microsoft-cognitiveservices-speech-sdk"); // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" const speechConfig = sdk.SpeechConfig.fromSubscription(process.env.SPEECH_KEY, process.env.SPEECH_REGION); speechConfig.speechRecognitionLanguage = "en-US"; function fromFile() { let audioConfig = sdk.AudioConfig.fromWavFileInput(fs.readFileSync("YourAudioFile.wav")); let speechRecognizer = new sdk.SpeechRecognizer(speechConfig, audioConfig); speechRecognizer.recognizeOnceAsync(result => { switch (result.reason) { case sdk.ResultReason.RecognizedSpeech: console.log(`RECOGNIZED: Text=${result.text}`); break; case sdk.ResultReason.NoMatch: console.log("NOMATCH: Speech could not be recognized."); break; case sdk.ResultReason.Canceled: const cancellation = sdk.CancellationDetails.fromResult(result); console.log(`CANCELED: Reason=${cancellation.reason}`); if (cancellation.reason == sdk.CancellationReason.Error) { console.log(`CANCELED: ErrorCode=${cancellation.ErrorCode}`); console.log(`CANCELED: ErrorDetails=${cancellation.errorDetails}`); console.log("CANCELED: Did you set the speech resource key and region values?"); } break; } speechRecognizer.close(); }); } fromFile();Dans SpeechRecognition.js, remplacez YourAudioFile.wav par votre propre fichier .wav. Cet exemple reconnaît uniquement la voix à partir d’un fichier .wav. Pour plus d’informations sur d’autres formats audio, consultez Utilisation de l’audio d’entrée compressée. Cet exemple prend en charge jusqu’à 30 secondes d’audio.
Pour modifier la langue de la reconnaissance vocale, remplacez
en-USpar une autre langue prise en charge. Par exemple, utilisezes-ESpour l’espagnol (Espagne). Si vous ne spécifiez pas de langue, la valeur par défaut esten-US. Pour plus d’informations sur l’identification de l’une des nombreuses langues qui peuvent être parlées, consultez Identification de la langue.Exécutez votre nouvelle application console pour démarrer la reconnaissance vocale à partir d’un fichier :
node.exe SpeechRecognition.jsImportant
N’oubliez pas de définir les variables d’environnement
SPEECH_KEYetSPEECH_REGION. Si vous ne définissez pas ces variables, l’exemple échoue avec un message d’erreur.La parole du fichier audio doit être générée sous forme de texte :
RECOGNIZED: Text=I'm excited to try speech to text.
Notes
Cet exemple utilise l’opération recognizeOnceAsync pour transcrire les énoncés de jusqu’à 30 secondes ou jusqu’à ce que le silence soit détecté. Pour plus d’informations sur la reconnaissance continue des données audio plus longues, y compris les conversations multilingues, consultez Comment effectuer la reconnaissance vocale.
Notes
La reconnaissance de la parole à partir d’un microphone n’est pas prise en charge dans Node.js. Elle est prise en charge uniquement dans un environnement JavaScript basé sur un navigateur. Pour plus d’informations, consultez l’exemple React et l’implémentation de la conversion de parole en texte à partir d’un microphone sur GitHub.
L’exemple React présente les modèles de conception pour l’échange et la gestion des jetons d’authentification. Il montre également la capture de l’audio à partir d’un microphone ou d’un fichier pour les conversions de parole en texte.
Nettoyer les ressources
Vous pouvez utiliser le portail Azure ou l’interface de ligne de commande (CLI) Azure pour supprimer la ressource Speech que vous avez créée.
Documentation de référence | Package (PyPi) | Exemples supplémentaires sur GitHub
Dans ce guide de démarrage rapide, vous créez et exécutez une application pour reconnaître et transcrire la reconnaissance vocale en temps réel.
Pour transcrire des fichiers audio de manière asynchrone, consultez Qu’est-ce que la transcription par lots ?. Si vous ne savez pas quelle solution de reconnaissance vocale est la plus adaptée pour vous, consultez Qu’est-ce que la reconnaissance vocale ?
Prérequis
- Un abonnement Azure. Vous pouvez en créer un gratuitement.
- Créer une ressource Speech dans le portail Azure.
- Obtenez la clé de ressource et la région Speech. Une fois votre ressource vocale déployée, sélectionnez Accéder à la ressource pour afficher et gérer les clés.
Configurer l’environnement
Le kit SDK Speech pour Python est disponible sous forme de module Python Package Index (PyPI). Le Kit de développement logiciel (SDK) Speech pour Python est compatible avec Windows, Linux et macOS.
- Pour Windows, vous devez installer Microsoft Redistributable Visual C++ pour Visual Studio 2015, 2017, 2019 et 2022 pour votre plateforme. La toute première installation de ce package peut nécessiter un redémarrage.
- Sur Linux, vous devez utiliser l’architecture cible x64.
Installez Python 3.7 ou une version ultérieure. Pour d’autres exigences, consultez Installer le Kit de développement logiciel (SDK) Speech.
Définir des variables d’environnement
Vous devez authentifier votre application pour accéder à Azure AI services. Cet article vous montre comment utiliser des variables d’environnement pour stocker vos informations d’identification. Vous pouvez ensuite accéder aux variables d’environnement à partir de votre code pour authentifier votre application. Pour la production, utilisez un moyen plus sécurisé pour stocker vos informations d’identification et y accéder.
Important
Nous vous recommandons l’authentification Microsoft Entra ID avec les identités managées pour les ressources Azure pour éviter de stocker des informations d’identification avec vos applications qui s’exécutent dans le cloud.
Si vous utilisez une clé API, stockez-la en toute sécurité dans un autre emplacement, par exemple dans Azure Key Vault. N'incluez pas la clé API directement dans votre code et ne la diffusez jamais publiquement.
Pour plus d’informations sur la sécurité des services IA, consultez Authentifier les demandes auprès d’Azure AI services.
Pour définir les variables d'environnement de votre clé de ressource Speech et de votre région, ouvrez une fenêtre de console et suivez les instructions de votre système d'exploitation et de votre environnement de développement.
- Pour définir la variable d’environnement
SPEECH_KEY, remplacez your-key par l’une des clés de votre ressource. - Pour définir la variable d’environnement
SPEECH_REGION, remplacez your-region par l’une des régions de votre ressource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Remarque
Si vous avez uniquement besoin d’accéder aux variables d’environnement dans la console en cours d’exécution, vous pouvez la définir avec set au lieu de setx.
Après avoir ajouté les variables d'environnement, vous devrez éventuellement redémarrer tous les programmes qui ont besoin de lire les variables d'environnement, y compris la fenêtre de console. Par exemple, si vous utilisez Visual Studio comme éditeur, redémarrez Visual Studio avant d’exécuter l’exemple.
Reconnaître la voix provenant d’un micro
Conseil
Essayez la boîte à outils Azure AI Speech Toolkit pour générer et exécuter facilement des exemples sur Visual Studio Code.
Suivez ces étapes pour créer une application console.
Ouvrez une fenêtre d’invite de commandes dans le dossier où vous souhaitez placer le nouveau projet. Créez un fichier nommé speech_recognition.py.
Exécutez cette commande pour installer le SDK Speech :
pip install azure-cognitiveservices-speechCopiez le code suivant dans le fichier speech_recognition.py :
import os import azure.cognitiveservices.speech as speechsdk def recognize_from_microphone(): # This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('SPEECH_KEY'), region=os.environ.get('SPEECH_REGION')) speech_config.speech_recognition_language="en-US" audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True) speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config) print("Speak into your microphone.") speech_recognition_result = speech_recognizer.recognize_once_async().get() if speech_recognition_result.reason == speechsdk.ResultReason.RecognizedSpeech: print("Recognized: {}".format(speech_recognition_result.text)) elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized: {}".format(speech_recognition_result.no_match_details)) elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled: cancellation_details = speech_recognition_result.cancellation_details print("Speech Recognition canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) print("Did you set the speech resource key and region values?") recognize_from_microphone()Pour modifier la langue de la reconnaissance vocale, remplacez
en-USpar une autre langue prise en charge. Par exemple, utilisezes-ESpour l’espagnol (Espagne). Si vous ne spécifiez pas de langue, la valeur par défaut esten-US. Pour plus d’informations sur l’identification de l’une des langues qui peuvent être parlées, consultez Identification de la langue.Exécutez votre nouvelle application console pour démarrer la reconnaissance vocale à partir d’un microphone :
python speech_recognition.pyImportant
N’oubliez pas de définir les variables d’environnement
SPEECH_KEYetSPEECH_REGION. Si vous ne définissez pas ces variables, l’exemple échoue avec un message d’erreur.Parlez dans votre microphone lorsque vous y êtes invité. Ce que vous dites doit apparaître sous forme de texte :
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Notes
Voici quelques autres éléments à prendre en compte :
Cet exemple utilise l’opération
recognize_once_asyncpour transcrire les énoncés de jusqu’à 30 secondes ou jusqu’à ce que le silence soit détecté. Pour plus d’informations sur la reconnaissance continue des données audio plus longues, y compris les conversations multilingues, consultez Comment effectuer la reconnaissance vocale.Pour reconnaître la parole à partir d’un fichier audio, utilisez
filenameau lieu deuse_default_microphone:audio_config = speechsdk.audio.AudioConfig(filename="YourAudioFile.wav")Pour les fichiers audio compressés tels que les fichiers MP4, installez GStreamer et utilisez
PullAudioInputStreamouPushAudioInputStream. Pour plus d’informations, consultez Utilisation de l’audio d’entrée compressée.
Nettoyer les ressources
Vous pouvez utiliser le portail Azure ou l’interface de ligne de commande (CLI) Azure pour supprimer la ressource Speech que vous avez créée.
Documentation de référence | Package (téléchargement) | Exemples supplémentaires sur GitHub
Dans ce guide de démarrage rapide, vous créez et exécutez une application pour reconnaître et transcrire la reconnaissance vocale en temps réel.
Pour transcrire des fichiers audio de manière asynchrone, consultez Qu’est-ce que la transcription par lots ?. Si vous ne savez pas quelle solution de reconnaissance vocale est la plus adaptée pour vous, consultez Qu’est-ce que la reconnaissance vocale ?
Prérequis
- Un abonnement Azure. Vous pouvez en créer un gratuitement.
- Créer une ressource Speech dans le portail Azure.
- Obtenez la clé de ressource et la région Speech. Une fois votre ressource vocale déployée, sélectionnez Accéder à la ressource pour afficher et gérer les clés.
Configurer l’environnement
Le kit de développement logiciel (SDK) Speech pour Swift est distribué en tant que bundle de framework. L’infrastructure prend en charge Objective-C et Swift sur iOS et macOS.
Le kit de développement logiciel (SDK) Speech peut être utilisé dans les projets Xcode en tant que CocoaPod, ou téléchargé directement et lié manuellement. Ce guide utilise un CocoaPod. Installez le gestionnaire de dépendances de CocoaPod comme décrit dans ses instructions d’installation.
Définir des variables d’environnement
Vous devez authentifier votre application pour accéder à Azure AI services. Cet article vous montre comment utiliser des variables d’environnement pour stocker vos informations d’identification. Vous pouvez ensuite accéder aux variables d’environnement à partir de votre code pour authentifier votre application. Pour la production, utilisez un moyen plus sécurisé pour stocker vos informations d’identification et y accéder.
Important
Nous vous recommandons l’authentification Microsoft Entra ID avec les identités managées pour les ressources Azure pour éviter de stocker des informations d’identification avec vos applications qui s’exécutent dans le cloud.
Si vous utilisez une clé API, stockez-la en toute sécurité dans un autre emplacement, par exemple dans Azure Key Vault. N'incluez pas la clé API directement dans votre code et ne la diffusez jamais publiquement.
Pour plus d’informations sur la sécurité des services IA, consultez Authentifier les demandes auprès d’Azure AI services.
Pour définir les variables d'environnement de votre clé de ressource Speech et de votre région, ouvrez une fenêtre de console et suivez les instructions de votre système d'exploitation et de votre environnement de développement.
- Pour définir la variable d’environnement
SPEECH_KEY, remplacez your-key par l’une des clés de votre ressource. - Pour définir la variable d’environnement
SPEECH_REGION, remplacez your-region par l’une des régions de votre ressource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Remarque
Si vous avez uniquement besoin d’accéder aux variables d’environnement dans la console en cours d’exécution, vous pouvez la définir avec set au lieu de setx.
Après avoir ajouté les variables d'environnement, vous devrez éventuellement redémarrer tous les programmes qui ont besoin de lire les variables d'environnement, y compris la fenêtre de console. Par exemple, si vous utilisez Visual Studio comme éditeur, redémarrez Visual Studio avant d’exécuter l’exemple.
Reconnaître la voix provenant d’un micro
Pour reconnaître la parole dans une application macOS, procédez comme suit.
Clonez le référentiel Azure-Samples/cognitive-services-speech-sdk pour obtenir la reconnaissance vocale à partir d’un microphone dans l’exemple de projet Swift sur macOS. Le référentiel contient également des exemples iOS.
Accédez au répertoire de l’exemple d’application téléchargé (
helloworld) dans un terminal.Exécutez la commande
pod install. Cette commande génère un espace de travail Xcodehelloworld.xcworkspacecontenant l’exemple d’application et le SDK Speech comme dépendance.Ouvrez l’espace de travail
helloworld.xcworkspacedans Xcode.Ouvrez le fichier nommé AppDelegate.swift et recherchez les méthodes
applicationDidFinishLaunchingetrecognizeFromMiccomme indiqué ici.import Cocoa @NSApplicationMain class AppDelegate: NSObject, NSApplicationDelegate { var label: NSTextField! var fromMicButton: NSButton! var sub: String! var region: String! @IBOutlet weak var window: NSWindow! func applicationDidFinishLaunching(_ aNotification: Notification) { print("loading") // load subscription information sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"] label = NSTextField(frame: NSRect(x: 100, y: 50, width: 200, height: 200)) label.textColor = NSColor.black label.lineBreakMode = .byWordWrapping label.stringValue = "Recognition Result" label.isEditable = false self.window.contentView?.addSubview(label) fromMicButton = NSButton(frame: NSRect(x: 100, y: 300, width: 200, height: 30)) fromMicButton.title = "Recognize" fromMicButton.target = self fromMicButton.action = #selector(fromMicButtonClicked) self.window.contentView?.addSubview(fromMicButton) } @objc func fromMicButtonClicked() { DispatchQueue.global(qos: .userInitiated).async { self.recognizeFromMic() } } func recognizeFromMic() { var speechConfig: SPXSpeechConfiguration? do { try speechConfig = SPXSpeechConfiguration(subscription: sub, region: region) } catch { print("error \(error) happened") speechConfig = nil } speechConfig?.speechRecognitionLanguage = "en-US" let audioConfig = SPXAudioConfiguration() let reco = try! SPXSpeechRecognizer(speechConfiguration: speechConfig!, audioConfiguration: audioConfig) reco.addRecognizingEventHandler() {reco, evt in print("intermediate recognition result: \(evt.result.text ?? "(no result)")") self.updateLabel(text: evt.result.text, color: .gray) } updateLabel(text: "Listening ...", color: .gray) print("Listening...") let result = try! reco.recognizeOnce() print("recognition result: \(result.text ?? "(no result)"), reason: \(result.reason.rawValue)") updateLabel(text: result.text, color: .black) if result.reason != SPXResultReason.recognizedSpeech { let cancellationDetails = try! SPXCancellationDetails(fromCanceledRecognitionResult: result) print("cancelled: \(result.reason), \(cancellationDetails.errorDetails)") print("Did you set the speech resource key and region values?") updateLabel(text: "Error: \(cancellationDetails.errorDetails)", color: .red) } } func updateLabel(text: String?, color: NSColor) { DispatchQueue.main.async { self.label.stringValue = text! self.label.textColor = color } } }Dans AppDelegate.m, utilisez les variables d’environnement que vous avez précédemment définies pour la clé et la région de votre ressource Speech.
sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"]Pour modifier la langue de la reconnaissance vocale, remplacez
en-USpar une autre langue prise en charge. Par exemple, utilisezes-ESpour l’espagnol (Espagne). Si vous ne spécifiez pas de langue, la valeur par défaut esten-US. Pour plus d’informations sur l’identification de l’une des nombreuses langues qui peuvent être parlées, consultez Identification de la langue.Pour afficher la sortie de débogage, sélectionnez View>Debug Area>Activate Console.
Générez et exécutez l’exemple de code en sélectionnant Produit>Exécuter dans le menu ou en sélectionnant le bouton Lecture.
Important
N’oubliez pas de définir les variables d’environnement
SPEECH_KEYetSPEECH_REGION. Si vous ne définissez pas ces variables, l’exemple échoue avec un message d’erreur.
Après avoir sélectionné le bouton dans l’application et prononcé quelques mots, vous devez voir le texte énoncé dans la partie inférieure de l’écran. Quand vous exécutez l’application pour la première fois, elle vous invite à autoriser l’application à accéder au microphone de votre ordinateur.
Notes
Cet exemple utilise l’opération recognizeOnce pour transcrire les énoncés de jusqu’à 30 secondes ou jusqu’à ce que le silence soit détecté. Pour plus d’informations sur la reconnaissance continue des données audio plus longues, y compris les conversations multilingues, consultez Comment effectuer la reconnaissance vocale.
Objective-C
Le Kit de développement logiciel (SDK) Speech pour Objective-C partage les bibliothèques clientes et la documentation de référence avec le Kit de développement logiciel (SDK) Speech pour Swift. Pour obtenir des exemples de code Objective-C, consultez l’exemple de projet Reconnaissance vocale depuis un microphone dans Objective-C sur macOS dans GitHub.
Nettoyer les ressources
Vous pouvez utiliser le portail Azure ou l’interface de ligne de commande (CLI) Azure pour supprimer la ressource Speech que vous avez créée.
Informations de référence sur l’API REST de reconnaissance vocale | Informations de référence sur l’API REST de reconnaissance vocale pour l’audio court | Exemples supplémentaires sur GitHub
Dans ce guide de démarrage rapide, vous créez et exécutez une application pour reconnaître et transcrire la reconnaissance vocale en temps réel.
Pour transcrire des fichiers audio de manière asynchrone, consultez Qu’est-ce que la transcription par lots ?. Si vous ne savez pas quelle solution de reconnaissance vocale est la plus adaptée pour vous, consultez Qu’est-ce que la reconnaissance vocale ?
Prérequis
- Un abonnement Azure. Vous pouvez en créer un gratuitement.
- Créer une ressource Speech dans le portail Azure.
- Obtenez la clé de ressource et la région Speech. Une fois votre ressource vocale déployée, sélectionnez Accéder à la ressource pour afficher et gérer les clés.
Vous avez également besoin d’un fichier audio .wav sur votre ordinateur local. Vous pouvez utiliser votre propre fichier .wav (jusqu’à 60 secondes) ou télécharger l’exemple de fichier https://crbn.us/whatstheweatherlike.wav.
Définir des variables d’environnement
Vous devez authentifier votre application pour accéder à Azure AI services. Cet article vous montre comment utiliser des variables d’environnement pour stocker vos informations d’identification. Vous pouvez ensuite accéder aux variables d’environnement à partir de votre code pour authentifier votre application. Pour la production, utilisez un moyen plus sécurisé pour stocker vos informations d’identification et y accéder.
Important
Nous vous recommandons l’authentification Microsoft Entra ID avec les identités managées pour les ressources Azure pour éviter de stocker des informations d’identification avec vos applications qui s’exécutent dans le cloud.
Si vous utilisez une clé API, stockez-la en toute sécurité dans un autre emplacement, par exemple dans Azure Key Vault. N'incluez pas la clé API directement dans votre code et ne la diffusez jamais publiquement.
Pour plus d’informations sur la sécurité des services IA, consultez Authentifier les demandes auprès d’Azure AI services.
Pour définir les variables d'environnement de votre clé de ressource Speech et de votre région, ouvrez une fenêtre de console et suivez les instructions de votre système d'exploitation et de votre environnement de développement.
- Pour définir la variable d’environnement
SPEECH_KEY, remplacez your-key par l’une des clés de votre ressource. - Pour définir la variable d’environnement
SPEECH_REGION, remplacez your-region par l’une des régions de votre ressource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Remarque
Si vous avez uniquement besoin d’accéder aux variables d’environnement dans la console en cours d’exécution, vous pouvez la définir avec set au lieu de setx.
Après avoir ajouté les variables d'environnement, vous devrez éventuellement redémarrer tous les programmes qui ont besoin de lire les variables d'environnement, y compris la fenêtre de console. Par exemple, si vous utilisez Visual Studio comme éditeur, redémarrez Visual Studio avant d’exécuter l’exemple.
Utiliser la reconnaissance vocale à partir d’un fichier
Ouvrez une fenêtre de console et exécutez la commande cURL suivante. Remplacez YourAudioFile.wav par le chemin d’accès et le nom de votre fichier audio.
curl --location --request POST "https://%SPEECH_REGION%.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed" ^
--header "Ocp-Apim-Subscription-Key: %SPEECH_KEY%" ^
--header "Content-Type: audio/wav" ^
--data-binary "@YourAudioFile.wav"
Important
N’oubliez pas de définir les variables d’environnement SPEECH_KEY et SPEECH_REGION. Si vous ne définissez pas ces variables, l’exemple échoue avec un message d’erreur.
Vous devriez recevoir une réponse similaire à ce qui est présenté ici. DisplayText doit être le texte qui a été reconnu à partir de votre fichier audio. La commande reconnaît jusqu’à 60 secondes d’audio et la convertit en texte.
{
"RecognitionStatus": "Success",
"DisplayText": "My voice is my passport, verify me.",
"Offset": 6600000,
"Duration": 32100000
}
Pour plus d’informations, consultez API REST de reconnaissance vocale pour l’audio court.
Nettoyer les ressources
Vous pouvez utiliser le portail Azure ou l’interface de ligne de commande (CLI) Azure pour supprimer la ressource Speech que vous avez créée.
Dans ce guide de démarrage rapide, vous créez et exécutez une application pour reconnaître et transcrire la reconnaissance vocale en temps réel.
Pour transcrire des fichiers audio de manière asynchrone, consultez Qu’est-ce que la transcription par lots ?. Si vous ne savez pas quelle solution de reconnaissance vocale est la plus adaptée pour vous, consultez Qu’est-ce que la reconnaissance vocale ?
Prérequis
- Un abonnement Azure. Vous pouvez en créer un gratuitement.
- Créer une ressource Speech dans le portail Azure.
- Obtenez la clé de ressource et la région Speech. Une fois votre ressource vocale déployée, sélectionnez Accéder à la ressource pour afficher et gérer les clés.
Configurer l’environnement
Suivez ces étapes et consultez le guide de démarrage rapide de l’interface CLI Speech pour connaître les autres conditions requises pour votre plateforme.
Exécutez la commande CLI .NET suivante pour installer l’interface CLI Speech :
dotnet tool install --global Microsoft.CognitiveServices.Speech.CLIExécutez les commandes suivantes pour configurer la clé et la région de votre ressource Speech. Remplacez
SUBSCRIPTION-KEYpar la clé de la ressource Speech et remplacezREGIONpar la région de la ressource Speech.spx config @key --set SUBSCRIPTION-KEY spx config @region --set REGION
Reconnaître la voix provenant d’un micro
Exécutez la commande suivante pour démarrer la reconnaissance vocale à partir d’un microphone :
spx recognize --microphone --source en-USParlez dans le microphone et vous verrez la transcription de vos mots en texte en temps réel. L’interface CLI Speech s’arrête après une période de silence de 30 secondes ou quand vous appuyez sur Ctrl+C.
Connection CONNECTED... RECOGNIZED: I'm excited to try speech to text.
Notes
Voici quelques autres éléments à prendre en compte :
Pour effectuer une reconnaissance vocale à partir d’un fichier audio, utilisez
--fileau lieu de--microphone. Pour les fichiers audio compressés tels que les fichiers MP4, installez GStreamer et utilisez--format. Pour plus d’informations, consultez Utilisation de l’audio d’entrée compressée.spx recognize --file YourAudioFile.wav spx recognize --file YourAudioFile.mp4 --format anyPour améliorer la précision de la reconnaissance de mots ou d’énoncés spécifiques, utilisez une liste d’expressions. Vous incluez une liste d’expressions en ligne ou via un fichier texte avec la commande
recognize:spx recognize --microphone --phrases "Contoso;Jessie;Rehaan;" spx recognize --microphone --phrases @phrases.txtPour modifier la langue de la reconnaissance vocale, remplacez
en-USpar une autre langue prise en charge. Par exemple, utilisezes-ESpour l’espagnol (Espagne). Si vous ne spécifiez pas de langue, la valeur par défaut esten-US.spx recognize --microphone --source es-ESPour une reconnaissance continue d’un élément audio de plus de 30 secondes, ajoutez
--continuous:spx recognize --microphone --source es-ES --continuousExécutez cette commande pour obtenir des informations sur d’autres options de reconnaissance vocale, telles que l’entrée et la sortie de fichiers :
spx help recognize
Nettoyer les ressources
Vous pouvez utiliser le portail Azure ou l’interface de ligne de commande (CLI) Azure pour supprimer la ressource Speech que vous avez créée.