Personnaliser un modèle avec des réglages
Azure OpenAI Service vous permet d’adapter nos modèles à vos jeux de données personnels à l’aide d’un processus appelé ajustement. Cette étape de personnalisation vous permet de profiter au mieux du service en vous fournissant les éléments suivants :
- Résultats de qualité supérieure à ce que vous pouvez obtenir simplement à partir de l’ingénierie rapide
- La possibilité de s’entraîner sur un plus grand nombre d’exemples que ne le permet la limite maximale du contexte de requête d’un modèle.
- Économies de jetons en raison d’invites plus courtes
- Demandes à latence inférieure, en particulier lors de l’utilisation de modèles plus petits.
Contrairement à l’apprentissage en quelques essais, l’ajustement améliore le modèle en effectuant un apprentissage sur beaucoup plus d’exemples qu’il n’est possible d’en contenir dans une invite, ce qui vous permet d’obtenir de meilleurs résultats pour un grand nombre de tâches. Étant donné que l’ajustement adapte les poids du modèle de base afin d’améliorer les performances pour une tâche spécifique, vous n’aurez pas besoin d’inclure autant d’exemples ou d’instructions dans votre invite. Cela signifie moins de texte envoyé et moins de jetons traités sur chaque appel d’API, ce qui permet potentiellement d’économiser des coûts et d’améliorer la latence des requêtes.
Nous utilisons la LoRA (low rank approximation), ou approximation de rang faible, pour ajuster les modèles de manière à réduire leur complexité sans affecter leurs performances de manière significative. Cette méthode consiste à rapprocher la matrice originale de rang élevé d’une matrice de rang inférieur, ce qui permet d’ajuster uniquement un sous-ensemble plus restreint de paramètres importants au cours de la phase d’apprentissage supervisée, rendant ainsi le modèle plus facile à gérer et plus efficace. Pour les utilisateurs, cela rend l’apprentissage plus rapide et plus abordable que d’autres techniques.
Deux expériences uniques de réglage précis existent dans le portail Azure AI Foundry :
- Vue Hub/Project : prend en charge le réglage précis de modèles de plusieurs fournisseurs, notamment Azure OpenAI, Meta Llama, Microsoft Phi, etc.
- Vue centrée sur Azure OpenAI : prend uniquement en charge le réglage précis des modèles Azure OpenAI, mais prend en charge des fonctionnalités supplémentaires telles que l’intégration en préversion Weights & Biases (W&B).
Si vous n’effectuez des réglages précis que sur les modèles Azure OpenAI, nous vous recommandons d’utiliser l’expérience de réglage précis centrée sur Azure OpenAI, disponible en accédant à https://oai.azure.com.
Prérequis
- Lisez le guide expliquant quand utiliser l’ajustement Azure OpenAI.
- Un abonnement Azure. Créez-en un gratuitement.
- Une ressource Azure OpenAI située dans une région qui prend en charge un ajustement du modèle Azure OpenAI. Consultez le tableau récapitulatif des modèles et de leur disponibilité par région pour obtenir la liste des modèles disponibles par région et les fonctionnalités prises en charge. Pour plus d’informations, consultez l’article Créer une ressource et déployer un modèle à l’aide d’Azure OpenAI.
- L’accès au réglage précis nécessite un contributeur OpenAI de Cognitive Services.
- Si vous n’avez pas encore accès au quota d’affichage et que vous déployez des modèles dans le portail Azure AI Foundry, vous aurez besoin d’autorisations supplémentaires.
Modèles
Les modèles suivants prennent en charge le réglage précis :
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)*gpt-4o(2024-08-06)gpt-4o-mini(18-07-2024)
* L’optimisation de ce modèle est actuellement en préversion publique.
Vous pouvez également ajuster un modèle précédemment ajusté, formaté comme base-model.ft-{jobid}.
Consultez la page modèles pour vérifier quelles régions prennent actuellement en charge le réglage précis.
Passez en revue le flux de travail pour le portail Azure AI Foundry
Prenez un moment pour passer en revue le flux de travail de réglage précis pour l’utilisation du portail Azure AI Foundry :
- Préparer vos données d’apprentissage et de validation.
- Utiliser l’Assistant Créer un modèle personnalisé dans le portail Azure AI Foundry pour entraîner votre modèle personnalisé.
- Vérifier l’état de votre modèle personnalisé et ajusté.
- Déployer votre modèle personnalisé pour une utilisation.
- Utiliser votre modèle personnalisé.
- Éventuellement, analyser les performances et l’ajustement de votre modèle personnalisé.
Préparer vos données d’entraînement et de validation
Vos données d’apprentissage et vos jeux de données de validation se composent d’exemples d’entrée et de sortie de la façon dont vous souhaitez que le modèle fonctionne.
Différents types de modèles nécessitent un format différent de données d’entraînement.
Les données d’entraînement et de validation que vous utilisez doivent être mises en forme en tant que document JSON Lines (JSONL). Pour gpt-35-turbo (toutes les versions), gpt-4, gpt-4o et gpt-4o-mini, le jeu de données d’ajustement doit être mis en forme au format conversationnel utilisé par l’API Chat completions (Saisies semi-automatiques de conversation).
Si vous souhaitez obtenir la procédure pas à pas permettant d’ajuster un modèle gpt-4o-mini (2024-07-18), veuillez vous référer au didacticiel sur le réglage précis avec Azure OpenAI.
Exemple de format de fichier
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
Format de fichier de conversation multitour Azure OpenAI
Plusieurs tours d’une invite dans une seule ligne de votre fichier de formation jsonl sont également pris en charge. Pour ignorer le fine-tuning sur des messages d’assistant spécifiques, ajoutez la paire clé/valeur facultative weight. Actuellement, weight peut être défini sur 0 ou 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Saisies semi-automatiques de conversation avec vision
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Outre le format JSONL, les fichiers de données d’apprentissage et de validation doivent être encodés en UTF-8 et inclure une marque d’ordre d’octet (BOM). La taille du fichier doit être inférieure à 512 Mo.
Créer vos jeux de données d’apprentissage et de validation
Plus vous avez d’exemples de formation, mieux c’est. Les travaux d’ajustement ne seront pas effectués sans au moins 10 exemples d’apprentissage, mais un si petit nombre ne suffit pas pour influencer de façon notable les réponses du modèle. Il est recommandé de fournir des centaines, voire des milliers d’exemples d’apprentissage pour obtenir de bons résultats.
En général, le doublement de la taille du jeu de données peut entraîner une augmentation linéaire de la qualité du modèle. Mais gardez à l’esprit que les exemples de faible qualité peuvent avoir un impact négatif sur les performances. Si vous entraînez le modèle sur une grande quantité de données internes, sans élaguer au préalable l’ensemble de données pour ne conserver que les exemples de la plus haute qualité, vous risquez d’obtenir un modèle dont les performances sont bien inférieures à celles attendues.
Utiliser l’assistant Créer un modèle personnalisé
Le portail Azure AI Foundry fournit l'Assistant Créer un modèle personnalisé . Vous pouvez donc créer et entraîner de manière interactive un modèle affiné pour votre ressource Azure.
Ouvrez le portail Azure AI Foundry à https://oai.azure.com/ et connectez-vous avec les informations d’identification qui ont accès à votre ressource Azure OpenAI. Pendant le flux de travail de connexion, sélectionnez le répertoire approprié, l’abonnement Azure et la ressource Azure OpenAI.
Dans le portail Azure AI Foundry, accédez au volet Outils > Réglage précis, puis sélectionnez Réglage précis du modèle.


L’assistant Créer un modèle personnalisé s’ouvre.
Sélectionnez le modèle de base
La première étape de la création d’un modèle personnalisé consiste à choisir un modèle de base. Le volet Modèle de base vous permet de choisir un modèle de base à utiliser pour votre modèle personnalisé. Votre choix influence les performances et le coût de votre modèle.
Sélectionnez un modèle de base dans la liste déroulante Type de modèle de base, puis Suivant pour continuer.
Vous pouvez créer un modèle personnalisé à partir de l’un des modèles de base disponibles suivants :
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)Vous pouvez également ajuster un modèle précédemment ajusté, formaté comme base-model.ft-{jobid}.

Pour plus d’informations sur les modèles de base qui peuvent être affinés, consultez la section Modèles.
Choisir vos données d’entraînement
L’étape suivante consiste à choisir les données d’entraînement préparées existantes ou à charger de nouvelles données d’entraînement préparées à utiliser lors de la personnalisation de votre modèle. Le volet Données d’apprentissage affiche les jeux de données existants précédemment chargés et fournit également des options permettant de charger de nouvelles données d’apprentissage.

Si vos données d’apprentissage sont déjà chargées sur le service, sélectionnez Fichiers à partir d’une connexion Azure OpenAI.
- Sélectionnez le fichier dans la liste déroulante affichée.
Pour charger de nouvelles données d’apprentissage, utilisez l’une des options suivantes :
Sélectionnez Fichier local pour charger des données d’apprentissage à partir d’un fichier local.
Sélectionnez Blob Azure ou autres emplacements web partagés pour importer des données d’apprentissage à partir du Blob Azure ou d’un autre emplacement web partagé.
Pour des fichiers de données volumineux, nous vous recommandons d’importer à partir d’un magasin Blob Azure. Les fichiers volumineux peuvent devenir instables lors du chargement via des formulaires multipart, car les requêtes sont atomiques et ne peuvent pas être retentées ou reprises. Pour plus d’informations sur le stockage Blob Azure, consultez Qu’est-ce qu’un stockage Blob Azure ?
Remarque
Les fichiers de données d’apprentissage doivent être formatés en fichiers JSONL, encodés en UTF-8 avec une marque d’ordre d’octet (BOM). La taille du fichier doit être inférieure à 512 Mo.
Charger des données d’apprentissage à partir d’un fichier local
Vous pouvez charger un nouveau jeu de données d’entraînement sur le service à partir d’un fichier local à l’aide de l’une des méthodes suivantes :
Faites glisser et déposez le fichier dans la zone cliente du volet Données d’apprentissage, puis sélectionnez Charger le fichier.
Sélectionnez Rechercher un fichier dans la zone cliente du volet Données d’entraînement, choisissez le fichier à charger dans la boîte de dialogue Ouvrir, puis sélectionnez Charger le fichier.
Après avoir sélectionné et chargé le jeu de données d’apprentissage, sélectionnez Suivant pour continuer.

Importer des données d’apprentissage à partir d’un magasin Blob Azure
Vous pouvez importer un jeu de données d’apprentissage à partir d’un Blob Azure ou d’un autre emplacement web partagé en fournissant le nom et l’emplacement du fichier.
Entrez le nom de fichier du fichier.
Dans l’emplacement du fichier, indiquez l’URL du Blob Azure, la signature d’accès partagé (SAP) du Stockage Azure ou un autre lien vers un emplacement web partagé accessible.
Sélectionnez Importer pour importer le jeu de données d’apprentissage dans le service.
Après avoir sélectionné et chargé le jeu de données d’apprentissage, sélectionnez Suivant pour continuer.

Choisir vos données de validation
L’étape suivante fournit des options pour configurer le modèle afin d’utiliser des données de validation dans le processus d’apprentissage. Si vous ne souhaitez pas utiliser de données de validation, vous pouvez choisir Suivant pour continuer vers les options avancées du modèle. Sinon, si vous avez un jeu de données de validation, vous pouvez choisir les données de validation préparées existantes ou charger de nouvelles données de validation préparées à utiliser lors de la personnalisation de votre modèle.
Le volet Données de validation affiche les jeux de données d’apprentissage et de validation existants précédemment chargés et fournit des options vous permettant de charger de nouvelles données de validation.

Si vos données de validation sont déjà chargées dans le service, sélectionnez Choisir un jeu de données.
- Sélectionnez le fichier dans la liste affichée dans le volet Données de validation.
Pour charger de nouvelles données de validation, utilisez l’une des options suivantes :
Sélectionnez Fichier local pour charger des données de validation à partir d’un fichier local.
Sélectionnez Blob Azure ou autres emplacements web partagés pour importer des données de validation à partir du Blob Azure ou d’un autre emplacement web partagé.
Pour des fichiers de données volumineux, nous vous recommandons d’importer à partir d’un magasin Blob Azure. Les fichiers volumineux peuvent devenir instables lors du chargement via des formulaires multipart, car les requêtes sont atomiques et ne peuvent pas être retentées ou reprises.
Remarque
Comme les fichiers de données d’apprentissage, les fichiers de données de validation doivent être formatés en fichiers JSONL, encodés en UTF-8 avec une marque d’ordre d’octet (BOM). La taille du fichier doit être inférieure à 512 Mo.
Charger des données de validation à partir d’un fichier local
Vous pouvez charger un nouveau jeu de données de validation sur le service à partir d’un fichier local à l’aide de l’une des méthodes suivantes :
Faites glisser et déposez le fichier dans la zone cliente du volet Données de validation, puis sélectionnez Charger le fichier.
Sélectionnez Rechercher un fichier dans la zone cliente du volet Données de validation, choisissez le fichier à charger dans la boîte de dialogue Ouvrir, puis sélectionnez Charger le fichier.
Après avoir sélectionné et chargé le jeu de données de validation, sélectionnez Suivant pour continuer.

Importer des données de validation à partir d’un magasin Blob Azure
Vous pouvez importer un jeu de données de validation à partir d’un Blob Azure ou d’un autre emplacement web partagé en fournissant le nom et l’emplacement du fichier.
Entrez le nom de fichier du fichier.
Dans l’emplacement du fichier, indiquez l’URL du Blob Azure, la signature d’accès partagé (SAP) du Stockage Azure ou un autre lien vers un emplacement web partagé accessible.
Sélectionnez Importer pour importer le jeu de données d’apprentissage dans le service.
Après avoir sélectionné et chargé le jeu de données de validation, sélectionnez Suivant pour continuer.

Configurer les paramètres de tâche
L’Assistant Créer un modèle personnalisé présente les paramètres pour l’apprentissage de votre modèle ajusté dans le volet Paramètres de tâche. Les paramètres disponibles sont les suivants :
| Nom | Type | Description |
|---|---|---|
batch_size |
entier | Taille de lot à utiliser pour la formation. La taille du lot est le nombre d’exemples de la formation utilisés pour entraîner un seul passage avant et arrière. En général, nous avons constaté que les tailles de lot plus grandes ont tendance à fonctionner mieux pour les jeux de données plus volumineux. La valeur par défaut et la valeur maximale de cette propriété sont propres à un modèle de base. Une taille de lot plus grande signifie que les paramètres de modèle sont mis à jour moins souvent, mais avec une variance plus faible. |
learning_rate_multiplier |
number | Multiplicateur de taux de formation à utiliser pour la formation. Le taux d’apprentissage de réglage est le taux d’apprentissage d’origine utilisé pour le pré-entraînement multiplié par cette valeur. Les taux d’apprentissage plus importants ont tendance à mieux fonctionner que les tailles de lot plus grandes. Nous vous recommandons d’expérimenter des valeurs comprises entre 0,02 et 0,2 pour voir ce qui produit les meilleurs résultats. Un taux d’apprentissage plus faible peut être utile pour éviter un surajustement. |
n_epochs |
entier | Nombre d’époques pour lequel effectuer la formation du modèle. Une époque fait référence à un cycle complet dans le jeu de données de formation. |
seed |
entier | La graine contrôle la reproductibilité du travail. La transmission de la même graine et des mêmes paramètres de travail doit produire les mêmes résultats, mais peut différer dans de rares cas. Si aucune graine n’est spécifiée, une graine sera générée pour vous |
Beta |
entier | Paramètre de température pour la perte de dpo, généralement comprise entre 0,1 et 0,5. Cela contrôle la quantité d’attention que nous accordons au modèle de référence. Plus la version bêta est petite, plus nous permettons au modèle de dériver du modèle de référence. Comme la version bêta est plus petite, nous ignorons le modèle de référence. |

Sélectionnez Par défaut pour utiliser les valeurs par défaut du travail d’ajustement, ou sélectionnez Personnalisé pour afficher et modifier les valeurs des hyperparamètres. Lorsque les valeurs par défaut sont sélectionnées, nous déterminons la valeur correcte par algorithme en fonction de vos données de formation.
Après avoir configuré les options avancées, sélectionnez Suivant pour passer en revue vos choix et effectuer l’apprentissage de votre modèle ajusté.
Passez en revue vos choix et entraîner votre modèle
Le volet Révision de l’assistant affiche des informations sur vos choix de configuration.

Si vous êtes prêt à effectuer l’apprentissage de votre modèle, sélectionnez Commencer la tâche d’entraînement pour démarrer le travail d’ajustement et revenir au volet Modèles.
Vérifier l’état de votre modèle personnalisé
Le volet Modèles affiche des informations sur votre modèle personnalisé sous l’onglet Modèles personnalisés. L’onglet inclut des informations sur l’état et l’ID de la tâche d’ajustement de votre modèle personnalisé. Une fois la tâche terminée, l’onglet affiche l’ID de fichier du fichier de résultat. Vous devrez peut-être sélectionner Actualiser pour afficher un état mis à jour pour le travail d’entraînement du modèle.

Après avoir démarré une tâche de réglage précis, un certain temps peut être nécessaire pour qu’elle s’achève. Votre tâche peut être mise en file d’attente derrière d’autres tâches sur le système. L’apprentissage de votre modèle peut prendre quelques minutes ou quelques heures selon le modèle et la taille du jeu de données.
Voici quelques-unes des tâches que vous pouvez effectuer dans le volet Modèles :
Vérifiez l’état de la tâche de réglage précis de votre modèle personnalisé dans la colonne État de l’onglet Modèles personnalisés.
Dans la colonne Nom du modèle, sélectionner le nom du modèle pour afficher plus d’informations sur le modèle personnalisé. Vous pouvez voir l’état de la tâche de réglage précis, les résultats de la formation, les événements liés à l’entraînement et les hyperparamètres utilisés dans la tâche.
Sélectionner Télécharger le fichier d’apprentissage pour télécharger les données d’apprentissage que vous avez utilisées pour le modèle.
Sélectionnez Télécharger les résultats pour télécharger le fichier des résultats joint à la tâche d’ajustement de votre modèle et analyser votre modèle personnalisé pour obtenir ses performances d’apprentissage et de validation.
Sélectionnez Actualiser pour mettre à jour les informations sur la page.
Points de contrôle
Lorsque chaque époque de formation termine un point de contrôle est généré. Un point de contrôle est une version entièrement fonctionnelle d’un modèle qui peut être déployé et utilisé comme modèle cible pour les travaux d’ajustement suivants. Les points de contrôle peuvent être particulièrement utiles, car ils peuvent fournir un instantané de votre modèle avant le surajustement. Lorsqu’un travail d’ajustement se termine, vous disposez des trois versions les plus récentes du modèle disponibles pour le déploiement.
Évaluation de la sécurité pour l’ajustement de GPT-4, GPT-4o, et GPT-4o-mini – Préversion publique
GPT-4o, GPT-4o-mini et GPT-4 sont nos modèles les plus avancés qui peuvent être ajustés à vos besoins. Comme pour les modèles Azure OpenAI de façon générale, les capacités avancées des modèles ajustés s’accompagnent d’enjeux plus importants en matière d’IA responsable eu égard au contenu nuisible, à la manipulation, au comportement pseudo-humain, aux problèmes de confidentialité, etc. Pour en savoir plus sur les risques, les capacités et les limites, consultez Vue d’ensemble des pratiques de l’IA responsable et Note de transparence. Pour aider à atténuer les risques associés aux modèles ajustés avancés, nous avons mis en place des étapes d’évaluation supplémentaires pour contribuer à la détection et à la prévention des contenus nuisibles dans l’entraînement et les sorties des modèles ajustés. Ces étapes reposent sur le standard Microsoft en matière d’IA responsable et le filtrage de contenu Azure OpenAI Service.
- Les évaluations sont réalisées dans des espaces de travail privés dédiés, spécifiques au client ;
- Les points de terminaison d’évaluation se trouvent dans la même zone géographique que la ressource Azure OpenAI ;
- Les données d’entraînement ne sont pas stockées au cours des évaluations ; seule l’évaluation du modèle final (déployable ou non déployable) est conservée ; et
Les filtres d’évaluation de modèles affinés GPT-4o, GPT-4o-mini et GPT-4 sont définis sur des seuils prédéfinis et ne peuvent pas être modifiés par les clients ; elles ne sont liées à aucune configuration de filtrage de contenu personnalisée que vous avez peut-être créée.
Évaluation des données
Avant le commencement de l’entraînement, vos données sont évaluées par rapport à la présence de contenu potentiellement nuisible (violence, contenu sexuel, haine et impartialité, automutilation – voir la définition des différentes catégories ici). Si du contenu nuisible est détecté et qu’il dépasse le niveau de gravité spécifié, votre tâche d’entraînement échoue et vous obtenez un message vous indiquant la raison (catégorie) de l’échec.
Exemple de message :
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
Vos données d’entraînement sont évaluées automatiquement lors de votre tâche d’importation de données dans le cadre de la capacité de fine-tuning.
Si la tâche de fine-tuning échoue suite à la détection de contenu nuisible dans les données d’entraînement, vous n’êtes pas facturé.
Évaluation du modèle
Une fois l’entraînement terminé, mais avant que le modèle ajusté soit en mesure d’être déployé, le modèle résultant est évalué par rapport à la présence de réponses potentiellement nuisibles à l’aide des métriques de risque et de sécurité intégrées d’Azure. En suivant la même approche de test que celle que nous appliquons aux grands modèles de langage de base, notre fonctionnalité d’évaluation simule une conversation avec votre modèle ajusté pour évaluer le potentiel de génération de contenu nuisible, encore une fois en utilisant les catégories de contenu nuisible spécifiées (violence, contenu sexuel, haine et impartialité, automutilation).
S’il s’avère qu’un modèle génère une sortie dont le contenu est détecté comme présentant un caractère nuisible au-delà d’un niveau acceptable, vous êtes informé que votre modèle ne peut pas être déployé, et vous obtenez des indications sur les catégories spécifiques de nuisances détectées :
Exemple de message :
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.

Comme pour l’évaluation de données, le modèle est évalué automatiquement lors de votre tâche de fine-tuning dans le cadre de la capacité de fine-tuning. Seule l’évaluation résultante (déployable ou non déployable) est journalisée par le service. Si le déploiement du modèle affiné échoue en raison de la détection de contenu nuisible dans les sorties générées par le modèle, l’entraînement exécuté ne vous est pas facturé.
Déployer un modèle ajusté
Lorsque la tâche de réglage précis réussit, vous pouvez déployer le modèle personnalisé à partir du volet Modèles. Vous devez déployer votre modèle personnalisé pour le rendre disponible pour une utilisation avec des appels d’achèvement.
Important
Après le déploiement d’un modèle personnalisé, si le déploiement reste inactif pendant plus de quinze (15) jours consécutifs, le déploiement est supprimé. Le déploiement d’un modèle personnalisé est inactif si le déploiement du modèle a été effectué plus de quinze (15) jours auparavant et qu’aucun appel de complétion ou d’achèvement de conversation n’a été effectué pendant une période continue de 15 jours.
La suppression d’un déploiement inactif ne supprime ou n’affecte pas le modèle personnalisé sous-jacent. Ainsi, le modèle personnalisé peut être redéployé à tout moment. Comme décrit dans la tarification d’Azure OpenAI Service, chaque modèle personnalisé (ajusté) déployé entraîne un coût horaire d’hébergement, indépendamment des appels d’achèvement ou d’achèvements de conversations instantanées effectués vers le modèle. Pour en savoir plus sur la planification et la gestion des coûts avec Azure OpenAI, reportez-vous à l’aide fournie dans Planifier la gestion des coûts pour Azure OpenAI Service.
Remarque
Un seul déploiement est autorisé par modèle personnalisé. Un message d’erreur s’affiche si vous sélectionnez un modèle personnalisé déjà déployé.
Pour déployer votre modèle personnalisé, sélectionnez le modèle personnalisé à déployer, puis sélectionnez Déployer le modèle.

La boîte de dialogue Déployer un modèle s’ouvre. Dans la boîte de dialogue, entrez votre Nom de déploiement, puis sélectionnez Créer pour démarrer le déploiement de votre modèle personnalisé.

Vous pouvez surveiller la progression de votre déploiement dans le volet Déploiements du portail Azure AI Foundry.
Déploiement inter-région
L’ajustement prend en charge le déploiement d’un modèle ajusté vers une autre région que celle où il a été ajusté à l’origine. Vous pouvez également déployer vers une autre région/un autre abonnement.
Les seules limitations sont que la nouvelle région doit également prendre en charge l’ajustement et que, lors du déploiement sur plusieurs abonnements, le compte générant le jeton d’autorisation pour le déploiement doit avoir accès aux abonnements source et destination.
Vous pouvez effectuer un déploiement sur plusieurs abonnements/régions via Python ou REST.
Utiliser un modèle personnalisé déployé
Après le déploiement de votre modèle personnalisé, vous pouvez l’utiliser comme n’importe quel autre modèle déployé. Vous pouvez utiliser les terrains de jeu dans portail Azure AI Foundry pour expérimenter votre nouveau déploiement. Vous pouvez continuer à utiliser les mêmes paramètres avec votre modèle personnalisé, comme temperature et max_tokens, que vous pouvez utiliser avec d’autres modèles déployés. Pour les modèles babbage-002 et davinci-002 ajustés, vous utiliserez le terrain de jeu d’achèvements et l’API d’achèvements. Pour les modèles gpt-35-turbo-0613 ajustés, vous utiliserez le terrain de jeu de conversation et l’API d’achèvements de conversation.

Analyser votre modèle personnalisé
Azure OpenAI joint un fichier de résultats nommé results.csv à chaque tâche de réglage précis après son achèvement. Vous pouvez utiliser le fichier de résultats pour analyser les performances d’apprentissage et de validation de votre modèle personnalisé. L’ID de fichier du fichier de résultats est répertorié pour chaque modèle personnalisé dans la colonne ID de fichier de résultat dans le volet Modèles pour le portail Azure AI Foundry. Vous pouvez utiliser l’ID de fichier pour identifier et télécharger le fichier de résultat à partir du volet fichiers de données du portail Azure AI Foundry.
Le fichier de résultats est un fichier CSV contenant une ligne d’en-tête et une ligne pour chaque étape d’entraînement effectuée par la tâche de réglage précis. Le fichier de résultats contient les colonnes suivantes :
| Nom de la colonne | Description |
|---|---|
step |
Nombre de l’étape d’entraînement. Une étape d’entraînement représente une seule passe, avant et arrière, sur un lot de données d’entraînement. |
train_loss |
Perte du lot d’entraînement. |
train_mean_token_accuracy |
Pourcentage de jetons dans le lot d’apprentissage correctement prédits par le modèle. Par exemple, si la taille du lot est définie sur 3 et que vos données contiennent des achèvements [[1, 2], [0, 5], [4, 2]], cette valeur est définie sur 0,83 (5 sur 6) si le modèle prédit [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
Perte du lot de validation. |
validation_mean_token_accuracy |
Pourcentage de jetons dans le lot de validation correctement prédits par le modèle. Par exemple, si la taille du lot est définie sur 3 et que vos données contiennent des achèvements [[1, 2], [0, 5], [4, 2]], cette valeur est définie sur 0,83 (5 sur 6) si le modèle prédit [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
La perte de validation calculée à la fin de chaque époque. Lorsque la formation va bien, la perte doit diminuer. |
full_valid_mean_token_accuracy |
La précision moyenne valide des jetons calculée à la fin de chaque époque. Lorsque la formation va bien, la précision des jetons doit augmenter. |
Vous pouvez également afficher les données de votre fichier results.csv sous forme de tracés dans le portail Azure AI Foundry. Sélectionnez le lien pour votre modèle entraîné, et vous verrez trois graphiques : perte, précision moyenne du jeton et précision du jeton. Si vous avez fourni des données de validation, les deux jeux de données apparaissent sur le même tracé.
Les pertes devraient diminuer avec le temps et la précision augmenter. Si vous voyez une divergence entre vos données d’apprentissage et de validation, cela peut indiquer que vous êtes en surajustement. Essayez d’effectuer l’apprentissage avec moins d’époques, ou un multiplicateur de taux d’apprentissage plus petit.
Nettoyer vos déploiements, modèles personnalisés et fichiers d’apprentissage
Lorsque vous en avez terminé avec votre modèle personnalisé, vous pouvez supprimer le déploiement et le modèle. Vous pouvez également supprimer les fichiers d’entraînement et de validation que vous avez chargés sur le service, si nécessaire.
Supprimer votre modèle de déploiement
Important
Après le déploiement d’un modèle personnalisé, si le déploiement reste inactif pendant plus de quinze (15) jours consécutifs, le déploiement est supprimé. Le déploiement d’un modèle personnalisé est inactif si le déploiement du modèle a été effectué plus de quinze (15) jours auparavant et qu’aucun appel de complétion ou d’achèvement de conversation n’a été effectué pendant une période continue de 15 jours.
La suppression d’un déploiement inactif ne supprime ou n’affecte pas le modèle personnalisé sous-jacent. Ainsi, le modèle personnalisé peut être redéployé à tout moment. Comme décrit dans la tarification d’Azure OpenAI Service, chaque modèle personnalisé (ajusté) déployé entraîne un coût horaire d’hébergement, indépendamment des appels d’achèvement ou d’achèvements de conversations instantanées effectués vers le modèle. Pour en savoir plus sur la planification et la gestion des coûts avec Azure OpenAI, reportez-vous à l’aide fournie dans Planifier la gestion des coûts pour Azure OpenAI Service.
Vous pouvez supprimer le déploiement de votre modèle personnalisé dans le volet Déploiements du portail Azure AI Foundry. Sélectionnez le déploiement à supprimer, puis sélectionnez Supprimer pour supprimer le déploiement.
Supprimer votre modèle personnalisé
Vous pouvez supprimer un modèle personnalisé dans le volet Modèles du portail Azure AI Foundry. Sélectionnez le modèle personnalisé à supprimer dans l’onglet Modèles personnalisés, puis sélectionnez Supprimer pour supprimer le modèle personnalisé.
Remarque
Vous ne pouvez pas supprimer un modèle personnalisé si un déploiement de ce modèle existe. Vous devez d’abord supprimer le déploiement de votre modèle avant de pouvoir supprimer votre modèle personnalisé.
Supprimer vos fichiers de formation
Vous pouvez éventuellement supprimer les fichiers de formation et de validation que vous avez chargés pour la formation, ainsi que les fichiers de résultats générés pendant la formation, dans le volet Gestion>Données + indexes du portail Azure AI Foundry. Sélectionnez le fichier à supprimer, puis sélectionnez Supprimer pour supprimer le fichier.
Ajustement continu
Une fois que vous avez créé un modèle ajusté, vous pouvez continuer à affiner le modèle au fil du temps via un ajustement plus précis. L’ajustement continu correspond au processus itératif de sélection d’un modèle déjà affiné comme modèle de base et à l’ajuster davantage sur de nouveaux ensembles d’exemples d’apprentissage.
Si vous souhaitez effectuer l’ajustement d’un modèle précédemment ajusté, vous utiliserez le même processus décrit dans créer un modèle personnalisé mais, au lieu de spécifier le nom d’un modèle de base générique, vous spécifierez votre modèle déjà ajusté. Un modèle ajusté personnalisé ressemblera à gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7

Nous vous conseillons également d’inclure le paramètre suffix pour faciliter la distinction entre les différentes itérations de votre modèle ajusté. suffix prend une chaîne et est défini pour identifier le modèle ajusté. Avec l’API Python OpenAI, une chaîne 18 caractères au maximum est prise en charge et est ajoutée au nom de votre modèle ajusté.







Prérequis
- Lisez le guide expliquant quand utiliser l’ajustement Azure OpenAI.
- Un abonnement Azure. Créez-en un gratuitement.
- Ressource Azure OpenAI. Pour plus d’informations, consultez l’article Créer une ressource et déployer un modèle à l’aide d’Azure OpenAI.
- Bibliothèques Python suivantes :
os,json,requests,openai. - La bibliothèque Python OpenAI doit être au moins la version 0.28.1.
- L’accès au réglage précis nécessite un contributeur OpenAI de Cognitive Services.
- Si vous n’avez pas encore accès au quota d’affichage et que vous déployez des modèles dans le portail Azure AI Foundry, vous aurez besoin d’autorisations supplémentaires.
Modèles
Les modèles suivants prennent en charge le réglage précis :
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)*gpt-4o(2024-08-06)gpt-4o-mini(18-07-2024)
* L’optimisation de ce modèle est actuellement en préversion publique.
Vous pouvez également ajuster un modèle précédemment ajusté, mis en forme comme base-model.ft-{jobid}.
Consultez la page modèles pour vérifier quelles régions prennent actuellement en charge le réglage précis.
Passez en revue le flux de travail du kit de développement logiciel (SDK) Python
Prenez un moment pour passer en revue le flux de travail d’ajustement pour une utilisation du kit de développement logiciel (SDK) Python avec Azure OpenAI :
- Préparer vos données d’apprentissage et de validation.
- Sélectionner un modèle de base.
- Charger vos données d’apprentissage.
- Effectuer l’apprentissage de votre nouveau modèle personnalisé.
- Vérifier l’état de votre modèle personnalisé.
- Déployer votre modèle personnalisé pour une utilisation.
- Utiliser votre modèle personnalisé.
- Éventuellement, analyser les performances et l’ajustement de votre modèle personnalisé.
Préparer vos données d’entraînement et de validation
Vos données d’apprentissage et vos jeux de données de validation se composent d’exemples d’entrée et de sortie de la façon dont vous souhaitez que le modèle fonctionne.
Différents types de modèles nécessitent un format différent de données d’entraînement.
Les données d’entraînement et de validation que vous utilisez doivent être mises en forme en tant que document JSON Lines (JSONL). Pour gpt-35-turbo-0613 le jeu de données de réglage précis doit être mis en forme dans le format conversationnel utilisé par l’API des achèvements de conversation.
Si vous souhaitez une procédure pas à pas de réglage précis d’un gpt-35-turbo-0613, reportez-vous au didacticiel de réglage détaillé d’Azure OpenAI
Exemple de format de fichier
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
Format de fichier d’invite multitour
Plusieurs tours d’une invite dans une seule ligne de votre fichier de formation jsonl sont également pris en charge. Pour ignorer le fine-tuning sur des messages d’assistant spécifiques, ajoutez la paire clé/valeur facultative weight. Actuellement, weight peut être défini sur 0 ou 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Saisies semi-automatiques de conversation avec vision
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Outre le format JSONL, les fichiers de données d’apprentissage et de validation doivent être encodés en UTF-8 et inclure une marque d’ordre d’octet (BOM). La taille du fichier doit être inférieure à 512 Mo.
Créer vos jeux de données d’apprentissage et de validation
Plus vous avez d’exemples de formation, mieux c’est. Les travaux de fine-tuning ne seront pas effectués sans au moins 10 exemples d’apprentissage, mais un si petit nombre ne suffit pas pour influencer de façon notable les réponses du modèle. Il est recommandé de fournir des centaines, voire des milliers d’exemples d’apprentissage pour obtenir de bons résultats.
En général, le doublement de la taille du jeu de données peut entraîner une augmentation linéaire de la qualité du modèle. Mais gardez à l’esprit que les exemples de faible qualité peuvent avoir un impact négatif sur les performances. Si vous entraînez le modèle sur une grande quantité de données internes, sans élaguer au préalable l’ensemble de données pour ne conserver que les exemples de la plus haute qualité, vous risquez d’obtenir un modèle dont les performances sont bien inférieures à celles attendues.
Charger vos données d’entraînement
L’étape suivante consiste à choisir les données d’entraînement préparées existantes ou à charger de nouvelles données d’entraînement préparées à utiliser lors de la personnalisation de votre modèle. Après avoir préparé vos données d’apprentissage, vous pouvez charger vos fichiers dans le service. Il existe deux façons de charger des données d’apprentissage :
- À partir d’un fichier local
- Importer à partir d’un magasin d’objets blob Azure ou d’un autre emplacement web
Pour des fichiers de données volumineux, nous vous recommandons d’importer à partir d’un magasin Blob Azure. Les fichiers volumineux peuvent devenir instables lors du chargement via des formulaires multipart, car les requêtes sont atomiques et ne peuvent pas être retentées ou reprises. Pour plus d’informations sur le stockage Blob Azure, consultez Qu’est-ce que le stockage d’objets blob Azure ?
Remarque
Les fichiers de données d’apprentissage doivent être formatés en fichiers JSONL, encodés en UTF-8 avec une marque d’ordre d’octet (BOM). La taille du fichier doit être inférieure à 512 Mo.
L’exemple Python suivant télécharge les fichiers locaux d’entraînement et de validation en utilisant le SDK Python, et récupère les identifiants des fichiers renvoyés.
# Upload fine-tuning files
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-05-01-preview" # This API version or later is required to access seed/events/checkpoint capabilities
)
training_file_name = 'training_set.jsonl'
validation_file_name = 'validation_set.jsonl'
# Upload the training and validation dataset files to Azure OpenAI with the SDK.
training_response = client.files.create(
file=open(training_file_name, "rb"), purpose="fine-tune"
)
training_file_id = training_response.id
validation_response = client.files.create(
file=open(validation_file_name, "rb"), purpose="fine-tune"
)
validation_file_id = validation_response.id
print("Training file ID:", training_file_id)
print("Validation file ID:", validation_file_id)
Créer un modèle personnalisé
Après avoir chargé vos fichiers d’entraînement et de validation, vous êtes prêt à démarrer la tâche de réglage précis.
Le code Python suivant montre un exemple de création d’un travail d’ajustement avec le Kit de développement logiciel (SDK) Python :
Dans cet exemple, nous transmettons également le paramètre de graine. La graine contrôle la reproductibilité du travail. La transmission de la même graine et des mêmes paramètres de travail doit produire les mêmes résultats, mais peut différer dans de rares cas. Si aucune graine n’est spécifiée, une graine sera générée pour vous.
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-35-turbo-0613", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
seed = 105 # seed parameter controls reproducibility of the fine-tuning job. If no seed is specified one will be generated automatically.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
Vous pouvez également passer d’autres paramètres facultatifs tels que des hyperparamètres pour mieux contrôler le processus d’ajustement. Pour l’apprentissage initial, nous vous conseillons d’utiliser les valeurs par défaut automatiques qui sont présentes sans spécifier ces paramètres.
Les hyperparamètres actuels pris en charge pour l’ajustement sont les suivants :
| Nom | Type | Description |
|---|---|---|
batch_size |
entier | Taille de lot à utiliser pour la formation. La taille du lot est le nombre d’exemples de la formation utilisés pour entraîner un seul passage avant et arrière. En général, nous avons constaté que les tailles de lot plus grandes ont tendance à fonctionner mieux pour les jeux de données plus volumineux. La valeur par défaut et la valeur maximale de cette propriété sont propres à un modèle de base. Une taille de lot plus grande signifie que les paramètres de modèle sont mis à jour moins souvent, mais avec une variance plus faible. |
learning_rate_multiplier |
number | Multiplicateur de taux de formation à utiliser pour la formation. Le taux d’apprentissage de réglage est le taux d’apprentissage d’origine utilisé pour le pré-entraînement multiplié par cette valeur. Les taux d’apprentissage plus importants ont tendance à mieux fonctionner que les tailles de lot plus grandes. Nous vous recommandons d’expérimenter des valeurs comprises entre 0,02 et 0,2 pour voir ce qui produit les meilleurs résultats. Un taux d’apprentissage plus faible peut être utile pour éviter un surajustement. |
n_epochs |
entier | Nombre d’époques pour lequel effectuer la formation du modèle. Une époque fait référence à un cycle complet dans le jeu de données de formation. |
seed |
entier | La graine contrôle la reproductibilité du travail. La transmission de la même graine et des mêmes paramètres de travail doit produire les mêmes résultats, mais peut différer dans de rares cas. Si aucune graine n’est spécifiée, une graine sera générée pour vous. |
Si vous souhaitez définir des hyperparamètres personnalisés avec la version 1.x de l’API Python OpenAI :
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01" # This API version or later is required to access fine-tuning for turbo/babbage-002/davinci-002
)
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-35-turbo-0613", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
hyperparameters={
"n_epochs":2
}
)
Vérifier l’état du travail de réglage précis
response = client.fine_tuning.jobs.retrieve(job_id)
print("Job ID:", response.id)
print("Status:", response.status)
print(response.model_dump_json(indent=2))
Répertorier les événements ajustés
Pour examiner les événements ajustés individuels générés lors de la formation :
Vous devrez peut-être mettre à niveau votre bibliothèque de client OpenAI vers la dernière version avec pip install openai --upgrade pour exécuter cette commande.
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Points de contrôle
Lorsque chaque époque de formation termine un point de contrôle est généré. Un point de contrôle est une version entièrement fonctionnelle d’un modèle qui peut être déployé et utilisé comme modèle cible pour les travaux d’ajustement suivants. Les points de contrôle peuvent être particulièrement utiles, car ils peuvent fournir un instantané de votre modèle avant le surajustement. Lorsqu’un travail d’ajustement se termine, vous disposez des trois versions les plus récentes du modèle disponibles pour le déploiement. L’époque finale sera représentée par votre modèle ajusté, les deux époques précédentes seront disponibles en tant que points de contrôle.
Vous pouvez exécuter la commande list checkpoints pour récupérer la liste des points de contrôle associés à un travail d’ajustement individuel :
Vous devrez peut-être mettre à niveau votre bibliothèque de client OpenAI vers la dernière version avec pip install openai --upgrade pour exécuter cette commande.
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Évaluation de la sécurité pour l’ajustement de GPT-4, GPT-4o, et GPT-4o-mini – Préversion publique
GPT-4o, GPT-4o-mini et GPT-4 sont nos modèles les plus avancés qui peuvent être ajustés à vos besoins. Comme pour les modèles Azure OpenAI de façon générale, les capacités avancées des modèles ajustés s’accompagnent d’enjeux plus importants en matière d’IA responsable eu égard au contenu nuisible, à la manipulation, au comportement pseudo-humain, aux problèmes de confidentialité, etc. Pour en savoir plus sur les risques, les capacités et les limites, consultez Vue d’ensemble des pratiques de l’IA responsable et Note de transparence. Pour aider à atténuer les risques associés aux modèles ajustés avancés, nous avons mis en place des étapes d’évaluation supplémentaires pour contribuer à la détection et à la prévention des contenus nuisibles dans l’entraînement et les sorties des modèles ajustés. Ces étapes reposent sur le standard Microsoft en matière d’IA responsable et le filtrage de contenu Azure OpenAI Service.
- Les évaluations sont réalisées dans des espaces de travail privés dédiés, spécifiques au client ;
- Les points de terminaison d’évaluation se trouvent dans la même zone géographique que la ressource Azure OpenAI ;
- Les données d’entraînement ne sont pas stockées au cours des évaluations ; seule l’évaluation du modèle final (déployable ou non déployable) est conservée ; et
Les filtres d’évaluation de modèles affinés GPT-4o, GPT-4o-mini et GPT-4 sont définis sur des seuils prédéfinis et ne peuvent pas être modifiés par les clients ; elles ne sont liées à aucune configuration de filtrage de contenu personnalisée que vous avez peut-être créée.
Évaluation des données
Avant le commencement de l’entraînement, vos données sont évaluées par rapport à la présence de contenu potentiellement nuisible (violence, contenu sexuel, haine et impartialité, automutilation – voir la définition des différentes catégories ici). Si du contenu nuisible est détecté et qu’il dépasse le niveau de gravité spécifié, votre tâche d’entraînement échoue et vous obtenez un message vous indiquant la raison (catégorie) de l’échec.
Exemple de message :
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
Vos données d’entraînement sont évaluées automatiquement lors de votre tâche d’importation de données dans le cadre de la capacité de fine-tuning.
Si la tâche de fine-tuning échoue suite à la détection de contenu nuisible dans les données d’entraînement, vous n’êtes pas facturé.
Évaluation du modèle
Une fois l’entraînement terminé, mais avant que le modèle ajusté soit en mesure d’être déployé, le modèle résultant est évalué par rapport à la présence de réponses potentiellement nuisibles à l’aide des métriques de risque et de sécurité intégrées d’Azure. En suivant la même approche de test que celle que nous appliquons aux grands modèles de langage de base, notre fonctionnalité d’évaluation simule une conversation avec votre modèle ajusté pour évaluer le potentiel de génération de contenu nuisible, encore une fois en utilisant les catégories de contenu nuisible spécifiées (violence, contenu sexuel, haine et impartialité, automutilation).
S’il s’avère qu’un modèle génère une sortie dont le contenu est détecté comme présentant un caractère nuisible au-delà d’un niveau acceptable, vous êtes informé que votre modèle ne peut pas être déployé, et vous obtenez des indications sur les catégories spécifiques de nuisances détectées :
Exemple de message :
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.
Comme pour l’évaluation de données, le modèle est évalué automatiquement lors de votre tâche de fine-tuning dans le cadre de la capacité de fine-tuning. Seule l’évaluation résultante (déployable ou non déployable) est journalisée par le service. Si le déploiement du modèle affiné échoue en raison de la détection de contenu nuisible dans les sorties générées par le modèle, l’entraînement exécuté ne vous est pas facturé.
Déployer un modèle ajusté
Lorsque le travail d’ajustement réussit, la valeur de la variable fine_tuned_model dans le corps de la réponse est définie sur le nom de votre modèle personnalisé. Votre modèle est désormais également disponible pour la découverte à partir de l’API Modèles de liste. Toutefois, vous ne pouvez pas émettre d’appels d’achèvement vers votre modèle personnalisé tant que votre modèle personnalisé n’est pas déployé. Vous devez déployer votre modèle personnalisé pour le rendre disponible pour une utilisation avec des appels d’achèvement.
Important
Après le déploiement d’un modèle personnalisé, si le déploiement reste inactif pendant plus de quinze (15) jours consécutifs, le déploiement est supprimé. Le déploiement d’un modèle personnalisé est inactif si le déploiement du modèle a été effectué plus de quinze (15) jours auparavant et qu’aucun appel de complétion ou d’achèvement de conversation n’a été effectué pendant une période continue de 15 jours.
La suppression d’un déploiement inactif ne supprime ou n’affecte pas le modèle personnalisé sous-jacent. Ainsi, le modèle personnalisé peut être redéployé à tout moment. Comme décrit dans la tarification d’Azure OpenAI Service, chaque modèle personnalisé (ajusté) déployé entraîne un coût horaire d’hébergement, indépendamment des appels d’achèvement ou d’achèvements de conversations instantanées effectués vers le modèle. Pour en savoir plus sur la planification et la gestion des coûts avec Azure OpenAI, reportez-vous à l’aide fournie dans Planifier la gestion des coûts pour Azure OpenAI Service.
Vous pouvez également utiliser Azure AI Foundry ou l’interface Azure CLI pour déployer votre modèle personnalisé.
Remarque
Un seul déploiement est autorisé pour un modèle personnalisé. Une erreur se produit si vous sélectionnez un modèle personnalisé déjà déployé.
Contrairement aux commandes précédentes du SDK, le déploiement doit être effectué à l’aide de l’API du plan de contrôle qui nécessite une autorisation distincte, un chemin d’API différent et une autre version de l’API.
| variable | Définition |
|---|---|
| token | Il existe plusieurs façons de générer un jeton d’autorisation. La méthode la plus simple pour le test initial consiste à lancer le service Cloud Shell à partir du Portail Azure. Exécutez ensuite az account get-access-token. Vous pouvez utiliser ce jeton comme jeton d’autorisation temporaire pour le test d’API. Nous vous recommandons de le stocker dans une nouvelle variable d’environnement. |
| abonnement | ID d’abonnement de la ressource Azure OpenAI associée. |
| resource_group | Nom du groupe de ressources de votre ressource Azure OpenAI. |
| resource_name | Le nom de ressource Azure OpenAI. |
| model_deployment_name | Nom personnalisé de votre nouveau modèle de déploiement de modèle. Il s’agit du nom qui sera référencé dans votre code lors de l’exécution d’appels de conversation. |
| fine_tuned_model | Récupérez cette valeur à partir de votre travail d’optimisation des résultats à l’étape précédente. Cela ressemble à ceci gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83. Vous devez ajouter cette valeur au deploy_data json. Vous pouvez également déployer un point de contrôle en transmettant l’ID de point de contrôle qui apparaîtra au format ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<YOUR_SUBSCRIPTION_ID>"
resource_group = "<YOUR_RESOURCE_GROUP_NAME>"
resource_name = "<YOUR_AZURE_OPENAI_RESOURCE_NAME>"
model_deployment_name ="gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2023-05-01"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"fine_tuned_model">, #retrieve this value from the previous call, it will look like gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83
"version": "1"
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Déploiement inter-région
L’ajustement prend en charge le déploiement d’un modèle ajusté vers une autre région que celle où il a été ajusté à l’origine. Vous pouvez également déployer vers une autre région/un autre abonnement.
Les seules limitations sont que la nouvelle région doit également prendre en charge l’ajustement et que, lors du déploiement sur plusieurs abonnements, le compte générant le jeton d’autorisation pour le déploiement doit avoir accès aux abonnements source et destination.
Vous trouverez ci-dessous un exemple de déploiement d’un modèle ajusté dans une région/un abonnement vers un autre.
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<DESTINATION_SUBSCRIPTION_ID>"
resource_group = "<DESTINATION_RESOURCE_GROUP_NAME>"
resource_name = "<DESTINATION_AZURE_OPENAI_RESOURCE_NAME>"
source_subscription = "<SOURCE_SUBSCRIPTION_ID>"
source_resource_group = "<SOURCE_RESOURCE_GROUP>"
source_resource = "<SOURCE_RESOURCE>"
source = f'/subscriptions/{source_subscription}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_resource}'
model_deployment_name ="gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2023-05-01"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"FINE_TUNED_MODEL_NAME">, # This value will look like gpt-35-turbo-0613.ft-0ab3f80e4f2242929258fff45b56a9ce
"version": "1",
"source": source
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Si vous souhaitez déployer dans le même abonnement, mais dans des régions différentes, vos groupes de ressources et votre abonnement seront simplement identiques pour les variables source et de destination et seuls les noms de ressource source et de destination doivent être uniques.
Déploiement entre locataires
Le compte utilisé pour générer des jetons d’accès avec az account get-access-token --tenant doivent disposer des autorisations Contributeur OpenAI Cognitive Services pour les ressources Azure OpenAI source et de destination. Vous devrez générer deux jetons différents, un pour le locataire source et un pour le locataire de destination.
import requests
subscription = "DESTINATION-SUBSCRIPTION-ID"
resource_group = "DESTINATION-RESOURCE-GROUP"
resource_name = "DESTINATION-AZURE-OPENAI-RESOURCE-NAME"
model_deployment_name = "DESTINATION-MODEL-DEPLOYMENT-NAME"
fine_tuned_model = "gpt-4o-mini-2024-07-18.ft-f8838e7c6d4a4cbe882a002815758510" #source fine-tuned model id example id provided
source_subscription_id = "SOURCE-SUBSCRIPTION-ID"
source_resource_group = "SOURCE-RESOURCE-GROUP"
source_account = "SOURCE-AZURE-OPENAI-RESOURCE-NAME"
dest_token = "DESTINATION-ACCESS-TOKEN" # az account get-access-token --tenant DESTINATION-TENANT-ID
source_token = "SOURCE-ACCESS-TOKEN" # az account get-access-token --tenant SOURCE-TENANT-ID
headers = {
"Authorization": f"Bearer {dest_token}",
"x-ms-authorization-auxiliary": f"Bearer {source_token}",
"Content-Type": "application/json"
}
url = f"https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}?api-version=2024-10-01"
payload = {
"sku": {
"name": "standard",
"capacity": 1
},
"properties": {
"model": {
"format": "OpenAI",
"name": fine_tuned_model,
"version": "1",
"sourceAccount": f"/subscriptions/{source_subscription_id}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_account}"
}
}
}
response = requests.put(url, headers=headers, json=payload)
# Check response
print(f"Status Code: {response.status_code}")
print(f"Response: {response.json()}")
Déployer un modèle avec Azure CLI
L’exemple suivant montre comment utiliser Azure CLI pour déployer votre modèle personnalisé. Avec Azure CLI, vous devez spécifier un nom pour le déploiement de votre modèle personnalisé. Pour obtenir plus d’informations sur l’utilisation d’Azure CLI pour déployer des modèles personnalisés, consultez az cognitiveservices account deployment.
Pour exécuter cette commande Azure CLI dans une fenêtre de console, vous devez remplacer les <espaces réservés> suivants par les valeurs correspondantes de votre modèle personnalisé :
| Espace réservé | Valeur |
|---|---|
| <YOUR_AZURE_SUBSCRIPTION> | Nom ou ID de votre abonnement Azure. |
| <YOUR_RESOURCE_GROUP> | Nom de votre groupe de ressources Azure. |
| <YOUR_RESOURCE_NAME> | Nom de votre ressource Azure OpenAI. |
| <YOUR_DEPLOYMENT_NAME> | Nom que vous souhaitez utiliser pour le déploiement de votre modèle. |
| <YOUR_FINE_TUNED_MODEL_ID> | Nom de votre modèle personnalisé |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
Utilisez un modèle personnalisé déployé
Après le déploiement de votre modèle personnalisé, vous pouvez l’utiliser comme n’importe quel autre modèle déployé. Vous pouvez utiliser les Terrains de jeu dans Azure AI Foundry pour tester votre nouveau déploiement. Vous pouvez continuer à utiliser les mêmes paramètres avec votre modèle personnalisé, comme temperature et max_tokens, que vous pouvez utiliser avec d’autres modèles déployés. Pour les modèles babbage-002 et davinci-002 ajustés, vous utiliserez le terrain de jeu d’achèvements et l’API d’achèvements. Pour les modèles gpt-35-turbo-0613 ajustés, vous utiliserez le terrain de jeu de conversation et l’API d’achèvements de conversation.
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.chat.completions.create(
model="gpt-35-turbo-ft", # model = "Custom deployment name you chose for your fine-tuning model"
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},
{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},
{"role": "user", "content": "Do other Azure AI services support this too?"}
]
)
print(response.choices[0].message.content)
Analysez votre modèle personnalisé
Azure OpenAI joint un fichier de résultats nommé results.csv à chaque tâche d’ajustement après son achèvement. Vous pouvez utiliser le fichier de résultats pour analyser les performances d’entraînement et de validation de votre modèle personnalisé. L’ID de fichier du fichier de résultats est répertorié pour chaque modèle personnalisé, et vous pouvez utiliser le Kit de développement logiciel (SDK) Python pour récupérer l’ID de fichier et télécharger le fichier de résultats à des fins d’analyse.
L’exemple Python suivant récupère l’ID de fichier du premier fichier de résultats attaché au travail d’ajustement de votre modèle personnalisé, puis utilise le Kit de développement logiciel (SDK) Python pour télécharger le fichier dans votre répertoire de travail à des fins d’analyse.
# Retrieve the file ID of the first result file from the fine-tuning job
# for the customized model.
response = client.fine_tuning.jobs.retrieve(job_id)
if response.status == 'succeeded':
result_file_id = response.result_files[0]
retrieve = client.files.retrieve(result_file_id)
# Download the result file.
print(f'Downloading result file: {result_file_id}')
with open(retrieve.filename, "wb") as file:
result = client.files.content(result_file_id).read()
file.write(result)
Le fichier de résultats est un fichier CSV contenant une ligne d’en-tête et une ligne pour chaque étape d’entraînement effectuée par la tâche de réglage précis. Le fichier de résultats contient les colonnes suivantes :
| Nom de la colonne | Description |
|---|---|
step |
Nombre de l’étape d’entraînement. Une étape d’entraînement représente une seule passe, avant et arrière, sur un lot de données d’entraînement. |
train_loss |
Perte du lot d’entraînement. |
train_mean_token_accuracy |
Pourcentage de jetons dans le lot d’apprentissage correctement prédits par le modèle. Par exemple, si la taille du lot est définie sur 3 et que vos données contiennent des achèvements [[1, 2], [0, 5], [4, 2]], cette valeur est définie sur 0,83 (5 sur 6) si le modèle prédit [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
Perte du lot de validation. |
validation_mean_token_accuracy |
Pourcentage de jetons dans le lot de validation correctement prédits par le modèle. Par exemple, si la taille du lot est définie sur 3 et que vos données contiennent des achèvements [[1, 2], [0, 5], [4, 2]], cette valeur est définie sur 0,83 (5 sur 6) si le modèle prédit [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
La perte de validation calculée à la fin de chaque époque. Lorsque la formation va bien, la perte doit diminuer. |
full_valid_mean_token_accuracy |
La précision moyenne valide des jetons calculée à la fin de chaque époque. Lorsque la formation va bien, la précision des jetons doit augmenter. |
Vous pouvez également afficher les données de votre fichier results.csv sous forme de tracés dans le portail Azure AI Foundry. Sélectionnez le lien pour votre modèle entraîné, et vous verrez trois graphiques : perte, précision moyenne du jeton et précision du jeton. Si vous avez fourni des données de validation, les deux jeux de données apparaissent sur le même tracé.
Les pertes devraient diminuer avec le temps et la précision augmenter. Si vous voyez une divergence entre vos données de formation et de validation, cela peut indiquer que vous vous trouvez en surajustement. Essayez d’effectuer l’apprentissage avec moins d’époques, ou un multiplicateur de taux d’apprentissage plus petit.
Nettoyez vos déploiements, modèles personnalisés et fichiers d’entraînement
Lorsque vous avez terminé avec votre modèle personnalisé, vous pouvez supprimer le déploiement et le modèle. Vous pouvez également supprimer les fichiers d’entraînement et de validation que vous avez chargés sur le service, si nécessaire.
Supprimer votre modèle de déploiement
Important
Après le déploiement d’un modèle personnalisé, si le déploiement reste inactif pendant plus de quinze (15) jours consécutifs, le déploiement est supprimé. Le déploiement d’un modèle personnalisé est inactif si le déploiement du modèle a été effectué plus de quinze (15) jours auparavant et qu’aucun appel de complétion ou d’achèvement de conversation n’a été effectué pendant une période continue de 15 jours.
La suppression d’un déploiement inactif ne supprime ou n’affecte pas le modèle personnalisé sous-jacent. Ainsi, le modèle personnalisé peut être redéployé à tout moment. Comme décrit dans la tarification d’Azure OpenAI Service, chaque modèle personnalisé (ajusté) déployé entraîne un coût horaire d’hébergement, indépendamment des appels d’achèvement ou d’achèvements de conversations instantanées effectués vers le modèle. Pour en savoir plus sur la planification et la gestion des coûts avec Azure OpenAI, reportez-vous à l’aide fournie dans Planifier la gestion des coûts pour Azure OpenAI Service.
Vous pouvez utiliser différentes méthodes pour supprimer le déploiement de votre modèle personnalisé :
Supprimer votre modèle personnalisé
De même, vous pouvez utiliser différentes méthodes pour supprimer votre modèle personnalisé :
Remarque
Vous ne pouvez pas supprimer un modèle personnalisé si un déploiement de ce modèle existe. Vous devez d’abord supprimer votre déploiement de modèle avant de pouvoir supprimer votre modèle personnalisé.
Supprimer vos fichiers de formation
Vous pouvez éventuellement supprimer les fichiers d’apprentissage et de validation que vous avez chargés pour l’apprentissage et les fichiers de résultats générés pendant l’apprentissage, à partir de votre abonnement Azure OpenAI. Vous pouvez utiliser les méthodes suivantes pour supprimer vos fichiers d’entraînement, de validation et de résultats :
- Azure AI Foundry
- Les API REST
- SDK Python
L’exemple Python suivant utilise le kit de développement logiciel (SDK) Python pour supprimer les fichiers d’apprentissage, de validation et de résultats de votre modèle personnalisé :
print('Checking for existing uploaded files.')
results = []
# Get the complete list of uploaded files in our subscription.
files = openai.File.list().data
print(f'Found {len(files)} total uploaded files in the subscription.')
# Enumerate all uploaded files, extracting the file IDs for the
# files with file names that match your training dataset file and
# validation dataset file names.
for item in files:
if item["filename"] in [training_file_name, validation_file_name, result_file_name]:
results.append(item["id"])
print(f'Found {len(results)} already uploaded files that match our files')
# Enumerate the file IDs for our files and delete each file.
print(f'Deleting already uploaded files.')
for id in results:
openai.File.delete(sid = id)
Ajustement continu
Une fois que vous avez créé un modèle ajusté, il est possible que vous vouliez continuer à affiner le modèle au fil du temps via un ajustement plus précis. L’ajustement continu correspond au processus itératif de sélection d’un modèle déjà affiné comme modèle de base et à l’ajuster davantage sur de nouveaux ensembles d’exemples d’apprentissage.
Si vous souhaitez effectuer l’ajustement d’un modèle précédemment ajusté, vous utiliserez le même processus décrit dans créer un modèle personnalisé mais, au lieu de spécifier le nom d’un modèle de base générique, vous spécifierez l’ID de votre modèle déjà ajusté. Un ID de modèle ajusté personnalisé ressemblera à gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7" # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
Nous vous conseillons également d’inclure le paramètre suffix pour faciliter la distinction entre les différentes itérations de votre modèle ajusté. suffix prend une chaîne et est défini pour identifier le modèle ajusté. Avec l’API Python OpenAI, une chaîne 18 caractères au maximum est prise en charge et est ajoutée au nom de votre modèle ajusté.
Si vous ne connaissez pas l’ID de votre modèle ajusté existant, cette information est disponible sur la page Modèles d’Azure AI Foundry, ou vous pouvez générer une liste de modèles pour une ressource Azure OpenAI donnée en utilisant l’API REST.
Prérequis
- Lisez le guide expliquant quand utiliser l’ajustement Azure OpenAI.
- Un abonnement Azure. Créez-en un gratuitement.
- Ressource Azure OpenAI. Pour plus d’informations, consultez l’article Créer une ressource et déployer un modèle à l’aide d’Azure OpenAI.
- L’accès au réglage précis nécessite un contributeur OpenAI de Cognitive Services.
- Si vous n’avez pas encore accès au quota d’affichage et que vous déployez des modèles dans le portail Azure AI Foundry, vous aurez besoin d’autorisations supplémentaires.
Modèles
Les modèles suivants prennent en charge le réglage précis :
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)*gpt-4o(2024-08-06)gpt-4o-mini(18-07-2024)
* L’optimisation de ce modèle est actuellement en préversion publique.
Vous pouvez également ajuster un modèle précédemment ajusté, formaté comme base-model.ft-{jobid}.
Consultez la page modèles pour vérifier quelles régions prennent actuellement en charge le réglage précis.
Passer en revue le flux de travail de l’API REST
Prenez un moment pour évaluer le flux de travail de l’ajustement pour une utilisation des API REST et de Python avec Azure OpenAI :
- Préparer vos données d’apprentissage et de validation.
- Sélectionner un modèle de base.
- Charger vos données d’apprentissage.
- Effectuer l’apprentissage de votre nouveau modèle personnalisé.
- Vérifier l’état de votre modèle personnalisé.
- Déployer votre modèle personnalisé pour une utilisation.
- Utiliser votre modèle personnalisé.
- Éventuellement, analyser les performances et l’ajustement de votre modèle personnalisé.
Préparer vos données d’entraînement et de validation
Vos données d’apprentissage et vos jeux de données de validation se composent d’exemples d’entrée et de sortie de la façon dont vous souhaitez que le modèle fonctionne.
Différents types de modèles nécessitent un format différent de données d’entraînement.
Les données d’entraînement et de validation que vous utilisez doivent être mises en forme en tant que document JSON Lines (JSONL). Pour gpt-35-turbo-0613 et les autres modèles liés, le jeu de données de fine-tuning doit être mis en forme dans le format conversationnel utilisé par l’API des achèvements de conversation.
Si vous souhaitez une procédure pas à pas de l’ajustement d’un gpt-35-turbo-0613, reportez-vous au Tutoriel : Ajustement Azure OpenAI.
Exemple de format de fichier
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
Format de fichier d’invite multitour
Plusieurs tours d’une invite dans une seule ligne de votre fichier de formation jsonl sont également pris en charge. Pour ignorer le fine-tuning sur des messages d’assistant spécifiques, ajoutez la paire clé/valeur facultative weight. Actuellement, weight peut être défini sur 0 ou 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Saisies semi-automatiques de conversation avec vision
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Outre le format JSONL, les fichiers de données d’apprentissage et de validation doivent être encodés en UTF-8 et inclure une marque d’ordre d’octet (BOM). La taille du fichier doit être inférieure à 512 Mo.
Créer vos jeux de données d’apprentissage et de validation
Plus vous avez d’exemples de formation, mieux c’est. Les travaux de fine-tuning ne seront pas effectués sans au moins 10 exemples d’apprentissage, mais un si petit nombre ne suffit pas pour influencer de façon notable les réponses du modèle. Il est recommandé de fournir des centaines, voire des milliers d’exemples d’apprentissage pour obtenir de bons résultats.
En général, le doublement de la taille du jeu de données peut entraîner une augmentation linéaire de la qualité du modèle. Mais gardez à l’esprit que les exemples de faible qualité peuvent avoir un impact négatif sur les performances. Si vous effectuez l’apprentissage du modèle sur une grande quantité de données internes, sans nettoyer au préalable le jeu de données pour ne conserver que les exemples de la plus haute qualité, vous risquez d’obtenir un modèle dont les performances sont bien inférieures à celles attendues.
Sélectionnez le modèle de base
La première étape de la création d’un modèle personnalisé consiste à choisir un modèle de base. Le volet Modèle de base vous permet de choisir un modèle de base à utiliser pour votre modèle personnalisé. Votre choix influence les performances et le coût de votre modèle.
Sélectionnez un modèle de base dans la liste déroulante Type de modèle de base, puis Suivant pour continuer.
Vous pouvez créer un modèle personnalisé à partir de l’un des modèles de base disponibles suivants :
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)gpt-4o(2024-08-06)gpt-4o-mini(2023-07-18)
Vous pouvez également ajuster un modèle précédemment ajusté, formaté comme base-model.ft-{jobid}.
Pour plus d’informations sur les modèles de base qui peuvent être affinés, consultez la section Modèles.
Charger vos données d’entraînement
L’étape suivante consiste à choisir les données d’entraînement préparées existantes ou à charger de nouvelles données d’entraînement préparées à utiliser lors de l’ajustement de votre modèle. Après avoir préparé vos données d’apprentissage, vous pouvez charger vos fichiers dans le service. Il existe deux façons de charger des données d’apprentissage :
Pour des fichiers de données volumineux, nous vous recommandons d’importer à partir d’un magasin Blob Azure. Les fichiers volumineux peuvent devenir instables lors du chargement via des formulaires multipart, car les requêtes sont atomiques et ne peuvent pas être retentées ou reprises. Pour plus d’informations sur le stockage Blob Azure, consultez Qu’est-ce que le stockage d’objets blob Azure ?
Remarque
Les fichiers de données d’apprentissage doivent être formatés en fichiers JSONL, encodés en UTF-8 avec une marque d’ordre d’octet (BOM). La taille du fichier doit être inférieure à 512 Mo.
Charger des données d’entraînement
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\training_set.jsonl;type=application/json"
Charger des données de validation
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\validation_set.jsonl;type=application/json"
Créer un modèle personnalisé
Après avoir chargé vos fichiers d’entraînement et de validation, vous êtes prêt à démarrer la tâche de réglage précis. Le code suivant montre un exemple de création d’un travail d’ajustement avec l’API REST.
Dans cet exemple, nous transmettons également le paramètre de graine. La graine contrôle la reproductibilité du travail. La transmission de la même graine et des mêmes paramètres de travail doit produire les mêmes résultats, mais peut différer dans de rares cas. Si une graine n’est pas spécifiée, une graine est générée pour vous.
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-35-turbo-0613",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"seed": 105
}'
Vous pouvez également passer d’autres paramètres facultatifs tels que des hyperparamètres pour mieux contrôler le processus d’ajustement. Pour l’apprentissage initial, nous vous conseillons d’utiliser les valeurs par défaut automatiques qui sont présentes sans spécifier ces paramètres.
Les hyperparamètres actuels pris en charge pour l’ajustement sont les suivants :
| Nom | Type | Description |
|---|---|---|
batch_size |
entier | Taille de lot à utiliser pour la formation. La taille du lot est le nombre d’exemples de la formation utilisés pour entraîner un seul passage avant et arrière. En général, nous avons constaté que les tailles de lot plus grandes ont tendance à fonctionner mieux pour les jeux de données plus volumineux. La valeur par défaut et la valeur maximale de cette propriété sont propres à un modèle de base. Une taille de lot plus grande signifie que les paramètres de modèle sont mis à jour moins souvent, mais avec une variance plus faible. |
learning_rate_multiplier |
number | Multiplicateur de taux de formation à utiliser pour la formation. Le taux d’apprentissage de réglage est le taux d’apprentissage d’origine utilisé pour le pré-entraînement multiplié par cette valeur. Les taux d’apprentissage plus importants ont tendance à mieux fonctionner que les tailles de lot plus grandes. Nous vous recommandons d’expérimenter des valeurs comprises entre 0,02 et 0,2 pour voir ce qui produit les meilleurs résultats. Un taux d’apprentissage plus faible peut être utile pour éviter un surajustement. |
n_epochs |
entier | Nombre d’époques pour lequel effectuer la formation du modèle. Une époque fait référence à un cycle complet dans le jeu de données de formation. |
seed |
entier | La graine contrôle la reproductibilité du travail. La transmission de la même graine et des mêmes paramètres de travail doit produire les mêmes résultats, mais peut différer dans de rares cas. Si aucune graine n’est spécifiée, une graine sera générée pour vous. |
Vérifier l’état de votre modèle personnalisé
Après avoir démarré une tâche d’ajustement, un certain temps peut être nécessaire pour qu’elle s’achève. Votre tâche peut être mise en file d’attente derrière d’autres tâches sur le système. L’apprentissage de votre modèle peut prendre quelques minutes ou quelques heures selon le modèle et la taille du jeu de données. L’exemple suivant utilise l’API REST pour vérifier l’état de votre travail d’ajustement. L’exemple récupère des informations sur votre tâche à l’aide de l’ID de tâche retourné depuis l’exemple précédent :
curl -X GET $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<YOUR-JOB-ID>?api-version=2024-05-01-preview \
-H "api-key: $AZURE_OPENAI_API_KEY"
Répertorier les événements ajustés
Pour examiner les événements ajustés individuels générés lors de la formation :
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/events?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Points de contrôle
Lorsque chaque époque de formation termine un point de contrôle est généré. Un point de contrôle est une version entièrement fonctionnelle d’un modèle qui peut être déployé et utilisé comme modèle cible pour les travaux d’ajustement suivants. Les points de contrôle peuvent être particulièrement utiles, car ils peuvent fournir un instantané de votre modèle avant le surajustement. Lorsqu’un travail d’ajustement se termine, vous disposez des trois versions les plus récentes du modèle disponibles pour le déploiement. L’époque finale sera représentée par votre modèle ajusté, les deux époques précédentes seront disponibles en tant que points de contrôle.
Vous pouvez exécuter la commande list checkpoints pour récupérer la liste des points de contrôle associés à un travail d’ajustement individuel :
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/checkpoints?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Évaluation de la sécurité pour l’ajustement de GPT-4, GPT-4o, et GPT-4o-mini – Préversion publique
GPT-4o, GPT-4o-mini et GPT-4 sont nos modèles les plus avancés qui peuvent être ajustés à vos besoins. Comme pour les modèles Azure OpenAI de façon générale, les capacités avancées des modèles ajustés s’accompagnent d’enjeux plus importants en matière d’IA responsable eu égard au contenu nuisible, à la manipulation, au comportement pseudo-humain, aux problèmes de confidentialité, etc. Pour en savoir plus sur les risques, les capacités et les limites, consultez Vue d’ensemble des pratiques de l’IA responsable et Note de transparence. Pour aider à atténuer les risques associés aux modèles ajustés avancés, nous avons mis en place des étapes d’évaluation supplémentaires pour contribuer à la détection et à la prévention des contenus nuisibles dans l’entraînement et les sorties des modèles ajustés. Ces étapes reposent sur le standard Microsoft en matière d’IA responsable et le filtrage de contenu Azure OpenAI Service.
- Les évaluations sont réalisées dans des espaces de travail privés dédiés, spécifiques au client ;
- Les points de terminaison d’évaluation se trouvent dans la même zone géographique que la ressource Azure OpenAI ;
- Les données d’entraînement ne sont pas stockées au cours des évaluations ; seule l’évaluation du modèle final (déployable ou non déployable) est conservée ; et
Les filtres d’évaluation de modèles affinés GPT-4o, GPT-4o-mini et GPT-4 sont définis sur des seuils prédéfinis et ne peuvent pas être modifiés par les clients ; elles ne sont liées à aucune configuration de filtrage de contenu personnalisée que vous avez peut-être créée.
Évaluation des données
Avant le commencement de l’entraînement, vos données sont évaluées par rapport à la présence de contenu potentiellement nuisible (violence, contenu sexuel, haine et impartialité, automutilation – voir la définition des différentes catégories ici). Si du contenu nuisible est détecté et qu’il dépasse le niveau de gravité spécifié, votre tâche d’entraînement échoue et vous obtenez un message vous indiquant la raison (catégorie) de l’échec.
Exemple de message :
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
Vos données d’entraînement sont évaluées automatiquement lors de votre tâche d’importation de données dans le cadre de la capacité de fine-tuning.
Si la tâche de fine-tuning échoue suite à la détection de contenu nuisible dans les données d’entraînement, vous n’êtes pas facturé.
Évaluation du modèle
Une fois l’entraînement terminé, mais avant que le modèle ajusté soit en mesure d’être déployé, le modèle résultant est évalué par rapport à la présence de réponses potentiellement nuisibles à l’aide des métriques de risque et de sécurité intégrées d’Azure. En suivant la même approche de test que celle que nous appliquons aux grands modèles de langage de base, notre fonctionnalité d’évaluation simule une conversation avec votre modèle ajusté pour évaluer le potentiel de génération de contenu nuisible, encore une fois en utilisant les catégories de contenu nuisible spécifiées (violence, contenu sexuel, haine et impartialité, automutilation).
S’il s’avère qu’un modèle génère une sortie dont le contenu est détecté comme présentant un caractère nuisible au-delà d’un niveau acceptable, vous êtes informé que votre modèle ne peut pas être déployé, et vous obtenez des indications sur les catégories spécifiques de nuisances détectées :
Exemple de message :
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.
Comme pour l’évaluation de données, le modèle est évalué automatiquement lors de votre tâche de fine-tuning dans le cadre de la capacité de fine-tuning. Seule l’évaluation résultante (déployable ou non déployable) est journalisée par le service. Si le déploiement du modèle affiné échoue en raison de la détection de contenu nuisible dans les sorties générées par le modèle, l’entraînement exécuté ne vous est pas facturé.
Déployer un modèle ajusté
Important
Après le déploiement d’un modèle personnalisé, si le déploiement reste inactif pendant plus de quinze (15) jours consécutifs, le déploiement est supprimé. Le déploiement d’un modèle personnalisé est inactif si le déploiement du modèle a été effectué plus de quinze (15) jours auparavant et qu’aucun appel de complétion ou d’achèvement de conversation n’a été effectué pendant une période continue de 15 jours.
La suppression d’un déploiement inactif ne supprime ou n’affecte pas le modèle personnalisé sous-jacent. Ainsi, le modèle personnalisé peut être redéployé à tout moment. Comme décrit dans la tarification d’Azure OpenAI Service, chaque modèle personnalisé (ajusté) déployé entraîne un coût horaire d’hébergement, indépendamment des appels d’achèvement ou d’achèvements de conversations instantanées effectués vers le modèle. Pour en savoir plus sur la planification et la gestion des coûts avec Azure OpenAI, reportez-vous à l’aide fournie dans Planifier la gestion des coûts pour Azure OpenAI Service.
L’exemple Python suivant montre comment utiliser l’API REST pour créer un déploiement de modèle pour votre modèle personnalisé. L’API REST génère un nom pour le déploiement de votre modèle personnalisé.
| variable | Définition |
|---|---|
| token | Il existe plusieurs façons de générer un jeton d’autorisation. La méthode la plus simple pour le test initial consiste à lancer le service Cloud Shell à partir du Portail Azure. Exécutez ensuite az account get-access-token. Vous pouvez utiliser ce jeton comme jeton d’autorisation temporaire pour le test d’API. Nous vous recommandons de le stocker dans une nouvelle variable d’environnement. |
| abonnement | ID d’abonnement de la ressource Azure OpenAI associée. |
| resource_group | Nom du groupe de ressources de votre ressource Azure OpenAI. |
| resource_name | Le nom de ressource Azure OpenAI. |
| model_deployment_name | Nom personnalisé de votre nouveau modèle de déploiement de modèle. Il s’agit du nom qui sera référencé dans votre code lors de l’exécution d’appels de conversation. |
| fine_tuned_model | Récupérez cette valeur à partir de votre travail d’optimisation des résultats à l’étape précédente. Cela ressemble à ceci gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83. Vous devez ajouter cette valeur au fichier json deploy_data. Vous pouvez également déployer un point de contrôle en transmettant l’ID de point de contrôle qui apparaîtra au format ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
curl -X POST "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2023-05-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1"
}
}
}'
Déploiement inter-région
L’ajustement prend en charge le déploiement d’un modèle ajusté vers une autre région que celle où il a été ajusté à l’origine. Vous pouvez également déployer vers une autre région/un autre abonnement.
Les seules limitations sont que la nouvelle région doit également prendre en charge l’ajustement et que, lors du déploiement sur plusieurs abonnements, le compte générant le jeton d’autorisation pour le déploiement doit avoir accès aux abonnements source et destination.
Vous trouverez ci-dessous un exemple de déploiement d’un modèle ajusté dans une région/un abonnement vers un autre.
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2023-05-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"source": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
Si vous souhaitez déployer dans le même abonnement, mais dans des régions différentes, vos groupes de ressources et votre abonnement seront simplement identiques pour les variables source et de destination et seuls les noms de ressource source et de destination doivent être uniques.
Déploiement entre locataires
Le compte utilisé pour générer des jetons d’accès avec az account get-access-token --tenant doivent disposer des autorisations Contributeur OpenAI Cognitive Services pour les ressources Azure OpenAI source et de destination. Vous devrez générer deux jetons différents, un pour le locataire source et un pour le locataire de destination.
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>?api-version=2024-10-01" \
-H "Authorization: Bearer <DESTINATION TOKEN>" \
-H "x-ms-authorization-auxiliary: Bearer <SOURCE TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"sourceAccount": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
Déployer un modèle avec Azure CLI
L’exemple suivant montre comment utiliser Azure CLI pour déployer votre modèle personnalisé. Avec Azure CLI, vous devez spécifier un nom pour le déploiement de votre modèle personnalisé. Pour obtenir plus d’informations sur l’utilisation d’Azure CLI pour déployer des modèles personnalisés, consultez az cognitiveservices account deployment.
Pour exécuter cette commande Azure CLI dans une fenêtre de console, vous devez remplacer les <espaces réservés> suivants par les valeurs correspondantes de votre modèle personnalisé :
| Espace réservé | Valeur |
|---|---|
| <YOUR_AZURE_SUBSCRIPTION> | Nom ou ID de votre abonnement Azure. |
| <YOUR_RESOURCE_GROUP> | Nom de votre groupe de ressources Azure. |
| <YOUR_RESOURCE_NAME> | Nom de votre ressource Azure OpenAI. |
| <YOUR_DEPLOYMENT_NAME> | Nom que vous souhaitez utiliser pour le déploiement de votre modèle. |
| <YOUR_FINE_TUNED_MODEL_ID> | Nom de votre modèle personnalisé |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
Utilisez un modèle personnalisé déployé
Après le déploiement de votre modèle personnalisé, vous pouvez l’utiliser comme n’importe quel autre modèle déployé. Vous pouvez utiliser les Terrains de jeu dans Azure AI Foundry pour tester votre nouveau déploiement. Vous pouvez continuer à utiliser les mêmes paramètres avec votre modèle personnalisé, comme temperature et max_tokens, que vous pouvez utiliser avec d’autres modèles déployés. Pour les modèles babbage-002 et davinci-002 ajustés, vous utiliserez le terrain de jeu Saisies semi-automatique et l’API Saisies semi-automatique. Pour les modèles gpt-35-turbo-0613 ajustés, vous utiliserez le terrain de jeu Conversation et l’API Saisie semi-automatique de conversation.
curl $AZURE_OPENAI_ENDPOINT/openai/deployments/<deployment_name>/chat/completions?api-version=2023-05-15 \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{"messages":[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},{"role": "user", "content": "Do other Azure AI services support this too?"}]}'
Analysez votre modèle personnalisé
Azure OpenAI joint un fichier de résultats nommé results.csv à chaque tâche d’ajustement après son achèvement. Vous pouvez utiliser le fichier de résultats pour analyser les performances d’entraînement et de validation de votre modèle personnalisé. L’ID de fichier du fichier de résultats est répertorié pour chaque modèle personnalisé, et vous pouvez utiliser l’API REST pour récupérer l’ID de fichier et télécharger le fichier de résultats pour l’analyse.
L’exemple Python suivant utilise l’API REST pour récupérer l’ID de fichier du premier fichier de résultats attaché au travail d’ajustement de votre modèle personnalisé, puis télécharge le fichier dans votre répertoire de travail à des fins d’analyse.
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<JOB_ID>?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY")
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/files/<RESULT_FILE_ID>/content?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY" > <RESULT_FILENAME>
Le fichier de résultats est un fichier CSV contenant une ligne d’en-tête et une ligne pour chaque étape d’entraînement effectuée par la tâche de réglage précis. Le fichier de résultats contient les colonnes suivantes :
| Nom de la colonne | Description |
|---|---|
step |
Nombre de l’étape d’entraînement. Une étape d’entraînement représente une seule passe, avant et arrière, sur un lot de données d’entraînement. |
train_loss |
Perte du lot d’entraînement. |
train_mean_token_accuracy |
Pourcentage de jetons dans le lot d’apprentissage correctement prédits par le modèle. Par exemple, si la taille du lot est définie sur 3 et que vos données contiennent des achèvements [[1, 2], [0, 5], [4, 2]], cette valeur est définie sur 0,83 (5 sur 6) si le modèle prédit [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
Perte du lot de validation. |
validation_mean_token_accuracy |
Pourcentage de jetons dans le lot de validation correctement prédits par le modèle. Par exemple, si la taille du lot est définie sur 3 et que vos données contiennent des achèvements [[1, 2], [0, 5], [4, 2]], cette valeur est définie sur 0,83 (5 sur 6) si le modèle prédit [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
La perte de validation calculée à la fin de chaque époque. Lorsque la formation va bien, la perte doit diminuer. |
full_valid_mean_token_accuracy |
La précision moyenne valide des jetons calculée à la fin de chaque époque. Lorsque la formation va bien, la précision des jetons doit augmenter. |
Vous pouvez également afficher les données de votre fichier results.csv sous forme de tracés dans le portail Azure AI Foundry. Sélectionnez le lien pour votre modèle entraîné, et vous verrez trois graphiques : perte, précision moyenne du jeton et précision du jeton. Si vous avez fourni des données de validation, les deux jeux de données apparaissent sur le même tracé.
Les pertes devraient diminuer avec le temps et la précision augmenter. Si vous voyez une divergence entre vos données d’apprentissage et de validation, cela peut indiquer que vous vous trouvez en surajustement. Essayez d’effectuer l’apprentissage avec moins d’époques, ou un multiplicateur de taux d’apprentissage plus petit.
Nettoyez vos déploiements, modèles personnalisés et fichiers d’entraînement
Lorsque vous avez terminé avec votre modèle personnalisé, vous pouvez supprimer le déploiement et le modèle. Vous pouvez également supprimer les fichiers d’entraînement et de validation que vous avez chargés sur le service, si nécessaire.
Supprimer votre modèle de déploiement
Vous pouvez utiliser différentes méthodes pour supprimer le déploiement de votre modèle personnalisé :
Supprimer votre modèle personnalisé
De même, vous pouvez utiliser différentes méthodes pour supprimer votre modèle personnalisé :
Remarque
Vous ne pouvez pas supprimer un modèle personnalisé si un déploiement de ce modèle existe. Vous devez d’abord supprimer votre déploiement de modèle avant de pouvoir supprimer votre modèle personnalisé.
Supprimer vos fichiers de formation
Vous pouvez éventuellement supprimer les fichiers d’apprentissage et de validation que vous avez chargés pour l’apprentissage et les fichiers de résultats générés pendant l’apprentissage, à partir de votre abonnement Azure OpenAI. Vous pouvez utiliser les méthodes suivantes pour supprimer vos fichiers d’entraînement, de validation et de résultats :
Ajustement continu
Une fois que vous avez créé un modèle ajusté, il est possible que vous vouliez continuer à affiner le modèle au fil du temps via un ajustement plus précis. L’ajustement continu correspond au processus itératif de sélection d’un modèle déjà affiné comme modèle de base et à l’ajuster davantage sur de nouveaux ensembles d’exemples d’apprentissage.
Si vous souhaitez effectuer l’ajustement d’un modèle précédemment ajusté, vous utiliserez le même processus décrit dans créer un modèle personnalisé mais, au lieu de spécifier le nom d’un modèle de base générique, vous spécifierez l’ID de votre modèle déjà ajusté. Un ID de modèle ajusté personnalisé ressemblera à gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2023-12-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"suffix": "<additional text used to help identify fine-tuned models>"
}'
Nous vous conseillons également d’inclure le paramètre suffix pour faciliter la distinction entre les différentes itérations de votre modèle ajusté. suffix prend une chaîne et est défini pour identifier le modèle ajusté. Le suffixe peut contenu jusqu’à 40 caractères (a-z, A-Z, 0-9, - et _) qui seront ajoutés au nom de votre modèle ajusté.
Si vous ne connaissez pas l’ID de votre modèle ajusté, cette information est disponible sur la page Modèles d’Azure AI Foundry, ou vous pouvez générer une liste de modèles pour une ressource Azure OpenAI donnée en utilisant l’API REST.
Standard global (préversion)
Le réglage précis d’Azure OpenAI prend en charge déploiements standard globaux dans la région USA Est2, USA Centre Nord et Suède Centre pour :
gpt-4o-mini-2024-07-18gpt-4o-2024-08-06(les nouveaux déploiements ne sont pas disponibles avant janvier 2025)
Les déploiements globaux standard et ajustés offrent des économies, mais les poids des modèles personnalisés peuvent être temporairement stockés en dehors de la zone géographique de votre ressource Azure OpenAI.

Actuellement, les déploiements d’optimisation globale standard ne prennent pas en charge la vision et les sorties structurées.
Optimisation de Vision
Le réglage précis est également possible avec des images dans vos fichiers JSONL. Tout comme vous pouvez envoyer une ou plusieurs entrées d’image à des complétions de conversation, vous pouvez inclure ces mêmes types de messages dans vos données d’entraînement. Les images peuvent être fournies sous forme d’URL accessibles publiquement ou d’URI de données contenant images encodées en base64.
Configuration requise pour le jeu de données d’image
- Votre fichier d’entraînement peut contenir au maximum 50 000 exemples contenant des images (sans inclure d’exemples de texte).
- Chaque exemple peut avoir au maximum 64 images.
- Chaque image peut être au maximum de 10 Mo.
Format
Les images doivent être :
- JPEG
- PNG
- WEBP
Les images doivent être en mode image RVB ou RVBA.
Vous ne pouvez pas inclure d’images comme sortie de messages avec le rôle Assistant.
Stratégie de modération du contenu
Nous scannons vos images avant la formation pour vous assurer qu’elles respectent notre stratégie d’utilisation Note de transparence. Cela peut introduire la latence dans la validation de fichier avant le début du réglage précis.
Les images contenant les éléments suivants sont exclues de votre jeu de données et ne sont pas utilisées pour l’entraînement :
- Contacts
- Visages
- CAPTCHAs
Important
Pour l'amélioration de la vision, le processus de filtrage des visages : Nous sélectionnons les visages/personnes afin d'exclure ces images de la formation du modèle. La fonctionnalité de dépistage tire parti de la détection des visages WITHOUT Identification du visage, ce qui signifie que nous ne créons pas de modèles de visage ni de mesurer une géométrie faciale spécifique, et la technologie utilisée pour détecter les visages n’est pas capable d’identifier de manière unique les individus. Pour en savoir plus sur les données et la confidentialité du visage, reportez-vous à – Données et confidentialité pour Visage – Services Azure AI | Microsoft Learn.
Mise en cache des prompts
Le réglage précis d’Azure OpenAI prend en charge la mise en cache des invites avec des modèles sélectionnés. La mise en cache des invites vous permet de réduire la latence globale des requêtes et des coûts pour les invites plus longues qui ont du contenu identique au début de l’invite. Pour en savoir plus sur la mise en cache des invites, consultez prise en main de la mise en cache des invites.
Optimisation des préférences directes (DPO) (préversion)
L’optimisation des préférences directes (DPO) est une technique d’alignement pour les modèles de langage volumineux, utilisée pour ajuster les pondérations des modèles en fonction des préférences humaines. Il diffère de l’apprentissage par renforcement des commentaires humains (RLHF) dans le fait qu’il ne nécessite pas l’ajustement d’un modèle de récompense et utilise des préférences de données binaires plus simples pour l’entraînement. Il est plus léger de calcul et plus rapide que RLHF, tout en étant tout aussi efficace à l’alignement.
Pourquoi le DPO est-il utile ?
DPO est particulièrement utile dans les scénarios où il n’existe aucune réponse correcte claire et des éléments subjectifs tels que le ton, le style ou les préférences de contenu spécifiques sont importants. Cette approche permet également au modèle d’apprendre des exemples positifs (ce qui est considéré comme correct ou idéal) et des exemples négatifs (ce qui est moins souhaité ou incorrect).
DPO est considéré comme une technique qui permettra aux clients de générer plus facilement des jeux de données d’entraînement de haute qualité. Bien que de nombreux clients aient du mal à générer suffisamment de jeux de données volumineux pour le réglage précis supervisé, ils ont souvent des données de préférence déjà collectées en fonction des journaux d’activité utilisateur, des tests A/B ou des efforts d’annotation manuelle plus petits.
Format de jeu de données d’optimisation des préférences directes
Les fichiers d’optimisation des préférences directes ont un format différent du réglage précis supervisé. Les clients fournissent une « conversation » contenant le message système et le message utilisateur initial, puis des « achèvements » avec des données de préférence jumelées. Les utilisateurs ne peuvent fournir que deux saisies semi-automatiques.
Trois champs de niveau supérieur : input, preferred_output et non_preferred_output
- Chaque élément du preferred_output/non_preferred_output doit contenir au moins un message d’assistant
- Chaque élément du preferred_output/non_preferred_output ne peut avoir que des rôles dans (Assistant, outil)
{
"input": {
"messages": {"role": "system", "content": ...},
"tools": [...],
"parallel_tool_calls": true
},
"preferred_output": [{"role": "assistant", "content": ...}],
"non_preferred_output": [{"role": "assistant", "content": ...}]
}
Les jeux de données d’apprentissage doivent être au format jsonl :
{{"input": {"messages": [{"role": "system", "content": "You are a chatbot assistant. Given a user question with multiple choice answers, provide the correct answer."}, {"role": "user", "content": "Question: Janette conducts an investigation to see which foods make her feel more fatigued. She eats one of four different foods each day at the same time for four days and then records how she feels. She asks her friend Carmen to do the same investigation to see if she gets similar results. Which would make the investigation most difficult to replicate? Answer choices: A: measuring the amount of fatigue, B: making sure the same foods are eaten, C: recording observations in the same chart, D: making sure the foods are at the same temperature"}]}, "preferred_output": [{"role": "assistant", "content": "A: Measuring The Amount Of Fatigue"}], "non_preferred_output": [{"role": "assistant", "content": "D: making sure the foods are at the same temperature"}]}
}
Prise en charge du modèle d’optimisation des préférences directes
gpt-4o-2024-08-06prend en charge l’optimisation directe des préférences dans ses régions de réglage précis respectives. La disponibilité de la dernière région est mise à jour dans la page modèles
Les utilisateurs peuvent utiliser le réglage des préférences avec les modèles de base ainsi que les modèles qui ont déjà été affinés à l’aide d’un réglage précis supervisé tant qu’ils sont d’un modèle/version pris en charge.
Comment utiliser le réglage précis de l’optimisation des préférences directes ?
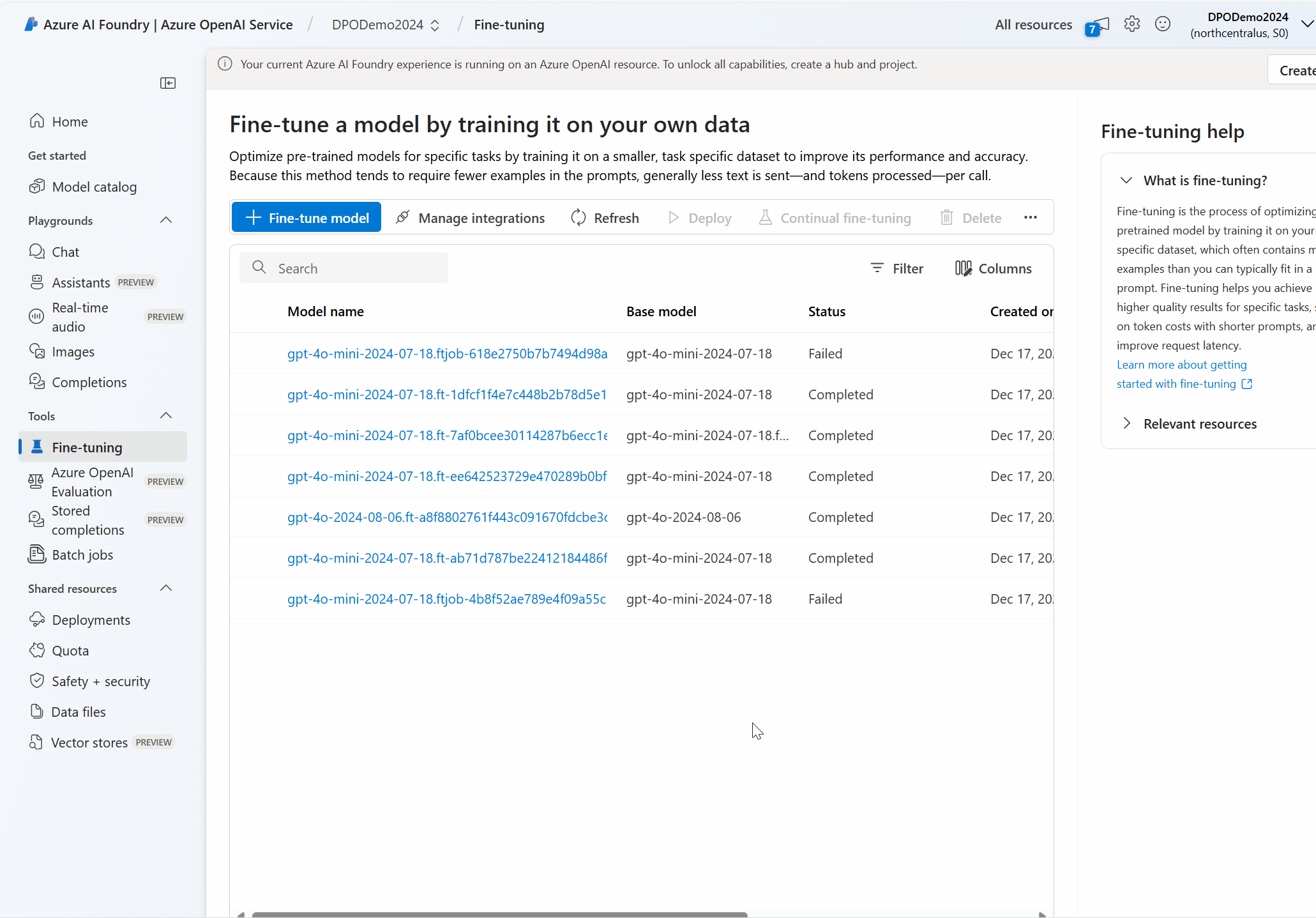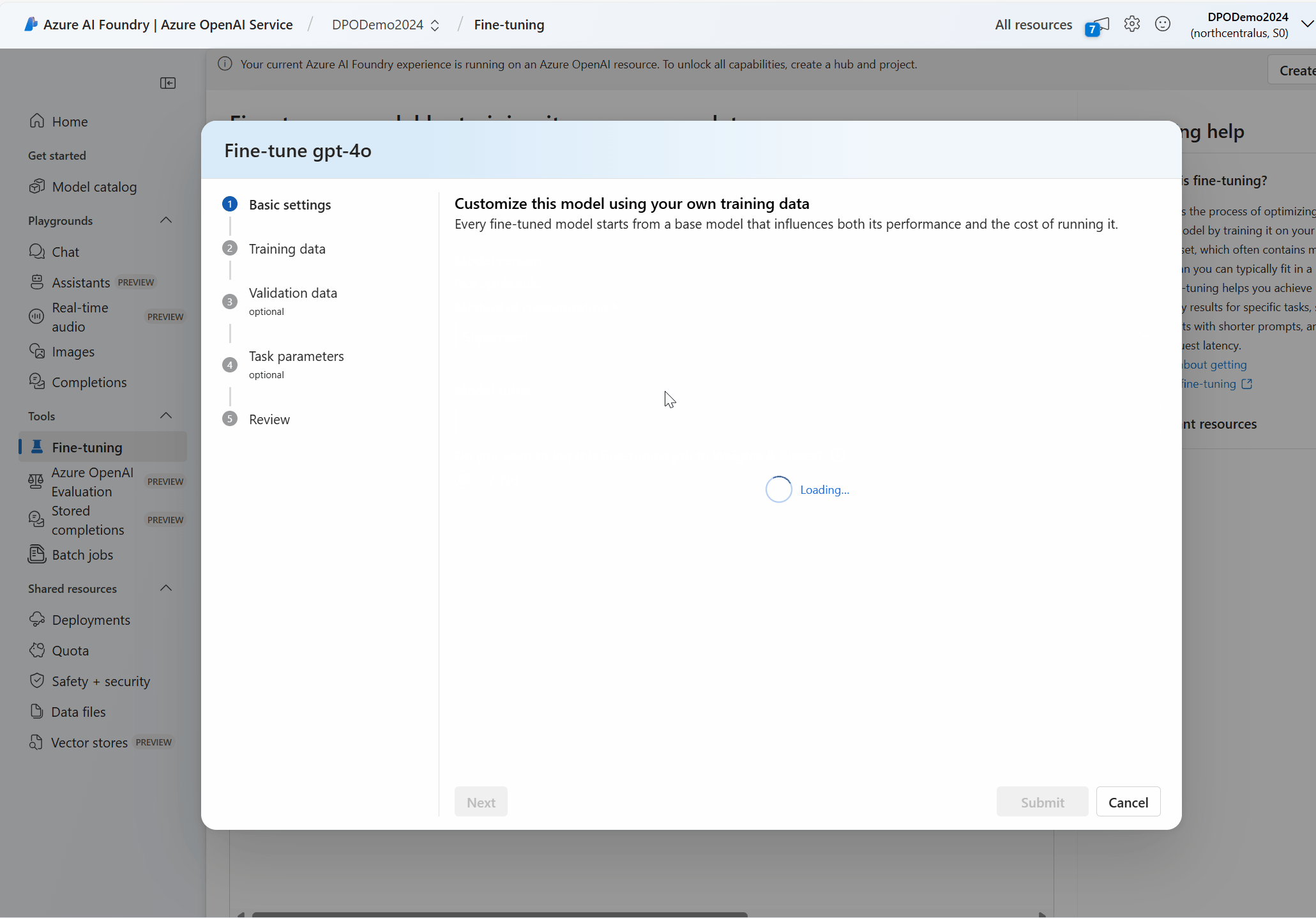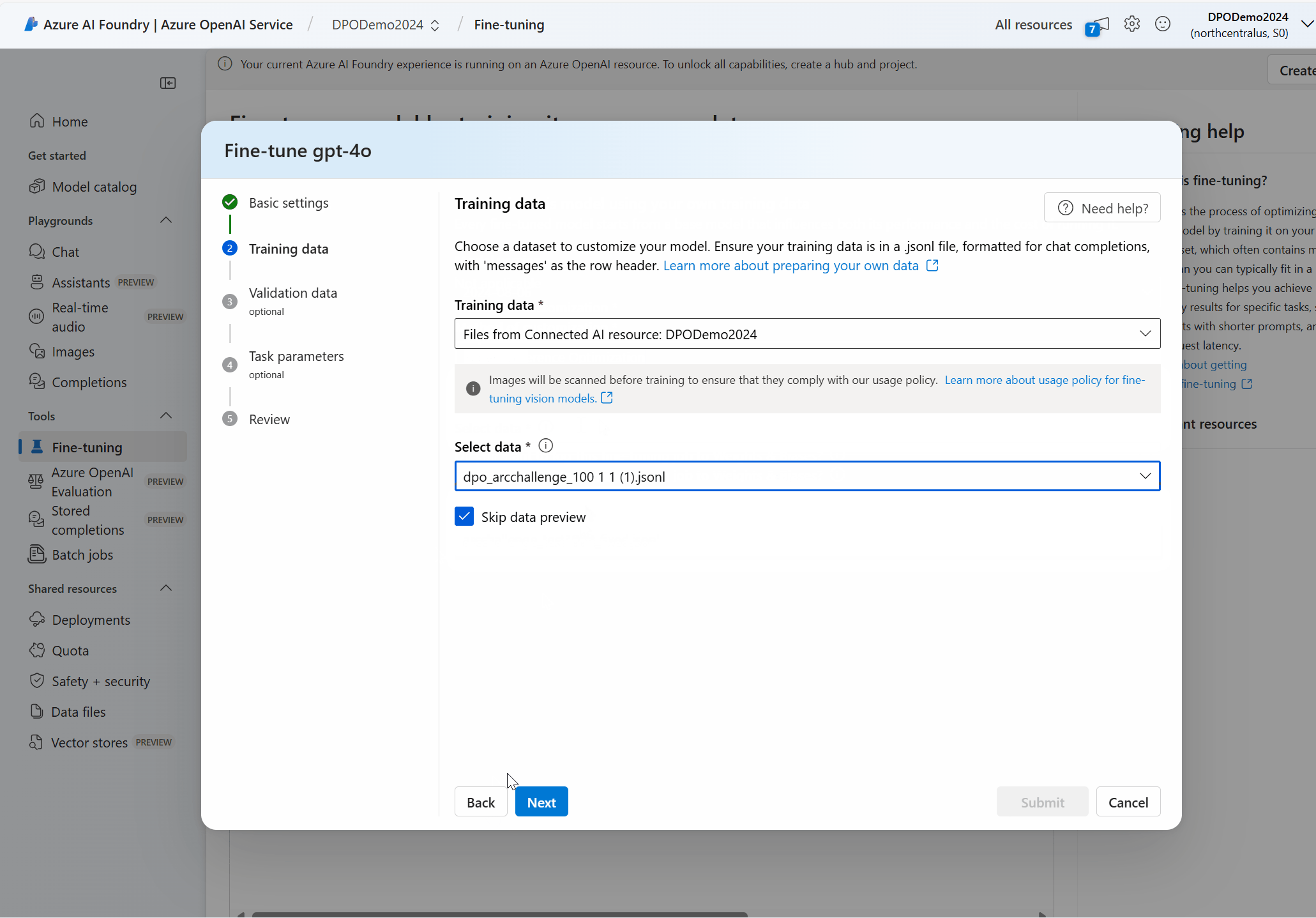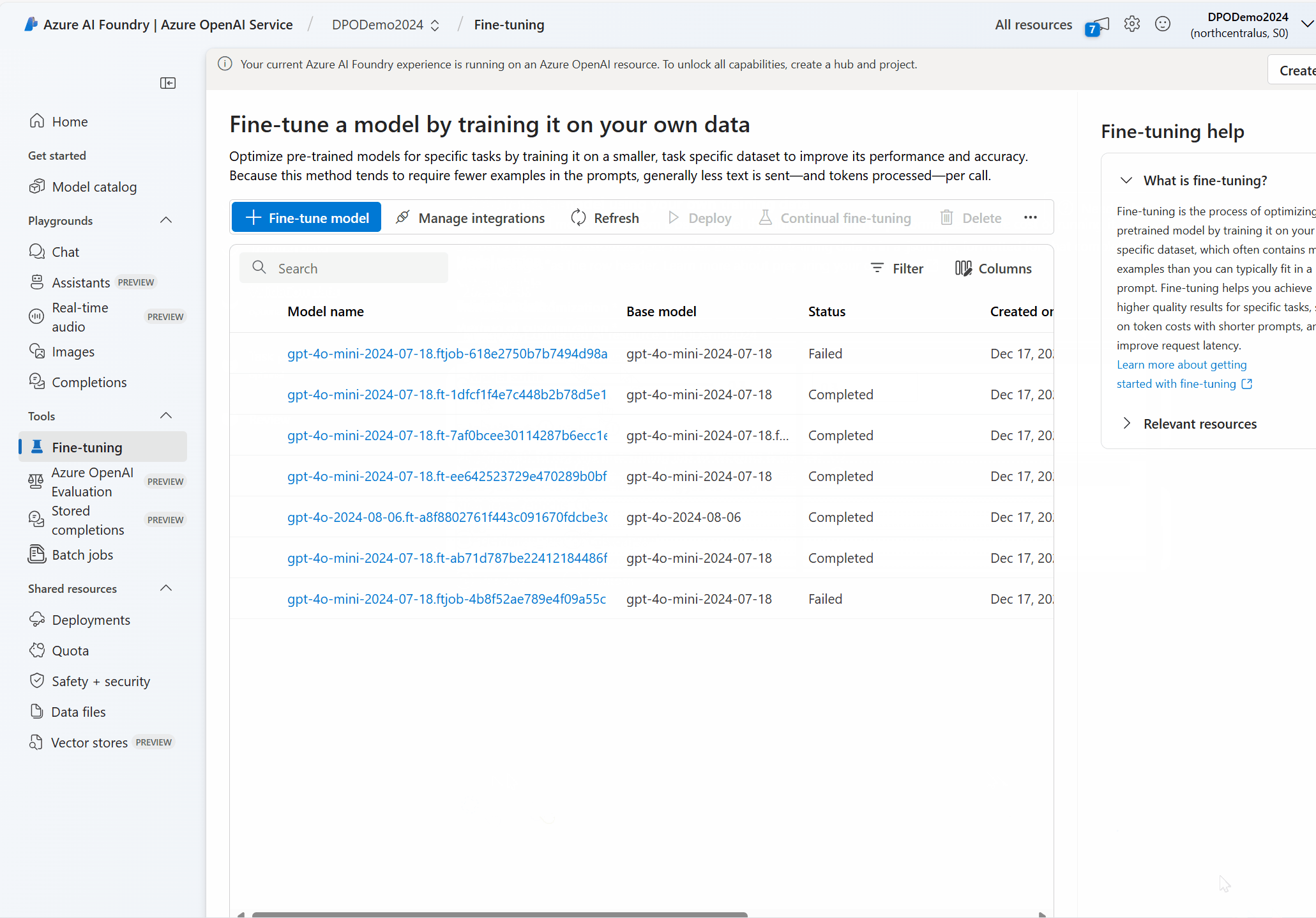
- Préparez
jsonljeux de données au format de préférence. - Sélectionnez le modèle, puis sélectionnez la méthode de personnalisation Optimisation des préférences directes.
- Chargez la formation et la validation des jeux de données. Préversion si nécessaire.
- Sélectionnez des hyperparamètres, les valeurs par défaut sont recommandées pour l’expérimentation initiale.
- Passez en revue les sélections et créez un travail de réglage précis.
Dépannage
Comment faire pour activer le réglage précis ?
Si vous souhaitez obtenir un ajustement correct, vous devez avoir le rôle Contributeur OpenAI Cognitive Services attribué. Même une personne disposant d’autorisations d’administrateur de service de haut niveau aura toujours besoin que ce compte soit défini explicitement pour accéder à l’ajustement. Pour plus d’informations, consultez les conseils relatifs au contrôle d’accès en fonction du rôle.
Pourquoi mon chargement a-t-il échoué ?
Si votre chargement de fichier échoue dans le portail Azure AI Foundry, vous pouvez afficher le message d’erreur sous fichiers de données dans le portail Azure AI Foundry. Placez votre souris sur l’emplacement indiquant « erreur » (sous la colonne d’état) et une explication de la défaillance s’affiche.

Mon modèle ajusté ne semble pas s’être amélioré
Message système manquant : vous devez fournir un message système lorsque vous ajustez ; vous devrez fournir ce même message système lorsque vous utiliserez le modèle ajusté. Si vous fournissez un message système différent, vous pouvez voir des résultats différents de ceux pour lesquels vous avez effectué un ajustement.
Données insuffisantes : alors que 10 est le minimum pour que le pipeline s’exécute, vous avez besoin de centaines ou de milliers de points de données pour enseigner une nouvelle compétence au modèle. Un nombre insuffisant de points de données risque d’entraîner un surajustement et une mauvaise généralisation. Votre modèle ajusté peut fonctionner correctement sur les données d’apprentissage, mais mal sur d’autres données, car il a mémorisé les exemples d’apprentissage au lieu d’apprendre des modèles. Pour obtenir de meilleurs résultats, envisagez de préparer un jeu de données avec des centaines ou des milliers de points de données.
Données incorrectes : un jeu de données mal organisé ou non représentatif produira un modèle de faible qualité. Votre modèle peut apprendre des modèles incorrects ou biaisés à partir de votre jeu de données. Par exemple, si vous effectuez l’apprentissage d’un chatbot pour le service clientèle, mais que vous ne lui fournissez des données d’apprentissage que pour un seul scénario (par exemple, les retours d’articles), il ne saura pas comment répondre à d’autres scénarios. Ou, si vos données d’apprentissage sont incorrectes (contiennent des réponses incorrectes), votre modèle apprendra à fournir des résultats erronés.
Réglage précis avec vision
Que faire si vos images sont ignorées
Vos images peuvent être ignorées pour les raisons suivantes :
- contient des CAPTCHAs
- contient des personnes
- contient des visages
Supprimer l’image. Pour l’instant, nous ne pouvons pas affiner les modèles avec des images contenant ces entités.
Problèmes courants
| Problème | Raison/solution |
|---|---|
| Images ignorées | Les images peuvent être ignorées pour les raisons suivantes : contient des CAPTCHAs, des personnes ou des visages. Supprimer l’image. Pour l’instant, nous ne pouvons pas affiner les modèles avec des images contenant ces entités. |
| URL Inaccessible | Vérifiez que l’URL de l’image est accessible publiquement. |
| Message trop large | Vérifiez que vos images se trouvent dans nos limites de taille de jeu de données. |
| Format d'image non valide | Vérifiez que vos images se trouvent dans notre format de jeu de données. |
Comment charger les fichiers volumineux
Vos fichiers d’entraînement peuvent être assez volumineux. Vous pouvez charger des fichiers allant jusqu’à 8 Go en plusieurs parties à l’aide de l’API Chargements par opposition à l’API Files, ce qui autorise uniquement les chargements de fichiers allant jusqu’à 512 Mo.
Réduire les coûts de formation
Si vous définissez le paramètre de détail d’une image sur faible, l’image est redimensionnée à 512 par 512 pixels et n’est représentée que par 85 jetons, quelle que soit sa taille. Cela réduira le coût de la formation.
{
"type": "image_url",
"image_url": {
"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png",
"detail": "low"
}
}
Autres considérations relatives à l’optimisation de la vision
Pour contrôler la fidélité de la compréhension des images, définissez le paramètre de détail de image_url sur low, highou auto pour chaque image. Cela affectera également le nombre de jetons par image que le modèle voit pendant le temps d’entraînement et affectera le coût de l’entraînement.
Étapes suivantes
- Explorez les fonctionnalités de réglage précis dans le didacticiel sur le réglage précis avec Azure OpenAI.
- Passez en revue la disponibilité régionale du modèle d’ajustement
- Découvrir plus d’informations sur les quotas Azure OpenAI