Stratégies pour le développement et le déploiement des bases de données (C#)
par Scott Mitchell
Lorsque vous déployez une application pilotée par les données pour la première fois, vous pouvez copier aveuglément la base de données dans l’environnement de développement dans l’environnement de production. Toutefois, l’exécution d’une copie aveugle dans les déploiements suivants remplacera toutes les données entrées dans la base de données de production. Au lieu de cela, le déploiement d’une base de données implique l’application des modifications apportées à la base de données de développement depuis le dernier déploiement sur la base de données de production. Ce tutoriel examine ces défis et propose différentes stratégies pour vous aider à chroniquer et à appliquer les modifications apportées à la base de données depuis le dernier déploiement.
Introduction
Comme indiqué dans les tutoriels précédents, le déploiement d’une application ASP.NET implique de copier le contenu pertinent de l’environnement de développement vers l’environnement de production. Le déploiement n’est pas un événement ponctuel, mais plutôt un événement qui se produit chaque fois qu’une nouvelle version du logiciel est publiée ou lorsque des bogues ou des problèmes de sécurité ont été identifiés et résolus. Lorsque vous copiez ASP.NET pages, images, fichiers JavaScript et autres fichiers de ce type dans l’environnement de production, vous n’avez pas besoin de vous soucier de la façon dont ces fichiers ont été modifiés depuis le dernier déploiement. Vous pouvez copier aveuglément le fichier en production, en remplaçant le contenu existant. Malheureusement, cette simplicité ne s’étend pas au déploiement de la base de données.
Lorsque vous déployez une application pilotée par les données pour la première fois, vous pouvez copier aveuglément la base de données dans l’environnement de développement dans l’environnement de production. Toutefois, l’exécution d’une copie aveugle dans les déploiements suivants remplacera toutes les données entrées dans la base de données de production. Au lieu de cela, le déploiement d’une base de données implique l’application des modifications apportées à la base de données de développement depuis le dernier déploiement sur la base de données de production. Ce tutoriel examine ces défis et propose différentes stratégies pour vous aider à chroniquer et à appliquer les modifications apportées à la base de données depuis le dernier déploiement.
Les défis du déploiement d’une base de données
Avant qu’une application pilotée par les données ne soit déployée pour la première fois, il n’existe qu’une seule base de données, à savoir la base de données dans l’environnement de développement. C’est pourquoi, lors du premier déploiement d’une application pilotée par les données, vous pouvez copier aveuglément la base de données dans l’environnement de développement dans l’environnement de production. Mais une fois l’application déployée, il existe deux copies de la base de données : une en développement et une en production.
Entre les déploiements, les bases de données de développement et de production peuvent devenir non synchronisées. Bien que le schéma de la base de données de production reste inchangé, le schéma de la base de données de développement peut changer à mesure que de nouvelles fonctionnalités sont ajoutées. Vous pouvez ajouter ou supprimer des colonnes, des tables, des vues ou des procédures stockées. Des données importantes peuvent également être ajoutées à la base de données de développement. De nombreuses applications pilotées par les données incluent des tables de recherche remplies de données spécifiques à l’application codées en dur qui ne sont pas modifiables par l’utilisateur. Par exemple, un site web d’enchères peut avoir une liste déroulante avec des choix qui décrivent l’état de l’article mis aux enchères : Nouveau, Comme nouveau, Bon et Juste. Plutôt que de coder en dur ces options directement dans la liste déroulante, il est généralement préférable de les placer dans une table de base de données. Si, pendant le développement, une nouvelle condition nommée Poor est ajoutée à la table, lors du déploiement de l’application, ce même enregistrement doit être ajouté à la table de recherche dans la base de données de production.
Dans l’idéal, le déploiement de la base de données implique la copie de la base de données du développement vers la production. Mais gardez à l’esprit qu’une fois que vous avez déployé l’application et repris le développement, la base de données de production est remplie avec des données réelles provenant d’utilisateurs réels. Par conséquent, si vous deviez simplement copier la base de données du développement vers la production lors du déploiement suivant, vous remplaceriez la base de données de production et perdriez ses données existantes. Le résultat net est que le déploiement de la base de données se résume à appliquer les modifications apportées à la base de données de développement depuis le dernier déploiement.
Étant donné que le déploiement d’une base de données implique l’application des modifications apportées au schéma et, éventuellement, aux données depuis le dernier déploiement, un historique des modifications doit être conservé (ou déterminé au moment du déploiement) afin que ces modifications puissent être appliquées en production. Il existe diverses techniques pour gérer et appliquer des modifications au modèle de données.
Définition de la base de référence
Pour gérer les modifications apportées à la base de données de votre application, vous devez disposer d’un état de départ, une base de référence à laquelle les modifications sont appliquées. À un extrême, l’état de départ peut être une base de données vide sans tables, vues ou procédures stockées. Une telle base de référence génère un journal des modifications volumineux, car elle doit inclure la création de toutes les tables, vues et procédures stockées de la base de données, ainsi que toutes les modifications apportées après le déploiement initial. À l’autre extrémité du spectre, vous pouvez définir la base de référence comme version de la base de données initialement déployée dans l’environnement de production. Ce choix entraîne un journal des modifications beaucoup plus petit, car il inclut uniquement les modifications apportées à la base de données après le premier déploiement. C’est l’approche que je préfère. Et bien sûr, vous pouvez choisir une approche plus en milieu de route, en définissant la ligne de base de référence comme un point entre la création initiale de la base de données et le moment où la base de données est déployée pour la première fois.
Une fois que vous avez choisi une base de référence, envisagez de générer un script SQL qui peut être exécuté pour recréer la version de base. Un tel script permet de recréer rapidement la version de base de référence de la base de données. Cette fonctionnalité est particulièrement utile dans les projets plus grands, où plusieurs développeurs peuvent travailler sur le projet ou des environnements supplémentaires, tels que des tests ou des préproductions, qui ont chacun besoin de leur propre copie de la base de données.
Il existe divers outils à votre disposition pour générer un script SQL de la version de base. À partir de SQL Server Management Studio (SSMS), vous pouvez cliquer avec le bouton droit sur la base de données, accéder au sous-menu Tâches, puis choisir l’option Générer des scripts. Cela lance l’Assistant Script, que vous pouvez demander de générer un fichier qui contient les commandes SQL pour créer des objets s de votre base de données. Une autre option est l’Assistant Publication de base de données, qui peut générer les commandes SQL pour non seulement créer le schéma de base de données, mais également les données dans les tables de base de données. L’Assistant Publication de base de données a été examiné en détail dans le didacticiel Déploiement d’une base de données . Quel que soit l’outil que vous utilisez, à la fin, vous devez disposer d’un fichier de script que vous pouvez utiliser pour recréer la version de base de référence de votre base de données, le cas échéant.
Documentation des modifications de base de données dans Prose
Le moyen le plus simple de conserver un journal des modifications apportées au modèle de données pendant la phase de développement consiste à enregistrer les modifications en prose. Par exemple, si, lors du développement d’une application déjà déployée, vous ajoutez une nouvelle colonne à la Employees table, supprimez une colonne de la Orders table et ajoutez une nouvelle table (ProductCategories), vous conservez un fichier texte ou microsoft Word document avec l’historique suivant :
| Date de modification | Modifier les détails |
|---|---|
| 2009-02-03: | Ajout de la colonne DepartmentID (int, NOT NULL) à la Employees table. Ajout d’une contrainte de clé étrangère de Departments.DepartmentID à Employees.DepartmentID. |
| 2009-02-05: | Colonne TotalWeight supprimée de la Orders table. Données déjà capturées dans les enregistrements associés OrderDetails . |
| 2009-02-12: | Création de la ProductCategories table. Il existe trois colonnes : ProductCategoryID (int, IDENTITY, NOT NULL), CategoryName (nvarchar(50), NOT NULL) et Active (bit, NOT NULL). Ajout d’une contrainte de clé primaire à ProductCategoryID, et d’une valeur par défaut de 1 à Active. |
Cette approche présente un certain nombre d’inconvénients. Pour commencer, il n’y a aucun espoir d’automatisation. Chaque fois que ces modifications doivent être appliquées à une base de données, par exemple lors du déploiement de l’application, un développeur doit implémenter manuellement chaque modification, une par une. En outre, si vous devez reconstruire une version particulière de la base de données à partir de la base de référence à l’aide du journal des modifications, cela prend de plus en plus de temps à mesure que la taille du journal augmente. Un autre inconvénient de cette méthode est que la clarté et le niveau de détail de chaque entrée de journal des modifications sont laissés à la personne qui enregistre la modification. Dans une équipe avec plusieurs développeurs, certains peuvent créer des entrées plus détaillées, plus lisibles ou plus précises que d’autres. En outre, les fautes de frappe et d’autres erreurs de saisie de données liées à l’homme sont possibles.
Le principal avantage de documenter les changements de base de données en prose est la simplicité. Vous n’avez pas besoin de connaître la syntaxe SQL pour créer et modifier des objets de base de données. Au lieu de cela, vous pouvez enregistrer les modifications dans prose et les implémenter via l’interface utilisateur graphique de SQL Server Management Studio.
La maintenance de votre journal des modifications en prose n’est, certes, pas très sophistiquée et ne fonctionne pas bien avec certains projets, tels que ceux qui sont de grande portée, qui ont des modifications fréquentes dans le modèle de données ou qui impliquent plusieurs développeurs. Mais j’ai vu que cette approche fonctionne assez bien dans de petits projets unimaniques qui n’ont que des modifications occasionnelles dans le modèle de données et où le développeur solo n’a pas une solide expérience dans la syntaxe SQL pour la création et la modification d’objets de base de données.
Notes
Bien que les informations contenues dans le journal des modifications soient, techniquement, nécessaires uniquement jusqu’au moment du déploiement, je vous recommande de conserver un historique des modifications. Mais plutôt que de conserver un fichier journal des modifications unique et toujours croissant, envisagez d’avoir un fichier journal des modifications différent pour chaque version de base de données. En règle générale, vous souhaiterez versionner la base de données chaque fois qu’elle est déployée. En conservant un journal des journaux des modifications, vous pouvez, à partir de la base de référence, recréer n’importe quelle version de base de données en exécutant les scripts de journal des modifications à partir de la version 1 et en continuant jusqu’à atteindre la version que vous devez recréer.
Enregistrement des instructions de modification SQL
Le principal inconvénient de la maintenance du journal des modifications en prose est le manque d’automatisation. Dans l’idéal, l’implémentation des modifications apportées à la base de données de production au moment du déploiement serait aussi simple que de cliquer sur un bouton pour exécuter un script plutôt que d’avoir à exécuter manuellement une liste d’instructions. Une telle automatisation est possible en conservant un journal des modifications qui contient les commandes SQL utilisées pour modifier le modèle de données.
La syntaxe SQL comprend un certain nombre d’instructions permettant de créer et de modifier différents objets de base de données. Par exemple, l’instruction CREATE TABLE, lorsqu’elle est exécutée, crée une table avec les colonnes et contraintes spécifiées. L’instruction ALTER TABLE modifie une table existante, en ajoutant, en supprimant ou en modifiant ses colonnes ou contraintes. Il existe également des instructions pour créer, modifier et supprimer des index, des vues, des fonctions définies par l’utilisateur, des procédures stockées, des déclencheurs et d’autres objets de base de données.
Pour revenir à notre exemple précédent, image que lors du développement d’une application déjà déployée, vous ajoutez une nouvelle colonne à la Employees table, supprimez une colonne de la Orders table et ajoutez une nouvelle table (ProductCategories). De telles actions entraîneraient un fichier journal des modifications avec les commandes SQL suivantes :
-- Add the DepartmentID column
ALTER TABLE [Employees] ADD [DepartmentID]
int NOT NULL
-- Add a foreign key constraint between Departments.DepartmentID and Employees.DepartmentID
ALTER TABLE [Employees] ADD
CONSTRAINT [FK_Departments_DepartmentID]
FOREIGN
KEY ([DepartmentID])
REFERENCES
[Departments] ([DepartmentID])
-- Remove TotalWeight column from Orders
ALTER TABLE [Orders] DROP COLUMN
[TotalWeight]
-- Create the ProductCategories table
CREATE TABLE [ProductCategories]
(
[ProductCategoryID]
int IDENTITY(1,1) NOT NULL,
[CategoryName]
nvarchar(50) NOT NULL,
[Active]
bit NOT NULL CONSTRAINT [DF_ProductCategories_Active] DEFAULT
((1)),
CONSTRAINT
[PK_ProductCategories] PRIMARY KEY CLUSTERED ( [ProductCategoryID])
)
L’envoi push de ces modifications à la base de données de production au moment du déploiement est une opération en un clic : ouvrez SQL Server Management Studio, connectez-vous à votre base de données de production, ouvrez une fenêtre Nouvelle requête, collez le contenu du journal des modifications, puis cliquez sur Exécuter pour exécuter le script.
Utilisation d’un outil de comparaison pour synchroniser les modèles de données
La documentation des modifications apportées à la base de données en prose est facile, mais l’implémentation des modifications nécessite qu’un développeur apporte chaque modification à la base de données de production une par une ; La documentation des commandes SQL modifiées rend l’implémentation de ces modifications sur la base de données de production aussi simple et rapide que de cliquer sur un bouton, mais nécessite l’apprentissage et la maîtrise des instructions SQL et de la syntaxe pour créer et modifier des objets de base de données. Les outils de comparaison de bases de données tirent le meilleur des deux approches et ignorent le pire.
Un outil de comparaison de bases de données compare le schéma ou les données de deux bases de données et affiche un rapport récapitulatif montrant comment les bases de données diffèrent. Ensuite, en cliquant sur un bouton, vous pouvez générer les commandes SQL pour synchroniser un ou plusieurs objets de base de données. En résumé, vous pouvez utiliser un outil de comparaison de bases de données pour comparer les bases de données de développement et de production au moment du déploiement, en générant un fichier qui contient les commandes SQL qui, une fois exécutées, appliqueront les modifications au schéma de la base de données de production afin qu’il reflète le schéma de la base de données de développement.
Il existe une variété d’outils de comparaison de bases de données tiers proposés par de nombreux fournisseurs différents. Sql Compare, par Red Gate Software, en est un exemple. Passons en revue le processus d’utilisation de SQL Compare pour comparer et synchroniser les schémas des bases de données de développement et de production.
Notes
Au moment de la rédaction de cet article, la version actuelle de SQL Compare était la version 7.1, l’édition Standard coûtant 395 $. Vous pouvez suivre la procédure en téléchargeant un essai gratuit de 14 jours.
Lorsque la comparaison SQL démarre, la boîte de dialogue Projets de comparaison s’ouvre, affichant les projets de comparaison SQL enregistrés. Créez un projet. Cela lance l’Assistant Configuration de projet, qui demande des informations sur les bases de données à comparer (voir la figure 1). Entrez les informations relatives aux bases de données de l’environnement de développement et de production.
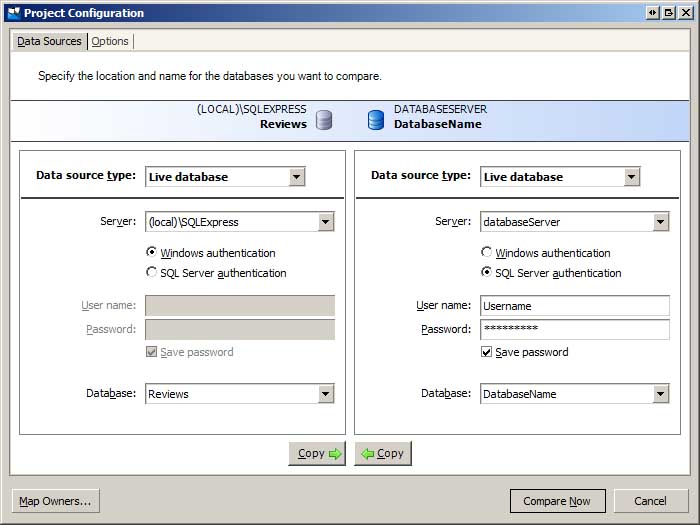
Figure 1 : Comparer les bases de données de développement et de production (cliquer pour afficher l’image en taille réelle)
{kind=link}
Notes
Si votre base de données d’environnement de développement est un fichier de base de données SQL Express Edition dans le App_Data dossier de votre site web, vous devez inscrire la base de données dans le serveur de base de données SQL Server Express afin de la sélectionner dans la boîte de dialogue illustrée à la figure 1. Le moyen le plus simple consiste à ouvrir SQL Server Management Studio (SSMS), à se connecter au serveur de base de données SQL Server Express et à attacher la base de données. Si SSMS n’est pas installé sur votre ordinateur, vous pouvez télécharger et installer le SQL Server Management Studio gratuit.
En plus de sélectionner les bases de données à comparer, vous pouvez également spécifier divers paramètres de comparaison à partir de l’onglet Options. Une option que vous pouvez activer est « Ignorer les noms de contrainte et d’index ». Rappelez-vous que dans le tutoriel précédent, nous avons ajouté les objets de base de données des services d’application aux bases de données de développement et de production. Si vous avez utilisé l’outil aspnet_regsql.exe pour créer ces objets sur la base de données de production, vous constaterez que les noms de clé primaire et de contrainte unique diffèrent entre les bases de données de développement et de production. Par conséquent, SQL Compare marque toutes les tables des services d’application comme étant différentes. Vous pouvez laisser la case « Ignorer les noms de contrainte et d’index » décochée et synchroniser les noms de contrainte, ou demander à SQL Compare d’ignorer ces différences.
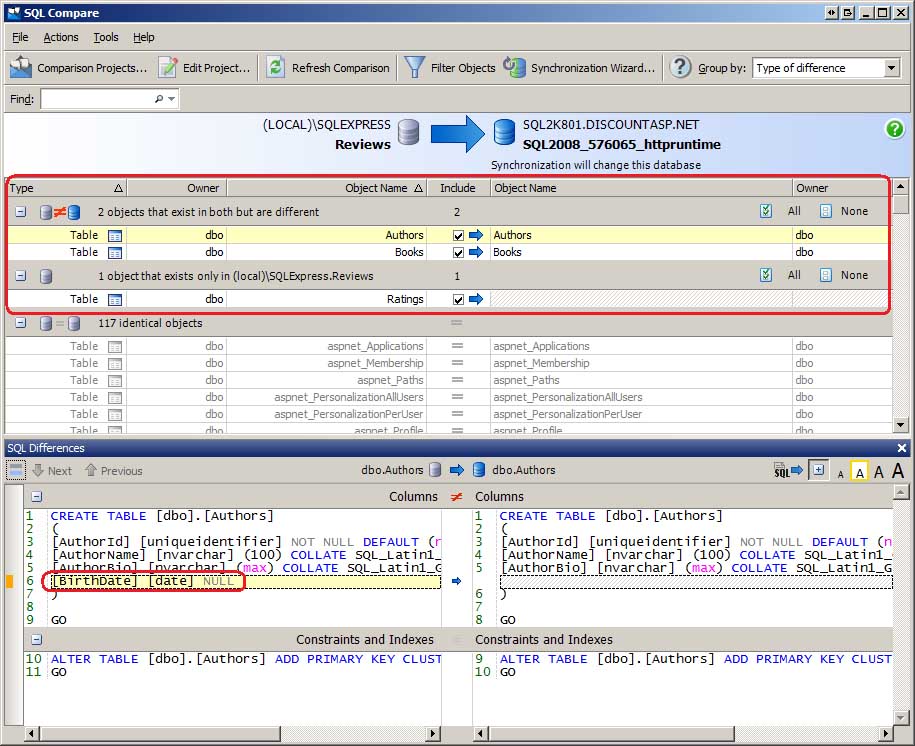
Après avoir sélectionné les bases de données à comparer (et passé en revue les options de comparaison), cliquez sur le bouton Comparer maintenant pour commencer la comparaison. Au cours des quelques secondes suivantes, SQL Compare examine les schémas des deux bases de données et génère un rapport sur leur différence. J’ai apporté des modifications à la base de données de développement pour montrer comment ces différences sont notées dans l’interface SQL Compare. Comme le montre la figure 2, j’ai ajouté une BirthDate colonne à la Authors table, supprimé la ISBN colonne de la Books table et ajouté une nouvelle table, Ratings, qui est destinée à permettre aux utilisateurs qui visitent le site d’évaluer les livres révisés.
Notes
Les modifications apportées au modèle de données dans ce didacticiel ont été effectuées pour illustrer l’utilisation d’un outil de comparaison de base de données. Vous ne trouverez pas ces modifications dans la base de données dans les prochains tutoriels.
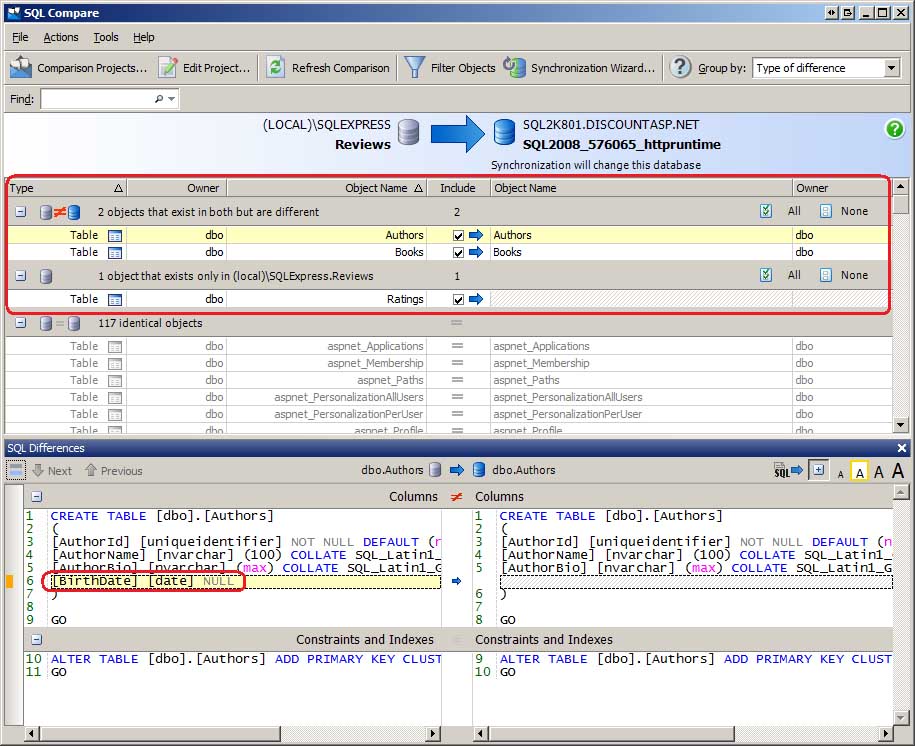
Figure 2 : Comparaison SQL Listes différences entre les bases de données de développement et de production (cliquez pour afficher l’image en taille réelle)
{kind=link}
SQL Compare décompose les objets de base de données en groupes, vous montrant rapidement quels objets existent dans les deux bases de données, mais sont différents, quels objets existent dans une base de données, mais pas l’autre, et quels objets sont identiques. Comme vous pouvez le voir, il existe deux objets qui existent dans les deux bases de données, mais qui sont différents : la Authors table, à laquelle une colonne a été ajoutée, et la Books table, qui en avait une supprimée. Il existe un objet qui existe uniquement dans la base de données de développement, à savoir la table nouvellement créée Ratings . Et il existe 117 objets identiques dans les deux bases de données.
La sélection d’un objet de base de données affiche la fenêtre Différences SQL, qui montre comment ces objets diffèrent. La fenêtre Différences SQL, affichée en bas de la figure 2, met en évidence que la Authors table de la base de données de développement contient la BirthDate colonne , qui est introuvable dans la Authors table de la base de données de production.
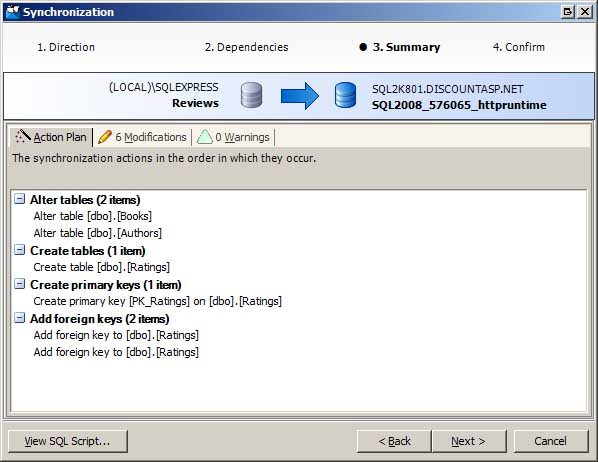
Après avoir examiné les différences et sélectionné les objets à synchroniser, l’étape suivante consiste à générer les commandes SQL nécessaires pour mettre à jour le schéma de la base de données de production pour qu’il corresponde à la base de données de développement. Pour ce faire, l’Assistant Synchronisation s’effectue. L’Assistant Synchronisation confirme les objets à synchroniser et résume le plan d’action (voir la figure 3). Vous pouvez synchroniser les bases de données immédiatement ou générer un script avec les commandes SQL qui peuvent être exécutées à votre guise.
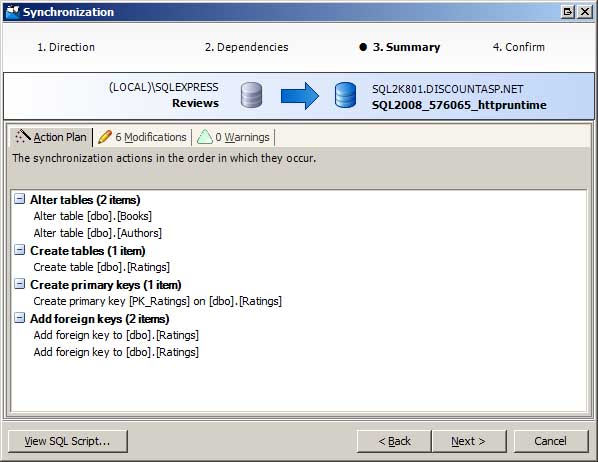
Figure 3 : Utiliser l’Assistant Synchronisation pour synchroniser vos schémas de bases de données (cliquez pour afficher l’image en taille réelle)
{kind=link}
Les outils de comparaison de bases de données comme La comparaison sql de Red Gate Software permettent d’appliquer les modifications au schéma de base de données de développement à la base de données de production aussi facilement que pointer et cliquer.
Notes
SQL Compare compare et synchronise deux schémas de bases de données. Malheureusement, il ne compare pas et ne synchronise pas les données au sein de deux tables de bases de données. Red Gate Software propose un produit nommé SQL Data Compare qui compare et synchronise les données entre deux bases de données, mais il s’agit d’un produit distinct de SQL Compare et coûte encore 395 $.
Mise hors connexion de l’application pendant le déploiement
Comme nous l’avons vu tout au long de ces tutoriels, le déploiement est un processus qui implique plusieurs étapes : copie des pages ASP.NET, des pages master, des fichiers CSS, des fichiers JavaScript, des images et d’autres contenus nécessaires de l’environnement de développement vers l’environnement de production, la copie des informations de configuration spécifiques à l’environnement de production, si nécessaire, et l’application des modifications apportées au modèle de données depuis le dernier déploiement. Selon le nombre de fichiers et la complexité des modifications apportées à votre base de données, ces étapes peuvent prendre entre quelques secondes et plusieurs minutes. Pendant cette fenêtre, l’application web est en flux et les utilisateurs qui visitent le site peuvent rencontrer des erreurs ou un comportement inattendu.
Lors du déploiement d’un site web, il est préférable de mettre l’application web « hors connexion » jusqu’à ce que le déploiement soit terminé. Le fait de mettre l’application hors connexion (et de la réactiver une fois le processus de déploiement terminé) est aussi simple que de charger un fichier, puis de le supprimer. À compter de ASP.NET 2.0, la simple présence d’un fichier nommé app_offline.htm dans le répertoire racine de l’application met tout le site web hors connexion. Toute demande adressée à une page de ASP.NET sur ce site est automatiquement répondue avec le contenu du app_offline.htm fichier. Une fois ce fichier supprimé, l’application revient en ligne.
La mise hors connexion d’une application pendant le déploiement est donc aussi simple que de charger un app_offline.htm fichier dans le répertoire racine de l’environnement de production avant de commencer le processus de déploiement, puis de le supprimer (ou de le renommer en autre chose) une fois le déploiement terminé. Pour plus d’informations sur cette technique, consultez l’article de John Peterson, Mise hors connexion d’une application ASP.NET.
Résumé
Le main défi dans le déploiement d’une application pilotée par les données se concentre sur le déploiement de la base de données. Étant donné qu’il existe deux versions de la base de données : l’une dans l’environnement de développement et l’autre dans l’environnement de production, ces deux schémas de bases de données peuvent devenir désynchronisées à mesure que de nouvelles fonctionnalités sont ajoutées au développement. De plus, étant donné que la base de données de production est remplie de données réelles provenant d’utilisateurs réels, vous ne pouvez pas remplacer la base de données de production par la base de données de développement modifiée comme vous le pouvez lors du déploiement des fichiers qui composent l’application (les pages ASP.NET, les fichiers image, etc.). Au lieu de cela, le déploiement d’une base de données implique l’implémentation de l’ensemble précis des modifications apportées à la base de données de développement sur la base de données de production depuis le dernier déploiement.
Ce tutoriel a examiné trois techniques de gestion et d’application d’un journal des modifications de base de données. L’approche la plus simple consiste à enregistrer les changements dans la prose. Bien que cette tactique rende l’implémentation de ces modifications sur la base de données de production un processus manuel, elle ne nécessite pas la connaissance des commandes SQL pour créer et modifier des objets de base de données. Une approche plus sophistiquée, et beaucoup plus acceptable dans les projets de plus grande envergure ou avec plusieurs développeurs, consiste à enregistrer les modifications sous la forme d’une série de commandes SQL. Cela accélère considérablement le déploiement de ces modifications dans la base de données cible. Le meilleur des deux approches peut être obtenu à l’aide d’un outil de comparaison de base de données, tel que Red Gate Software SQL Compare.
Ce tutoriel conclut notre focus sur le déploiement d’une application pilotée par les données. L’ensemble suivant de tutoriels examine comment répondre aux erreurs dans l’environnement de production. Nous allons voir comment afficher une page d’erreur conviviale plutôt que l’écran jaune de la mort. Et nous verrons comment journaliser les détails de l’erreur et comment vous avertir quand de telles erreurs se produisent.
Bonne programmation !