Battle Simulation: size vs. smarts (part 3)
How much stupidity does it take to prevail over intelligence?
I previously explored simulating Real-time-strategy battles with IronPython. (Part 1, Part 2). We saw that even with very simple rules, different strategies are better than others. If two armies of equal size attack each other, a good strategy clobbers a bad one.
In this entry, I use Python to look at the flip question: how much larger does the dumb army need to be to prevail over the smart one?
This answer leads to another practical tidbit, listed in the conclusion section.
Background:
See Part 1 for the code snippets and the rules.
The only choice that the armies have is for each unit within an army to decide which enemy unit it's going to attack each turn. The 3 strategies we've seen so far are:
- Attack-weakest: attack the weakest target each turn
- Sticky-random: pick a random target and attack it until you kill it, and then pick a new random target
- Attack-random: attack a random target each turn.
Part 2 showed that attack-weakest appears to be hands down the best over the other two, and attack-random is the worst. Of course, this is just 3 strategies out of a possible infinite, and there's likely a better strategy even than attack-weakest. Here's a graph of victory margin for each of the 3 matchups for army sizes up to 20 units per side. I'll refer to 'attack-weakest' as the 'smart' strategy, and 'attack-random' as the 'dumb' one.
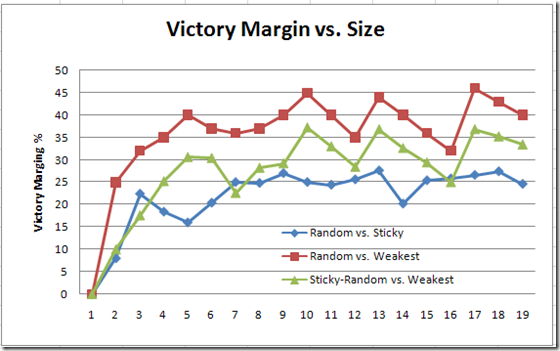{kind=link}
Recall the code snippets from before:
- Make(n) makes an army of n units that all use the attack-weakest opponent strategy. MakeR(n) makes an army of n units that all use the attack-random strategy. These are just convenience functions to simplifying writing queries.
- Battle(x,y) fights the two armies x and y to the death, and then returns a statistics structure. The 'victory' property is the victory margin between -100% if x wins perfectly and 100% if y wins perfectly, and 0% if a tie.
- Battle(MakeR(n), Make(n)).victory fights a battle between a dumb army of size n and a smart army of size n, and then returns the victory margin. We saw previously that the smart army generally wins.
Here's the Python snippet to answer the question. favg() runs the lambda function a number of times to get an average. You can see that it runs the battle in a loop, gradually increasing MakeR's size until it finally wins. It records results: for each initial size between min and max, record the size advantage MakeR needed to finally win.
The code:
def ComputeSize(size = 10, nTimes = 20):
advantage = 0
l=[]
while True:
print '*******************************'
print 'ad', advantage, 'size', size
v = favg(nTimes, lambda: Battle(MakeR(size+advantage), Make(size)).victory)
l.append((advantage, v))
if v < 0:
break
advantage += 1
return l
def Compute(min, max, nTimes = 20):
r = { }
for size in range(min, max):
r[size] = ComputeSize(size)
return r
Note this code has a simplifying assumption that the smart army will always win. Our previous results show that to be a safe and cogent assumption. Fortunately, we'll know if the dumb army wins (we'll see a size advantages of just 1), in which case we can go back and add the additional complexity to deal with the situation.
The key thing here is that our queries are now beyond the simple Sum/Avg/Select/Where and have become full-fledged algorithms.
The results:
Here's the raw dump of some of the results of running Compute() with nTimes=3 (average across 3 runs). Each row is for a given base size (starting at 5 and shown up to 19), and the row is a list of tuples (size advantage, victory margin) where advantage ranges from 0 (tied) to however large it takes for the dumb army to beat the smart army.
|
So when a smart army of size 5 fights a dumb army of size 5, the smart one wins with a 40% victory margin. When it's 5-on-6, the smart one only wins by 15%. When it's 5-on-7, the dumb one finally prevails.
To see how much advantage the dumb army needs per size:
for size in r: print size, len(r[size])
Here's a graph of the results, showing size vs. len(r[size]). The data there looks somewhat random.
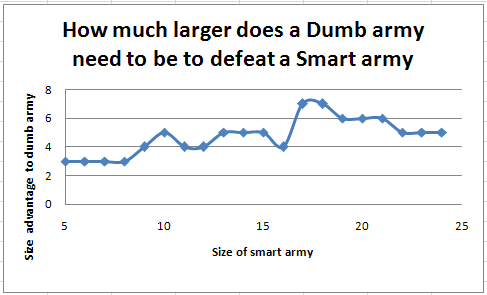
The advantage line gradually trends up, suggesting that with larger battles, the dumb army needs a larger advantage to win.
Random Noise or Numerical Conspiracy?
Why is the graph above so random, as opposed to a more monotonic changing curve? Is that just random noise. Afterall, we only averaged it over 3 runs. Some of the previous graphs (like victory margin in attack-random vs. attack-weakest) that appeared to be random were actually very deterministic. (This was Quiz #2 from Part 1)
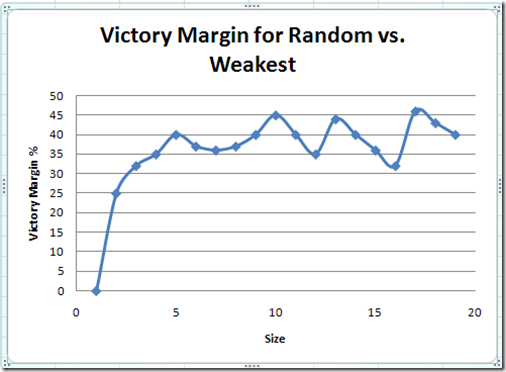{kind=link}
I ran the above with an average over 30 runs and still got nearly exactly the same data. So despite having results built on a random number generator, all that apparently random chaos is actually very deterministic. (Quiz #2 again ... why?)
Playing with the data
To put it in more context, we can show the sizes as a ratio. So here's (Dumb-size / Smart Size) vs smart-size, for each of the cases that the dumb army wins. Since the dumb-army is larger, the ratio is always greater than 1.
I did the ratio in Excel. I already had the data in Excel for the graphing, and Excel is very easy for this sort of primitive manipulation. I see that as a case of using the best tool for the job. This would have been easy to do with Python too:
for x in r:
a=len(r[x])
print x, float(a+x)/x
And I'd probably do more complex manipulation with Python instead of Excel.
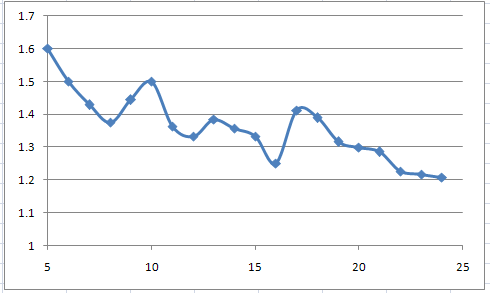
The results here are still pretty random without a clear trend line. This kind of looks like it's approaching an asymptote. If that's true, then it would mean that the smart army loses its advantage in larger scale battles. However, I think that would be a premature conclusion. Afterall, it we cut the size window at 10, 13, or 17 instead of 25, we'd jump to very different conclusions.
To make a good conclusion here, we'd need enough data to see the trend line stabilize.
Conclusion:
- We can see that the dumb army can prevail over the smart one if it's 50% larger. That's actually a useful piece of data, because when the armies are the same size, the smart one wins with a victory margin around 40% and all the smart units survive.
- The smart strategy is good at maintaining low death rates against a similarly sized dumb army, but it is not going to beat overwhelming numbers (even a dumb army 2x its size).
- Practical tidbit #3: Having an extra 50% units would let you just throw an army into battle without having to micromanage it and likely win. This can be useful in an arcade situation where you don't have the time to ensure your units are behaving optimally intelligent. (contrast this to Pracitcal tidbit #1: micromanaging gets better results)
- We're left with some strange outstanding questions. Why does a random attack strategy produce such a deterministic curve? Is there a trendline?
The good news is that this was is still pretty easy to model and query in Python. Next up, I'll try using Python to explore more scenarios in search of a trendline and answers to the outstanding questions. Stay tuned...
Comments
Anonymous
January 16, 2008
Well, I'm rather tired, but I'd guess because of the RNG using the same seed? I doubt it, though.Anonymous
January 17, 2008
TraumaPony - It's a good guess, but I don't think it's the seed. When I first saw it, that was my concern too. So I looked at the more verbose output, I can see each run is actually different. The attack-random AI really does attack different enemies each time. It's just that on the large scale, the random behavior actually converges to something determinstic. But another way to reason it is: (the code is at http://blogs.msdn.com/jmstall/attachment/6957037.ashx)
- The runs are all being done sequentially in the same session ( for favg, it basically just executes the lambda expression in a for loop)
- All runs use the same single global random generator in the file (g_rand) So each run's random generator is using a seed that was already changed by the previous run.
- Anonymous
February 18, 2008
The comment has been removed