Battle Simulations with Iron Python (part 2)
I previously wrote about modeling RTS battles with IronPython. In this entry I'll explore a new policy for attacking that was suggested on the last thread.
Previously, I compared 2 policies for picking which opponent to attack:
1. Attack the weakest enemy.
2. Attack a random enemy.
Each turn (eg, after each round of shooting each other), units reapplied their policy to pick a new target.
Timothy Fries asked what would happen if units kept their targets until they killed the target, rather than picking a new target each turn. I'll call that a "sticky" policy, which can serve as a modifier to another policy. So a Sticky-random (SR) policy is a policy that randomly picks a target and attacks it until it destroys it, and then randomly picks the next target.
Code changes
It was very simple to adjust the python scripts for the new policy:
Our Unit class's PickTarget(self, army) function gets changed from:
def PickTarget(self, army):
guy = self.fpAttackPolicy(army)
assert(guy.IsAlive())
return guy
To:
def PickTarget(self, army):
if (self.stickyTarget and self.target and self.target.IsAlive()):
return self.target
# use policy to pick a target.
self.target = self.fpAttackPolicy(army)
assert(self.target.IsAlive())
return self.target
So now we remember the target in a member field and only pick a new target one the old target is dead. The sticky policy is only applied if stickyTarget is true.
And then we add some new convenient builder functions (in addition to Make(), and MakeR()) to easily create armies with the Sticky-Random policy:
# set the army policy to "sticky-attack" (don't pick a new target until it destroys the current one)
def Sticky(army):
for x in army:
x.stickyTarget = True
return army
def MakeSR(size):
return Sticky(MakeR(size))
Show it's fair
Let's look at two equally sized armies applying a stick-random policy fighting each other. As with random, we'd expect the battles to average out as a tie.
This gets a vector of victory margins from 20 battles of 5-on-5. l1 is using an attack random policy (MakeR), l2 is using a sticky-random policy (MakeSR).
l1 = frun(20, lambda: Battle(MakeR(5), MakeR(5)).victory)
l2 = frun(20, lambda: Battle(MakeSR(5), MakeSR(5)).victory)
Recall that the victory margin in Battle(x,y) is between -100% (army x wins with no damage) to +100% (army y wins with no damage).
Last time, we saw that the random policy is basically a tie with an average victory margin of 0% and a standard deviation under 5.
Here's a python function to compute standard deviation:
# compute standard deviation against 0
def sd(l):
import math
return math.sqrt(sum([x*x for x in l])/len(l))
We can look at the average and standard deviation of each run:
>>> avg(l1)
-1.2
>>> avg(l2)
3.75
>>> sd(l1)
4.69041575982
>>> sd(l2)
16.7630546142
In both cases, the averages come close to 0. However, sticky-random has a significantly larger standard deviation than random (16 vs. 4). In other words, overall stick-random averages out to a tie, but whoever does win, wins by a bigger margin than in an attack-random policy.
Quiz #1: Explain why sticky-random has a wide victory-margin spread than just random.
Random vs. Sticky-Random
We can see how an army using Random policy fares vs. an army using the Stick-Random policy.
def RvsSR(nMax, nTimes=1):
return [ favg(nTimes, lambda : Battle(MakeR(i),MakeSR(i)).victory) for i in range(1,nMax+1)]
This is very similar to the matchups used last time, but we use MakeSR() instead of Make() or MakeR() to get an army of the appropriate policy.
Here's a chart showing the victory margin of all 3 matchups (R vs SR, R vs. W, SR vs w). In all cases of X vs Y, Y is the winning army and the graph shows Y's victory margin over X:
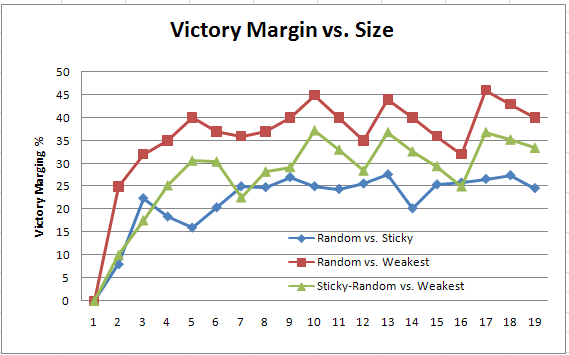
We can see that Attack-Weakest is the best policy. It beats the other two, and it even beats Random by a larger margin than Sticky-random does (the red line is consistently higher than the blue line).
So Sticky-random is an intermediate policy: it's better than just attack-random, but not as good as ganging up on the weakest.
Conclusion
A key takeaway was that with Python, it was very easy to both a) adjust the object model and b) run a wide variety of queries. (In fact, I found it harder to make the charts with Excel 2007 then I did to generate the data with Python)
We can objectively rank the attack policies from best to worst:
- Attack-weakest: attack the weakest target each turn
- Sticky-random: pick a random target and attack it until you kill it, and then pick a new random target
- Attack-random: attack a random target each turn.
Comments
Anonymous
January 12, 2008
Hi, Nice to see the blogs/articles coming up with Dynamic Languages. It would be great and helpful, if you start blogging about IronRuby and its implementation with Visual studio express editions. So far, i have not seen a single tutorial on IronRuby. ThanksAnonymous
January 14, 2008
Parag - You're in luck. John Lam, who is a key player on IronRuby, has an excellent blog at http://www.iunknown.com. Check it out!