Migrer un magasin HDFS local vers Stockage Azure avec Azure Data Box
Vous pouvez migrer des données d’un magasin HDFS local de votre cluster Hadoop vers Azure Storage (stockage blob ou Data Lake Storage) à l’aide d’un appareil Data Box. Vous pouvez choisir entre les appareils Data Box Disk, Data Box de 80 To ou Data Box Heavy de 770 To.
Cet article vous aide à effectuer les étapes suivantes :
- Se préparer à la migration de vos données
- Copier vos données sur un appareil Data Box Disk, Data Box ou Data Box Heavy
- Retourner l’appareil à Microsoft
- Appliquez des autorisations d'accès aux fichiers et aux répertoires (Data Lake Storage uniquement)
Prérequis
Vous avez besoin des éléments suivants pour finaliser la migration.
Un compte de stockage Azure.
Un cluster Hadoop en local contenant vos données source.
Une Azure Data Box.
Branchez et connectez votre Data Box ou Data Box Heavy à un réseau local.
Si vous êtes prêt, commençons.
Copier vos données vers une Azure Data Box
Si vos données tiennent dans une seule Data Box, copiez les données dans la Data Box.
Si la taille de vos données dépasse la capacité de la Data Box, utilisez la procédure optionnelle pour répartir les données entre plusieurs Data Box, puis effectuez cette étape.
Pour copier les données de votre magasin HDFS local vers une Data Box, vous devez configurer quelques paramètres, puis lancer l’outil DistCp.
Suivez ces étapes pour copier des données via les API REST du stockage Blob/Object vers votre Data Box. L’interface de l’API REST fait apparaître l’appareil comme un magasin HDFS sur votre cluster.
Avant de copier les données via REST, identifiez les primitives de sécurité et de connexion pour accéder à l'interface REST sur la Data Box ou la Data Box Heavy. Connectez-vous à l'interface web locale de la Data Box, puis accédez à page Connexion et copie. Dans le compte de stockage Azure pour votre appareil, sous Paramètres d’accès, recherchez puis sélectionnez REST.
Dans la boîte de dialogue Accéder au compte de stockage et charger des données, copiez le point de terminaison du service BLOB et la clé du compte de stockage. Dans le point de terminaison du service blob, supprimez la partie
https://et la barre oblique finale.Dans ce cas, le point de terminaison est :
https://mystorageaccount.blob.mydataboxno.microsoftdatabox.com/. La partie hôte de l’URI que vous utilisez est :mystorageaccount.blob.mydataboxno.microsoftdatabox.com. Pour obtenir un exemple, consultez la section Se connecter à REST via http.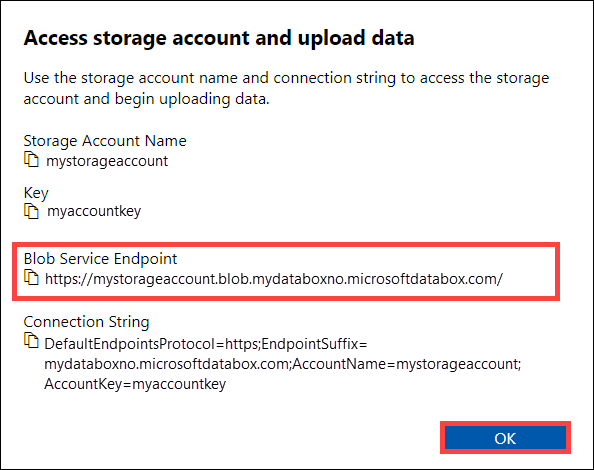
Ajoutez le point de terminaison et l'adresse IP du nœud Data Box ou Data Box Heavy à
/etc/hostssur chaque nœud.10.128.5.42 mystorageaccount.blob.mydataboxno.microsoftdatabox.comSi vous utilisez un autre mécanisme pour DNS, vérifiez que le point de terminaison Data Box peut être résolu.
Définissez la variable d’environnement
azjarssur l’emplacement des fichiers jarhadoop-azureetazure-storage. Vous trouverez ces fichiers dans le répertoire d'installation de Hadoop.Pour déterminer si ces fichiers existent, utilisez la commande suivante :
ls -l $<hadoop_install_dir>/share/hadoop/tools/lib/ | grep azure. Remplacez l’espace réservé<hadoop_install_dir>par le chemin du répertoire où vous avez installé Hadoop. Veillez à utiliser des chemins d'accès complets.Exemples :
azjars=$hadoop_install_dir/share/hadoop/tools/lib/hadoop-azure-2.6.0-cdh5.14.0.jarazjars=$azjars,$hadoop_install_dir/share/hadoop/tools/lib/microsoft-windowsazure-storage-sdk-0.6.0.jarCréez le conteneur de stockage à utiliser pour la copie des données. Vous devez également spécifier un répertoire de destination dans le cadre de cette commande. À ce stade, il peut s’agir d’un répertoire de destination fictif.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -mkdir -p wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Remplacez l’espace réservé
<blob_service_endpoint>par le nom de votre point de terminaison de service blob.Remplacez l’espace réservé
<account_key>par la clé d’accès de votre compte.Remplacez l’espace réservé
<container-name>par le nom de votre conteneur.Remplacez l’espace réservé
<destination_directory>par le nom du répertoire où vous voulez copier vos données.
Exécutez une commande list pour vérifier que votre conteneur et votre répertoire ont été créés.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -ls -R wasb://<container_name>@<blob_service_endpoint>/Remplacez l’espace réservé
<blob_service_endpoint>par le nom de votre point de terminaison de service blob.Remplacez l’espace réservé
<account_key>par la clé d’accès de votre compte.Remplacez l’espace réservé
<container-name>par le nom de votre conteneur.
Copiez les données du magasin HDFS Hadoop vers le stockage d’objets blob Data Box, dans le conteneur que vous avez créé précédemment. Si le répertoire dans lequel vous effectuez la copie est introuvable, la commande le crée automatiquement.
hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -filters <exclusion_filelist_file> \ [-f filelist_file | /<source_directory> \ wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Remplacez l’espace réservé
<blob_service_endpoint>par le nom de votre point de terminaison de service blob.Remplacez l’espace réservé
<account_key>par la clé d’accès de votre compte.Remplacez l’espace réservé
<container-name>par le nom de votre conteneur.Remplacez l’espace réservé
<exclusion_filelist_file>par le nom du fichier contenant votre liste d'exclusions de fichiers.Remplacez l’espace réservé
<source_directory>par le nom du répertoire contenant les données à copier.Remplacez l’espace réservé
<destination_directory>par le nom du répertoire où vous voulez copier vos données.
L’option
-libjarssert à rendre les fichiershadoop-azure*.jaret les fichiersazure-storage*.jardépendants disponibles pourdistcp. Cela peut déjà être le cas pour certains clusters.L'exemple suivant montre comment la commande
distcpest utilisée pour copier des données.hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.mystorageaccount.blob.mydataboxno.microsoftdatabox.com=myaccountkey \ -filter ./exclusions.lst -f /tmp/copylist1 -m 4 \ /data/testfiles \ wasb://hdfscontainer@mystorageaccount.blob.mydataboxno.microsoftdatabox.com/dataPour accélérer la copie :
Essayez d’augmenter le nombre de mappeurs. (Le nombre par défaut de mappeurs est 20. L’exemple ci-dessus utilise
m= 4 mappeurs.)Essayer
-D fs.azure.concurrentRequestCount.out=<thread_number>. Remplacez<thread_number>par le nombre de threads par mappeur. Le produit du nombre de mappeurs et du nombre de threads par mappeur,m*<thread_number>, ne doit pas dépasser 32.Essayez d’exécuter plusieurs éléments
distcpen parallèle.Rappelez-vous que les gros fichiers sont plus performants que les petits fichiers.
Si vous avez des fichiers de plus de 200 Go, nous vous recommandons de remplacer la taille de bloc par 100 Mo avec les paramètres suivants :
hadoop distcp \ -libjars $azjars \ -Dfs.azure.write.request.size= 104857600 \ -Dfs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -Dfs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -strategy dynamic \ -Dmapreduce.map.memory.mb=16384 \ -Dfs.azure.concurrentRequestCount.out=8 \ -Dmapreduce.map.java.opts=-Xmx8196m \ -m 4 \ -update \ /data/bigfile wasb://hadoop@mystorageaccount.blob.core.windows.net/bigfile
Expédier la Data Box à Microsoft
Suivez ces étapes pour préparer et expédier la Data Box à Microsoft.
Tout d’abord, préparez l’expédition de votre Data Box ou Data Box Heavy.
Une fois la préparation de l’appareil terminée, téléchargez les fichiers de nomenclature. Vous utilisez ces fichiers de nomenclature (BOM) ou de manifeste plus tard pour vérifier les données chargées sur Azure.
Mettez l’appareil hors tension et débranchez les câbles.
Planifiez un enlèvement avec UPS.
Pour les Data Box, consultez Expédier votre Data Box.
Pour les Data Box Heavy, consultez Expédier votre Data Box Heavy.
Quand Microsoft reçoit votre appareil, celui-ci est connecté au réseau du centre de données et les données sont chargées vers le compte de stockage que vous avez spécifié lors de la commande de l’appareil. À l’aide des fichiers de nomenclature, vérifiez que toutes vos données sont chargées vers Azure.
Appliquez des autorisations d'accès aux fichiers et aux répertoires (Data Lake Storage uniquement)
Les données figurent déjà dans votre compte de stockage Azure. Vous appliquez maintenant des autorisations d’accès aux fichiers et aux répertoires.
Remarque
Cette étape n’est nécessaire que si vous utilisez Azure Data Lake Storage comme magasin de données. Si vous n'utilisez qu'un compte de stockage d’objets blob sans espace de noms hiérarchique comme banque de données, vous pouvez ignorer cette section.
Créez un principal de service pour votre compte compatible Azure Data Lake Storage
Pour créer un principal de service, consultez Procédure : utiliser le portail pour créer une application et un principal du service Microsoft Entra capables d’accéder aux ressources.
Au cours des étapes décrites dans la section Attribuer un rôle à l’application de l’article, veillez à affecter le rôle Contributeur aux données Blob du stockage au principal de service.
Au cours des étapes indiquées dans la section Obtenir les valeurs de connexion de l’article, enregistrez l’ID d’application et le secret client dans un fichier texte. Vous en aurez besoin bientôt.
Générer une liste des fichiers copiés avec leurs autorisations
À partir du cluster Hadoop en local, exécutez cette commande :
sudo -u hdfs ./copy-acls.sh -s /{hdfs_path} > ./filelist.json
Cette commande génère une liste de fichiers copiés avec leurs autorisations.
Notes
Selon le nombre de fichiers dans HDFS, cette commande peut prendre beaucoup de temps à exécuter.
Générer une liste d’identités et les mapper aux identités Microsoft Entra
Téléchargez le script
copy-acls.py. Consultez la section Télécharger des scripts d'aide et configurer votre nœud de périphérie pour qu'il les exécute de cet article.Exécutez cette commande pour générer une liste d’identités uniques.
./copy-acls.py -s ./filelist.json -i ./id_map.json -gCe script génère un fichier nommé
id_map.jsonqui contient les identités nécessaires pour mapper des identités basées sur ADD.Ouvrez le fichier
id_map.jsondans un éditeur de texte.Pour chaque objet JSON qui apparaît dans le fichier, mettez à jour l’attribut
targetd’un nom d’utilisateur principal (UPN) ou d’un ID d’objet (OID) Microsoft Entra, avec l’identité mappée correspondante. Quand vous avez terminé, enregistrez le fichier. Vous en aurez besoin dans la prochaine étape.
Appliquer des autorisations à des fichiers copiés et appliquer des mappages d’identités
Exécutez cette commande pour appliquer les autorisations aux données que vous avez copiées dans le compte compatible Data Lake Storage :
./copy-acls.py -s ./filelist.json -i ./id_map.json -A <storage-account-name> -C <container-name> --dest-spn-id <application-id> --dest-spn-secret <client-secret>
Remplacez la valeur d’espace réservé
<storage-account-name>par le nom de votre compte de stockage.Remplacez l’espace réservé
<container-name>par le nom de votre conteneur.Remplacez les espaces réservés
<application-id>et<client-secret>par l’ID d’application et la clé secrète client que vous avez collectés lorsque vous avez créé le principal du service.
Annexe : Répartir les données sur plusieurs Data Box
Avant de déplacer vos données vers une Data Box, vous devrez télécharger des scripts d’assistance, vérifier que vos données sont organisées pour tenir sur une Data Box, puis exclure tous les fichiers non nécessaires.
Télécharger des scripts d'aide et configurer votre nœud de périphérie pour qu'il les exécute
À partir du nœud de périphérie ou du nœud principal votre cluster Hadoop en local, exécutez cette commande :
git clone https://github.com/jamesbak/databox-adls-loader.git cd databox-adls-loaderCette commande clone le référentiel GitHub contenant contient les scripts d'aide.
Vérifiez que le package jq est installé sur votre ordinateur local.
sudo apt-get install jqInstallez le package Python requests.
pip install requestsDéfinissez les autorisations d’exécution sur les scripts requis.
chmod +x *.py *.sh
Assurez-vous que vos données sont organisées de manière à tenir dans un service Data Box.
Si la taille de vos données dépasse celle d’un seul appareil Data Box, vous pouvez diviser les fichiers en groupes afin de les stocker sur plusieurs appareils Data Box.
Si vos données ne dépassent pas la taille d'une seule Data Box, vous pouvez passer à la section suivante.
Avec des autorisations élevées, exécutez le script
generate-file-listque vous avez téléchargé en suivant les instructions de la section précédente.Voici une description des paramètres de la commande :
sudo -u hdfs ./generate-file-list.py [-h] [-s DATABOX_SIZE] [-b FILELIST_BASENAME] [-f LOG_CONFIG] [-l LOG_FILE] [-v {DEBUG,INFO,WARNING,ERROR}] path where: positional arguments: path The base HDFS path to process. optional arguments: -h, --help show this help message and exit -s DATABOX_SIZE, --databox-size DATABOX_SIZE The size of each Data Box in bytes. -b FILELIST_BASENAME, --filelist-basename FILELIST_BASENAME The base name for the output filelists. Lists will be named basename1, basename2, ... . -f LOG_CONFIG, --log-config LOG_CONFIG The name of a configuration file for logging. -l LOG_FILE, --log-file LOG_FILE Name of file to have log output written to (default is stdout/stderr) -v {DEBUG,INFO,WARNING,ERROR}, --log-level {DEBUG,INFO,WARNING,ERROR} Level of log information to output. Default is 'INFO'.Copiez les listes de fichiers générées vers HDFS afin qu’elles soient accessibles à la tâche DistCp.
hadoop fs -copyFromLocal {filelist_pattern} /[hdfs directory]
Exclure les fichiers inutiles
Vous devez exclure certains répertoires du travail DisCp. Par exemple, excluez les répertoires qui contiennent des informations d’intégrité empêchant l’exécution du cluster.
Sur le cluster Hadoop local dans lequel vous envisagez de lancer la tâche DistCp, créez un fichier qui spécifie la liste des répertoires à exclure.
Voici un exemple :
.*ranger/audit.*
.*/hbase/data/WALs.*
Étapes suivantes
Découvrez comment Data Lake Storage fonctionne avec les clusters HDInsight. Pour plus d’informations, consultez Utiliser Azure Data Lake Storage avec les clusters Azure HDInsight.