Copier et transformer des données dans Snowflake V2 en utilisant Azure Data Factory ou Azure Synapse Analytics
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article indique comment utiliser l’activité Copy dans des pipelines Azure Data Factory Azure Synapse pour copier des données depuis et vers Snowflake, puis comment utiliser Data Flow pour transformer des données dans Snowflake. Pour en savoir plus, lisez l’article de présentation d’Azure Data Factory ou d’Azure Synapse Analytics.
Important
Le connecteur Snowflake V2 fournit une prise en charge native améliorée de Snowflake. Si vous utilisez le connecteur Snowflake V1 dans votre solution, nous vous recommandons de mettre à niveau votre connecteur Snowflake dès que possible. Pour plus de détails sur les différences entre la V2 et la V1, reportez-vous à cette section.
Fonctionnalités prises en charge
Ce connecteur Snowflake est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR |
|---|---|
| Activité de copie (source/récepteur) | ① ② |
| Mappage de flux de données (source/récepteur) | ① |
| Activité de recherche | ① ② |
| Activité de script | ① ② |
① Runtime d’intégration Azure ② Runtime d’intégration auto-hébergé
Pour l’activité de copie, ce connecteur Snowflake prend en charge les fonctions suivantes :
- Copiez des données à partir de Snowflake qui utilise la commande COPY into [emplacement] de Snowflake pour obtenir les meilleures performances.
- Copiez des données dans Snowflake qui utilise la commande COPY into [table] de Snowflake pour obtenir les meilleures performances. Il prend en charge Snowflake sur Azure.
- Si un proxy est requis pour se connecter à Snowflake à partir d’un Integration Runtime auto-hébergé, vous devez configurer les variables d’environnement pour HTTP_PROXY et HTTPS_PROXY sur l’hôte Integration Runtime.
Prérequis
Si votre magasin de données se trouve dans un réseau local, un réseau virtuel Azure ou un cloud privé virtuel Amazon, vous devez configurer un runtime d’intégration auto-hébergé pour vous y connecter. Veillez à ajouter les adresses IP que le runtime d’intégration auto-hébergé utilise dans la liste autorisée.
Si votre magasin de données est un service de données cloud managé, vous pouvez utiliser Azure Integration Runtime. Si l’accès est limité aux adresses IP qui sont approuvées dans les règles de pare-feu, vous pouvez ajouter les adresses IP Azure Integration Runtime dans la liste autorisée.
Le compte Snowflake utilisé en tant que Source ou Récepteur doit disposer de l’accès USAGE nécessaire sur la base de données et d’un accès en lecture/écriture sur le schéma et les tables/vues sous-jacentes. En outre, il doit également disposer de CREATE STAGE sur le schéma pour pouvoir créer l’étape externe avec l’URI SAP.
Les valeurs des propriétés de compte suivantes doivent être définies
| Propriété | Description | Obligatoire | Default |
|---|---|---|---|
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_CREATION | Indique s’il faut exiger un objet d’intégration de stockage en tant qu’informations d’identification cloud lors de la création d’une phase externe nommée (à l’aide de CREATE STAGE) pour accéder à un emplacement de stockage cloud privé. | false | false |
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_OPERATION | Indique s’il faut utiliser une étape externe nommée qui référence un objet d’intégration de stockage en tant qu’informations d’identification cloud lors du chargement ou du déchargement de données vers un emplacement de stockage cloud privé. | false | false |
Pour plus d’informations sur les mécanismes de sécurité réseau et les options pris en charge par Data Factory, consultez Stratégies d’accès aux données.
Bien démarrer
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
Créer un service lié à Snowflake l’aide de l’interface utilisateur
Suivez les étapes suivantes pour créer un service lié à Snowflake dans l’interface utilisateur du portail Azure.
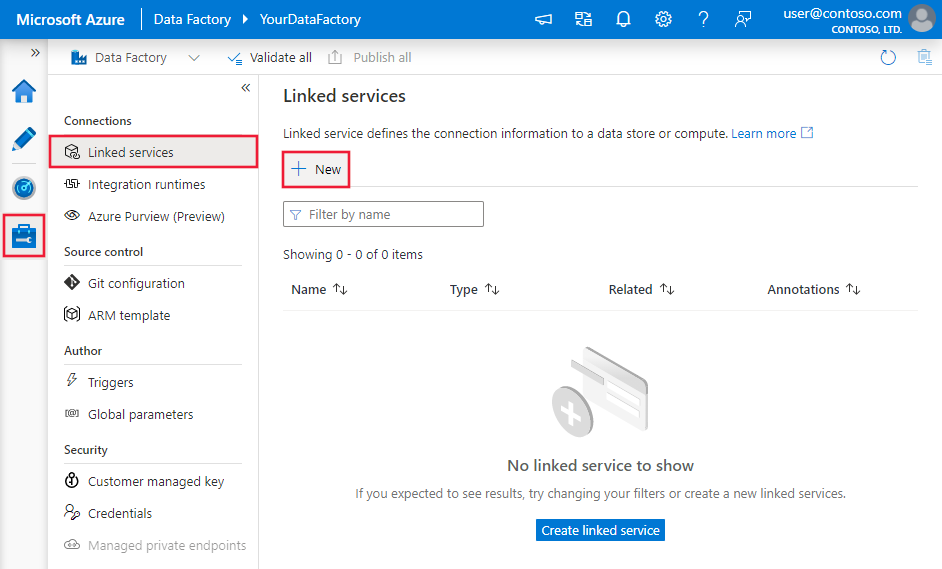
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse, sélectionnez Services liés, puis cliquez sur Nouveau :
Recherchez Snowflake, puis sélectionnez le connecteur Snowflake.

Configurez les informations du service, testez la connexion et créez le nouveau service lié.
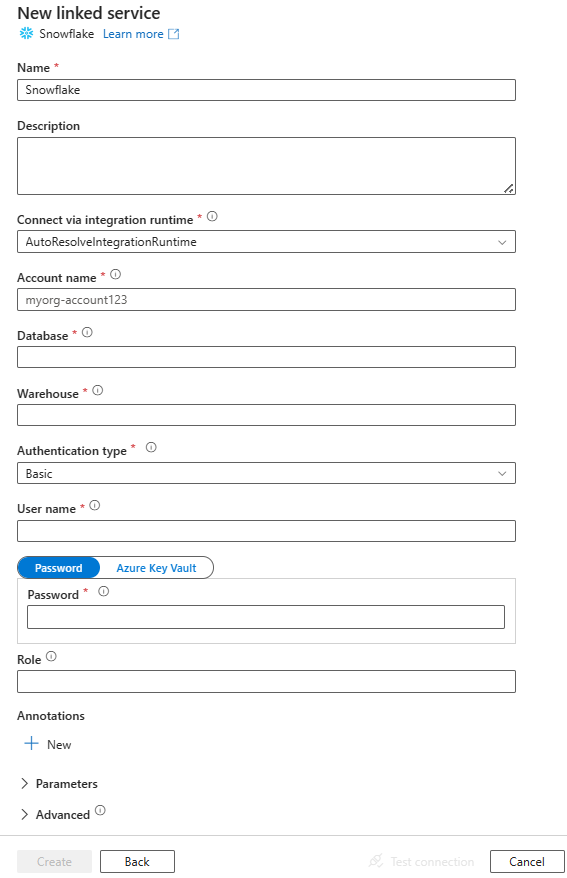
Détails de configuration du connecteur
Les sections suivantes donnent des précisions sur les propriétés utilisées qui définissent des entités propres à un connecteur Snowflake.
Propriétés du service lié
Les propriétés génériques prises en charge pour un service lié Snowflake sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur SnowflakeV2. | Oui |
| accountIdentifier | Le nom du compte ainsi que son organisation. Par exemple, monorg-compte123. | Oui |
| database | La base de données par défaut utilisée pour la session après la connexion. | Oui |
| warehouse | L’entrepôt virtuel par défaut utilisé pour la session après la connexion. | Oui |
| authenticationType | Type d’authentification utilisé pour se connecter au service Snowflake. Les valeurs autorisées sont : De base (par défaut) et Paire de clés. Pour d’autres propriétés et exemples, voir les sections correspondantes ci-dessous. | Non |
| role | Le rôle de sécurité par défaut utilisé pour la session après la connexion. | Non |
| host | Nom d’hôte du compte Snowflake. Par exemple : contoso.snowflakecomputing.com.
.cn est également pris en charge. |
Non |
| connectVia | Le runtime d’intégration utilisé pour la connexion à la banque de données. Vous pouvez utiliser le runtime d’intégration Azure ou un runtime d’intégration auto-hébergé si votre banque de données se trouve sur un réseau privé. À défaut de spécification, le runtime d’intégration Azure par défaut est utilisé. | Non |
Ce connecteur Snowflake prend en charge les types d’authentification suivants. Pour plus d’informations, consultez les sections correspondantes.
Authentification de base
Pour utiliser l’authentification De base, en plus des propriétés génériques décrites dans la section précédente, spécifiez les propriétés suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| utilisateur | ID de connexion de l’utilisateur Snowflake. | Oui |
| mot de passe | Le mot de passe de l’utilisateur Snowflake. Vous pouvez marquer ce champ en tant que type SecureString pour le stocker de manière sécurisée. Vous pouvez également référencer un secret stocké dans Azure Key Vault. | Oui |
Exemple :
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "Basic",
"user": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"role": "<role>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Mot de passe dans Azure Key Vault :
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "Basic",
"user": "<username>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Remarque
Les flux de données de mappage prennent en charge seulement l’authentification de base.
Authentification avec une paire de clés
Pour utiliser l’authentification avec une Paire de clés, vous devez configurer et créer un utilisateur d’authentification avec une paire de clés dans Snowflake en faisant référence à Authentification par paire de clés et rotation de paire de clés. Ensuite, notez la clé privée et la phrase secrète (facultatif) que vous utilisez pour définir le service lié.
Outre les propriétés génériques décrites dans la section précédente, spécifiez les propriétés suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| utilisateur | ID de connexion de l’utilisateur Snowflake. | Oui |
| privateKey | La clé privée utilisée pour l’authentification avec une paire de clés. Pour vous assurer que la clé privée est valide lorsqu’elle est envoyée à Azure Data Factory, et compte tenu du fait que le fichier privateKey (clé privée) inclut des caractères de nouvelle ligne (\n), il est essentiel de mettre en forme correctement le contenu privateKey sous sa forme littérale de chaîne. Ce processus implique l’ajout explicite de \n à chaque nouvelle ligne. |
Oui |
| privateKeyPassphrase | La phrase secrète utilisée pour déchiffrer la clé privée, si elle est chiffrée. | Non |
Exemple :
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "KeyPair",
"user": "<username>",
"privateKey": {
"type": "SecureString",
"value": "<privateKey>"
},
"privateKeyPassphrase": {
"type": "SecureString",
"value": "<privateKeyPassphrase>"
},
"role": "<role>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article Jeux de données.
Les propriétés suivantes sont prises en charge pour le jeu de données Snowflake.
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur SnowflakeV2Table. | Oui |
| schéma | Nom du schéma. Remarque : le nom du schéma respecte la casse. | Non pour Source, Oui pour Récepteur |
| table | Nom de la table/vue. Remarque : le nom de la table respecte la casse. | Non pour Source, Oui pour Récepteur |
Exemple :
{
"name": "SnowflakeV2Dataset",
"properties": {
"type": "SnowflakeV2Table",
"typeProperties": {
"schema": "<Schema name for your Snowflake database>",
"table": "<Table name for your Snowflake database>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Propriétés de l’activité de copie
Pour obtenir la liste complète des sections et des propriétés disponibles pour la définition des activités, consultez l’article Pipelines. Cette section fournit la liste des propriétés prises en charge par Snowflake en tant que source et récepteur.
Snowflake en tant que source
Un connecteur Snowflake utilise la commande COPY vers [emplacement] de Snowflake pour obtenir les meilleures performances.
Si le magasin de données récepteur et le format sont pris en charge en mode natif par la commande COPY de Snowflake, vous pouvez utiliser l’activité de copie pour copier directement de Snowflake vers un récepteur. Pour plus d’informations, consultez Copie directe à l’aide de Snowflake. Dans le cas contraire, utilisez la copie intermédiaire intégrée à Snowflake.
Pour copier des données à partir de Snowflake, les propriétés prises en charge dans la section source de l’activité de copie sont les suivantes.
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source de l’activité Copy doit être définie sur SnowflakeV2Source. | Oui |
| query | Spécifie la requête SQL pour lire les données de Snowflake. Si les noms du schéma, de la table et des colonnes contiennent des minuscules, citez l’identificateur d’objet dans la requête, par exemple select * from "schema"."myTable".L’exécution de la procédure stockée n'est pas prise en charge. |
Non |
| exportSettings | Paramètres avancés utilisés pour récupérer des données de Snowflake. Vous pouvez configurer pris en charge par la commande COPY into que le service empruntera lorsque vous appelez l’instruction. | Oui |
Sous exportSettings : |
||
| type | Type de commande d’exportation, défini sur SnowflakeExportCopyCommand. | Oui |
| storageIntegration | Spécifiez le nom de l’intégration de stockage que vous avez créée dans Snowflake. Pour connaître les étapes préalables à l’utilisation de l’intégration du stockage, consultez Configuration d’une intégration de stockage Snowflake. | Non |
| additionalCopyOptions | Options de copie supplémentaires, fournies sous la forme d’un dictionnaire de paires clé-valeur. Exemples : MAX_FILE_SIZE, OVERWRITE. Pour plus d'informations, consultez Options de copie de Snowflake. | Non |
| additionalFormatOptions | Options de format de fichier supplémentaires, fournies à la commande COPY sous la forme d’un dictionnaire de paires clé-valeur. Exemples : DATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT, NULL_IF. Pour plus d’informations, consultez Options de type de format de Snowflake. Lorsque vous utilisez NULL_IF, la valeur NULL dans Snowflake est convertie en la valeur spécifiée (qui doit être entre guillemets uniques) lors de l’écriture dans le fichier texte délimité dans le stockage intermédiaire. Cette valeur spécifiée est traitée comme NULL lors de la lecture du fichier intermédiaire vers le stockage récepteur. La valeur par défaut est 'NULL'. |
Non |
Notes
Vérifiez que vous êtes autorisé à exécuter la commande suivante et à accéder au schéma INFORMATION_SCHEMA et à la table COLUMNS.
COPY INTO <location>
Copie directe à partir de Snowflake
Si le magasin de données récepteur et le format remplissent les critères décrits dans cette section, vous pouvez utiliser l’activité de copie pour effectuer une copie directe de Snowflake vers un récepteur. Le service vérifie les paramètres et fait échouer l’exécution de l’activité Copy si les critères suivants ne sont pas respectés :
Lorsque vous spécifiez
storageIntegrationdans la source :Le magasin de données récepteur est le Stockage Blob Azure que vous avez référencé dans la phase externe dans Snowflake. Vous devez effectuer les étapes suivantes avant de copier des données :
Créez un service lié Stockage Blob Azure pour le Stockage Blob Azure récepteur avec tous les types d’authentification pris en charge.
Accordez au moins le rôle Contributeur aux données Blob du stockage au principal du service Snowflake dans le contrôle d’accès (IAM) au Stockage Blob Azure du récepteur.
Lorsque vous ne spécifiez pas
storageIntegrationdans la source :Le service lié au récepteur est le stockage d’objets blob Azure avec l’authentification par signature d’accès partagé. Si vous souhaitez copier directement des données dans Azure Data Lake Storage Gen2 dans le format pris en charge suivant, vous pouvez créer un service lié Stockage Blob Azure avec une authentification par SAP sur votre compte Azure Data Lake Storage Gen2, afin d’éviter d’utiliser la copie intermédiaire à partir de Snowflake.
Le format de données du récepteur est Parquet, Texte délimité ou JSON avec les configurations suivantes :
- Pour le format Parquet, le codec de compression est Aucun, Snappyou Lzo.
- Pour le format texte délimité :
-
rowDelimiterest \r\n, ou n’importe quel caractère unique. -
compressionpeut être aucune compression, gzip, bzip2, ou deflate. -
encodingNameconserve sa valeur par défaut ou est défini sur utf-8. -
quoteCharest un guillemet double, un guillemet simpleou une chaîne vide (sans guillemets).
-
- Pour le format JSON, la copie directe ne prend en charge que le cas où la table Snowflake de la source ou le résultat de la requête ne possède qu’une seule colonne, dont les données sont de type VARIANT, OBJET ou TABLEAU.
-
compressionpeut être aucune compression, gzip, bzip2, ou deflate. -
encodingNameconserve sa valeur par défaut ou est défini sur utf-8. -
filePatterndans le récepteur de l’activité de copie conserve sa valeur par défaut ou est défini sur setOfObjects.
-
Dans la source de l’activité Copy,
additionalColumnsn’est pas indiqué.Le mappage de colonnes n’est pas indiqué.
Exemple :
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeV2Source",
"query": "SELECT * FROM MYTABLE",
"exportSettings": {
"type": "SnowflakeExportCopyCommand",
"additionalCopyOptions": {
"MAX_FILE_SIZE": "64000000",
"OVERWRITE": true
},
"additionalFormatOptions": {
"DATE_FORMAT": "'MM/DD/YYYY'"
},
"storageIntegration": "< Snowflake storage integration name >"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Copie intermédiaire à partir de Snowflake
Lorsque le magasin de données récepteur ou le format ne sont pas compatibles en mode natif avec la commande COPY de Snowflake, comme indiqué dans la dernière section, activez la copie intermédiaire intégrée à l’aide d’une instance de stockage intermédiaire d’objets Blob Azure. La fonctionnalité de copie intermédiaire vous offre également un meilleur débit. Le service exporte des données à partir de Snowflake dans le stockage intermédiaire, puis copie les données sur le récepteur et nettoie vos données temporaires sur le stockage intermédiaire. Pour plus d’informations sur la copie de données à l’aide de la mise en lots, consultez Copie intermédiaire.
Pour utiliser cette fonctionnalité, créez un service lié au Stockage Blob Azure qui fait référence au compte de stockage Azure en tant qu’intermédiaire. Spécifiez ensuite les propriétés enableStaging et stagingSettings dans l’activité de copie.
Lorsque vous spécifiez
storageIntegrationdans la source, le Stockage Blob Azure intermédiaire doit être celui que vous avez référencé dans la phase externe dans Snowflake. Veillez à créer un service lié Stockage Blob Azure pour celui-ci avec n’importe quelle authentification prise en charge, et accordez au moins le rôle Contributeur aux données Blob du stockage au principal du service Snowflake dans le contrôle d’accès (IAM) de Stockage Blob Azure intermédiaire.Lorsque vous ne spécifiez pas
storageIntegrationdans la source, le service lié Stockage Blob Azure intermédiaire doit utiliser l’authentification par signature d’accès partagé, comme exigé par la commande COPY de Snowflake. Veillez à accorder une autorisation d’accès appropriée à Snowflake dans le Stockage Blob Azure intermédiaire. Pour en savoir plus sur ce sujet, consultez cet article.
Exemple :
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeV2Source",
"query": "SELECT * FROM MyTable",
"exportSettings": {
"type": "SnowflakeExportCopyCommand",
"storageIntegration": "< Snowflake storage integration name >"
}
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Lors de l’exécution d’une copie intermédiaire à partir de Snowflake, il est essentiel de définir le comportement de copie du récepteur sur Fusionner les fichiers. Ce paramètre garantit que tous les fichiers partitionnés sont correctement gérés et fusionnés, ce qui empêche que le problème où seul le dernier fichier partitionné est copié se produise.
Exemple de configuration
{
"type": "Copy",
"source": {
"type": "SnowflakeSource",
"query": "SELECT * FROM my_table"
},
"sink": {
"type": "AzureBlobStorage",
"copyBehavior": "MergeFiles"
}
}
Remarque
Si vous ne définissez pas le comportement de copie du récepteur sur Fusionner les fichiers, seul le dernier fichier partitionné risque d’être copié.
Snowflake en tant que récepteur
Un connecteur Snowflake utilise la commande COPY into [table] de Snowflake pour obtenir les meilleures performances. Il prend en charge l’écriture de données vers Snowflake sur Azure.
Si le magasin de données source et le format sont pris en charge en mode natif par la commande COPY de Snowflake, vous pouvez utiliser l’activité de copie pour copier directement d’une source vers Snowflake. Pour plus d’informations, consultez Copie directe vers Snowflake. Dans le cas contraire, utilisez la copie intermédiaire intégrée vers Snowflake.
Pour copier des données dans Snowflake, les propriétés suivantes sont prises en charge dans la section récepteur de l’activité de copie.
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du récepteur de l'activité Copy, définie sur SnowflakeV2Sink. | Oui |
| preCopyScript | Spécifiez une requête SQL pour l’activité de copie à exécuter avant l’écriture de données dans Snowflake à chaque exécution. Utilisez cette propriété pour nettoyer les données préchargées. | Non |
| importSettings | Paramètres avancés utilisés pour écrire des données dans Snowflake. Vous pouvez configurer pris en charge par la commande COPY into que le service empruntera lorsque vous appelez l’instruction. | Oui |
Sous importSettings : |
||
| type | Type de commande d’importation, défini sur SnowflakeImportCopyCommand. | Oui |
| storageIntegration | Spécifiez le nom de l’intégration de stockage que vous avez créée dans Snowflake. Pour connaître les étapes préalables à l’utilisation de l’intégration du stockage, consultez Configuration d’une intégration de stockage Snowflake. | Non |
| additionalCopyOptions | Options de copie supplémentaires, fournies sous la forme d’un dictionnaire de paires clé-valeur. Exemples : ON_ERROR, FORCE, LOAD_UNCERTAIN_FILES. Pour plus d'informations, consultez Options de copie de Snowflake. | Non |
| additionalFormatOptions | Options de format de fichier supplémentaires, fournies à la commande COPY sous la forme d’un dictionnaire de paires clé-valeur. Exemples : DATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT. Pour plus d’informations, consultez Options de type de format de Snowflake. | Non |
Notes
Vérifiez que vous êtes autorisé à exécuter la commande suivante et à accéder au schéma INFORMATION_SCHEMA et à la table COLUMNS.
SELECT CURRENT_REGION()COPY INTO <table>SHOW REGIONSCREATE OR REPLACE STAGEDROP STAGE
Copie directe vers Snowflake
Si le magasin de données source et le format remplissent les critères décrits dans cette section, vous pouvez utiliser l’activité de copie pour effectuer une copie directe depuis une source vers Snowflake. Le service vérifie les paramètres et fait échouer l’exécution de l’activité Copy si les critères suivants ne sont pas respectés :
Lorsque vous spécifiez
storageIntegrationdans le récepteur :Le magasin de données source est le Stockage Blob Azure que vous avez référencé dans la phase externe dans Snowflake. Vous devez effectuer les étapes suivantes avant de copier des données :
Créez un service lié Stockage Blob Azure pour le Stockage Blob Azure source avec tous les types d’authentification pris en charge.
Accordez au moins le rôle Lecteur des données blob du stockage au principal du service Snowflake dans le contrôle d’accès (IAM) au Stockage Blob Azure source.
Lorsque vous ne spécifiez pas
storageIntegrationdans le récepteur :Le service lié à la source est le stockage d’objets blob Azure avec l’authentification par signature d’accès partagé. Si vous souhaitez copier directement des données à partir d’Azure Data Lake Storage Gen2 dans le format pris en charge suivant, vous pouvez créer un service lié Stockage Blob Azure avec une authentification par SAP sur votre compte Azure Data Lake Storage Gen2, afin d’éviter d’utiliser la copie intermédiaire vers Snowflake.
Le format de données de la source est Parquet, Texte délimité ou JSON avec les configurations suivantes :
Pour le format Parquet, le codec de compression est Aucun ou Snappy.
Pour le format texte délimité :
-
rowDelimiterest \r\n, ou n’importe quel caractère unique. Si le délimiteur de ligne n’est pas « \r\n »,firstRowAsHeaderdoit être faux, etskipLineCountn’est pas indiqué. -
compressionpeut être aucune compression, gzip, bzip2, ou deflate. -
encodingNameest conservé comme valeur par défaut ou défini sur "UTF-8", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "BIG5", "EUC-JP", "EUC-KR", "GB18030", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255". -
quoteCharest un guillemet double, un guillemet simpleou une chaîne vide (sans guillemets).
-
Pour le format JSON, la copie directe ne prend en charge que le cas où la table Snowflake du récepteur ne possède qu’une seule colonne, dont les données sont de type VARIANT, OBJET ou TABLEAU.
-
compressionpeut être aucune compression, gzip, bzip2, ou deflate. -
encodingNameconserve sa valeur par défaut ou est défini sur utf-8. - Le mappage de colonnes n’est pas indiqué.
-
Dans la source de l’activité de copie :
-
additionalColumnsn’est pas indiqué. - Si votre source est un dossier,
recursivea la valeur true. -
prefix,modifiedDateTimeStart,modifiedDateTimeEnd, etenablePartitionDiscoveryne sont pas spécifiés.
-
Exemple :
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeV2Sink",
"importSettings": {
"type": "SnowflakeImportCopyCommand",
"copyOptions": {
"FORCE": "TRUE",
"ON_ERROR": "SKIP_FILE"
},
"fileFormatOptions": {
"DATE_FORMAT": "YYYY-MM-DD"
},
"storageIntegration": "< Snowflake storage integration name >"
}
}
}
}
]
Copie intermédiaire vers Snowflake
Lorsque le format ou le magasin de données source ne sont pas compatibles en mode natif avec la commande COPY de Snowflake, comme indiqué dans la dernière section, activez la copie intermédiaire intégrée à l’aide d’une instance de Stockage Blob Azure temporaire. La fonctionnalité de copie intermédiaire vous offre également un meilleur débit. Le service convertit automatiquement les données pour répondre aux exigences de format de données de Snowflake. Il appelle ensuite la commande COPY pour charger les données dans Snowflake. Pour finir, il nettoie vos données temporaires du stockage Blob. Pour plus d’informations sur la copie de données à l’aide de la mise en lots, consultez Copie intermédiaire.
Pour utiliser cette fonctionnalité, créez un service lié au Stockage Blob Azure qui fait référence au compte de stockage Azure en tant qu’intermédiaire. Spécifiez ensuite les propriétés enableStaging et stagingSettings dans l’activité de copie.
Lorsque vous spécifiez
storageIntegrationdans le récepteur, le Stockage Blob Azure intermédiaire doit être celui que vous avez référencé dans la phase externe dans Snowflake. Veillez à créer un service lié Stockage Blob Azure pour celui-ci avec n’importe quelle authentification prise en charge, et accordez au moins le rôle Lecteur des données blob du stockage au principal du service Snowflake dans le contrôle d’accès (IAM) de Stockage Blob Azure intermédiaire.Lorsque vous ne spécifiez pas
storageIntegrationdans le récepteur, le service lié Stockage Blob Azure intermédiaire doit utiliser l’authentification par signature d’accès partagé, comme exigé par la commande COPY de Snowflake.
Exemple :
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeV2Sink",
"importSettings": {
"type": "SnowflakeImportCopyCommand",
"storageIntegration": "< Snowflake storage integration name >"
}
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Propriétés du mappage de flux de données
Lors de la transformation de données dans le flux de données de mappage, vous pouvez lire et écrire dans les tables de Snowflake. Pour plus d’informations, consultez la transformation de la source et la transformation du récepteur dans le flux de données de mappage. Vous pouvez choisir d’utiliser un jeu de données Snowflake ou un jeu de données inlined en tant que type de source et de récepteur.
Transformation de la source
Le tableau ci-dessous répertorie les propriétés prises en charge par la source Snowflake. Vous pouvez modifier ces propriétés sous l’onglet Options de la source. Le connecteur utilise le transfert de données interne de Snowflake.
| Nom | Description | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Table de charge de travail | Si vous sélectionnez Table comme entrée, le flux de données extraira toutes les données de la table spécifiée dans le jeu de données Snowflake ou dans les options source lorsque vous utilisez le jeu de données inlined. | Non | String |
(pour le jeu de données inlined uniquement) tableName schemaName |
| Requête | Si vous sélectionnez Requête comme entrée, entrez une requête pour extraire les données de Snowflake. Ce paramètre remplace toute table que vous avez choisie dans le jeu de données. Si les noms du schéma, de la table et des colonnes contiennent des minuscules, citez l’identificateur d’objet dans la requête, par exemple select * from "schema"."myTable". |
Non | String | query |
| Activer l’extraction incrémentielle (préversion) | Utilisez cette option pour indiquer à ADF de traiter seulement les lignes qui ont changé depuis la dernière exécution du pipeline. | Non | Booléen | enableCdc |
| Colonne incrémentielle | Quand vous utilisez la fonctionnalité d’extraction incrémentielle, vous devez choisir la colonne date/heure/numérique que vous voulez utiliser comme filigrane dans votre table source. | Non | Chaîne | waterMarkColumn |
| Activer le Change Tracking de Snowflake (préversion) | Cette option permet à ADF de tirer parti de la technologie de capture des changements de données de Snowflake pour traiter uniquement les données delta depuis l’exécution précédente du pipeline. Cette option charge automatiquement les données delta avec des opérations d’insertion, de mise à jour et de suppression de ligne sans nécessiter de colonne incrémentielle. | Non | Booléen | enableNativeCdc |
| Modifications nettes | Lorsque vous utilisez Change Tracking de Snowflake, vous pouvez utiliser cette option pour obtenir des lignes modifiées dédupliquées ou des modifications exhaustives. Les lignes modifiées dédupliquées affichent uniquement les dernières versions des lignes qui ont changé depuis un point donné dans le temps, tandis que les modifications exhaustives vous indiquent toutes les versions de chaque ligne qui ont changé, y compris celles qui ont été supprimées ou mises à jour. Par exemple, si vous mettez à jour une ligne, vous verrez une version de suppression et une version d’insertion dans les modifications exhaustives, mais uniquement la version d’insertion dans les lignes modifiées dédupliquées. Selon votre cas d’usage, vous pouvez choisir l’option qui répond à vos besoins. L’option par défaut est false, ce qui implique des modifications exhaustives. | Non | Booléen | netChanges |
| Inclure des colonnes système | Lorsque vous utilisez le change tracking (suivi des modifications) Snowflake, vous pouvez utiliser l’option systemColumns pour contrôler si les colonnes de flux de métadonnées fournies par Snowflake sont incluses ou exclues dans la sortie de suivi des modifications. Par défaut, systemColumns est défini sur true, ce qui signifie que les colonnes de flux de métadonnées sont incluses. Vous pouvez définir systemColumns sur false si vous souhaitez les exclure. | Non | Booléen | systemColumns |
| Commencer la lecture depuis le début | La définition de cette option avec l’extraction incrémentielle et le suivi des modifications indique à ADF de lire toutes les lignes lors de la première exécution d’un pipeline qui a l’extraction incrémentielle activée. | Non | Booléen | skipInitialLoad |
Exemples de scripts de source Snowflake
Quand vous utilisez un jeu de données Snowflake comme type de source, le script de flux de données associé est le suivant :
source(allowSchemaDrift: true,
validateSchema: false,
query: 'select * from MYTABLE',
format: 'query') ~> SnowflakeSource
Si vous utilisez un jeu de données inlined, le script de flux de données associé est le suivant :
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'select * from MYTABLE',
store: 'snowflake') ~> SnowflakeSource
Change Tracking natif
Azure Data Factory prend désormais en charge une fonctionnalité native dans Snowflake appelée change tracking (suivi des modifications), ce qui implique le suivi des modifications sous la forme de journaux. Cette fonctionnalité de Snowflake nous permet de suivre les modifications apportées aux données au fil du temps, ce qui la rend utile pour le chargement et l’audit incrémentiels des données. Pour utiliser cette fonctionnalité, lorsque vous activez la Capture des changements de données et sélectionnez le Change Tracking de Snowflake, nous créons un objet Flux (Stream) pour la table source qui active le suivi des modifications sur la table Snowflake source. Ensuite, nous utilisons la clause CHANGES (modifications) dans notre requête pour extraire uniquement les données nouvelles ou mises à jour de la table source. Il est également recommandé de planifier le pipeline de manière à ce que les modifications soient consommées dans l’intervalle de durée de conservation des données défini pour la table source Snowflake, faute de quoi l’utilisateur pourrait constater un comportement incohérent dans les modifications capturées.
Transformation du récepteur
Le tableau ci-dessous répertorie les propriétés prises en charge par le récepteur Snowflake. Vous pouvez modifier ces propriétés sous l’onglet Paramètres. Lorsque vous utilisez un jeu de données inclus, vous verrez des paramètres supplémentaires qui sont les mêmes que les propriétés décrites dans la section Propriétés du jeu de données. Le connecteur utilise le transfert de données interne de Snowflake.
| Nom | Description | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Mettre à jour la méthode | Spécifiez quelles opérations sont autorisées sur votre destination Snowflake. Pour mettre à jour, effectuer un upsert ou supprimer des lignes, une transformation de modification de ligne est requise afin de baliser les lignes relatives à ces actions. |
Oui |
true ou false |
deletable insertable updateable upsertable |
| Colonnes clés | Pour les mises à jour, les opérations upsert et les suppressions, une ou plusieurs colonnes clés doivent être définies afin de déterminer la ligne à modifier. | Non | Array | clés |
| Action table | Détermine si toutes les lignes de la table de destination doivent être recréées ou supprimées avant l’écriture. - Aucun : Aucune action ne sera effectuée sur la table. - Recréer : La table sera supprimée et recréée. Obligatoire en cas de création dynamique d’une nouvelle table. - Tronquer : Toutes les lignes de la table cible seront supprimées. |
Non |
true ou false |
recreate truncate |
Exemples de scripts de récepteur Snowflake
Quand vous utilisez un jeu de données Snowflake comme type de récepteur, le script de flux de données associé est le suivant :
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
Si vous utilisez un jeu de données inlined, le script de flux de données associé est le suivant :
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
tableName: 'table',
schemaName: 'schema',
deletable: true,
insertable: true,
updateable: true,
upsertable: false,
store: 'snowflake',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
Optimisation du pushdown des requêtes
En définissant le niveau de journalisation du pipeline sur None, nous excluons la transmission des métriques de transformation intermédiaires, ce qui évite les obstacles potentiels aux optimisations Spark et permet l’optimisation du pushdown des requêtes fournie par Snowflake. Cette optimisation de pushdown permet des améliorations substantielles des performances pour les tables Snowflake volumineuses avec des jeux de données étendus.
Remarque
Nous ne prenons pas en charge les tables temporaires dans Snowflake, car elles sont locales à la session ou à l’utilisateur qui les créent, ce qui les rend inaccessibles à d’autres sessions et sujettes à être remplacées sous forme de tables standard par Snowflake. Bien que Snowflake offre des tables temporaires comme alternative, qui sont accessibles globalement, elles nécessitent une suppression manuelle, ce qui va à l’encontre de notre objectif principal d’utilisation des tables Temp (temporaires), qui est d’éviter toute opération de suppression dans le schéma source.
Propriétés de l’activité Lookup
Pour plus d’informations sur les propriétés, consultez Activité de recherche.
Mettre à niveau le connecteur Snowflake
Pour mettre à niveau le connecteur Snowflake, vous pouvez effectuer une mise à niveau côte à côte, ou une mise à niveau sur place.
Mise à niveau côte à côte
Pour effectuer une mise à niveau côte à côte, procédez comme suit :
- Créez un service lié Snowflake et configurez-le en vous référant aux propriétés du service lié V2.
- Créez un jeu de données basé sur le service lié Snowflake nouvellement créé.
- Remplacez le nouveau service lié et le nouveau jeu de données par ceux existants dans les pipelines qui ciblent les objets V1.
Mise à niveau sur place
Pour effectuer une mise à niveau sur place, vous devez modifier la charge utile du service lié existant, et mettre à jour le jeu de données afin d’utiliser le nouveau service lié.
Mettez à jour le type de Snowflake vers SnowflakeV2.
Modifiez la charge utile du service lié de son format V1 en V2. Vous pouvez remplir chaque champ à partir de l’interface utilisateur après avoir modifié le type mentionné ci-dessus, ou mettre à jour la charge utile directement via l’éditeur JSON. Reportez-vous à la section Propriétés du service lié dans cet article pour connaître les propriétés de connexion prises en charge. Les exemples suivants montrent les différences de charge utile entre le service lié à Snowflake V1 et le service lié à Snowflake V2 :
Charge utile JSON du service lié à Snowflake V1 :
{ "name": "Snowflake1", "type": "Microsoft.DataFactory/factories/linkedservices", "properties": { "annotations": [], "type": "Snowflake", "typeProperties": { "authenticationType": "Basic", "connectionString": "jdbc:snowflake://<fake_account>.snowflakecomputing.com/?user=FAKE_USER&db=FAKE_DB&warehouse=FAKE_DW&schema=PUBLIC", "encryptedCredential": "<your_encrypted_credential_value>" }, "connectVia": { "referenceName": "AzureIntegrationRuntime", "type": "IntegrationRuntimeReference" } } }Charge utile JSON du service lié à Snowflake V2 :
{ "name": "Snowflake2", "type": "Microsoft.DataFactory/factories/linkedservices", "properties": { "parameters": { "schema": { "type": "string", "defaultValue": "PUBLIC" } }, "annotations": [], "type": "SnowflakeV2", "typeProperties": { "authenticationType": "Basic", "accountIdentifier": "<FAKE_Account>", "user": "FAKE_USER", "database": "FAKE_DB", "warehouse": "FAKE_DW", "encryptedCredential": "<placeholder>" }, "connectVia": { "referenceName": "AutoResolveIntegrationRuntime", "type": "IntegrationRuntimeReference" } } }Mettez à jour le jeu de données pour utiliser le nouveau service lié. Vous pouvez créer un jeu de données basé sur le service lié nouvellement créé ou mettre à jour la propriété de type d’un jeu de données existant de SnowflakeTable vers SnowflakeV2Table.
Différences entre Snowflake V2 et V1
Le connecteur Snowflake V2 offre de nouvelles fonctionnalités et est compatible avec la plupart des fonctionnalités du connecteur Snowflake V1. Le tableau ci-dessous présente les différences de fonctionnalités entre V2 et V1.
| Snowflake V2 | Snowflake V1 |
|---|---|
| Prise en charge de l’authentification de base et par paire de clés. | Prise en charge de l’authentification de base. |
| Actuellement, les paramètres de script ne sont pas pris en charge dans l’activité de script. En guise d’alternative, utilisez des expressions dynamiques pour les paramètres de script. Pour plus d’informations, consultez l’article Expressions et fonctions dans Azure Data Factory et Azure Synapse Analytics. | Prise en charge des paramètres de script dans l’activité de script. |
Prise en charge de BigDecimal dans l’activité de recherche. Le type NUMBER, tel que défini dans Snowflake, s’affiche sous forme de chaîne dans l’activité de recherche. Si vous souhaitez le convertir en type numérique, vous pouvez utiliser le paramètre de pipeline avec la fonction int ou la fonction float. Par exemple, int(activity('lookup').output.firstRow.VALUE),float(activity('lookup').output.firstRow.VALUE) |
BigDecimal n’est pas pris en charge dans l’activité de recherche. |
Les propriétés accountIdentifier, warehouse, database, schema et role sont utilisées pour établir une connexion. |
La propriété connectionstring est utilisée pour établir une connexion. |
| Le type de données timestamp dans Snowflake est lu comme type de données DateTimeOffset dans les activités Lookup et Script. | Le type de données timestamp dans Snowflake est lu en tant que type de données DateTime dans les activités Lookup et Script. Si vous devez toujours utiliser la valeur Datetime comme paramètre dans votre pipeline après la mise à niveau du connecteur, vous pouvez convertir le type DateTimeOffset en type DateTime à l’aide de la fonction formatDateTime (recommandée) ou de la fonction concat. Par exemple : formatDateTime(activity('lookup').output.firstRow.DATETIMETYPE), concat(substring(activity('lookup').output.firstRow.DATETIMETYPE, 0, 19), 'Z') |
Contenu connexe
Consultez les formats et magasins de données pris en charge pour obtenir la liste des sources et magasins de données pris en charge en tant que récepteurs par l’activité Copy.