Tutoriel : créer, évaluer et noter un modèle de prédiction d’attrition
Ce tutoriel présente un exemple de bout en bout d’un workflow Synapse Data Science dans Microsoft Fabric. Le scénario construit un modèle pour prédire si les clients bancaires se désengagent ou non. Le taux de résiliation, ou le taux d'attrition, implique le taux auquel les clients bancaires mettent fin à leur relation avec la banque.
Ce tutoriel décrit les étapes suivantes :
- Installer des bibliothèques personnalisées
- Charger les données
- Comprendre et traiter les données par le biais d’une analyse exploratoire des données et montrer l’utilisation de la fonctionnalité Fabric Data Wrangler
- Utiliser scikit-learn et LightGBM pour entraîner des modèles d'apprentissage automatique et suivre des expériences avec les fonctionnalités de journalisation automatique de MLflow et Fabric.
- Évaluer et enregistrer le modèle Machine Learning final
- Afficher les performances du modèle avec les visualisations Power BI
Conditions préalables
Souscrivez à un abonnement Microsoft Fabric . Vous pouvez également vous inscrire à une version d’évaluation gratuite de Microsoft Fabric .
Connectez-vous à Microsoft Fabric.
Utilisez le sélecteur d’expérience en bas à gauche de votre page d’accueil pour basculer vers Fabric.
- Si nécessaire, créez un lakehouse Microsoft Fabric comme décrit dans Créer un lakehouse dans Microsoft Fabric.
Suivez avec un carnet
Vous pouvez choisir l’une de ces options à suivre dans un bloc-notes :
- Ouvrez et exécutez le notebook intégré.
- Chargez votre bloc-notes à partir de GitHub.
Ouvrir le notebook intégré
L’échantillon de fidélisation de la clientèle carnet accompagne ce didacticiel.
Pour ouvrir l’exemple de notebook pour ce didacticiel, suivez les instructions de Préparer votre système pour les didacticiels de science des données.
Assurez-vous d’attacher un lakehouse au notebook avant de commencer à exécuter du code.
Importer le notebook à partir de GitHub
Le bloc-notes AIsample - Bank Customer Churn.ipynb est fourni avec ce tutoriel.
Pour ouvrir le bloc-notes associé pour ce didacticiel, suivez les instructions de Préparer votre système pour les didacticiels de science des données pour importer le bloc-notes dans votre espace de travail.
Si vous préférez copier et coller le code à partir de cette page, vous pouvez créer un bloc-notes.
Assurez-vous d'attacher un lakehouse au notebook avant de commencer à exécuter du code.
Étape 1 : Installer des bibliothèques personnalisées
Pour le développement de modèles Machine Learning ou l’analyse des données ad hoc, vous devrez peut-être installer rapidement une bibliothèque personnalisée pour votre session Apache Spark. Vous avez deux options d’installation des bibliothèques.
- Utilisez les fonctionnalités d’installation inline (
%pipou%conda) de votre notebook pour installer une bibliothèque, dans votre bloc-notes actuel uniquement. - Vous pouvez également créer un environnement Fabric, installer des bibliothèques à partir de sources publiques ou charger des bibliothèques personnalisées vers celui-ci, puis l’administrateur de votre espace de travail peut attacher l’environnement comme valeur par défaut pour l’espace de travail. Toutes les bibliothèques de l’environnement seront ensuite disponibles pour être utilisées dans les blocs-notes et les définitions de travaux Spark dans l’espace de travail. Pour plus d’informations sur les environnements, consultez créer, configurer et utiliser un environnement dans Microsoft Fabric.
Pour ce tutoriel, utilisez %pip install pour installer la bibliothèque de imblearn dans votre notebook.
Remarque
Le noyau PySpark redémarre après l’exécution de %pip install. Installez les bibliothèques nécessaires avant d’exécuter d’autres cellules.
# Use pip to install libraries
%pip install imblearn
Étape 2 : Charger les données
Le jeu de données dans churn.csv contient le statut de résiliation de 10 000 clients, ainsi que 14 attributs qui incluent :
- Score de crédit
- Emplacement géographique (Allemagne, France, Espagne)
- Sexe (mâle, femelle)
- Âge
- Mandat (nombre d’années où la personne était cliente à cette banque)
- Solde du compte
- Salaire estimé
- Nombre de produits achetés par le biais de la banque
- État de la carte de crédit (qu’un client dispose ou non d’une carte de crédit)
- Statut de membre actif (qu’il s’agisse ou non d’un client bancaire actif)
Le jeu de données inclut également le numéro de ligne, l’ID client et les colonnes de nom de client. Les valeurs de ces colonnes ne doivent pas influencer la décision d’un client de quitter la banque.
Un événement de fermeture de compte bancaire client définit l’évolution pour ce client. La colonne Exited du jeu de données fait référence à l’abandon du client. Étant donné que nous avons peu de contexte sur ces attributs, nous n’avons pas besoin d’informations générales sur le jeu de données. Nous voulons comprendre comment ces attributs contribuent à l’état Exited.
Sur ces 10 000 clients, seuls 2037 clients (environ 20%) ont quitté la banque. En raison du déséquilibre de classes, nous vous recommandons de générer des données synthétiques. La précision de la matrice de confusion peut ne pas avoir de pertinence pour la classification déséquilibrée. Nous pouvons mesurer la précision à l’aide de la zone sous la courbe de Precision-Recall (AUPRC).
- Ce tableau affiche un aperçu des données
churn.csv:
| CustomerID | Nom de famille | Score de crédit | Géographie | Sexe | Âge | Titularisation | Équilibre | NumOfProducts | HasCrCard | EstMembreActif | Salaire estimé | Sorti |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15634602 | Hargrave | 619 | France | Femelle | 42 | 2 | 0,00 | 1 | 1 | 1 | 101348.88 | 1 |
| 15647311 | Colline | 608 | Espagne | Femelle | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
Téléchargez le jeu de données et chargez-le dans le lakehouse
Définissez ces paramètres pour pouvoir utiliser ce notebook avec différents jeux de données :
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only SAMPLE_ROWS of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/churn" # Folder with data files
DATA_FILE = "churn.csv" # Data file name
Ce code télécharge une version publiquement disponible du jeu de données, puis stocke ce jeu de données dans un lac Fabric :
Important
Ajoutez un lakehouse au bloc-notes avant de le lancer. L’échec de cette opération entraîne une erreur.
import os, requests
if not IS_CUSTOM_DATA:
# With an Azure Synapse Analytics blob, this can be done in one line
# Download demo data files into the lakehouse if they don't exist
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/bankcustomerchurn"
file_list = ["churn.csv"]
download_path = "/lakehouse/default/Files/churn/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Commencez à enregistrer le temps nécessaire pour exécuter le notebook :
# Record the notebook running time
import time
ts = time.time()
Lire des données brutes à partir du lakehouse
Ce code lit les données brutes de la section Dossiers du lakehouse et ajoute d’autres colonnes pour différentes parties de date. La création de la table delta partitionnée utilise ces informations.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Créer un DataFrame pandas à partir du jeu de données
Ce code convertit le DataFrame Spark en DataFrame pandas pour faciliter le traitement et la visualisation :
df = df.toPandas()
Étape 3 : Effectuer une analyse exploratoire des données
Afficher des données brutes
Explorez les données brutes avec display, calculez certaines statistiques de base et affichez des vues de graphique. Vous devez d’abord importer les bibliothèques requises pour la visualisation des données , par exemple, seaborn. Seaborn est une bibliothèque de visualisation de données Python et fournit une interface de haut niveau pour créer des visuels sur des trames de données et des tableaux.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Utiliser Data Wrangler pour effectuer le nettoyage initial des données
Lancez « Data Wrangler » directement à partir du notebook pour explorer et transformer des dataframes de pandas. Sélectionnez la liste déroulante Data Wrangler dans la barre d’outils horizontale pour parcourir les DataFrames pandas activés disponibles pour modification. Sélectionnez le DataFrame que vous souhaitez ouvrir dans Data Wrangler.
Remarque
Data Wrangler ne peut pas être ouvert pendant que le noyau du notebook est occupé. L’exécution de la cellule doit se terminer avant de lancer Data Wrangler. En savoir plus sur data Wrangler.

Après le lancement de Data Wrangler, une vue d’ensemble descriptive du panneau de données est générée, comme illustré dans les images suivantes. La vue d’ensemble comprend des informations sur la dimension du DataFrame, les valeurs manquantes, etc. Vous pouvez utiliser Data Wrangler pour générer le script pour supprimer les lignes avec des valeurs manquantes, les lignes dupliquées et les colonnes avec des noms spécifiques. Vous pouvez ensuite copier le script dans une cellule. La cellule suivante montre le script copié.


def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
Déterminer les attributs
Ce code détermine les attributs catégoriels, numériques et cibles :
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
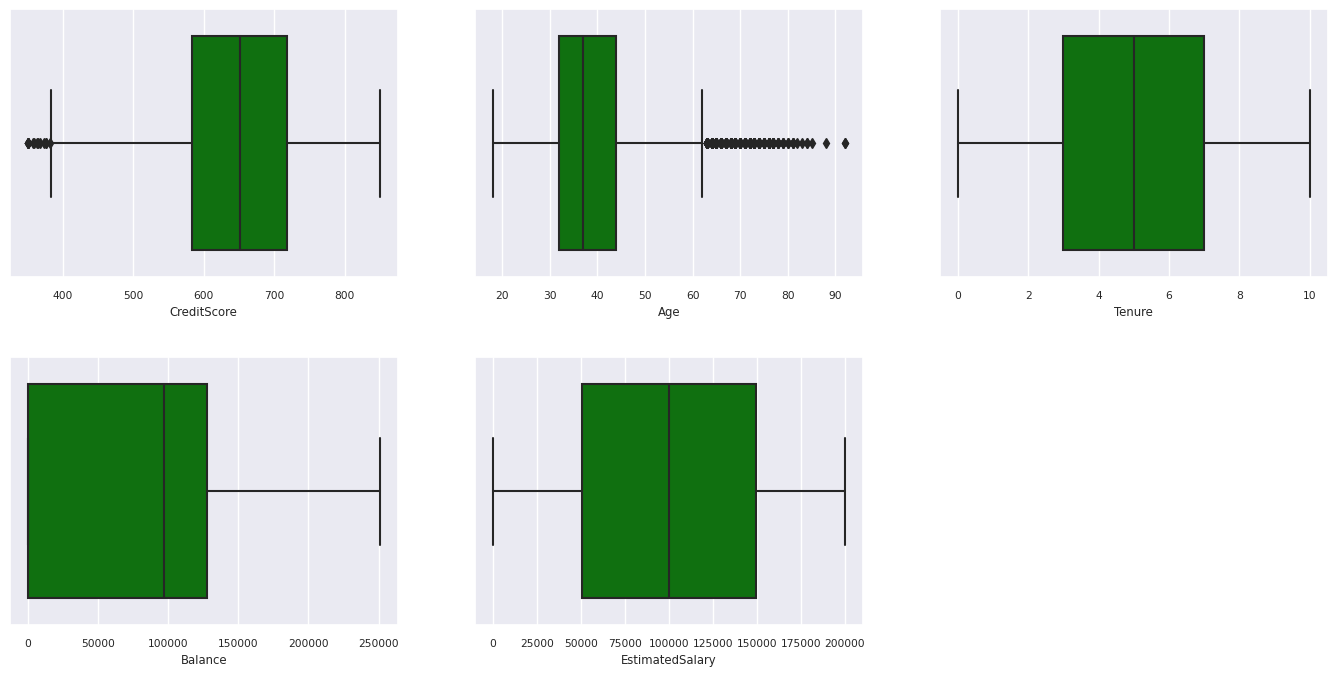
Afficher le résumé à cinq nombres
Utiliser des tracés de zone pour afficher le résumé à cinq nombres
- le score minimal
- premier quartile
- médiane
- troisième quartile
- score maximal
pour les attributs numériques.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
# fig.suptitle('visualize and compare the distribution and central tendency of numerical attributes', color = 'k', fontsize = 12)
fig.delaxes(axes[1,2])
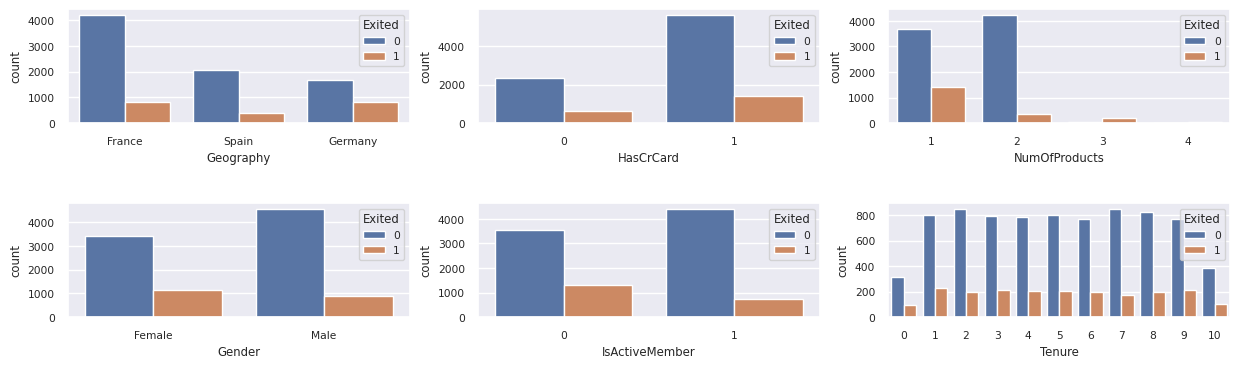
Afficher la distribution des clients sortants et non sortants
Affichez la distribution des clients sortants et non sortants, entre les attributs catégoriels :
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
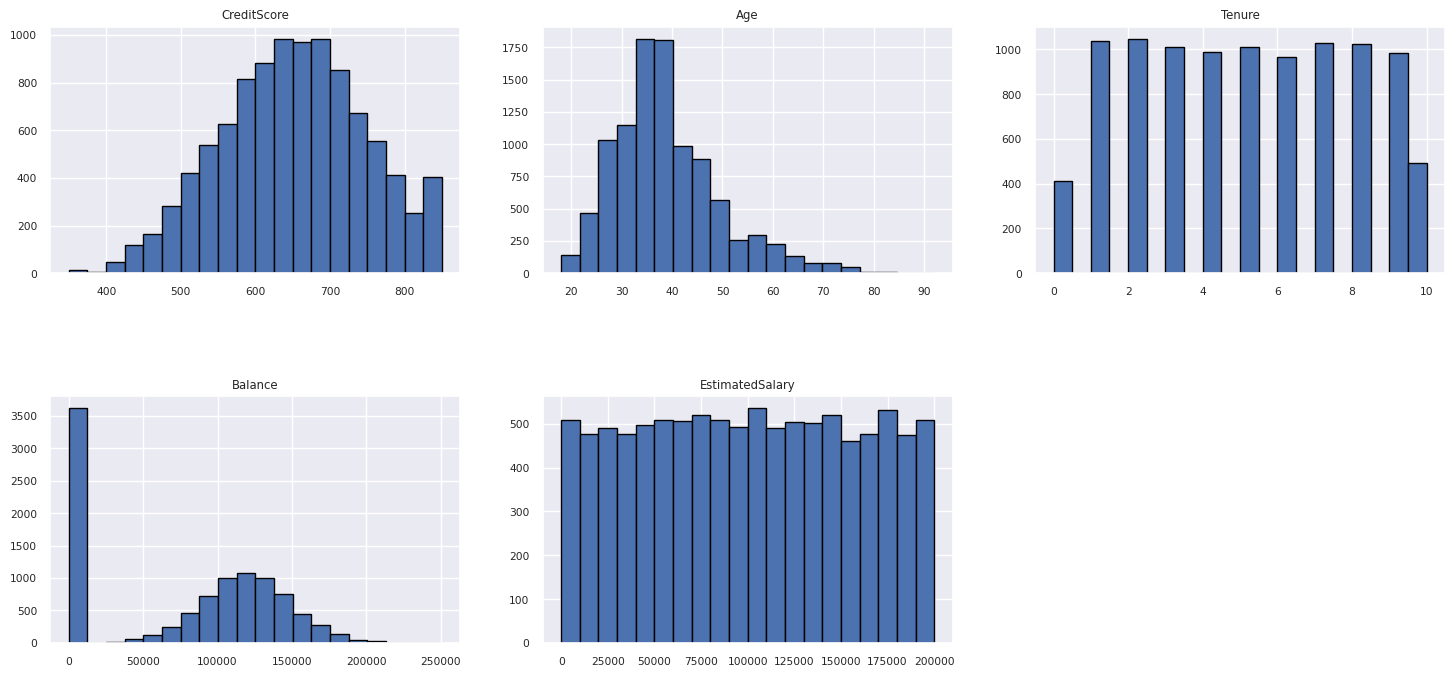
Afficher la distribution des attributs numériques
Utilisez un histogramme pour afficher la distribution de fréquence des attributs numériques :
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
# fig = fig.suptitle('distribution of numerical attributes', color = 'r' ,fontsize = 14)
plt.show()
Effectuer l’ingénierie des fonctionnalités
Cette ingénierie de fonctionnalité génère de nouveaux attributs en fonction des attributs actuels :
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Utiliser Data Wrangler pour effectuer un encodage à chaud
Avec les mêmes étapes pour lancer Data Wrangler, comme indiqué précédemment, utilisez Data Wrangler pour effectuer un encodage à chaud. Cette cellule affiche le script généré, copié pour l'encodage one-hot :


df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
Créer une table delta pour générer le rapport Power BI
table_name = "df_clean"
# Create a PySpark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Résumé des observations de l’analyse exploratoire des données
- La plupart des clients sont de France. L’Espagne a le taux d’attrition le plus bas, comparé à la France et à l’Allemagne.
- La plupart des clients ont des cartes de crédit
- Certains clients ont plus de 60 ans et ont des scores de crédit inférieurs à 400. Toutefois, elles ne peuvent pas être considérées comme des valeurs hors norme
- Très peu de clients ont plus de deux produits bancaires
- Les clients inactifs ont un taux de désabonnement plus élevé
- Les années d’occupation et de sexe ont peu d’impact sur la décision d’un client de fermer un compte bancaire
Étape 4 : Effectuer l’entraînement et le suivi des modèles
Avec les données en place, vous pouvez maintenant définir le modèle. Appliquez des modèles de forêt aléatoire et LightGBM dans ce carnet.
Utilisez les bibliothèques scikit-learn et LightGBM pour implémenter les modèles, avec quelques lignes de code. En outre, utilisez MLfLow et Fabric Autologging pour suivre les expériences.
Cet exemple de code charge la table delta à partir du lakehouse. Vous pouvez utiliser d’autres tables delta qui utilisent elles-mêmes le lac comme source.
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Générer une expérience pour le suivi et la journalisation des modèles à l’aide de MLflow
Cette section montre comment générer une expérience et spécifie les paramètres de modèle et d’entraînement et les métriques de scoring. En outre, il montre comment entraîner les modèles, les journaliser et enregistrer les modèles entraînés pour une utilisation ultérieure.
import mlflow
# Set up the experiment name
EXPERIMENT_NAME = "sample-bank-churn-experiment" # MLflow experiment name
L’autologging capture automatiquement les valeurs des paramètres d’entrée et les métriques de sortie d’un modèle Machine Learning, car ce modèle est entraîné. Ces informations sont ensuite consignées dans votre espace de travail, où les API MLflow ou l’expérience correspondante dans votre espace de travail peuvent y accéder et les visualiser.
Une fois terminée, votre expérience ressemble à cette image :

Toutes les expériences avec leurs noms respectifs sont journalisées et vous pouvez suivre leurs paramètres et métriques de performances. Pour en savoir plus sur l’autologging, consultez autologging dans Microsoft Fabric.
Définir les spécifications d'expérience et de journalisation automatique
mlflow.set_experiment(EXPERIMENT_NAME) # Use a date stamp to append to the experiment
mlflow.autolog(exclusive=False)
Importer scikit-learn et LightGBM
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Préparer des jeux de données d’entraînement et de test
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Train/test separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
Appliquer SMOTE aux données d’apprentissage
La classification déséquilibrée a un problème, car il a trop peu d’exemples de la classe minoritaire pour qu’un modèle apprenne efficacement la limite de décision. Pour gérer cela, la méthode SMOTE (Synthetic Minority Oversampling Technique) est la technique la plus couramment utilisée pour synthétiser de nouveaux échantillons pour la classe minoritaire. Accédez à SMOTE avec la bibliothèque imblearn que vous avez installée à l’étape 1.
Appliquez SMOTE uniquement au jeu de données d’entraînement. Vous devez laisser le jeu de données de test dans sa distribution déséquilibrée d’origine pour obtenir une approximation valide des performances du modèle sur les données d’origine. Cette expérience représente la situation en production.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Pour plus d'informations, consultez SMOTE et Du suréchantillonnage aléatoire à SMOTE et ADASYN. Le site web d’apprentissage déséquilibré héberge ces ressources.
Entraîner le modèle
Utilisez la forêt aléatoire pour entraîner le modèle, avec une profondeur maximale de quatre et quatre caractéristiques :
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_test, y_test)
y_pred = rfc1_sm.predict(X_test)
cr_rfc1_sm = classification_report(y_test, y_pred)
cm_rfc1_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
Utilisez la forêt aléatoire pour entraîner le modèle, avec une profondeur maximale de huit et six fonctionnalités :
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_test, y_test)
y_pred = rfc2_sm.predict(X_test)
cr_rfc2_sm = classification_report(y_test, y_pred)
cm_rfc2_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
Entraîner le modèle avec LightGBM :
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cr_lgbm_sm = classification_report(y_test, y_pred)
cm_lgbm_sm = confusion_matrix(y_test, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Afficher l’artefact d’expérience pour suivre les performances du modèle
Les exécutions de l’expérience sont automatiquement enregistrées dans l’artefact de l’expérience. Vous pouvez trouver cet artefact dans l’espace de travail. Un nom d’artefact est basé sur le nom utilisé pour définir l’expérience. Tous les modèles entraînés, leurs exécutions, les métriques de performances et les paramètres de modèle sont enregistrés sur la page de l’expérience.
Pour afficher vos expériences :
- Dans le volet gauche, sélectionnez votre espace de travail.
- Recherchez et sélectionnez le nom de l’expérience, dans ce cas, sample-bank-churn-experiment.
Étape 5 : Évaluer et enregistrer le modèle Machine Learning final
Ouvrez l’expérience enregistrée à partir de l’espace de travail pour sélectionner et enregistrer le meilleur modèle :
# Define run_uri to fetch the model
# MLflow client: mlflow.model.url, list model
load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model")
load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model")
load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model")
Évaluer les performances des modèles enregistrés sur le jeu de données de test
ypred_rfc1_sm = load_model_rfc1_sm.predict(X_test) # Random forest with maximum depth of 4 and 4 features
ypred_rfc2_sm = load_model_rfc2_sm.predict(X_test) # Random forest with maximum depth of 8 and 6 features
ypred_lgbm1_sm = load_model_lgbm1_sm.predict(X_test) # LightGBM
Afficher les vrais/faux positifs/négatifs à l’aide d’une matrice de confusion
Pour évaluer la précision de la classification, générez un script qui trace la matrice de confusion. Vous pouvez également tracer une matrice de confusion à l’aide d’outils SynapseML, comme indiqué dans l’exemple Détection des fraudes.
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
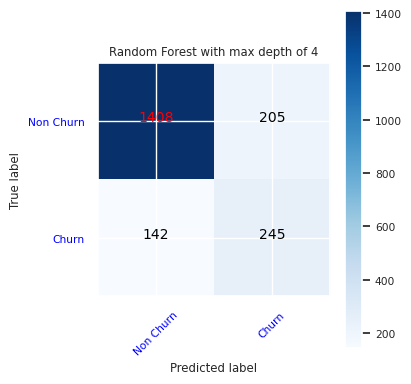
Créez une matrice de confusion pour le classifieur de forêt aléatoire, avec une profondeur maximale de quatre, avec quatre caractéristiques :
cfm = confusion_matrix(y_test, y_pred=ypred_rfc1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
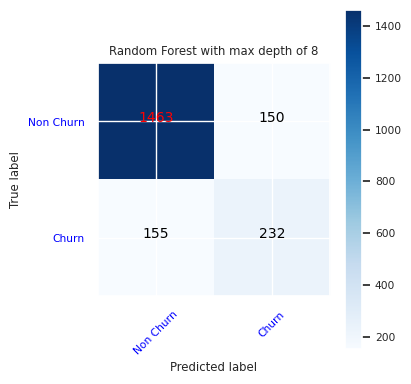
Créez une matrice de confusion pour le classifieur de forêt aléatoire avec une profondeur maximale de huit, avec six caractéristiques :
cfm = confusion_matrix(y_test, y_pred=ypred_rfc2_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
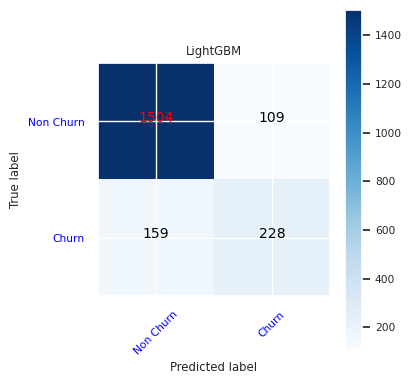
Créez une matrice de confusion pour LightGBM :
cfm = confusion_matrix(y_test, y_pred=ypred_lgbm1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()
Enregistrer les résultats pour Power BI
Enregistrez la trame delta dans le lakehouse afin de transférer les résultats de prédiction du modèle vers une visualisation Power BI.
df_pred = X_test.copy()
df_pred['y_test'] = y_test
df_pred['ypred_rfc1_sm'] = ypred_rfc1_sm
df_pred['ypred_rfc2_sm'] =ypred_rfc2_sm
df_pred['ypred_lgbm1_sm'] = ypred_lgbm1_sm
table_name = "df_pred_results"
sparkDF=spark.createDataFrame(df_pred)
sparkDF.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Étape 6 : Accéder aux visualisations dans Power BI
Accédez à votre table enregistrée dans Power BI :
- Sur la gauche, sélectionnez OneLake.
- Sélectionnez le lakehouse que vous avez ajouté à ce notebook.
- Dans la section Ouvrir ce Lakehouse, sélectionnez Ouvrir.
- Dans le ruban, sélectionnez nouveau modèle sémantique. Sélectionnez
df_pred_results, puis sélectionnez Confirmer pour créer un modèle sémantique Power BI lié aux prédictions. - Ouvrez un nouveau modèle sémantique. Vous pouvez le trouver dans OneLake.
- Sélectionnez Créer un rapport sous fichier à partir des outils en haut de la page modèles sémantiques pour ouvrir la page de création de rapports Power BI.
La capture d’écran suivante montre quelques exemples de visualisations. Le panneau de données affiche les tables et colonnes delta à sélectionner dans une table. Après avoir sélectionné l'axe de catégorie (x) et l'axe de valeur (y), vous pouvez choisir les filtres et les fonctions, par exemple, la somme ou la moyenne de la colonne du tableau.
Remarque
Dans cette capture d’écran, l’exemple illustré décrit l’analyse des résultats de prédiction enregistrés dans Power BI :

Toutefois, pour un cas d’usage réel d’attrition des clients, l’utilisateur peut avoir besoin d’un ensemble plus approfondi d’exigences pour les visualisations à créer, basé sur l’expertise dans le domaine, et sur ce que l’équipe d’analyse et l’entreprise ont standardisé comme métriques.
Le rapport Power BI montre que les clients qui utilisent plus de deux des produits bancaires ont un taux d’évolution plus élevé. Toutefois, peu de clients avaient plus de deux produits. (Voir le tracé dans le volet inférieur gauche.) La banque doit collecter plus de données, mais doit également examiner d’autres fonctionnalités qui correspondent à davantage de produits.
Les clients bancaires en Allemagne ont un taux de résiliation plus élevé par rapport aux clients en France et en Espagne. (Voir le tracé dans le panneau inférieur droit). En fonction des résultats du rapport, une enquête sur les facteurs qui ont encouragé les clients à quitter peut aider.
Il y a plus de clients d’âge moyen (entre 25 et 45). Les clients entre 45 et 60 ont tendance à quitter plus.
Enfin, les clients avec des scores de crédit inférieurs quitteraient probablement la banque pour d’autres institutions financières. La banque devrait explorer les moyens d’encourager les clients avec des scores de crédit et des soldes de compte inférieurs à rester avec la banque.
# Determine the entire runtime
print(f"Full run cost {int(time.time() - ts)} seconds.")