Transformer les données en exécutant un notebook
L'activité Notebook en pipeline vous permet d'exécuter Notebook créé dans Microsoft Fabric. Vous pouvez créer une activité Notebook directement via l'interface utilisateur Fabric. Cet article fournit une procédure pas à pas qui décrit comment créer une activité Notebook à l'aide de l'interface utilisateur de Data Factory.
Ajouter une activité Notebook à un pipeline
Cette section décrit comment utiliser une activité Notebook dans un pipeline.
Prérequis
Pour commencer, vous devez remplir les conditions préalables suivantes :
- Un compte locataire avec un abonnement actif. Créez un compte gratuitement.
- Un espace de travail est créé.
- Un carnet est créé dans votre espace de travail. Pour créer un nouveau bloc-notes, reportez-vous à la section Comment créer des blocs-notes Microsoft Fabric.
Création de l'activité
Créez un nouveau pipeline dans votre espace de travail.
Recherchez Notebook dans le volet Activités du pipeline et sélectionnez-le pour l'ajouter au canevas du pipeline.
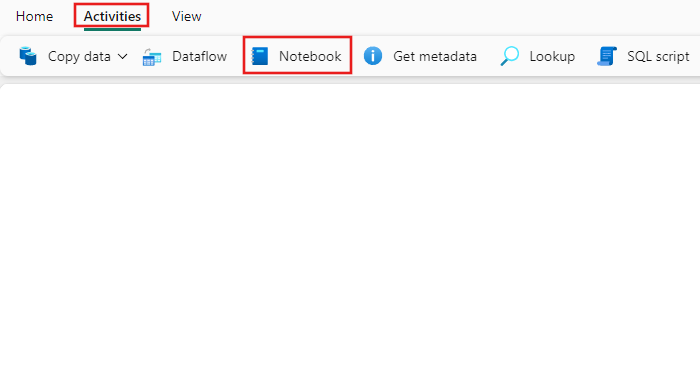
Sélectionnez la nouvelle activité Notebook sur le canevas si elle n'est pas déjà sélectionnée.
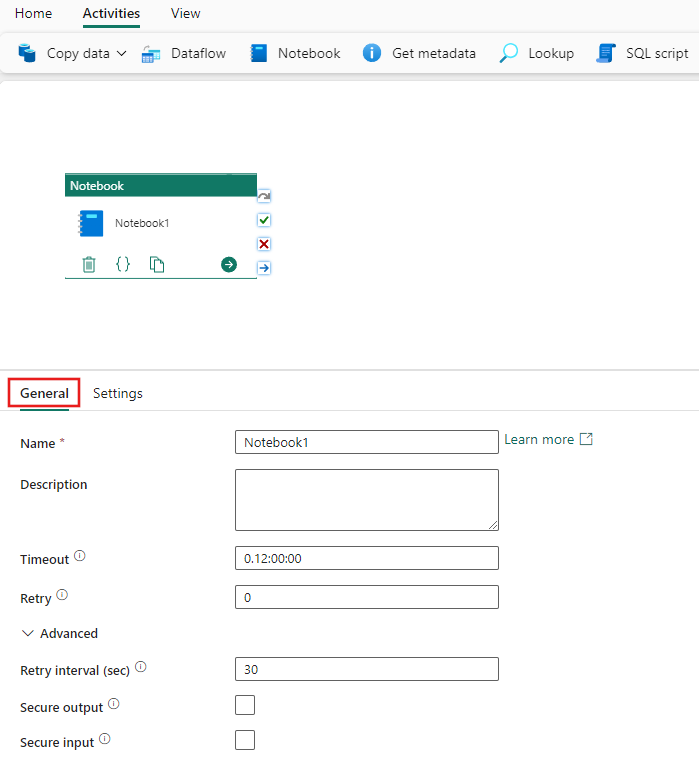
Reportez-vous aux instructions relatives aux paramètres Général pour configurer l’onglet Paramètres Général .
Paramètres du notebook
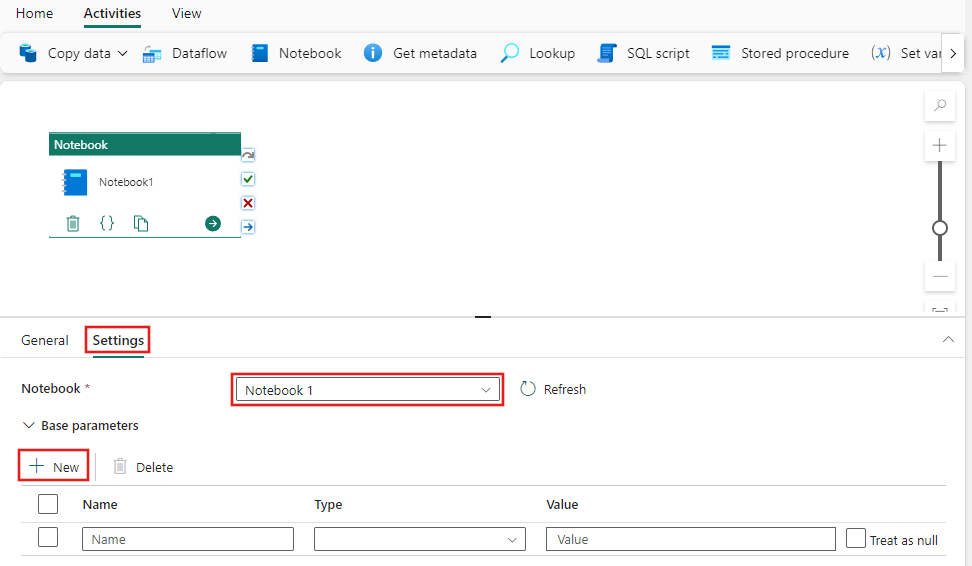
Sélectionnez l'onglet Paramètres, sélectionnez un Notebook existant dans la liste déroulante Bloc-notes et spécifiez éventuellement les paramètres à transmettre au bloc-notes.
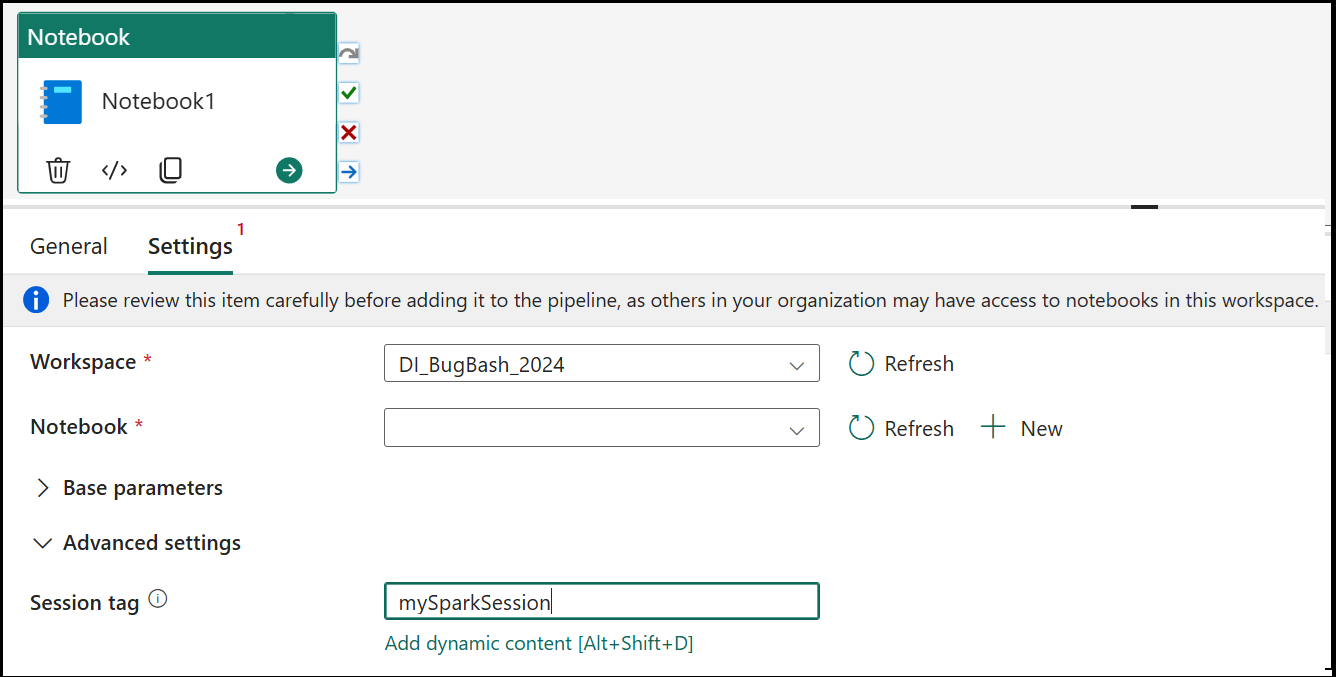
Balise de session
Pour réduire le temps nécessaire à l’exécution de votre travail de bloc-notes, vous pourriez éventuellement définir une balise de session. La définition de la balise de session demande à Spark de réutiliser une session Spark existante réduisant ainsi le temps de démarrage. Toute valeur de chaîne arbitraire peut être utilisée pour la balise de session. Si aucune session n’existe, une nouvelle session est créée à l’aide de la valeur de balise.
Remarque
Pour pouvoir utiliser la balise de session, le mode haute concurrence pour le pipeline exécutant plusieurs blocs-notes doit être activé. Cette option se trouve sous le mode haute concurrence pour les paramètres Spark dans les paramètres de l’espace de travail

Enregistrer et exécuter ou planifier le pipeline
Basculez vers l'onglet Accueil en haut de l'éditeur de pipeline et sélectionnez le bouton Enregistrer pour enregistrer votre pipeline. Sélectionnez Exécuter pour l'exécuter directement ou Planifier pour le planifier. Vous pouvez également afficher l'historique d'exécution ici ou configurer d'autres paramètres.
