S’abonner à des événements
Conseil
Ce contenu est un extrait du livre électronique « .NET Microservices Architecture for Containerized .NET Applications », disponible sur .NET Docs ou sous forme de PDF téléchargeable gratuitement et pouvant être lu hors ligne.

Pour utiliser Service Bus, vous devez d’abord abonner les microservices aux événements souhaités. Cette étape doit être effectuée dans les microservices récepteurs.
L’exemple de code suivant montre ce que chaque microservice récepteur doit implémenter au démarrage du service (dans la classe Startup) pour s’abonner aux événements dont il a besoin. Dans ce cas, le microservice basket-api doit s’abonner à ProductPriceChangedIntegrationEvent et aux messages OrderStartedIntegrationEvent.
Par exemple, quand il s’abonne à l’événement ProductPriceChangedIntegrationEvent, le microservice de panier d’achat est informé du changement de prix d’un produit et avertit l’utilisateur de ce changement si ce produit se trouve dans son panier.
var eventBus = app.ApplicationServices.GetRequiredService<IEventBus>();
eventBus.Subscribe<ProductPriceChangedIntegrationEvent,
ProductPriceChangedIntegrationEventHandler>();
eventBus.Subscribe<OrderStartedIntegrationEvent,
OrderStartedIntegrationEventHandler>();
Lorsque ce code est exécuté, le microservice abonné écoute via les canaux RabbitMQ. Quand un message de type ProductPriceChangedIntegrationEvent est reçu, le code appelle le gestionnaire d’événements qui lui est passé et traite l’événement.
Publication d’événements via le bus d’événements
Enfin, l’expéditeur du message (le microservice d’origine) publie les événements d’intégration avec du code similaire à celui de l’exemple suivant. (Cette approche est un exemple simplifié qui ne prend pas en compte l’atomicité.) Vous devez implémenter un code similaire chaque fois qu’un événement doit être propagé sur plusieurs microservices, généralement juste après la validation de données ou de transactions à partir du microservice d’origine.
Tout d’abord, l’objet d’implémentation du bus d’événements (basé sur RabbitMQ ou sur un bus de services) est injecté dans le constructeur du contrôleur, comme dans le code suivant :
[Route("api/v1/[controller]")]
public class CatalogController : ControllerBase
{
private readonly CatalogContext _context;
private readonly IOptionsSnapshot<Settings> _settings;
private readonly IEventBus _eventBus;
public CatalogController(CatalogContext context,
IOptionsSnapshot<Settings> settings,
IEventBus eventBus)
{
_context = context;
_settings = settings;
_eventBus = eventBus;
}
// ...
}
Ensuite, utilisez-le à partir des méthodes de votre contrôleur comme dans la méthode UpdateProduct :
[Route("items")]
[HttpPost]
public async Task<IActionResult> UpdateProduct([FromBody]CatalogItem product)
{
var item = await _context.CatalogItems.SingleOrDefaultAsync(
i => i.Id == product.Id);
// ...
if (item.Price != product.Price)
{
var oldPrice = item.Price;
item.Price = product.Price;
_context.CatalogItems.Update(item);
var @event = new ProductPriceChangedIntegrationEvent(item.Id,
item.Price,
oldPrice);
// Commit changes in original transaction
await _context.SaveChangesAsync();
// Publish integration event to the event bus
// (RabbitMQ or a service bus underneath)
_eventBus.Publish(@event);
// ...
}
// ...
}
Dans ce cas, le microservice d’origine étant un microservice CRUD simple, le code est placé dans un contrôleur d’API web.
Dans les microservices plus avancés, comme avec l’approche CQRS, vous pouvez l’implémenter dans la classe CommandHandler, dans la méthode Handle().
Conception de l’atomicité et de la résilience lors de la publication d’événements dans le bus d’événements
Quand vous publiez des événements d’intégration par le biais d’un système de messagerie distribuée comme votre bus d’événements, vous être confronté au problème de mettre à jour la base de données d’origine et de publier un événement de manière atomique (autrement dit, les deux opérations se terminent ou aucune des deux ne se termine). Par exemple, dans l’exemple simplifié précédent, le code valide les données dans la base de données lorsque le prix du produit est modifié, puis il publie un message ProductPriceChangedIntegrationEvent. Au début, il peut paraître essentiel que ces deux opérations soient effectuées de manière atomique. Toutefois, si vous utilisez une transaction distribuée impliquant la base de données et le répartiteur de messages comme vous le feriez sur les anciens systèmes tels que MSMQ (Microsoft Message Queuing), cette approche n’est pas recommandée pour les raisons énoncées par le théorème CAP.
Pour résumer, vous utilisez des microservices pour créer des systèmes évolutifs et hautement disponibles. Pour simplifier quelque peu, selon le théorème CAP, il n’est pas possible de générer une base de données (distribuée) (ou un microservice propriétaire de son modèle) qui soit continuellement disponible, fortement cohérente et tolérante à toutes les partitions. Vous ne pouvez avoir que deux de ces propriétés à la fois.
Dans les architectures basées sur les microservices, vous devez choisir la disponibilité et la tolérance, et donner moins d’importance à la cohérence. Par conséquent, dans les applications de microservice les plus récentes, il n’est généralement pas souhaitable d’utiliser des transactions distribuées pour la messagerie, comme vous le feriez pour implémenter des transactions distribuées DTC avec MSMQ.
Revenons au problème de départ et à son exemple. Si le service tombe en panne après la mise à jour de la base de données (dans ce cas, juste après la ligne de code avec _context.SaveChangesAsync()), mais avant la publication de l’événement d’intégration, l’ensemble du système risque de devenir incohérent. Cette approche peut être critique pour l’entreprise, selon le type d’opération métier concerné.
Comme déjà mentionné dans la section relative à l’architecture, plusieurs méthodes permettent de traiter ce problème :
Utiliser la version complète du modèle d’approvisionnement en événements
Utiliser l’exploration des données du journal des transactions
Utiliser le modèle de boîte d’envoi Il s’agit d’une table transactionnelle permettant de stocker les événements d’intégration (en étendant la transaction locale).
Pour ce scénario, l’utilisation du modèle d’approvisionnement en événements est l’une des meilleures approches, sinon la meilleure. Toutefois, dans de nombreux scénarios d’application, vous ne pourrez pas implémenter un système d’approvisionnement en événements complet. Avec l’approvisionnement en événements, vous stockez uniquement des événements de domaine dans votre base de données transactionnelle, au lieu de stocker les données de l’état actuel. Le fait de stocker uniquement les événements de domaine comporte des avantages, tels que la disponibilité de l’historique de votre système et la capacité à déterminer l’état antérieur de votre système. Toutefois, l’implémentation d’un système d’approvisionnement en événements complet nécessite la modification d’une grande partie de l’architecture de votre système, et ajoute de nombreuses exigences et davantage de complexité. Par exemple, vous pouvez utiliser une base de données créée spécialement pour l’approvisionnement en événements, telle qu’un magasin d’événements, ou une base de données orientée documents, telle qu’Azure Cosmos DB, MongoDB, Cassandra, CouchDB ou RavenDB. L’approvisionnement en événements est une excellente approche pour ce problème, mais ce n’est pas la plus simple, sauf si vous êtes déjà familiarisé avec l’approvisionnement en événements.
L’exploration du journal des transactions peut paraître simple au premier abord. Toutefois, pour cette méthode, vous devez associer le microservice à votre journal des transactions SGBDR, comme par exemple le journal des transactions SQL Server. Cette approche n’est probablement pas souhaitable. Un autre inconvénient à cela est que les mises à jour de bas niveau enregistrées dans le journal des transactions peuvent ne pas être au même niveau que les événements d’intégration de haut niveau. Si c’est le cas, il peut être difficile d’effectuer une rétroconception sur les opérations du journal des transactions.
La meilleure approche consiste à combiner une table de base de données transactionnelle et un modèle simplifié d’approvisionnement en événements. Vous pouvez utiliser un état du type « prêt à publier l’événement » que vous définissez dans l’événement d’origine quand vous le validez dans la table d’événements d’intégration. Ensuite, vous essayez de publier l’événement dans le bus d’événements. Si l’action de publication de l’événement réussit, démarrez une autre transaction dans le service d’origine, puis remplacez l’état « prêt à publier l’événement » par l’état « événement déjà publié ».
Si l’action de publication de l’événement échoue dans le bus d’événements, les données ne seront toujours pas incohérentes dans le microservice d’origine. Elles continueront d’être signalées comme étant « prêtes à publier l’événement », et par rapport aux autres services, elles seront cohérentes à terme. Vous pouvez toujours avoir des tâches en arrière-plan qui vérifient l’état des transactions ou des événements d’intégration. Si la tâche détecte un événement avec l’état « prêt à publier l’événement », elle peut tenter de republier cet événement dans le bus d’événements.
Notez qu’avec cette approche, vous conservez uniquement les événements d’intégration de chaque microservice d’origine, et uniquement les événements que vous souhaitez communiquer aux autres microservices ou systèmes externes. En revanche, dans un système d’approvisionnement en événements complet, tous les événements de domaine sont également stockés.
Par conséquent, cette approche mixte n’est autre qu’un système simplifié d’approvisionnement en événements. Vous avez besoin de la liste des événements d’intégration avec leur état actuel (« prêt pour la publication » ou « publié »). Toutefois, vous avez uniquement besoin d’implémenter ces états pour les événements d’intégration. En outre, avec cette approche, il n’est pas nécessaire de stocker toutes les données de votre domaine comme des événements dans la base de données transactionnelle, comme vous le feriez dans un système d’approvisionnement en événements complet.
Si vous utilisez déjà une base de données relationnelle, vous pouvez utiliser une table transactionnelle pour stocker les événements d’intégration. Pour obtenir l’atomicité de votre application, vous devez utiliser un processus en deux étapes basé sur les transactions locales. Pour résumer, une table IntegrationEvent doit se trouver dans la même base de données que vos entités de domaine. Cette table fonctionne comme une garantie d’obtention de l’atomicité, et vous permet d’inclure les événements d’intégration persistants dans les transactions qui valident vos données de domaine.
Voici, étape par étape, le déroulement de ce processus :
L’application commence une transaction de base de données locale.
Ensuite, elle met à jour l’état de vos entités de domaine et insère un événement dans la table d’événements d’intégration.
Enfin, elle valide la transaction pour vous permettre d’obtenir l’atomicité souhaitée, puis
Vous publiez l’événement d’une manière ou d’une autre (à venir).
Lorsque vous implémentez les étapes de publication des événements, vous avez les possibilités suivantes :
Publiez l’événement d’intégration juste après la validation de la transaction, puis utilisez une autre transaction locale pour marquer les événements de la table comme étant publiés. Ensuite, utilisez la table comme un artefact pour effectuer le suivi des événements d’intégration en cas de problèmes au niveau des microservices distants, puis effectuez des actions compensatoires en fonction des événements d’intégration stockés.
Utilisez la table comme un type de file d’attente. Un thread d’application ou un processus distinct interroge la table d’événements d’intégration, publie les événements dans le bus d’événements, puis utilise une transaction locale pour marquer les événements comme étant publiés.
La figure 6-22 montre l’architecture de la première de ces approches.
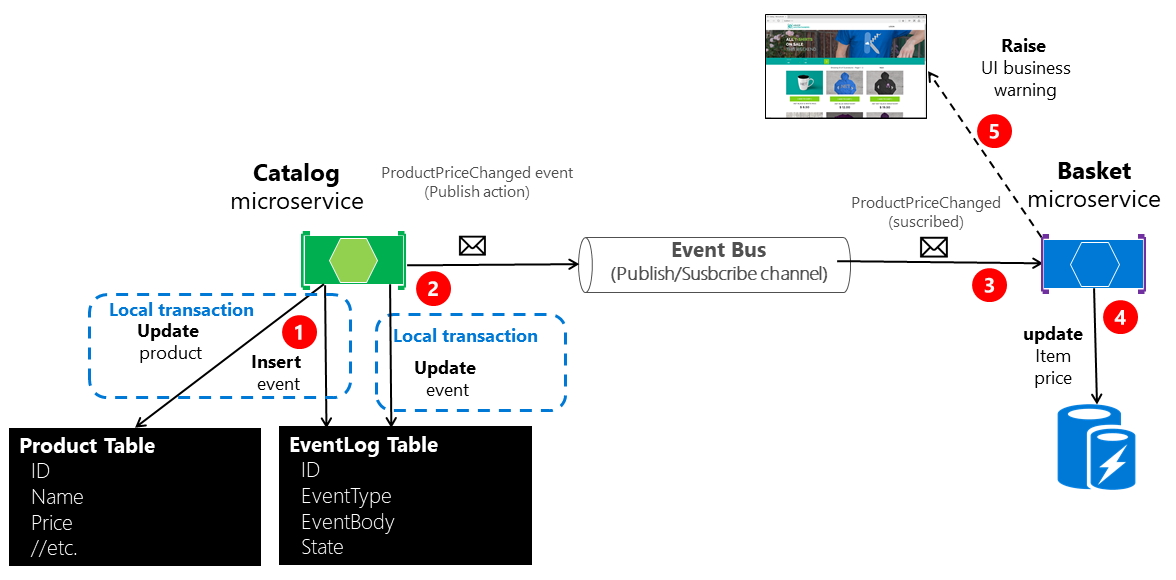
Figure 6-22. Atomicité lors de la publication d’événements dans le bus d’événements
Il manque à l’approche illustrée à la figure 6-22 un microservice de worker supplémentaire chargé de vérifier et de confirmer la publication des événements d’intégration. En cas d’échec, le microservice de worker de vérification supplémentaire peut lire les événements de la table et les republier (autrement dit, répétez l’étape 2).
Pour la deuxième approche, vous devez utiliser la table EventLog comme une file d’attente et toujours utiliser un microservice de worker pour publier les messages. Dans ce cas, le processus est similaire à celui illustré dans la figure 6-23. On y voit un microservice supplémentaire, ainsi que la table qui est la seule source lors de la publication d’événements.
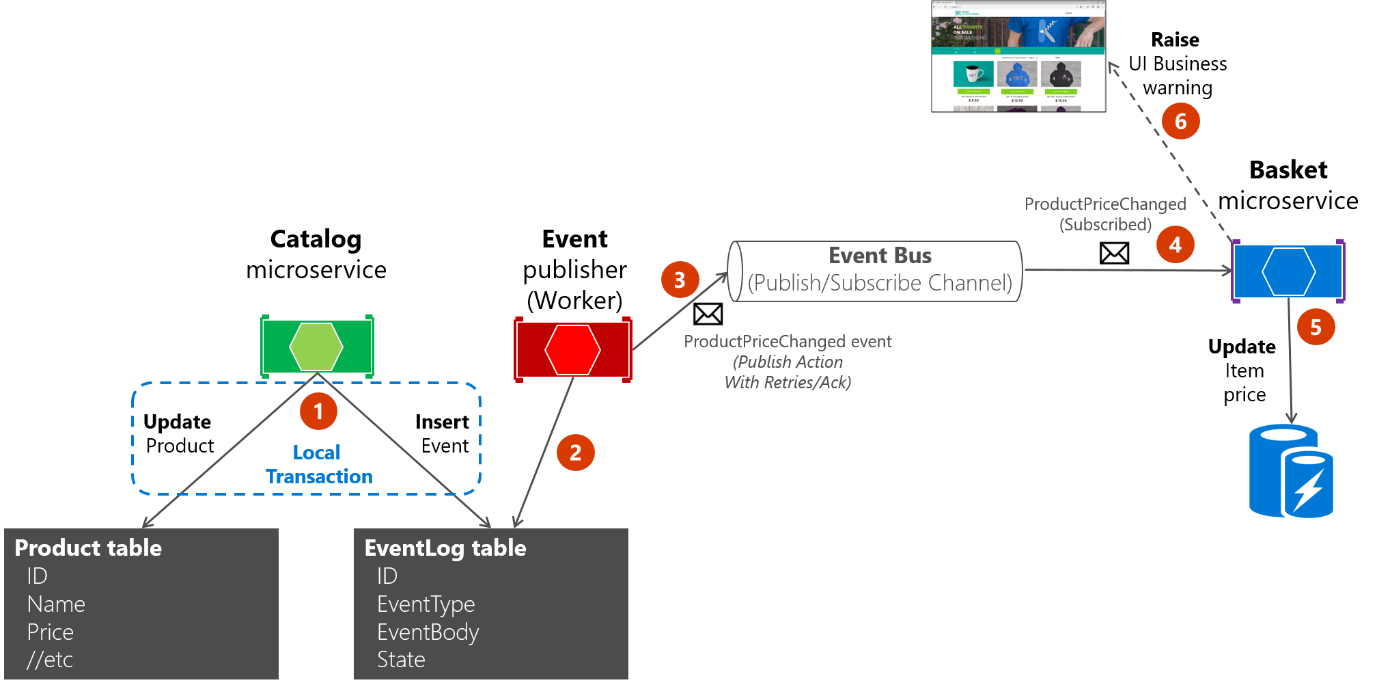
Figure 6-23. Atomicité lors de la publication d’événements dans le bus d’événements avec un microservice de worker
Par souci de simplicité, l’exemple eShopOnContainers utilise la première approche (sans processus ou microservices de vérification supplémentaires), ainsi que le bus d’événements. Toutefois, l’exemple eShopOnContainers ne gère pas tous les cas de défaillance possibles. Dans une application réelle déployée dans le cloud, vous devez accepter le fait que des problèmes surviendront un jour ou l’autre. Il est donc nécessaire d’implémenter cette logique de vérification et de renvoi. L’utilisation de la table comme une file d’attente peut se révéler plus efficace que la première approche si cette table est la seule source d’événements quand vous les publiez (avec le worker) à l’aide du bus d’événements.
Implémentation de l’atomicité lors de la publication d’événements d’intégration via le bus d’événements
Le code suivant montre comment vous pouvez créer une transaction impliquant plusieurs objets DbContext : un contexte lié aux données d’origine mises à jour, et le deuxième contexte lié à la table IntegrationEventLog.
La transaction de l’exemple de code ci-dessous ne sera pas résiliente si les connexions à la base de données rencontrent un problème quand le code est exécuté. Cela peut se produire dans les systèmes cloud comme Azure SQL DB, qui sont susceptibles de déplacer des bases de données d’un serveur à un autre. Pour implémenter des transactions résilientes dans plusieurs contextes, consultez la section Implémentation de connexions SQL à Entity Framework Core résilientes plus loin dans ce guide.
Pour plus de clarté, l’exemple suivant montre l’ensemble du processus dans un même bloc de code. Cependant, l’implémentation d’eShopOnContainers est refactorisée et divise cette logique en plusieurs classes pour faciliter sa gestion.
// Update Product from the Catalog microservice
//
public async Task<IActionResult> UpdateProduct([FromBody]CatalogItem productToUpdate)
{
var catalogItem =
await _catalogContext.CatalogItems.SingleOrDefaultAsync(i => i.Id ==
productToUpdate.Id);
if (catalogItem == null) return NotFound();
bool raiseProductPriceChangedEvent = false;
IntegrationEvent priceChangedEvent = null;
if (catalogItem.Price != productToUpdate.Price)
raiseProductPriceChangedEvent = true;
if (raiseProductPriceChangedEvent) // Create event if price has changed
{
var oldPrice = catalogItem.Price;
priceChangedEvent = new ProductPriceChangedIntegrationEvent(catalogItem.Id,
productToUpdate.Price,
oldPrice);
}
// Update current product
catalogItem = productToUpdate;
// Just save the updated product if the Product's Price hasn't changed.
if (!raiseProductPriceChangedEvent)
{
await _catalogContext.SaveChangesAsync();
}
else // Publish to event bus only if product price changed
{
// Achieving atomicity between original DB and the IntegrationEventLog
// with a local transaction
using (var transaction = _catalogContext.Database.BeginTransaction())
{
_catalogContext.CatalogItems.Update(catalogItem);
await _catalogContext.SaveChangesAsync();
await _integrationEventLogService.SaveEventAsync(priceChangedEvent);
transaction.Commit();
}
// Publish the integration event through the event bus
_eventBus.Publish(priceChangedEvent);
_integrationEventLogService.MarkEventAsPublishedAsync(
priceChangedEvent);
}
return Ok();
}
Une fois que l’événement d’intégration ProductPriceChangedIntegrationEvent a été créé, la transaction qui stocke l’opération de domaine d’origine (mise à jour de l’élément de catalogue) inclut également la persistance de l’événement dans la table EventLog. De cette façon, vous n’obtenez qu’une seule transaction, et vous pourrez toujours vérifier si les messages d’événement ont été envoyés.
La table du journal des événements est mise à jour atomiquement avec l’opération de base de données d’origine, à l’aide d’une transaction locale dans la même base de données. Si l’une des opérations échoue, une exception est levée et la transaction restaure toute opération terminée, de manière à maintenir la cohérence entre les opérations de domaine et les messages d’événement envoyés enregistrés dans la table.
Réception de messages provenant d’abonnements : les gestionnaires d’événements dans les microservices récepteurs
En plus de la logique d’abonnement aux événements, vous devez implémenter le code interne pour les gestionnaires d’événements d’intégration (comme une méthode de rappel). C’est dans le gestionnaire d’événements que vous spécifiez où les messages d’événement d’un certain type doivent être reçus et traités.
Un gestionnaire d’événements reçoit d’abord une instance d’événement provenant du bus d’événements. Il localise ensuite le composant à traiter qui est lié à cet événement d’intégration, en propageant et en conservant l’événement en tant que changement d’état dans le récepteur de microservice. Par exemple, si un événement ProductPriceChanged provient du microservice de catalogue, il est géré dans le microservice de panier d’achat et change également d’état dans le microservice de panier récepteur, comme indiqué dans le code suivant.
namespace Microsoft.eShopOnContainers.Services.Basket.API.IntegrationEvents.EventHandling
{
public class ProductPriceChangedIntegrationEventHandler :
IIntegrationEventHandler<ProductPriceChangedIntegrationEvent>
{
private readonly IBasketRepository _repository;
public ProductPriceChangedIntegrationEventHandler(
IBasketRepository repository)
{
_repository = repository;
}
public async Task Handle(ProductPriceChangedIntegrationEvent @event)
{
var userIds = await _repository.GetUsers();
foreach (var id in userIds)
{
var basket = await _repository.GetBasket(id);
await UpdatePriceInBasketItems(@event.ProductId, @event.NewPrice, basket);
}
}
private async Task UpdatePriceInBasketItems(int productId, decimal newPrice,
CustomerBasket basket)
{
var itemsToUpdate = basket?.Items?.Where(x => int.Parse(x.ProductId) ==
productId).ToList();
if (itemsToUpdate != null)
{
foreach (var item in itemsToUpdate)
{
if(item.UnitPrice != newPrice)
{
var originalPrice = item.UnitPrice;
item.UnitPrice = newPrice;
item.OldUnitPrice = originalPrice;
}
}
await _repository.UpdateBasket(basket);
}
}
}
}
Le gestionnaire d’événements doit vérifier si le produit se trouve dans une des instances du panier d’achat. Il met également à jour le prix de chaque article associé. Enfin, il crée une alerte pour l’utilisateur concernant le changement de prix, comme indiqué dans la figure 6-24.
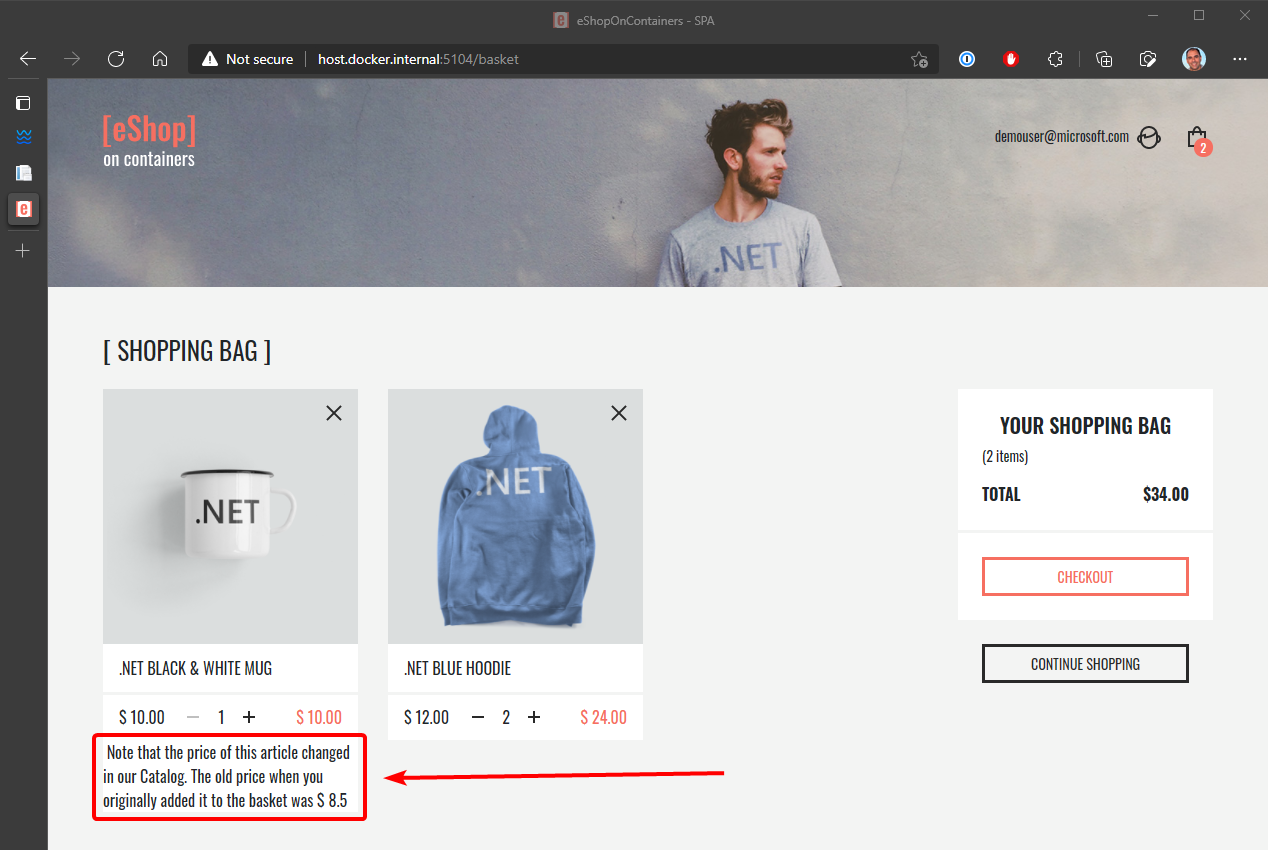
Figure 6-24. Affichage du changement de prix d’un article du panier, communiqué par les événements d’intégration
Idempotence des événements de mise à jour des messages
Un aspect important des événements de mise à jour des messages est qu’une défaillance se produisant à n’importe quel moment de la communication doit entraîner une nouvelle tentative de publication du message. Sinon, une tâche en arrière-plan pourrait tenter de publier un événement qui a déjà été publié, ce qui aurait pour effet de créer une condition de concurrence. Veillez à ce que les mises à jour soient idempotentes ou fournissent suffisamment d’informations pour que vous puissiez détecter un doublon, le supprimer et renvoyer une seule réponse.
Comme indiqué précédemment, l’idempotence signifie qu’une opération peut être effectuée plusieurs fois sans que le résultat soit modifié. Dans un environnement de messagerie, comme lorsque vous communiquez des événements, un événement est idempotent s’il peut être remis plusieurs fois sans modifier le résultat pour le microservice récepteur. Cela peut être nécessaire en raison de la nature de l’événement, ou en raison de la façon dont le système gère l’événement. L’idempotence des messages est importante dans les applications qui utilisent la messagerie, et pas seulement dans les applications qui implémentent le modèle de bus d’événements.
Un exemple d’opération idempotente est une instruction SQL qui insère des données dans une table uniquement si ces données ne s’y trouvent pas déjà. Quel que soit le nombre de fois que vous exécutez cette instruction SQL INSERT, le résultat sera le même et la table contiendra les mêmes données. Une telle idempotence peut également être nécessaire lorsque vous traitez des messages, si ces messages sont susceptibles d’être envoyés et donc traités plusieurs fois. Par exemple, si la logique de nouvelle tentative fait qu’un émetteur envoie exactement le même message plusieurs fois, vous devez vous assurer qu’il est idempotent.
Il est possible de concevoir des messages idempotents. Par exemple, vous pouvez créer un événement indiquant « fixer le prix du produit à 25 $ » au lieu de « ajouter 5 $ au prix du produit ». Vous pouvez traiter le premier message autant de fois que vous le souhaitez ; le résultat sera le même. Cependant, ce n’est pas vrai pour le deuxième message. Mais même dans le premier cas, il n’est pas forcément souhaitable de traiter le premier événement, car le système peut avoir envoyé un événement de changement de prix plus récent et vous écraseriez ainsi le nouveau prix.
Un autre exemple peut être un événement de commande terminée propagé vers plusieurs abonnés. L’application doit veiller à ce que les informations de commande ne soient mises à jour qu’une seule fois dans les autres systèmes, même s’il existe des événements de message en double pour le même événement de commande terminée.
Il peut être utile d’attribuer une identité à chaque événement, pour que vous puissiez créer une logique selon laquelle un événement ne doit être traité qu’une seule fois pour chaque récepteur.
Le traitement des messages est fondamentalement idempotent. Par exemple, si un système génère des images miniatures, le nombre de traitements du message concernant la génération des miniatures importe peu. Le résultat est que les miniatures sont générées et qu’elles sont identiques à chaque fois. En revanche, les opérations telles que l’appel d’une passerelle de paiement pour prélever un montant sur une carte de crédit peuvent ne pas être idempotentes du tout. Dans ce cas, vous devez être sûr que le fait de traiter un message plusieurs fois aura l’effet que vous attendez.
Ressources supplémentaires
- Honoring message idempotency
https://learn.microsoft.com/previous-versions/msp-n-p/jj591565(v=pandp.10)#honoring-message-idempotency
Déduplication des messages d’événements d’intégration
Vous pouvez faire en sorte que les événements de message ne soient envoyés et traités qu’une seule une fois par abonné à différents niveaux. L’une des méthodes possibles consiste à utiliser la fonctionnalité de déduplication proposée par l’infrastructure de messagerie que vous utilisez. Une autre consiste à implémenter une logique personnalisée dans votre microservice de destination. La meilleure solution est d’avoir des validations à la fois au niveau du transport et au niveau de l’application.
Déduplication d’événements de message au niveau d’EventHandler
Un moyen de s’assurer qu’un événement n’est traité qu’une seule fois par un récepteur est d’implémenter une logique spécifique lors du traitement des événements de message dans les gestionnaires d’événements. Il s’agit de l’approche utilisée dans l’application eShopOnContainers comme vous pouvez le voir dans le code source de la classe UserCheckoutAcceptedIntegrationEventHandler à la réception d’un événement d’intégration UserCheckoutAcceptedIntegrationEvent. (Dans le cas présent, nous wrappons l’objet CreateOrderCommand avec un IdentifiedCommand en utilisant le eventMsg.RequestId comme identificateur avant de l’envoyer au gestionnaire de commandes).
Déduplication de messages lors de l’utilisation de RabbitMQ
Lorsque des défaillances intermittentes du réseau se produisent, des messages peuvent être dupliqués et le récepteur des messages doit être prêt à gérer cette déduplication. Si possible, les récepteurs doivent gérer les messages de manière idempotente, ce qui est mieux que de les gérer explicitement avec la déduplication.
Conformément à la documentation RabbitMQ, si un message est remis à un utilisateur, puis est replacé dans la file d’attente (parce qu’il n’a pas été accepté avant la perte de la connexion de l’utilisateur, par exemple), RabbitMQ lui associe l’indicateur de redistribution quand il est remis à nouveau (au même utilisateur ou à un autre).
Si l’indicateur de redistribution est défini, le récepteur doit en tenir compte, car le message peut déjà avoir été traité. Toutefois, cela n’est pas garanti. Le message peut ne jamais avoir atteint le récepteur après avoir quitté le répartiteur de messages, peut-être en raison de problèmes de réseau. En revanche, si l’indicateur de redistribution n’est pas défini, il est garanti que le message n’a pas été envoyé plusieurs fois. Ainsi, le récepteur doit dédupliquer les messages ou les traiter de manière idempotente uniquement si l’indicateur de redistribution est défini dans le message.
Ressources supplémentaires
Forked eShopOnContainers using NServiceBus (Particular Software)
https://go.particular.net/eShopOnContainersEvent Driven Messaging
https://patterns.arcitura.com/soa-patterns/design_patterns/event_driven_messagingJimmy Bogard. Refactoring Towards Resilience: Evaluating Coupling
https://jimmybogard.com/refactoring-towards-resilience-evaluating-coupling/Publish-Subscribe channel
https://www.enterpriseintegrationpatterns.com/patterns/messaging/PublishSubscribeChannel.htmlCommunication entre contextes délimités
https://learn.microsoft.com/previous-versions/msp-n-p/jj591572(v=pandp.10)Eventual Consistency
https://en.wikipedia.org/wiki/Eventual_consistencyPhilip Brown. Strategies for Integrating Bounded Contexts
https://www.culttt.com/2014/11/26/strategies-integrating-bounded-contexts/Chris Richardson. Developing Transactional Microservices Using Aggregates, Event Sourcing and CQRS - Part 2
https://www.infoq.com/articles/microservices-aggregates-events-cqrs-part-2-richardsonChris Richardson. Modèle d'approvisionnement en événements
https://microservices.io/patterns/data/event-sourcing.htmlIntroducing Event Sourcing
https://learn.microsoft.com/previous-versions/msp-n-p/jj591559(v=pandp.10)Base de données du magasin d’événements. Site officiel.
https://geteventstore.com/Patrick Nommensen. Event-Driven Data Management for Microservices
https://dzone.com/articles/event-driven-data-management-for-microservices-1The CAP Theorem
https://en.wikipedia.org/wiki/CAP_theoremWhat is CAP Theorem?
https://www.quora.com/What-Is-CAP-Theorem-1Data Consistency Primer (Manuel d’introduction à la cohérence des données)
https://learn.microsoft.com/previous-versions/msp-n-p/dn589800(v=pandp.10)Rick Saling. The CAP Theorem: Why “Everything is Different” with the Cloud and Internet
https://learn.microsoft.com/archive/blogs/rickatmicrosoft/the-cap-theorem-why-everything-is-different-with-the-cloud-and-internet/Eric Brewer. CAP Twelve Years Later: How the "Rules" Have Changed
https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changedCAP, PACELC et microservices
https://ardalis.com/cap-pacelc-and-microservices/Azure Service Bus. Messagerie répartie : détection des doublons
https://github.com/microsoftarchive/msdn-code-gallery-microsoft/tree/master/Windows%20Azure%20Product%20Team/Brokered%20Messaging%20Duplicate%20DetectionReliability Guide (documentation RabbitMQ)
https://www.rabbitmq.com/reliability.html#consumer