Créer des travaux et des données d’entrée pour les points de terminaison de lot
Lorsque vous utilisez des points de terminaison de traitement par lots dans Azure Machine Learning, vous pouvez effectuer des opérations de traitement par lots longues sur de grandes quantités de données d’entrée. Les données peuvent être situées à différents endroits, par exemple dans des régions différentes. Certains types de points de terminaison de lot peuvent également recevoir des paramètres de littéraux en tant qu’entrées.
Cet article explique comment spécifier des entrées de paramètres pour les points de terminaison de lot et créer des travaux de déploiement. Le processus prend en charge l’utilisation des données provenant de différentes sources, telles que les ressources de données, les magasins de données, les comptes de stockage et les fichiers locaux.
Prérequis
Un point de terminaison par lots et un déploiement. Pour créer ces ressources, voir Déployer des modèles MLflow dans des déploiements par lots dans Azure Machine Learning.
Des autorisations pour exécuter un déploiement de point de terminaison par lots. Vous pouvez utiliser les rôles de scientifique des données AzureML, de Contributeur(-trice) et de propriétaire pour exécuter un déploiement. Pour examiner les autorisations spécifiques requises pour les définitions de rôles personnalisés, voir Autorisation sur les terminaux de traitement par lots.
Informations d’identification pour appeler un point de terminaison. Pour plus d’informations, consultez Établir une authentification.
Accès en lecture aux données d'entrée à partir de la grappe de calcul où le point final est déployé.
Conseil
Certaines situations nécessitent l’utilisation d’un magasin de données sans informations d’identification ou d’un compte de stockage Azure externe en tant qu’entrée de données. Dans ces scénarios, veillez à configurer des clusters de calcul pour l’accès aux données, car l’identité managée du cluster de calcul est utilisée pour monter le compte de stockage. Le contrôle d'accès reste granulaire, car l'identité du travail (invoker) est utilisée pour lire les données sous-jacentes.
Établir l’authentification
Pour appeler un point de terminaison, vous avez besoin d’un jeton Microsoft Entra valide. Lorsque vous avez appelé un point de terminaison, Azure Machine Learning crée un travail de déploiement par lots sous l’identité associée au jeton.
- Si vous utilisez Azure Machine Learning CLI (v2) ou Azure Machine Learning SDK for Python (v2) pour invoquer des points de terminaison, vous n'avez pas besoin d'obtenir manuellement le jeton Microsoft Entra. Pendant la connexion, le système authentifie votre identité utilisateur. Il récupère et transmet également le jeton pour vous.
- Si vous utilisez l’API REST pour appeler des points de terminaison, vous devez obtenir le jeton manuellement.
Vous pouvez utiliser vos propres informations d’identification pour l’appel, comme décrit dans les procédures suivantes.
Utilisez Azure CLI pour vous connecter avec l’authentification interactive ou par code d’appareil :
az login
Pour plus d’informations sur différents types d’informations d’identification, consultez Comment exécuter des travaux à l’aide de différents types d’informations d’identification.
Créer des travaux de base
Pour créer un travail à partir d’un point de terminaison de lot, vous appelez le point de terminaison. L’appel peut être effectué avec Azure Machine Learning CLI, le kit SDK Azure Machine Learning pour Python, ou un appel d’API REST.
Les exemples suivants montrent les principes de base d’un appel de point de terminaison de lot qui reçoit un seul dossier de données d’entrée à traiter. Pour obtenir des exemples qui impliquent plusieurs entrées et sorties, consultez Présentation des entrées et sorties.
Utilisez l’opération invoke sous des points de terminaison de lot :
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Appeler un déploiement spécifique
Les points de terminaison par lots peuvent héberger plusieurs déploiements sous le même point de terminaison. Le point de terminaison par défaut est utilisé, sauf si l’utilisateur le spécifiez autrement. Vous pouvez utiliser les procédures suivantes pour modifier le déploiement que vous utilisez.
Utilisez l’argument --deployment-name ou -d pour spécifier le nom du déploiement :
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Configurer les propriétés du travail
Vous pouvez configurer certaines propriétés de travail au moment de l’appel.
Remarque
Actuellement, vous ne pouvez configurer les propriétés des travaux que dans les points de terminaison batch avec les déploiements de composants de pipeline.
Configurer le nom de l’expérience
Appliquez les procédures suivantes pour configurer le nom de votre expérience.
Utilisez l’argument --experiment-name pour spécifier le nom de l’expérience :
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Présentation des entrées et des sorties
Les points de terminaison par lots fournissent une API durable que les consommateurs peuvent utiliser pour créer des programmes de traitement par lots. La même interface peut être utilisée pour spécifier les entrées et les sorties attendues par votre déploiement. Utilisez des entrées pour transmettre les informations dont votre point de terminaison a besoin pour effectuer le travail.
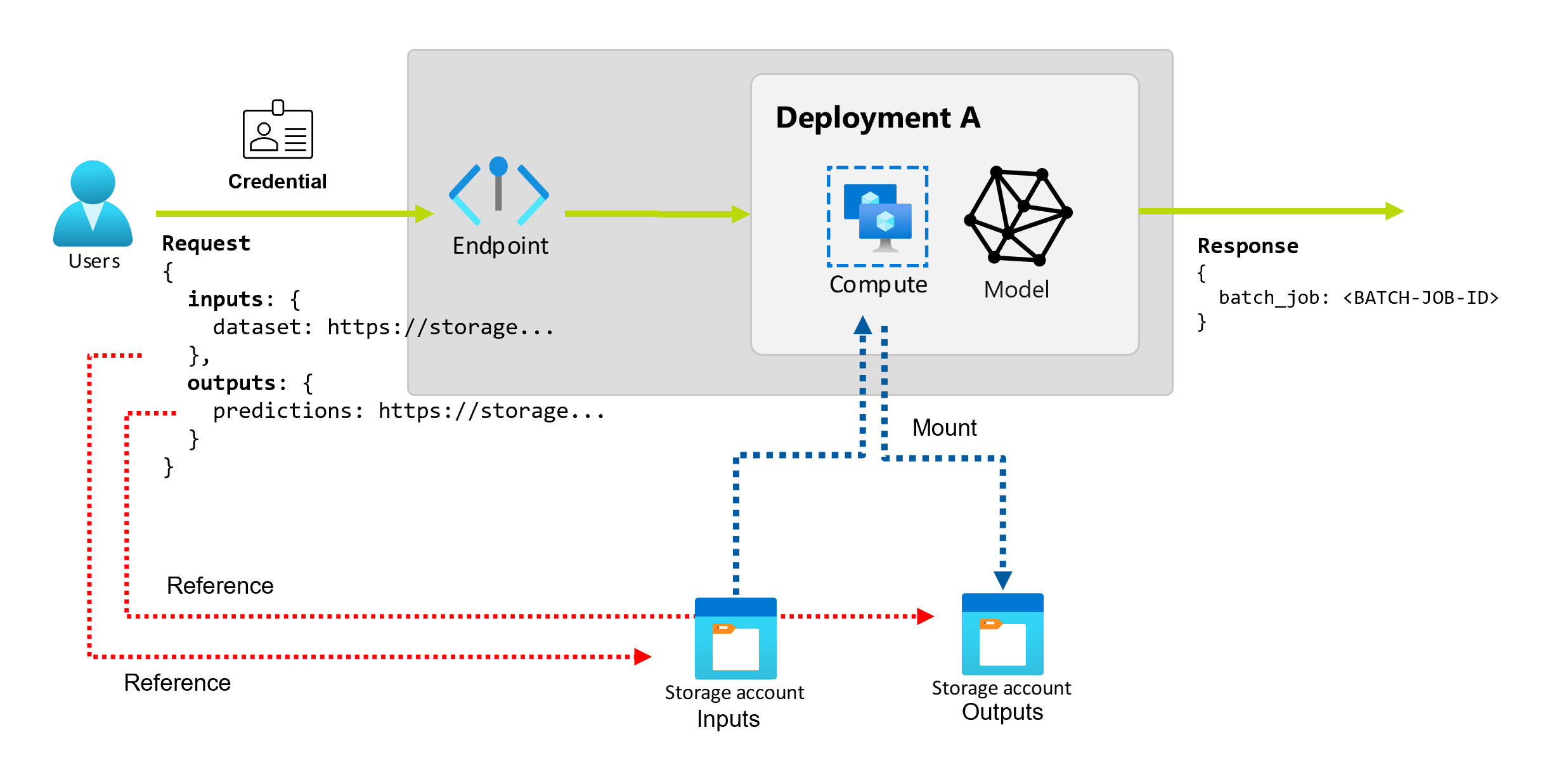
Les points de terminaison par lots prennent en charge deux types d’entrées :
- Entrées de données ou pointeurs vers un emplacement de stockage spécifique ou une ressource Azure Machine Learning
- Entrées littérales ou valeurs littérales, comme des nombres ou des chaînes, que vous souhaitez transmettre au travail
Le nombre et le type d’entrées et de sorties dépendent du type de déploiement par lots. Les modèles de déploiement nécessitent toujours une entrée de données et produisent une sortie de données. Les entrées littérales ne sont pas prises en charge dans les modèles de déploiements. En revanche, les déploiements de composants de pipeline offrent une structure plus générale pour la création de points de terminaison. Dans un déploiement de composant de pipeline, vous pouvez spécifier n’importe quel nombre d’entrées de données, d’entrées littérales et de sorties.
Le tableau suivant récapitule les entrées et sorties pour les déploiements par lots :
| Type de déploiement | Nombre d’entrées | Types d’entrée pris en charge | Nombre de sorties | Types de sortie pris en charge |
|---|---|---|---|---|
| Déploiement de modèle | 1 | Entrées de données | 1 | Sorties de données |
| Déploiement de composant de pipeline | 0-N | Entrées de données et entrées de littéral | 0-N | Sorties de données |
Conseil
Les entrées et sorties sont toujours nommées. Chaque nom sert de clé pour cerner les données et transmettre la valeur pendant l’appel. Les déploiements de modèles nécessitant toujours une entrée et une sortie, les noms sont ignorés lors de l'invocation dans les modèles de déploiements. Vous pouvez attribuer le nom qui correspond le mieux à votre cas d’usage, par exemple sales_estimation.
Explorer les entrées de données
Les entrées de données désignent les entrées qui pointent vers un emplacement où les données sont placées. Les points de terminaison de lot consommant généralement de grandes quantités de données, vous ne pouvez pas transmettre les données d’entrée dans le cadre de la demande d’appel. Au lieu de cela, vous devez spécifiez l’emplacement où le point de terminaison par lots doit se rendre pour rechercher les données. Les données d’entrée sont montées et diffusées en continu sur l’instance de calcul cible pour améliorer les performances.
Les points de terminaison Batch peuvent lire les fichiers situés dans les types de stockage suivants :
-
Ressources de données Azure Machine Learning, y compris les types de dossier (
uri_folder) et de fichier (uri_file). - Magasins de données Azure Machine Learning, y compris Stockage Blob Azure, Azure Data Lake Storage Gen1 et Azure Data Lake Storage Gen2.
- Comptes de stockage Azure, y compris Stockage Blob, Data Lake Storage Gen1, et Data Lake Storage Gen2.
- Dossiers et fichiers de données locaux, lorsque vous utilisez Azure Machine Learning CLI ou Azure Machine Learning SDK for Python pour invoquer des points de terminaison. Mais les données locales sont téléchargées dans le magasin de données par défaut de votre espace de travail Azure Machine Learning.
Important
Note relative à la suppression de fonctionnalités : les ressources de données de type FileDataset (V1) sont déconseillés et seront mis hors service à l’avenir. Les points de terminaison de lot existants qui s’appuient sur cette fonctionnalité continueront de fonctionner. Toutefois, il n’existe aucune prise en charge des jeux de données V1 dans les points de terminaison de traitement par lots créés avec :
- Versions d’Azure Machine Learning CLI v2 généralement disponibles (2.4.0 et versions ultérieures).
- Versions de l’API REST généralement disponibles (01-05-2022 et versions ultérieures).
Explorer les entrées littérales
Les entrées de littéral font référence aux entrées qui peuvent être représentées et résolues au moment de l’appel, telles que les chaînes, les nombres et les valeurs booléennes. Vous utilisez généralement des entrées de littéral pour transmettre des paramètres à votre point de terminaison dans le cadre d’un déploiement de composants de pipeline. Les points de terminaison par lots prennent en charge les types de littéral suivants :
stringbooleanfloatinteger
Les entrées littérales ne sont prises en charge que dans les déploiements de composants de pipeline. Pour savoir comment spécifier des points finaux littéraux, voir Créer des travaux avec des entrées littérales.
Explorer les sorties de données
Les sorties de données font référence à l’emplacement où les résultats d’un programme de traitement par lots sont placés. Chaque sortie a un nom identifiable, et Azure Machine Learning attribue automatiquement un chemin d’accès unique à chaque sortie nommée. Vous pouvez spécifier un autre chemin d’accès, le cas échéant.
Important
Les points de terminaison Batch prennent uniquement en charge l’écriture de sorties dans les magasins de données du Stockage Blob. Si vous devez écrire sur un compte de stockage dont les espaces de noms hiérarchiques sont activés, tel que Data Lake Storage Gen2, vous pouvez enregistrer le service de stockage en tant que magasin de données de Stockage Blob, car les services sont entièrement compatibles. De cette façon, vous pouvez écrire des sorties de points de terminaison de lot vers Data Lake Storage Gen2.
Créer des tâches avec des entrées de données
Les exemples suivants montrent comment créer des tâches en utilisant des entrées de données à partir de ressources de données, magasins de données et comptes de Stockage Azure.
Utilisez la saisie de données à partir d’une ressource de données
Les ressources de données Azure Machine Learning (anciennement appelées jeux de données) sont prises en charge comme entrées pour les travaux. Suivez ces étapes pour exécuter un travail de point de terminaison par lot qui utilise des données d'entrée stockées dans une ressource de données enregistrée dans Azure Machine Learning.
Avertissement
Les ressources de données de type Table (MLTable) ne sont actuellement pas prises en charge.
Créez la ressource de données. Dans cet exemple, il se compose d’un dossier qui contient plusieurs fichiers CSV. Vous utilisez des points de terminaison de traitement par lots pour traiter les fichiers en parallèle. Vous pouvez ignorer cette étape si vos données sont déjà inscrites en tant que ressource de données.
Créez une définition de ressource de données dans un fichier YAML nommé heart-data.yml :
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-data description: An unlabeled data asset for heart classification. type: uri_folder path: dataCréez la ressource de données :
az ml data create -f heart-data.yml
Configurez l’entrée :
DATA_ASSET_ID=$(az ml data show -n heart-data --label latest | jq -r .id)L’ID de ressource de données a le format
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/<data-asset-name>/versions/<data-asset-version>.Exécutez le point de terminaison :
Utilisez l’argument
--setpour spécifier l’entrée. Remplacez tout d’abord les traits d’union dans le nom de la ressource de données par des caractères de soulignement. Les clés ne peuvent contenir que des caractères alphanumériques et des traits de soulignement.az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$DATA_ASSET_IDPour un point de terminaison qui sert un déploiement de modèle, vous pouvez utiliser l’argument
--inputpour spécifier l’entrée de données, car un modèle de déploiement nécessite toujours une seule entrée de données.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATA_ASSET_IDL’argument
--seta tendance à produire de longues commandes lorsque vous spécifiez plusieurs entrées. Dans ce cas, vous pouvez répertorier vos entrées dans un fichier, puis faire référence au fichier lorsque vous appelez votre point de terminaison. Par exemple, vous pouvez créer un fichier YAML nommé inputs.yml qui contient les lignes suivantes :inputs: heart_data: type: uri_folder path: /subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/heart-data/versions/1Vous pouvez ensuite exécuter la commande suivante, qui utilise l’argument
--filepour spécifier les entrées :az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Utilisez la saisie de données à partir d’un magasin de données
Vos tâches de déploiement par lots peuvent faire directement référence aux données qui se trouvent dans les magasins de données enregistrés d'Azure Machine Learning. Dans cet exemple, vous chargez d’abord des données dans un magasin de données dans votre espace de travail Azure Machine Learning. Ensuite, vous exécutez un déploiement par lots sur ces données.
Cet exemple utilise le magasin de données par défaut, mais vous pouvez utiliser un autre magasin de données. Dans n’importe quel espace de travail Azure Machine Learning, le nom du magasin de données blob par défaut est workspaceblobstore. Si vous souhaitez utiliser un autre magasin de données dans les étapes suivantes, remplacez workspaceblobstore par le nom de votre magasin de données préféré.
Chargez des échantillons de données dans le magasin de données. Les échantillons de données sont disponibles dans le référentiel azureml-examples . Vous trouverez les données dans le kit sdk sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/data dossier de ce référentiel.
- Dans Azure Machine Learning studio, ouvrez la page ressources de données de votre magasin de données d’objets blob par défaut, puis recherchez le nom de son conteneur d’objets blob.
- Utilisez un outil tel que l’Explorateur Stockage Azure ou AzCopy pour charger les exemples de données dans un dossier nommé heart-disease-uci-unlabeled dans ce conteneur.
Configurez les informations d’entrée :
Placez le chemin d’accès du fichier dans la variable
INPUT_PATH:DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="azureml://datastores/workspaceblobstore/paths/$DATA_PATH"Notez que le dossier
pathsfait partie du chemin d’accès d’entrée. Ce format indique que la valeur qui suit est un chemin d’accès.Exécutez le point de terminaison :
Utilisez l’argument
--setpour spécifier l’entrée :az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_PATHPour un point de terminaison qui sert un déploiement de modèle, vous pouvez utiliser l’argument
--inputpour spécifier l’entrée de données, car un modèle de déploiement nécessite toujours une seule entrée de données.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folderL’argument
--seta tendance à produire de longues commandes lorsque vous spécifiez plusieurs entrées. Dans ce cas, vous pouvez répertorier vos entrées dans un fichier, puis faire référence au fichier lorsque vous appelez votre point de terminaison. Par exemple, vous pouvez créer un fichier YAML nommé inputs.yml qui contient les lignes suivantes :inputs: heart_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/<data-path>Si vos données sont dans un fichier, utilisez plutôt le type
uri_filepour l’entrée.Vous pouvez ensuite exécuter la commande suivante, qui utilise l’argument
--filepour spécifier les entrées :az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Utiliser des données d'entrée provenant d'un compte de stockage Azure
Les points de terminaison par lots Azure Machine Learning peuvent lire des données à partir d’emplacements cloud dans les comptes de stockage Azure publics et privés. Effectuez les étapes suivantes pour exécuter un travail de point de terminaison de lot avec des données dans un compte de stockage.
Pour en savoir plus sur les configurations supplémentaires requises pour lire des données à partir de comptes de stockage, consultez Configurer des clusters de calcul pour l’accès aux données.
Configurez l’entrée :
Définissez la variable
INPUT_DATA:INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Si vos données se situent dans un fichier, utilisez un format similaire à celui suivant pour définir le chemin d’accès d’entrée :
INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data/heart.csv"Exécutez le point de terminaison :
Utilisez l’argument
--setpour spécifier l’entrée :az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_DATAPour un point de terminaison qui sert un déploiement de modèle, vous pouvez utiliser l’argument
--inputpour spécifier l’entrée de données, car un modèle de déploiement nécessite toujours une seule entrée de données.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folderL’argument
--seta tendance à produire de longues commandes lorsque vous spécifiez plusieurs entrées. Dans ce cas, vous pouvez répertorier vos entrées dans un fichier, puis faire référence au fichier lorsque vous appelez votre point de terminaison. Par exemple, vous pouvez créer un fichier YAML nommé inputs.yml qui contient les lignes suivantes :inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/dataVous pouvez ensuite exécuter la commande suivante, qui utilise l’argument
--filepour spécifier les entrées :az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlSi vos données se trouvent dans un fichier, utilisez le type
uri_filedans le fichier inputs.yml pour l’entrée de données.
Créer des tâches avec des entrées littérales
Les déploiements de composants de pipeline prennent en charge les entrées littérales. Pour obtenir un exemple de déploiement par lots qui contient un pipeline de base, consultez Guide pratique pour déployer des pipelines avec des points de terminaison de lot.
L’exemple suivant montre comment spécifier une entrée nommée score_mode, de type string, avec la valeur append :
Placez vos entrées dans un fichier YAML, tel qu’un fichier nommé inputs.yml :
inputs:
score_mode:
type: string
default: append
Exécutez la commande suivante, qui utilise l’argument --file pour spécifier les entrées.
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Vous pouvez également utiliser l'argument --set pour spécifier le type et la valeur par défaut. Mais cette approche tend à produire de longues commandes lorsque vous spécifiez plusieurs entrées :
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
Créer des tâches avec des sorties de données
L’exemple suivant montre comment modifier l’emplacement d’une sortie nommée score. À des fins d’exhaustivité, l’exemple configure également une entrée nommée heart_data.
Cet exemple utilise le magasin de données par défaut, workspaceblobstore. Mais vous pouvez utiliser n’importe quel autre magasin de données dans votre espace de travail, tant qu’il s’agit d’un compte Stockage Blob. Si vous souhaitez utiliser un autre magasin de données, remplacez workspaceblobstore dans les étapes suivantes le nom de votre magasin de données préféré.
Obtient l’ID du magasin de données.
DATA_STORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')L’ID de magasin de données a le format
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/datastores/workspaceblobstore.Créez une sortie de données :
Définissez les valeurs d’entrée et de sortie dans un fichier nommé inputs-and-outputs.yml. Utilisez l’ID du magasin de données dans le chemin de sortie. À des fins d’exhaustivité, définissez également l’entrée de données.
inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data outputs: score: type: uri_file path: <data-store-ID>/paths/batch-jobs/my-unique-pathRemarque
Notez que le dossier
pathsfait partie du chemin d’accès de sortie. Ce format indique que la valeur qui suit est un chemin d’accès.Exécutez le déploiement :
Utilisez l'argument
--filepour spécifier les valeurs d'entrée et de sortie :az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs-and-outputs.yml