Comment générer des complétions de conversation avec l’inférence de modèle Azure AI
Important
Les éléments marqués (préversion) dans cet article sont actuellement en préversion publique. Cette préversion est fournie sans contrat de niveau de service, nous la déconseillons dans des charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Cet article explique comment utiliser l’API de complétions de conversation avec les modèles déployés dans l’inférence de modèle Azure AI dans Azure AI Services.
Prérequis
Pour utiliser des modèles de complétion de conversation dans votre application, vous avez besoin des éléments suivants :
Un abonnement Azure. Si vous utilisez des modèles GitHub, vous pouvez mettre à niveau votre expérience et créer un abonnement Azure dans le processus. Lisez Passer des modèles GitHub à l’inférence de modèle Azure AI si vous êtes dans ce cas.
Une ressource Azure AI services. Pour plus d’informations, consultez Créer une ressource Azure AI Services.
L’URL et la clé du point de terminaison.

Un modèle de déploiement des complétions de conversation. Si vous n’en avez pas, veuillez lire Ajouter des modèles à Azure AI services et les configurer pour ajouter un modèle de complétions de conversation à votre ressource.
Installez le package d’inférence Azure AI avec la commande suivante :
pip install -U azure-ai-inferenceConseil
En savoir plus sur le Package d’inférence et les informations de référence Azure AI.
Utiliser les complétions de conversation
Tout d’abord, créez le client pour consommer le modèle. Le code suivant utilise une URL de point de terminaison et une clé qui sont stockées dans les variables d’environnement.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="mistral-large-2407"
)
Si vous avez configuré la ressource avec la prise en charge de Microsoft Entra ID, vous pouvez utiliser l’extrait de code suivant pour créer un client.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.identity import DefaultAzureCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="mistral-large-2407"
)
Créer une requête de complétion de conversation
L’exemple suivant vous montre comment créer une requête de complétions de conversation de base sur le modèle.
from azure.ai.inference.models import SystemMessage, UserMessage
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
)
Remarque
Certains modèles ne prennent pas en charge les messages système (role="system"). Lorsque vous utilisez l’API Inférence de modèle Azure AI, les messages système sont traduits en messages utilisateur, ce qui est la fonctionnalité la plus proche disponible. Cette traduction est proposée pour des raisons pratiques, mais il est important de vérifier que le modèle suit les instructions du message système avec le niveau de confiance approprié.
La réponse est comme suit, où vous pouvez voir les statistiques d’utilisation du modèle :
print("Response:", response.choices[0].message.content)
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Examinez la section usage dans la réponse pour voir le nombre de jetons utilisés pour l’invite, le nombre total de jetons générés et le nombre de jetons utilisés pour la complétion.
Diffuser du contenu
Par défaut, l’API de complétion retourne l’intégralité du contenu généré dans une réponse unique. Si vous générez des complétions longues, l’attente de la réponse peut durer plusieurs secondes.
Vous pouvez diffuser en continu le contenu pour l’obtenir à mesure qu’il est généré. Diffuser le contenu en continu vous permet de commencer à traiter la complétion à mesure que le contenu devient disponible. Ce mode renvoie un objet qui diffuse la réponse en tant qu’événements envoyés par le serveur contenant uniquement des données. Extrayez les blocs du champ delta, plutôt que le champ de message.
Pour diffuser en continu des complétions, définissez stream=True lorsque vous appelez le modèle.
result = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
temperature=0,
top_p=1,
max_tokens=2048,
stream=True,
)
Pour visualiser la sortie, définissez une fonction d’assistance pour imprimer le flux.
def print_stream(result):
"""
Prints the chat completion with streaming.
"""
import time
for update in result:
if update.choices:
print(update.choices[0].delta.content, end="")
Vous pouvez visualiser la façon dont la diffusion en continu génère du contenu :
print_stream(result)
Découvrir d’autres paramètres pris en charge par le client d’inférence
Explorez d’autres paramètres que vous pouvez spécifier dans le client d’inférence. Pour obtenir la liste complète de tous les paramètres pris en charge et leur documentation correspondante, consultez Référence de l’API Inférence de modèle Azure AI.
from azure.ai.inference.models import ChatCompletionsResponseFormatText
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
presence_penalty=0.1,
frequency_penalty=0.8,
max_tokens=2048,
stop=["<|endoftext|>"],
temperature=0,
top_p=1,
response_format={ "type": ChatCompletionsResponseFormatText() },
)
Certains modèles ne prennent pas en charge la mise en forme de sortie JSON. Vous pouvez toujours demander au modèle de générer des sorties JSON. Cependant, il n’est pas garanti que de telles sorties soient en JSON valide.
Si vous souhaitez transmettre un paramètre qui ne figure pas dans la liste des paramètres pris en charge, vous pouvez le transmettre au modèle sous-jacent en utilisant des paramètres supplémentaires. Consulter Transmettre des paramètres supplémentaires au modèle.
Créer des sorties JSON
Certains modèles peuvent créer des sorties JSON. Définissez response_format sur json_object pour activer le mode JSON et garantir que le message généré par le modèle est un fichier JSON valide. Vous devez également vous-même demander au modèle de produire du JSON via un message système ou utilisateur. En outre, le contenu du message peut être partiellement coupé si finish_reason="length", ce qui indique que la génération a dépassé max_tokens ou que la conversation a dépassé la longueur maximale du contexte.
from azure.ai.inference.models import ChatCompletionsResponseFormatJSON
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant that always generate responses in JSON format, using."
" the following format: { ""answer"": ""response"" }."),
UserMessage(content="How many languages are in the world?"),
],
response_format={ "type": ChatCompletionsResponseFormatJSON() }
)
Transmettre des paramètres supplémentaires au modèle
L'API d'inférence du modèle Azure AI vous permet de transmettre des paramètres supplémentaires au modèle. L’exemple de code suivant montre comment transmettre le paramètre supplémentaire logprobs au modèle.
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
model_extras={
"logprobs": True
}
)
Avant de transmettre des paramètres supplémentaires à l’API Inférence de modèle Azure AI, assurez-vous que votre modèle prend en charge ces paramètres supplémentaires. Lorsque la requête est adressée au modèle sous-jacent, l’en-tête extra-parameters est transmis au modèle avec la valeur pass-through. Cette valeur indique au point de terminaison de transmettre les paramètres supplémentaires au modèle. L’utilisation de paramètres supplémentaires avec le modèle ne garantit pas que le modèle peut réellement les gérer. Lisez la documentation du modèle pour comprendre quels paramètres supplémentaires sont pris en charge.
Utiliser des outils
Certains modèles prennent en charge l’utilisation d’outils, ce qui peut être une ressource extraordinaire lorsqu’il s’agit de décharger le modèle de langage de tâches spécifiques et de se tourner plutôt vers un système plus déterministe ou même un modèle de langage différent. L'API Inférence de modèle Azure AI vous permet de définir des outils de la manière suivante.
L’exemple de code suivant crée une définition d’outil capable d’examiner les informations de vol de deux villes différentes.
from azure.ai.inference.models import FunctionDefinition, ChatCompletionsFunctionToolDefinition
flight_info = ChatCompletionsFunctionToolDefinition(
function=FunctionDefinition(
name="get_flight_info",
description="Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters={
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates",
},
"destination_city": {
"type": "string",
"description": "The flight destination city",
},
},
"required": ["origin_city", "destination_city"],
},
)
)
tools = [flight_info]
Dans cet exemple, la sortie de la fonction est qu’il n’existe aucun vol disponible pour l’itinéraire sélectionné, mais que l’utilisateur doit envisager de prendre un train.
def get_flight_info(loc_origin: str, loc_destination: str):
return {
"info": f"There are no flights available from {loc_origin} to {loc_destination}. You should take a train, specially if it helps to reduce CO2 emissions."
}
Remarque
Les modèles Cohere nécessitent que les réponses d’un outil soient du contenu JSON valide se présentant sous la forme d’une chaîne. Lors de la construction de messages de type Outil, vérifiez que la réponse est une chaîne JSON valide.
Demandez au modèle de réserver des vols à l’aide de cette fonction :
messages = [
SystemMessage(
content="You are a helpful assistant that help users to find information about traveling, how to get"
" to places and the different transportations options. You care about the environment and you"
" always have that in mind when answering inqueries.",
),
UserMessage(
content="When is the next flight from Miami to Seattle?",
),
]
response = client.complete(
messages=messages, tools=tools, tool_choice="auto"
)
Vous pouvez inspecter la réponse pour savoir si un outil doit être appelé. Inspectez le motif de fin pour déterminer si l’outil doit être appelé. N’oubliez pas que plusieurs types d’outils peuvent être indiqués. Cet exemple illustre un outil de type function.
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
print("Finish reason:", response.choices[0].finish_reason)
print("Tool call:", tool_calls)
Pour continuer, ajoutez ce message à l’historique des conversations :
messages.append(
response_message
)
À présent, il est temps d’appeler la fonction appropriée pour gérer l’appel d’outil. L’extrait de code suivant itère sur tous les appels d’outil indiqués dans la réponse et appelle la fonction correspondante avec les paramètres appropriés. La réponse est également ajoutée à l’historique des conversations.
import json
from azure.ai.inference.models import ToolMessage
for tool_call in tool_calls:
# Get the tool details:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments.replace("\'", "\""))
tool_call_id = tool_call.id
print(f"Calling function `{function_name}` with arguments {function_args}")
# Call the function defined above using `locals()`, which returns the list of all functions
# available in the scope as a dictionary. Notice that this is just done as a simple way to get
# the function callable from its string name. Then we can call it with the corresponding
# arguments.
callable_func = locals()[function_name]
function_response = callable_func(**function_args)
print("->", function_response)
# Once we have a response from the function and its arguments, we can append a new message to the chat
# history. Notice how we are telling to the model that this chat message came from a tool:
messages.append(
ToolMessage(
tool_call_id=tool_call_id,
content=json.dumps(function_response)
)
)
Voir la réponse du modèle :
response = client.complete(
messages=messages,
tools=tools,
)
Appliquer la sécurité du contenu
L’API Inférence de modèle Azure AI prend en charge Azure AI Sécurité du Contenu. Lorsque vous utilisez des déploiements avec la sécurité du contenu Azure AI activée, les entrées et les sorties passent par un ensemble de modèles de classification visant à détecter et à empêcher la sortie de contenu dangereux. Le système de filtrage du contenu détecte les catégories spécifiques de contenu potentiellement nuisible dans les invites d’entrée et les achèvements de sortie et prend des mesures correspondantes.
L’exemple suivant montre comment gérer les évènements lorsque le modèle détecte du contenu dangereux dans l’invite d’entrée et que la sécurité du contenu est activée.
from azure.ai.inference.models import AssistantMessage, UserMessage, SystemMessage
try:
response = client.complete(
messages=[
SystemMessage(content="You are an AI assistant that helps people find information."),
UserMessage(content="Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."),
]
)
print(response.choices[0].message.content)
except HttpResponseError as ex:
if ex.status_code == 400:
response = ex.response.json()
if isinstance(response, dict) and "error" in response:
print(f"Your request triggered an {response['error']['code']} error:\n\t {response['error']['message']}")
else:
raise
raise
Conseil
Pour en savoir plus sur la façon dont vous pouvez configurer et contrôler les paramètres de sécurité du contenu Azure AI, consultez la Documentation Azure AI Sécurité du Contenu.
Utiliser les saisies semi-automatiques de conversation avec des images
Certains modèles peuvent raisonner à partir de texte et d’images et générer des complétions de texte basées sur les deux types d’entrée. Dans cette section, vous allez explorer les fonctionnalités de certains modèles pour la vision dans un mode conversation :
Important
Certains modèles prennent en charge une seule image pour chaque tour de conversation, et seule la dernière image est gardée en contexte. Si vous ajoutez plusieurs images, une erreur s’affiche.
Pour afficher cette fonctionnalité, téléchargez une image et encodez les informations en tant que chaîne base64. Les données obtenues doivent se trouver à l’intérieur d’une URL de données:
from urllib.request import urlopen, Request
import base64
image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg"
image_format = "jpeg"
request = Request(image_url, headers={"User-Agent": "Mozilla/5.0"})
image_data = base64.b64encode(urlopen(request).read()).decode("utf-8")
data_url = f"data:image/{image_format};base64,{image_data}"
Visualisez l’image :
import requests
import IPython.display as Disp
Disp.Image(requests.get(image_url).content)

À présent, créez une demande de saisie semi-automatique de conversation avec l’image :
from azure.ai.inference.models import TextContentItem, ImageContentItem, ImageUrl
response = client.complete(
messages=[
SystemMessage("You are a helpful assistant that can generate responses based on images."),
UserMessage(content=[
TextContentItem(text="Which conclusion can be extracted from the following chart?"),
ImageContentItem(image=ImageUrl(url=data_url))
]),
],
temperature=0,
top_p=1,
max_tokens=2048,
)
La réponse est la suivante, où vous pouvez voir les statistiques d'utilisation du modèle :
print(f"{response.choices[0].message.role}:\n\t{response.choices[0].message.content}\n")
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Important
Les éléments marqués (préversion) dans cet article sont actuellement en préversion publique. Cette préversion est fournie sans contrat de niveau de service, nous la déconseillons dans des charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Cet article explique comment utiliser l’API de complétions de conversation avec les modèles déployés dans l’inférence de modèle Azure AI dans Azure AI Services.
Prérequis
Pour utiliser des modèles de complétion de conversation dans votre application, vous avez besoin des éléments suivants :
Un abonnement Azure. Si vous utilisez des modèles GitHub, vous pouvez mettre à niveau votre expérience et créer un abonnement Azure dans le processus. Lisez Passer des modèles GitHub à l’inférence de modèle Azure AI si vous êtes dans ce cas.
Une ressource Azure AI services. Pour plus d’informations, consultez Créer une ressource Azure AI Services.
L’URL et la clé du point de terminaison.
Un modèle de déploiement des complétions de conversation. Si vous n’en avez pas, veuillez lire Ajouter des modèles à Azure AI services et les configurer pour ajouter un modèle de complétions de conversation à votre ressource.
Installez la bibliothèque d’inférence Azure pour JavaScript avec la commande suivante :
npm install @azure-rest/ai-inferenceConseil
En savoir plus sur le Package d’inférence et les informations de référence Azure AI.
Utiliser les complétions de conversation
Tout d’abord, créez le client pour consommer le modèle. Le code suivant utilise une URL de point de terminaison et une clé qui sont stockées dans les variables d’environnement.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { AzureKeyCredential } from "@azure/core-auth";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL)
);
Si vous avez configuré la ressource avec la prise en charge de Microsoft Entra ID, vous pouvez utiliser l’extrait de code suivant pour créer un client.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { DefaultAzureCredential } from "@azure/identity";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new DefaultAzureCredential()
);
Créer une requête de complétion de conversation
L’exemple suivant vous montre comment créer une requête de complétions de conversation de base sur le modèle.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
Remarque
Certains modèles ne prennent pas en charge les messages système (role="system"). Lorsque vous utilisez l’API Inférence de modèle Azure AI, les messages système sont traduits en messages utilisateur, ce qui est la fonctionnalité la plus proche disponible. Cette traduction est proposée pour des raisons pratiques, mais il est important de vérifier que le modèle suit les instructions du message système avec le niveau de confiance approprié.
La réponse est comme suit, où vous pouvez voir les statistiques d’utilisation du modèle :
if (isUnexpected(response)) {
throw response.body.error;
}
console.log("Response: ", response.body.choices[0].message.content);
console.log("Model: ", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Examinez la section usage dans la réponse pour voir le nombre de jetons utilisés pour l’invite, le nombre total de jetons générés et le nombre de jetons utilisés pour la complétion.
Diffuser du contenu
Par défaut, l’API de complétion retourne l’intégralité du contenu généré dans une réponse unique. Si vous générez des complétions longues, l’attente de la réponse peut durer plusieurs secondes.
Vous pouvez diffuser en continu le contenu pour l’obtenir à mesure qu’il est généré. Diffuser le contenu en continu vous permet de commencer à traiter la complétion à mesure que le contenu devient disponible. Ce mode renvoie un objet qui diffuse la réponse en tant qu’événements envoyés par le serveur contenant uniquement des données. Extrayez les blocs du champ delta, plutôt que le champ de message.
Pour diffuser les complétions en continu, utilisez .asNodeStream() lorsque vous appelez le modèle.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
}).asNodeStream();
Vous pouvez visualiser la façon dont la diffusion en continu génère du contenu :
var stream = response.body;
if (!stream) {
stream.destroy();
throw new Error(`Failed to get chat completions with status: ${response.status}`);
}
if (response.status !== "200") {
throw new Error(`Failed to get chat completions: ${response.body.error}`);
}
var sses = createSseStream(stream);
for await (const event of sses) {
if (event.data === "[DONE]") {
return;
}
for (const choice of (JSON.parse(event.data)).choices) {
console.log(choice.delta?.content ?? "");
}
}
Découvrir d’autres paramètres pris en charge par le client d’inférence
Explorez d’autres paramètres que vous pouvez spécifier dans le client d’inférence. Pour obtenir la liste complète de tous les paramètres pris en charge et leur documentation correspondante, consultez Référence de l’API Inférence de modèle Azure AI.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
presence_penalty: "0.1",
frequency_penalty: "0.8",
max_tokens: 2048,
stop: ["<|endoftext|>"],
temperature: 0,
top_p: 1,
response_format: { type: "text" },
}
});
Certains modèles ne prennent pas en charge la mise en forme de sortie JSON. Vous pouvez toujours demander au modèle de générer des sorties JSON. Cependant, il n’est pas garanti que de telles sorties soient en JSON valide.
Si vous souhaitez transmettre un paramètre qui ne figure pas dans la liste des paramètres pris en charge, vous pouvez le transmettre au modèle sous-jacent en utilisant des paramètres supplémentaires. Consulter Transmettre des paramètres supplémentaires au modèle.
Créer des sorties JSON
Certains modèles peuvent créer des sorties JSON. Définissez response_format sur json_object pour activer le mode JSON et garantir que le message généré par le modèle est un fichier JSON valide. Vous devez également vous-même demander au modèle de produire du JSON via un message système ou utilisateur. En outre, le contenu du message peut être partiellement coupé si finish_reason="length", ce qui indique que la génération a dépassé max_tokens ou que la conversation a dépassé la longueur maximale du contexte.
var messages = [
{ role: "system", content: "You are a helpful assistant that always generate responses in JSON format, using."
+ " the following format: { \"answer\": \"response\" }." },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
response_format: { type: "json_object" }
}
});
Transmettre des paramètres supplémentaires au modèle
L'API d'inférence du modèle Azure AI vous permet de transmettre des paramètres supplémentaires au modèle. L’exemple de code suivant montre comment transmettre le paramètre supplémentaire logprobs au modèle.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
headers: {
"extra-params": "pass-through"
},
body: {
messages: messages,
logprobs: true
}
});
Avant de transmettre des paramètres supplémentaires à l’API Inférence de modèle Azure AI, assurez-vous que votre modèle prend en charge ces paramètres supplémentaires. Lorsque la requête est adressée au modèle sous-jacent, l’en-tête extra-parameters est transmis au modèle avec la valeur pass-through. Cette valeur indique au point de terminaison de transmettre les paramètres supplémentaires au modèle. L’utilisation de paramètres supplémentaires avec le modèle ne garantit pas que le modèle peut réellement les gérer. Lisez la documentation du modèle pour comprendre quels paramètres supplémentaires sont pris en charge.
Utiliser des outils
Certains modèles prennent en charge l’utilisation d’outils, ce qui peut être une ressource extraordinaire lorsqu’il s’agit de décharger le modèle de langage de tâches spécifiques et de se tourner plutôt vers un système plus déterministe ou même un modèle de langage différent. L'API Inférence de modèle Azure AI vous permet de définir des outils de la manière suivante.
L’exemple de code suivant crée une définition d’outil capable d’examiner les informations de vol de deux villes différentes.
const flight_info = {
name: "get_flight_info",
description: "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters: {
type: "object",
properties: {
origin_city: {
type: "string",
description: "The name of the city where the flight originates",
},
destination_city: {
type: "string",
description: "The flight destination city",
},
},
required: ["origin_city", "destination_city"],
},
}
const tools = [
{
type: "function",
function: flight_info,
},
];
Dans cet exemple, la sortie de la fonction est qu’il n’existe aucun vol disponible pour l’itinéraire sélectionné, mais que l’utilisateur doit envisager de prendre un train.
function get_flight_info(loc_origin, loc_destination) {
return {
info: "There are no flights available from " + loc_origin + " to " + loc_destination + ". You should take a train, specially if it helps to reduce CO2 emissions."
}
}
Remarque
Les modèles Cohere nécessitent que les réponses d’un outil soient du contenu JSON valide se présentant sous la forme d’une chaîne. Lors de la construction de messages de type Outil, vérifiez que la réponse est une chaîne JSON valide.
Demandez au modèle de réserver des vols à l’aide de cette fonction :
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
tool_choice: "auto"
}
});
Vous pouvez inspecter la réponse pour savoir si un outil doit être appelé. Inspectez le motif de fin pour déterminer si l’outil doit être appelé. N’oubliez pas que plusieurs types d’outils peuvent être indiqués. Cet exemple illustre un outil de type function.
const response_message = response.body.choices[0].message;
const tool_calls = response_message.tool_calls;
console.log("Finish reason: " + response.body.choices[0].finish_reason);
console.log("Tool call: " + tool_calls);
Pour continuer, ajoutez ce message à l’historique des conversations :
messages.push(response_message);
À présent, il est temps d’appeler la fonction appropriée pour gérer l’appel d’outil. L’extrait de code suivant itère sur tous les appels d’outil indiqués dans la réponse et appelle la fonction correspondante avec les paramètres appropriés. La réponse est également ajoutée à l’historique des conversations.
function applyToolCall({ function: call, id }) {
// Get the tool details:
const tool_params = JSON.parse(call.arguments);
console.log("Calling function " + call.name + " with arguments " + tool_params);
// Call the function defined above using `window`, which returns the list of all functions
// available in the scope as a dictionary. Notice that this is just done as a simple way to get
// the function callable from its string name. Then we can call it with the corresponding
// arguments.
const function_response = tool_params.map(window[call.name]);
console.log("-> " + function_response);
return function_response
}
for (const tool_call of tool_calls) {
var tool_response = tool_call.apply(applyToolCall);
messages.push(
{
role: "tool",
tool_call_id: tool_call.id,
content: tool_response
}
);
}
Voir la réponse du modèle :
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
}
});
Appliquer la sécurité du contenu
L’API Inférence de modèle Azure AI prend en charge Azure AI Sécurité du Contenu. Lorsque vous utilisez des déploiements avec la sécurité du contenu Azure AI activée, les entrées et les sorties passent par un ensemble de modèles de classification visant à détecter et à empêcher la sortie de contenu dangereux. Le système de filtrage du contenu détecte les catégories spécifiques de contenu potentiellement nuisible dans les invites d’entrée et les achèvements de sortie et prend des mesures correspondantes.
L’exemple suivant montre comment gérer les évènements lorsque le modèle détecte du contenu dangereux dans l’invite d’entrée et que la sécurité du contenu est activée.
try {
var messages = [
{ role: "system", content: "You are an AI assistant that helps people find information." },
{ role: "user", content: "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills." },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
console.log(response.body.choices[0].message.content);
}
catch (error) {
if (error.status_code == 400) {
var response = JSON.parse(error.response._content);
if (response.error) {
console.log(`Your request triggered an ${response.error.code} error:\n\t ${response.error.message}`);
}
else
{
throw error;
}
}
}
Conseil
Pour en savoir plus sur la façon dont vous pouvez configurer et contrôler les paramètres de sécurité du contenu Azure AI, consultez la Documentation Azure AI Sécurité du Contenu.
Utiliser les saisies semi-automatiques de conversation avec des images
Certains modèles peuvent raisonner à partir de texte et d’images et générer des complétions de texte basées sur les deux types d’entrée. Dans cette section, vous allez explorer les fonctionnalités de certains modèles pour la vision dans un mode conversation :
Important
Certains modèles prennent en charge une seule image pour chaque tour de conversation, et seule la dernière image est gardée en contexte. Si vous ajoutez plusieurs images, une erreur s’affiche.
Pour afficher cette fonctionnalité, téléchargez une image et encodez les informations en tant que chaîne base64. Les données obtenues doivent se trouver à l’intérieur d’une URL de données:
const image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
const image_format = "jpeg";
const response = await fetch(image_url, { headers: { "User-Agent": "Mozilla/5.0" } });
const image_data = await response.arrayBuffer();
const image_data_base64 = Buffer.from(image_data).toString("base64");
const data_url = `data:image/${image_format};base64,${image_data_base64}`;
Visualisez l’image :
const img = document.createElement("img");
img.src = data_url;
document.body.appendChild(img);
À présent, créez une demande de saisie semi-automatique de conversation avec l’image :
var messages = [
{ role: "system", content: "You are a helpful assistant that can generate responses based on images." },
{ role: "user", content:
[
{ type: "text", text: "Which conclusion can be extracted from the following chart?" },
{ type: "image_url", image:
{
url: data_url
}
}
]
}
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
temperature: 0,
top_p: 1,
max_tokens: 2048,
}
});
La réponse est la suivante, où vous pouvez voir les statistiques d'utilisation du modèle :
console.log(response.body.choices[0].message.role + ": " + response.body.choices[0].message.content);
console.log("Model:", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Important
Les éléments marqués (préversion) dans cet article sont actuellement en préversion publique. Cette préversion est fournie sans contrat de niveau de service, nous la déconseillons dans des charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Cet article explique comment utiliser l’API de complétions de conversation avec les modèles déployés dans l’inférence de modèle Azure AI dans Azure AI Services.
Prérequis
Pour utiliser des modèles de complétion de conversation dans votre application, vous avez besoin des éléments suivants :
Un abonnement Azure. Si vous utilisez des modèles GitHub, vous pouvez mettre à niveau votre expérience et créer un abonnement Azure dans le processus. Lisez Passer des modèles GitHub à l’inférence de modèle Azure AI si vous êtes dans ce cas.
Une ressource Azure AI services. Pour plus d’informations, consultez Créer une ressource Azure AI Services.
L’URL et la clé du point de terminaison.
Un modèle de déploiement des complétions de conversation. Si vous n’en avez pas, veuillez lire Ajouter des modèles à Azure AI services et les configurer pour ajouter un modèle de complétions de conversation à votre ressource.
Ajoutez le package d’inférence Azure AI à votre projet :
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.1</version> </dependency>Conseil
En savoir plus sur le Package d’inférence et les informations de référence Azure AI.
Si vous utilisez Entra ID, vous avez également besoin du package suivant :
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.13.3</version> </dependency>Importez l’espace de noms suivant :
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
Utiliser les complétions de conversation
Tout d’abord, créez le client pour consommer le modèle. Le code suivant utilise une URL de point de terminaison et une clé qui sont stockées dans les variables d’environnement.
Si vous avez configuré la ressource avec la prise en charge de Microsoft Entra ID, vous pouvez utiliser l’extrait de code suivant pour créer un client.
Créer une requête de complétion de conversation
L’exemple suivant vous montre comment créer une requête de complétions de conversation de base sur le modèle.
Remarque
Certains modèles ne prennent pas en charge les messages système (role="system"). Lorsque vous utilisez l’API Inférence de modèle Azure AI, les messages système sont traduits en messages utilisateur, ce qui est la fonctionnalité la plus proche disponible. Cette traduction est proposée pour des raisons pratiques, mais il est important de vérifier que le modèle suit les instructions du message système avec le niveau de confiance approprié.
La réponse est comme suit, où vous pouvez voir les statistiques d’utilisation du modèle :
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Examinez la section usage dans la réponse pour voir le nombre de jetons utilisés pour l’invite, le nombre total de jetons générés et le nombre de jetons utilisés pour la complétion.
Diffuser du contenu
Par défaut, l’API de complétion retourne l’intégralité du contenu généré dans une réponse unique. Si vous générez des complétions longues, l’attente de la réponse peut durer plusieurs secondes.
Vous pouvez diffuser en continu le contenu pour l’obtenir à mesure qu’il est généré. Diffuser le contenu en continu vous permet de commencer à traiter la complétion à mesure que le contenu devient disponible. Ce mode renvoie un objet qui diffuse la réponse en tant qu’événements envoyés par le serveur contenant uniquement des données. Extrayez les blocs du champ delta, plutôt que le champ de message.
Vous pouvez visualiser la façon dont la diffusion en continu génère du contenu :
Découvrir d’autres paramètres pris en charge par le client d’inférence
Explorez d’autres paramètres que vous pouvez spécifier dans le client d’inférence. Pour obtenir la liste complète de tous les paramètres pris en charge et leur documentation correspondante, consultez Référence de l’API Inférence de modèle Azure AI. Certains modèles ne prennent pas en charge la mise en forme de sortie JSON. Vous pouvez toujours demander au modèle de générer des sorties JSON. Cependant, il n’est pas garanti que de telles sorties soient en JSON valide.
Si vous souhaitez transmettre un paramètre qui ne figure pas dans la liste des paramètres pris en charge, vous pouvez le transmettre au modèle sous-jacent en utilisant des paramètres supplémentaires. Consulter Transmettre des paramètres supplémentaires au modèle.
Créer des sorties JSON
Certains modèles peuvent créer des sorties JSON. Définissez response_format sur json_object pour activer le mode JSON et garantir que le message généré par le modèle est un fichier JSON valide. Vous devez également vous-même demander au modèle de produire du JSON via un message système ou utilisateur. En outre, le contenu du message peut être partiellement coupé si finish_reason="length", ce qui indique que la génération a dépassé max_tokens ou que la conversation a dépassé la longueur maximale du contexte.
Transmettre des paramètres supplémentaires au modèle
L'API d'inférence du modèle Azure AI vous permet de transmettre des paramètres supplémentaires au modèle. L’exemple de code suivant montre comment transmettre le paramètre supplémentaire logprobs au modèle.
Avant de transmettre des paramètres supplémentaires à l’API Inférence de modèle Azure AI, assurez-vous que votre modèle prend en charge ces paramètres supplémentaires. Lorsque la requête est adressée au modèle sous-jacent, l’en-tête extra-parameters est transmis au modèle avec la valeur pass-through. Cette valeur indique au point de terminaison de transmettre les paramètres supplémentaires au modèle. L’utilisation de paramètres supplémentaires avec le modèle ne garantit pas que le modèle peut réellement les gérer. Lisez la documentation du modèle pour comprendre quels paramètres supplémentaires sont pris en charge.
Utiliser des outils
Certains modèles prennent en charge l’utilisation d’outils, ce qui peut être une ressource extraordinaire lorsqu’il s’agit de décharger le modèle de langage de tâches spécifiques et de se tourner plutôt vers un système plus déterministe ou même un modèle de langage différent. L'API Inférence de modèle Azure AI vous permet de définir des outils de la manière suivante.
L’exemple de code suivant crée une définition d’outil capable d’examiner les informations de vol de deux villes différentes.
Dans cet exemple, la sortie de la fonction est qu’il n’existe aucun vol disponible pour l’itinéraire sélectionné, mais que l’utilisateur doit envisager de prendre un train.
Remarque
Les modèles Cohere nécessitent que les réponses d’un outil soient du contenu JSON valide se présentant sous la forme d’une chaîne. Lors de la construction de messages de type Outil, vérifiez que la réponse est une chaîne JSON valide.
Demandez au modèle de réserver des vols à l’aide de cette fonction :
Vous pouvez inspecter la réponse pour savoir si un outil doit être appelé. Inspectez le motif de fin pour déterminer si l’outil doit être appelé. N’oubliez pas que plusieurs types d’outils peuvent être indiqués. Cet exemple illustre un outil de type function.
Pour continuer, ajoutez ce message à l’historique des conversations :
À présent, il est temps d’appeler la fonction appropriée pour gérer l’appel d’outil. L’extrait de code suivant itère sur tous les appels d’outil indiqués dans la réponse et appelle la fonction correspondante avec les paramètres appropriés. La réponse est également ajoutée à l’historique des conversations.
Voir la réponse du modèle :
Appliquer la sécurité du contenu
L’API Inférence de modèle Azure AI prend en charge Azure AI Sécurité du Contenu. Lorsque vous utilisez des déploiements avec la sécurité du contenu Azure AI activée, les entrées et les sorties passent par un ensemble de modèles de classification visant à détecter et à empêcher la sortie de contenu dangereux. Le système de filtrage du contenu détecte les catégories spécifiques de contenu potentiellement nuisible dans les invites d’entrée et les achèvements de sortie et prend des mesures correspondantes.
L’exemple suivant montre comment gérer les évènements lorsque le modèle détecte du contenu dangereux dans l’invite d’entrée et que la sécurité du contenu est activée.
Conseil
Pour en savoir plus sur la façon dont vous pouvez configurer et contrôler les paramètres de sécurité du contenu Azure AI, consultez la Documentation Azure AI Sécurité du Contenu.
Utiliser les saisies semi-automatiques de conversation avec des images
Certains modèles peuvent raisonner à partir de texte et d’images et générer des complétions de texte basées sur les deux types d’entrée. Dans cette section, vous allez explorer les fonctionnalités de certains modèles pour la vision dans un mode conversation :
Important
Certains modèles prennent en charge une seule image pour chaque tour de conversation, et seule la dernière image est gardée en contexte. Si vous ajoutez plusieurs images, une erreur s’affiche.
Pour afficher cette fonctionnalité, téléchargez une image et encodez les informations en tant que chaîne base64. Les données obtenues doivent se trouver à l’intérieur d’une URL de données:
Visualisez l’image :
À présent, créez une demande de saisie semi-automatique de conversation avec l’image :
La réponse est la suivante, où vous pouvez voir les statistiques d'utilisation du modèle :
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Important
Les éléments marqués (préversion) dans cet article sont actuellement en préversion publique. Cette préversion est fournie sans contrat de niveau de service, nous la déconseillons dans des charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Cet article explique comment utiliser l’API de complétions de conversation avec les modèles déployés dans l’inférence de modèle Azure AI dans Azure AI Services.
Prérequis
Pour utiliser des modèles de complétion de conversation dans votre application, vous avez besoin des éléments suivants :
Un abonnement Azure. Si vous utilisez des modèles GitHub, vous pouvez mettre à niveau votre expérience et créer un abonnement Azure dans le processus. Lisez Passer des modèles GitHub à l’inférence de modèle Azure AI si vous êtes dans ce cas.
Une ressource Azure AI services. Pour plus d’informations, consultez Créer une ressource Azure AI Services.
L’URL et la clé du point de terminaison.
Un modèle de déploiement des complétions de conversation. Si vous n’en avez pas, veuillez lire Ajouter des modèles à Azure AI services et les configurer pour ajouter un modèle de complétions de conversation à votre ressource.
Installez le package d’inférence Azure AI avec la commande suivante :
dotnet add package Azure.AI.Inference --prereleaseConseil
En savoir plus sur le Package d’inférence et les informations de référence Azure AI.
Si vous utilisez Entra ID, vous avez également besoin du package suivant :
dotnet add package Azure.Identity
Utiliser les complétions de conversation
Tout d’abord, créez le client pour consommer le modèle. Le code suivant utilise une URL de point de terminaison et une clé qui sont stockées dans les variables d’environnement.
ChatCompletionsClient client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
"mistral-large-2407"
);
Si vous avez configuré la ressource avec la prise en charge de Microsoft Entra ID, vous pouvez utiliser l’extrait de code suivant pour créer un client.
client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(includeInteractiveCredentials: true),
"mistral-large-2407"
);
Créer une requête de complétion de conversation
L’exemple suivant vous montre comment créer une requête de complétions de conversation de base sur le modèle.
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
};
Response<ChatCompletions> response = client.Complete(requestOptions);
Remarque
Certains modèles ne prennent pas en charge les messages système (role="system"). Lorsque vous utilisez l’API Inférence de modèle Azure AI, les messages système sont traduits en messages utilisateur, ce qui est la fonctionnalité la plus proche disponible. Cette traduction est proposée pour des raisons pratiques, mais il est important de vérifier que le modèle suit les instructions du message système avec le niveau de confiance approprié.
La réponse est comme suit, où vous pouvez voir les statistiques d’utilisation du modèle :
Console.WriteLine($"Response: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Examinez la section usage dans la réponse pour voir le nombre de jetons utilisés pour l’invite, le nombre total de jetons générés et le nombre de jetons utilisés pour la complétion.
Diffuser du contenu
Par défaut, l’API de complétion retourne l’intégralité du contenu généré dans une réponse unique. Si vous générez des complétions longues, l’attente de la réponse peut durer plusieurs secondes.
Vous pouvez diffuser en continu le contenu pour l’obtenir à mesure qu’il est généré. Diffuser le contenu en continu vous permet de commencer à traiter la complétion à mesure que le contenu devient disponible. Ce mode renvoie un objet qui diffuse la réponse en tant qu’événements envoyés par le serveur contenant uniquement des données. Extrayez les blocs du champ delta, plutôt que le champ de message.
Pour diffuser en continu des complétions, utilisez la méthode CompleteStreamingAsync lorsque vous appelez le modèle. Notez que dans cet exemple, l’appel est encapsulé dans une méthode asynchrone.
static async Task StreamMessageAsync(ChatCompletionsClient client)
{
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world? Write an essay about it.")
},
MaxTokens=4096
};
StreamingResponse<StreamingChatCompletionsUpdate> streamResponse = await client.CompleteStreamingAsync(requestOptions);
await PrintStream(streamResponse);
}
Pour visualiser la sortie, définissez une méthode asynchrone pour imprimer le flux dans la console.
static async Task PrintStream(StreamingResponse<StreamingChatCompletionsUpdate> response)
{
await foreach (StreamingChatCompletionsUpdate chatUpdate in response)
{
if (chatUpdate.Role.HasValue)
{
Console.Write($"{chatUpdate.Role.Value.ToString().ToUpperInvariant()}: ");
}
if (!string.IsNullOrEmpty(chatUpdate.ContentUpdate))
{
Console.Write(chatUpdate.ContentUpdate);
}
}
}
Vous pouvez visualiser la façon dont la diffusion en continu génère du contenu :
StreamMessageAsync(client).GetAwaiter().GetResult();
Découvrir d’autres paramètres pris en charge par le client d’inférence
Explorez d’autres paramètres que vous pouvez spécifier dans le client d’inférence. Pour obtenir la liste complète de tous les paramètres pris en charge et leur documentation correspondante, consultez Référence de l’API Inférence de modèle Azure AI.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
PresencePenalty = 0.1f,
FrequencyPenalty = 0.8f,
MaxTokens = 2048,
StopSequences = { "<|endoftext|>" },
Temperature = 0,
NucleusSamplingFactor = 1,
ResponseFormat = new ChatCompletionsResponseFormatText()
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
Certains modèles ne prennent pas en charge la mise en forme de sortie JSON. Vous pouvez toujours demander au modèle de générer des sorties JSON. Cependant, il n’est pas garanti que de telles sorties soient en JSON valide.
Si vous souhaitez transmettre un paramètre qui ne figure pas dans la liste des paramètres pris en charge, vous pouvez le transmettre au modèle sous-jacent en utilisant des paramètres supplémentaires. Consulter Transmettre des paramètres supplémentaires au modèle.
Créer des sorties JSON
Certains modèles peuvent créer des sorties JSON. Définissez response_format sur json_object pour activer le mode JSON et garantir que le message généré par le modèle est un fichier JSON valide. Vous devez également vous-même demander au modèle de produire du JSON via un message système ou utilisateur. En outre, le contenu du message peut être partiellement coupé si finish_reason="length", ce qui indique que la génération a dépassé max_tokens ou que la conversation a dépassé la longueur maximale du contexte.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage(
"You are a helpful assistant that always generate responses in JSON format, " +
"using. the following format: { \"answer\": \"response\" }."
),
new ChatRequestUserMessage(
"How many languages are in the world?"
)
},
ResponseFormat = new ChatCompletionsResponseFormatJSON()
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
Transmettre des paramètres supplémentaires au modèle
L'API d'inférence du modèle Azure AI vous permet de transmettre des paramètres supplémentaires au modèle. L’exemple de code suivant montre comment transmettre le paramètre supplémentaire logprobs au modèle.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
AdditionalProperties = { { "logprobs", BinaryData.FromString("true") } },
};
response = client.Complete(requestOptions, extraParams: ExtraParameters.PassThrough);
Console.WriteLine($"Response: {response.Value.Content}");
Avant de transmettre des paramètres supplémentaires à l’API Inférence de modèle Azure AI, assurez-vous que votre modèle prend en charge ces paramètres supplémentaires. Lorsque la requête est adressée au modèle sous-jacent, l’en-tête extra-parameters est transmis au modèle avec la valeur pass-through. Cette valeur indique au point de terminaison de transmettre les paramètres supplémentaires au modèle. L’utilisation de paramètres supplémentaires avec le modèle ne garantit pas que le modèle peut réellement les gérer. Lisez la documentation du modèle pour comprendre quels paramètres supplémentaires sont pris en charge.
Utiliser des outils
Certains modèles prennent en charge l’utilisation d’outils, ce qui peut être une ressource extraordinaire lorsqu’il s’agit de décharger le modèle de langage de tâches spécifiques et de se tourner plutôt vers un système plus déterministe ou même un modèle de langage différent. L'API Inférence de modèle Azure AI vous permet de définir des outils de la manière suivante.
L’exemple de code suivant crée une définition d’outil capable d’examiner les informations de vol de deux villes différentes.
FunctionDefinition flightInfoFunction = new FunctionDefinition("getFlightInfo")
{
Description = "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
Parameters = BinaryData.FromObjectAsJson(new
{
Type = "object",
Properties = new
{
origin_city = new
{
Type = "string",
Description = "The name of the city where the flight originates"
},
destination_city = new
{
Type = "string",
Description = "The flight destination city"
}
}
},
new JsonSerializerOptions() { PropertyNamingPolicy = JsonNamingPolicy.CamelCase }
)
};
ChatCompletionsFunctionToolDefinition getFlightTool = new ChatCompletionsFunctionToolDefinition(flightInfoFunction);
Dans cet exemple, la sortie de la fonction est qu’il n’existe aucun vol disponible pour l’itinéraire sélectionné, mais que l’utilisateur doit envisager de prendre un train.
static string getFlightInfo(string loc_origin, string loc_destination)
{
return JsonSerializer.Serialize(new
{
info = $"There are no flights available from {loc_origin} to {loc_destination}. You " +
"should take a train, specially if it helps to reduce CO2 emissions."
});
}
Remarque
Les modèles Cohere nécessitent que les réponses d’un outil soient du contenu JSON valide se présentant sous la forme d’une chaîne. Lors de la construction de messages de type Outil, vérifiez que la réponse est une chaîne JSON valide.
Demandez au modèle de réserver des vols à l’aide de cette fonction :
var chatHistory = new List<ChatRequestMessage>(){
new ChatRequestSystemMessage(
"You are a helpful assistant that help users to find information about traveling, " +
"how to get to places and the different transportations options. You care about the" +
"environment and you always have that in mind when answering inqueries."
),
new ChatRequestUserMessage("When is the next flight from Miami to Seattle?")
};
requestOptions = new ChatCompletionsOptions(chatHistory);
requestOptions.Tools.Add(getFlightTool);
requestOptions.ToolChoice = ChatCompletionsToolChoice.Auto;
response = client.Complete(requestOptions);
Vous pouvez inspecter la réponse pour savoir si un outil doit être appelé. Inspectez le motif de fin pour déterminer si l’outil doit être appelé. N’oubliez pas que plusieurs types d’outils peuvent être indiqués. Cet exemple illustre un outil de type function.
var responseMessage = response.Value;
var toolsCall = responseMessage.ToolCalls;
Console.WriteLine($"Finish reason: {response.Value.Choices[0].FinishReason}");
Console.WriteLine($"Tool call: {toolsCall[0].Id}");
Pour continuer, ajoutez ce message à l’historique des conversations :
requestOptions.Messages.Add(new ChatRequestAssistantMessage(response.Value));
À présent, il est temps d’appeler la fonction appropriée pour gérer l’appel d’outil. L’extrait de code suivant itère sur tous les appels d’outil indiqués dans la réponse et appelle la fonction correspondante avec les paramètres appropriés. La réponse est également ajoutée à l’historique des conversations.
foreach (ChatCompletionsToolCall tool in toolsCall)
{
if (tool is ChatCompletionsFunctionToolCall functionTool)
{
// Get the tool details:
string callId = functionTool.Id;
string toolName = functionTool.Name;
string toolArgumentsString = functionTool.Arguments;
Dictionary<string, object> toolArguments = JsonSerializer.Deserialize<Dictionary<string, object>>(toolArgumentsString);
// Here you have to call the function defined. In this particular example we use
// reflection to find the method we definied before in an static class called
// `ChatCompletionsExamples`. Using reflection allows us to call a function
// by string name. Notice that this is just done for demonstration purposes as a
// simple way to get the function callable from its string name. Then we can call
// it with the corresponding arguments.
var flags = BindingFlags.Instance | BindingFlags.Public | BindingFlags.NonPublic | BindingFlags.Static;
string toolResponse = (string)typeof(ChatCompletionsExamples).GetMethod(toolName, flags).Invoke(null, toolArguments.Values.Cast<object>().ToArray());
Console.WriteLine("->", toolResponse);
requestOptions.Messages.Add(new ChatRequestToolMessage(toolResponse, callId));
}
else
throw new Exception("Unsupported tool type");
}
Voir la réponse du modèle :
response = client.Complete(requestOptions);
Appliquer la sécurité du contenu
L’API Inférence de modèle Azure AI prend en charge Azure AI Sécurité du Contenu. Lorsque vous utilisez des déploiements avec la sécurité du contenu Azure AI activée, les entrées et les sorties passent par un ensemble de modèles de classification visant à détecter et à empêcher la sortie de contenu dangereux. Le système de filtrage du contenu détecte les catégories spécifiques de contenu potentiellement nuisible dans les invites d’entrée et les achèvements de sortie et prend des mesures correspondantes.
L’exemple suivant montre comment gérer les évènements lorsque le modèle détecte du contenu dangereux dans l’invite d’entrée et que la sécurité du contenu est activée.
try
{
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage(
"Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
),
},
};
response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
}
catch (RequestFailedException ex)
{
if (ex.ErrorCode == "content_filter")
{
Console.WriteLine($"Your query has trigger Azure Content Safety: {ex.Message}");
}
else
{
throw;
}
}
Conseil
Pour en savoir plus sur la façon dont vous pouvez configurer et contrôler les paramètres de sécurité du contenu Azure AI, consultez la Documentation Azure AI Sécurité du Contenu.
Utiliser les saisies semi-automatiques de conversation avec des images
Certains modèles peuvent raisonner à partir de texte et d’images et générer des complétions de texte basées sur les deux types d’entrée. Dans cette section, vous allez explorer les fonctionnalités de certains modèles pour la vision dans un mode conversation :
Important
Certains modèles prennent en charge une seule image pour chaque tour de conversation, et seule la dernière image est gardée en contexte. Si vous ajoutez plusieurs images, une erreur s’affiche.
Pour afficher cette fonctionnalité, téléchargez une image et encodez les informations en tant que chaîne base64. Les données obtenues doivent se trouver à l’intérieur d’une URL de données:
string imageUrl = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
string imageFormat = "jpeg";
HttpClient httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0");
byte[] imageBytes = httpClient.GetByteArrayAsync(imageUrl).Result;
string imageBase64 = Convert.ToBase64String(imageBytes);
string dataUrl = $"data:image/{imageFormat};base64,{imageBase64}";
Visualisez l’image :
À présent, créez une demande de saisie semi-automatique de conversation avec l’image :
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage([
new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"),
new ChatMessageImageContentItem(new Uri(dataUrl))
]),
},
MaxTokens=2048,
};
var response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
La réponse est la suivante, où vous pouvez voir les statistiques d'utilisation du modèle :
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Important
Les éléments marqués (préversion) dans cet article sont actuellement en préversion publique. Cette préversion est fournie sans contrat de niveau de service, nous la déconseillons dans des charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Cet article explique comment utiliser l’API de complétions de conversation avec les modèles déployés dans l’inférence de modèle Azure AI dans Azure AI Services.
Prérequis
Pour utiliser des modèles de complétion de conversation dans votre application, vous avez besoin des éléments suivants :
Un abonnement Azure. Si vous utilisez des modèles GitHub, vous pouvez mettre à niveau votre expérience et créer un abonnement Azure dans le processus. Lisez Passer des modèles GitHub à l’inférence de modèle Azure AI si vous êtes dans ce cas.
Une ressource Azure AI services. Pour plus d’informations, consultez Créer une ressource Azure AI Services.
L’URL et la clé du point de terminaison.
- Un modèle de déploiement des complétions de conversation. Si vous n’en avez pas, veuillez lire Ajouter des modèles à Azure AI services et les configurer pour ajouter un modèle de complétions de conversation à votre ressource.
Utiliser les complétions de conversation
Pour utiliser les incorporations de texte, utilisez l’itinéraire /chat/completions ajouté à l’URL de base ainsi que vos informations d’identification indiquées dans api-key. L’en-tête Authorization est également pris en charge avec le format Bearer <key>.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
Si vous avez configuré la ressource avec la prise en charge de Microsoft Entra ID, transmettez le jeton dans l’en-tête Authorization :
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
Créer une requête de complétion de conversation
L’exemple suivant vous montre comment créer une requête de complétions de conversation de base sur le modèle.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
]
}
Remarque
Certains modèles ne prennent pas en charge les messages système (role="system"). Lorsque vous utilisez l’API Inférence de modèle Azure AI, les messages système sont traduits en messages utilisateur, ce qui est la fonctionnalité la plus proche disponible. Cette traduction est proposée pour des raisons pratiques, mais il est important de vérifier que le modèle suit les instructions du message système avec le niveau de confiance approprié.
La réponse est comme suit, où vous pouvez voir les statistiques d’utilisation du modèle :
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Examinez la section usage dans la réponse pour voir le nombre de jetons utilisés pour l’invite, le nombre total de jetons générés et le nombre de jetons utilisés pour la complétion.
Diffuser du contenu
Par défaut, l’API de complétion retourne l’intégralité du contenu généré dans une réponse unique. Si vous générez des complétions longues, l’attente de la réponse peut durer plusieurs secondes.
Vous pouvez diffuser en continu le contenu pour l’obtenir à mesure qu’il est généré. Diffuser le contenu en continu vous permet de commencer à traiter la complétion à mesure que le contenu devient disponible. Ce mode renvoie un objet qui diffuse la réponse en tant qu’événements envoyés par le serveur contenant uniquement des données. Extrayez les blocs du champ delta, plutôt que le champ de message.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"stream": true,
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
Vous pouvez visualiser la façon dont la diffusion en continu génère du contenu :
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"role": "assistant",
"content": ""
},
"finish_reason": null,
"logprobs": null
}
]
}
Le dernier message dans le flux a finish_reason défini, indiquant la raison de l’arrêt du processus de génération.
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"content": ""
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Découvrir d’autres paramètres pris en charge par le client d’inférence
Explorez d’autres paramètres que vous pouvez spécifier dans le client d’inférence. Pour obtenir la liste complète de tous les paramètres pris en charge et leur documentation correspondante, consultez Référence de l’API Inférence de modèle Azure AI.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"presence_penalty": 0.1,
"frequency_penalty": 0.8,
"max_tokens": 2048,
"stop": ["<|endoftext|>"],
"temperature" :0,
"top_p": 1,
"response_format": { "type": "text" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Certains modèles ne prennent pas en charge la mise en forme de sortie JSON. Vous pouvez toujours demander au modèle de générer des sorties JSON. Cependant, il n’est pas garanti que de telles sorties soient en JSON valide.
Si vous souhaitez transmettre un paramètre qui ne figure pas dans la liste des paramètres pris en charge, vous pouvez le transmettre au modèle sous-jacent en utilisant des paramètres supplémentaires. Consulter Transmettre des paramètres supplémentaires au modèle.
Créer des sorties JSON
Certains modèles peuvent créer des sorties JSON. Définissez response_format sur json_object pour activer le mode JSON et garantir que le message généré par le modèle est un fichier JSON valide. Vous devez également vous-même demander au modèle de produire du JSON via un message système ou utilisateur. En outre, le contenu du message peut être partiellement coupé si finish_reason="length", ce qui indique que la génération a dépassé max_tokens ou que la conversation a dépassé la longueur maximale du contexte.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that always generate responses in JSON format, using the following format: { \"answer\": \"response\" }"
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"response_format": { "type": "json_object" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718727522,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "{\"answer\": \"There are approximately 7,117 living languages in the world today, according to the latest estimates. However, this number can vary as some languages become extinct and others are newly discovered or classified.\"}",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 39,
"total_tokens": 87,
"completion_tokens": 48
}
}
Transmettre des paramètres supplémentaires au modèle
L'API d'inférence du modèle Azure AI vous permet de transmettre des paramètres supplémentaires au modèle. L’exemple de code suivant montre comment transmettre le paramètre supplémentaire logprobs au modèle.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Authorization: Bearer <TOKEN>
Content-Type: application/json
extra-parameters: pass-through
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"logprobs": true
}
Avant de transmettre des paramètres supplémentaires à l’API Inférence de modèle Azure AI, assurez-vous que votre modèle prend en charge ces paramètres supplémentaires. Lorsque la requête est adressée au modèle sous-jacent, l’en-tête extra-parameters est transmis au modèle avec la valeur pass-through. Cette valeur indique au point de terminaison de transmettre les paramètres supplémentaires au modèle. L’utilisation de paramètres supplémentaires avec le modèle ne garantit pas que le modèle peut réellement les gérer. Lisez la documentation du modèle pour comprendre quels paramètres supplémentaires sont pris en charge.
Utiliser des outils
Certains modèles prennent en charge l’utilisation d’outils, ce qui peut être une ressource extraordinaire lorsqu’il s’agit de décharger le modèle de langage de tâches spécifiques et de se tourner plutôt vers un système plus déterministe ou même un modèle de langage différent. L'API Inférence de modèle Azure AI vous permet de définir des outils de la manière suivante.
L’exemple de code suivant crée une définition d’outil capable d’examiner les informations de vol de deux villes différentes.
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
Dans cet exemple, la sortie de la fonction est qu’il n’existe aucun vol disponible pour l’itinéraire sélectionné, mais que l’utilisateur doit envisager de prendre un train.
Remarque
Les modèles Cohere nécessitent que les réponses d’un outil soient du contenu JSON valide se présentant sous la forme d’une chaîne. Lors de la construction de messages de type Outil, vérifiez que la réponse est une chaîne JSON valide.
Demandez au modèle de réserver des vols à l’aide de cette fonction :
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
]
}
Vous pouvez inspecter la réponse pour savoir si un outil doit être appelé. Inspectez le motif de fin pour déterminer si l’outil doit être appelé. N’oubliez pas que plusieurs types d’outils peuvent être indiqués. Cet exemple illustre un outil de type function.
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726007,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0dF1gh",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
"finish_reason": "tool_calls",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 190,
"total_tokens": 226,
"completion_tokens": 36
}
}
Pour continuer, ajoutez ce message à l’historique des conversations :
À présent, il est temps d’appeler la fonction appropriée pour gérer l’appel d’outil. L’extrait de code suivant itère sur tous les appels d’outil indiqués dans la réponse et appelle la fonction correspondante avec les paramètres appropriés. La réponse est également ajoutée à l’historique des conversations.
Voir la réponse du modèle :
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0DeFgH",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
{
"role": "tool",
"content": "{ \"info\": \"There are no flights available from Miami to Seattle. You should take a train, specially if it helps to reduce CO2 emissions.\" }",
"tool_call_id": "abc0DeFgH"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters":{
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": ["origin_city", "destination_city"]
}
}
}
]
}
Appliquer la sécurité du contenu
L’API Inférence de modèle Azure AI prend en charge Azure AI Sécurité du Contenu. Lorsque vous utilisez des déploiements avec la sécurité du contenu Azure AI activée, les entrées et les sorties passent par un ensemble de modèles de classification visant à détecter et à empêcher la sortie de contenu dangereux. Le système de filtrage du contenu détecte les catégories spécifiques de contenu potentiellement nuisible dans les invites d’entrée et les achèvements de sortie et prend des mesures correspondantes.
L’exemple suivant montre comment gérer les évènements lorsque le modèle détecte du contenu dangereux dans l’invite d’entrée et que la sécurité du contenu est activée.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are an AI assistant that helps people find information."
},
{
"role": "user",
"content": "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
}
]
}
{
"error": {
"message": "The response was filtered due to the prompt triggering Microsoft's content management policy. Please modify your prompt and retry.",
"type": null,
"param": "prompt",
"code": "content_filter",
"status": 400
}
}
Conseil
Pour en savoir plus sur la façon dont vous pouvez configurer et contrôler les paramètres de sécurité du contenu Azure AI, consultez la Documentation Azure AI Sécurité du Contenu.
Utiliser les saisies semi-automatiques de conversation avec des images
Certains modèles peuvent raisonner à partir de texte et d’images et générer des complétions de texte basées sur les deux types d’entrée. Dans cette section, vous allez explorer les fonctionnalités de certains modèles pour la vision dans un mode conversation :
Important
Certains modèles prennent en charge une seule image pour chaque tour de conversation, et seule la dernière image est gardée en contexte. Si vous ajoutez plusieurs images, une erreur s’affiche.
Pour afficher cette fonctionnalité, téléchargez une image et encodez les informations en tant que chaîne base64. Les données obtenues doivent se trouver à l’intérieur d’une URL de données:
Conseil
Vous devez construire l’URL de données à l’aide d’un script ou d’un langage de programmation. Ce tutoriel utilise cet exemple d’image au format JPEG. Une URL de données a un format comme suit : data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ....
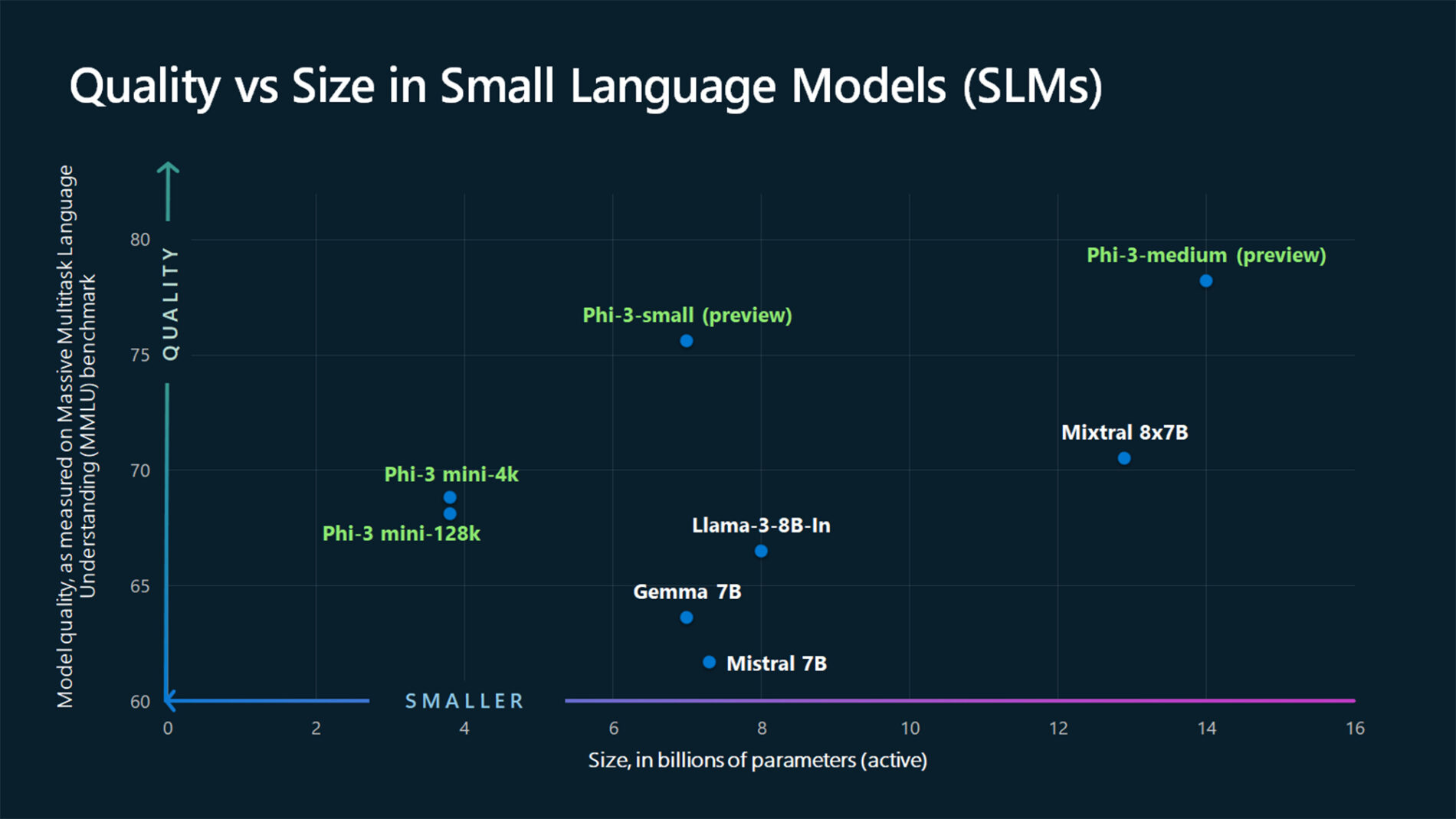{kind=link}
Visualisez l’image :
À présent, créez une demande de saisie semi-automatique de conversation avec l’image :
{
"model": "phi-3.5-vision-instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Which peculiar conclusion about LLMs and SLMs can be extracted from the following chart?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ..."
}
}
]
}
],
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
La réponse est la suivante, où vous pouvez voir les statistiques d'utilisation du modèle :
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "phi-3.5-vision-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 2380,
"completion_tokens": 126,
"total_tokens": 2506
}
}