Registered features - definitions and implementations (p – t) (OpenType 1.8.3)
a - e | f - j | k - o | p - t | u - z
Tag: 'palt'
Friendly name: Proportional Alternate Widths
Registered by: Adobe
Function: Respaces glyphs designed to be set on full-em widths, fitting them onto individual (more or less proportional) horizontal widths. This differs from 'pwid' in that it does not substitute new glyphs (GPOS, not GSUB feature). The user may prefer the monospaced form, or may simply want to ensure that the glyph is well-fit and not rotated in vertical setting (Latin forms designed for proportional spacing would be rotated).
Example: The user may invoke this feature in a Japanese font to get Latin, Kanji, Kana or Symbol glyphs with the full-width design but individual metrics.
Recommended implementation: The font specifies alternate metrics for the full-width glyphs (GPOS lookup type 1).
Application interface: For GIDs found in the 'palt' coverage table, the application passes the GIDs to the table and gets back positional adjustments (XPlacement, XAdvance, YPlacement and YAdvance).
UI suggestion: This feature would be off by default.
Script/language sensitivity: Used mostly in CJKV fonts.
Feature interaction: This feature is mutually exclusive with all other glyph-width features (e.g. 'fwid', 'halt', 'hwid', 'qwid' and 'twid'), which should be turned off when it’s applied. If 'palt' is activated, there is no requirement that 'kern' must also be activated. If 'kern' is activated, 'palt' must also be activated if it exists. See also 'vpal'.
Tag: 'pcap'
Friendly name: Petite Capitals
Registered by: Tiro Typeworks / Emigre
Function: Some fonts contain an additional size of capital letters, shorter than the regular smallcaps and whimsically referred to as petite caps. Such forms are most likely to be found in designs with a small lowercase x-height, where they better harmonise with lowercase text than the taller smallcaps (for examples of petite caps, see the Emigre type families Mrs Eaves and Filosofia). This feature turns lowercase characters into petite capitals. Forms related to petite capitals, such as specially designed figures, may be included.

Example: The user enters text as lowercase or mixed case, and gets petite cap text or text with regular uppercase and petite caps. Note that some designers, might extend the petite cap lookups to include uppercase-to-smallcap substitutions, creating a shifting hierarchy of uppercase forms.
Recommended implementation: The 'pcap' table maps lowercase glyphs to the corresponding petite cap forms (GSUB lookup type 1).
Application interface: For GIDs found in the 'pcap' coverage table, the application passes GIDs to the 'pcap' table, and gets back new GIDs. Petite cap substitutions should follow language rules for smallcap ('smcp') substitutions.
UI suggestion: This feature should be off by default.
Script/language sensitivity: Applies only to scripts with both upper- and lowercase forms (e.g. Latin, Cyrillic, Greek).
Feature interaction: This feature may be used in combination with other substitution (GSUB) features, whose results it may override.
Tag: 'pkna'
Friendly name: Proportional Kana
Registered by: Adobe
Function: Replaces glyphs, kana and kana-related, set on uniform widths (half or full-width) with proportional glyphs.
Example: The user may invoke this feature in a Japanese font to get a proportional glyph instead of a corresponding half- or full-width kana glyph.
Recommended implementation: The font contains alternate kana and kana-related glyphs designed to be set on proportional widths (GSUB lookup type 1).
Application interface: For GIDs found in the 'pkna' coverage table, the application passes the GIDs to the table and gets back new GIDs.
UI suggestion: This feature would normally be off by default.
Script/language sensitivity: Generally used only in Japanese fonts.
Feature interaction: This feature is mutually exclusive with all other glyph-width features (e.g. 'fwid', 'halt', 'hwid', 'palt', 'pwid', 'qwid', 'twid', and 'vhal'), which should be turned off when it’s applied. Applying this feature should activate the 'kern' feature.
Tag: 'pnum'
Friendly name: Proportional Figures
Registered by: Microsoft/Adobe
Function: Replaces figure glyphs set on uniform (tabular) widths with corresponding glyphs set on glyph-specific (proportional) widths. Tabular widths will generally be the default, but this cannot be safely assumed. Of course this feature would not be present in monospaced designs.
Example: The user may apply this feature to get even spacing for lining figures used as dates in an all-cap headline.
Recommended implementation: In order to simplify associated kerning and get the best glyph design for a given width, this feature should use new glyphs for the figures, rather than only adjusting the fit of the tabular glyphs (although some may be simple copies); i.e. not a GPOS feature. The 'pnum' table maps tabular versions of lining and/or oldstyle figures to corresponding proportional glyphs (GSUB lookup type 1).
Application interface: For GIDs found in the 'pnum' coverage table, the application passes GIDs to the 'pnum' table and gets back new GIDs.
UI suggestion: This feature should be off by default. The application may want to query the user about this feature when the user changes figure style ('onum' or 'lnum').
Script/language sensitivity: None.
Feature interaction: This feature overrides the results of the Tabular Figures feature ('tnum').
Tag: 'pref'
Friendly name: Pre-base Forms
Registered by: Microsoft
Function: Substitutes the pre-base form of a consonant.
In some scripts of south or southeast Asia, such as Khmer, the conjoined form of certain consonants is always denoted as a pre-base form. In the case of some scripts of south India, variations in writing conventions exist such that a conjoined Ra consonant may be written as a pre-base form, or a below-base or post-base form. Fonts may be designed to support one or another convention. If a font is designed to support a writing convention in which conjoined Ra is a pre-base form, the Pre-Base Forms feature would be used.
Example: In the Khmer script, the consonant Ra has a pre-base subscript form called Coeng Ra. When the sequence of Coeng followed by Ra occurs, its pre-base form is substituted.
Recommended implementation: The 'pref' table maps the sequence required to convert a consonant into its pre-base form (GSUB lookup type 4).
Application interface: For substitutions defined in the 'pref' table, the application passes the sequence of GIDs to the table, and gets back the GID for the pre base form of the consonant. When shaping scripts of south India, the application may examine the results of processing this feature to determine if the conjoining consonant form needs to be re-ordered.
UI suggestion: In recommended usage, this feature triggers substitutions that are required for correct display of the given script. It should be applied in the appropriate contexts, as determined by script-specific processing. Control of the feature should not generally be exposed to the user.
Script/language sensitivity: Required in Khmer and Myanmar (Burmese) scripts that have pre-base forms for consonants.It is also required for southern Indic scripts that may display a pre-base form of Ra, such as Malayalam or Telugu.
Feature interaction: This feature is used in conjunction with certain other features to derive required forms of certain Indic and southeast Asian scripts. The application is expected to process this feature and certain other features in an appropriate order to obtain the correct set of basic forms for the given script. For Indic scripts, the following features should be applied in order: 'nukt', 'akhn', 'rphf', 'rkrf', 'pref', 'blwf', 'half', 'pstf', 'cjct'. Other discretionary features for optional typographic effects may also be applied. Lookups for such discretionary features should be processed after lookups for this feature have been processed.
Tag: 'pres'
Friendly name: Pre-base Substitutions
Registered by: Microsoft
Function: Produces the pre-base forms of conjuncts in Indic scripts. It can also be used to substitute the appropriate glyph variant for pre-base vowel signs.
Example: In the Gujarati (Indic) script, the doubling of consonant Ka requires the first Ka to be substituted by its pre-base form. This in turn ligates with the second Ka. Applying this feature would result in the ligaturised version of the doubled Ka.
Recommended implementation: The 'pres' table maps a sequence of consonants separated by the virama (halant), to the ligated conjunct form (GSUB lookup type 4). In the case of pre-base matra substitution, the appropriate matra can be substituted using contextual substitution (GSUB lookup type 5).
Application interface: For substitutions defined in the 'pres' table, the application passes the sequence of GIDs to the feature, and gets back the GID for the ligature (or matra as the case may be).
UI suggestion: This feature should be on by default.
Script/language sensitivity: Required in Indic scripts.
Feature interaction: This feature overrides the results of all other features.
Tag: 'pstf'
Friendly name: Post-base Forms
Registered by: Microsoft
Function: Substitutes the post-base form of a consonant.
Example: In the Gurmukhi (Indic) script, the consonant Ya has a post base form. When the Ya is used as the second consonant in conjunct formation, its post-base form is substituted.
Recommended implementation: The 'pstf' table maps the sequence required to convert a consonant into its post-base form (GSUB lookup type 4).
Application interface: For substitutions defined in the 'pstf' table, the application passes the sequence of GIDs to the feature, and gets back the GID for the post base form of the consonant.
UI suggestion: In recommended usage, this feature triggers substitutions that are required for correct display of the given script. It should be applied in the appropriate contexts, as determined by script-specific processing. Control of the feature should not generally be exposed to the user.
Script/language sensitivity: Required in scripts of south and southeast Asia that have post-base forms for consonants eg: Gurmukhi, Malayalam, Khmer.
Feature interaction: This feature is used in conjunction with certain other features to derive required forms of Indic and other related scripts. The application is expected to process this feature and certain other features in an appropriate order to obtain the correct set of basic forms for the given script. For Indic scripts, the following features should be applied in order: 'nukt', 'akhn', 'rphf', 'rkrf', 'pref', 'blwf', 'half', 'pstf', 'cjct'. Other discretionary features for optional typographic effects may also be applied. Lookups for such discretionary features should be processed after lookups for this feature have been processed.
Tag: 'psts'
Friendly name: Post-base Substitutions
Registered by: Microsoft
Function: Substitutes a sequence of a base glyph and post-base glyph, with its ligaturised form.
Example: In the Malayalam (Indic) script, the consonant Va has a post base form. When the Va is doubled to form a conjunct- VVa; the first Va [base] and the post base form that follows it, is substituted with a ligature.
Recommended implementation: The 'psts' table maps identified conjunct formation sequences to corresponding ligatures (GSUB lookup type 4).
Application interface: For substitutions defined in the 'psts' table, the application passes the sequence of GIDs to the feature, and gets back the GID for the ligature.
UI suggestion: This feature should be on by default.
Script/language sensitivity: Can be used in any alphabetic script. Required in Indic scripts.
Feature interaction: This feature overrides the results of all other features.
Tag: 'pwid'
Friendly name: Proportional Widths
Registered by: Adobe
Function: Replaces glyphs set on uniform widths (typically full or half-em) with proportionally spaced glyphs. The proportional variants are often used for the Latin characters in CJKV fonts, but may also be used for Kana in Japanese fonts.
Example: The user may invoke this feature in a Japanese font to get a proportionally-spaced glyph instead of a corresponding half-width Roman glyph or a full-width Kana glyph.
Recommended implementation: The font contains alternate glyphs designed to be set on proportional widths (GSUB lookup type 1).
Application interface: For GIDs found in the 'pwid' coverage table, the application passes the GIDs to the table and gets back new GIDs.
UI suggestion: Applications may want to have this feature active or inactive by default depending on their markets.
Script/language sensitivity: Although used mostly in CJKV fonts, this feature could be applied in European scripts.
Feature interaction: This feature is mutually exclusive with all other glyph-width features (e.g. 'fwid', 'halt', 'hwid', 'palt', 'qwid', 'twid', 'valt' and 'vhal'), which should be turned off when it’s applied. Applying this feature should activate the 'kern' feature.
Tag: 'qwid'
Friendly name: Quarter Widths
Registered by: Adobe
Function: Replaces glyphs on other widths with glyphs set on widths of one quarter of an em (half an en). The characters involved are normally figures and some forms of punctuation.
Example: The user may apply 'qwid' to place a four-digit figure in a single slot in a column of vertical text.
Recommended implementation: The font may contain alternate glyphs designed to be set on quarter-em widths (GSUB lookup type 1), or it may specify alternate metrics for the original glyphs (GPOS lookup type 1) which adjust their spacing to fit in quarter-em widths.
Application interface: For GIDs found in the 'qwid' coverage table, the application passes the GIDs to the table and gets back either new GIDs or positional adjustments (XPlacement and XAdvance).
UI suggestion: This feature would normally be off by default.
Script/language sensitivity: Generally used only in CJKV fonts.
Feature interaction: This feature is mutually exclusive with all other glyph-width features (e.g. 'fwid', 'halt', 'hwid' and 'twid'), which should be turned off when it’s applied. It deactivates the 'kern' feature.
Tag: 'rand'
Friendly name: Randomize
Registered by: Adobe
Function: In order to emulate the irregularity and variety of handwritten text, this feature allows multiple alternate forms to be used.
Example: The user applies this feature in FF Kosmic to get three forms of f in one word.
Recommended implementation: The rand table maps GIDs for default glyphs to one or more GIDs for corresponding alternates (GSUB lookup type 3).
Application interface: For GIDs found in the rand coverage table, the application passes a GID to the rand table and gets back one or more new GIDs. The application selects one of these either by a pseudo-random algorithm, or by noting the sequence of IDs returned, storing that sequence, and stepping through that set as the corresponding character code is invoked.
UI suggestion: This feature should be enabled/disabled via a preference setting; “enabled” is the recommended default.
Script/language sensitivity: None.
Feature interaction: This feature may be used in combination with other substitution (GSUB) features, whose results it may override.
Tag: 'rclt'
Friendly name: Required Contextual Alternates
Registered by: Microsoft
Function: In specified situations, replaces default glyphs with alternate forms which provide for better joining behavior or other glyph relationships. Especially important in script typefaces which are designed to have some or all of their glyphs join, but applicable also to e.g. variants to improve spacing. This feature is similar to 'calt', but with the difference that it should not be possible to turn off 'rclt' substitutions: they are considered essential to correct layout of the font.
Example: In an Arabic calligraphic font the 'rclt' feature is used to contextually substitute variant forms of letters sin and yeh providing for a correct join between these two letters that differs from the default join of either to other letters.
Recommended implementation: The 'rclt' table specifies the context in which each substitution occurs, and maps one or more default glyphs to replacement glyphs (GSUB lookup type 6).
Application interface: The application passes sequences of GIDs to the feature table, and gets back new GIDs. Note that full sequences must be passed.
UI suggestion: This feature should be active by default. It is recommended that this feature not be turned off, to avoid breaking obligatory shaping.
Script/language sensitivity: May apply to any script, but is especially important for many styles of Arabic.
Feature interaction: This feature may be used in combination with other substitution (GSUB) features, whose results it may override. For complex scripts, lookups for this feature should be ordered and processed after basic script and language shaping features.
Tag: 'rlig'
Friendly name: Required Ligatures
Registered by: Microsoft
Function: Replaces a sequence of glyphs with a single glyph which is preferred for typographic purposes. This feature covers those ligatures, which the script determines as required to be used in normal conditions. This feature is important for some scripts to insure correct glyph formation.
Example: The Arabic character lam followed by alef will always form a ligated lamalef form. This ligated form is a requirement of the script’s shaping. The same happens with the Syriac script.
Recommended implementation: The 'rlig' table maps GIDs for default glyphs to one or more GIDs for corresponding alternates (GSUB lookup type 3).
Application interface: The 'rlig' table maps sequences of glyphs to corresponding ligatures (GSUB lookup type 4). Ligatures with more components must be stored ahead of those with fewer components in order to be found. The set of standard ligatures will normally remain constant by script.
UI suggestion: This feature should be active by default. It is recommended that this feature not be turned off to avoid breaking obligatory script shaping.
Script/language sensitivity: Applies to Arabic and Syriac. May apply to some other scripts.
Feature interaction: This feature may be used in combination with other substitution (GSUB) features, whose results it may override. See also 'liga'.
Tag: 'rkrf'
Friendly name: Rakar Forms
Registered by: Microsoft
Function: Produces conjoined forms for consonants with rakar in Devanagari and Gujarati scripts.
In Devanagari and Gujarati scripts, consonant clusters involving Ra following another consonant are denoted by conjoining an alternate form of Ra to the preceding consonant. Depending on the particular syllable, the preceding consonant may be denoted in its full form or as a half form. Because of interactions involving other behaviors of these scripts, a font implementation may need to process substitution lookups for rakar forms and half forms in a particular sequence in order to derive the appropriate display for various sequences. In recommended usage, the Rakar Forms feature is processed before the Half Forms feature; a half form for a given consonant-Ra combination can be derived by subsequent application of the Half Forms feature. This sequential ordering allows for correct display results.
Example: In Hindi (Devanagari script), the conjunct KRa is denoted with a conjunct ligature form.
Recommended implementation: The 'rkrf' table maps the sequence of a consonant (the nominal form only) followed by a virama (halant) followed by Ra (the nominal form) to the corresponding conjoined form (GSUB lookup type 4).
Application interface: For substitution sequences defined in the 'rkrf' table, the application passes the sequence of GIDs to the table, and gets back the GID for the half form.
UI suggestion: In recommended usage, this feature triggers substitutions that are required for correct display of the given script. It should be applied in the appropriate contexts, as determined by script-specific processing. Control of the feature should not generally be exposed to the user.
Script/language sensitivity: Required in Devanagari and Gujarati scripts.
Feature interaction: This feature is used in conjunction with certain other features to derive required forms of Indic scripts. The application is expected to process this feature and certain other features in an appropriate order to obtain the correct set of basic forms: 'nukt', 'akhn', 'rphf', 'rkrf', 'pref', 'blwf', 'half', 'pstf', 'cjct'. Other discretionary features for optional typographic effects may also be applied. Lookups for such discretionary features should be processed after lookups for this feature have been processed.
Tag: 'rphf'
Friendly name: Reph Form
Registered by: Microsoft
Function: Substitutes the Reph form for a consonant and halant sequence.
Example: In the Devanagari (Indic) script, the consonant Ra possesses a reph form. When the Ra is a syllable initial consonant and is followed by the virama, it is repositioned after the post base vowel sign within the syllable, and also substituted with a mark that sits above the base glyph.
Recommended implementation: The 'rphf' table maps the sequence of default form of Ra and virama to the Reph (GSUB lookup type 4).
Application interface: The application passes the GIDs for Ra and virama to the table and gets back the GID for the reph mark. The application may examine the results of processing other features to determine where in the sequence the reph mark should be re-ordered to.
UI suggestion: In recommended usage, this feature triggers substitutions that are required for correct display of the given script. It should be applied in the appropriate contexts, as determined by script-specific processing. Control of the feature should not generally be exposed to the user.
Script/language sensitivity: Required in Indic scripts. eg: Devanagari, Kannada.
Feature interaction: This feature is used in conjunction with certain other features to derive required forms of Indic scripts. The application is expected to process this feature and certain other features in an appropriate order to obtain the correct set of basic forms: 'nukt', 'akhn', 'rphf', 'rkrf', 'pref', 'blwf', 'half', 'pstf', 'cjct'. Other discretionary features for optional typographic effects may also be applied. Lookups for such discretionary features should be processed after lookups for this feature have been processed.
Tag: 'rtbd'
Friendly name: Right Bounds
Registered by: Adobe
Function: Aligns glyphs by their apparent right extents at the right ends of horizontal lines of text, replacing the default behavior of aligning glyphs by their origins. This feature is called by the Optical Bounds ('opbd') feature.
Example: Succeeding lines ending with r, h and y would shift to the right by differing degrees when the text is right-justified and this feature is applied.
Recommended implementation: Values for affected glyphs describe the amount by which the placement and advance width should be altered (GPOS lookup type 1).
Application interface: For GIDs found in the 'rtbd' coverage table, the application passes a GID to the table and gets back a new XPlacement and XAdvance value.
UI suggestion: This feature is called by an application when the user invokes the 'opbd' feature.
Script/language sensitivity: None.
Feature interaction: Should not be applied to glyphs which use fixed-width features (e.g. 'fwid', 'halt', 'hwid', 'qwid' and 'twid') or vertical features (e.g. 'vert', 'vrt2', 'vpal', 'valt' and 'vhal'). Is called by 'opbd' feature.
Tag: 'rtla'
Friendly name: Right-to-left alternates
Registered by: Adobe
Function: This feature applies glyphic variants (other than mirrored forms) appropriate for right-to-left text. (For mirrored forms, see 'rtlm'.)
Recommended implementation: These are required to be glyph substitutions, and it is recommended that they be one-to-one (GSUB lookup type 1).
Application interface: See section “Left-to-right and right-to-left text” on the Advanced Typographic Extensions page.
UI suggestion: None.
Script/language sensitivity: Right-to-left runs of text.
Feature interaction: This feature is to be applied simultaneously with other pre-shaping features such as 'ccmp' and 'locl'.
Tag: 'rtlm'
Friendly name: Right-to-left mirrored forms
Registered by: Adobe
Function: This feature applies mirrored forms appropriate for right-to-left text other than for those characters that would be covered by the character-level mirroring step performed by an OpenType layout engine. (For right-to-left glyph alternates, see 'rtla'.)
Example: The 'rtlm' feature replaces the glyph for U+2232, CLOCKWISE CONTOUR INTEGRAL, with one in which the integral sign is mirrored but the circular arrow has retained its direction.
Implementation: These are required to be glyph substitutions, and it is recommended that they be one-to-one (GSUB lookup type 1).
Application interface: See section “Left-to-right and right-to-left text” on the Advanced Typographic Extensions page.
UI suggestion: None.
Script/language sensitivity: Right-to-left runs of text.
Feature interaction: This feature is to be applied simultaneously with other pre-shaping features such as 'ccmp' and 'locl'.
Tag: 'ruby'
Friendly name: Ruby Notation Forms
Registered by: Adobe
Function: Japanese typesetting often uses smaller kana glyphs, generally in superscripted form, to clarify the meaning of kanji which may be unfamiliar to the reader. These are called “ruby”, from the old typesetting term for four-point-sized type. This feature identifies glyphs in the font which have been designed for this use, substituting them for the default designs.
Example: The user applies this feature to the kana character U+3042, to get the ruby form for annotation.
Recommended implementation: The font contains alternate glyphs for all kana characters which are enabled for ruby notation. The 'ruby' table maps GIDs for default forms to GIDs for corresponding ruby alternates. These are one-to-one substitutions (GSUB lookup type 1).
Application interface: For GIDs found in the 'ruby' coverage table, the application passes the GIDs for default forms to the table and gets back new GIDs for ruby forms. The application then scales and positions these forms according to its defaults, which may take user parameters.
UI suggestion: This feature should be inactive by default. Applications may offer the user an opportunity to specify the degree of scaling and baseline shift.
Script/language sensitivity: Applies only to Japanese.
Feature interaction: This feature overrides the results of any other feature for the affected characters.
Tag: 'rvrn'
Friendly name: Required Variation Alternates
Registered by: Microsoft
Function: This feature is used in fonts that support OpenType Font Variations in order to select alternate glyphs for particular variation instances. (For background on OpenType Font Variations, see OpenType Font Variations Overview.)
When a variable font is used, all of the interpolated variants of a given glyph ID have exactly the same contours and points. It is possible to use glyph variation mechanisms to make significant outline changes, such as reducing strokes in heavy-weight or narrow-width variants, but this approach may be difficult to implement and may not produce desired results for all variation instances. Instead, better results for these scenarios might be achieved by substitution to a different glyph ID. The specific substitutions applied would be conditioned by the particular variation instance that is selected by the user. This conditional behavior is implemented using the required variation alternates feature in conjunction with a FeatureVariations table within the GSUB table.
Example: A variable font supports weight variations ranging from thin to black. The default glyph for the dollar sign has two vertical strokes running through the full extent of the glyph. In the bold variation instance, the default glyph is substituted to an alternate glyph that has only one vertical stroke. In the black variation instance, the default glyph is substituted to an alternate glyph have has only single vertical bars at the top and bottom extremities, with no vertical bars in the two counters in between.
Recommended implementation: The feature is used to activate single substitution (GSUB type 1) lookups, and is always used in conjunction with a FeatureVariations table. Typically, a FeatureTable referenced in a FeatureRecord with the 'rvrn' tag will have LookupCount set to 0; in this way, the default variation instance does not have any glyph substitution applied but, rather, uses default glyphs. Alternate glyphs for particular variation instances are obtained by adding a substitution of the feature table to an alternate feature table within a FeatureVariations table. Different alternate feature tables may be selected using condition sets that specify particular variation-axis value ranges.
One or more Condition tables is used to determine variation-axis value ranges for which an alternate feature table (and associated lookups) is selected. The axis values used to trigger a condition should normally be midway between values used for named instances. This will avoid any possibility of inconsistent behavior in different applications when using named instances that might arise due to small discrepancies in processing the numeric values.
The default language system for the DFLT script can reference a feature record for this feature with a feature table that will be substituted for particular variation instances to use lookups that apply default, language-independent glyph substitutions; this feature record should be the first feature record for this feature. Some applications may choose to process this feature without processing other features or the script/language system hierarchy; for this purpose, they should choose the first feature record for this feature to obtain the most suitable substitutions for language-independent results.
Application interface: Application of the 'rvrn' feature is mandatory in implementations that support OpenType Font Variations whenever a variable font is in use. The feature should be processed in any layout process that supports use of variations, even if other OpenType Layout processing is not supported.
The feature is applied only during the process of deriving final glyph IDs (GSUB); it is not used for glyph positioning (GPOS). It should be processed early in GSUB processing, before application of the localized forms feature or features related to shaping of complex scripts or discretionary typographic effects.
Processing of the 'rvrn' feature also requires processing of the FeatureVariations table. ConditionSet tables are scanned for a ConditionSet matching the current variation instance, and then a corresponding FeatureTableSubstitution table is used to locate an alternate feature table. For complete details on processing a FeatureVariations table, see OpenType Layout Common Table Formats .
When an applicable feature table is located, only single substitution (GSUB type 1) lookups are processed; any other lookup types are ignored. For any glyph IDs in the coverage table, the application passes the glyph ID to the lookup, and gets back the new glyph ID.
UI suggestion: The 'rvrn' feature is mandatory: it should be active by default and not directly exposed to user control.
Script/language sensitivity: Used for all languages and scripts.
Feature interaction: The feature should be processed early after initial character-to-glyph mapping, before application of the localized forms ('locl') feature, any features related to shaping of complex scripts, or any discretionary features.
Tag: 'salt'
Friendly name: Stylistic Alternates
Registered by: Adobe
Function: Many fonts contain alternate glyph designs for a purely esthetic effect; these don’t always fit into a clear category like swash or historical. As in the case of swash glyphs, there may be more than one alternate form. This feature replaces the default forms with the stylistic alternates.
Example: The user applies this feature to Industria to get the alternate form of g.
Recommended implementation: The 'salt' table maps GIDs for default forms to one or more GIDs for corresponding stylistic alternatives. While many of these substitutions are one-to-one (GSUB lookup type 1), others require a selection from a set (GSUB lookup type 3). The manufacturer may choose to build two tables (one for each lookup type) or only one which uses lookup type 3 for all substitutions. As in any one-from-many substitution, alternates present in more than one face should be ordered consistently across a family, so that those alternates can work correctly when switching between family members.
Application interface: For GIDs found in the 'salt' coverage table, the application passes the GIDs to the 'salt' table and gets back one or more new GIDs. If more than one GID is returned, the application must provide a means for the user to select the one desired.
UI suggestion: This feature should be inactive by default. When more than one GID is returned, an application could display the forms sequentially in context, or present a palette showing all the forms at once, or give the user a choice between these approaches. The application may assume that the first glyph in a set is the preferred form, so the font developer should order them accordingly.
Script/language sensitivity: None.
Feature interaction: This feature may be used in combination with other substitution (GSUB) features, whose results it may override.
Tag: 'sinf'
Friendly name: Scientific Inferiors
Registered by: Microsoft/Adobe
Function: Replaces lining or oldstyle figures with inferior figures (smaller glyphs which sit lower than the standard baseline, primarily for chemical or mathematical notation). May also replace lowercase characters with alphabetic inferiors.
Example: The application can use this feature to automatically access the inferior figures (more legible than scaled figures).
Recommended implementation: The 'sinf' table maps figures to the corresponding inferior forms (GSUB lookup type 1).
Application interface: For GIDs found in the 'sinf' coverage table, the application passes a GID to the feature and gets back a new GID.
UI suggestion: This feature should be off by default.
Script/language sensitivity: Can apply to nearly any script.
Feature interaction: This feature may be used in combination with other substitution (GSUB) features, whose results it may override.
Tag: 'size'
Note: Use of this feature has been superseded by the STAT table. See “Families with Optical Size Variants” in the Recommendations section for more information.
Friendly name: Optical size
Registered by: Adobe
Function: This feature stores two kinds of information about the optical size of the font: design size (the point size for which the font is optimized) and size range (the range of point sizes which the font can serve well), as well as other information which helps applications use the size range. The design size is useful for determining proper tracking behavior. The size range is useful in families which have fonts covering several ranges. Additional values serve to identify the set of fonts which share related size ranges, and to identify their shared name. Note that sizes refer to nominal final output size, and are independent of viewing magnification or resolution.
Required implementation:
The Feature table of this GPOS feature contains no lookups; its Feature Parameters field records an offset from the beginning of the Feature table to an array of five 16-bit unsigned integer values. The size feature must be implemented in all fonts in any family which uses the feature. In this usage, a family is a set of fonts which share a Typographic Family name (name ID 16), or Font Family name (name ID 1) if the Typographic Family name is absent.
- The first value represents the design size in 720/inch units (decipoints). The design size entry must be non-zero. When there is a design size but no recommended size range, the rest of the array will consist of zeros.
- The second value has no independent meaning, but serves as an identifier that associates fonts in a subfamily. All fonts which share a Typographic or Font Family name and which differ only by size range shall have the same subfamily value, and no fonts which differ in weight or style shall have the same subfamily value. If this value is zero, the remaining fields in the array will be ignored.
- The third value enables applications to use a single name for the subfamily identified by the second value. If the preceding value is non-zero, this value must be set in the range 256 - 32767 (inclusive). It records the value of a field in the 'name' table, which must contain English-language strings encoded in Windows Unicode and Macintosh Roman, and may contain additional strings localized to other scripts and languages. Each of these strings is the name an application should use, in combination with the family name, to represent the subfamily in a menu. Applications will choose the appropriate version based on their selection criteria.
- The fourth and fifth values represent the small end of the recommended usage range (exclusive) and the large end of the recommended usage range (inclusive), stored in 720/inch units (decipoints). Ranges must not overlap, and should generally be contiguous.
Example: The 'size' information in Bell Centennial is [60 0 0 0 0]. This tells an application that the font’s design size is six points, so larger sizes may need proportionate reduction in default inter-glyph spacing. The 'size' information in Minion Pro Semibold Condensed Subhead is [180 3 257 139 240]. These values tell an application that:
- The font’s design size is 18 points;
- This font is part of a subfamily of fonts that differ only by the size range which each covers, and which share the arbitrary identifier number 3;
- ID 257 in the 'name' table is the suggested menu name for this subfamily. In this case, the string at name ID 257 is Semibold Condensed;
- This font is the recommended choice from sizes greater than 13.9-point up through 24-points.
Application interface: When the user specifies a size, the application checks for a 'size' feature in the active font. If none is found, the application follows its default behavior. If one is found, the application follows the specified offset to retrieve the five values.
Design size: Applications which offer size-based tracking have a pre-defined curve which they can apply. By default, this curve should be set to produce no adjustment at the font’s design size (first value in the array, in decipoints).
Size ranges: If the second value in the 'size' array is non-zero, the font has a recommended size range. When any such font is selected by the user, the application builds a list of all fonts with this subfamily value and the same Typographic Family name, and notes the size range in the current font. Applications may want to cache the subfamily list at this point. If the specified size falls in the current font’s range, the application uses the current font. If not, the application checks the other ranges in the subfamily, and if the specified size falls in one of them, uses that font. If the specified size is not in any range present, the font with the range closest to the specified value is used. If the specified size falls exactly between two ranges, the range with the larger values is used. Since adding or removing fonts from a subfamily may cause reflow, applications should note which fonts are used for which text.
UI suggestion: This feature should be active by default. Applications may want to present the tracking curve to the user for adjustments via a GUI. At start-up, and when fonts are added or removed, applications may want to build a list of fonts with such ranges, and display the filtered subfamily names in their font selection UI, with each filtered name representing the full set of related sizes. Applications may also present a setting which allows the user to select non-default sizes (for example, in the case where final output is intended for on-screen viewing, a smaller optical size will produce better results). In such a case, the font-selection UI should present the unfiltered names. Applications should notify the user if fonts are removed or added from a subfamily with size ranges, and query about desired behavior.
Script/language sensitivity: None. The FeatureParams of all 'size' features in the GPOS FeatureList must point to the same set of values.
Feature interaction: None.
Tag: 'smcp'
Friendly name: Small Capitals
Registered by: Microsoft/Adobe
Function: This feature turns lowercase characters into small capitals. This corresponds to the common SC font layout. It is generally used for display lines set in Large & small caps, such as titles. Forms related to small capitals, such as oldstyle figures, may be included.
Example: The user enters text as mixed capitals and lowercase, and gets Large & small cap text.
Recommended implementation: The 'smcp' table maps lowercase glyphs to the corresponding small-cap forms (GSUB lookup type 1).
Application interface: For GIDs found in the 'smcp' coverage table, the application passes GIDs to the 'smcp' table, and gets back new GIDs. Note that applications should treat ß (U+00DF) as a pair of s characters, and that the Turkish dotless i maps to the normal small cap I.
UI suggestion: This feature should be off by default.
Script/language sensitivity: Applies only to bicameral scripts (i.e. those with case differences), such as Latin, Greek, Cyrillic, and Armenian.
Feature interaction: This feature may be used in combination with other substitution (GSUB) features, whose results it may override. Also see 'c2sc'.
Tag: 'smpl'
Friendly name: Simplified Forms
Registered by: Adobe
Function: Replaces “traditional” Chinese or Japanese forms with the corresponding “simplified” forms.
Example: The user gets U+53F0 when U+6AAF, U+81FA, or U+98B1 is entered.
Recommended implementation: The 'smpl' table maps each traditional form in a font to a corresponding simplified form (GSUB lookup type 1). Note that more than one traditional form may map to a single simplified form.
Application interface: For GIDs found in the 'smpl' coverage table, the application passes the GIDs to the table and gets back one new GID for each. Note: This is a change of character code. Besides the original character code, the application should store the code for the new character.
UI suggestion: This feature would be off by default, but could be made the default by a preference setting.
Script/language sensitivity: Applies only to Chinese and Japanese.
Feature interaction: This feature is mutually exclusive with all other features, which should be turned off when it’s applied, except the 'palt', 'vert' and 'vrt2' features, which may be used in addition; 'trad' and 'tnam' are mutally exclusive, and override the results of 'smpl'.
Tag: 'ss01' - 'ss20'
Friendly name: Stylistic Set 1 - Stylistic Set 20
Registered by: Tiro Typeworks
Function: In addition to, or instead of, stylistic alternatives of individual glyphs (see 'salt' feature), some fonts may contain sets of stylistic variant glyphs corresponding to portions of the character set, e.g. multiple variants for lowercase letters in a Latin font. Glyphs in stylistic sets may be designed to harmonise visually, interract in particular ways, or otherwise work together. Examples of fonts including stylistic sets are Zapfino Linotype and Adobe’s Poetica. Individual features numbered sequentially with the tag name convention 'ss01', 'ss02', 'ss03'… 'ss20' provide a mechanism for glyphs in these sets to be associated via GSUB lookup indexes to default forms and to each other, and for users to select from available stylistic sets.
Recommended implementation: An 'ssXX' table maps GIDs for default forms to GIDs for corresponding stylistic alternatives in each set. Each 'ssXX' feature uses one-to-one (GSUB lookup type 1) substitutions. Font developers may choose to map only from default forms to variants for each stylistic set, or may choose to map between all stylistic sets in each feature, depending on intended user experience. For example, feature 'ss03' might contain lookups mapping variant glyphs from 'ss01' and 'ss02' to corresponding variants in 'ss03', in addition to mapping from default forms.
The FeatureParams field of the Feature Table of these GSUB features may be set to 0, or to an offset to a Feature Parameters table comprising two successive uint16 values, as follows:
Version (set to 0): This corresponds to a “minor” version number. Additional data may be added to the end of this Feature Parameters table in the future.
UI Name ID: The 'name' table name ID that specifies a string (or strings, for multiple languages) for a user-interface label for this feature. The value of uiLabelNameId is expected to be in the font-specific name ID range (256-32767), though that is not a requirement in this Feature Parameters specification. The user-interface label for the feature can be provided in multiple languages. An English string should be included as a fallback. The string should be kept to a minimal length to fit comfortably with different application interfaces.
Application interface: Note that the application is responsible for counting and enumerating the number of features in the font with tag names of the format 'ss01' to 'ss20', and for presenting the user with an appropriate selection mechanism. For GIDs found in the 'ssXX' coverage table, the application passes the GIDs to the 'ssXX' table and gets back one or more new GIDs.
UI suggestion: This feature should be off by default.
Script/language sensitivity: None. For each respective[/distinct] 'ssXX' feature, the FeatureParams in the FeatureList must point to the same set of values.
Feature interaction: This feature may be used in combination with other substitution (GSUB) features, whose results it may override. Note that after an 'ssXX' feature has been applied, the user may wish to apply glyph-specific features, e.g. 'salt', to individual glyphs in the resulting layout; font developers are responsible for ordering substitution lookups to obtain desired user experience.
Tag: 'ssty'
Friendly name: Math script style alternates
Registered by: Microsoft
Function: This feature provides glyph variants adjusted to be more suitable for use in subscripts and superscripts. The script style forms should not be scaled or moved in the font; scaling and moving them is done by the math handling client. Instead, the 'ssty' feature should provide glyph forms that result in shapes that look good as superscripts and subscripts when scaled and positioned by the Math engine. When designing the script forms, the font developer may assume that MATH.MathConstants.scriptPercentScaleDown and MATH.MathConstants.scriptScriptPercentScaleDown will be the scaling factors used by the Math engine.
This feature can have a parameter indicating the script level: 1 for simple subscripts and superscripts, 2 for second level subscripts and superscripts (that is, scripts on scripts), and so on. (Currently, only the first two alternates are used). For glyphs that are not covered by this feature, the original glyph is used in subscripts and superscripts..
Example: In 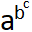 formula letter b will be substituted with script level 1 variant and letter c will be substituted with script level 2 variant.
formula letter b will be substituted with script level 1 variant and letter c will be substituted with script level 2 variant.
Recommended implementation: Alternate substitution, with parameter 1 or 2 corresponding to sub- or super-script level alternate glyphs. If there are no second-level alternates defined in the font, single substitution may also be used. Glyphs that don’t have script alternates can be omitted from this table. See the MATH table specification for details.
Application interface: Feature is invoked automatically by math layout handler depending on nesting level inside the math formula.
UI suggestion: In recommended usage, this feature triggers substitutions that are required for correct display of math formula. It should be applied in the appropriate contexts, as determined by math layout handler. Control of the feature should not generally be exposed to the user.
Script/language sensitivity: Applied to math formula layout.
Feature interaction: This feature is applied to individual glyphs during layout of math formula.
Tag: 'stch'
Friendly name: Stretching Glyph Decomposition
Registered by: Microsoft
Function: Unicode characters, such as the Syriac Abbreviation Mark (U+070F), that enclose other characters need to be able to stretch in order to dynamically adapt to the width of the enclosed text. This feature defines a decomposition set consisting of an odd number of glyphs which describe the stretching glyph. The odd numbered glyphs in the decomposition are fixed reference points which are distributed evenly from the start to the end of the enclosed text. The even numbered glyphs may be repeated as necessary to fill the space between the fixed glyphs. The first and last glyphs may either be simple glyphs with width at the baseline, or mark glyphs. All other decomposition glyphs should have width, but must be defined as mark glyphs.
Example: In Syriac, the character 0x070F is a control character that is rendered as a line above an abbreviation in Syriac script. The line should have a circle at each end and at the mid point. The decomposition sequence for this character should consist of a circle at the start of a line, a connecting line, a circle on a line for the mid point, a second connecting line, and a circle at the end of the line. The connecting lines will repeat in order to fill the space between the circle glyphs.
Recommended implementation: The 'stch' table maps the character to a set containing an odd number of corresponding glyphs (GSUB lookup type 2). The rendering engine reorders the last glyph from the substituted set to the end of the set of characters being enclosed. The remaining glyphs from the substituted set are positioned at the start of the set of characters being enclosed. Odd-numbered glyphs in the decomposition set are positioned so that they are distributed evenly over the width of the text being enclosed. Even-numbered glyphs in the decomposition set are repeated by the rendering engine so the width of the space between fixed, odd-numbered glyphs is filled by the spacing, even-numbered glyphs.
Application interface: For GIDs found in the 'stch' coverage table, the application passes the sequence of GIDs to the table, and gets back the GIDs for the multiple substitution.
UI suggestion: This feature should be on by default.
Script/language sensitivity: None
Feature interaction: None
Tag: 'subs'
Friendly name: Subscript
Registered by: Microsoft/Adobe
Function: The 'subs' feature may replace a default glyph with a subscript glyph, or it may combine a glyph substitution with positioning adjustments for proper placement.
Recommended implementation: First, a single or contextual substitution lookup implements the subscript glyph (GSUB lookup type 1). Then, if the glyph needs repositioning, an application may apply a single adjustment, pair adjustment, or contextual adjustment positioning lookup to modify its position.
Application interface: For GIDs found in the 'subs' coverage table, the application passes a GID to the feature and gets back a new GID. Note: This is a change of semantic value. Besides the original character codes, the application should store the code for the new character.
UI suggestion: This feature should be off by default.
Script/language sensitivity: Can apply to nearly any script.
Feature interaction: This feature may be used in combination with other substitution (GSUB) features, whose results it may override.
Tag: 'sups'
Friendly name: Superscript
Registered by: Microsoft/Adobe
Function: Replaces lining or oldstyle figures with superior figures (primarily for footnote indication), and replaces lowercase letters with superior letters (primarily for abbreviated French titles).
Example: The application can use this feature to automatically access the superior figures (more legible than scaled figures) for footnotes, or the user can apply it to Mssr to get the classic form.
Recommended implementation: The 'sups' table maps figures and lowercase letters to the corresponding superior forms (GSUB lookup type 1).
Application interface: For GIDs found in the 'sups' coverage table, the application passes a GID to the feature and gets back a new GID. Note: This can include a change of semantic value. Besides the original character codes, the application should store the code for the new character.
UI suggestion: This feature should be off by default.
Script/language sensitivity: Can apply to nearly any script.
Feature interaction: This feature may be used in combination with other substitution (GSUB) features, whose results it may override.
Tag: 'swsh'
Friendly name: Swash
Registered by: Microsoft/Adobe
Function: This feature replaces default character glyphs with corresponding swash glyphs. Note that there may be more than one swash alternate for a given character.
Example: The user inputs the ampersand character when setting text with Poetica with this feature active, and is presented with a choice of the 63 ampersand forms in that face.
Recommended implementation: The 'swsh' table maps GIDs for default forms to those for one or more corresponding swash forms. While many of these substitutions are one-to-one (GSUB lookup type 1), others require a selection from a set (GSUB lookup type 3). The manufacturer may choose to build two tables (one for each lookup type) or only one which uses lookup type 3 for all substitutions. If several styles of swash are present across the font, the set of forms for each character should be ordered consistently.
Application interface: For GIDs found in the 'swsh' coverage table, the application passes the GIDs to the 'swsh' table and gets back one or more new GIDs. If more than one GID is returned, the application must provide a means for the user to select the one desired.
UI suggestion: This feature should be inactive by default. When more than one GID is returned, an application could display the forms sequentially in context, or present a palette showing all the forms at once, or give the user a choice between these approaches. The application may assume that the first glyph in a set is the preferred form, so the font developer should order them accordingly.
Script/language sensitivity: Does not apply to ideographic scripts.
Feature interaction: This feature may be used in combination with other substitution (GSUB) features, whose results it may override.
Tag: 'titl'
Friendly name: Titling
Registered by: Adobe
Function: This feature replaces the default glyphs with corresponding forms designed specifically for titling. These may be all-capital and/or larger on the body, and adjusted for viewing at larger sizes.
Example: The user applies this feature in Adobe Garamond to get the titling caps.
Recommended implementation: The 'titl' table maps default forms to corresponding titling forms (GSUB lookup type 1).
Application interface: For GIDs found in the 'titl' coverage table, the application passes the GIDs to the 'titl' table and gets back new GIDs.
UI suggestion: This feature should be off by default.
Script/language sensitivity: None.
Feature interaction: This feature may be used in combination with other substitution (GSUB) features, whose results it may override.
Tag: 'tjmo'
Friendly name: Trailing Jamo Forms
Registered by: Microsoft
Function: Substitutes the trailing jamo form of a cluster.
Example: In Hangul script, the jamo cluster is composed of three parts (leading consonant, vowel, and trailing consonant). When a sequence of trailing class jamos are found, their combined trailing jamo form is substituted.
Recommended implementation: The 'tjmo' table maps the sequence required to convert a series of jamos into its trailing jamo form (GSUB lookup type 4).
Application interface: For substitutions defined in the 'tjmo' table, the application passes the sequence of GIDs to the feature, and gets back the GID for the trailing jamo form.
UI suggestion: This feature should be on by default.
Script/language sensitivity: Required for Hangul script when Ancient Hangul writing system is supported.
Feature interaction: This feature overrides the results of all other features.
Tag: 'tnam'
Friendly name: Traditional Name Forms
Registered by: Adobe
Function: Replaces “simplified” Japanese kanji forms with the corresponding “traditional” forms. This is equivalent to the Traditional Forms feature, but explicitly limited to the traditional forms considered proper for use in personal names (as many as 205 glyphs in some fonts).
Example: The user inputs U+4E9C and gets U+4E9E.
Recommended implementation: The 'tnam' table maps simplified forms in a font to corresponding traditional forms which can be used in personal names (GSUB lookup type 1). The application stores a record of any simplified forms which resulted from substitutions (the 'smpl' feature); for such forms, applying the 'tnam' feature undoes the previous substitution.
Application interface: For GIDs found in the 'tnam' coverage table, the application passes the GIDs to the table and gets back new GIDs. Note: This is a change of character code. Besides the original character code, the application should store the code for the new character.
UI suggestion: This feature should be off by default.
Script/language sensitivity: Applies only to Japanese.
Feature interaction: May include some characters affected by the Proportional Alternate Widths feature ('palt'); 'trad' and 'tnam' are mutually exclusive, and override the results of 'smpl'.
Tag: 'tnum'
Friendly name: Tabular Figures
Registered by: Adobe
Function: Replaces figure glyphs set on proportional widths with corresponding glyphs set on uniform (tabular) widths. Tabular widths will generally be the default, but this cannot be safely assumed. Of course this feature would not be present in monospaced designs.
Example: The user may apply this feature to get oldstyle figures to align vertically in a column.
Recommended implementation: In order to simplify associated kerning and get the best glyph design for a given width, this feature should use new glyphs for the figures, rather than only adjusting the fit of the proportional glyphs (although some may be simple copies); i.e. not a GPOS feature. The 'tnum' table maps proportional versions of lining &/or oldstyle figures to corresponding tabular glyphs (GSUB lookup type 1).
Application interface: For GIDs found in the 'tnum' coverage table, the application passes GIDs to the 'tnum' table and gets back new GIDs.
UI suggestion: This feature should be off by default. The application may want to query the user about this feature when the user changes figure style ('onum' or 'lnum').
Script/language sensitivity: None.
Feature interaction: This feature overrides the results of the Proportional Figures feature ('pnum').
Tag: 'trad'
Friendly name: Traditional Forms
Registered by: Adobe
Function: Replaces 'simplified' Chinese hanzi or Japanese kanji forms with the corresponding 'traditional' forms.
Example: The user inputs U+53F0 and is offered a choice of U+6AAF, U+81FA, or U+98B1.
Recommended implementation: The 'trad' table maps each simplified form in a font to one or more traditional forms. While many of these substitutions are one-to-one (GSUB lookup type 1), others require a selection from a set (GSUB lookup type 3). The manufacturer may choose to build two tables (one for each lookup type) or only one which uses lookup type 3 for all substitutions. As in any one-from-many substitution, alternates present in more than one face should be ordered consistently across a family, so that those alternates can work correctly when switching between family members.
Application interface: For GIDs found in the 'trad' coverage table, the application passes the GIDs to the table and gets back one or more new GIDs. If more than one GID is returned, the application must provide a means for the user to select the one desired. The application stores a record of any simplified forms which resulted from substitutions (the 'smpl' feature); for such forms, applying the 'trad' feature undoes the previous substitution. Note: This is a change of character code. Besides the original character code, the application should store the code for the new character.
UI suggestion: This feature should be inactive by default. If there’s no record of a conversion from traditional to simplified, the user must be offered a set of possibilities from which to select. The application may note the user’s choice, and offer it as a default the next time the source simplified character is encountered. In the absence of such prior information, the application may assume that the first glyph in a set is the preferred form, so the font developer should order them accordingly.
Script/language sensitivity: Applies only to Chinese and Japanese.
Feature interaction: May include some characters affected by the Proportional Alternate Widths feature ('palt'); 'trad' and 'tnam' are mutually exclusive, and override the results of 'smpl'.
Tag: 'twid'
Friendly name: Third Widths
Registered by: Adobe
Function: Replaces glyphs on other widths with glyphs set on widths of one third of an em. The characters involved are normally figures and some forms of punctuation.
Example: The user may apply 'twid' to place a three-digit figure in a single slot in a column of vertical text.
Recommended implementation: The font may contain alternate glyphs designed to be set on third-em widths (GSUB lookup type 1), or it may specify alternate metrics for the original glyphs (GPOS lookup type 1) which adjust their spacing to fit in third-em widths.
Application interface: For GIDs found in the 'twid' coverage table, the application passes the GIDs to the table and gets back either new GIDs or positional adjustments (XPlacement and XAdvance).
UI suggestion: This feature would normally be off by default.
Script/language sensitivity: Generally used only in CJKV fonts.
Feature interaction: This feature is mutually exclusive with all other glyph-width features (e.g. 'fwid', 'halt', 'hwid' and 'qwid'), which should be turned off when it’s applied. It deactivates the 'kern' feature.
OpenType specification