Data quality for Microsoft synapse serverless and data warehouse
Azure Synapse Analytics is an enterprise analytics service that accelerates time to insight across data warehouses and big data systems. It brings together the best SQL technologies used in enterprise data warehousing, Apache Spark technologies for big data, and Azure Data Explorer for log and time series analytics.
Azure Synapse is a limitless analytics service that brings together enterprise data warehousing and Big Data analytics. It gives you the freedom to query data on your terms, using either serverless or dedicated resources—at scale, For more details about Azure Synapse review the Fabric documentation.
Example of synapse workspace with an instance of Dedicated Synapse Data Warehouse (DWH) Table EMPLOYEE and a Serverless Database (SQL_ON_DEMAND) with SynapseSalesDelta table.
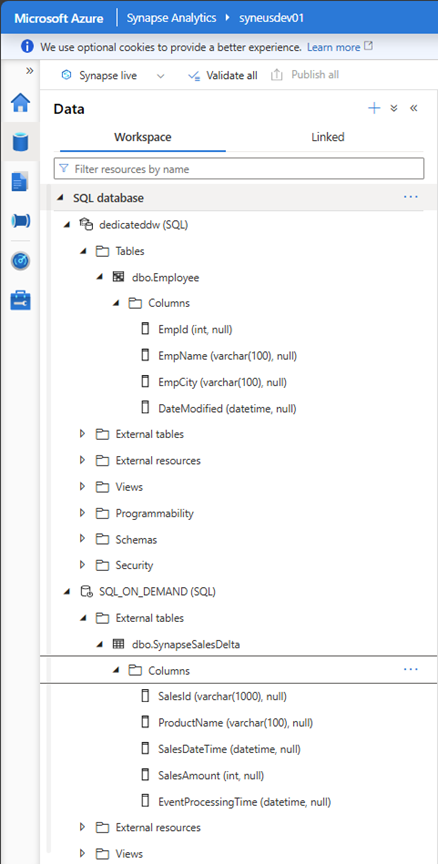
Once scanned, the assets are available in Microsoft Purview. The following is an example of an Employee Table on Synapse Analytics Dedicated instance.
Azure Synapse analytics Dedicated (Data Warehouse)
Set up Data Map scan
To scan Azure Synapse Analytics Dedicated (Data Warehouse) follow the documentation: and to grant necessary MI permissions on the Dedicated DWH instance, follow the documentation.
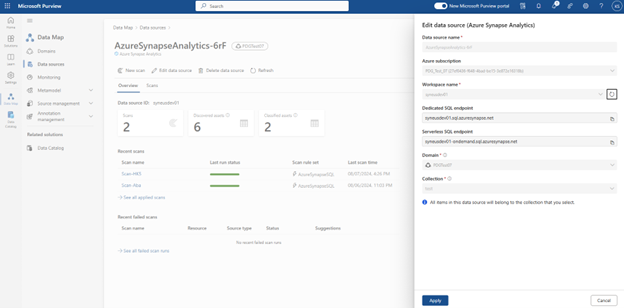
Once scanned, the assets are available on the Microsoft Purview catalog. The following is an example of an Employee Table on Synapse Analytics Dedicated instance.
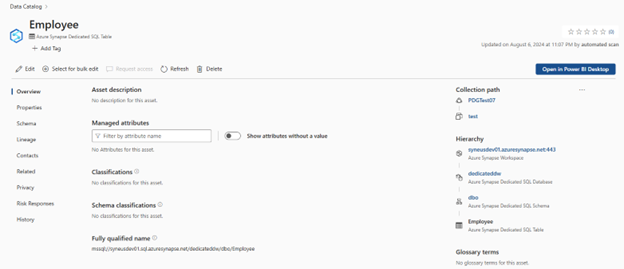
Set up connection to your synapse dedicated data warehouse
At this point, we have the scanned asset ready for cataloging and governance. Associate the scanned asset to the Data Product in a Governance Domain Sele. At the Data Quality Tab, add a new Azure SQL Database Connection: Get the Database Name entered manually.
Select Data quality > Governance Domain > Manage tab to create connection.
Configure connection in the connection page.
- Add connection name and description.
- Select source type Azure Synapse Analytics.
- Select Azure subscription.
- Select Workspace name.
- Select Dedicated SQL endpoint.
- Select serverless SQL endpoint.
- Select Endpoint type.
- Select Database.
- Add MSI as Credential.
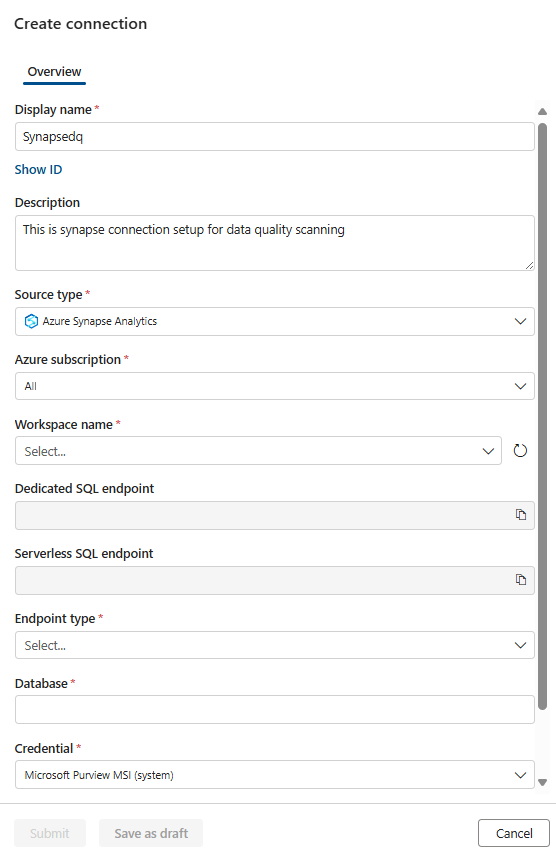
Test the connection. After configuring the data source connection and successfully testing it, you can proceed to configure and run Data Profiling and Data Quality scans.
If your Synapse data source is located behind a private endpoint, you need to enable managed vNet. Follow the document how to configure managed vNet.


Important
Data Quality stewards need read only access to synapse dedicated data warehouse to setup data quality connection. For managed vNet setup, you will not able to test the connection.
Profiling and Data Quality scanning for data in synapse dedicated data warehouse
After completed connection setup successfully, you can profile, create and apply rules, and run DQ scan of your data in synapse warehouse. Follow the step-by-step guideline described in below documents:
Important
- Performance of the queries and even their successful runs are dependent on the DW configuration the customers have for their dedicated database instances.
- Respective DQ assessment jobs or for that matter any other DQ job induces a connection on the Dedicated DW and may fail if the instance is under provisioned or fails on concurrency limits, customers need to be aware of the DW configuration. Its concurrency has very hard limits for any instance in time.
- Concurrency limits may lead to job termination. DW Limits (such 1000 DW) provides the power to run the queries.
- vNet support is in preview with GA grade support.
Azure Synapse Analytics Serverless
Setup data map scan
To scan Azure Synapse Analytics Serverless follow the documentation: and to grant necessary MI permissions on the Dedicated DWH instance, follow the documentation. Once scanned, the serverless assets are available on the Microsoft Purview catalog.
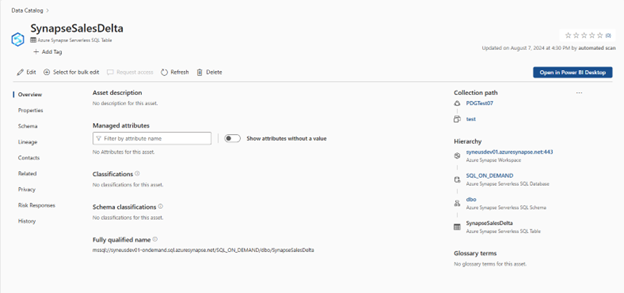
Set up connection to your synapse Serverless
At this point, we have the scanned asset ready for cataloging and governance. Associate the scanned asset to the Data Product in a Governance Domain Sele. In Data Quality, add a new Azure SQL Database Connection: Get the Database Name entered manually.
Select Data quality > Governance Domain > Manage tab to create connection.
Configure connection in the connection page.
- Add connection name and description.
- Select source type Azure Synapse Analytics.
- Select Azure subscription.
- Select Workspace name.
- Select Dedicated SQL endpoint.
- Select serverless SQL endpoint.
- Select Endpoint type.
- Select Database.
- Add MSI as Credential.
Test the connection. After configuring the data source connection and successfully testing it, you can proceed to configure and run Data Profiling and Data Quality scans.
If your Synapse data source is located behind a private endpoint, you need to enable managed vNet. Follow the document how to configure managed vNet.
Important
- Data Quality stewards need read only access to synapse dedicated data warehouse to setup data quality connection.
- In Synapse serverless setup, the external table points to Delta formatted data stored in ADLS Gen2.
- vNet support is in Gated preview. Please contact with Purview sales team to allowlist your tenant for Gated preview.
- Synapse Connector only detects and supports sql.azuresynapse.net. If Fully Qualified Name (FQN) generated by your Data Mmap scan contains database.windows.net, then your Synapse connection for DQ scan will fail.
Profiling and Data Quality (DQ) scanning for data in synapse serverless
After completed connection setup successfully, you can profile, create and apply rules, and run Data Quality (DQ) scan of your data in synapse warehouse. Follow the step-by-step guideline described in below documents:
Important
- The DQ assessments, profiling run on spark in the background, customers will have multiple connections where each spark node will have a connection SPID hence DWH may run into current query limits if used/scheduled beyond DW Limits, resulting failures. But for Azure Synapse Serverless SQL Table - No such concurrency limits apply; it totally depends on the Serverless Delta parquet optimizations the customers have on their ADLS Gen2 instance. The engine can be considered closely resonating Databricks Serverless DW both operate on external Lakehouse sources such a DELTA format tables.