Use unstructured clinical notes enrichment (preview) in healthcare data solutions
[This article is prerelease documentation and is subject to change.]
Note
This content is currently being updated.
Unstructured clinical notes enrichment (preview) uses Azure AI Language's Text Analytics for health service to extract key Fast Healthcare Interoperability Resources (FHIR) entities from unstructured clinical notes. It creates structured data from these clinical notes. You can then analyze this structured data to derive insights, predictions, and quality measures aimed at enhancing patient health outcomes.
To learn more about the capability and understand how to deploy and configure it, see:
- Overview of unstructured clinical notes enrichment (preview)
- Deploy and configure unstructured clinical notes enrichment (preview)
Unstructured clinical notes enrichment (preview) has a direct dependency on the healthcare data foundations capability. Ensure you successfully set up and execute the healthcare data foundations pipelines first.
Prerequisites
- Deploy healthcare data solutions in Microsoft Fabric
- Install the foundational notebooks and pipelines in Deploy healthcare data foundations.
- Set up the Azure language service as explained in Set up Azure Language service.
- Deploy and configure unstructured clinical notes enrichment (preview)
- Deploy and configure OMOP transformations. This step is optional.
NLP ingestion service
The healthcare#_msft_ta4h_silver_ingestion notebook executes the NLPIngestionService module in the healthcare data solutions library to invoke the Text Analytics for health service. This service extracts unstructured clinical notes from the FHIR resource DocumentReference.Content to create a flattened output. To learn more, see Review the notebook configuration.
Data storage in silver layer
After the natural language processing (NLP) API analysis, the structured and flattened output is stored in the following native tables within the healthcare#_msft_silver lakehouse:
- nlpentity: Contains the flattened entities extracted from the unstructured clinical notes. Each row is a single term extracted from the unstructured text after performing the text analysis.
- nlprelationship: Provides the relationship between the extracted entities.
- nlpfhir: Contains the FHIR output bundle as a JSON string.
To track the last updated timestamp, the NLPIngestionService uses the parent_meta_lastUpdated field in all the three silver lakehouse tables. This tracking ensures that the source document DocumentReference, which is the parent resource, is first stored to maintain referential integrity. This process helps prevent inconsistencies in the data and orphaned resources.
Important
Currently, Text Analytics for health returns vocabularies listed in the UMLS Metathesaurus Vocabulary Documentation. For guidance on these vocabularies, see Import data from UMLS.
For the preview release, we use the SNOMED-CT (Systematized Nomenclature of Medicine - Clinical Terms), LOINC (Logical Observation Identifiers, Names, and Codes), and RxNorm terminologies that are included with the OMOP sample dataset based on guidance from Observational Health Data Sciences and Informatics (OHDSI).
OMOP transformation
Healthcare data solutions in Microsoft Fabric also provide another capability for Observational Medical Outcomes Partnership (OMOP) transformations. When you execute this capability, the underlying transformation from the silver lakehouse to the OMOP gold lakehouse also transforms the structured and flattened output of the unstructured clinical notes analysis. The transformation reads from the nlpentity table in the silver lakehouse and maps the output to the NOTE_NLP table in the OMOP gold lakehouse.
For more information, see Overview of OMOP transformations.
Here's the schema for the structured NLP outputs, with the corresponding NOTE_NLP column mapping to the OMOP common data model:
| Flattened document reference | Description | Note_NLP mapping | Sample data |
|---|---|---|---|
| id | Unique identifier for the entity. Composite key of parent_id, offset, and length. |
note_nlp_id |
1380 |
| parent_id | A foreign key to the flattened documentreferencecontent text the term was extracted from. | note_id |
625 |
| text | Entity text as appears in the document. | lexical_variant |
No Known Allergies |
| Offset | Character offset of the extracted term in the input documentreferencecontent text. | offset |
294 |
| data_source_entity_id | ID of the entity in the given source catalog. | note_nlp_concept_id and note_nlp_source_concept_id |
37396387 |
| nlp_last_executed | The date of the documentreferencecontent text analysis processing. | nlp_date_time and nlp_date |
2023-05-17T00:00:00.0000000 |
| model | Name and version of the NLP system (Name of the Text Analytics for health NLP system and the version). | nlp_system |
MSFT TA4H |

Service limits for Text Analytics for health
- Maximum number of characters per document is limited to 125,000.
- Maximum size of documents contained in the entire request is limited to 1 MB.
- Maximum number of documents per request is limited to:
- 25 for the web-based API.
- 1000 for the container.
Enable logs
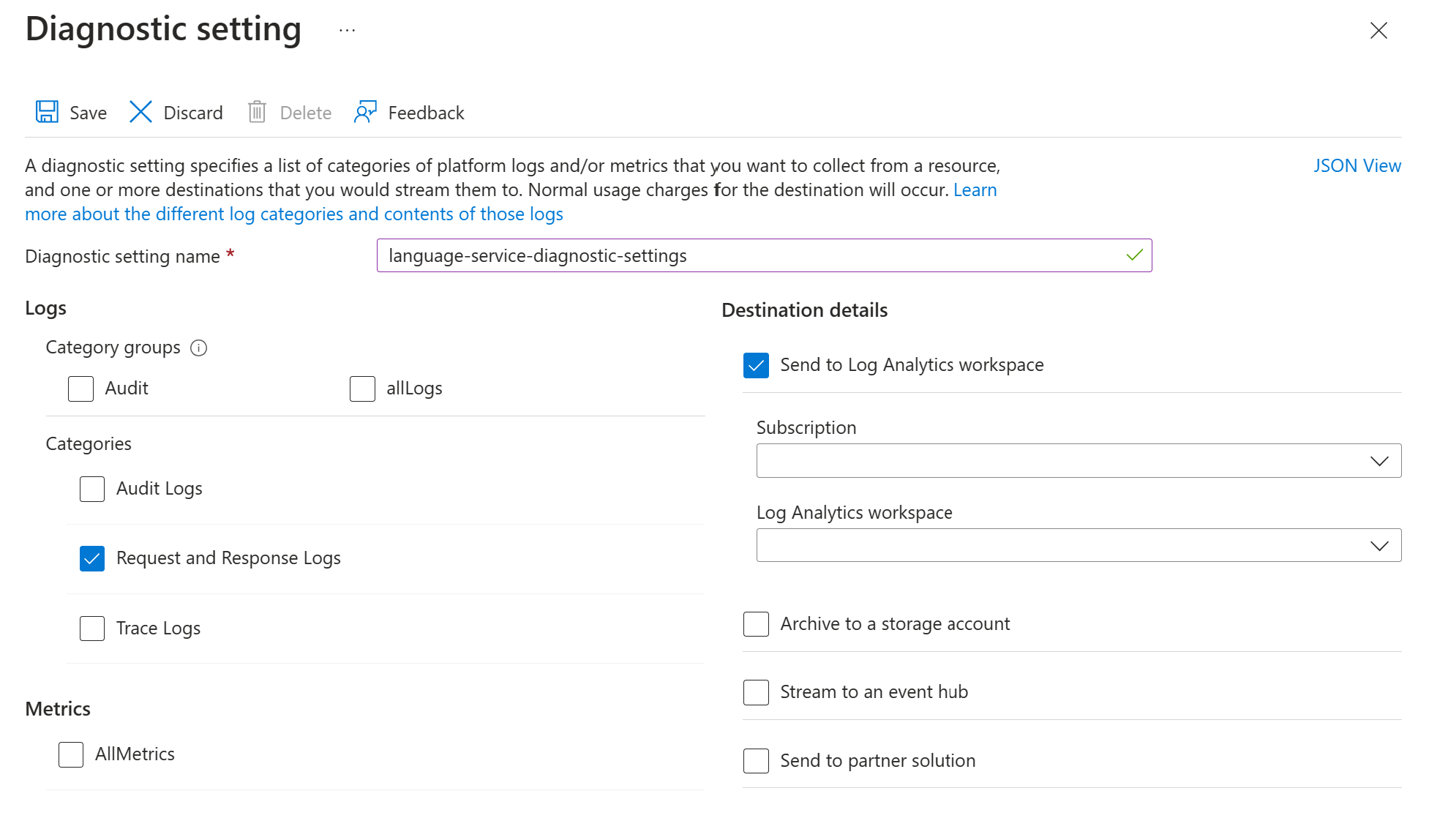
Follow these steps to enable request and response logging for the Text Analytics for health API:
Enable the diagnostic settings for your Azure Language service resource using the instructions in Enable diagnostic logging for Azure AI services. This resource is the same language service that you created during the Set up Azure Language service deployment step.
- Enter a diagnostic setting name.
- Set the category to Request and Response Logs.
- For destination details, select Send to Log Analytics workspace, and select the required Log Analytics workspace. If you don't have a workspace, follow the prompts to create one.
- Save the settings.
Go to the NLP Config section in the NLP ingestion service notebook. Update the value of the configuration parameter
enable_text_analytics_logstoTrue. For more information about this notebook, see Review the notebook configuration.

View logs in Azure Log Analytics
To explore the log analytics data:
- Navigate to the Log Analytics workspace.
- Locate and select Logs. From this page, you can run queries against your logs.
Sample query
Following is a basic Kusto query that you can use to explore your log data. This sample query retrieves all the failed requests from the Azure Cognitive Services resource provider in the past day, grouped by error type:
AzureDiagnostics
| where TimeGenerated > ago(1d)
| where Category == "RequestResponse"
| where ResourceProvider == "MICROSOFT.COGNITIVESERVICES"
| where tostring(ResultSignature) startswith "4" or tostring(ResultSignature) startswith "5"
| summarize NumberOfFailedRequests = count() by ResultSignature