Tutki tietoja peilatussa tietokannassa muistikirjojen avulla
Voit tutkia peilatun tietokannan replikoituja tietoja muistikirjojen Spark-kyselyillä.
Muistikirjat ovat tehokas koodikohde, jonka avulla voit kehittää tietoihisi liittyviä Apache Spark -töitä ja koneoppimiskokeiluja. Voit käyttää Fabric Lakehouse -muistikirjoja peilitaulukoiden tutkimiseen.
Edellytykset
- Suorita opetusohjelma, jotta voit luoda peilatun tietokannan lähdetietokannasta.
- Opetusohjelma: Määritä Microsoft Fabric -peilattu tietokanta Azure Cosmos DB:tä varten (esikatselu)
- Opetusohjelma: Määritä Microsoft Fabric -peilatut tietokannat Azure Databricksista (esikatselu)
- Opetusohjelma: Määritä Microsoft Fabric -peilatut tietokannat Azure SQL -tietokannasta
- Opetusohjelma: Määritä Microsoft Fabric -peilatut tietokannat Azure SQL:n hallitusta esiintymästä (esikatselu)
- Opetusohjelma: Määritä Microsoft Fabric -peilatut tietokannat Snowflakesta
Pikakuvakkeen luominen
Ensin on luotava pikakuvake peilatuista taulukoista Lakehouseen ja sitten rakennettava muistikirjoja Spark-kyselyillä Lakehouse-taloosi.
Avaa Fabric-portaalissa Data Engineering.
Jos Lakehousea ei ole vielä luotu, valitse Lakehouse ja luo uusi Lakehouse antamalla sille nimi.
Valitse Nouda tiedot –> Uusi pikakuvake.
Valitse Microsoft OneLake.
Näet kaikki peilatut tietokannat Fabric-työtilassa.
Valitse pikakuvakkeeksi peilattu tietokanta, jonka haluat lisätä Lakehouseesi.
Valitse halutut taulukot peilattusta tietokannasta.
Valitse Seuraava ja sitten Luo.
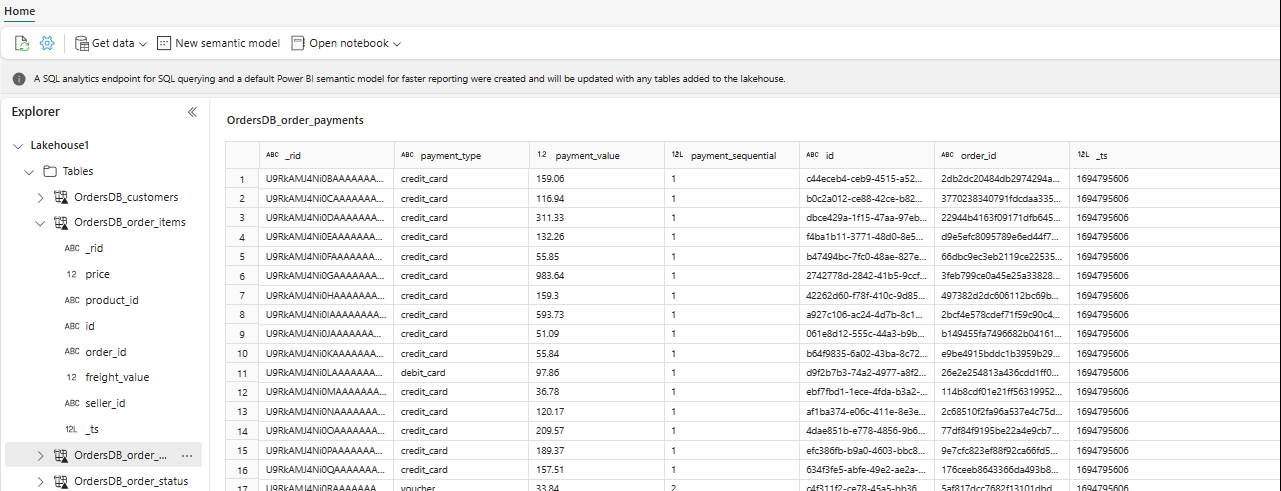
Näet nyt valittuja taulukkotietoja Lakehousessa resurssienhallinnassa.
Vihje
Voit lisätä muita tietoja suoraan Lakehousessa tai tuoda pikakuvakkeita, kuten S3, ADLS Gen2. Voit siirtyä Lakehousen SQL-analytiikan päätepisteeseen ja liittää kaikkien näiden lähteiden tiedot peilattuihin tietoihin saumattomasti.
Voit tutkia näitä tietoja Sparkissä valitsemalla minkä
...tahansa taulukon vieressä olevat pisteet. Aloita analysointi valitsemalla Uusi muistikirja tai Aiemmin luotu muistikirja .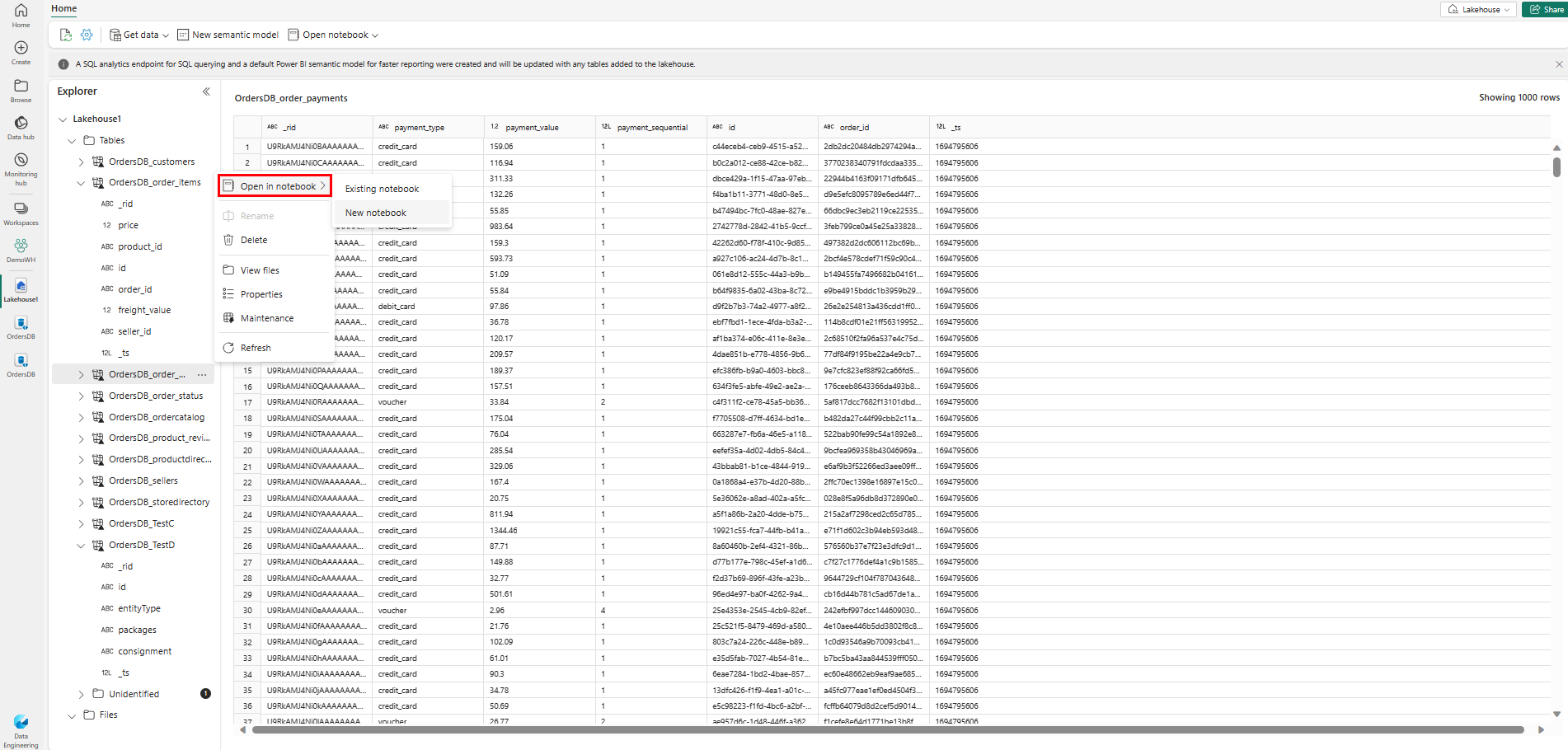
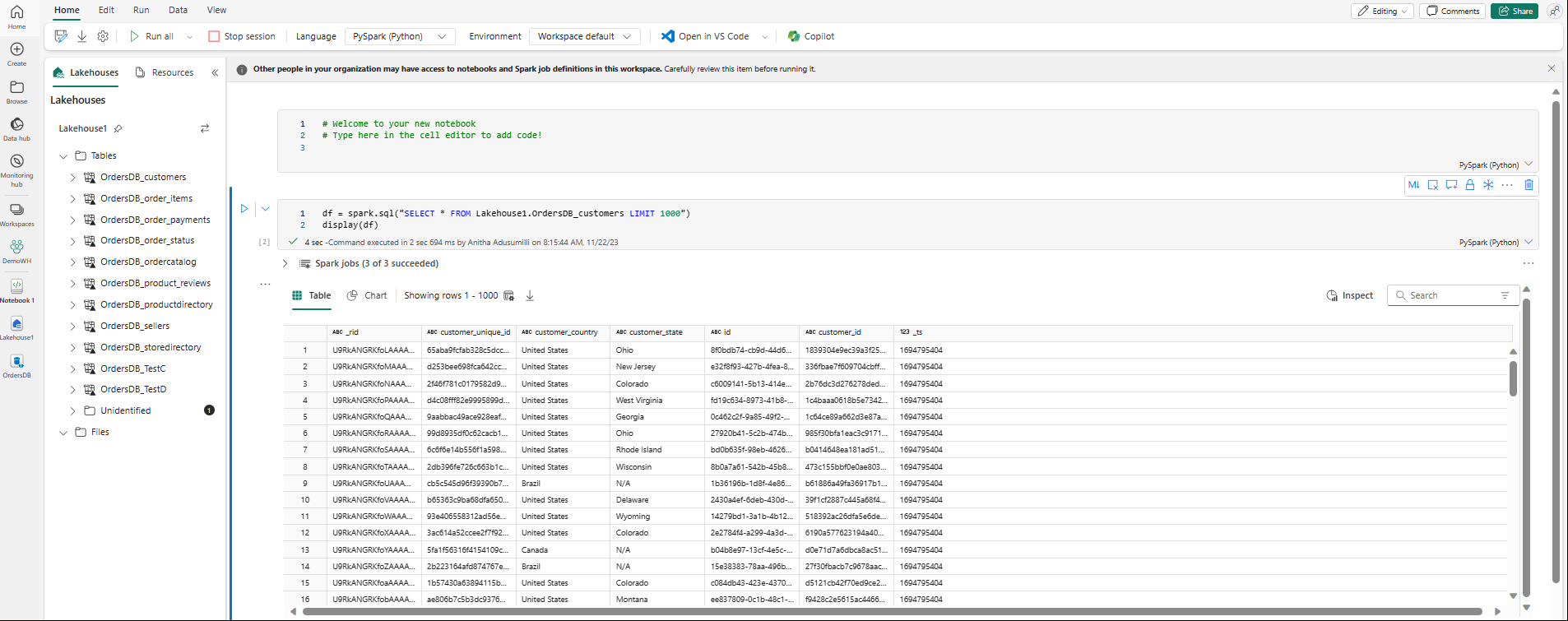
Muistikirja avautuu automaattisesti, ja tietokehys ladataan Spark SQL -kyselyn avulla
SELECT ... LIMIT 1000.- Uusien muistikirjojen lataaminen kokonaan voi kestää jopa kaksi minuuttia. Voit välttää tämän viiveen käyttämällä aiemmin luotua muistikirjaa aktiivisessa istunnossa.
- Uusien muistikirjojen lataaminen kokonaan voi kestää jopa kaksi minuuttia. Voit välttää tämän viiveen käyttämällä aiemmin luotua muistikirjaa aktiivisessa istunnossa.


