Superstore-myynnin ennustemallin kehittäminen, arvioiminen ja pisteytys
Tässä opetusohjelmassa esitellään päästä päähän -esimerkki Synapse Data Science -työnkulusta Microsoft Fabricissa. Skenaario luo ennustemallin, joka käyttää historiallisia myyntitietoja tuoteluokan myynnin ennustamiseen superkaupassa.
Ennustaminen on tärkeä resurssi myynnissä. Se yhdistää historialliset tiedot ja ennakoivat menetelmät ja tarjoaa merkityksellisiä tietoja tulevista trendeistä. Ennustaminen voi analysoida aiempia myynnit mallien tunnistamiseksi ja oppia kuluttajien toiminnasta varasto-, tuotanto- ja markkinointistrategioiden optimoimiseksi. Tämä ennakoiva lähestymistapa parantaa yritysten mukautuvuutta, reagointia ja dynaamisten Marketplacen yritysten yleistä suorituskykyä.
Tässä opetusohjelmassa käsitellään seuraavat vaiheet:
- Lataa tiedot
- Tietojen ymmärtäminen ja käsitteleminen valmistelevan tietoanalyysin avulla
- Harjoita koneoppimismalli avoimen lähdekoodin ohjelmistopaketilla ja seuraa MLflow-ja Fabric-automaattianalyysiominaisuuksien kokeiluja
- Tallenna lopullinen koneoppimismalli ja tee ennusteita
- Mallin suorituskyvyn näyttäminen Power BI -visualisointien avulla
Edellytykset
Hanki Microsoft Fabric -tilaus. Voit myös rekisteröityä ilmaiseen Microsoft Fabric -kokeiluversioon.
Siirry Synapse Data Science -käyttökokemukseen aloitussivun vasemmassa reunassa olevan käyttökokemuksen vaihtajan avulla.

- Luo tarvittaessa Microsoft Fabric Lakehouse kohdan Lakehouse luominen Microsoft Fabricissa ohjeiden mukaan.
Seuraa mukana muistikirjassa
Voit valita jonkin seuraavista vaihtoehdoista, joita voit seurata muistikirjassa:
- Avaa ja suorita sisäinen muistikirja Synapse Data Science -kokemuksessa
- Lataa muistikirjasi GitHubista Synapse Data Science -kokemukseen
Avaa sisäinen muistikirja
Tämän opetusohjelman mukana on Myyntiennusteiden muistikirjamalli.
Opetusohjelman sisäinen näytemuistikirja avataan Synapse Data Science -kokemuksesta seuraavasti:
Siirry Synapse Data Science -aloitussivulle.
Valitse Käytä mallia.
Valitse vastaava malli:
- Oletusarvoisen Päästä päähän -työnkulkujen (Python) välilehdestä, jos malli on tarkoitettu Python-opetusohjelmaa varten.
- Jos malli on R-opetusohjelmassa, päästä päähän -työnkulut (R) -välilehdeltä.
- Pikaopetusohjelmat-välilehdessä, jos malli on pikaopetusohjelmaa varten.
Liitä muistikirjaan lakehouse, ennen kuin aloitat koodin suorittamisen.
Tuo muistikirja GitHubista
AIsample - Superstore Forecast.ipynb -muistikirja on tämän opetusohjelman mukana.
Jos haluat avata tämän opetusohjelman liitteenä olevan muistikirjan, tuo muistikirja työtilaasi noudattamalla ohjeita kohdassa Järjestelmän valmisteleminen datatieteen opetusohjelmia varten.
Jos haluat kopioida ja liittää koodin tältä sivulta, voit luoda uuden muistikirjan.
Muista liittää lakehouse muistikirjaan ennen kuin aloitat koodin suorittamisen.
Vaihe 1: Lataa tiedot
Tietojoukko sisältää 9 995 eri tuotteiden myynnin esiintymää. Se sisältää myös 21 määritettä. Tämä taulukko on tässä muistikirjassa käytetystä Superstore.xlsx tiedostosta:
| Rivin tunnus | Tilauksen tunnus | Tilauspäivä | Toimituspäivämäärä | Lähetystila | Asiakastunnus | Asiakkaan nimi | Segmentti | Country | City | Vaihe | Postinumero | Region | Tuotetunnus | Luokka | Alaluokka | Tuotteen nimi | Myynti | Määrä | Alennus | Tuotto |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | US-2015-108966 | 2015-10-11 | 2015-10-18 | Vakioluokka | SO-20335 | Sean O'Donnell | Kuluttaja | Yhdysvallat | Fort Lauderdale | Florida | 33311 | Etelä | FUR-TA-10000577 | Huonekalut | Taulukot | Bretford CR4500 Series Slim Suorakulmainen taulukko | 957.5775 | 5 | 0.45 | -383.0310 |
| 11 | CA-2014-115812 | 2014-06-09 | 2014-06-09 | Vakioluokka | Vakioluokka | Brosina Hoffman | Kuluttaja | Yhdysvallat | Los Angeles | California | 90032 | Länsi | FUR-TA-10001539 | Huonekalut | Taulukot | Chromcraft-suorakulmaiset konferenssitaulukot | 1706.184 | 9 | 0.2 | 85.3092 |
| 31 | US-2015-150630 | 2015-09-17 | 2015-09-21 | Vakioluokka | Tt–21520 | Tracy Blumstein | Kuluttaja | Yhdysvallat | Philadelphia | Pennsylvania | 19140 | Itä | OFF-EN-10001509 | Toimistotarvikkeet | Kirjekuoret | Poly String Tie Kirjekuori | 3.264 | 2 | 0.2 | 1.1016 |
Määritä nämä parametrit niin, että voit käyttää tätä muistikirjaa eri tietojoukkojen kanssa:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/salesforecast" # Folder with data files
DATA_FILE = "Superstore.xlsx" # Data file name
EXPERIMENT_NAME = "aisample-superstore-forecast" # MLflow experiment name
Lataa tietojoukko ja lataa se Lakehouse-palveluun
Tämä koodi lataa tietojoukosta julkisesti saatavilla olevan version ja tallentaa sen Fabric Lakehouse -järjestelmään:
Tärkeä
Muista lisätä muistikirjaan lakehouse ennen kuin suoritat sen. Muussa tapauksessa saat virheilmoituksen.
import os, requests
if not IS_CUSTOM_DATA:
# Download data files into the lakehouse if they're not already there
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Forecast_Superstore_Sales"
file_list = ["Superstore.xlsx"]
download_path = "/lakehouse/default/Files/salesforecast/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
MLflow-kokeilujen seurannan määrittäminen
Microsoft Fabric tallentaa automaattisesti koneoppimismallin syöteparametrien arvot ja tulostemittarit harjoittaessasi sitä. Tämä laajentaa MLflow-automaattisen lokeroinnin ominaisuuksia. Tiedot kirjataan sitten työtilaan, jossa voit käyttää ja visualisoida niitä MLflow-ohjelmointirajapinnoilla tai vastaavalla työtilan kokeilulla. Saat lisätietoja automaattianalyysipalveluista ohjeartikkelista Automaattinen lokiloggaus Microsoft Fabricissa.
Jos haluat poistaa Microsoft Fabricin automaattisen lokerauksen käytöstä muistikirjaistunnossa, kutsu mlflow.autolog() ja määritä disable=True:
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Turn off MLflow autologging
Raakadata Lakehousesta
Lue raakadataa Lakehousen Tiedostot-osiosta . Lisää sarakkeita eri päivämääräosille. Samoja tietoja käytetään ositetun delta-taulukon luomiseen. Raakatiedot on tallennettu Excel-tiedostoon, joten niiden lukeminen edellyttää pandojen käyttöä:
import pandas as pd
df = pd.read_excel("/lakehouse/default/Files/salesforecast/raw/Superstore.xlsx")
Vaihe 2: Tee valmisteleva tietoanalyysi
Tuontikirjastot
Tuo tarvittavat kirjastot ennen analyysiä:
# Importing required libraries
import warnings
import itertools
import numpy as np
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.style.use('fivethirtyeight')
import pandas as pd
import statsmodels.api as sm
import matplotlib
matplotlib.rcParams['axes.labelsize'] = 14
matplotlib.rcParams['xtick.labelsize'] = 12
matplotlib.rcParams['ytick.labelsize'] = 12
matplotlib.rcParams['text.color'] = 'k'
from sklearn.metrics import mean_squared_error,mean_absolute_percentage_error
Raakatietojen näyttäminen
Tarkista tietojen alijoukko manuaalisesti, jotta ymmärrät paremmin tietojoukon itse, ja käytä display funktiota DataFrame-kehyksen tulostamiseen. Lisäksi näkymien Chart avulla voidaan helposti visualisoida tietojoukon alijoukkoja.
display(df)
Tämä muistikirja keskittyy ensisijaisesti luokan myynnin ennustamiseen Furniture . Tämä nopeuttaa laskentaa ja auttaa näyttämään mallin suorituskyvyn. Tämä muistikirja käyttää kuitenkin mukautuvia tekniikoita. Voit laajentaa näitä tekniikoita ennustaaksesi muiden tuoteluokkien myynnin.
# Select "Furniture" as the product category
furniture = df.loc[df['Category'] == 'Furniture']
print(furniture['Order Date'].min(), furniture['Order Date'].max())
Tietojen esikäsittely
Reaalimaailman liiketoimintaskenaarioiden on usein ennustettava myyntiä kolmessa erillisessä luokassa:
- Tietty tuoteluokka
- Tietty asiakasluokka
- Tuoteluokan ja asiakasluokan tietty yhdistelmä
Hylkää ensin tarpeettomat sarakkeet tietojen esikäsittelyä varten. Jotkin sarakkeet (Row ID, ,Customer IDja Customer Name) ovat tarpeettomia, Order IDkoska niillä ei ole vaikutusta. Haluamme ennustaa kokonaismyynnin osavaltiosta ja alueesta tietylle tuoteluokalle (Furniture), jotta voimme pudottaa State-, - Region, Country-, City- ja Postal Code -sarakkeet. Jos haluat ennustaa tietyn sijainnin tai luokan myynnin, sinun on ehkä muutettava esikäsittelyvaihetta vastaavasti.
# Data preprocessing
cols = ['Row ID', 'Order ID', 'Ship Date', 'Ship Mode', 'Customer ID', 'Customer Name',
'Segment', 'Country', 'City', 'State', 'Postal Code', 'Region', 'Product ID', 'Category',
'Sub-Category', 'Product Name', 'Quantity', 'Discount', 'Profit']
# Drop unnecessary columns
furniture.drop(cols, axis=1, inplace=True)
furniture = furniture.sort_values('Order Date')
furniture.isnull().sum()
Tietojoukko jäsennetty päivittäin. Meidän täytyy määrittää sarake Order Dateuudelleen, koska haluamme kehittää mallin, joka ennustaa myynnin kuukausittain.
Ryhmittele luokka ensin :n Furniture mukaan Order Date. Laske sitten kunkin ryhmän sarakkeen Sales summa määrittääksesi jokaisen yksilöllisen Order Date arvon kokonaismyynnin. Nimeä sarake uudelleen Sales tiheydellä MS koostaaksesi tiedot kuukauden mukaan. Laske lopuksi kunkin kuukauden keskimääräinen myyntiarvo.
# Data preparation
furniture = furniture.groupby('Order Date')['Sales'].sum().reset_index()
furniture = furniture.set_index('Order Date')
furniture.index
y = furniture['Sales'].resample('MS').mean()
y = y.reset_index()
y['Order Date'] = pd.to_datetime(y['Order Date'])
y['Order Date'] = [i+pd.DateOffset(months=67) for i in y['Order Date']]
y = y.set_index(['Order Date'])
maximim_date = y.reset_index()['Order Date'].max()
Näytä kohteen vaikutus Order Date Sales Furniture luokkaan:
# Impact of order date on the sales
y.plot(figsize=(12, 3))
plt.show()
Ennen tilastoanalyysia sinun on tuotava Python-moduuli statsmodels . Se tarjoaa luokkia ja funktioita monien tilastollisten mallien arviointia varten. Se tarjoaa myös luokkia ja funktioita tilastollisten testien ja tilastollisten tietojen tutkimisen suorittamiseen.
import statsmodels.api as sm
Tilastollisen analyysin suorittaminen
Aikasarja seuraa näitä tietoelementtejä määritetyin väliajoin määrittääkseen näiden elementtien vaihtelun aikasarjamallissa:
Taso: Perusosa, joka edustaa tietyn ajanjakson keskiarvoa
Trendi: Kuvailee, pieneneekö, pysyykö aikasarja vakiona vai kasvaako se ajan mittaan
Kausivaihtelu: Kuvaa aikasarjan kausittaisen signaalin ja etsii sykliset esiintymät, jotka vaikuttavat aikasarjamallien lisääntymiseen tai pienenemiseen
Melu/jäännös: Viittaa aikasarjatietojen satunnaisiin vaihteluihin ja vaihteluihin, joita malli ei pysty selittämään.
Tässä koodissa tarkkailet näitä tietojoukkosi elementtejä esikäsittelyn jälkeen:
# Decompose the time series into its components by using statsmodels
result = sm.tsa.seasonal_decompose(y, model='additive')
# Labels and corresponding data for plotting
components = [('Seasonality', result.seasonal),
('Trend', result.trend),
('Residual', result.resid),
('Observed Data', y)]
# Create subplots in a grid
fig, axes = plt.subplots(nrows=4, ncols=1, figsize=(12, 7))
plt.subplots_adjust(hspace=0.8) # Adjust vertical space
axes = axes.ravel()
# Plot the components
for ax, (label, data) in zip(axes, components):
ax.plot(data, label=label, color='blue' if label != 'Observed Data' else 'purple')
ax.set_xlabel('Time')
ax.set_ylabel(label)
ax.set_xlabel('Time', fontsize=10)
ax.set_ylabel(label, fontsize=10)
ax.legend(fontsize=10)
plt.show()
Kaaviot kuvaavat ennustetiedoissa kausivaihtelua, trendejä ja melua. Voit tallentaa pohjana olevat mallit ja kehittää malleja, jotka tekevät tarkkoja ennusteita, jotka kestävät satunnaisia vaihteluja.
Vaihe 3: Mallin harjoittaminen ja seuraaminen
Nyt kun tiedot ovat käytettävissä, määritä ennustemalli. Käytä tässä muistikirjassa ennustemallia nimeltä kausittainen autoregressiivinen integroitu liukuva keskiarvo laajennettaviin tekijöihin (SARIMAX). SARIMAX yhdistää autoregressiiviset (AR) ja liukuvan keskiarvon (MA) osat, kausivaihtelun ja ulkoiset ennusteet aikasarjatietojen tarkkojen ja joustavien ennusteiden tekemiseksi.
Voit myös käyttää MLflow- ja Fabric-automaattianalyysipalveluita kokeilujen seuraamiseen. Lastatkaa deltataulukko lakehousesta. Voit käyttää muita delta-taulukoita, jotka pitävät Lakehousea lähteenä.
# Import required libraries for model evaluation
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error
Hyperparametrien hienosäätäminen
SARIMAX ottaa huomioon tavalliseen automaattisesti regressiiviseen integroituun liukuvaan keskiarvotilaan (, , ) liittyvät parametrit (, , ), ja lisää kausivaihteluparametrit (P, D, Q, s). qdp Näitä SARIMAX-malliargumentteja kutsutaan järjestykseksi (, , ) qja kausijärjestykseksi (P, D, Q, s). dp Tämän vuoksi meidän on ensin hienosäädettävä seitsemää parametria, jotta voimme harjoittaa mallin.
Tilausparametrit:
p: AR-osan järjestys, joka edustaa senhetkisen arvon ennustamiseen käytetyn aikasarjan aiempien havaintojen määrää.Yleensä tämän parametrin tulee olla ei-negatiivinen kokonaisluku. Yleiset arvot ovat välillä
0,3vaikka suuremmat arvot ovat mahdollisia, riippuen tietyistä tieto-ominaisuuksista. Korkeampiparvo tarkoittaa pidempää muistia mallin aiemmista arvoista.d: Eriytymisjärjestys, joka edustaa aikasarjan erottamisen määrää, jotta saadaan aikaan asema.Tämän parametrin on oltava ei-negatiivinen kokonaisluku. Yleiset arvot ovat välillä
02. Arvod0tarkoittaa, että aikasarja on jo paikallaan. Korkeammat arvot ilmaisevat sen kiinteäksi tekemiseen tarvittavien erilaisten toimintojen määrän.q: MA-osan järjestys, joka edustaa nykyisen arvon ennustamiseen käytettyjen aiempien white-noise-virhesanomien määrää.Tämän parametrin on oltava ei-negatiivinen kokonaisluku. Yleiset arvot ovat välillä
0,3mutta korkeammat arvot saattavat olla tarpeen tietyille aikasarjoille. Korkeampiqarvo ilmaisee sitä, että ennusteiden tekeminen perustuu aiempiin virheehtoihin vahvemmin.
Kausitilauksen parametrit:
P: Ar-osan kausijärjestys, joka on samanlainen kuinpkausivaihteluosan muttaD: Erojen kausijärjestys, joka ondsamanlainen kuin kausivaihteluosan mukaanQ: Ma-osan kausijärjestys, joka on samanlainen kuinqkausivaihteluosan muttas: Kausijaksoa kohti olevien aikavaiheiden määrä (esimerkiksi 12 kuukausittaisille tiedoille, joilla on vuosittaista kausivaihtelua)
# Hyperparameter tuning
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
SARIMAX sisältää muita parametreja:
enforce_stationarity: Tuleeko mallin pakottaa aikasarjatietojen paikallaan ennen SARIMAX-mallin asentamista.Jos
enforce_stationarityon määritettyTrue(oletus), se ilmaisee, että SARIMAX-mallin tulee pakottaa aikasarjatietojen stationaarisuus. SARIMAX-malli soveltaa sitten automaattisesti eriäviä tietoja, jotta ne pysyvät paikallaan - jaD-tilausten määrittämällädtavalla ennen mallin asentamista. Tämä on yleinen käytäntö, koska monet aikasarjamallit, mukaan lukien SARIMAX, olettavat tietojen olevan paikallaan.Jos kyseessä on ei-stationaarinen aikasarja (esimerkiksi siinä on trendejä tai kausivaihteluja), on hyvä käytäntö määrittää
enforce_stationarityarvoksiTrue, ja antaa SARIMAX-mallin käsitellä erot asematietojen saavuttamiseksi. Kiinteän aikasarjan (esimerkiksi sellaisessa, jolla ei ole trendejä tai kausivaihtelua) osalta on määritettyenforce_stationarityFalsevälttämään tarpeetonta eroa.enforce_invertibility: Määrittää, pitääkö mallin pakottaa kääntämättömyys arvioituihin parametreihin optimointiprosessin aikana.Jos
enforce_invertibility-asetuksenaTrueon (oletus), se ilmaisee, että SARIMAX-mallin tulisi pakottaa kääntämättömyys arvioituihin parametreihin. Kääntämättömyys varmistaa, että malli on määritelty hyvin ja että arvioitu AR- ja MA-kerroin osuu maahan aseman alueen sisäpuolella.Kääntömyyden pakottaminen auttaa varmistamaan, että SARIMAX-malli noudattaa vakaan aikasarjamallin teoreettisia vaatimuksia. Se auttaa myös estämään mallin arvioon ja vakauteen liittyviä ongelmia.
Oletusarvo on AR(1) malli. Tämä viittaa kohteeseen (1, 0, 0). On kuitenkin yleinen käytäntö kokeilla eri yhdistelmiä tilausparametreista ja kausijärjestysparametreista ja arvioida tietojoukon mallin suorituskyky. Soveltuvat arvot voivat vaihdella aikasarjasta toiseen.
Optimaalisen arvon määrittäminen edellyttää usein aikasarjatietojen autocorrelation-funktion (ACF) ja osittaisen autosarelaatiofunktion (PACF) analyysia. Siihen liittyy usein myös mallin valintakriteerien käyttö, kuten Akaike-tietokriteeri (AIC) tai bayesiläisen tiedon kriteeri (BIC).
Hyperparametrien hienosäätäminen:
# Tune the hyperparameters to determine the best model
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
Edellä mainittujen tulosten arvioinnin jälkeen voit määrittää sekä tilausparametrien että kausijärjestysparametrien arvot. Valinta on order=(0, 1, 1) ja seasonal_order=(0, 1, 1, 12), jotka tarjoavat pienimmän AIC:n (esimerkiksi 279,58). Näiden arvojen avulla voit harjoittaa mallin.
Sinun täytyy harjoittaa malli.
# Model training
mod = sm.tsa.statespace.SARIMAX(y,
order=(0, 1, 1),
seasonal_order=(0, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print(results.summary().tables[1])
Tämä koodi visualisoi aikasarjaennusteen huonekalujen myyntitieduksille. Piirtotuloksissa näkyvät sekä havaitut tiedot että yksi askel eteenpäin -ennuste, ja niissä on varjostettu alue luottamusvälille.
# Plot the forecasting results
pred = results.get_prediction(start=maximim_date, end=maximim_date+pd.DateOffset(months=6), dynamic=False) # Forecast for the next 6 months (months=6)
pred_ci = pred.conf_int() # Extract the confidence intervals for the predictions
ax = y['2019':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead forecast', alpha=.7, figsize=(12, 7))
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('Furniture Sales')
plt.legend()
plt.show()
# Validate the forecasted result
predictions = results.get_prediction(start=maximim_date-pd.DateOffset(months=6-1), dynamic=False)
# Forecast on the unseen future data
predictions_future = results.get_prediction(start=maximim_date+ pd.DateOffset(months=1),end=maximim_date+ pd.DateOffset(months=6),dynamic=False)
Käytä tätä predictions mallin suorituskyvyn arvioimiseen vertaamalla sitä todellisiin arvoihin. Arvo predictions_future ilmaisee tulevia ennusteita.
# Log the model and parameters
model_name = f"{EXPERIMENT_NAME}-Sarimax"
with mlflow.start_run(run_name="Sarimax") as run:
mlflow.statsmodels.log_model(results,model_name,registered_model_name=model_name)
mlflow.log_params({"order":(0,1,1),"seasonal_order":(0, 1, 1, 12),'enforce_stationarity':False,'enforce_invertibility':False})
model_uri = f"runs:/{run.info.run_id}/{model_name}"
print("Model saved in run %s" % run.info.run_id)
print(f"Model URI: {model_uri}")
mlflow.end_run()
# Load the saved model
loaded_model = mlflow.statsmodels.load_model(model_uri)
Vaihe 4: Mallin pisteytys ja ennusteiden tallentaminen
Voit luoda Power BI -raportin integroimalla todelliset arvot ennustettuihin arvoihin. Tallenna nämä tulokset järvenmökissä olevalle taulukolle.
# Data preparation for Power BI visualization
Future = pd.DataFrame(predictions_future.predicted_mean).reset_index()
Future.columns = ['Date','Forecasted_Sales']
Future['Actual_Sales'] = np.NAN
Actual = pd.DataFrame(predictions.predicted_mean).reset_index()
Actual.columns = ['Date','Forecasted_Sales']
y_truth = y['2023-02-01':]
Actual['Actual_Sales'] = y_truth.values
final_data = pd.concat([Actual,Future])
# Calculate the mean absolute percentage error (MAPE) between 'Actual_Sales' and 'Forecasted_Sales'
final_data['MAPE'] = mean_absolute_percentage_error(Actual['Actual_Sales'], Actual['Forecasted_Sales']) * 100
final_data['Category'] = "Furniture"
final_data[final_data['Actual_Sales'].isnull()]
input_df = y.reset_index()
input_df.rename(columns = {'Order Date':'Date','Sales':'Actual_Sales'}, inplace=True)
input_df['Category'] = 'Furniture'
input_df['MAPE'] = np.NAN
input_df['Forecasted_Sales'] = np.NAN
# Write back the results into the lakehouse
final_data_2 = pd.concat([input_df,final_data[final_data['Actual_Sales'].isnull()]])
table_name = "Demand_Forecast_New_1"
spark.createDataFrame(final_data_2).write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Vaihe 5: Visualisointi Power BI:ssä
Power BI -raportti näyttää absoluuttisen prosenttivirheen (MAPE) keskiarvona 16,58. MAPE-arvo määrittää ennustemenetelmän tarkkuuden. Se edustaa ennustettujen määrien tarkkuutta verrattuna todellisiin määriin.
MAPE on yksinkertainen mittausarvo. 10 %:n MAPE-funktio edustaa sitä, että ennustettujen arvojen ja todellisten arvojen välinen keskihajonta on 10 %, riippumatta siitä, oliko poikkeama positiivinen vai negatiivinen. Haluttavien MAPE-arvojen standardit vaihtelevat eri toimialoilla.
Vaaleansininen viiva tässä kaaviossa edustaa todellisia myyntiarvoja. Tummansininen viiva edustaa ennustettuja myyntiarvoja. Toteutuneiden ja ennustettujen myyntien vertailu osoittaa, että malli ennustaa luokan myynnin Furniture tehokkaasti vuoden 2023 kuuden ensimmäisen kuukauden aikana.
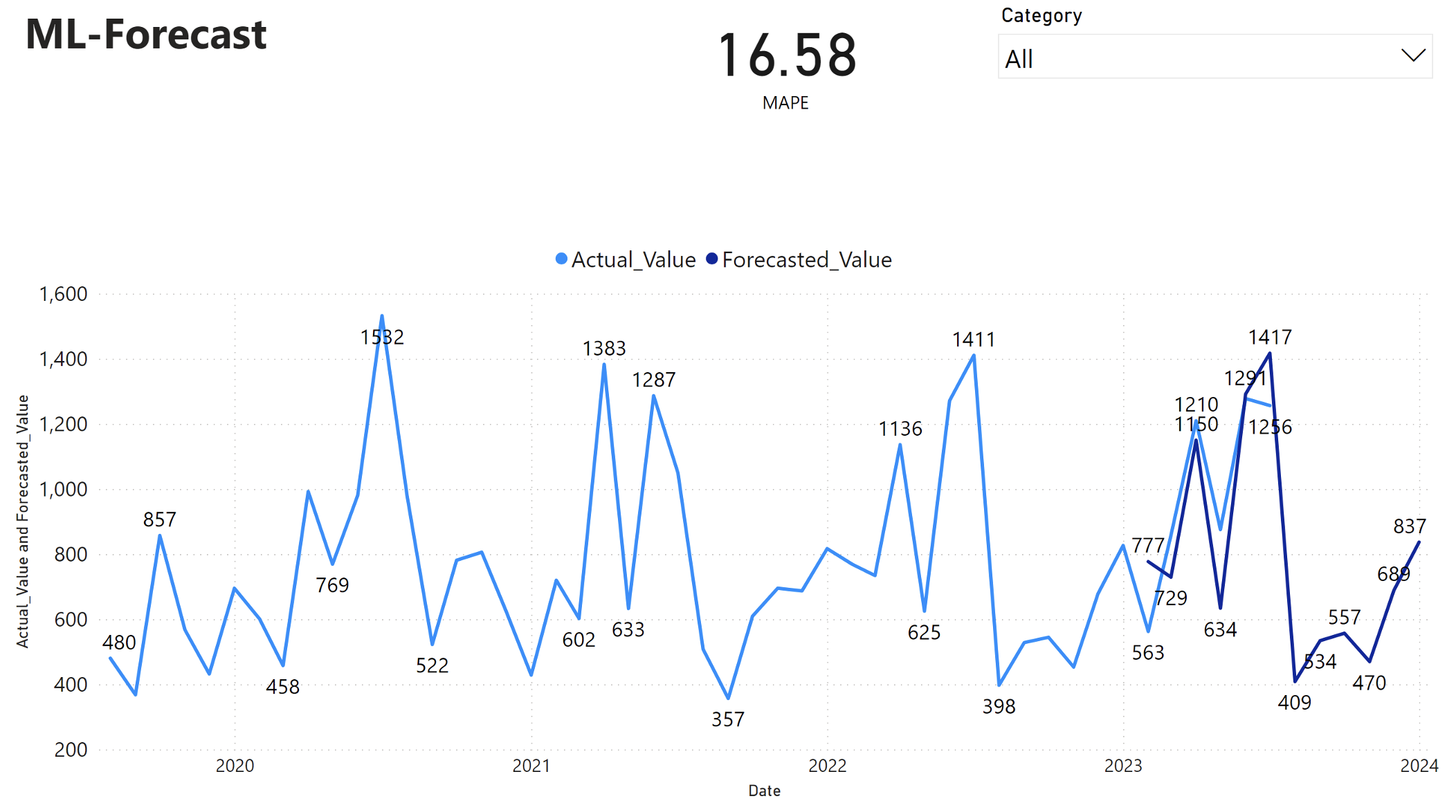
Tämän havainnon perusteella voimme luottaa mallin ennusteominaisuuksiin, kokonaismyyntiin vuoden 2023 viimeisten kuuden kuukauden aikana ja ulottuen vuoteen 2024. Tämä luottamus voi antaa tietoja strategisista päätöksistä varastonhallinnasta, raaka-aineiden hankinnasta ja muista liiketoimintaan liittyvistä seikoista.