Opetusohjelma: Suositusjärjestelmän luominen, arvioiminen ja pisteytys
Tässä opetusohjelmassa esitellään päästä päähän -esimerkki Synapse Data Science -työnkulusta Microsoft Fabricissa. Skenaario luo mallin online-kirjasuosituksia varten.
Tässä opetusohjelmassa käsitellään seuraavat vaiheet:
- Tietojen lataaminen Lakehouse-järjestelmään
- Tietojen valmistelevan analyysin suorittaminen
- Harjoita malli ja kirjaa se MLflow'n avulla
- Lataa malli ja tee ennusteita
Saatavilla on monenlaisia suositusalgoritmeja. Tässä opetusohjelmassa käytetään Als-matriisimuodostimen (Alternating Least Squares) algoritmia. ALS on mallipohjainen yhteistyösuodatusalgoritmi.

ALS yrittää arvioida luokituksia R kahden alemman tason matriisin, sinun ja V:n, tulokseksi. Tässä R = U * Vt. Yleensä näitä arvioita kutsutaan tekijämatriiseiksi.
ALS-algoritmi iteratiivista. Jokainen iteraatio sisältää yhden tekijän matriisivakiosta, kun taas toinen ratkaistaan käyttämällä vähintään neliön menetelmää. Se pitää sitten sisällään vastikään ratkaistun kertoimen matriisivakion, kun se ratkaisee toisen tekijän matriisin.

Edellytykset
Hanki Microsoft Fabric -tilaus. Voit myös rekisteröityä ilmaiseen Microsoft Fabric -kokeiluversioon.
Siirry Synapse Data Science -käyttökokemukseen aloitussivun vasemmassa reunassa olevan käyttökokemuksen vaihtajan avulla.

- Luo tarvittaessa Microsoft Fabric Lakehouse kohdan Lakehouse luominen Microsoft Fabricissa ohjeiden mukaan.
Seuraa mukana muistikirjassa
Voit valita jonkin seuraavista vaihtoehdoista, joita voit seurata muistikirjassa:
- Avaa ja suorita sisäinen muistikirja Synapse Data Science -kokemuksessa
- Lataa muistikirjasi GitHubista Synapse Data Science -kokemukseen
Avaa sisäinen muistikirja
Tämän opetusohjelman mukana on esimerkki Kirjasuositus-muistikirjasta .
Opetusohjelman sisäinen näytemuistikirja avataan Synapse Data Science -kokemuksesta seuraavasti:
Siirry Synapse Data Science -aloitussivulle.
Valitse Käytä mallia.
Valitse vastaava malli:
- Oletusarvoisen Päästä päähän -työnkulkujen (Python) välilehdestä, jos malli on tarkoitettu Python-opetusohjelmaa varten.
- Jos malli on R-opetusohjelmassa, päästä päähän -työnkulut (R) -välilehdeltä.
- Pikaopetusohjelmat-välilehdessä, jos malli on pikaopetusohjelmaa varten.
Liitä muistikirjaan lakehouse, ennen kuin aloitat koodin suorittamisen.
Tuo muistikirja GitHubista
AIsample - Book Recommendation.ipynb -muistikirja on mukana tässä opetusohjelmassa.
Jos haluat avata tämän opetusohjelman liitteenä olevan muistikirjan, tuo muistikirja työtilaasi noudattamalla ohjeita kohdassa Järjestelmän valmisteleminen datatieteen opetusohjelmia varten.
Jos haluat kopioida ja liittää koodin tältä sivulta, voit luoda uuden muistikirjan.
Muista liittää lakehouse muistikirjaan ennen kuin aloitat koodin suorittamisen.
Vaihe 1: Lataa tiedot
Tässä skenaariossa kirjan suosituksen tietojoukko koostuu kolmesta erillisestä tietojoukosta:
Books.csv: Kansainvälinen vakiokirjannumero (ISBN) tunnistaa jokaisen kirjan, ja virheelliset päivämäärät on jo poistettu. Tietojoukko sisältää myös otsikon, tekijän ja julkaisijan. Jos kirja sisältää useita kirjailijoita, Books.csv tiedostossa luetellaan vain ensimmäinen tekijä. URL-osoitteet osoittavat Amazonin verkkosivuston resursseihin kansikuville kolmessa koossa.
ISBN Kirjan otsikko Kirjan tekijä Julkaisuvuosi Publisher Image-URL-S Image-URL-M Image-URL-l 0195153448 Klassinen mytologia Mark P. O. Morford 2002 Oxford University Press http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg 0002005018 Clara Callan Richard Bruce Wright 2001 HarperFlamingo Kanada http://images.amazon.com/images/P/0002005018.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0002005018.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0002005018.01.LZZZZZZZ.jpg Ratings.csv: Kunkin kirjan luokitukset ovat joko eksplisiittisiä (käyttäjien antamia asteikolla 1–10) tai implisiittisiä (havaitaan ilman käyttäjän syötettä ja ne on merkitty arvolla 0).
Käyttäjätunnus ISBN Kirjan luokitus 276725 034545104X 0 276726 0155061224 5 Users.csv: Käyttäjätunnukset on muunnettu nimettömään muotoon ja yhdistetty kokonaislukuihin. Demografiset tiedot – esimerkiksi sijainti ja ikä – annetaan, jos ne ovat käytettävissä. Jos nämä tiedot eivät ole käytettävissä, nämä arvot ovat
null.Käyttäjätunnus Location Ikä 1 "new york usa" 2 "stockton california usa" 18,0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Määritä nämä parametrit niin, että voit tehdä tämän muistikirjan, jossa on eri tietojoukkoja:
IS_CUSTOM_DATA = False # If True, the dataset has to be uploaded manually
USER_ID_COL = "User-ID" # Must not be '_user_id' for this notebook to run successfully
ITEM_ID_COL = "ISBN" # Must not be '_item_id' for this notebook to run successfully
ITEM_INFO_COL = (
"Book-Title" # Must not be '_item_info' for this notebook to run successfully
)
RATING_COL = (
"Book-Rating" # Must not be '_rating' for this notebook to run successfully
)
IS_SAMPLE = True # If True, use only <SAMPLE_ROWS> rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_FOLDER = "Files/book-recommendation/" # Folder that contains the datasets
ITEMS_FILE = "Books.csv" # File that contains the item information
USERS_FILE = "Users.csv" # File that contains the user information
RATINGS_FILE = "Ratings.csv" # File that contains the rating information
EXPERIMENT_NAME = "aisample-recommendation" # MLflow experiment name
Tietojen lataaminen ja tallentaminen Lakehouse-järjestelmään
Tämä koodi lataa tietojoukon ja tallentaa sen lakehouse-järjestelmään.
Tärkeä
Muista lisätä muistikirjaan lakehouse ennen kuin suoritat sen. Muussa tapauksessa saat virheilmoituksen.
if not IS_CUSTOM_DATA:
# Download data files into a lakehouse if they don't exist
import os, requests
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Book-Recommendation-Dataset"
file_list = ["Books.csv", "Ratings.csv", "Users.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
MLflow-kokeilujen seurannan määrittäminen
Tämän koodin avulla voit määrittää MLflow-kokeilujen seurannan. Tämä esimerkki poistaa käytöstä automaattisen lokittelun. Lisätietoja on artikkelissa Automaattinen lokiloggaus Microsoft Fabricissa .
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Disable MLflow autologging
Tietojen lukeminen Lakehousesta
Kun oikeat tiedot on sijoitettu lakehouse-järjestelmään, lue muistikirjasta kolme tietojoukkoa erillisiksi Spark DataFrame -kehyksiksi. Tämän koodin tiedostopolut käyttävät aiemmin määritettyjä parametreja.
df_items = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{ITEMS_FILE}")
.cache()
)
df_ratings = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{RATINGS_FILE}")
.cache()
)
df_users = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{USERS_FILE}")
.cache()
)
Vaihe 2: Tee valmisteleva tietoanalyysi
Raakatietojen näyttäminen
Tutustu DataFrame-kehyksiin komennolla display . Tämän komennon avulla voit tarkastella korkean tason DataFrame-tilastoja ja ymmärtää, miten eri tietojoukkojen sarakkeet liittyvät toisiinsa. Ennen kuin tutustut tietojoukkoihin, tuo tarvittavat kirjastot tämän koodin avulla:
import pyspark.sql.functions as F
from pyspark.ml.feature import StringIndexer
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette() # Adjusting plotting style
import pandas as pd # DataFrames
Tämän koodin avulla voit tarkastella dataframe-kehyksen, joka sisältää kirjan tiedot:
display(df_items, summary=True)
_item_id Lisää sarake myöhempää käyttöä varten. Arvon _item_id on oltava kokonaisluku suositusmalleille. Tätä koodia käytetään StringIndexer muuntamaan ITEM_ID_COL indekseihin:
df_items = (
StringIndexer(inputCol=ITEM_ID_COL, outputCol="_item_id")
.setHandleInvalid("skip")
.fit(df_items)
.transform(df_items)
.withColumn("_item_id", F.col("_item_id").cast("int"))
)
Näytä DataFrame ja tarkista, kasvaako _item_id arvo yksitoikkoisesti ja peräkkäin odotetulla tavalla:
display(df_items.sort(F.col("_item_id").desc()))
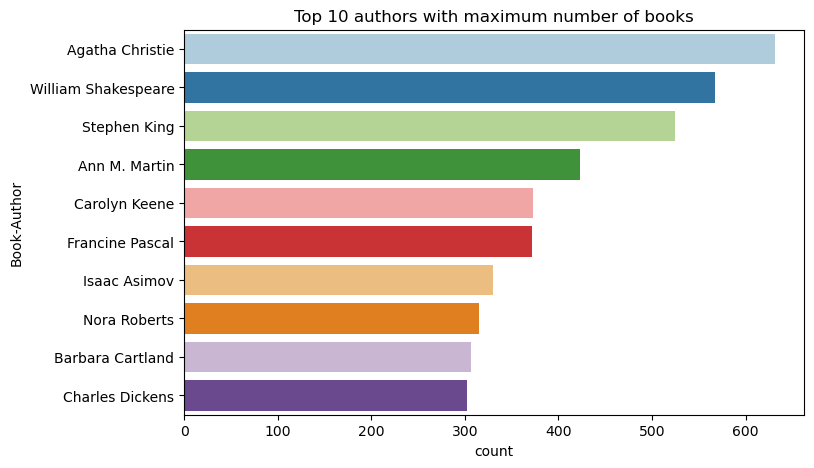
Tämän koodin avulla voit piirtää kymmenen parasta tekijää kirjoittamien kirjojen määrän mukaan laskevaan järjestykseen. Agatha Christie on johtava kirjailija, jolla on yli 600 kirjaa, jota seuraa William Shakespeare.
df_books = df_items.toPandas() # Create a pandas DataFrame from the Spark DataFrame for visualization
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Author",palette = 'Paired', data=df_books,order=df_books['Book-Author'].value_counts().index[0:10])
plt.title("Top 10 authors with maximum number of books")
Näytä seuraavaksi DataFrame, joka sisältää käyttäjätiedot:
display(df_users, summary=True)
Jos riviltä puuttuu User-ID arvo, pudota kyseinen rivi. Mukautetun tietojoukon puuttuvat arvot eivät aiheuta ongelmia.
df_users = df_users.dropna(subset=(USER_ID_COL))
display(df_users, summary=True)
_user_id Lisää sarake myöhempää käyttöä varten. Suositusmalleissa _user_id arvon on oltava kokonaisluku. Seuraava koodiesimerkki muuntaa USER_ID_COL indekseihin muunnoksen avullaStringIndexer.
Kirjan tietojoukossa on jo kokonaislukusarake User-ID . Sarakkeen _user_id lisääminen yhteensopivuuden lisäämiseksi eri tietojoukkojen kanssa tekee tästä esimerkistä kuitenkin tehokkaampi. Lisää sarake käyttämällä tätä koodia _user_id :
df_users = (
StringIndexer(inputCol=USER_ID_COL, outputCol="_user_id")
.setHandleInvalid("skip")
.fit(df_users)
.transform(df_users)
.withColumn("_user_id", F.col("_user_id").cast("int"))
)
display(df_users.sort(F.col("_user_id").desc()))
Tämän koodin avulla voit tarkastella luokitustietoja:
display(df_ratings, summary=True)
Hanki erilliset luokitukset ja tallenna ne myöhempää käyttöä varten luettelossa nimeltä ratings:
ratings = [i[0] for i in df_ratings.select(RATING_COL).distinct().collect()]
print(ratings)
Tämän koodin avulla voit näyttää top 10 kirjaa, joilla on eniten luokituksia:
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Title",palette = 'Paired',data= df_books, order=df_books['Book-Title'].value_counts().index[0:10])
plt.title("Top 10 books per number of ratings")
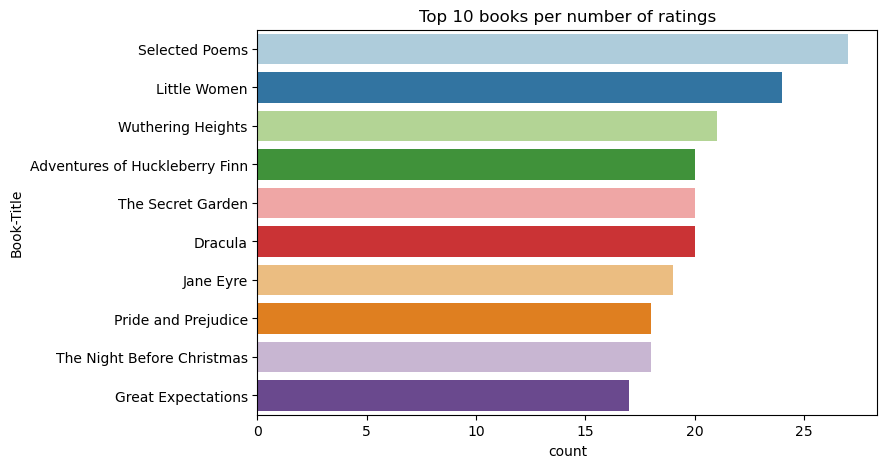
Katsojalukujen mukaan Valitut runot on suosituin kirja. Adventures of Huckleberry Finn, The Secret Garden ja Dracula ovat saaneet saman arvion.
Tietojen yhdistäminen
Yhdistä kolme DataFrame-kehystä yhdeksi DataFrameksi kattavampaa analyysia varten:
df_all = df_ratings.join(df_users, USER_ID_COL, "inner").join(
df_items, ITEM_ID_COL, "inner"
)
df_all_columns = [
c for c in df_all.columns if c not in ["_user_id", "_item_id", RATING_COL]
]
# Reorder the columns to ensure that _user_id, _item_id, and Book-Rating are the first three columns
df_all = (
df_all.select(["_user_id", "_item_id", RATING_COL] + df_all_columns)
.withColumn("id", F.monotonically_increasing_id())
.cache()
)
display(df_all)
Tämän koodin avulla voit näyttää erillisten käyttäjien, kirjojen ja vuorovaikutusten määrän:
print(f"Total Users: {df_users.select('_user_id').distinct().count()}")
print(f"Total Items: {df_items.select('_item_id').distinct().count()}")
print(f"Total User-Item Interactions: {df_all.count()}")
Laske ja piirtää suosituimmat kohteet
Käytä tätä koodia kymmenen suosituimman kirjan laskemiseen ja näyttämiseen:
# Compute top popular products
df_top_items = (
df_all.groupby(["_item_id"])
.count()
.join(df_items, "_item_id", "inner")
.sort(["count"], ascending=[0])
)
# Find top <topn> popular items
topn = 10
pd_top_items = df_top_items.limit(topn).toPandas()
pd_top_items.head(10)
Vihje
Käytä suositusosioiden <topn> Suositut tai Suurin ostettu arvo.
# Plot top <topn> items
f, ax = plt.subplots(figsize=(10, 5))
plt.xticks(rotation="vertical")
sns.barplot(y=ITEM_INFO_COL, x="count", data=pd_top_items)
ax.tick_params(axis='x', rotation=45)
plt.xlabel("Number of Ratings for the Item")
plt.show()

Koulutuksen ja testitietojoukkojen valmistelu
ALS-matriisi edellyttää jonkin verran tietojen valmistelua ennen harjoittamista. Valmistele tiedot tämän koodimallin avulla. Koodi suorittaa seuraavat toimet:
- Luokitussarakkeen heittäminen oikeaan tyyppiin
- Esimerkki koulutustiedoista käyttäjäluokitusten avulla
- Tietojen jakaminen harjoittamisen ja testaamisen tietojoukkoihin
if IS_SAMPLE:
# Must sort by '_user_id' before performing limit to ensure that ALS works normally
# If training and test datasets have no common _user_id, ALS will fail
df_all = df_all.sort("_user_id").limit(SAMPLE_ROWS)
# Cast the column into the correct type
df_all = df_all.withColumn(RATING_COL, F.col(RATING_COL).cast("float"))
# Using a fraction between 0 and 1 returns the approximate size of the dataset; for example, 0.8 means 80% of the dataset
# Rating = 0 means the user didn't rate the item, so it can't be used for training
# We use the 80% of the dataset with rating > 0 as the training dataset
fractions_train = {0: 0}
fractions_test = {0: 0}
for i in ratings:
if i == 0:
continue
fractions_train[i] = 0.8
fractions_test[i] = 1
# Training dataset
train = df_all.sampleBy(RATING_COL, fractions=fractions_train)
# Join with leftanti will select all rows from df_all with rating > 0 and not in the training dataset; for example, the remaining 20% of the dataset
# test dataset
test = df_all.join(train, on="id", how="leftanti").sampleBy(
RATING_COL, fractions=fractions_test
)
Sparsity viittaa niukkaan palautetietoon, joka ei pysty tunnistamaan samankaltaisuuksia käyttäjien kiinnostuksen kohteissa. Saat paremman käsityksen sekä tiedoista että nykyisestä ongelmasta käyttämällä tätä koodia tietojoukon sparsiteettien laskemiseen:
# Compute the sparsity of the dataset
def get_mat_sparsity(ratings):
# Count the total number of ratings in the dataset - used as numerator
count_nonzero = ratings.select(RATING_COL).count()
print(f"Number of rows: {count_nonzero}")
# Count the total number of distinct user_id and distinct product_id - used as denominator
total_elements = (
ratings.select("_user_id").distinct().count()
* ratings.select("_item_id").distinct().count()
)
# Calculate the sparsity by dividing the numerator by the denominator
sparsity = (1.0 - (count_nonzero * 1.0) / total_elements) * 100
print("The ratings DataFrame is ", "%.4f" % sparsity + "% sparse.")
get_mat_sparsity(df_all)
# Check the ID range
# ALS supports only values in the integer range
print(f"max user_id: {df_all.agg({'_user_id': 'max'}).collect()[0][0]}")
print(f"max user_id: {df_all.agg({'_item_id': 'max'}).collect()[0][0]}")
Vaihe 3: Mallin kehittäminen ja harjoittaminen
Harjoita ALS-malli antamaan käyttäjille henkilökohtaisia suosituksia.
Mallin määrittäminen
Spark ML tarjoaa kätevän ohjelmointirajapinnan ALS-mallin luomiseen. Malli ei kuitenkaan pysty käsittelemään luotettavasti ongelmia, kuten tietojen säätöä ja kylmäkäynnistystä (suositusten tekemistä, kun käyttäjät tai kohteet ovat uusia). Mallin suorituskyvyn parantamiseksi yhdistä ristiintarkistus ja automaattinen hyperparametrin säätö.
Tämän koodin avulla voit tuoda kirjastot, joita tarvitaan mallin harjoittamiseen ja arviointiin:
# Import Spark required libraries
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator, TrainValidationSplit
# Specify the training parameters
num_epochs = 1 # Number of epochs; here we use 1 to reduce the training time
rank_size_list = [64] # The values of rank in ALS for tuning
reg_param_list = [0.01, 0.1] # The values of regParam in ALS for tuning
model_tuning_method = "TrainValidationSplit" # TrainValidationSplit or CrossValidator
# Build the recommendation model by using ALS on the training data
# We set the cold start strategy to 'drop' to ensure that we don't get NaN evaluation metrics
als = ALS(
maxIter=num_epochs,
userCol="_user_id",
itemCol="_item_id",
ratingCol=RATING_COL,
coldStartStrategy="drop",
implicitPrefs=False,
nonnegative=True,
)
Mallin hyperparametrien hienosäätäminen
Seuraava koodiesimerkki muodostaa parametriruudukon, jonka avulla voidaan hakea hyperparametreja. Koodi luo myös regression arvioijan, joka käyttää arviointimittarina juuritason keskiarvon neliön virhettä (RMSE):
# Construct a grid search to select the best values for the training parameters
param_grid = (
ParamGridBuilder()
.addGrid(als.rank, rank_size_list)
.addGrid(als.regParam, reg_param_list)
.build()
)
print("Number of models to be tested: ", len(param_grid))
# Define the evaluator and set the loss function to the RMSE
evaluator = RegressionEvaluator(
metricName="rmse", labelCol=RATING_COL, predictionCol="prediction"
)
Seuraava koodiesimerkki käynnistää erilaisia mallin säätömenetelmiä esimääritettyjen parametrien perusteella. Lisätietoja mallin virittämisestä on Apache Spark -sivuston kohdassa Koneoppimisen viritys: mallin valinta ja hyperparametrin säätö .
# Build cross-validation by using CrossValidator and TrainValidationSplit
if model_tuning_method == "CrossValidator":
tuner = CrossValidator(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
numFolds=5,
collectSubModels=True,
)
elif model_tuning_method == "TrainValidationSplit":
tuner = TrainValidationSplit(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
# 80% of the training data will be used for training; 20% for validation
trainRatio=0.8,
collectSubModels=True,
)
else:
raise ValueError(f"Unknown model_tuning_method: {model_tuning_method}")
Mallin arvioiminen
Arvioi moduuleja testitietojen perusteella. Hyvin harjoitetulla mallilla tulisi olla suuret mittausarvot tietojoukossa.
Ylikuormitettu malli saattaa tarvita harjoitustietojen koon kasvattamista tai joidenkin tarpeettomien ominaisuuksien vähentämistä. Malliarkkitehtuuria on ehkä muutettava, tai sen parametrit saattavat edellyttää säätämistä.
Muistiinpano
Negatiivinen R-neliön mittausarvo ilmaisee, että harjoitettu malli toimii huonommin kuin vaakasuora viiva. Tämä havainto viittaa siihen, että harjoitettu malli ei selitä tietoja.
Määritä arviointifunktio käyttämällä tätä koodia:
def evaluate(model, data, verbose=0):
"""
Evaluate the model by computing rmse, mae, r2, and variance over the data.
"""
predictions = model.transform(data).withColumn(
"prediction", F.col("prediction").cast("double")
)
if verbose > 1:
# Show 10 predictions
predictions.select("_user_id", "_item_id", RATING_COL, "prediction").limit(
10
).show()
# Initialize the regression evaluator
evaluator = RegressionEvaluator(predictionCol="prediction", labelCol=RATING_COL)
_evaluator = lambda metric: evaluator.setMetricName(metric).evaluate(predictions)
rmse = _evaluator("rmse")
mae = _evaluator("mae")
r2 = _evaluator("r2")
var = _evaluator("var")
if verbose > 0:
print(f"RMSE score = {rmse}")
print(f"MAE score = {mae}")
print(f"R2 score = {r2}")
print(f"Explained variance = {var}")
return predictions, (rmse, mae, r2, var)
Seuraa kokeilua MLflow'n avulla
MLflow-parametrien avulla voit seurata kaikkia kokeita ja kirjata parametrit, mittarit ja mallit. Voit aloittaa mallin harjoittamisen ja arvioinnin käyttämällä seuraavaa koodia:
from mlflow.models.signature import infer_signature
with mlflow.start_run(run_name="als"):
# Train models
models = tuner.fit(train)
best_metrics = {"RMSE": 10e6, "MAE": 10e6, "R2": 0, "Explained variance": 0}
best_index = 0
# Evaluate models
# Log models, metrics, and parameters
for idx, model in enumerate(models.subModels):
with mlflow.start_run(nested=True, run_name=f"als_{idx}") as run:
print("\nEvaluating on test data:")
print(f"subModel No. {idx + 1}")
predictions, (rmse, mae, r2, var) = evaluate(model, test, verbose=1)
signature = infer_signature(
train.select(["_user_id", "_item_id"]),
predictions.select(["_user_id", "_item_id", "prediction"]),
)
print("log model:")
mlflow.spark.log_model(
model,
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
print("log metrics:")
current_metric = {
"RMSE": rmse,
"MAE": mae,
"R2": r2,
"Explained variance": var,
}
mlflow.log_metrics(current_metric)
if rmse < best_metrics["RMSE"]:
best_metrics = current_metric
best_index = idx
print("log parameters:")
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
# Log the best model and related metrics and parameters to the parent run
mlflow.spark.log_model(
models.subModels[best_index],
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
mlflow.log_metrics(best_metrics)
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
Valitse työtilastasi nimetty aisample-recommendation kokeilu, niin näet harjoittamisen kirjatut tiedot. Jos muutit kokeilun nimeä, valitse kokeilu, jolla on uusi nimi. Kirjatut tiedot muistuttavat tätä kuvaa:

Vaihe 4: Lataa lopullinen malli pisteytystä varten ja tee ennusteita
Kun olet suorittanut mallin harjoittamisen ja valinnut sitten parhaan mallin, lataa malli pisteytystä varten (kutsutaan joskus päätelyksi). Tämä koodi lataa mallin ja käyttää ennusteita suositellakseen 10 parasta kirjaa kullekin käyttäjälle:
# Load the best model
# MLflow uses PipelineModel to wrap the original model, so we extract the original ALSModel from the stages
model_uri = f"models:/{EXPERIMENT_NAME}-alsmodel/1"
loaded_model = mlflow.spark.load_model(model_uri, dfs_tmpdir="Files/spark").stages[-1]
# Generate top 10 book recommendations for each user
userRecs = loaded_model.recommendForAllUsers(10)
# Represent the recommendations in an interpretable format
userRecs = (
userRecs.withColumn("rec_exp", F.explode("recommendations"))
.select("_user_id", F.col("rec_exp._item_id"), F.col("rec_exp.rating"))
.join(df_items.select(["_item_id", "Book-Title"]), on="_item_id")
)
userRecs.limit(10).show()
Tuloste muistuttaa tätä taulukkoa:
| _item_id | _user_id | rating | Kirjan otsikko |
|---|---|---|---|
| 44865 | 7 | 7.9996786 | Lasher: Lives of ... |
| 786 | 7 | 6.2255826 | Pianomiehen d... |
| 45330 | 7 | 4.980466 | Mielentila |
| 38960 | 7 | 4.980466 | Kaikki mitä hän on koskaan halunnut |
| 125415 | 7 | 4.505084 | Harry Potter ja ... |
| 44939 | 7 | 4.3579073 | Taltos: Lives of ... |
| 175247 | 7 | 4.3579073 | Bonesetterin ... |
| 170183 | 7 | 4.228735 | Yksinkertaisten... |
| 88503 | 7 | 4.221206 | Blu-saari... |
| 32894 | 7 | 3.9031885 | Talvipäivänseisaus |
Tallenna ennusteet Lakehouse-talolle
Kirjoita tämän koodin avulla suositukset takaisin Lakehouseen:
# Code to save userRecs into the lakehouse
userRecs.write.format("delta").mode("overwrite").save(
f"{DATA_FOLDER}/predictions/userRecs"
)