Opetusohjelma: konevirheentunnistusmallin luominen, arvioiminen ja pisteytys
Tässä opetusohjelmassa esitellään päästä päähän -esimerkki Synapse Data Science -työnkulusta Microsoft Fabricissa. Skenaariossa käytetään koneoppimista järjestelmällisempään lähestymistapaan vikadiagnoosiin, ongelmien ennakoivaan tunnistamiseen ja toimiin ennen varsinaisia konevirheitä. Tavoitteena on ennustaa, kokevatko kone prosessin lämpötilaan, pyörimisnopeutta ja niin edelleen perustuvaa vikaan.
Tässä opetusohjelmassa käsitellään seuraavat vaiheet:
- Mukautettujen kirjastojen asentaminen
- Tietojen lataaminen ja käsitteleminen
- Tietojen ymmärtäminen valmistelevan tietoanalyysin avulla
- Scikit-learnin, LightGBM:n ja MLflow:n avulla voit kouluttaa koneoppimismalleja ja käyttää Fabric Autologging -ominaisuutta kokeilujen seuraamiseen
- Pisteytä koulutetut mallit Fabric-ominaisuudella
PREDICT, tallenna paras malli ja lataa malli ennusteita varten - Ladatun mallin suorituskyvyn näyttäminen Power BI -visualisoinneilla
Edellytykset
Hanki Microsoft Fabric -tilaus. Voit myös rekisteröityä ilmaiseen Microsoft Fabric -kokeiluversioon.
Siirry Synapse Data Science -käyttökokemukseen aloitussivun vasemmassa reunassa olevan käyttökokemuksen vaihtajan avulla.

- Luo tarvittaessa Microsoft Fabric Lakehouse kohdan Lakehouse luominen Microsoft Fabricissa ohjeiden mukaan.
Seuraa mukana muistikirjassa
Voit valita jonkin seuraavista vaihtoehdoista, joita voit seurata muistikirjassa:
- Avaa ja suorita sisäinen muistikirja Data Science -kokemuksessa
- Lataa muistikirjasi GitHubista Data Science -kokemukseen
Avaa sisäinen muistikirja
Tässä opetusohjelmassa on konevirheiden muistikirjamalli.
Opetusohjelman sisäinen näytemuistikirja avataan Synapse Data Science -kokemuksesta seuraavasti:
Siirry Synapse Data Science -aloitussivulle.
Valitse Käytä mallia.
Valitse vastaava malli:
- Oletusarvoisen Päästä päähän -työnkulkujen (Python) välilehdestä, jos malli on tarkoitettu Python-opetusohjelmaa varten.
- Jos malli on R-opetusohjelmassa, päästä päähän -työnkulut (R) -välilehdeltä.
- Pikaopetusohjelmat-välilehdessä, jos malli on pikaopetusohjelmaa varten.
Liitä muistikirjaan lakehouse, ennen kuin aloitat koodin suorittamisen.
Tuo muistikirja GitHubista
AISample – Ennakoiva ylläpito - muistikirja on tämän opetusohjelman mukana.
Jos haluat avata tämän opetusohjelman liitteenä olevan muistikirjan, tuo muistikirja työtilaasi noudattamalla ohjeita kohdassa Järjestelmän valmisteleminen datatieteen opetusohjelmia varten.
Jos haluat kopioida ja liittää koodin tältä sivulta, voit luoda uuden muistikirjan.
Muista liittää lakehouse muistikirjaan ennen kuin aloitat koodin suorittamisen.
Vaihe 1: Mukautettujen kirjastojen asentaminen
Koneoppimismallin kehittämistä tai ad-hoc-tietojen analysointia varten sinun on ehkä asennettava nopeasti mukautettu kirjasto Apache Spark -istuntoa varten. Sinulla on kaksi vaihtoehtoa kirjastojen asentamiseen.
- Asenna muistikirjasi sisäiset asennusominaisuudet (
%piptai%conda) kirjastoon, vain senhetkiseen muistikirjaasi. - Vaihtoehtoisesti voit luoda Fabric-ympäristön, asentaa kirjastoja julkisista lähteistä tai ladata mukautettuja kirjastoja siihen, jonka jälkeen työtilan järjestelmänvalvoja voi liittää ympäristön työtilan oletusarvoksi. Kaikki ympäristön kirjastot ovat sitten käytettävissä missä tahansa muistikirjoissa ja Spark-työmääritelmissä työtilassa. Katso lisätietoja ympäristöistä kohdasta Ympäristön luominen, määrittäminen ja käyttäminen Microsoft Fabricissa.
Tätä opetusohjelmaa varten %pip install voit asentaa kirjaston imblearn muistikirjaasi.
Muistiinpano
PySpark-ydin käynnistyy uudelleen suoritusten jälkeen %pip install . Asenna tarvittavat kirjastot, ennen kuin suoritat muita soluja.
# Use pip to install imblearn
%pip install imblearn
Vaihe 2: Lataa tiedot
Tietojoukko simuloi valmistuskoneen parametrien kirjaamista ajan funktiona, mikä on yleistä teollisuusasetuksissa. Se sisältää 10 000 arvopistettä, jotka on tallennettu riveinä ja ominaisuudet sarakkeina. Näitä ominaisuuksia ovat muun muassa seuraavat:
Yksilöllinen tunniste (UID), joka on välillä 1–1 0000
Tuotetunnus, joka sisältää kirjaimen L (matalalle), M (keskitasolle) tai H (korkealle), tuotelaatuvarianttia ja tuotekohtaista sarjanumeroa varten. Vähäiset, keskitasoiset ja laadukkaat variantit muodostavat 60 %, 30 % ja 10 % kaikista tuotteista
Ilman lämpötila, asteina Kelvin (K)
Prosessin lämpötila, asteina Kelvin
Pyörimisnopeus, vallankumoukset minuutissa (RPM)
Vääntö, Newtonin metrit (Nm)
Työkalu kuluu muutamassa minuutissa. Laatuvariantit H, M ja L kuluvat 5, 3 ja 2 minuuttia prosessin aikana käytetyn työkalun kanssa.
Konevirheen otsikko, joka ilmaisee, epäonnistuiko kone tietyssä arvopisteessä. Tällä tietyllä arvopisteellä voi olla mikä tahansa seuraavista viidestä itsenäisen epäonnistumisen tilasta:
- Työkalun kulumisvirhe (TWF): Työkalu korvataan tai se epäonnistuu satunnaisesti valitun työkalun kulumisaikana 200–240 minuuttia
- Lämmön häviämisvirhe (HDF): lämmön häviäminen aiheuttaa prosessin epäonnistumisen, jos ilman lämpötilan ja prosessin lämpötilan ero on alle 8,6 K ja työkalun pyörimisnopeus on alle 1 380 RPM
- Tehon epäonnistuminen (PWF): vääntösäätimen ja pyörimisnopeuden tuote (radassa/s) on yhtä suuri kuin prosessissa vaadittu teho. Prosessi epäonnistuu, jos virta on alle 3 500 W tai yli 9 000 W
- OverStrain Failure (OSF): jos työkalun kuluminen ja vääntömoksi ylittää 11 000 Nm:n vähimmäisarvon L-tuotevariantille (12 000 M:lle, 13 000 H:lle), prosessi epäonnistuu ylilyönnin vuoksi
- Satunnaiset epäonnistumiset (RNF): jokaisella prosessilla on epäonnistumismahdollisuus 0,1 %, prosessin parametreista riippumatta
Muistiinpano
Jos vähintään yksi edellä mainituista virhetiloista on tosi, prosessi epäonnistuu ja konevirheen selitteeksi on määritetty 1. Koneoppimismenetelmä ei pysty selvittämään, mikä vikatila aiheutti prosessin epäonnistumisen.
Lataa tietojoukko ja lataa se Lakehouse-palveluun
Näyttöyhteys Azure Open Datasets -säilöön ja lataa ennakoivan ylläpidon tietojoukko. Tämä koodi lataa tietojoukosta julkisesti saatavilla olevan version ja tallentaa sen Fabric Lakehouse -järjestelmään:
Tärkeä
Lisää muistikirjaan lakehouse ennen kuin suoritat sen. Muussa tapauksessa saat virheilmoituksen. Lisätietoja Lakehousen lisäämisestä on Näyttöyhteys lakehouseista ja muistikirjoista.
# Download demo data files into the lakehouse if they don't exist
import os, requests
DATA_FOLDER = "Files/predictive_maintenance/" # Folder that contains the dataset
DATA_FILE = "predictive_maintenance.csv" # Data file name
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/MachineFaultDetection"
file_list = ["predictive_maintenance.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Kun olet ladannut tietojoukon Lakehouseen, voit ladata sen Spark DataFrame -nimellä:
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}raw/{DATA_FILE}")
.cache()
)
df.show(5)
Tässä taulukossa näkyy tietojen esikatselu:
| UDI | Tuotetunnus | Tyyppi | Ilman lämpötila [K] | Prosessin lämpötila [K] | Pyörimisnopeus [rpm] | Vääntö [Nm] | Työkalun kuluminen [min] | Tavoite | Virhetyyppi |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | M | 298.1 | 308.6 | 1551 | 42.8 | 0 | 0 | Ei epäonnistumista |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | Ei epäonnistumista |
| 3 | L47182 | L | 298.1 | 308.5 | 1498 | 49.4 | 5 | 0 | Ei epäonnistumista |
| 4 | L47183 | L | 298.2 | 308.6 | 1433 | 39.5 | 7 | 0 | Ei epäonnistumista |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40.0 | 9 | 0 | Ei epäonnistumista |
Kirjoita Spark DataFrame Lakehouse delta -taulukkoon
Muotoile tiedot (esimerkiksi korvaa välilyönnit alaviivoilla) Spark-toimintojen helpottamiseksi seuraavissa vaiheissa:
# Replace the space in the column name with an underscore to avoid an invalid character while saving
df = df.toDF(*(c.replace(' ', '_') for c in df.columns))
table_name = "predictive_maintenance_data"
df.show(5)
Tässä taulukossa on esiversio tiedoista, joissa on uudelleenmuotoitut sarakkeiden nimet:
| UDI | Product_ID | Tyyppi | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[min] | Tavoite | Failure_Type |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | M | 298.1 | 308.6 | 1551 | 42.8 | 0 | 0 | Ei epäonnistumista |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | Ei epäonnistumista |
| 3 | L47182 | L | 298.1 | 308.5 | 1498 | 49.4 | 5 | 0 | Ei epäonnistumista |
| 4 | L47183 | L | 298.2 | 308.6 | 1433 | 39.5 | 7 | 0 | Ei epäonnistumista |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40.0 | 9 | 0 | Ei epäonnistumista |
# Save data with processed columns to the lakehouse
df.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Vaihe 3: tietojen esikäsittely ja valmistelevan tietoanalyysin suorittaminen
Muunna Spark DataFrame pandas DataFrame -kehykseksi Pandas-yhteensopiviksi suosituiksi piirtokirjastoiksi.
Vihje
Suuren tietojoukon kohdalla saatat joutua lataamaan osan kyseisestä tietojoukosta.
data = spark.read.format("delta").load("Tables/predictive_maintenance_data")
SEED = 1234
df = data.toPandas()
df.drop(['UDI', 'Product_ID'],axis=1,inplace=True)
# Rename the Target column to IsFail
df = df.rename(columns = {'Target': "IsFail"})
df.info()
Muunna tietyt tietojoukon sarakkeet liukuluku- tai kokonaislukutyypeiksi tarvittaessa ja yhdistä merkkijonot ('L', 'M', 'H') numeerisiksi arvoiksi (0, 1, 2):
# Convert temperature, rotational speed, torque, and tool wear columns to float
df['Air_temperature_[K]'] = df['Air_temperature_[K]'].astype(float)
df['Process_temperature_[K]'] = df['Process_temperature_[K]'].astype(float)
df['Rotational_speed_[rpm]'] = df['Rotational_speed_[rpm]'].astype(float)
df['Torque_[Nm]'] = df['Torque_[Nm]'].astype(float)
df['Tool_wear_[min]'] = df['Tool_wear_[min]'].astype(float)
# Convert the 'Target' column to an integer
df['IsFail'] = df['IsFail'].astype(int)
# Map 'L', 'M', 'H' to numerical values
df['Type'] = df['Type'].map({'L': 0, 'M': 1, 'H': 2})
Tietojen tutkiminen visualisointien avulla
# Import packages and set plotting style
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
sns.set_style('darkgrid')
# Create the correlation matrix
corr_matrix = df.corr(numeric_only=True)
# Plot a heatmap
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True)
plt.show()
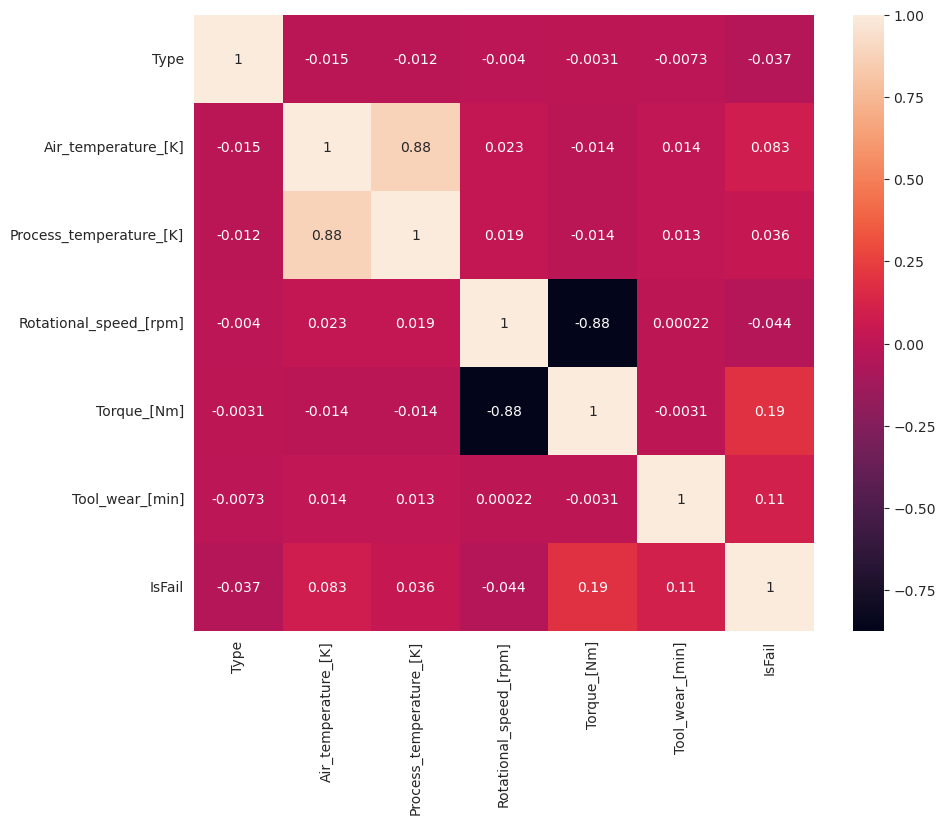
Epäonnistuminen (IsFail) korreloi odotetusti valittujen ominaisuuksien (sarakkeiden) kanssa. Korrelaatiomatriisissa näkyy, että Air_temperature, Process_temperature, Rotational_speed, Torqueja Tool_wear niillä on suurin korrelaatio muuttujaan IsFail .
# Plot histograms of select features
fig, axes = plt.subplots(2, 3, figsize=(18,10))
columns = ['Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']
data=df.copy()
for ind, item in enumerate (columns):
column = columns[ind]
df_column = data[column]
df_column.hist(ax = axes[ind%2][ind//2], bins=32).set_title(item)
fig.supylabel('count')
fig.subplots_adjust(hspace=0.2)
fig.delaxes(axes[1,2])
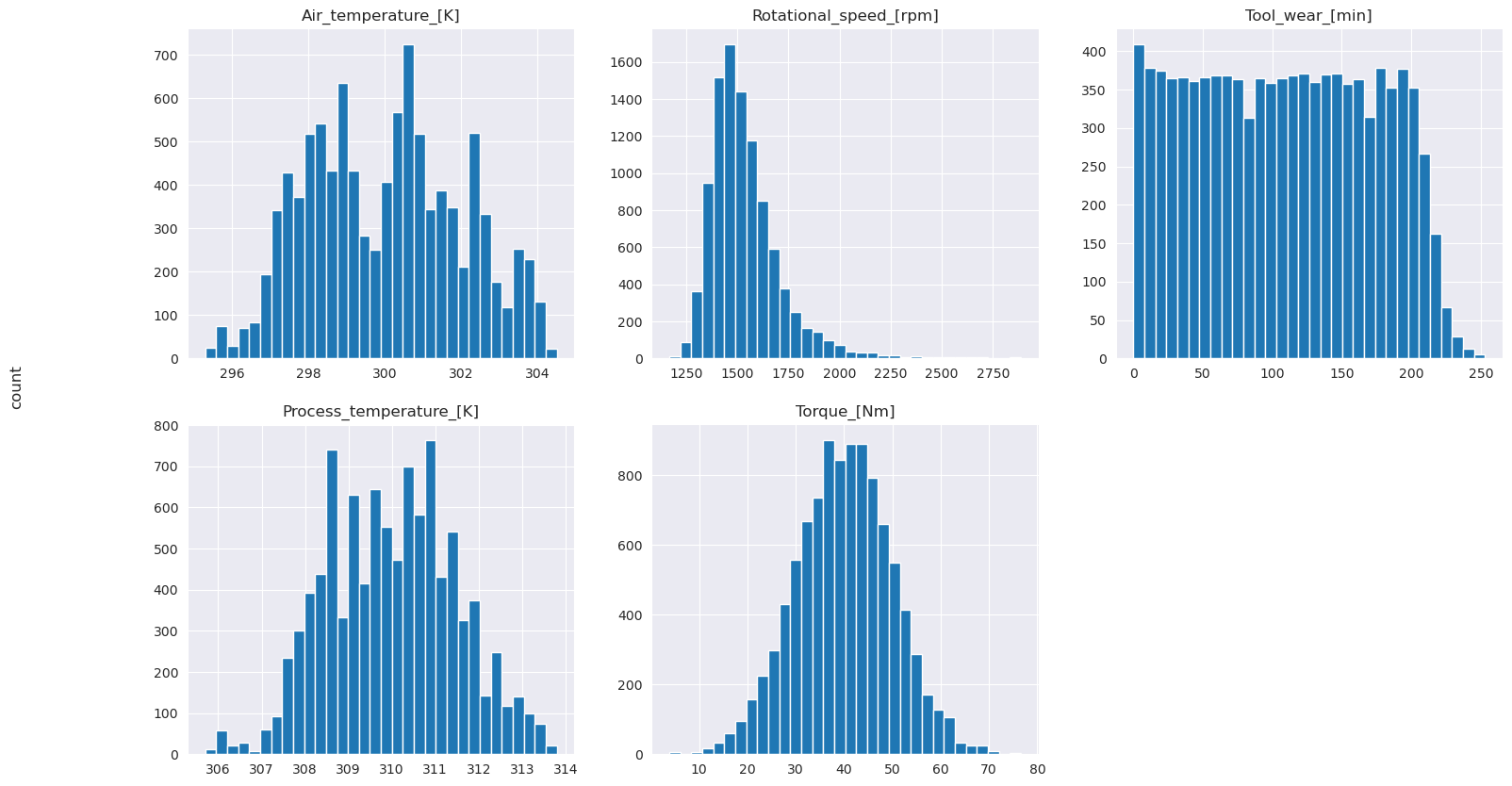
Kuten piirretyistä kaavioista ilmenee, - Air_temperature, - Process_temperature, Rotational_speed- Torqueja Tool_wear -muuttujat eivät ole niukat. Heillä näyttää olevan hyvä jatkuvuus ominaisuustilassa. Nämä kaaviot vahvistavat sitä, että koneoppimismallin harjoittaminen tähän tietojoukkoon tuottaa todennäköisesti luotettavia tuloksia, jotka voivat yleistyä uuteen tietojoukkoon.
Tarkista kohdemuuttuja luokan epätasapainon vuoksi
Laske epäonnistuneiden ja epäonnistumattomien koneiden näytteiden määrä ja tarkista kunkin luokan tietojen saldo (IsFail=0, IsFail=1):
# Plot the counts for no failure and each failure type
plt.figure(figsize=(12, 2))
ax = sns.countplot(x='Failure_Type', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
# Plot the counts for no failure versus the sum of all failure types
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
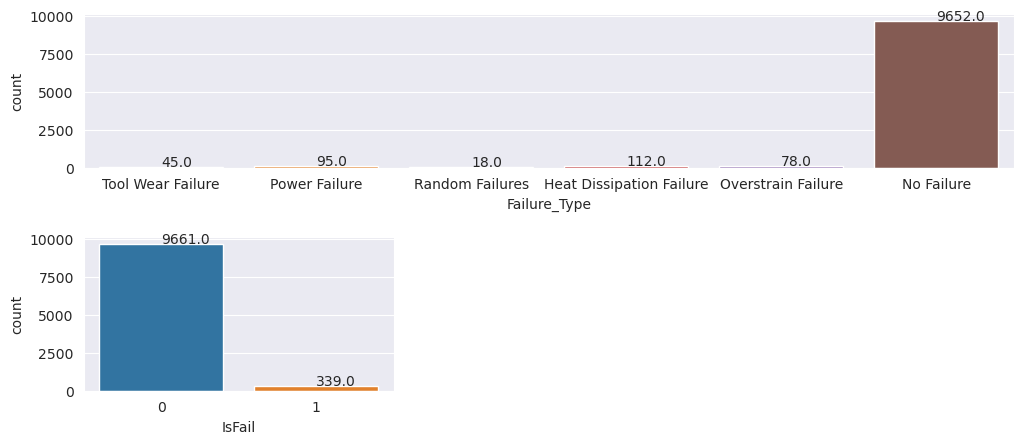
Kaaviot ilmaisevat, että epäonnistumatta jäänyt luokka (esitetään IsFail=0 toisessa kaaviossa) on suurin osa näytteistä. Luo tasapainoisempi harjoitustietojoukko ylimyyntitekniikalla:
# Separate features and target
features = df[['Type', 'Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']]
labels = df['IsFail']
# Split the dataset into the training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
# Ignore warnings
import warnings
warnings.filterwarnings('ignore')
# Save test data to the lakehouse for use in future sections
table_name = "predictive_maintenance_test_data"
df_test_X = spark.createDataFrame(X_test)
df_test_X.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Ylisampoinen harjoitustietojoukon luokkien tasapainottamiseksi
Edellinen analyysi osoitti, että tietojoukko on epätasapainoinen. Epätasapainosta tulee ongelma, koska vähemmistöluokalla on liian vähän esimerkkejä mallista, jotta se oppisi tehokkaasti päätösrajan.
SMOTE voi ratkaista ongelman. SMOTE on laajalti käytetty ylimyyntitekniikka, joka luo synteettisiä esimerkkejä. Se luo esimerkkejä vähemmistöluokasta arvopisteiden välisten euclidia-etäisyyksien perusteella. Tämä menetelmä eroaa satunnaisesta ylimyyntimenetelmästä, koska se luo uusia esimerkkejä, jotka eivät monista vain vähemmistöluokkaa. Menetelmästä tulee tehokkaampi tekniikka epätasapainoisen tietojoukon käsittelemiseksi.
# Disable MLflow autologging because you don't want to track SMOTE fitting
import mlflow
mlflow.autolog(disable=True)
from imblearn.combine import SMOTETomek
smt = SMOTETomek(random_state=SEED)
X_train_res, y_train_res = smt.fit_resample(X_train, y_train)
# Plot the counts for both classes
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=pd.DataFrame({'IsFail': y_train_res.values}))
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
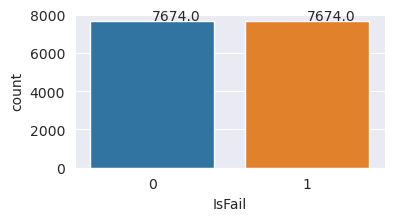
Tasapainotit tietojoukon onnistuneesti. Voit nyt siirtyä mallin harjoittamiseen.
Vaihe 4: Mallien harjoittaminen ja arvioiminen
MLflow rekisteröi mallit, junat ja vertaa eri malleja sekä poimii parhaan mallin ennustetta varten. Voit käyttää seuraavia kolmea mallia mallin harjoittamiseen:
- Satunnainen metsän luokittelu
- Logistinen regressioluokittaja
- XGBoost-luokittelu
Harjoita satunnainen metsänluokittaja
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from mlflow.models.signature import infer_signature
from sklearn.metrics import f1_score, accuracy_score, recall_score
mlflow.set_experiment("Machine_Failure_Classification")
mlflow.autolog(exclusive=False) # This is needed to override the preconfigured autologging behavior
with mlflow.start_run() as run:
rfc_id = run.info.run_id
print(f"run_id {rfc_id}, status: {run.info.status}")
rfc = RandomForestClassifier(max_depth=5, n_estimators=50)
rfc.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
rfc,
"machine_failure_model_rf",
signature=signature,
registered_model_name="machine_failure_model_rf"
)
y_pred_train = rfc.predict(X_train)
# Calculate the classification metrics for test data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = rfc.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
# Print the classification metrics
print("F1 score_test:", f1_test)
print("Accuracy_test:", accuracy_test)
print("Recall_test:", recall_test)
Tuloksesta sekä harjoitus- että testitietojoukot antavat F1-pisteet, tarkkuuden ja paikannuksen noin 0,9 käytettäessä satunnaismetsän luokittelua.
Logistisen regressioluokittajan harjoittaminen
from sklearn.linear_model import LogisticRegression
with mlflow.start_run() as run:
lr_id = run.info.run_id
print(f"run_id {lr_id}, status: {run.info.status}")
lr = LogisticRegression(random_state=42)
lr.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
lr,
"machine_failure_model_lr",
signature=signature,
registered_model_name="machine_failure_model_lr"
)
y_pred_train = lr.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = lr.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
XGBoost-luokittelun harjoittaminen
from xgboost import XGBClassifier
with mlflow.start_run() as run:
xgb = XGBClassifier()
xgb_id = run.info.run_id
print(f"run_id {xgb_id}, status: {run.info.status}")
xgb.fit(X_train_res.to_numpy(), y_train_res.to_numpy())
signature = infer_signature(X_train_res, y_train_res)
mlflow.xgboost.log_model(
xgb,
"machine_failure_model_xgb",
signature=signature,
registered_model_name="machine_failure_model_xgb"
)
y_pred_train = xgb.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = xgb.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
Vaihe 5: Valitse paras malli ja ennusta tulokset
Edellisessä osiossa koulutit kolme eri luokittelua: satunnaisen metsän, logistinen regressio ja XGBoost. Voit nyt joko käyttää tuloksia ohjelmallisesti tai käyttää käyttöliittymää.
Siirry Käyttöliittymäpolku-vaihtoehtoa työtilaasi ja suodata mallit.
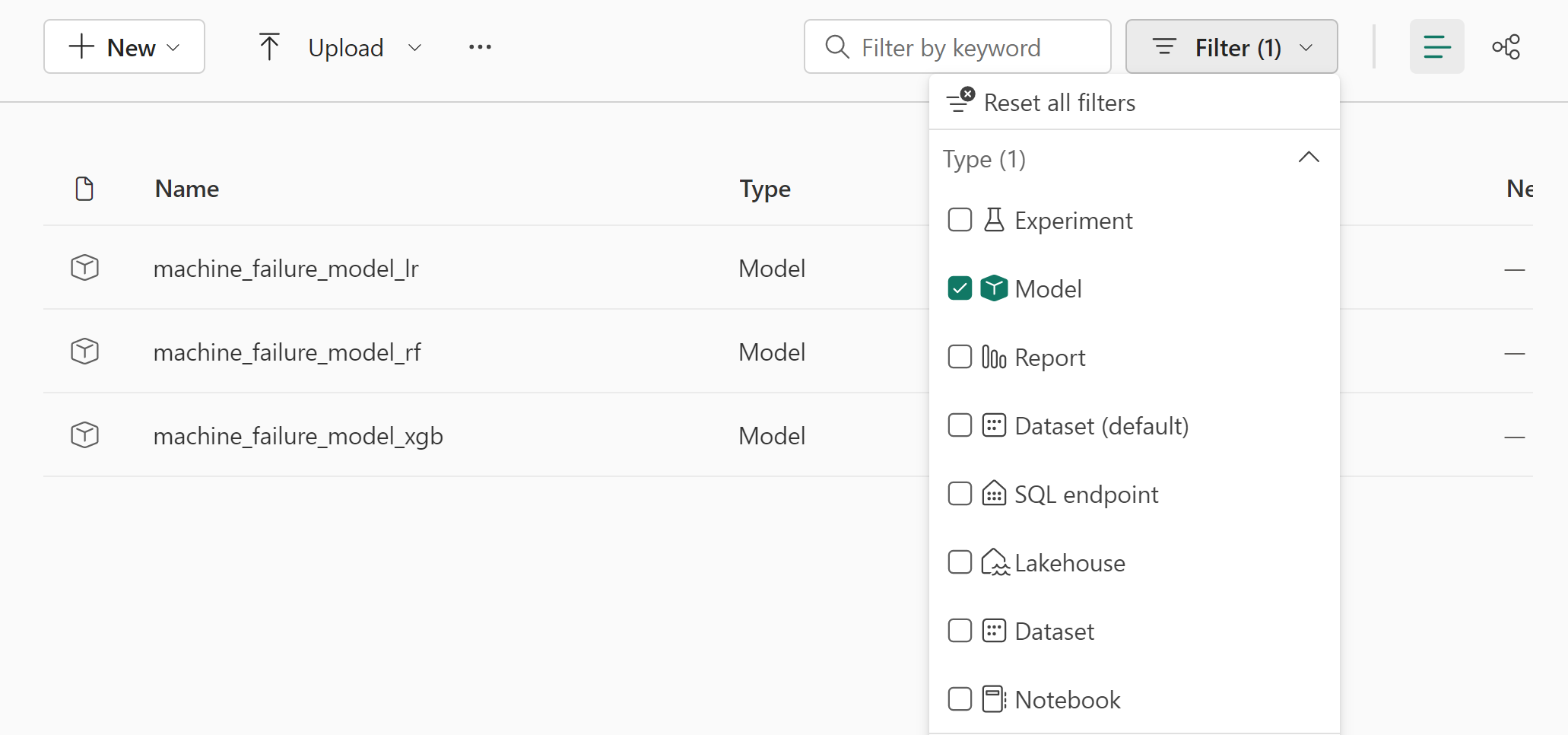
Saat lisätietoja mallin suorituskyvystä valitsemalla yksittäisiä malleja.
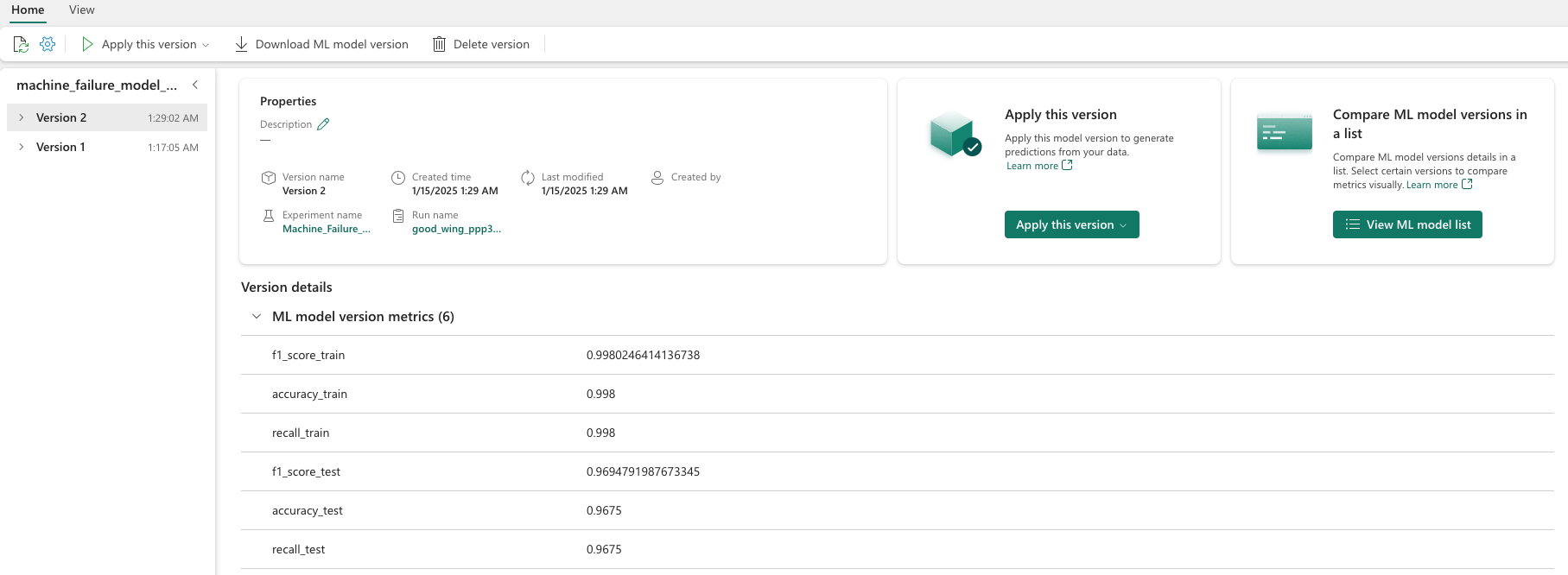
Tässä esimerkissä näytetään, miten voit käyttää malleja ohjelmallisesti MLflow'n kautta:
runs = {'random forest classifier': rfc_id,
'logistic regression classifier': lr_id,
'xgboost classifier': xgb_id}
# Create an empty DataFrame to hold the metrics
df_metrics = pd.DataFrame()
# Loop through the run IDs and retrieve the metrics for each run
for run_name, run_id in runs.items():
metrics = mlflow.get_run(run_id).data.metrics
metrics["run_name"] = run_name
df_metrics = df_metrics.append(metrics, ignore_index=True)
# Print the DataFrame
print(df_metrics)
Vaikka XGBoost tuottaa harjoitusjoukon parhaat tulokset, se suoriutuu testitietojoukossa huonosti. Heikko suorituskyky ilmaisee, että se on ylisovitus. Logistinen regressioluokittaja toimii huonosti sekä harjoittamisen että testin tietojoukoissa. Kaiken kaikkiaan satunnainen metsä löytää hyvän tasapainon koulutuksen suorituskyvyn ja ylikuormitettavuuden välttämisen välillä.
Valitse seuraavassa osiossa rekisteröity satunnaisen metsän malli ja suorita ennuste PREDICT-ominaisuudella:
from synapse.ml.predict import MLFlowTransformer
model = MLFlowTransformer(
inputCols=list(X_test.columns),
outputCol='predictions',
modelName='machine_failure_model_rf',
modelVersion=1
)
MLFlowTransformer Lataa malli päättelyä varten käyttämällä Muuntajan ohjelmointirajapintaa mallin pisteytykseen testitietojoukolle käyttämällä luomaasi objektia:
predictions = model.transform(spark.createDataFrame(X_test))
predictions.show()
Tässä taulukossa näytetään tulokset:
| Tyyppi | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[min] | Ennusteet |
|---|---|---|---|---|---|---|
| 0 | 300.6 | 309.7 | 1639.0 | 30.4 | 121.0 | 0 |
| 0 | 303.9 | 313.0 | 1551.0 | 36.8 | 140.0 | 0 |
| 1 | 299.1 | 308.6 | 1491.0 | 38.5 | 166.0 | 0 |
| 0 | 300.9 | 312.1 | 1359.0 | 51.7 | 146.0 | 1 |
| 0 | 303.7 | 312.6 | 1621.0 | 38.8 | 182.0 | 0 |
| 0 | 299.0 | 310.3 | 1868.0 | 24.0 | 221.0 | 1 |
| 2 | 297.8 | 307.5 | 1631.0 | 31.3 | 124.0 | 0 |
| 0 | 297.5 | 308.2 | 1327.0 | 56.5 | 189.0 | 1 |
| 0 | 301.3 | 310.3 | 1460.0 | 41.5 | 197.0 | 0 |
| 2 | 297.6 | 309.0 | 1413.0 | 40.2 | 51.0 | 0 |
| 1 | 300.9 | 309.4 | 1724.0 | 25.6 | 119.0 | 0 |
| 0 | 303.3 | 311.3 | 1389.0 | 53.9 | 39.0 | 0 |
| 0 | 298.4 | 307.9 | 1981.0 | 23.2 | 16.0 | 0 |
| 0 | 299.3 | 308.8 | 1636.0 | 29.9 | 201.0 | 0 |
| 1 | 298.1 | 309.2 | 1460.0 | 45.8 | 80,0 | 0 |
| 0 | 300.0 | 309.5 | 1728.0 | 26,0 | 37.0 | 0 |
| 2 | 299.0 | 308.7 | 1940.0 | 19.9 | 98.0 | 0 |
| 0 | 302.2 | 310.8 | 1383.0 | 46.9 | 45.0 | 0 |
| 0 | 300.2 | 309.2 | 1431.0 | 51.3 | 57.0 | 0 |
| 0 | 299.6 | 310.2 | 1468.0 | 48.0 | 9,0 | 0 |
Tallenna tiedot Lakehouse-tallennustilaan. Sen jälkeen tiedot ovat käytettävissä myöhempää käyttöä varten , esimerkiksi Power BI -koontinäyttöä varten.
# Save test data to the lakehouse for use in the next section.
table_name = "predictive_maintenance_test_with_predictions"
predictions.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Vaihe 6: liiketoimintatietojen tarkastelu Power BI:n visualisointien kautta
Näytä tulokset offline-muodossa Power BI -koontinäytön avulla.
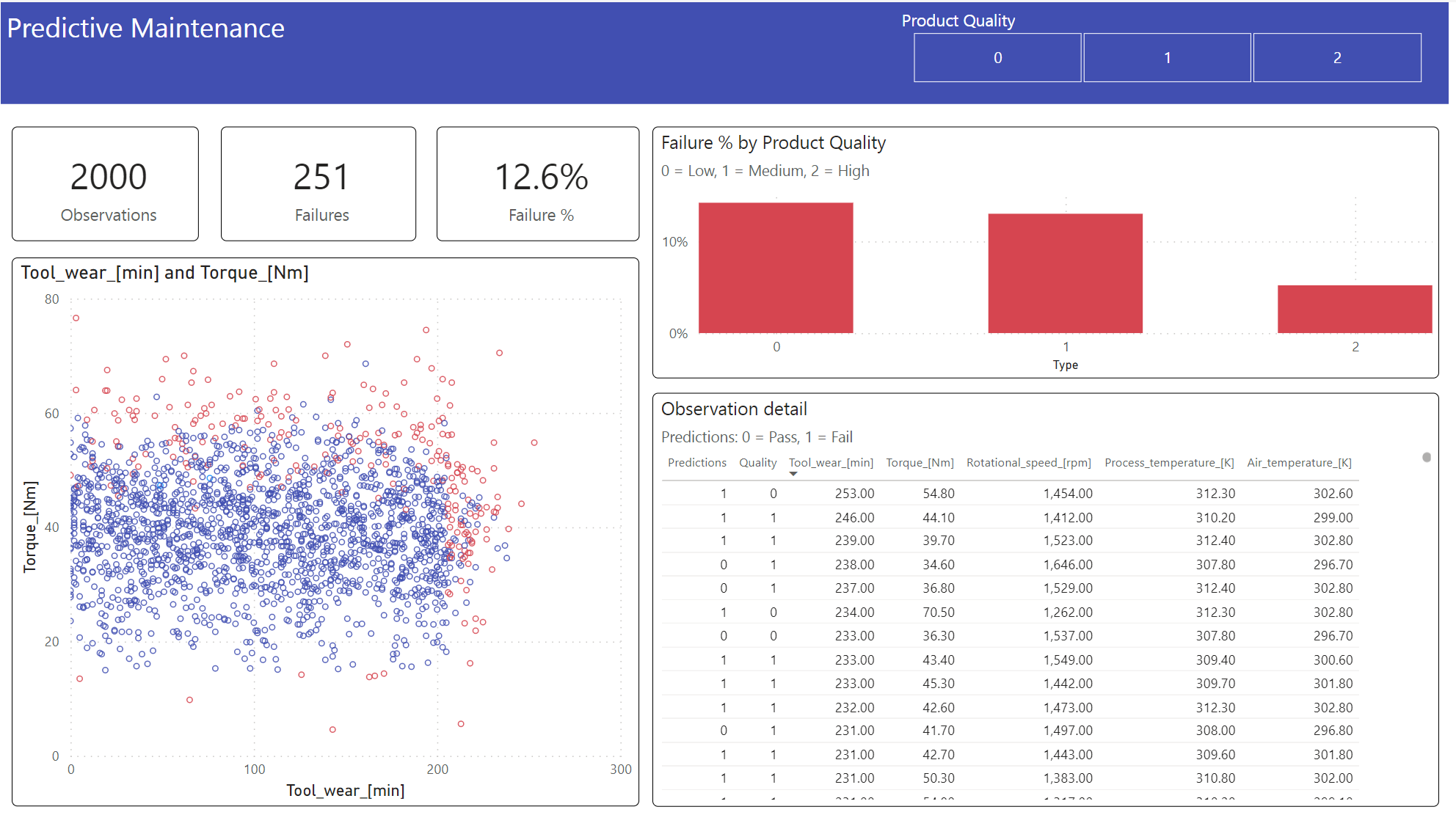
Koontinäyttö näyttää sen Tool_wear ja Torque luo epäonnistuneen ja epäonnistuneen tapauksen välille havaittavan rajan, kuten vaiheen 2 aiemmassa korrelaatioanalyysissa odotettiin.