Opetusohjelma: Vaihtuvuusennustemallin luominen, arvioiminen ja pisteytys
Tässä opetusohjelmassa esitellään päästä päähän -esimerkki Synapse Data Science -työnkulusta Microsoft Fabricissa. Skenaariossa luodaan malli, joka ennustaa, vaihtuvatko pankkiasiakkaat vai eivät. Vaihtuvuusprosentti eli vaihtuvuusprosentti liittyy siihen kurssiin, jolla pankkiasiakkaat lopettavat liiketoimintansa pankkiin.
Tässä opetusohjelmassa käsitellään seuraavat vaiheet:
- Mukautettujen kirjastojen asentaminen
- Lataa tiedot
- Tietojen ymmärtäminen ja käsitteleminen valmistelevan tietoanalyysin avulla sekä Fabric Data Wrangler -ominaisuuden käytön osoittaminen
- Scikit-learnin ja LightGBM:n avulla voit kouluttaa koneoppimismalleja sekä seurata MLflow- ja Fabric Autologging -ominaisuuksien kokeiluja
- Lopullisen koneoppimismallin arvioiminen ja tallentaminen
- Mallin suorituskyvyn näyttäminen Power BI -visualisointien avulla
Edellytykset
Hanki Microsoft Fabric -tilaus. Voit myös rekisteröityä microsoft fabric -kokeiluversion maksuttomaan .
Vaihda Fabriciin aloitussivun vasemmassa alakulmassa olevan käyttökokemuksen vaihtajan avulla.

- Luo tarvittaessa Microsoft Fabric Lakehouse kohdan Create a Lakehouse in Microsoft Fabrickuvatulla tavalla.
Seuraa mukana muistikirjassa
Voit valita jonkin seuraavista vaihtoehdoista, joita voit seurata muistikirjassa:
- Avaa ja suorita sisäinen muistikirja.
- Lataa muistikirja GitHubista.
Avaa sisäinen muistikirja
Tämän opetusohjelman mukana on malli Asiakas vaihtuva -muistikirja.
Avaa tätä opetusohjelmaa varten näytemuistikirja noudattamalla ohjeita kohdassa Järjestelmän valmisteleminen datatieteen opetusohjelmia varten.
Varmista, että liittää lakehouse- ennen kuin aloitat koodin suorittamisen.
Tuo muistikirja GitHubista
Tämän opetusohjelman mukana on AIsample - Bank Customer Churn.ipynb notebook.
Jos haluat avata tämän opetusohjelman liitteenä olevan muistikirjan, noudata ohjeita kohdassa Valmistele järjestelmäsi datatiedeopetusohjelmia varten muistikirjan tuomiseksi työtilaasi.
Jos haluat kopioida ja liittää koodin tältä sivulta, voit luoda uuden muistikirjan.
Muista liittää muistikirjaan lakehouse- ennen kuin aloitat koodin suorittamisen.
Vaihe 1: Mukautettujen kirjastojen asentaminen
Koneoppimismallin kehittämistä tai ad-hoc-tietojen analysointia varten sinun on ehkä asennettava nopeasti mukautettu kirjasto Apache Spark -istuntoa varten. Sinulla on kaksi vaihtoehtoa kirjastojen asentamiseen.
- Asenna kirjasto nykyiseen muistikirjaasi käyttämällä muistikirjasi sisäiset asennusominaisuudet (
%piptai%conda). - Vaihtoehtoisesti voit luoda Fabric-ympäristön, asentaa kirjastoja julkisista lähteistä tai ladata mukautettuja kirjastoja siihen, jonka jälkeen työtilan järjestelmänvalvoja voi liittää ympäristön työtilan oletusarvoksi. Kaikki ympäristön kirjastot ovat sitten käytettävissä missä tahansa muistikirjoissa ja Spark-työmääritelmissä työtilassa. Lisätietoja ympäristöistä on artikkelissa Ympäristön luominen, määrittäminen ja käyttäminen Microsoft Fabric -.
Tässä opetusohjelmassa asenna %pip install-kirjasto muistikirjaasi imblearn avulla.
Muistiinpano
PySpark-ydin käynnistyy uudelleen %pip install suoritusten jälkeen. Asenna tarvittavat kirjastot, ennen kuin suoritat muita soluja.
# Use pip to install libraries
%pip install imblearn
Vaihe 2: Lataa tiedot
churn.csv tietojoukko sisältää 10 000 asiakkaan vaihtuvuustilan sekä 14 määritettä, jotka ovat seuraavat:
- Luottopisteet
- Maantieteellinen sijainti (Saksa, Ranska, Espanja)
- Sukupuoli (mies, nainen)
- Ikä
- Hallinnan kesto (vuosien määrä, jolloin henkilö oli kyseisen pankin asiakas)
- Tilin saldo
- Arvioitu palkka
- Asiakkaan pankin kautta ostamien tuotteiden määrä
- Luottokortin tila (riippumatta siitä, onko asiakkaalla luottokortti)
- Aktiivisen jäsenen tila (riippumatta siitä, onko henkilö aktiivinen pankkiasiakas)
Tietojoukko sisältää myös rivin numeron, asiakastunnuksen ja asiakkaan sukunimisarakkeet. Näiden sarakkeiden arvojen ei pitäisi vaikuttaa asiakkaan päätökseen poistua pankista.
Asiakkaan pankkitilin sulkemisen tapahtuma määrittää kyseisen asiakkaan vaihtuvuuden. Tietojoukon Exited sarake viittaa asiakkaan hylkäämiseen. Koska näissä määritteissä ei ole juurikaan kontekstia, emme tarvitse tietojoukon taustatietoja. Haluamme ymmärtää, miten nämä määritteet vaikuttavat Exited tilaan.
Näistä 10 000 asiakkaalle vain 2037 asiakasta (noin 20%) lähti pankista. Luokan epätasapainosuhteen vuoksi suosittelemme synteettisten tietojen luontia. Hämmennysmatriisin tarkkuudella ei ehkä ole merkitystä epätasapainoisen luokituksen kannalta. Haluamme ehkä mitata tarkkuutta käyttämällä AUPRC(AUPRC) -Precision-Recall käyrän alla olevaa aluetta.
- Tässä taulukossa on esiversio
churn.csvtiedoista:
| Asiakastunnus | Sukunimi | CreditScore | Maantiede | Sukupuoli | Ikä | Virassaoloaika | Vaaka | NumOfProducts | HasCrCard | IsActiveMember | Arvioituväliarvo | Lähtenyt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15634602 | Hargrave | 619 | Ranska | Naispuolinen | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 |
| 15647311 | Kukkula | 608 | Espanja | Naispuolinen | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
Lataa tietojoukko ja lataa se Lakehouse-palveluun
Määritä nämä parametrit niin, että voit käyttää tätä muistikirjaa eri tietojoukkojen kanssa:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only SAMPLE_ROWS of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/churn" # Folder with data files
DATA_FILE = "churn.csv" # Data file name
Tämä koodi lataa tietojoukosta julkisesti saatavilla olevan version ja tallentaa sitten kyseisen tietojoukon Fabric lakehouse -järjestelmään:
Tärkeä
Lisää lakehouse- muistikirjaan ennen sen suorittamista. Jos näin ei tehdä, tuloksena on virhe.
import os, requests
if not IS_CUSTOM_DATA:
# With an Azure Synapse Analytics blob, this can be done in one line
# Download demo data files into the lakehouse if they don't exist
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/bankcustomerchurn"
file_list = ["churn.csv"]
download_path = "/lakehouse/default/Files/churn/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Aloita muistikirjan suorittamiseen tarvittava aika:
# Record the notebook running time
import time
ts = time.time()
Raakadata Lakehousesta
Tämä koodi lukee raakatiedot Lakehousen Files -osasta ja lisää sarakkeita eri päivämääräosiin. Osioituja delta-taulukkoja luodaan näitä tietoja hyödyntäen.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Pandas DataFrame -kehyksen luominen tietojoukosta
Tämä koodi muuntaa Spark DataFramen pandas DataFrame -kehykseksi, mikä helpottaa käsittelyä ja visualisointia:
df = df.toPandas()
Vaihe 3: Suorita valmisteleva tietoanalyysi
Raakatietojen näyttäminen
Tutustu raakatietoihin displayavulla, laske joitakin perustilastoja ja näytä kaavionäkymät. Sinun on ensin tuotava datavisualisointiin tarvittavat kirjastot, esimerkiksi merisyntyisiä. Seaborn on Python-tietojen visualisoinnin kirjasto, ja se tarjoaa korkean tason käyttöliittymän visualisointien luomiseen tietokehyksiin ja matriiseihin.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Tietojen ensimmäisen puhdistuksen suorittaminen Data Wrangler -funktion avulla
Käynnistä Data Wrangler suoraan muistikirjasta pandas-tietokehysten tutkimista ja muuntamista varten. Valitse avattava Data Wrangler -valikko vaakasuuntaisesta työkalurivistä ja selaa muokkausta varten käytettävissä olevia aktivoituja pandas DataFrame -kehyksiä. Valitse DataFrame, jonka haluat avata Data Wranglerissa.
Muistiinpano
Data Wrangleria ei voi avata, kun muistikirjan ydin on varattu. Solun suorituksen on oltava valmis, ennen kuin käynnistät Data Wranglerin. Lisätietoja Data Wrangler.

Kun Data Wrangler käynnistyy, tietopaneelista luodaan kuvaava yleiskatsaus seuraavissa kuvissa esitetyllä tavalla. Yleiskatsaus sisältää tietoja DataFramen dimensiosta, puuttuvista arvoista jne. Data Wrangler -funktion avulla voit luoda komentosarjan, jolla voit pudottaa rivit, joilla on puuttuvat arvot, rivien kaksoiskappaleet ja sarakkeet, joilla on tietyt nimet. Sen jälkeen voit kopioida komentosarjan soluun. Seuraavassa solussa näytetään kopioitu komentosarja.


def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
Määritteiden määrittäminen
Tämä koodi määrittää luokittaiset, numeeriset ja kohdemääritteet:
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
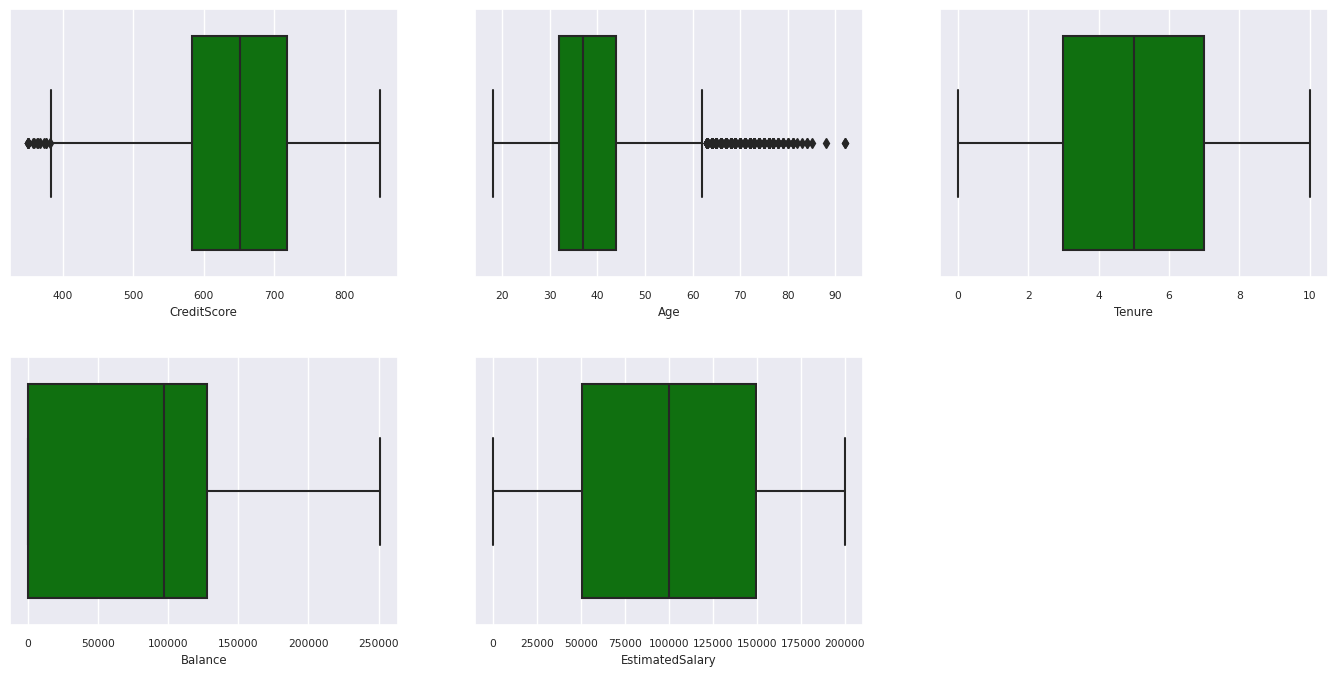
Näytä viisinumeroinen yhteenveto
Näytä viisinumeroinen yhteenveto ruutukaavioiden avulla
- vähimmäispisteet
- ensimmäinen louhos
- mediaani
- kolmas louhos
- enimmäispisteet
numeerisille määritteille.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
# fig.suptitle('visualize and compare the distribution and central tendency of numerical attributes', color = 'k', fontsize = 12)
fig.delaxes(axes[1,2])
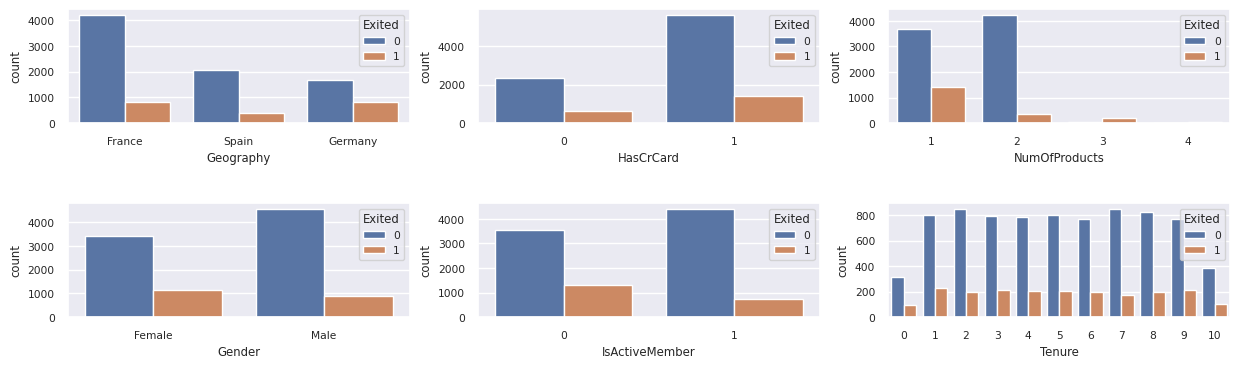
Näytä poistuneiden ja poistumattomien asiakkaiden jakauma
Näytä poistuneiden ja poistumattomien asiakkaiden jakauma luokittaisten määritteiden välillä:
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
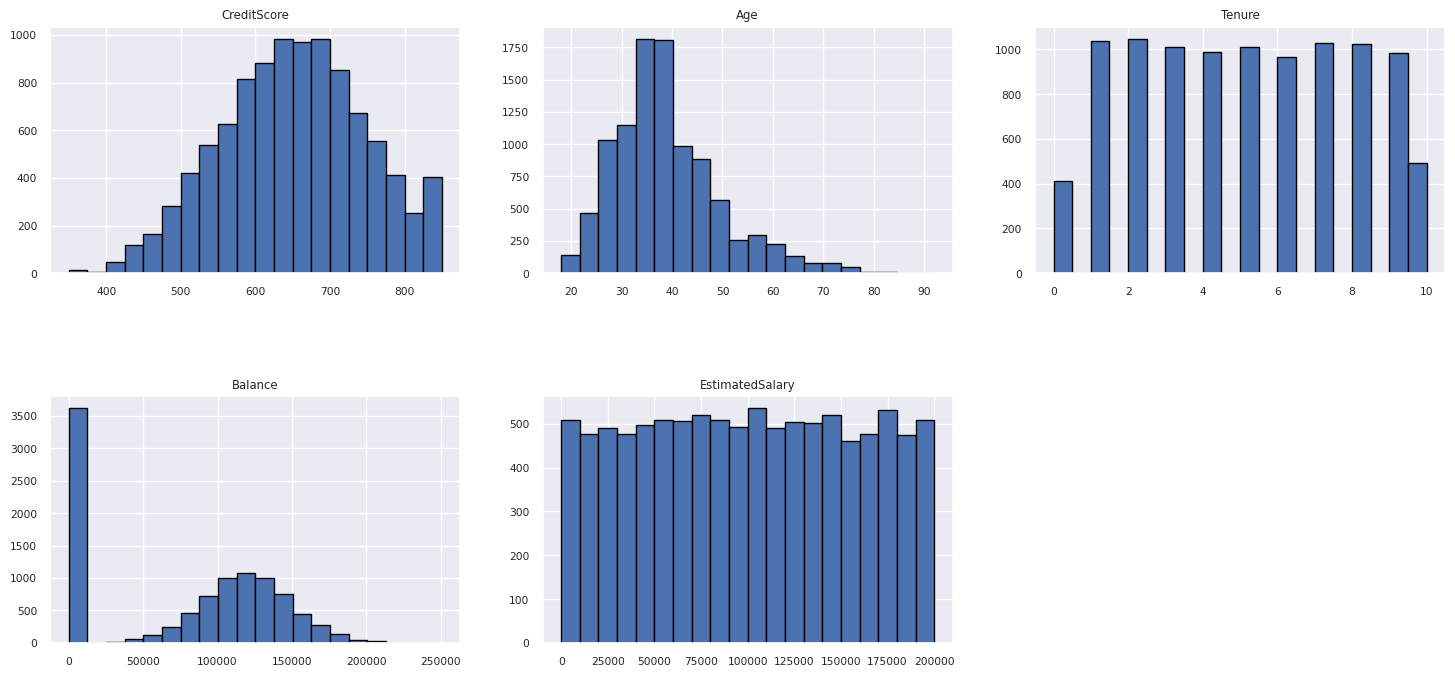
Numeeristen määritteiden jakauman näyttäminen
Näytä numeeristen määritteiden jakauma histogrammin avulla:
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
# fig = fig.suptitle('distribution of numerical attributes', color = 'r' ,fontsize = 14)
plt.show()
Ominaisuuksien suunnittelun suorittaminen
Tämä ominaisuustekniikka luo uusia määritteitä nykyisten määritteiden perusteella:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Käytä Data Wrangler -funktiota yhden kuuman koodauksen suorittamiseen
Samat vaiheet data Wranglerin käynnistämiseen, kuten aiemmin mainittiin, käytä Data Wrangleria yhden kuuman koodauksen suorittamiseen. Tässä solussa näytetään kopioitu luotu komentosarja yhden kuuman koodauksen koodausta varten:


df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
Luo Delta-taulukko Power BI -raportin luomiseksi
table_name = "df_clean"
# Create a PySpark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Yhteenveto valmistelevan tietoanalyysin havainnoista
- Suurin osa asiakkaista on ranskasta. Espanjan vaihtuvuusaste on alhaisin Verrattuna Ranskaan ja Saksaan.
- Useimmilla asiakkailla on luottokortit
- Jotkut asiakkaat ovat sekä yli 60-vuotiaita että heillä on luottopisteet alle 400. Niitä ei kuitenkaan voida pitää poikkeavina arvoina.
- Vain harvoilla asiakkailla on enemmän kuin kaksi pankkituote
- Passiivisten asiakkaiden vaihtuvuusaste on suurempi
- Sukupuoli- ja virkavuosilla ei ole juurikaan vaikutusta asiakkaan päätökseen sulkea pankkitili
Vaihe 4: Mallin harjoittamisen ja seurannan suorittaminen
Kun tiedot ovat paikoillaan, voit nyt määrittää mallin. Käytä satunnaiset metsä- ja LightGBM-malleja tässä muistikirjassa.
Käytä scikit-learn- ja LightGBM-kirjastoja mallien käyttöönottoon muutamalla koodirivillä. Käytä lisäksi MLfLow'ta ja Fabric Autologgingia kokeilujen seuraamiseen.
Tämä koodimalli lataa delta-taulukon Lakehousesta. Voit käyttää muita delta-taulukoita, jotka itse käyttävät lähdettä Lakehouse.
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Luo kokeilu mallien seurantaa ja kirjaamista varten MLflow:n avulla
Tässä osiossa näytetään, miten voit luoda kokeiluja, ja se määrittää mallin ja harjoittamisen parametrit sekä pisteytyksen mittarit. Lisäksi siinä kerrotaan, miten malleja koulutetaan, ne kirjataan lokiin ja miten harjoitetut mallit tallennetaan myöhempää käyttöä varten.
import mlflow
# Set up the experiment name
EXPERIMENT_NAME = "sample-bank-churn-experiment" # MLflow experiment name
Automaattinen kirjaaminen tallentaa automaattisesti sekä syöteparametriarvot että koneoppimismallin tulosarvot, kun kyseistä mallia harjoitetaan. Nämä tiedot kirjataan sitten työtilaan, jossa MLflow-ohjelmointirajapinnat tai niitä vastaavat kokeilut työtilassasi voivat käyttää ja visualisoida niitä.
Kun olet valmis, kokeilusi muistuttaa tätä kuvaa:

Kaikki kokeilut niiden nimillä kirjataan, ja voit seurata niiden parametreja ja suorituskykymittareita. Jos haluat lisätietoja automaattisesta lokista, katso automaattinen lokiloggaus Microsoft Fabric.
Määritä kokeilu- ja automaattianalyysimääritykset
mlflow.set_experiment(EXPERIMENT_NAME) # Use a date stamp to append to the experiment
mlflow.autolog(exclusive=False)
Tuo scikit-learn ja LightGBM
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Koulutuksen ja testitietojoukkojen valmistelu
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Train/test separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
Sovella SMOTE:a koulutustietoihin
Epätasapainoinen luokitus on ongelma, koska sillä on liian vähän esimerkkejä vähemmistöluokasta, jotta malli oppisi tehokkaasti päätösrajan. Tämän käsittelemiseksi synteettisvähemmistön ylimyyntitekniikka (SMOTE) on yleisin tekniikka, jolla syntetisoidaan uusia näytteitä vähemmistöluokalle. Käytä SMOTE:a vaiheessa 1 asentamasi imblearn kirjaston avulla.
Sovella SMOTE:a vain koulutustietojoukkoon. Testitietojoukko on jätettävä alkuperäiseen epätasapainoisen jakautumisensa, jotta alkuperäiset tiedot saavat kelvollisen arvion mallin suorituskyvystä. Tämä koe edustaa tuotantotilannetta.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Katso lisätietoja artikkelista SMOTE ja Satunnaisesta yliotannasta SMOTEen ja ADASYN. Epätasapainoinen Learn-sivusto isännöi näitä resursseja.
Harjoita mallia
Käytä Random Forestia mallin harjoittamiseen, enimmäissyvyytenä neljä ja neljä ominaisuutta:
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_test, y_test)
y_pred = rfc1_sm.predict(X_test)
cr_rfc1_sm = classification_report(y_test, y_pred)
cm_rfc1_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
Käytä Random Forestia mallin harjoittamiseen, enimmäissyvyys on kahdeksan, ja siinä on kuusi ominaisuutta:
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_test, y_test)
y_pred = rfc2_sm.predict(X_test)
cr_rfc2_sm = classification_report(y_test, y_pred)
cm_rfc2_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
Harjoita mallia LightGBM:llä:
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cr_lgbm_sm = classification_report(y_test, y_pred)
cm_lgbm_sm = confusion_matrix(y_test, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Tarkastele kokeiluarteefaktia mallin suorituskyvyn seuraamiseksi
Kokeilusuoritukset tallennetaan automaattisesti kokeiluarteefaktiin. Löydät kyseisen artefaktin työtilasta. Artefaktin nimi perustuu kokeilun määrittämiseen käytettyun nimeen. Kaikki koulutetut mallit, niiden suoritukset, suorituskykymittarit ja malliparametrit kirjataan kokeilusivulle.
Voit tarkastella kokeitasi:
- Valitse vasemmassa paneelissa työtilasi.
- Etsi ja valitse kokeilun nimi, tässä tapauksessa sample-bank-churn-experiment -.
Vaihe 5: Lopullisen koneoppimismallin arvioiminen ja tallentaminen
Avaa tallennettu kokeilu työtilasta, jotta voit valita ja tallentaa parhaan mallin:
# Define run_uri to fetch the model
# MLflow client: mlflow.model.url, list model
load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model")
load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model")
load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model")
Arvioi tallennettujen mallien suorituskykyä testitietojoukossa
ypred_rfc1_sm = load_model_rfc1_sm.predict(X_test) # Random forest with maximum depth of 4 and 4 features
ypred_rfc2_sm = load_model_rfc2_sm.predict(X_test) # Random forest with maximum depth of 8 and 6 features
ypred_lgbm1_sm = load_model_lgbm1_sm.predict(X_test) # LightGBM
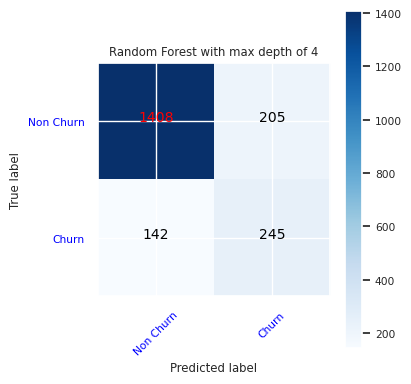
Näytä true/false-positiiviset/negatiiviset käyttämällä sekaannusmatriisia
Luokituksen tarkkuuden arvioimiseksi luo komentosarja, joka piirtää sekaannusmatriisin. Voit myös piirtää sekaannusmatriisin SynapseML-työkaluilla, kuten Petosten havaitsemisen malli -.
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
Luo sekaannusmatriisi satunnaiselle metsäluokittelulle, jonka enimmäissyvyys on neljä, ja neljä ominaisuutta:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
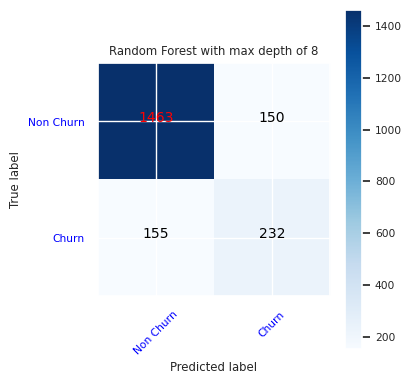
Luo sekaannusmatriisi satunnaiselle metsäluokittelulle, jonka enimmäissyvyys on kahdeksan, ja jossa on kuusi ominaisuutta:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc2_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
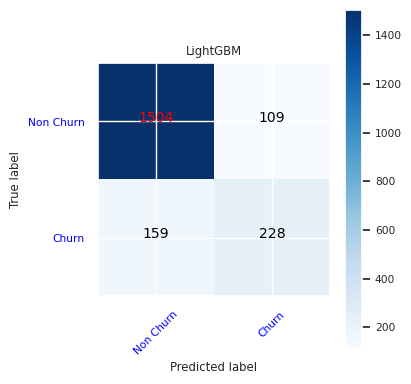
Luo sekaannusmatriisi LightGBM:lle:
cfm = confusion_matrix(y_test, y_pred=ypred_lgbm1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()
Tallenna Power BI:n tulokset
Tallenna delta-kehys Lakehouse-tallennustilaan, jotta mallin ennustetulokset siirretään Power BI -visualisointiin.
df_pred = X_test.copy()
df_pred['y_test'] = y_test
df_pred['ypred_rfc1_sm'] = ypred_rfc1_sm
df_pred['ypred_rfc2_sm'] =ypred_rfc2_sm
df_pred['ypred_lgbm1_sm'] = ypred_lgbm1_sm
table_name = "df_pred_results"
sparkDF=spark.createDataFrame(df_pred)
sparkDF.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Vaihe 6: Visualisointien käyttäminen Power BI:ssä
Käytä tallennettua taulukkoa Power BI:ssä:
- Valitse vasemmalta OneLake.
- Valitse lakehouse, jonka lisäsit tähän muistikirjaan.
- Valitse Avaa tämä Lakehouse -osassa Avaa.
- Valitse valintanauhassa Uusi semanttinen malli -. Valitse
df_pred_resultsja valitse sitten Vahvista luodaksesi uuden ennusteisiin linkitetyn Power BI -semanttisen mallin. - Avaa uusi semanttinen malli. Löydät sen OneLakesta.
- Valitse Luo uusi raportti -kohta tiedostossa semanttisten mallien sivun yläosassa olevista työkaluista, jolloin Power BI -raportin luontisivu avautuu.
Seuraavassa näyttökuvassa on esimerkkejä visualisoinneista. Tietopaneelissa näkyvät taulukosta valittavat deltataulukot ja sarakkeet. Kun olet valinnut sopivan luokka-akselin (x) ja arvon (y), voit valita suodattimet ja funktiot , kuten taulukon sarakkeen summan tai keskiarvon.
Muistiinpano
Tässä näyttökuvassa kuvitettu esimerkki kuvaa tallennettujen ennustetulosten analyysia Power BI:ssä:

Asiakaskohtaista käyttötapausta varten käyttäjä saattaa kuitenkin tarvita perusteellisemman joukon vaatimuksia luodakseen subjekteja asiantuntemuksen perusteella sekä sen, mitä yritys- ja liiketoiminta-analytiikkatiimi ja yritys ovat standardoineet mittareina.
Power BI -raportin mukaan asiakkailla, jotka käyttävät yli kahta pankkituotetta, on korkeampi vaihtuvuusprosentti. Vain harvoilla asiakkailla oli kuitenkin enemmän kuin kaksi tuotetta. (Katso vasemman alapaneelin kaavio.) Pankin pitäisi kerätä enemmän tietoja, mutta sen pitäisi myös tutkia muita ominaisuuksia, jotka korreloivat enemmän tuotteita.
Saksan pankkiasiakkaiden vaihtuvuusaste on suurempi kuin Ranskassa ja Espanjassa. (Katso piirtoa oikean alareunan paneelista). Raportin tulosten perusteella tutkimus niistä tekijöistä, jotka kannustivat asiakkaita lähtemään, voisi auttaa.
Keski-ikäisiä asiakkaita on enemmän (25–45-vuotiaita). 45–60-kymppisillä asiakkailla on tapana poistua enemmän.
Lopuksi asiakkaat, joilla on pienemmät luottopisteet, todennäköisesti jättäisivät pankin muille rahoituslaitoksille. Pankin pitäisi tutkia tapoja kannustaa asiakkaita, joilla on pienemmät luottopistemäärät ja tilisaldot, pysymään pankissa.
# Determine the entire runtime
print(f"Full run cost {int(time.time() - ts)} seconds.")
Aiheeseen liittyvä sisältö
- microsoft Fabric:n
-koneoppimismalli - Koneoppimismallien harjoittaminen
- Koneoppimisen kokeiluja Microsoft Fabric