SQL-tietokannan määrittäminen kopiointitoiminnossa (esikatselu)
Tässä artikkelissa kerrotaan, miten voit kopioida tietoja SQL-tietokannasta ja SQL-tietokantaan tietoputken kopiointitoiminnon avulla.
Tuettu määritys
Jos haluat määrittää kunkin välilehden kopiointitoiminnon kohdassa, siirry seuraaviin osioihin.
Yleiset
Katso Yleiset -asetukset -ohjeet, jotta voit määrittää Yleiset -asetukset -välilehden.
Lähde
Seuraavia ominaisuuksia tuetaan SQL-tietokannassa kopiointiaktiviteetin Source -välilehdellä.

Seuraavat ominaisuudet pakollisia:
Connection: Valitse aiemmin luotu SQL -tietokanta, joka viittaa tämän artikkelin.
Käytä kyselyä: Voit valita Table, Query, tai Stored procedure. Seuraavassa luettelossa kuvataan jokaisen asetuksen määritykset:
Table: Määritä SQL-tietokannan nimi tietojen lukemista varten. Valitse avattavasta luettelosta olemassa oleva taulukko tai valitse Anna manuaalisesti, jos haluat antaa rakenteen ja taulukon nimen.
Query: Määritä mukautettu SQL-kysely tietojen lukemista varten. Esimerkki tästä on
select * from MyTable. Voit muokata koodieditorissa valitsemalla kynäkuvakkeen.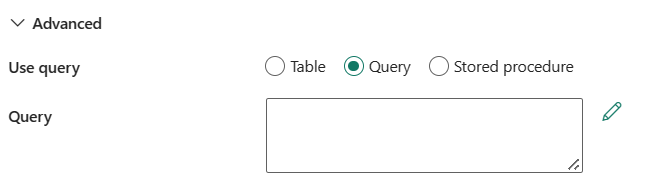
Tallennettu toimintosarja -: Valitse tallennettu toimintosarja avattavasta luettelosta.

Lisäasetukset-voit määrittää seuraavat kentät:
Kyselyn aikakatkaisu (minuuttia) -: Määritä kyselyn komennon suorittamisen aikakatkaisu, oletusarvo on 120 minuuttia. Jos tälle ominaisuudelle on määritetty parametri, sallitut arvot ovat aikaväli, kuten "02:00:00" (120 minuuttia).

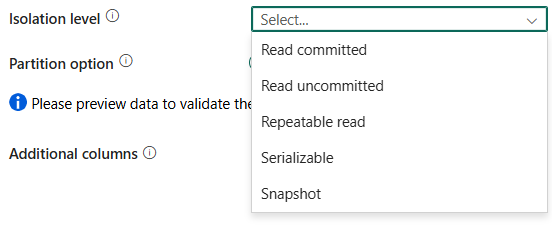
eristystason: Määrittää tapahtumalukon toiminnan SQL-lähteelle. Sallitut arvot ovat: Read committed, Read uncommitted, Repeatable Read, Serializable, tai Snapshot. Katso lisätietoja artikkelista IsolationLevel Enum.
Osio-vaihtoehdon: Määritä tietojen osiointiasetukset, joita käytetään tietojen lataamiseen SQL-tietokannasta. Sallitut arvot ovat: Ei mitään (oletus), taulukonfyysiset osiot ja Dynaaminen alue -. Kun osion asetus on käytössä (eli ei Ei mitään), rinnakkaisuuden astetta TIETOJEN samanaikaiseen lataamiseen SQL-tietokannasta hallitaan rinnakkaisuuden asteen Kopioi toimintoasetukset -välilehdessä.
Ei mitään: Valitse tämä asetus, jos haluat olla käyttämättä osiota.
taulukonfyysiset osiot: Kun käytät fyysistä osiota, osion sarake ja mekanismi määritetään automaattisesti fyysisen taulukkomäärityksen perusteella.
Dynaaminen alue -: Kun kyselyä käytetään rinnakkain käytössä, tarvitaan alueen osion parametri(
?DfDynamicRangePartitionCondition). Mallikysely:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.Osio-sarakkeen nimi: Määritä lähdesarakkeen nimi kokonaisluku tai päivämäärä/päivämäärä/päivämäärä/aika tyyppi (
int,smallint,bigint,date,smalldatetime,datetime,datetime2taidatetimeoffset), jota alueen osioiminen käyttää rinnakkaiselle kopiolle. Jos tätä ei määritetä, indeksi tai taulukon perusavain tunnistetaan automaattisesti ja sitä käytetään osiosarakkeena.Jos käytät kyselyä lähdetietojen noutamiseen, koukku
?DfDynamicRangePartitionConditionWHERE-lauseessa. Katso esimerkiksi kohtaa Rinnakkaisen kopiointi SQL-tietokannasta.Osion yläraja: Määritä osiosarakkeen enimmäisarvo osioalueen jakamiselle. Tämän arvon avulla päätetään osion harppaus, ei taulukon rivien suodattamisessa. Kaikki taulukon tai kyselyn tuloksen rivit ositetaan ja kopioidaan. Jos tätä ei määritetä, kopioi toiminnan automaattinen tunnista arvo. Katso esimerkiksi kohtaa Rinnakkaisen kopiointi SQL-tietokannasta.
Osion alaraja -: Määritä osion sarakkeen vähimmäisarvo osioalueen jakamiselle. Tämän arvon avulla päätetään osion harppaus, ei taulukon rivien suodattamisessa. Kaikki taulukon tai kyselyn tuloksen rivit ositetaan ja kopioidaan. Jos tätä ei määritetä, kopioi toiminnan automaattinen tunnista arvo. Katso esimerkiksi kohtaa Rinnakkaisen kopiointi SQL-tietokannasta.
Lisäsarakkeet-: Lisää tietosarakkeita lähdetiedostojen suhteellisen polun tai staattisen arvon tallentamiseksi. Lauseketta tuetaan jälkimmäisessä. Lisätietoja on kohdassa Lisää sarakkeita kopioinnin.


Kohde
Seuraavia ominaisuuksia tuetaan SQL-tietokannassa kopiointiaktiviteetin Destination -välilehdellä.

Seuraavat ominaisuudet pakollisia:
Connection: Valitse aiemmin luotu SQL -tietokanta, joka viittaa tämän artikkelin.
Taulukko -vaihtoehto: Valitse Käytä olemassa olevia tai Automaattinen luonti -taulukon.
Jos valitset Käytä olemassa olevia:
- Taulukon: Määritä SQL-tietokannan nimi tietojen kirjoittamista varten. Valitse avattavasta luettelosta olemassa oleva taulukko tai valitse Anna manuaalisesti, jos haluat antaa rakenteen ja taulukon nimen.
Jos valitset Luo taulukko automaattisesti -:
- Taulukon: Se luo taulukon automaattisesti lähderakenteeseen, jota ei tueta, kun tallennettua toimintosarjaa käytetään kirjoitustoimintona.
Lisäasetukset-voit määrittää seuraavat kentät:
Kirjoitustoiminta-: Määrittää kirjoitustoiminnon, kun lähde on tiedostopohjaisen tietosäilön tiedostot. Voit valita Lisää, Upsert tai Tallennettu toimintosarja -.

Lisää: Valitse tämä vaihtoehto, jos lähdetiedoissasi on lisäyksiä.
Upsert: Valitse tämä vaihtoehto, jos lähdetiedoissasi on sekä lisäyksiä että päivityksiä.
Käytä TempDB-: Määritä, käytetäänkö yleistä tilapäistä taulukkoa vai fyysistä taulukkoa päivityslisäyksen väliaikaisena taulukkona. Oletusarvoisesti palvelu käyttää väliaikaista taulukkona yleistä väliaikaista taulukkoa, ja tämä valintaruutu on valittuna.
Jos kirjoitat suuren määrän tietoja SQL-tietokantaan, poista valinta tästä ja määritä rakenteen nimi, jossa Data Factory luo valmistelutaulukon yläpuolisten tietojen lataamista ja automaattinen siistimistä varten suorittamisen jälkeen. Varmista, että käyttäjällä on tietokannan taulukon käyttöoikeus ja rakenteen muuttamisoikeudet. Jos tätä ei määritetä, yleistä tilapäistaulukkoa käytetään valmisteluna.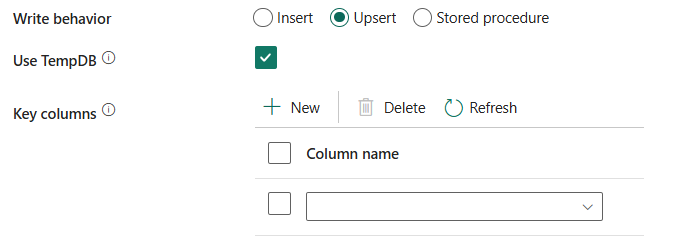
Valitse käyttäjän tietokantarakenne: Kun Käytä TempDB- ei ole valittuna, määritä rakenteen nimi, jonka alle Data Factory luo valmistelutaulukon tietojen lataamiseksi yläpuolista säilöön ja siistii ne automaattisesti valmistumisen jälkeen. Varmista, että sinulla on taulukon luontioikeus tietokantaan ja rakenteen muuttamisoikeudet.
Muistiinpano
Sinulla on oltava oikeudet taulukoiden luomiseen ja poistamiseen. Oletusarvoisesti välivaiheen taulukko jakaa saman rakenteen kuin kohdetaulukko.
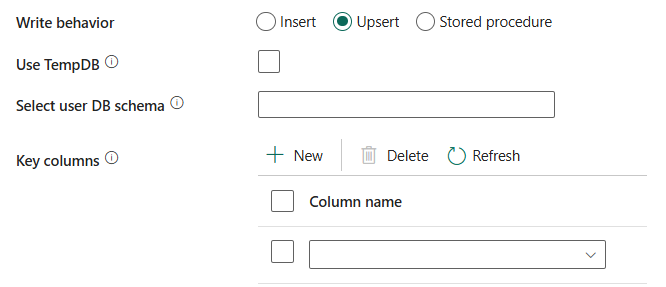
Avain-sarakkeet: Valitse, mitä saraketta käytetään sen selvittämiseen, vastaako lähteen rivi kohteen riviä.
Tallennettu toimintosarja -nimi: Valitse tallennettu toimintosarja avattavasta luettelosta.
Joukkolisää taulukkolukko: Valitse Kyllä tai Ei. Tämän asetuksen avulla voit parantaa kopioinnin suorituskykyä taulukon joukkolisäystoiminnon aikana ilman indeksiä useista asiakasohjelmista. Jos haluat lisätietoja, siirry kohtaan JOUKKOLISÄYS (Transact-SQL)
Esikopioi komentosarja: Määritä komentosarja suoritettavalle kopiointitoiminnolle ennen tietojen kirjoittamista kohdetaulukkoon jokaisen suorituksen aikana. Tämän ominaisuuden avulla voit puhdistaa esilatauksen tiedot.
Erän aikakatkaisun: Määritä erälisäystoiminnon odotusaika, joka on valmis ennen aikakatkaisua. Sallittu arvo on aikaväli. Oletusarvo on 00.30.00 (30 minuuttia).
Eräkoon kirjoittaminen: Määritä SQL-taulukkoon eränä lisättavien rivien määrä. Sallittu arvo on kokonaisluku (rivien määrä). Oletusarvoisesti palvelu määrittää dynaamisesti asianmukaisen erän koon rivin koon perusteella.
Samanaikaisten yhteyksien enimmäismäärä: Määritä tietosäilöön aktiviteetin suorittamisen aikana määritettyjen samanaikaisten yhteyksien yläraja. Määritä arvo vain, jos haluat rajoittaa samanaikaisia yhteyksiä.


Kuvaus
Jos Mapping -välilehden määrityksissä ei käytetä SQL-tietokantaa, jonka kohteena on automaattinen luontitaulukko, siirry kohtaan Mapping.
Jos käytät SQL-tietokantaa ja kohdesijaintina on automaattinen luontitaulukko, lukuun ottamatta Mappingmääritystä, voit muokata kohdesarakkeiden tyyppiä. Kun olet valinnut Tuo rakenteet, voit määrittää saraketyypin kohdesijainnissa.
Esimerkiksi id - lähdesarakkeen tyyppi on int, ja voit muuttaa sen liukulukutyypiksi, kun yhdistät kohdesarakkeeseen.

Asetukset
asetusten välilehden määrityksessä siirry kohtaan Muiden asetusten määrittäminen Asetukset-välilehdessä.
Rinnakkainen kopiointi SQL-tietokannasta
Kopiointitoiminnon SQL-tietokantayhdistin tarjoaa tietojen osioinnin tietojen kopioimiseksi rinnakkain. Löydät tietojen osiointiasetukset kopiointiaktiviteetin Source -välilehdestä.
Kun otat ositetun kopion käyttöön, kopiointitoiminto suorittaa rinnakkaisia kyselyitä SQL-tietokantalähteeseen tietojen lataamiseksi osioiden mukaan. Rinnakkaista tutkintoa hallitaan rinnakkaisuuden asteen Kopioi toiminta-asetukset -välilehdellä. Jos esimerkiksi määrität rinnakkaisuuden asteen neljään, palvelu luo ja suorittaa samanaikaisesti neljä kyselyä määritetyn osiovaihtoehdon ja -asetusten perusteella, ja kukin kysely noutaa osan tiedoista SQL-tietokannasta.
Suosittelemme, että otat käyttöön rinnakkaisen kopioinnin tietojen osioinnin avulla etenkin silloin, kun lataat suuren määrän tietoja SQL-tietokannasta. Seuraavassa on ehdotettu määrityksiä eri skenaarioita varten. Kopioitaessa tietoja tiedostopohjaiseen tietosäilöön on suositeltavaa kirjoittaa kansioon useana tiedostona (määritä vain kansion nimi), jolloin suorituskyky on parempi kuin yksittäiseen tiedostoon kirjoittaminen.
Parhaat käytännöt tietojen lataamiseen osioasetuksen kanssa:
- Valitse osiosarakkeeksi erottuva sarake (kuten perusavain tai yksilöivä avain), jotta vältät tietojen vinoutumisen.
- Jos taulukossa on sisäinen osio, käytä osioasetusta taulukon fyysisiä osioita suorituskyvyn parantamiseksi.
Esimerkkikysely fyysisen osion tarkistamista varten
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Jos taulukossa on fyysinen osio, näet "HasPartition"-kohdan arvona "kyllä" seuraavan mukaisesti.

Taulukon yhteenveto
Seuraavat taulukot sisältävät lisätietoja SQL-tietokannan kopiointitoiminnosta.
Lähde
| Nimi | Kuvaus | Arvo | Pakollinen | JSON-komentosarjaominaisuus |
|---|---|---|---|---|
| Connection | Yhteys lähdetietosäilöön. | yhteyden <> | Kyllä | yhteys |
| Kyselyn käyttäminen | Näin tietoja luetaan. Käytä -taulukon tietojen lukemiseen määritetystä taulukosta tai käytä Query tietojen lukemiseen SQL-kyselyiden avulla. | • Taulukon • Query • Tallennettu toimintosarja - |
Kyllä | / |
| rakenteen nimi | Rakenteen nimi. | < rakenteen nimi > | Ei | skeema |
| taulukon nimen | Taulukon nimi. | < taulukon nimen > | Ei | pöytä |
| Query | Määritä mukautettu SQL-kysely tietojen lukemista varten. Esimerkki: SELECT * FROM MyTable. |
SQL< kyselyiden > | Ei | sqlReaderQuery |
| Tallennettu toimintosarjan nimi - | Tallennetun toimintosarjan nimi. | < tallennettu toimintosarjasi nimi > | Ei | sqlReaderStoredProcedureName |
| Kyselyn aikakatkaisu (minuuttia) - | Kyselyn komennon suorituksen aikakatkaisu, oletusarvo on 120 minuuttia. Jos tälle ominaisuudelle on määritetty parametri, sallitut arvot ovat aikaväli, kuten "02:00:00" (120 minuuttia). | aikaväli | Ei | queryTimeout |
| eristystason | Määrittää SQL-lähteen tapahtumien lukitustoiminnon. | • Lue varattu • Lue sitomaton • Toistettavissa oleva luku • Sarjoitettava •Valokuva |
Ei | isolationLevel: • ReadCommitted • ReadUncommitted • Toistettavissa oleva • Sarjoitettava •Valokuva |
| Osio-asetuksen | Tietojen osioinnin asetukset, joita käytetään tietojen lataamiseen SQL-tietokannasta. | •Ei lainkaan • Taulukon fyysiset osiot • Dynaaminen alue |
Ei | partitionOption: • PhysicalPartitionsOfTable • DynamicRange |
| Osio-sarakkeen nimen | Lähdesarakkeen nimi kohteessa kokonaisluku tai päivämäärä/päivämäärä/päivämäärä/aika- tyyppi (int, smallint, bigint, date, smalldatetime, datetime, datetime2tai datetimeoffset), jota käytetään alueen jakamisessa rinnakkaista kopiota varten. Jos tätä ei määritetä, indeksi tai taulukon perusavain tunnistetaan automaattisesti ja sitä käytetään osiosarakkeena. Jos käytät kyselyä lähdetietojen noutamiseen, koukku ?DfDynamicRangePartitionCondition WHERE-lauseessa. |
osion sarakkeiden nimien <> | Ei | partitionColumnName |
| osion ylärajan | Osiosarakkeen enimmäisarvo osioalueen jakamisessa osiin. Tämän arvon avulla päätetään osion harppaus, ei taulukon rivien suodattamisessa. Kaikki taulukon tai kyselyn tuloksen rivit ositetaan ja kopioidaan. Jos tätä ei määritetä, kopioi toiminnan automaattinen tunnista arvo. | < osion ylärajan > | Ei | partitionUpperBound |
| osion alarajan | Osion sarakkeen vähimmäisarvo osioalueen jakamisessa. Tämän arvon avulla päätetään osion harppaus, ei taulukon rivien suodattamisessa. Kaikki taulukon tai kyselyn tuloksen rivit ositetaan ja kopioidaan. Jos tätä ei määritetä, kopioi toiminnan automaattinen tunnista arvo. | < osion alarajan > | Ei | partitionLowerBound |
| Lisää sarakkeita - | Lisää tietosarakkeita lähdetiedostojen suhteellisen polun tai staattisen arvon tallentamiseksi. Lauseketta tuetaan jälkimmäisessä. | •Nimi •Arvo |
Ei | additionalColumns: •Nimi •arvo |
Kohde
| Nimi | Kuvaus | Arvo | Pakollinen | JSON-komentosarjaominaisuus |
|---|---|---|---|---|
| Connection | Yhteytesi kohdetietosäilöön. | <yhteytesi > | Kyllä | yhteys |
| Taulukko -asetuksen | Kohdetietotaulukkosi. Valitse Käytä olemassa olevia tai Automaattinen luonti -taulukon. | • Käytä olemassa olevia • Automaattinen luontitaulukko |
Kyllä | skeema pöytä |
| kirjoitustoiminta | Määrittää kirjoituskäyttäytymisen, kun lähde on tiedostopohjaisen tietosäilön tiedostot. | •Insertti • Päivityslisäys • Tallennetut toimintosarjat |
Ei | writeBehavior: •insertti • päivityslisäys • sqlWriterStoredProcedureName |
| Joukkolisää taulukkolukko | Tämän asetuksen avulla voit parantaa kopioinnin suorituskykyä taulukon joukkolisäystoiminnon aikana ilman indeksiä useista asiakasohjelmista. | Kyllä tai Ei (oletus) | Ei | sqlWriterUseTableLock: tosi tai epätosi (oletus) |
| for Upsert | ||||
| TempDB- käyttäminen | Käytetäänkö yleistä tilapäistä taulukkoa vai fyysistä taulukkoa päivityslisäyksen väliaikaisena taulukkona. | valittuna (oletus) tai valitsemattomana | Ei | useTempDB: true (oletus) tai false |
| Avain-sarakkeet | Valitse, mitä saraketta käytetään määrittämään, vastaako lähteen rivi kohteen riviä. | avainsarakkeen <> | Ei | Avaimet |
| Tallennettu toimintosarjan nimi - | Tämä ominaisuus on sen tallennetun toimintosarjan nimi, joka lukee tietoja lähdetaulukosta. Viimeisen SQL-lausekkeen on oltava tallennetun toimintosarjan SELECT-lauseke. | tallennetun toimintosarjan nimen <> | Ei | sqlWriterStoredProcedureName |
| komentosarjan | Komentosarja, joka kopioi aktiviteetti suoritettavaksi ennen tietojen kirjoittamista kohdetaulukkoon kussakin suorittamisessa. Tämän ominaisuuden avulla voit puhdistaa esilatauksen tiedot. |
<komentosarjan> esikopio. (merkkijono) |
Ei | preCopyScript |
| eräaikakatkaisun | Erälisäystoiminnon odotusaika loppuun ennen aikakatkaisua. Sallittu arvo on aikaväli. Oletusarvo on 00.30.00 (30 minuuttia). | aikaväli | Ei | writeBatchTimeout |
| erän koon | SQL-taulukkoon erää kohden lisättavien rivien määrä. Oletusarvoisesti palvelu määrittää dynaamisesti asianmukaisen erän koon rivin koon perusteella. |
<rivien määrä> (kokonaisluku) |
Ei | writeBatchSize |
| samanaikaisten yhteyksien enimmäismäärä | Tietosäilöön aktiviteetin suorittamisen aikana määritettyjen samanaikaisten yhteyksien yläraja. Määritä arvo vain, jos haluat rajoittaa samanaikaisia yhteyksiä. |
<samanaikaisten yhteyksien> yläraja (kokonaisluku) |
Ei | maxConcurrentConnections |