Fabric Sparkin alkuperäinen suorittamismoduuli
Alkuperäinen suoritusmoduuli on uraauurtava parannus Apache Spark -työn suorituksiin Microsoft Fabricissa. Tämä vectorisoitu moduuli optimoi Spark-kyselyiden suorituskyvyn ja tehokkuuden suorittamalla ne suoraan Lakehouse-infrastruktuurissasi. Moduulin saumaton integrointi tarkoittaa, että se ei vaadi koodin muuttamista ja välttää toimittajan lukituksen. Se tukee Apache Spark -ohjelmointirajapintoja ja on yhteensopiva Runtime 1.3 :n (Apache Spark 3.5) kanssa, ja se toimii sekä Parquet- että Delta-muotojen kanssa. Riippumatta tietojen sijainnista OneLakessa tai jos käytät tietoja pikakuvakkeiden kautta, alkuperäinen suoritusmoduuli maksimoi tehokkuuden ja suorituskyvyn.
Alkuperäinen suoritusmoduuli nostaa merkittävästi kyselyn suorituskykyä ja minimoi toimintakustannukset. Se tarjoaa merkittävän nopeuden parannuksen ja saavuttaa jopa neljä kertaa nopeammin suorituskyvyn perinteiseen OSS:iin (avoimen lähdekoodin ohjelmistoon) Sparkiin verrattuna, kuten TPC-DS 1 Tt:n vertailuarvo vahvistaa. Moduuli on taitava hallitsemaan monenlaisia tietojenkäsittelyskenaarioita, aina tietojen käsittelyrutiineista, erätöistä ja ETL-tehtävistä (poimi, muuntaminen, lataaminen) monimutkaisiin tietojenkäsittelyanalytiikkaan ja reagoivia vuorovaikutteisia kyselyitä. Käyttäjät hyötyvät nopeutetusta käsittelyajoista, lisääntyneestä siirtomäärästä ja optimoidusta resurssien hyödyntämisestä.
Alkuperäinen suorittamismoduuli perustuu kahteen keskeiseen OSS-osaan: Veloxiin, Meta:n käyttöönottamaan C++-tietokannan kiihdytyskirjastoon ja Apache Gluteeniiniin (inkubointiin), keskikerrokseen, joka on vastuussa JVM-pohjaisten SQL-moduulien suorituksen purkamisesta Intelin käyttöön tuomiin alkuperäismoottoreihin.
Muistiinpano
Alkuperäinen suoritusmoduuli on tällä hetkellä julkisessa esikatselussa. Katso lisätietoja nykyisistä rajoituksista. Suosittelemme, että otat kuormillesi käyttöön alkuperäisen suoritusmoduulin ilman lisäkustannuksia. Voit hyötyä nopeammasta työn suorittamisesta maksamatta paremmin – käytännössä maksat vähemmän samasta työstä.
Milloin alkuperäistä suoritusmoduulia kannattaa käyttää?
Alkuperäinen suoritusmoduuli tarjoaa ratkaisun kyselyjen suorittamiseen suurissa tietojoukoissa. Se optimoi suorituskykyä käyttämällä pohjana olevien tietolähteiden alkuperäisiä ominaisuuksia ja minimoimalla yleensä tietojen siirtoon ja sarjoittamiseen liittyviä kuormituksia perinteisissä Spark-ympäristöissä. Moduuli tukee erilaisia operaattoreita ja tietotyyppejä, mukaan lukien kooste hajautusarvokooste, lähetys sisäkkäinen silmukkaliitos (BNLJ) ja tarkat aikaleimamuodot. Jotta voit hyödyntää moduulin ominaisuuksia täysin, harkitse sen optimaalisia käyttötapauksia:
- Moduuli on tehokas käsiteltäessä tietoja Parquet- ja Delta-muodoissa, jotka se voi käsitellä natiivisti ja tehokkaasti.
- Kyselyt, joihin liittyy monimutkaisia muunnoksia ja koosteita, hyötyvät merkittävästi moduulin sarakekäsittely- ja vektorisointitoiminnoista.
- Suorituskyvyn parannus on merkittävintä tilanteissa, joissa kyselyt eivät käynnistä varamekanismia välttämällä ominaisuuksia tai lausekkeita, joita ei tueta.
- Moduuli sopii hyvin kyselyihin, jotka vaativat laskennallisesti paljon en yksinkertaisesti tai I/O-sidottuna.
Lisätietoja alkuperäisen suoritusmoduulin tukemista operaattoreista ja funktioista on Apache Gluten -dokumentaatiossa.
Ota käyttöön alkuperäinen suoritusmoduuli
Kun haluat käyttää alkuperäisen suoritusmoduulin kaikkia ominaisuuksia esikatseluvaiheessa, tietyt määritykset ovat välttämättömiä. Seuraavissa menettelyissä näytetään, miten tämä ominaisuus aktivoidaan muistikirjoille, Spark-työmääritelmille ja kokonaisille ympäristöille.
Tärkeä
Alkuperäinen suoritusmoduuli tukee uusinta GA-suorituksenaikaista versiota, joka on Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2). Runtime 1.3:n alkuperäisen suorittamismoduulin julkaisun myötä edellisen version – Runtime 1.2 (Apache Spark 3.4, Delta Lake 2.4)) tuki on lopetettu. Kannustamme kaikkia asiakkaita päivittämään uusimpaan Runtime 1.3 -versioon. Jos käytät alkuperäistä suoritusmoduulia runtime 1.2:ssa, alkuperäinen kiihdytys poistetaan pian käytöstä.
Ota käyttöön ympäristön tasolla
Voit varmistaa yhtenäisen suorituskyvyn parantamisen ottamalla käyttöön alkuperäisen suoritusmoduulin kaikissa ympäristöösi liittyvissä työ- ja muistikirjoissa:
Siirry ympäristösi asetuksiin.
Siirry Spark-laskentaan.
Siirry Kiihdytys-välilehteen.
Valitse ruutu, jossa on otsikko Ota käyttöön alkuperäinen suoritusmoduuli.
Tallenna ja julkaise muutokset.
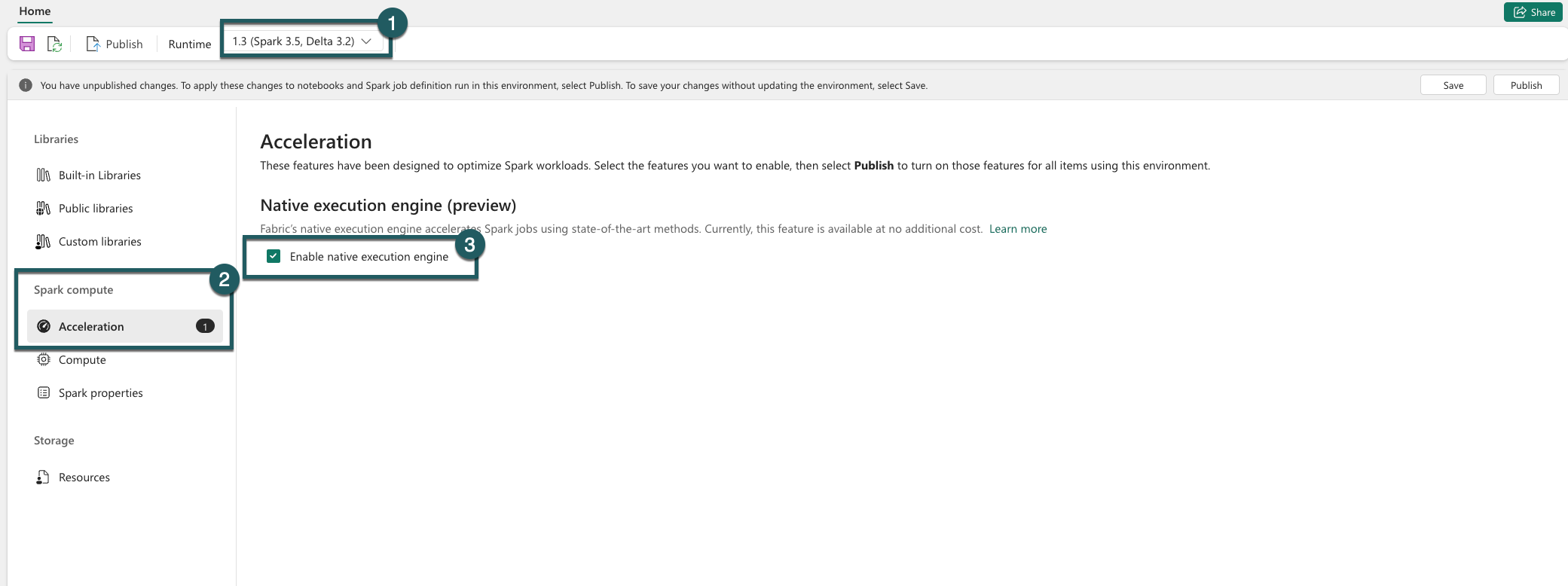

Kun tämä asetus on käytössä ympäristön tasolla, kaikki myöhemmät työt ja muistikirjat perivät asetuksen. Tämä periytyminen varmistaa, että ympäristössä luodut uudet istunnot tai resurssit hyötyvät automaattisesti parannetuista suoritustoiminnoista.
Tärkeä
Aiemmin alkuperäinen suoritusmoduuli otettiin käyttöön Spark-asetuksissa ympäristön määrityksissä. Viimeisimmän päivityksen (käyttöönotto on meneillään) myötä olemme yksinkertaistaneet tätä lisäämällä vaihtopainikkeen ympäristöasetusten Kiihdytys-välilehdelle. Ota alkuperäinen suoritusmoduuli uudelleen käyttöön uudella vaihtopainikkeella – jos haluat jatkaa alkuperäisen suorittamismoduulin käyttöä, siirry ympäristön asetusten Kiihdytys-välilehteen ja ota se käyttöön vaihtopainikkeen kautta. Käyttöliittymän uusi vaihtoasetus on nyt etusijalla aiempiin Spark-ominaisuuksien määrityksiin verrattuna. Jos olet aiemmin ottanut alkuperäisen suoritusmoduulin käyttöön Spark-asetusten kautta, se on poistettu käytöstä, kunnes se otetaan uudelleen käyttöön käyttöliittymän vaihtopainikkeella.
Ota käyttöön muistikirja tai Spark-työn määritys
Jotta alkuperäinen suoritusmoduuli voidaan ottaa käyttöön yksittäiselle muistikirjalle tai Spark-työmääritelmälle, sinun on sisällytettävä tarvittavat kokoonpanot suorituskomentosarjan alkuun:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
Lisää muistikirjojen osalta tarvittavat määrityskomennot ensimmäiseen soluun. Sisällytä Spark-työmääritelmien määritykset Spark-työmääritelmän etulinjaan. Alkuperäinen suoritusmoduuli on integroitu reaaliaikaisiin altaisiin, joten kun otat ominaisuuden käyttöön, se tulee voimaan heti ilman uuden istunnon aloittamista.
Tärkeä
Alkuperäisen suorittamismoduulin määritys on tehtävä ennen Spark-istunnon alkamista. Kun Spark-istunto alkaa, spark.shuffle.manager asetuksesta tulee muuttumaton, eikä sitä voi muuttaa. Varmista, että nämä määritykset on määritetty %%configure muistikirjojen lohkossa tai Spark-istunnon muodostimessa Spark-työmääritelmille.
Hallinta kyselytasolla
Mekanismit alkuperäisen suorittamismoduulin käyttöönottamiseksi vuokraajan, työtilan ja ympäristön tasoilla, jotka on integroitu saumattomasti käyttöliittymään, ovat aktiivisessa kehityksessä. Sillä välin voit poistaa alkuperäisen suoritusmoduulin käytöstä tietyille kyselyille, erityisesti jos niihin liittyy operaattoreita, joita ei tällä hetkellä tueta (katso rajoitukset). Jos haluat poistaa sen käytöstä, määritä Spark-määrityksen spark.native.enabled-arvoksi false tietylle kyselyn sisältävälle solulle.
%%sql
SET spark.native.enabled=FALSE;

Kun olet tehnyt kyselyn, jossa alkuperäinen suoritusmoduuli on poistettu käytöstä, sinun on otettava se uudelleen käyttöön myöhemmissä soluissa asettamalla spark.native.enabled-arvoksi true. Tämä vaihe on välttämätön, koska Spark suorittaa koodisoluja järjestyksessä.
%%sql
SET spark.native.enabled=TRUE;
Moduulin suorittamien toimintojen tunnistaminen
On olemassa useita menetelmiä, joilla voidaan selvittää, onko Apache Spark -työsi operaattori käsitelty käyttäen alkuperäistä suoritinmoduulia.
Spark-käyttöliittymä- ja Spark-historiapalvelin
Käytä Spark-käyttöliittymää tai Spark-historiapalvelinta, jotta voit paikantaa tarkistettavan kyselyn. Voit käyttää Spark-verkkokäyttöliittymää siirtymällä Spark-työn määritelmään ja suorittamalla sen. Valitse Juoksut -välilehdeltä ...Sovelluksen nimi - vierestä ja valitse Avaa Spark-verkkokäyttöliittymä -. Voit käyttää Spark-käyttöliittymää myös työtilan Valvonta -välilehdessä. Valitse muistikirja tai putki valvontasivulta suora linkki Spark UI - aktiivisille töille.

Etsi Spark-käyttöliittymän käyttöliittymässä näkyvästä kyselysuunnitelmasta solmun nimet, joiden päätteenä on Transformer, *NativeFileScan tai VeloxColumnarToRowExec. Liite ilmaisee, että alkuperäinen suoritusmoduuli suoritti toiminnon. Solmut voidaan esimerkiksi merkitä koosteiksi RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinExecTransformer tai BroadcastNestedLoopJoinExecTransformer.

DataFrame-kehyksen selitys
Vaihtoehtoisesti voit suorittaa komennon df.explain() muistikirjassasi suoritussuunnitelman tarkastelemiseksi. Etsi tulosteesta samat Transformer, *NativeFileScan tai VeloxColumnarToRowExec jälkiliitteet. Tämä menetelmä tarjoaa nopean tavan vahvistaa, käsitteleekö alkuperäinen suorittamismoduuli tiettyjä toimintoja.

Varamekanismi
Joissakin tapauksissa alkuperäinen suoritusmoduuli ei ehkä voi suorittaa kyselyä esimerkiksi tukemattomista ominaisuuksista johtuen. Näissä tapauksissa toiminto palataan perinteiseen Spark-moduuliin. Tämä automaattinen varamekanismi varmistaa, että työnkulkusi ei katkea.


Valvo moduulin suorittamia kyselyitä ja tietokehyksitä
Jos haluat ymmärtää paremmin, miten alkuperäistä suoritusmoduulia käytetään SQL-kyselyissä ja DataFrame-toiminnoissa, ja porautua vaihe- ja operaattoritasoille, katso tarkempia tietoja alkuperäisen moduulin suorittamisesta Spark-käyttöliittymä- ja Spark History Server -palvelimesta.
Alkuperäinen suoritusmoduulin välilehti
Voit siirtyä uuteen Gluteenin SQL / DataFrame -välilehteen, jotta voit tarkastella gluteenin koontitietojen ja kyselyn suorittamisen tietoja. Kyselyt-taulukko tarjoaa merkityksellisiä tietoja alkuperäisessä moduulissa suoritettavien solmujen määrästä ja niistä, jotka palaavat kunkin kyselyn JVM:ään.

Kyselyn suorittamisen kaavio
Voit myös valita kyselyn kuvauksen Apache Spark -kyselyn suoritussuunnitelman visualisoinnille. Suorituskaavio tarjoaa alkuperäiset suoritustiedot eri vaiheista ja niiden toiminnoista. Taustavärit erottavat suoritinmoduulit toisistaan: vihreä edustaa alkuperäistä suoritinmoduulia, kun taas vaaleansininen ilmaisee, että oletusarvoinen JVM-moduuli toimii.

Rajoitukset
Vaikka alkuperäinen suoritusmoduuli parantaa Apache Spark -töiden suorituskykyä, ota huomioon sen nykyiset rajoitukset.
- Joitakin Delta-kohtaisia toimintoja ei tueta (vaikka työstämme sitä aktiivisesti), kuten yhdistämistoimintoja, tarkistustarkistusten ja poistamisvektoreiden poistamista.
- Tietyt Sparkin ominaisuudet ja lausekkeet eivät ole yhteensopivia alkuperäisen suoritinmoduulin kanssa, kuten käyttäjän määrittämät funktiot (UDF) ja
array_containsfunktio, sekä Spark-jäsennetty suoratoisto. Näiden yhteensopimattomien toimintojen tai funktioiden käyttö osana tuotua kirjastoa hidastaa myös Spark-moduulia. - Skannauksia tallennusratkaisuista, jotka hyödyntävät yksityisiä päätepisteitä, ei tueta (vielä, kun työstämme sitä aktiivisesti).
- Moduuli ei tue ANSI-tilaa, joten se hakee. Kun ANSI-tila on käytössä, se palaa automaattisesti vanilla Sparkiin.
Kun käytät kyselyissä päivämääräsuodattimia, on tärkeää varmistaa, että vertailun molemmin puolin olevat tietotyypit täsmäävät suorituskykyongelmien välttämiseksi. Ristiriitaisen tietotyypin suorittaminen ei välttämättä tehosta kyselyä, ja se voi vaatia eksplisiittistä valamista. Varmista aina, että vertailun vasemmanpuoleisen (LHS) ja oikeanpuoleisen (RHS) tietotyypit ovat identtiset, koska ristiriitaisia tyyppejä ei aina muunteta automaattisesti. Jos tyypin ristiriita ei ole mahdollinen, käytä eksplisiittistä valua vastaamaan tietotyyppejä, kuten CAST(order_date AS DATE) = '2024-05-20'. Alkuperäinen suorittamismoduuli ei nopeutta kyselyjä, joiden tietotyypit ovat ristiriitaisia ja jotka edellyttävät valua. Tyypin yhdenmukaisuuden varmistaminen on siis ensiarvoisen tärkeää suorituskyvyn ylläpitämiseksi. Esimerkiksi sen sijaan, missä order_date = '2024-05-20' on order_date ja merkkijono on DATETIME, eksplisiittisesti muunnoksina DATEorder_date yhdenmukaisen DATE tietotyypin varmistamiseksi ja suorituskyvyn parantamiseksi.