Hive-metasäilön metatietojen siirtäminen Azure Synapse Analyticsista Fabriciin
HMS(Hive Metastore) -siirtymisen ensimmäisessä vaiheessa määritetään tietokannat, taulukot ja osiot, jotka haluat siirtää. Kaikkea ei tarvitse siirtää, vaan sitä ei tarvitse siirtää. Voit valita tietyt tietokannat. Kun tunnistat tietokantoja siirtämistä varten, varmista, että on hallittuja vai ulkoisia Spark-taulukoita.
HMS-huomioon otettavia seikkoja löytyy Azure Synapse Sparkin ja Fabricin välisistä eroista.
Muistiinpano
Vaihtoehtoisesti jos ADLS Gen2 sisältää Delta-taulukoita, voit luoda OneLake-pikakuvakkeen Delta-taulukkoon ADLS Gen2:ssa.
Edellytykset
- Jos sinulla ei vielä ole Fabric-työtilaa vuokraajassasi, luo Fabric-työtila .
- Jos sinulla ei vielä ole Fabric Lakehousea , luo Fabric Lakehouse työtilaasi.
Vaihtoehto 1: Vie ja tuo HMS Lakehouse-metakauppaan
Noudata näitä siirron tärkeimpiä vaiheita:
- Vaihe 1: metatietojen vieminen lähde-HMS:stä
- Vaihe 2: Tuo metatiedot Fabric Lakehouseen
- Siirron jälkeiset vaiheet: sisällön vahvistaminen
Muistiinpano
Komentosarjat kopioivat Spark-luettelo-objekteja vain Fabric Lakehouseen. Oletuksena on, että tiedot on jo kopioitu (esimerkiksi varastosijainnista ADLS Gen2:een) tai hallittuja ja ulkoisia taulukoita varten (esimerkiksi pikakuvakkeiden kautta – ensisijainen) Fabric Lakehouseen.
Vaihe 1: metatietojen vieminen lähde-HMS:stä
Vaiheessa 1 keskitytään metatietojen viemiseen HMS-lähdetiedostosta Fabric Lakehouse -järven Tiedostot-osioon. Tämä prosessi on seuraava:
1.1) Tuo HMS-metatietojen vientimuistikirja Azure Synapse työtilaan. Tämä muistikirja tekee kyselyjä ja vie tietokantojen, taulukoiden ja osioiden HMS-metatiedot OneLakessa olevaan välihakemistoon (funktiot, joita ei vielä ole mukana). Sparkin sisäistä hakemiston ohjelmointirajapintaa käytetään tässä komentosarjassa luettelo-objektien lukemiseen.
1.2) Määritä ensimmäisen komennon parametrit metatietojen viemiseksi välitallennustilaan (OneLake). Lähde- ja kohdeparametrit määritetään seuraavalla katkelmassa. Varmista, että korvaat ne omilla arvoillasi.
// Azure Synapse workspace config var SynapseWorkspaceName = "<synapse_workspace_name>" var DatabaseNames = "<db1_name>;<db2_name>" var SkipExportTablesWithUnrecognizedType:Boolean = false // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/"1.3) Vie luettelo-objektit OneLakeen suorittamalla kaikki muistikirjakomennot. Kun solut on suoritettu, järjestelmä luo tämän välitulosteen hakemiston alla olevan kansiorakenteen.
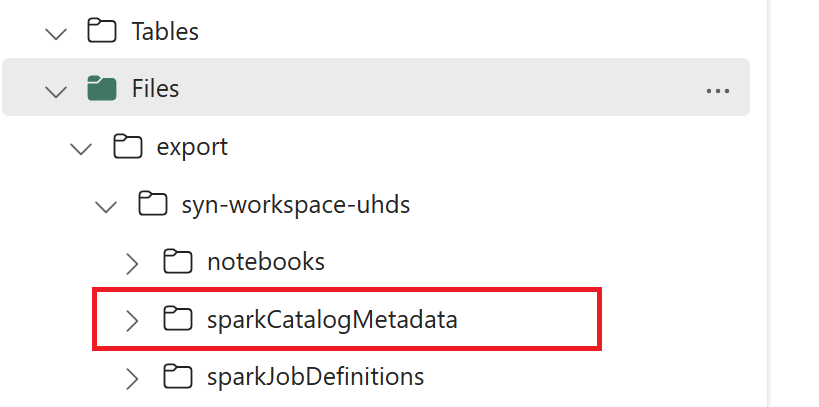
Vaihe 2: Tuo metatiedot Fabric Lakehouseen
Vaihe 2 on se, kun todelliset metatiedot tuodaan välivarastosta Fabric Lakehouseen. Tämän vaiheen tuloksena kaikki HMS-metatiedot (tietokannat, taulukot ja osiot) on siirretty. Tämä prosessi on seuraava:
2.1) Luo pikakuvake Lakehousen "Tiedostot"-osioon . Tämän pikakuvakkeen on osoitettava lähteen Spark-varaston hakemistoon, ja sitä käytetään myöhemmin spark-hallittujen taulukoiden korvaamiseen. Näytä pikakuvakeesimerkit, jotka osoittavat Spark-varaston hakemistoon:
- Pikakuvakepolku Spark Azure Synapse varaston hakemistoon:
abfss://<container>@<storage_name>.dfs.core.windows.net/synapse/workspaces/<workspace_name>/warehouse - Pikakuvakepolku Azure Databricks -varaston hakemistoon:
dbfs:/mnt/<warehouse_dir> - HDInsight Spark -varastohakemiston pikakuvakepolku:
abfss://<container>@<storage_name>.dfs.core.windows.net/apps/spark/warehouse
- Pikakuvakepolku Spark Azure Synapse varaston hakemistoon:
2.2) Tuo HMS-metatietojen tuontimuistikirja Fabric-työtilaan. Tuo tämä muistikirja , jotta voit tuoda tietokanta-, taulukko- ja osio-objekteja välitallennustilasta. Tässä komentosarjassa käytetään Sparkin sisäistä hakemiston ohjelmointirajapintaa luettelo-objektien luomiseen Fabricissa.
2.3) Määritä ensimmäisen komennon parametrit . Kun luot hallitun taulukon Apache Sparkissä, kyseisen taulukon tiedot tallennetaan Sparkin itsensä hallitsemaan sijaintiin, joka on yleensä Sparkin varaston hakemistossa. Spark määrittää tarkan sijainnin. Tämä on ristiriidassa ulkoisten taulukoiden kanssa, joissa määritetään sijainti ja hallitaan pohjana olevia tietoja. Kun siirrät hallitun taulukon metatiedot (siirtämättä todellisia tietoja), metatiedot sisältävät yhä alkuperäiset sijaintitiedot, jotka osoittavat vanhaan Spark-varaston hakemistoon. Näin ollen hallittujen taulukoiden
WarehouseMappingskohdalla korvaamme käyttämällä vaiheessa 2.1 luotua pikakuvaketta. Kaikki lähteen hallitsemat taulukot muunnetaan ulkoisiksi taulukoiksi tämän komentosarjan avulla.LakehouseIdviittaa vaiheessa 2.1 luotuun Lakehouseen, joka sisältää pikakuvakkeet.// Azure Synapse workspace config var ContainerName = "<container_name>" var StorageName = "<storage_name>" var SynapseWorkspaceName = "<synapse_workspace_name>" // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var ShortcutName = "<warehouse_dir_shortcut_name>" var WarehouseMappings:Map[String, String] = Map( f"abfss://${ContainerName}@${StorageName}.dfs.core.windows.net/synapse/workspaces/${SynapseWorkspaceName}/warehouse"-> f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ShortcutName}" ) var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/" var DatabasePrefix = "" var TablePrefix = "" var IgnoreIfExists = true2.4) Suorita kaikki muistikirjakomennot luettelo-objektien tuomiseksi välipolusta.
Muistiinpano
Kun tuot useita tietokantoja, voit (i) luoda yhden lakehouse-kohteen tietokantaa kohti (tässä käytetty lähestymistapa) tai (ii) siirtää kaikki taulukot eri tietokannoista yhteen Lakehouse-tietokantaan. Jälkimmäisessä tapauksessa kaikki siirretyt taulukot voivat olla <lakehouse>.<db_name>_<table_name>, ja sinun on muutettava tuontimuistikirjaa vastaavasti.
Vaihe 3: Sisällön vahvistaminen
Vaihe 3 varmistaa, että metatiedot on siirretty onnistuneesti. Katso eri esimerkkejä.
Näet tuodut tietokannat suorittamalla:
%%sql
SHOW DATABASES
Voit tarkistaa kaikki Lakehouse (tietokanta) -tietokannan taulukot suorittamalla:
%%sql
SHOW TABLES IN <lakehouse_name>
Näet tietyn taulukon tiedot suorittamalla:
%%sql
DESCRIBE EXTENDED <lakehouse_name>.<table_name>
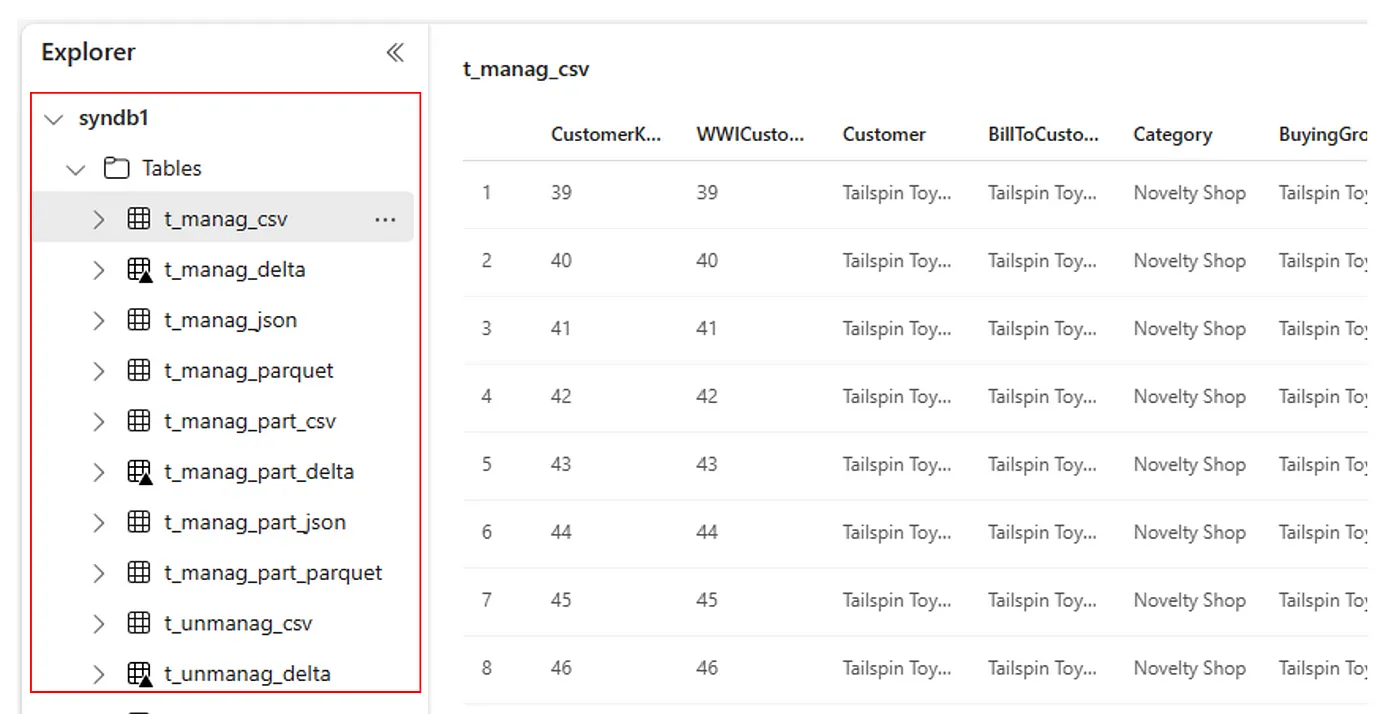
Vaihtoehtoisesti kaikki tuodut taulukot näkyvät Lakehouse Explorerin Käyttöliittymätaulukot-osassa kussakin lakehousessa.
Muuta huomioon otettavaa
- Skaalattavuus: Tässä ratkaisu käyttää sisäistä Spark-luettelon ohjelmointirajapintaa tuonnin/viennin suorittamiseen, mutta se ei ole yhteyden muodostaminen suoraan HMS:ään luettelo-objektien hakemiseksi, joten ratkaisua ei voi skaalata hyvin, jos luettelo on suuri. Sinun on muutettava vientilogiikkaa HMS DB:n avulla.
- Tietojen tarkkuus: Eristystakuuta ei ole, mikä tarkoittaa sitä, että jos Spark-laskentamoduuli tekee samanaikaisia muutoksia metasäilöön siirtomuistikirjan suorittamisen aikana, Fabric Lakehousessa voidaan ottaa käyttöön epäyhtenäisiä tietoja.