Service operations for Business Central online
Business Central runs globally in many Microsoft Azure datacenters. All parts of the infrastructure and services are continually monitored and optimized to deliver the best possible experience. Most service operations and optimizations happen without users being aware of them. In some situations, user interaction is needed, like reconnecting to Business Central or refreshing the browser. Users will be notified directly in the browser if any action is required on their part. Users are asked to take action before the optimizations are applied on the service. This way, they can continue to work without further interruptions. Service operations happen all day, every day, to always provide the best experience.
Service reliability engineering
Microsoft regularly ships feature updates to the underlying service and targeted on-demand fixes to address service quality issues. The release process includes a comprehensive set of quality gates:
- Thorough code reviews
- Ad-hoc testing
- Automated component-based and scenario-based tests
- Feature flighting
- Regional safe deployment
However, even with these safeguards, live site incidents can and do happen. Live site incidents can be divided into several categories:
- Dependent-service issues, such as Microsoft Entra ID, Azure SQL, Storage, virtual machine scale set, Service Fabric, and so on.
- Infrastructure outage, such as a hardware failure or datacenter failure.
- Configuration issues for Business Central environments, such as insufficient capacity.
- Code regressions in Business Central online.
- Customer-specific misconfiguration, such as bad queries or reports, or other types of problematic AL code.
Reducing the incident volume is one way to decrease live site burden and to improve customer satisfaction. However, it isn't always possible to do so. For example, when incident categories are outside the Business Central team's direct control. Also, as the service footprint expands to support rapid growth in usage, the probability of an incident occurring due to external factors increases.
High incident counts can happen, even in cases where the Business Central service has minimal service code regressions, and where the service has met or exceeded its service level objective (SLO) for an overall reliability of 99.95%. The Business Central team devotes significant resources to reducing incident costs to a level that is sustainable, by both financial and engineering measures.
Live site incident process
When investigating live site incidents, the Business Central team follows a standard operational process that's common across Microsoft and the industry.
The following diagram illustrates the main steps in the lifecycle of standard live site incident management.
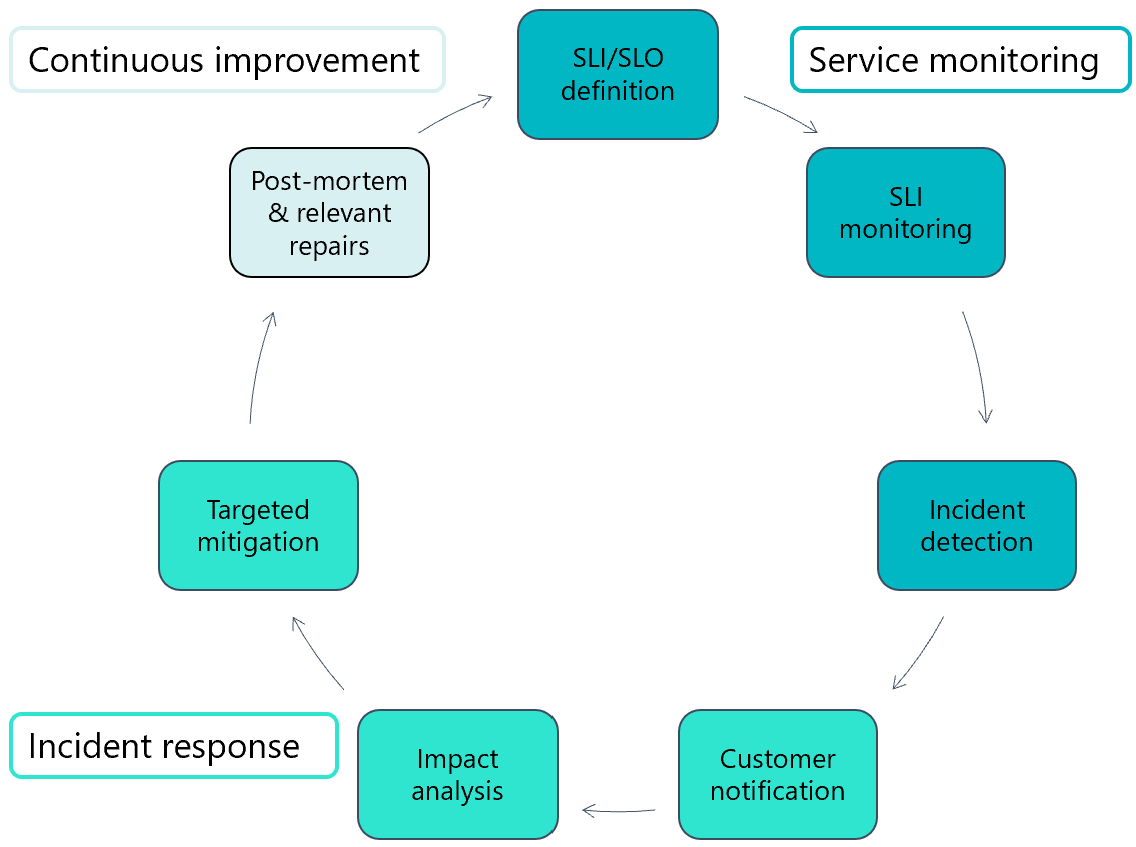
In the first phase, service monitoring, the development and operations (DevOps) team works with engineers, program managers, and the senior leadership team to define service level indicators (SLIs) and service level objectives (SLOs) for both major and minor scenarios. These objectives apply to different metrics of the service, including scenario/component reliability, scenario/component performance (latency), and resource consumption. The live site team and product team then craft alerts that monitor SLIs against agreed-upon targets. When violations are detected, an alert is triggered for investigation.
In the second phase, incident response, processes are structured to facilitate the following results:
- Prompt and targeted notification to customers.
- Analysis of affected service components and workflows.
- Targeted mitigation of incident impact.
In the final phase, continuous improvement, the team focuses on completing a post-mortem analysis and resolution of any identified process, monitoring, or configuration or code fixes. Based on overall severity and risk of recurrence, the fixes are then prioritized against the team's general engineering backlog.
Our practices for service monitoring
The Business Central team emphasizes a consistent, data-driven, and customer-centric approach to its live site operations. Defining SLIs and implementing live site monitoring alerts are part of the approval criteria for enabling any new Business Central feature in production. Product group engineers also include steps for investigation and mitigation of alerts when they occur using a template Troubleshooting Guide (TSG).
One way in which the Business Central team enables exponential service growth is by using a DevOps team. These individuals are skilled with service architecture, automation and incident management practices, and are embedded within incidents to drive end-to-end resolution. The DevOps team uses a rotational model, where engineering leaders from the product group assume an incident manager role for a scheduled number of days. The DevOps team ensures that a consistent group of individuals drives live site improvements and incorporates learnings from previous incidents in future escalations. The DevOps team also assists with large-scale drills that test Business Continuity and Disaster Recovery (BCDR) capabilities of the service.
DevOps practices also enforce alert quality in several ways:
- TSGs include impact analysis and escalation policy.
- Alerts execute for the shortest time possible for faster detection.
- Alerts use reliability thresholds instead of absolute limits to scale clusters of different sizes.
Our practices for incident response
When an automated live site incident is created for Business Central, one of the first priorities is to notify customers of potential impact. Azure's target notification time is 15 minutes. That target can be difficult to achieve, depending on the number of teams that are involved and the complexity of the incident. Communications in such cases are at risk of being late or inaccurate due to required manual analysis. Azure Monitoring offers centralized monitoring and alerting solutions that can detect impact to certain metrics within this time window.
The Business Central live site philosophy emphasizes automated resolution of incidents to improve overall scalability and sustainability of the service. The emphasis on automation enables mitigation at scale and can potentially avoid costly rollbacks or risky expedited fixes to production systems. When manual investigation is required, Business Central adopts a tiered approach with initial investigation done by a dedicated DevOps team. DevOps team members are experienced in managing live site incidents, facilitating cross-team communication, and driving mitigation. In cases where the acting DevOps team member requires more context on an impacted scenario/component, they may engage the subject matter expert (SME) of that area for guidance. Finally, the SME team conducts simulations of system component failures to understand and to mitigate issues in advance of an active live site incident.
Once the affected component/scenario of the service is determined, the Business Central team has multiple techniques for quickly mitigating impact. The following are some of the techniques:
- Activate side-by-side deployment infrastructure: Business Central supports running different versioned workloads in the same cluster. That allows the team to run a new (or previous) version of a specific workload for certain customers without triggering a full-scale deployment (or rollback). The approach can reduce mitigation time and lower overall deployment risk.
- Execute Business Continuity/Disaster Recovery (BCDR) process: Allows the team to fail over primary workloads to this alternate environment, typically within minutes, if there's a serious issue in a new service version. BCDR can also be used when environmental factors or dependent services prevent the primary cluster/region from operating normally.
- Leverage resiliency of dependent services: Business Central proactively evaluates and invests in resiliency and redundancy efforts for all dependent services (such as SQL and Key Vault). Resiliency includes sufficient component monitoring to detect upstream/downstream regressions and local, zonal, and regional redundancy (where applicable). Investing in these capabilities ensures that tooling exists for automatic or manual triggering of recovery operations to mitigate impact from an affected dependency.
Our practices for continuous improvement
The Business Central team reviews all customer-impacting incidents during a weekly service review. All engineering groups that contribute to the Business Central service participate in the reviews. The review disseminates key learnings from the incident to leaders across the organization and provides an opportunity to adapt our processes to close gaps and address inefficiencies.
Prior to review, the DevOps team prepares post-mortem content and identifies preliminary repair items for the live site team and product development team. Items may include code fixes, augmented telemetry, or updated alerts/TSGs. Business Central DevOps teams are familiar with many of these areas. Typically, they'll make the adjustments in real time while they respond to an active incident. Doing so helps to ensure that changes are incorporated into the system in time to detect recurrence of a similar issue. The detailed analysis by the live site team helps the product development team to design a more resilient, scalable, and supportable product.
Beyond review of specific post-mortems, the Business Central team also generates reports on aggregate incident data to identify opportunities for service improvement—for example, future automation of incident mitigation or product fixes. The reporting combines data from multiple sources, including the customer support team, automated alerting, and service telemetry. The consolidated view provides visibility into those issues that are most negatively impacting service and team health. The Business Central team uses overall ROI to prioritize improvements.
Release management and deployment process
Business Central releases weekly feature updates to the service and on-demand targeted fixes to address service quality issues. The approach is intended to balance speed and safety. Any code change in Business Central passes through various validation stages before being deployed broadly to external customers.
Every change to the Business Central code base passes through automated component and end-to-end tests. These tests validate common scenarios and ensure that interactions yield expected results. In addition, Business Central uses a continuous integration and continuous delivery (CI/CD) pipeline on main development branches to detect other issues that are cost-prohibitive to identify on a per-change basis. The CI/CD process triggers a full cluster build-out and various synthetic tests that must pass before a change can enter the next stage in the release process. Approved CI/CD builds are deployed to internal test environments for more automated and manual validation before they're included in weekly feature updates. The process means that a change will be incorporated into a candidate release within 1 to 7 days after it's complete.
A feature update then passes through various official deployment rings of Business Central's safe deployment process. The updated product build is applied first to an internal cluster that hosts content for the Business Central team, followed by the internal cluster that all employees across Microsoft use. The changes wait in each of these environments prior to moving to the final step: production deployment. Here, the deployment team adopts a gradual rollout process. The process selectively applies the new build by region to allow for validation in one region prior to broad application.
Scaling this deployment model to handle exponential service growth is accomplished in several ways, as the following bullets describe:
- Automation: Business Central deployments are essentially zero touch with little to no interaction required by the deployment team. Prebuilt rollout specifications exist for multiple deployment scenarios. Deployment configuration is validated at build-time to avoid unexpected errors during live deployment rollouts.
- Incident response process: Deployment issues are handled like other live site incidents using techniques that are discussed in more detail in the other sections of this article. Engineers analyze issues with a focus on immediate mitigation. They then follow up with manual or automated process changes to prevent recurrence.
- Feature management/exposure control: Business Central applies a comprehensive framework for selectively exposing new features to customers. Feature exposure is independent of deployment cadences. It allows code for new scenarios to be deployed in a disabled state until it has passed all quality bars. Also, new features can be exposed to a subset of the overall Business Central population as an extra validation step prior to enabling them globally. If an issue is detected, the Business Central feature management service lets you disable features in seconds, without waiting for more time-consuming deployment rollback operations.
These features have enabled the Business Central team to improve the success rate of deployments while absorbing a high year-over-year growth in monthly deployments.