SAP HANA infrastructure configurations and operations on Azure
This document provides guidance for configuring Azure infrastructure and operating SAP HANA systems that are deployed on Azure native virtual machines (VMs). The document also includes configuration information for SAP HANA scale-out for the M128s VM SKU. This document isn't intended to replace the standard SAP documentation, which includes the following content:
Prerequisites
To use this guide, you need basic knowledge of the following Azure components:
To learn more about SAP NetWeaver and other SAP components on Azure, see the SAP on Azure section of the Azure documentation.
Basic setup considerations
The following sections describe basic setup considerations for deploying SAP HANA systems on Azure VMs.
Connect into Azure virtual machines
As documented in the Azure virtual machines planning guide, there are two basic methods for connecting into Azure VMs:
- Connect through the internet and public endpoints on a Jump VM or on the VM that is running SAP HANA.
- Connect through a VPN or Azure ExpressRoute.
Site-to-site connectivity via VPN or ExpressRoute is necessary for production scenarios. This type of connection is also needed for non-production scenarios that feed into production scenarios where SAP software is being used. The following image shows an example of cross-site connectivity:
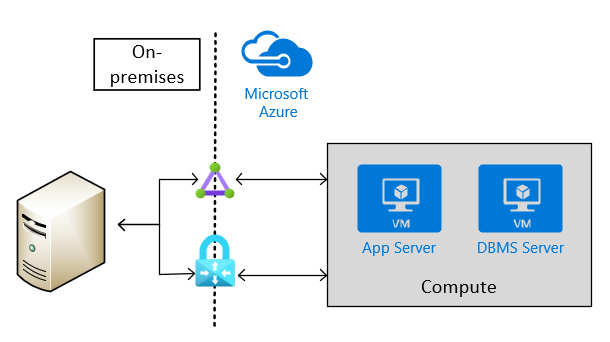
Choose Azure VM types
SAP lists which Azure VM types that you can use for production scenarios. For non-production scenarios, a wider variety of native Azure VM types is available.
Note
For non-production scenarios, use the VM types that are listed in the SAP note #1928533. For the usage of Azure VMs for production scenarios, check for SAP HANA certified VMs in the SAP published Certified IaaS Platforms list.
Deploy the VMs in Azure by using:
- The Azure portal.
- Azure PowerShell cmdlets.
- The Azure CLI.
Important
In order to use M208xx_v2 VMs, you need to be careful selecting your Linux image. For more information, see Memory optimized virtual machine sizes.
Storage configuration for SAP HANA
For storage configurations and storage types to be used with SAP HANA in Azure, read the document SAP HANA Azure virtual machine storage configurations
Set up Azure virtual networks
When you have site-to-site connectivity into Azure via VPN or ExpressRoute, you must have at least one Azure virtual network that is connected through a Virtual Gateway to the VPN or ExpressRoute circuit. In simple deployments, the Virtual Gateway can be deployed in a subnet of the Azure virtual network (VNet) that hosts the SAP HANA instances as well. To install SAP HANA, you create two more subnets within the Azure virtual network. One subnet hosts the VMs to run the SAP HANA instances. The other subnet runs Jumpbox or Management VMs to host SAP HANA Studio, other management software, or your application software.
Important
Out of functionality, but more important out of performance reasons, it is not supported to configure Azure Network Virtual Appliances in the communication path between the SAP application and the DBMS layer of a SAP NetWeaver, Hybris or S/4HANA based SAP system. The communication between the SAP application layer and the DBMS layer needs to be a direct one. The restriction does not include Azure ASG and NSG rules as long as those ASG and NSG rules allow a direct communication. Further scenarios where NVAs are not supported are in communication paths between Azure VMs that represent Linux Pacemaker cluster nodes and SBD devices as described in High availability for SAP NetWeaver on Azure VMs on SUSE Linux Enterprise Server for SAP applications. Or in communication paths between Azure VMs and Windows Server SOFS set up as described in Cluster an SAP ASCS/SCS instance on a Windows failover cluster by using a file share in Azure. NVAs in communication paths can easily double the network latency between two communication partners, can restrict throughput in critical paths between the SAP application layer and the DBMS layer. In some scenarios observed with customers, NVAs can cause Pacemaker Linux clusters to fail in cases where communications between the Linux Pacemaker cluster nodes need to communicate to their SBD device through an NVA.
Important
Another design that is NOT supported is the segregation of the SAP application layer and the DBMS layer into different Azure virtual networks that are not peered with each other. It is recommended to segregate the SAP application layer and DBMS layer using subnets within an Azure virtual network instead of using different Azure virtual networks. If you decide not to follow the recommendation, and instead segregate the two layers into different virtual network, the two virtual networks need to be peered. Be aware that network traffic between two peered Azure virtual networks are subject of transfer costs. With the huge data volume in many Terabytes exchanged between the SAP application layer and DBMS layer substantial costs can be accumulated if the SAP application layer and DBMS layer is segregated between two peered Azure virtual networks.
If you deployed Jumpbox or management VMs in a separate subnet, you can define multiple virtual network interface cards (vNICs) for the HANA VM, with each vNIC assigned to different subnet. With the ability to have multiple vNICs, you can set up network traffic separation, if necessary. For example, client traffic can be routed through the primary vNIC and admin traffic is routed through a second vNIC.
You also assign static private IP addresses that are deployed for both virtual NICs.
Note
You should assign static IP addresses through Azure means to individual vNICs. You should not assign static IP addresses within the guest OS to a vNIC. Some Azure services like Azure Backup Service rely on the fact that at least the primary vNIC is set to DHCP and not to static IP addresses. See also the document Troubleshoot Azure virtual machine backup. If you need to assign multiple static IP addresses to a VM, you need to assign multiple vNICs to a VM.
However, for deployments that are enduring, you need to create a virtual datacenter network architecture in Azure. This architecture recommends the separation of the Azure VNet Gateway that connects to on-premises into a separate Azure VNet. This separate VNet should host all the traffic that leaves either to on-premises or to the internet. This approach allows you to deploy software for auditing and logging traffic that enters the virtual datacenter in Azure in this separate hub VNet. So you have one VNet that hosts all the software and configurations that relate to in- and outgoing traffic to your Azure deployment.
The articles Azure Virtual Datacenter: A Network Perspective and Azure Virtual Datacenter and the Enterprise Control Plane give more information on the virtual datacenter approach and related Azure VNet design.
Note
Traffic that flows between a hub VNet and spoke VNet using Azure VNet peering is subject of additional costs. Based on those costs, you might need to consider making compromises between running a strict hub and spoke network design and running multiple Azure ExpressRoute Gateways that you connect to 'spokes' in order to bypass VNet peering. However, Azure ExpressRoute Gateways introduce additional costs as well. You also may encounter additional costs for third-party software you use for network traffic logging, auditing, and monitoring. Dependent on the costs for data exchange through VNet peering on the one side and costs created by additional Azure ExpressRoute Gateways and additional software licenses, you may decide for micro-segmentation within one VNet by using subnets as isolation unit instead of VNets.
For an overview of the different methods for assigning IP addresses, see IP address types and allocation methods in Azure.
For VMs running SAP HANA, you should work with static IP addresses assigned. Reason is that some configuration attributes for HANA reference IP addresses.
Azure Network Security Groups (NSGs) are used to direct traffic that's routed to the SAP HANA instance or the jumpbox. The NSGs and eventually Application Security Groups are associated to the SAP HANA subnet and the Management subnet.
To deploy SAP HANA in Azure without a site-to-site connection, you still want to shield the SAP HANA instance from the public internet and hide it behind a forward proxy. In this basic scenario, the deployment relies on Azure built-in DNS services to resolve hostnames. In a more complex deployment where public-facing IP addresses are used, Azure built-in DNS services are especially important. Use Azure NSGs and Azure NVAs to control, monitor the routing from the internet into your Azure VNet architecture in Azure. The following image shows a rough schema for deploying SAP HANA without a site-to-site connection in a hub and spoke VNet architecture:
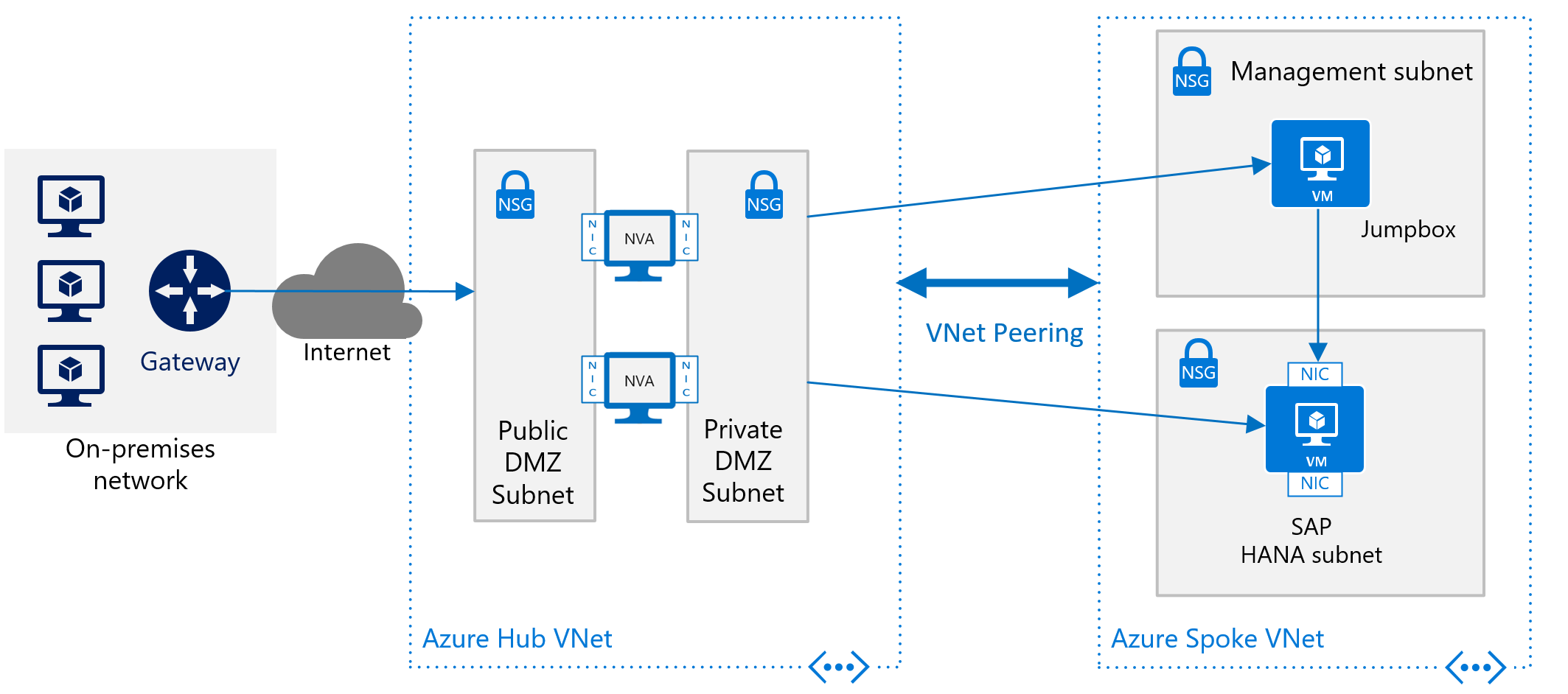
Another description on how to use Azure NVAs to control and monitor access from Internet without the hub and spoke VNet architecture can be found in the article Deploy highly available network virtual appliances.
Clock source options in Azure VMs
SAP HANA requires reliable and accurate timing information to perform optimally. Traditionally Azure VMs running on Azure hypervisor used only Hyper-V TSC page as a default clock source. Technology advancements in hardware, host OS and Linux guest OS kernels made it possible to provide "Invariant TSC" as a clock source option on some Azure VM SKUs.
Hyper-V TSC page (hyperv_clocksource_tsc_page) is supported on all Azure VMs as a clock source.
If the underlying hardware, hypervisor and guest OS linux kernel support Invariant TSC, tsc will be offered as available and supported clock source in the guest OS on Azure VMs.
Configuring Azure infrastructure for SAP HANA scale-out
In order to find out the Azure VM types that are certified for either OLAP scale-out or S/4HANA scale-out, check the SAP HANA hardware directory. A checkmark in the column 'Clustering' indicates scale-out support. Application type indicates whether OLAP scale-out or S/4HANA scale-out is supported. For details on nodes certified in scale-out, review the entry for a specific VM SKU listed in the SAP HANA hardware directory.
The minimum OS releases for deploying scale-out configurations in Azure VMs, check the details of the entries in the particular VM SKU listed in the SAP HANA hardware directory. Of a n-node OLAP scale-out configuration, one node functions as the main node. The other nodes up to the limit of the certification act as worker node. More standby nodes don't count into the number of certified nodes
Note
Azure VM scale-out deployments of SAP HANA with standby node are only possible using the Azure NetApp Files storage. No other SAP HANA certified Azure storage allows the configuration of SAP HANA standby nodes
For /hana/shared, we recommend the usage of Azure NetApp Files or Azure Files.
A typical basic design for a single node in a scale-out configuration, with /hana/shared deployed on Azure NetApp Files, looks like:
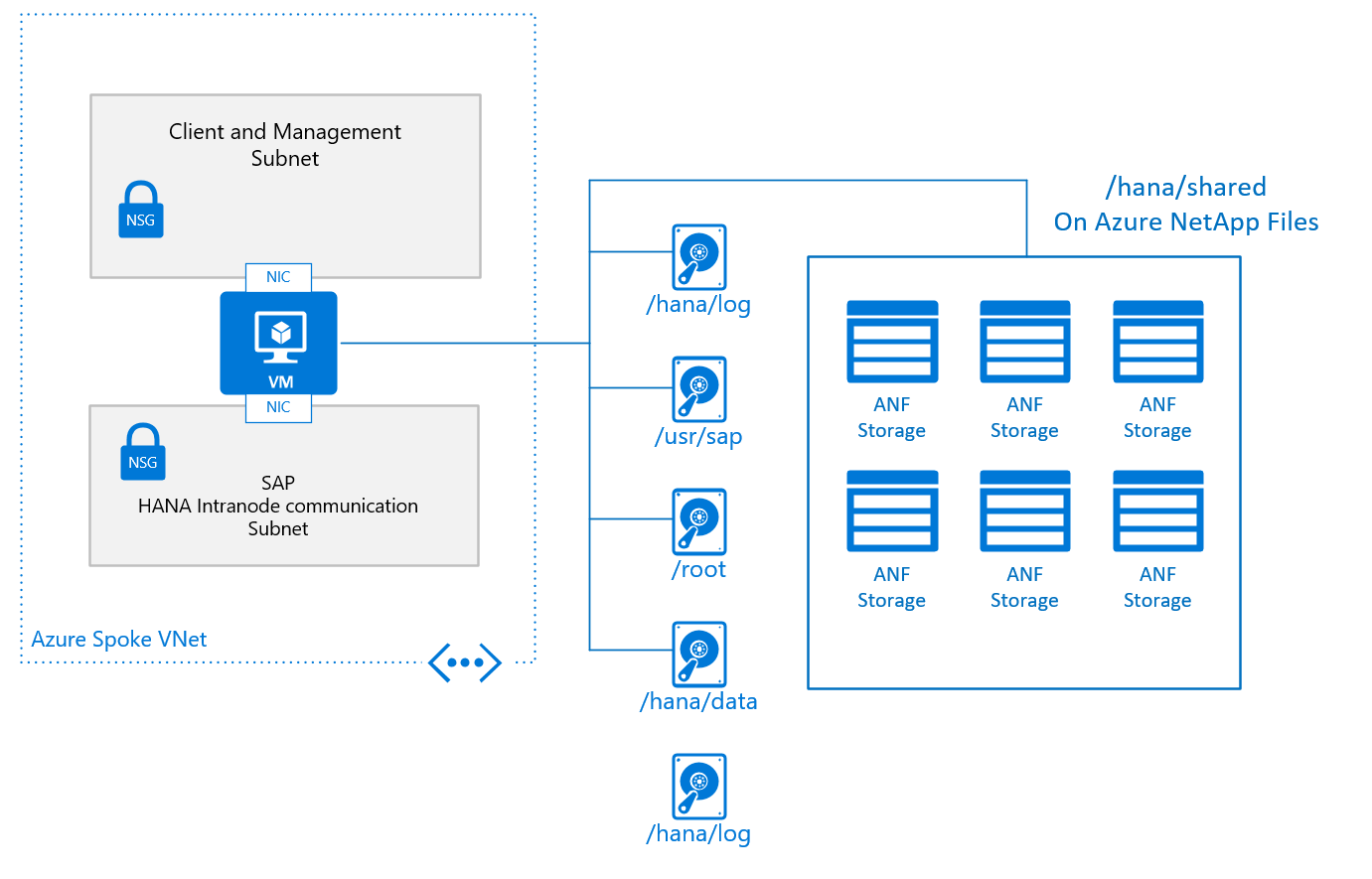
The basic configuration of a VM node for SAP HANA scale-out looks like:
- For /hana/shared, you use the native NFS service provided through Azure NetApp Files or Azure Files.
- All other disk volumes aren't shared among the different nodes and aren't based on NFS. Installation configurations and steps for scale-out HANA installations with non-shared /hana/data and /hana/log is provided further later in this document. For HANA certified storage that can be used, check the article SAP HANA Azure virtual machine storage configurations.
Sizing the volumes or disks, you need to check the document SAP HANA TDI Storage Requirements, for the size required dependent on the number of worker nodes. The document releases a formula you need to apply to get the required capacity of the volume
The other design criteria that is displayed in the graphics of the single node configuration for a scale-out SAP HANA VM is the VNet, or better the subnet configuration. SAP highly recommends a separation of the client/application facing traffic from the communications between the HANA nodes. As shown in the graphics, this goal is achieved by having two different vNICs attached to the VM. Both vNICs are in different subnets, have two different IP addresses. You then control the flow of traffic with routing rules using NSGs or user-defined routes.
Particularly in Azure, there are no means and methods to enforce quality of service and quotas on specific vNICs. As a result, the separation of client/application facing and intra-node communication doesn't open any opportunities to prioritize one traffic stream over the other. Instead the separation remains a measure of security in shielding the intra-node communications of the scale-out configurations.
Note
SAP recommends separating network traffic to the client/application side and intra-node traffic as described in this document. Therefore putting an architecture in place as shown in the last graphics is recommended. Also consult your security and compliance team for requirements that deviate from the recommendation
From a networking point of view the minimum required network architecture would look like:
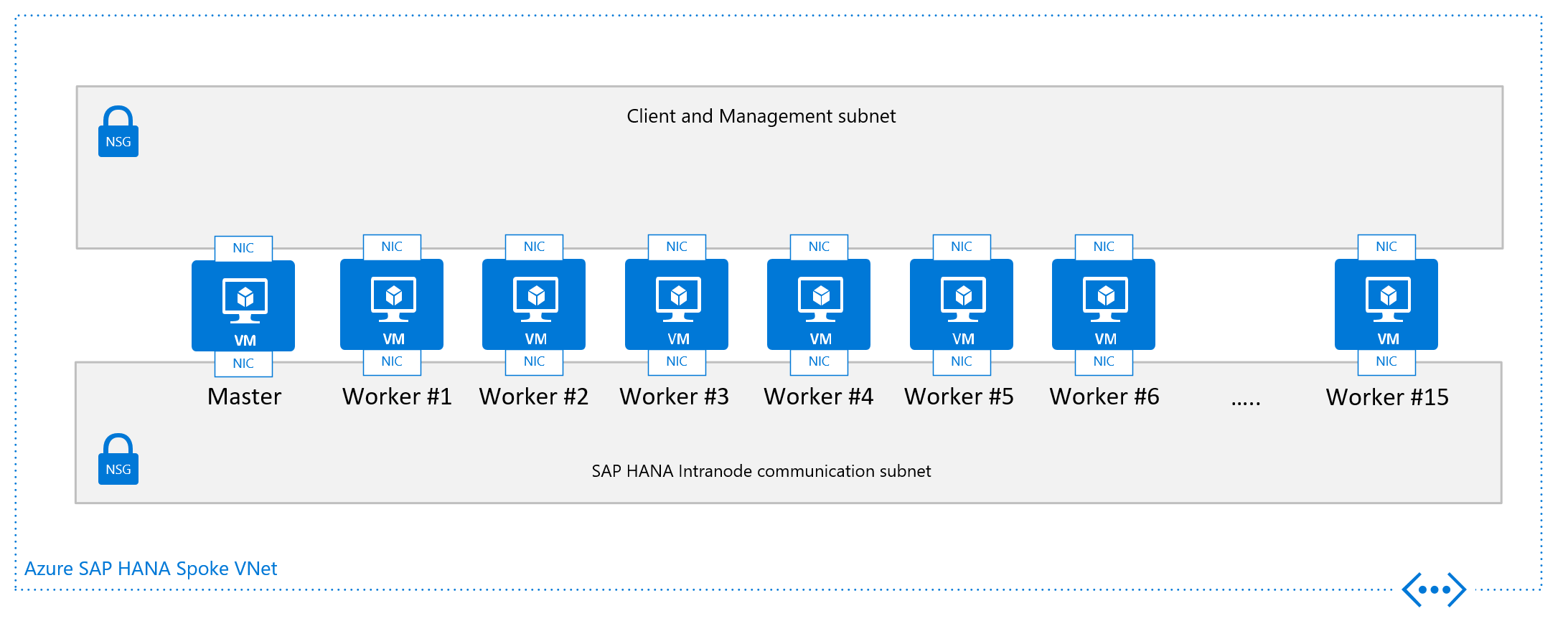
Installing SAP HANA scale-out n Azure
Installing a scale-out SAP configuration, you need to perform rough steps of:
- Deploying new or adapting an existing Azure VNet infrastructure
- Deploying the new VMs using Azure Managed Premium Storage, Ultra disk volumes, and/or NFS volumes based on ANF
-
- Adapt network routing to make sure that, for example, intra-node communication between VMs isn't routed through an NVA.
- Install the SAP HANA main node.
- Adapt configuration parameters of the SAP HANA main node
- Continue with the installation of the SAP HANA worker nodes
Installation of SAP HANA in scale-out configuration
As your Azure VM infrastructure is deployed, and all other preparations are done, you need to install the SAP HANA scale-out configurations in these steps:
- Install the SAP HANA main node according to SAP's documentation
- When using Azure Premium Storage or Ultra disk storage with non-shared disks of
/hana/dataand/hana/log, add the parameterbasepath_shared = noto theglobal.inifile. This parameter enables SAP HANA to run in scale-out without shared/hana/dataand/hana/logvolumes between the nodes. Details are documented in SAP Note #2080991. If you're using NFS volumes based on ANF for /hana/data and /hana/log, you don't need to make this change - After the eventual change in the global.ini parameter, restart the SAP HANA instance
- Add more worker nodes. For more information, see Add Hosts Using the Command-Line Interface. Specify the internal network for SAP HANA inter-node communication during the installation or afterwards using, for example, the local hdblcm. For more detailed documentation, see SAP Note #2183363.
To set up an SAP HANA scale-out system with a standby node, see the SUSE Linux deployment instructions or the Red Hat deployment instructions.
SAP HANA Dynamic Tiering 2.0 for Azure virtual machines
In addition to the SAP HANA certifications on Azure M-series VMs, SAP HANA Dynamic Tiering 2.0 is also supported on Microsoft Azure. For more information, see Links to DT 2.0 documentation. There's no difference in installing or operating the product. For example, you can install SAP HANA Cockpit inside an Azure VM. However, there are some mandatory requirements, as described in the following section, for official support on Azure. Throughout the article, the abbreviation "DT 2.0" is going to be used instead of the full name Dynamic Tiering 2.0.
SAP HANA Dynamic Tiering 2.0 isn't supported by SAP BW or S4HANA. Main use cases right now are native HANA applications.
Overview
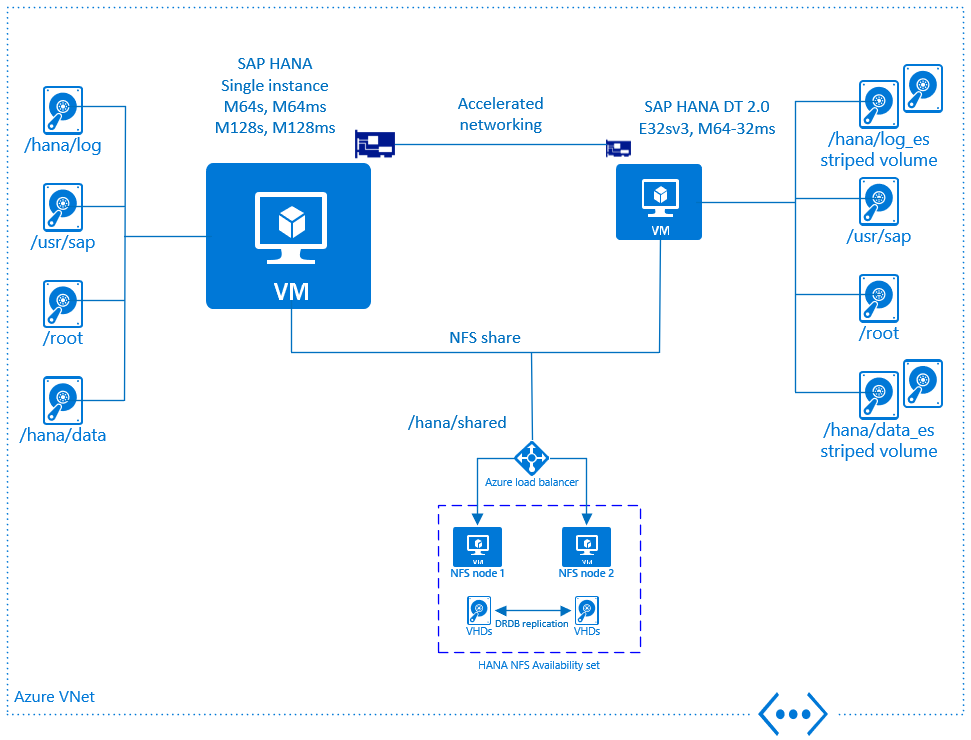
The picture below gives an overview regarding DT 2.0 support on Microsoft Azure. There's a set of mandatory requirements, which has to be followed to comply with the official certification:
- DT 2.0 must be installed on a dedicated Azure VM. It may not run on the same VM where SAP HANA runs
- SAP HANA and DT 2.0 VMs must be deployed within the same Azure Vnet
- The SAP HANA and DT 2.0 VMs must be deployed with Azure accelerated networking enabled
- Storage type for the DT 2.0 VMs must be Azure Premium Storage
- Multiple Azure disks must be attached to the DT 2.0 VM
- It's required to create a software raid / striped volume (either via lvm or mdadm) using striping across the Azure disks
More details are going to be explained in the following sections.
Dedicated Azure VM for SAP HANA DT 2.0
On Azure IaaS, DT 2.0 is only supported on a dedicated VM. It isn't allowed to run DT 2.0 on the same Azure VM where the HANA instance is running. Initially two VM types can be used to run SAP HANA DT 2.0:
- M64-32ms
- E32sv3
For more information on the VM type description, see Azure VM sizes - Memory
Given the basic idea of DT 2.0, which is about offloading "warm" data in order to save costs it makes sense to use corresponding VM sizes. There's no strict rule though regarding the possible combinations. It depends on the specific customer workload.
Recommended configurations would be:
| SAP HANA VM type | DT 2.0 VM type |
|---|---|
| M128ms | M64-32ms |
| M128s | M64-32ms |
| M64ms | E32sv3 |
| M64s | E32sv3 |
All combinations of SAP HANA-certified M-series VMs with supported DT 2.0 VMs (M64-32ms and E32sv3) are possible.
Azure networking and SAP HANA DT 2.0
Installing DT 2.0 on a dedicated VM requires network throughput between the DT 2.0 VM and the SAP HANA VM of 10 Gb minimum. Therefore it's mandatory to place all VMs within the same Azure Vnet and enable Azure accelerated networking.
See additional information about Azure accelerated networking Create an Azure VM with Accelerated Networking using Azure CLI
VM Storage for SAP HANA DT 2.0
According to DT 2.0 best practice guidance, the disk IO throughput should be minimum 50 MB/sec per physical core.
According to the specifications for the two Azure VM types, which are supported for DT 2.0, the maximum disk IO throughput limit for the VM looks like:
- E32sv3: 768 MB/sec (uncached) which means a ratio of 48 MB/sec per physical core
- M64-32ms: 1000 MB/sec (uncached) which means a ratio of 62.5 MB/sec per physical core
It's required to attach multiple Azure disks to the DT 2.0 VM and create a software raid (striping) on OS level to achieve the max limit of disk throughput per VM. A single Azure disk can't provide the throughput to reach the max VM limit in this regard. Azure Premium storage is mandatory to run DT 2.0.
- Details about available Azure disk types can be found on the Select a disk type for Azure IaaS VMs - managed disks page
- Details about creating software raid via mdadm can be found on the Configure software RAID on a Linux VM page
- Details about configuring LVM to create a striped volume for max throughput can be found on the Configure LVM on a virtual machine running Linux page
Depending on size requirements, there are different options to reach the max throughput of a VM. Here are possible data volume disk configurations for every DT 2.0 VM type to achieve the upper VM throughput limit. The E32sv3 VM should be considered as an entry level for smaller workloads. In case it should turn out that it's not fast enough it might be necessary to resize the VM to M64-32ms. As the M64-32ms VM has much memory, the IO load might not reach the limit especially for read intensive workloads. Therefore fewer disks in the stripe set might be sufficient depending on the customer specific workload. But to be on the safe side the disk configurations below were chosen to guarantee the maximum throughput:
| VM SKU | Disk Config 1 | Disk Config 2 | Disk Config 3 | Disk Config 4 | Disk Config 5 |
|---|---|---|---|---|---|
| M64-32ms | 4 x P50 -> 16 TB | 4 x P40 -> 8 TB | 5 x P30 -> 5 TB | 7 x P20 -> 3.5 TB | 8 x P15 -> 2 TB |
| E32sv3 | 3 x P50 -> 12 TB | 3 x P40 -> 6 TB | 4 x P30 -> 4 TB | 5 x P20 -> 2.5 TB | 6 x P15 -> 1.5 TB |
Especially in case the workload is read-intense it could boost IO performance to turn on Azure host cache "read-only" as recommended for the data volumes of database software. Whereas for the transaction log Azure host disk cache must be "none".
Regarding the size of the log volume a recommended starting point is a heuristic of 15% of the data size. The creation of the log volume can be accomplished by using different Azure disk types depending on cost and throughput requirements. For the log volume, high I/O throughput is required.
When using the VM type M64-32ms, it's mandatory to enable Write Accelerator. Azure Write Accelerator provides optimal disk write latency for the transaction log (only available for M-series). There are some items to consider though like the maximum number of disks per VM type. Details about Write Accelerator can be found on the Azure Write Accelerator page
Here are a few examples about sizing the log volume:
| data volume size and disk type | log volume and disk type config 1 | log volume and disk type config 2 |
|---|---|---|
| 4 x P50 -> 16 TB | 5 x P20 -> 2.5 TB | 3 x P30 -> 3 TB |
| 6 x P15 -> 1.5 TB | 4 x P6 -> 256 GB | 1 x P15 -> 256 GB |
Like for SAP HANA scale-out, the /hana/shared directory has to be shared between the SAP HANA VM and the DT 2.0 VM. The same architecture as for SAP HANA scale-out using dedicated VMs, which act as a highly available NFS server is recommended. In order to provide a shared backup volume, the identical design can be used. But it's up to the customer if HA would be necessary or if it's sufficient to just use a dedicated VM with enough storage capacity to act as a backup server.
Links to DT 2.0 documentation
- SAP HANA Dynamic Tiering installation and update guide
- SAP HANA Dynamic Tiering tutorials and resources
- SAP HANA Dynamic Tiering PoC
- SAP HANA 2.0 SPS 02 dynamic tiering enhancements
Operations for deploying SAP HANA on Azure VMs
The following sections describe some of the operations related to deploying SAP HANA systems on Azure VMs.
Back up and restore operations on Azure VMs
The following documents describe how to back up and restore your SAP HANA deployment:
Start and restart VMs that contain SAP HANA
A prominent feature of the Azure public cloud is that you're charged only for your computing minutes. For example, when you shut down a VM that is running SAP HANA, you're billed only for the storage costs during that time. Another feature is available when you specify static IP addresses for your VMs in your initial deployment. When you restart a VM that has SAP HANA, the VM restarts with its prior IP addresses.
Use SAProuter for SAP remote support
If you have a site-to-site connection between your on-premises locations and Azure, and you're running SAP components, then you're probably already running SAProuter. In this case, complete the following items for remote support:
- Maintain the private and static IP address of the VM that hosts SAP HANA in the SAProuter configuration.
- Configure the NSG of the subnet that hosts the HANA VM to allow traffic through TCP/IP port 3299.
If you're connecting to Azure through the internet, and you don't have an SAP router for the VM with SAP HANA, then you need to install the component. Install SAProuter in a separate VM in the Management subnet. The following image shows a rough schema for deploying SAP HANA without a site-to-site connection and with SAProuter:
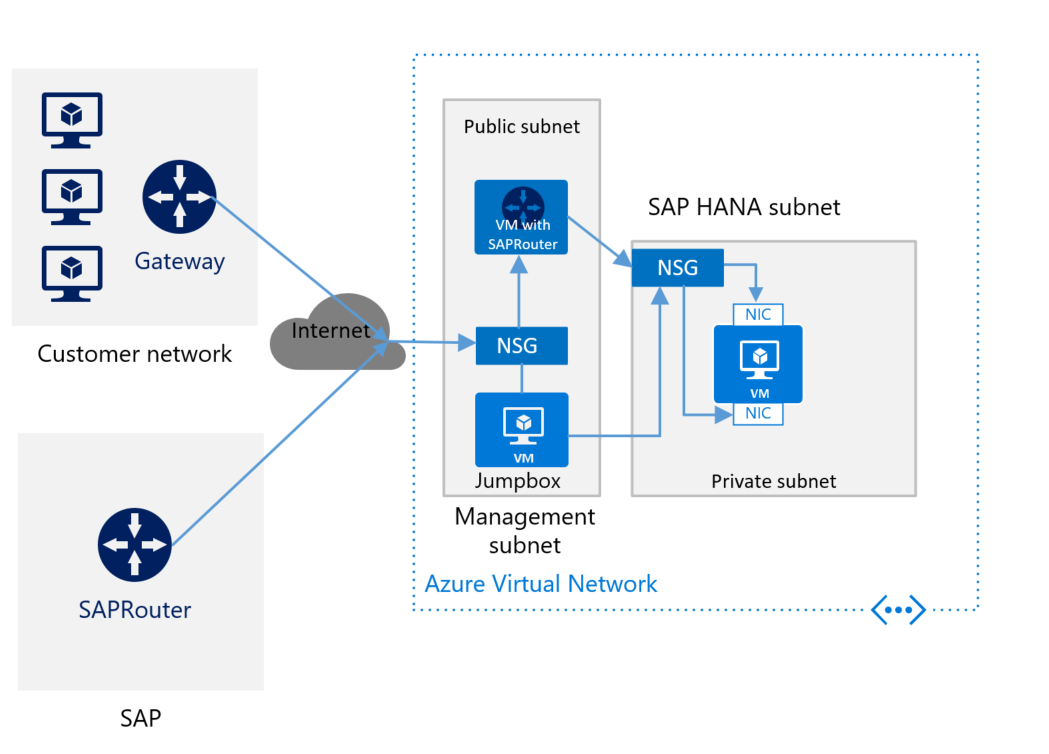
Be sure to install SAProuter in a separate VM and not in your Jumpbox VM. The separate VM must have a static IP address. To connect your SAProuter to the SAProuter that is hosted by SAP, contact SAP for an IP address. (The SAProuter that is hosted by SAP is the counterpart of the SAProuter instance that you install on your VM.) Use the IP address from SAP to configure your SAProuter instance. In the configuration settings, the only necessary port is TCP port 3299.
For more information on how to set up and maintain remote support connections through SAProuter, see the SAP documentation.
High-availability with SAP HANA on Azure native VMs
If you're running SUSE Linux Enterprise Server or Red Hat, you can establish a Pacemaker cluster with fencing devices. You can use the devices to set up an SAP HANA configuration that uses synchronous replication with HANA System Replication and automatic failover. For more information listed in the 'next steps' section.
Next Steps
Get familiar with the articles as listed
- SAP HANA Azure virtual machine storage configurations
- Deploy a SAP HANA scale-out system with standby node on Azure VMs by using Azure NetApp Files on SUSE Linux Enterprise Server
- Deploy a SAP HANA scale-out system with standby node on Azure VMs by using Azure NetApp Files on Red Hat Enterprise Linux
- Deploy a SAP HANA scale-out system with HSR and Pacemaker on Azure VMs on SUSE Linux Enterprise Server
- Deploy a SAP HANA scale-out system with HSR and PAcemaker on Azure VMs on Red Hat Enterprise Linux
- High availability of SAP HANA on Azure VMs on SUSE Linux Enterprise Server
- High availability of SAP HANA on Azure VMs on Red Hat Enterprise Linux