What is Interactive Query In Azure HDInsight
Interactive Query (also called Apache Hive LLAP, or Low Latency Analytical Processing) is an Azure HDInsight cluster type. Interactive Query supports in-memory caching, which makes Apache Hive queries faster and much more interactive. Customers use Interactive Query to query data stored in Azure storage & Azure Data Lake Storage in super-fast manner. Interactive query makes it easy for developers and data scientist to work with the big data using BI tools they love the most. HDInsight Interactive Query supports several tools to access big data in easy fashion.
An Interactive Query cluster is different from an Apache Hadoop cluster. It contains only the Hive service.
You can access the Hive service in the Interactive Query cluster only via Apache Ambari Hive View, Beeline, and the Microsoft Hive Open Database Connectivity driver (Hive ODBC). You can't access it via the Hive console, Templeton, the Azure Classic CLI, or Azure PowerShell.
Create an Interactive Query cluster
For information about creating a HDInsight cluster, see Create Apache Hadoop clusters in HDInsight. Choose the Interactive Query cluster type.
Important
The minimum headnode size for Interactive Query clusters is Standard_D13_v2. For more information, see the Azure Virtual Machine Sizing Chart.
Execute Apache Hive queries from Interactive Query
To execute Hive queries, you have the following options:
| Method | Description |
|---|---|
| Microsoft Power BI | See Visualize Interactive Query Apache Hive data with Power BI in Azure HDInsight, and Visualize big data with Power BI in Azure HDInsight. |
| Visual Studio | See Connect to Azure HDInsight and run Apache Hive queries using Data Lake Tools for Visual Studio. |
| Visual Studio Code | See Use Visual Studio Code for Apache Hive, LLAP, or pySpark. |
| Apache Ambari Hive View | See Use Apache Hive View with Apache Hadoop in Azure HDInsight. Hive View isn't available for HDInsight 4.0. |
| Apache Beeline | See Use Apache Hive with Apache Hadoop in HDInsight with Beeline. You can use Beeline from either the head node or from an empty edge node. We recommend using Beeline from an empty edge node. For information about creating a HDInsight cluster by using an empty edge node, see Use empty edge nodes in HDInsight. |
| Hive ODBC | See Connect Excel to Apache Hadoop with the Microsoft Hive ODBC driver. |
To find the Java Database Connectivity (JDBC) connection string:
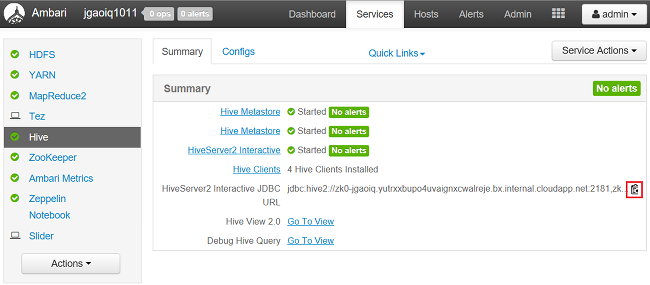
From a web browser, navigate to
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summary, whereCLUSTERNAMEis the name of your cluster.To copy the URL, select the clipboard icon:
Next steps
- Learn how to create Interactive Query clusters in HDInsight.
- Learn how to visualize big data with Power BI in Azure HDInsight.
- Learn how to use Apache Zeppelin to run Apache Hive queries in Azure HDInsight.