Get started with Databricks AI agents
This tutorial steps you through building an AI agent that uses retrieval and tools together. The dataset consists of a subset of the Databricks documentation that is already divided into chunks. In this tutorial, you build an agent that retrieves documents based on keywords.
For simplicity, this tutorial uses a simple in-memory approach based on TF-IDF for keyword extraction and keyword search over the documents. The example notebook includes all of the code used in the tutorial. For a more realistic example that uses Mosaic AI Vector Search to scalably index and search documents, see ChatAgent examples.
This tutorial covers some of the core challenges of building generative AI applications:
- Streamlining the development experience for common tasks like creating tools and debugging agent execution.
- Operational challenges such as:
- Tracking agent configuration
- Defining inputs and outputs in a predictable way
- Managing versions of dependencies
- Version control and deployment
- Measuring and improving the quality and reliability of an agent.
See Navigate the generative AI app guide for a guide to the entire development process of building an agent.
Example notebook
This standalone notebook is designed to quickly get you working with Mosaic AI agents using a sample document corpus. It is ready to run with no setup or data required.
Mosaic AI agent demo
Create an agent and tools
Mosaic AI Agent Framework supports many different authoring frameworks. This example uses LangGraph to illustrate concepts, but this is not a LangGraph tutorial.
For examples of other supported frameworks, see ChatAgent examples.
The first step is to create an agent. You must specify an LLM client and a list of tools. The databricks-langchain Python package includes LangChain- and LangGraph-compatible clients for both Databricks LLMs and tools registered in Unity Catalog.
The endpoint must be a function-calling Foundation Model API or External Model using AI Gateway. See Supported models.
from databricks_langchain import ChatDatabricks
llm = ChatDatabricks(endpoint="databricks-meta-llama-3-3-70b-instruct")
The following code defines a function that creates an agent from the model and some tools, discussing the internals of this agent code is outside the scope of this guide. For more information about how to build a LangGraph agent, see LangGraph documentation.
from typing import Optional, Sequence, Union
from langchain_core.language_models import LanguageModelLike
from langchain_core.runnables import RunnableConfig, RunnableLambda
from langchain_core.tools import BaseTool
from langgraph.graph import END, StateGraph
from langgraph.graph.graph import CompiledGraph
from langgraph.prebuilt.tool_executor import ToolExecutor
from mlflow.langchain.chat_agent_langgraph import ChatAgentState, ChatAgentToolNode
def create_tool_calling_agent(
model: LanguageModelLike,
tools: Union[ToolExecutor, Sequence[BaseTool]],
agent_prompt: Optional[str] = None,
) -> CompiledGraph:
model = model.bind_tools(tools)
def routing_logic(state: ChatAgentState):
last_message = state["messages"][-1]
if last_message.get("tool_calls"):
return "continue"
else:
return "end"
if agent_prompt:
system_message = {"role": "system", "content": agent_prompt}
preprocessor = RunnableLambda(
lambda state: [system_message] + state["messages"]
)
else:
preprocessor = RunnableLambda(lambda state: state["messages"])
model_runnable = preprocessor | model
def call_model(
state: ChatAgentState,
config: RunnableConfig,
):
response = model_runnable.invoke(state, config)
return {"messages": [response]}
workflow = StateGraph(ChatAgentState)
workflow.add_node("agent", RunnableLambda(call_model))
workflow.add_node("tools", ChatAgentToolNode(tools))
workflow.set_entry_point("agent")
workflow.add_conditional_edges(
"agent",
routing_logic,
{
"continue": "tools",
"end": END,
},
)
workflow.add_edge("tools", "agent")
return workflow.compile()
Define agent tools
Tools are a fundamental concept for building agents. They provide the ability to integrate LLMs with human-defined code. When provided a prompt and a list of tools, a tool-calling LLM generates the arguments to invoke the tool. For more information about tools and using them with Mosaic AI agents, see AI agent tools.
The first step is to create a keyword extraction tool based on TF-IDF. This example uses scikit-learn and a Unity Catalog tool.
The databricks-langchain package provides a convenient way to work with Unity Catalog tools. The following code illustrates how to implement and register a keyword extractor tool.
Note
The Databricks workspace has a built-in tool, system.ai.python_exec, that you can use to extend agents with the ability to execute Python scripts in a sandboxed execution environment. Other useful built-in tools include external connections and AI functions.
from databricks_langchain.uc_ai import (
DatabricksFunctionClient,
UCFunctionToolkit,
set_uc_function_client,
)
uc_client = DatabricksFunctionClient()
set_uc_function_client(client)
# Change this to your catalog and schema
CATALOG = "main"
SCHEMA = "my_schema"
def tfidf_keywords(text: str) -> list[str]:
"""
Extracts keywords from the provided text using TF-IDF.
Args:
text (string): Input text.
Returns:
list[str]: List of extracted keywords in ascending order of importance.
"""
from sklearn.feature_extraction.text import TfidfVectorizer
def keywords(text, top_n=5):
vec = TfidfVectorizer(stop_words="english")
tfidf = vec.fit_transform([text]) # Convert text to TF-IDF matrix
indices = tfidf.toarray().argsort()[0, -top_n:] # Get indices of top N words
return [vec.get_feature_names_out()[i] for i in indices]
return keywords(text)
# Create the function in the Unity Catalog catalog and schema specified
# When you use `.create_python_function`, the provided function’s metadata
# (docstring, parameters, return type) are used to create a tool in the specified catalog and schema.
function_info = uc_client.create_python_function(
func=tfidf_keywords,
catalog=CATALOG,
schema=SCHEMA,
replace=True, # Set to True to overwrite if the function already exists
)
print(function_info)
Here is an explanation of the code above:
- Creates a client that uses Unity Catalog in the Databricks workspace as a “registry” to create and discover tools.
- Defines a Python function that performs TF-IDF keyword extraction.
- Registers the Python function as a Unity Catalog function.
This workflow solves several common problems. You now have a central registry for tools which, like other objects in Unity Catalog, can be governed. For example, if a company has a standard way to calculate internal rate of return, you can define it as a function in Unity Catalog, and grant access to all users or agents with the FinancialAnalyst role.
To make this tool usable by a LangChain agent, use the [UCFunctionToolkit](/generative-ai/agent-framework/create-custom-tool.md] which creates a collection of tools to give to the LLM for selection:
# Use ".*" here to specify all the tools in the schema, or
# explicitly list functions by name
# uc_tool_names = [f"{CATALOG}.{SCHEMA}.*"]
uc_tool_names = [f"{CATALOG}.{SCHEMA}.tfidf_keywords"]
uc_toolkit = UCFunctionToolkit(function_names=uc_tool_names)
The following code shows how to test the tool:
uc_toolkit.tools[0].invoke({ "text": "The quick brown fox jumped over the lazy brown dog." })
The following code creates an agent that uses the keyword extraction tool.
import mlflow
mlflow.langchain.autolog()
agent = create_tool_calling_agent(llm, tools=[*uc_toolkit.tools])
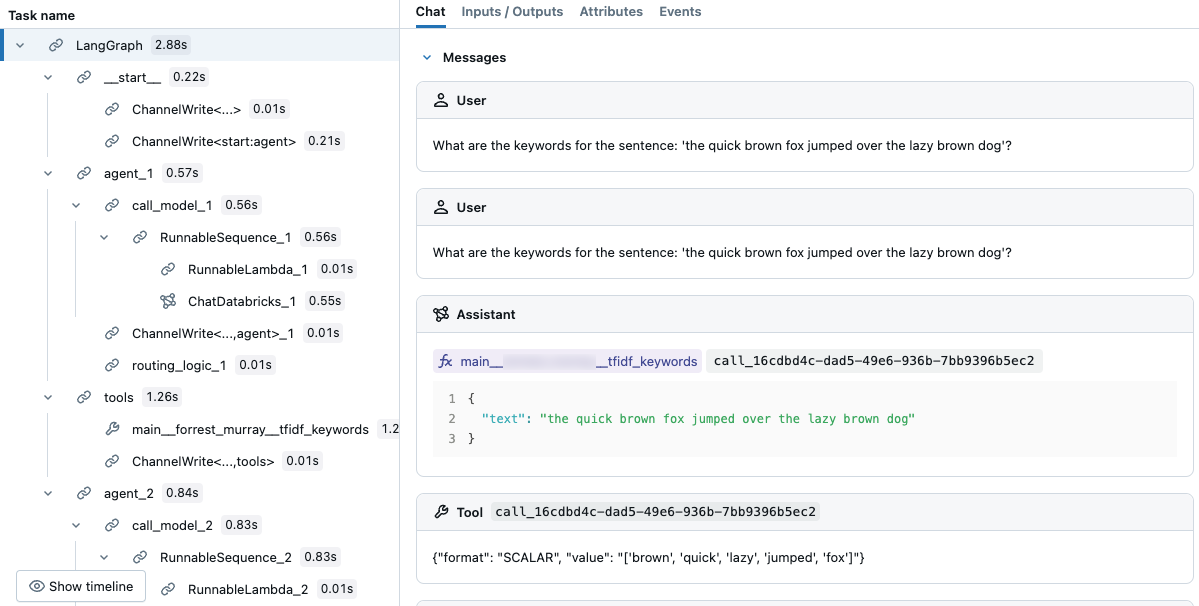
agent.invoke({"messages": [{"role": "user", "content":"What are the keywords for the sentence: 'the quick brown fox jumped over the lazy brown dog'?"}]})
In the resulting trace, you can see that the LLM selected the tool.
Use traces to debug agents
MLflow Tracing is a powerful tool for debugging and observing generative AI applications, including agents. It captures detailed execution information through spans, which encapsulate specific code segments and record inputs, outputs, and timing data.
For popular libraries like LangChain, enable automatic tracing with mlflow.langchain.autolog(). You can also use mlflow.start_span() to customize a trace. For example, you could add custom data value fields or labeling for observability. The code that runs in the context of that span gets associated with fields that you define. In this in-memory TF-IDF example, give it a name and a span type.
To learn more about tracing, see Agent observability with MLflow Tracing.
The following example creates a retriever tool using a simple in-memory TF-IDF index. It demonstrates both autologging for tool executions and custom span tracing for additional observability:
from sklearn.feature_extraction.text import TfidfVectorizer
import mlflow
from langchain_core.tools import tool
documents = parsed_docs_df
doc_vectorizer = TfidfVectorizer(stop_words="english")
tfidf_matrix = doc_vectorizer.fit_transform(documents["content"])
@tool
def find_relevant_documents(query, top_n=5):
"""gets relevant documents for the query"""
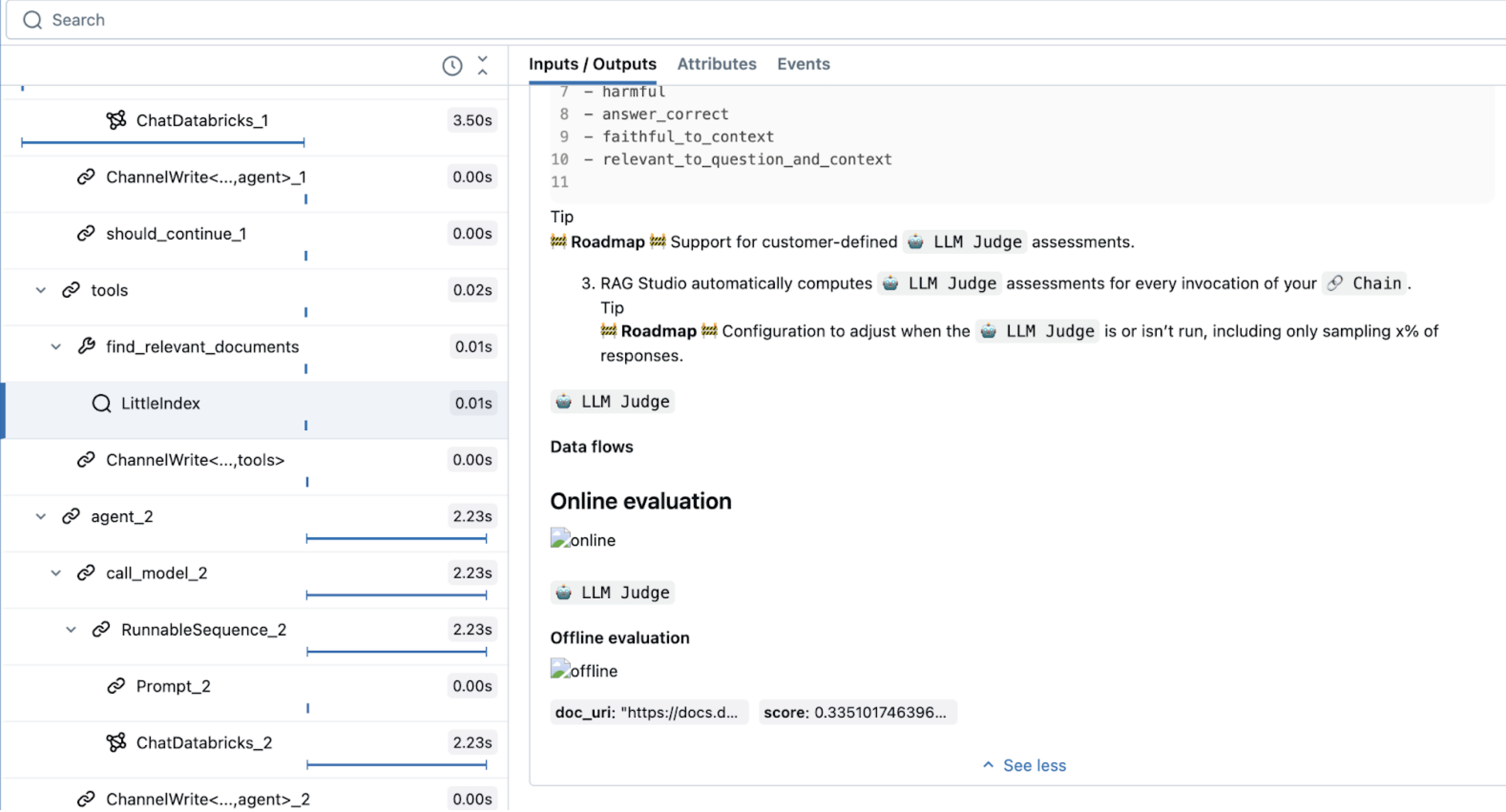
with mlflow.start_span(name="LittleIndex", span_type="RETRIEVER") as retriever_span:
retriever_span.set_inputs({"query": query})
retriever_span.set_attributes({"top_n": top_n})
query_tfidf = doc_vectorizer.transform([query])
similarities = (tfidf_matrix @ query_tfidf.T).toarray().flatten()
ranked_docs = sorted(enumerate(similarities), key=lambda x: x[1], reverse=True)
result = []
for idx, score in ranked_docs[:top_n]:
row = documents.iloc[idx]
content = row["content"]
doc_entry = {
"page_content": content,
"metadata": {
"doc_uri": row["doc_uri"],
"score": score,
},
}
result.append(doc_entry)
retriever_span.set_outputs(result)
return result
This code uses a special span type, RETRIEVER, which is reserved for retriever tools. Other Mosaic AI agent features (such as the AI Playground, review UI, and evaluation) use the RETRIEVER span type to display the retrieval results.
Retriever tools require you to specify their schema to ensure compatibility with downstream Databricks features. For more information about mlflow.models.set_retriever_schema, see Specify custom retriever schemas.
import mlflow
from mlflow.models import set_retriever_schema
uc_toolkit = UCFunctionToolkit(function_names=[f"{CATALOG}.{SCHEMA}.*"])
graph = create_tool_calling_agent(llm, tools=[*uc_toolkit.tools, find_relevant_documents])
mlflow.langchain.autolog()
set_retriever_schema(
primary_key="chunk_id",
text_column="chunk_text",
doc_uri="doc_uri",
other_columns=["title"],
)
graph.invoke(input = {"messages": [("user", "How do the docs say I use llm judges on databricks?")]})
Define the agent
The next step is to evaluate the agent and prepare it for deployment. At a high level, this involves the following:
- Define a predictable API for the agent using a signature.
- Add model configuration, which makes it easy to configure parameters.
- Log the model with dependencies that give it a reproducible environment and allow you to configure its authentication to other services.
The MLflow ChatAgent interface simplifies defining agent inputs and outputs. To use it, define your agent as a subclass of ChatAgent, implementing non-streaming inference with the predict function and streaming inference with the predict_stream function.
ChatAgent is agnostic to your choice of agent authoring framework, allowing you to easily test and use different frameworks and agent implementations - the only requirement is to implement the predict and predict_stream interfaces.
Authoring your agent using ChatAgent provides a number of benefits, including:
- Streaming output support
- Comprehensive tool-calling message history: Return multiple messages, including intermediate tool-calling messages, for improved quality and conversation management.
- Multi-agent system support
- Databricks feature integration: Out-of-the-box compatibility with AI Playground, Agent Evaluation, and Agent Monitoring.
- Typed authoring interfaces: Write agent code using typed Python classes, benefiting from IDE and notebook autocomplete.
For more information about authoring a ChatAgent see Use ChatAgent to author agents.
from mlflow.pyfunc import ChatAgent
from mlflow.types.agent import (
ChatAgentChunk,
ChatAgentMessage,
ChatAgentResponse,
ChatContext,
)
from typing import Any, Optional
class DocsAgent(ChatAgent):
def __init__(self, agent):
self.agent = agent
set_retriever_schema(
primary_key="chunk_id",
text_column="chunk_text",
doc_uri="doc_uri",
other_columns=["title"],
)
def predict(
self,
messages: list[ChatAgentMessage],
context: Optional[ChatContext] = None,
custom_inputs: Optional[dict[str, Any]] = None,
) -> ChatAgentResponse:
# ChatAgent has a built-in helper method to help convert framework-specific messages, like langchain BaseMessage to a python dictionary
request = {"messages": self._convert_messages_to_dict(messages)}
output = agent.invoke(request)
# Here 'output' is already a ChatAgentResponse, but to make the ChatAgent signature explicit for this demonstration, the code returns a new instance
return ChatAgentResponse(**output)
The following code shows how to use the ChatAgent.
AGENT = DocsAgent(agent=agent)
AGENT.predict(
{
"messages": [
{"role": "user", "content": "What is DLT in Databricks?"},
]
}
)
Configure agents with parameters
The Agent Framework lets you control agent execution with parameters. This means you can quickly test different agent configurations, like switching LLM endpoints or trying different tools without changing the underlying code.
The following code creates a config dictionary that sets agent parameters when initializing the model.
For more details about parameterizing agents, see Parametrize agent code for deployment across environments.
)
from mlflow.models import ModelConfig
baseline_config = {
"endpoint_name": "databricks-meta-llama-3-1-70b-instruct",
"temperature": 0.01,
"max_tokens": 1000,
"system_prompt": """You are a helpful assistant that answers questions about Databricks. Questions unrelated to Databricks are irrelevant.
You answer questions using a set of tools. If needed, you ask the user follow-up questions to clarify their request.
""",
"tool_list": ["catalog.schema.*"],
}
class DocsAgent(ChatAgent):
def __init__(self):
self.config = ModelConfig(development_config=baseline_config)
self.agent = self._build_agent_from_config()
def _build_agent_from_config(self):
temperature = config.get("temperature", 0.01)
max_tokens = config.get("max_tokens", 1000)
system_prompt = config.get("system_prompt", """You are a helpful assistant.
You answer questions using a set of tools. If needed you ask the user follow-up questions to clarify their request.""")
llm_endpoint_name = config.get("endpoint_name", "databricks-meta-llama-3-3-70b-instruct")
tool_list = config.get("tool_list", [])
llm = ChatDatabricks(endpoint=llm_endpoint_name, temperature=temperature, max_tokens=max_tokens)
toolkit = UCFunctionToolkit(function_names=tool_list)
agent = create_tool_calling_agent(llm, tools=[*toolkit.tools, find_relevant_documents], prompt=system_prompt)
return agent
Log the agent
After defining the agent, it's now ready to be logged. In MLflow, logging an agent means saving the agent's configuration (including dependencies) so it can be used for evaluation and deployment.
Note
When developing agents in a notebook, MLflow infers the agent's dependencies from the notebook environment.
To log an agent from a notebook, you can write all of the code that defines the model in a single cell, then use the %%writefile magic command to save the agent's definition to a file:
%%writefile agent.py
...
<Code that defines the agent>
If the agent requires access to external resources, such as Unity Catalog to execute the keyword extraction tool, you must configure authentication for the agent so it can access the resources when it's deployed.
To simplify authentication for Databricks resources, enable automatic authentication passthrough:
from mlflow.models.resources import DatabricksFunction, DatabricksServingEndpoint
resources = [
DatabricksServingEndpoint(endpoint_name=LLM_ENDPOINT_NAME),
DatabricksFunction(function_name=tool.uc_function_name),
]
with mlflow.start_run():
logged_agent_info = mlflow.pyfunc.log_model(
artifact_path="agent",
python_model="agent.py",
pip_requirements=[
"mlflow",
"langchain",
"langgraph",
"databricks-langchain",
"unitycatalog-langchain[databricks]",
"pydantic",
],
resources=resources,
)
To learn more about logging agents, see Code-based logging.
Evaluate the agent
The next step is to evaluate the agent to see how it performs. Agent Evaluation is challenging and raises many questions, such as the following:
- What are the right metrics to evaluate quality? How do I trust the outputs of these metrics?
- I need to evaluate many ideas - how do I…
- run evaluation quickly so most of my time isn’t spent waiting?
- quickly compare these different versions of my agent on quality, cost, and latency?
- How do I quickly identify the root cause of any quality problems?
As a data scientist or developer, you might not be the actual subject matter expert. The rest of this section describes Agent Evaluation tools that can help you define a good output.
Create an evaluation set
To define what quality means for an agent, you use metrics to measure the agent’s performance on an evaluation set. See Define “quality”: Evaluation sets.
With Agent Evaluation, you can create synthetic evaluation sets and measure quality by running evaluations. The idea is to start from the facts, like a set of documents, and “work backwards” by using those facts to generate a set of questions. You can condition the questions that are generated by providing some guidelines:
from databricks.agents.evals import generate_evals_df
import pandas as pd
databricks_docs_url = "https://raw.githubusercontent.com/databricks/genai-cookbook/refs/heads/main/quick_start_demo/chunked_databricks_docs_filtered.jsonl"
parsed_docs_df = pd.read_json(databricks_docs_url, lines=True)
agent_description = f"""
The agent is a RAG chatbot that answers questions about Databricks. Questions unrelated to Databricks are irrelevant.
"""
question_guidelines = f"""
# User personas
- A developer who is new to the Databricks platform
- An experienced, highly technical Data Scientist or Data Engineer
# Example questions
- what API lets me parallelize operations over rows of a delta table?
- Which cluster settings will give me the best performance when using Spark?
# Additional Guidelines
- Questions should be succinct, and human-like
"""
num_evals = 25
evals = generate_evals_df(
docs=parsed_docs_df[
:500
], # Pass your docs. They should be in a Pandas or Spark DataFrame with columns `content STRING` and `doc_uri STRING`.
num_evals=num_evals, # How many synthetic evaluations to generate
agent_description=agent_description,
question_guidelines=question_guidelines,
)
The generated evaluations include the following:
A request field that looks like the
ChatAgentRequestmentioned earlier:{"messages":[{"content":"What command must be run at the start of your workload to explicitly target the Workspace Model Registry if your workspace default catalog is in Unity Catalog and you use Databricks Runtime 13.3 LTS or above?","role":"user"}]}A list of “expected retrieved content”. The retriever schema was defined with
contentanddoc_urifields.[{"content":"If your workspace’s [default catalog](https://docs.databricks.com/data-governance/unity-catalog/create-catalogs.html#view-the-current-default-catalog) is in Unity Catalog (rather than `hive_metastore`) and you are running a cluster using Databricks Runtime 13.3 LTS or above, models are automatically created in and loaded from the workspace default catalog, with no configuration required. To use the Workspace Model Registry in this case, you must explicitly target it by running `import mlflow; mlflow.set_registry_uri(\"databricks\")` at the start of your workload.","doc_uri":"https://docs.databricks.com/machine-learning/manage-model-lifecycle/workspace-model-registry.html"}]A list of expected facts. When you compare two responses, it can be hard to find small differences between them. Expected facts distill what separates a correct answer from a partially correct answer from an incorrect answer and improve both the quality of the AI judges as well as the experience of the people working on the agent:
["The command must import the MLflow module.","The command must set the registry URI to \"databricks\"."]A source_id field which here is
SYNTHETIC_FROM_DOC. As you build more complete evaluation sets, the samples will come from various different sources, so this field distinguishes them.
To learn more about creating evaluation sets, see Synthesize evaluation sets.
Evaluate the agent using LLM judges
Manually evaluating an agent’s performance on so many generated examples will not scale well. At scale, using LLMs as judges is a much more reasonable solution. To use the built-in judges that are available when using Agent Evaluation, use the following code:
with mlflow.start_run(run_name="my_agent"):
eval_results = mlflow.evaluate(
data=evals, # Your evaluation set
model=model_info.model_uri, # Logged agent from above
model_type="databricks-agent", # activate Mosaic AI Agent Evaluation
)
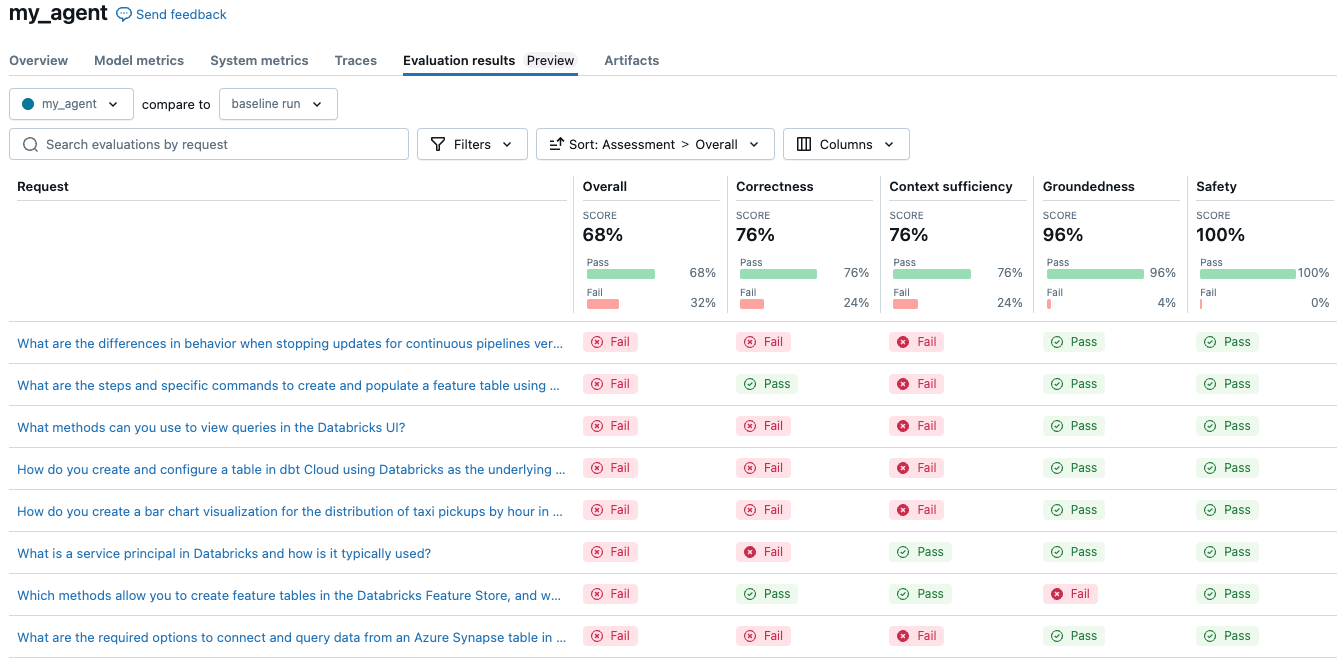
The simple agent scored 68% overall. Your results may differ here depending on the configuration you use. Running an experiment to compare three different LLMs for cost and quality is as simple as changing the configuration and re-evaluating.
Consider changing the model configuration to use a different LLM, system prompt, or temperature setting.
These judges can be customized to follow the same guidelines human experts would use to evaluate a response. For more information on LLM judges, see Built-in AI judges.
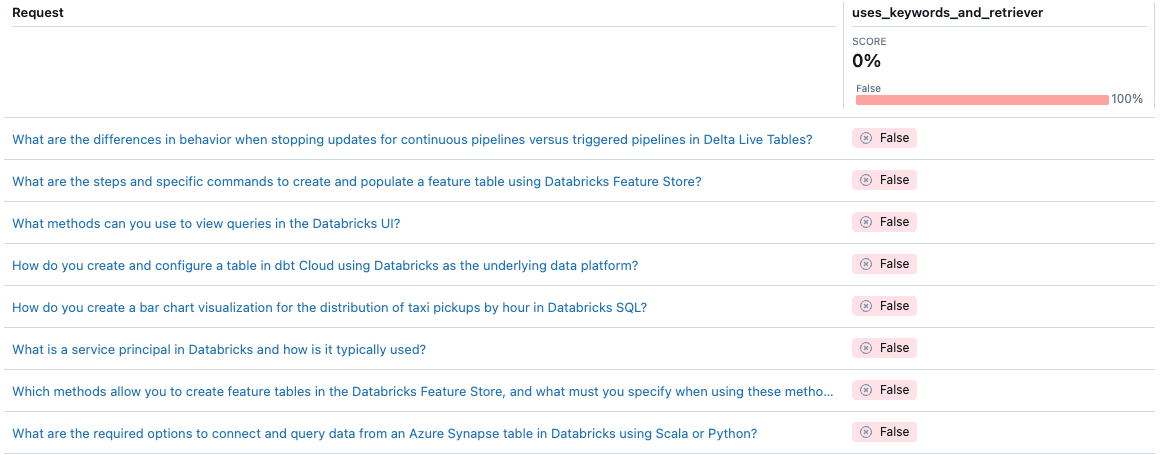
With Agent Evaluation, you can customize the way you measure the quality of a particular agent using custom metrics. You can think of the evaluation like an integration test, and individual metrics as unit tests. The following example uses a Boolean metric to check if the agent used both the keyword extraction and the retriever for a given request:
from databricks.agents.evals import metric
@metric
def uses_keywords_and_retriever(request, trace):
retriever_spans = trace.search_spans(span_type="RETRIEVER")
keyword_tool_spans = trace.search_spans(name=f"{CATALOG}__{SCHEMA}__tfidf_keywords")
return len(keyword_tool_spans) > 0 and len(retriever_spans) > 0
# same evaluate as above, with the addition of 'extra_metrics'
with mlflow.start_run(run_name="my_agent"):
eval_results = mlflow.evaluate(
data=evals, # Your evaluation set
model=model_info.model_uri, # Logged agent from above
model_type="databricks-agent", # activate Mosaic AI Agent Evaluation,
extra_metrics=[uses_keywords_and_retriever],
)
Note that the agent never uses the keyword extraction. How might you fix this issue?
Deploy and monitor the agent
When you're ready to start testing your agent with real users, Agent Framework provides a production-ready solution for serving the agent on Mosaic AI Model Serving.
Deploying agents to Model Serving provides the following benefits:
- Model Serving manages autoscaling, logging, version control, and access control, allowing you to focus on developing quality agents.
- Subject matter experts can use the Review App to interact with the agent and provide feedback that can be incorporated into your monitoring and evaluations.
- You can monitor the agent by running evaluations on live traffic. Although user traffic won’t include the ground truth, LLM judges (and the custom metric you created) perform an unsupervised evaluation.
The following code deploys the agents to a serving endpoint. For more information, see Deploy an agent for generative AI application.
from databricks import agents
import mlflow
# Connect to the Unity Catalog model registry
mlflow.set_registry_uri("databricks-uc")
# Configure UC model location
UC_MODEL_NAME = f"{CATALOG}.{SCHEMA}.getting_started_agent"
# REPLACE WITH UC CATALOG/SCHEMA THAT YOU HAVE `CREATE MODEL` permissions in
# Register to Unity Catalog
uc_registered_model_info = mlflow.register_model(
model_uri=model_info.model_uri, name=UC_MODEL_NAME
)
# Deploy to enable the review app and create an API endpoint
deployment_info = agents.deploy(
model_name=UC_MODEL_NAME, model_version=uc_registered_model_info.version
)