ORC format in Azure Data Factory and Synapse Analytics
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
Follow this article when you want to parse the ORC files or write the data into ORC format.
ORC format is supported for the following connectors: Amazon S3, Amazon S3 Compatible Storage, Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, HTTP, Oracle Cloud Storage and SFTP.
Dataset properties
For a full list of sections and properties available for defining datasets, see the Datasets article. This section provides a list of properties supported by the ORC dataset.
| Property | Description | Required |
|---|---|---|
| type | The type property of the dataset must be set to Orc. | Yes |
| location | Location settings of the file(s). Each file-based connector has its own location type and supported properties under location. See details in connector article -> Dataset properties section. |
Yes |
| compressionCodec | The compression codec to use when writing to ORC files. When reading from ORC files, Data Factories automatically determine the compression codec based on the file metadata. Supported types are none, zlib, snappy (default), and lzo. Note currently Copy activity doesn't support LZO when read/write ORC files. |
No |
Below is an example of ORC dataset on Azure Blob Storage:
{
"name": "OrcDataset",
"properties": {
"type": "Orc",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
}
}
}
}
Note the following points:
- Complex data types (e.g. MAP, LIST, STRUCT) are currently supported only in Data Flows, not in Copy Activity. To use complex types in data flows, do not import the file schema in the dataset, leaving schema blank in the dataset. Then, in the Source transformation, import the projection.
- White space in column name is not supported.
Copy activity properties
For a full list of sections and properties available for defining activities, see the Pipelines article. This section provides a list of properties supported by the ORC source and sink.
ORC as source
The following properties are supported in the copy activity *source* section.
| Property | Description | Required |
|---|---|---|
| type | The type property of the copy activity source must be set to OrcSource. | Yes |
| storeSettings | A group of properties on how to read data from a data store. Each file-based connector has its own supported read settings under storeSettings. See details in connector article -> Copy activity properties section. |
No |
ORC as sink
The following properties are supported in the copy activity *sink* section.
| Property | Description | Required |
|---|---|---|
| type | The type property of the copy activity sink must be set to OrcSink. | Yes |
| formatSettings | A group of properties. Refer to ORC write settings table below. | No |
| storeSettings | A group of properties on how to write data to a data store. Each file-based connector has its own supported write settings under storeSettings. See details in connector article -> Copy activity properties section. |
No |
Supported ORC write settings under formatSettings:
| Property | Description | Required |
|---|---|---|
| type | The type of formatSettings must be set to OrcWriteSettings. | Yes |
| maxRowsPerFile | When writing data into a folder, you can choose to write to multiple files and specify the max rows per file. | No |
| fileNamePrefix | Applicable when maxRowsPerFile is configured.Specify the file name prefix when writing data to multiple files, resulted in this pattern: <fileNamePrefix>_00000.<fileExtension>. If not specified, file name prefix will be auto generated. This property does not apply when source is file-based store or partition-option-enabled data store. |
No |
Mapping data flow properties
In mapping data flows, you can read and write to ORC format in the following data stores: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 and SFTP, and you can read ORC format in Amazon S3.
You can point to ORC files either using ORC dataset or using an inline dataset.
Source properties
The below table lists the properties supported by an ORC source. You can edit these properties in the Source options tab.
When using inline dataset, you will see additional file settings, which are the same as the properties described in dataset properties section.
| Name | Description | Required | Allowed values | Data flow script property |
|---|---|---|---|---|
| Format | Format must be orc |
yes | orc |
format |
| Wild card paths | All files matching the wildcard path will be processed. Overrides the folder and file path set in the dataset. | no | String[] | wildcardPaths |
| Partition root path | For file data that is partitioned, you can enter a partition root path in order to read partitioned folders as columns | no | String | partitionRootPath |
| List of files | Whether your source is pointing to a text file that lists files to process | no | true or false |
fileList |
| Column to store file name | Create a new column with the source file name and path | no | String | rowUrlColumn |
| After completion | Delete or move the files after processing. File path starts from the container root | no | Delete: true or false Move: [<from>, <to>] |
purgeFiles moveFiles |
| Filter by last modified | Choose to filter files based upon when they were last altered | no | Timestamp | modifiedAfter modifiedBefore |
| Allow no files found | If true, an error is not thrown if no files are found | no | true or false |
ignoreNoFilesFound |
Source example
The associated data flow script of an ORC source configuration is:
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'orc') ~> OrcSource
Sink properties
The below table lists the properties supported by an ORC sink. You can edit these properties in the Settings tab.
When using inline dataset, you will see additional file settings, which are the same as the properties described in dataset properties section.
| Name | Description | Required | Allowed values | Data flow script property |
|---|---|---|---|---|
| Format | Format must be orc |
yes | orc |
format |
| Clear the folder | If the destination folder is cleared prior to write | no | true or false |
truncate |
| File name option | The naming format of the data written. By default, one file per partition in format part-#####-tid-<guid> |
no | Pattern: String Per partition: String[] As data in column: String Output to single file: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Sink example
The associated data flow script of an ORC sink configuration is:
OrcSource sink(
format: 'orc',
filePattern:'output[n].orc',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> OrcSink
Using Self-hosted Integration Runtime
Important
For copy empowered by Self-hosted Integration Runtime e.g. between on-premises and cloud data stores, if you are not copying ORC files as-is, you need to install the 64-bit JRE 8 (Java Runtime Environment) or OpenJDK and Microsoft Visual C++ 2010 Redistributable Package on your IR machine. Check the following paragraph with more details.
For copy running on Self-hosted IR with ORC file serialization/deserialization, the service locates the Java runtime by firstly checking the registry (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) for JRE, if not found, secondly checking system variable JAVA_HOME for OpenJDK.
- To use JRE: The 64-bit IR requires 64-bit JRE. You can find it from here.
- To use OpenJDK: It's supported since IR version 3.13. Package the jvm.dll with all other required assemblies of OpenJDK into Self-hosted IR machine, and set system environment variable JAVA_HOME accordingly.
- To install Visual C++ 2010 Redistributable Package: Visual C++ 2010 Redistributable Package is not installed with self-hosted IR installations. You can find it from here.
Tip
If you copy data to/from ORC format using Self-hosted Integration Runtime and hit error saying "An error occurred when invoking java, message: java.lang.OutOfMemoryError:Java heap space", you can add an environment variable _JAVA_OPTIONS in the machine that hosts the Self-hosted IR to adjust the min/max heap size for JVM to empower such copy, then rerun the pipeline.
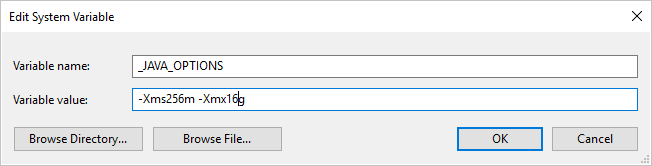
Example: set variable _JAVA_OPTIONS with value -Xms256m -Xmx16g. The flag Xms specifies the initial memory allocation pool for a Java Virtual Machine (JVM), while Xmx specifies the maximum memory allocation pool. This means that JVM will be started with Xms amount of memory and will be able to use a maximum of Xmx amount of memory. By default, the service uses min 64 MB and max 1G.