Data Quality
Data quality is a management function of cloud-scale analytics. It resides in the data management landing zone and is a core part of governance.
Data quality considerations
Data quality is the responsibility of every individual who creates and consumes data products. Creators should adhere to the global and domain rules, while consumers should report data inconsistencies to the owning data domain via a feedback loop.
Because data quality affects all the data provided to the board, it should start at the top of the organization. The board should have insights into the quality of data provided to them.
However, being proactive still requires you to have data quality experts who can clean buckets of data that require remediation. Avoid pushing this work to a central team and instead target the data domain, with specific data knowledge, for cleansing the data.
Data quality metrics
Data quality metrics are key to assessing and increasing the quality of your data products. At a global and domain level, you need to decide upon your quality metrics. At a minimum, we recommend the following metrics:
| Metrics | Metrics Definitions |
|---|---|
| Completeness = % total of non-nulls + nonblanks | Measures data availability, fields in the dataset that aren't empty, and default values that were changed. For example, if a record includes 01/01/1900 as a date of birth, it's highly likely that the field was never populated. |
| Uniqueness = % of nonduplicate values | Measures distinct values in a given column compared to the number of rows in the table. For example, given four distinct color values (red, blue, yellow, and green) in a table with five rows, that field is 80% (or 4/5) unique. |
| Consistency = % of data having patterns | Measures compliance within a given column to its expected data type or format. For example, an email field containing formatted email addresses, or a name field with numeric values. |
| Validity = % of reference matching | Measures successful data matching to its domain reference set. For example, given a country/region field (complying with taxonomy values) in a transactional records system, the value of "US of A" isn't valid. |
| Accuracy = % of unaltered values | Measures successful reproduction of the intended values across multiple systems. For example, if an invoice itemizes a SKU and extended price that differs from the original order, the invoice line item is inaccurate. |
| Linkage = % of well-integrated data | Measures successful association to its companion reference details in another system. For example, if an invoice itemizes an incorrect SKU or product description, the invoice line item isn't linkable. |
Data profiling
Data profiling examines data products that are registered in the data catalog and collects statistics and information about that data. To provide summary and trend views about the data quality over time, store this data in your metadata repository against the data product.
Data profiles help users answer questions about data products, including:
- Can it be used to solve my business problem?
- Does the data conform to particular standards or patterns?
- What are some of the anomalies of the data source?
- What are the possible challenges of integrating this data into my application?
Users can view the data product profile by using a reporting dashboard within their data marketplace.
You can report on such items as:
- Completeness: Indicates the percentage of data that isn't blank or null.
- Uniqueness: Indicates the percentage of data that isn't duplicated.
- Consistency: Indicates data where data integrity is maintained.
Data quality recommendations
To implement data quality, you need to use both human and computational power as follows:
Use solutions that include algorithms, rules, data profiling, and metrics.
Use domain experts who can step in when there's a requirement to train an algorithm due to a high number of errors passing through the compute layer.
Validate early. Traditional solutions apply data quality checks after extracting, transforming, and loading the data. By this time, the data product is already being consumed and errors surfaced to downstream data products. Instead, as data is ingested from the source, implement data quality checks near the sources and before downstream consumers use the data products. If there's batch ingestion from the data lake, do these checks when you move data from raw to enriched.
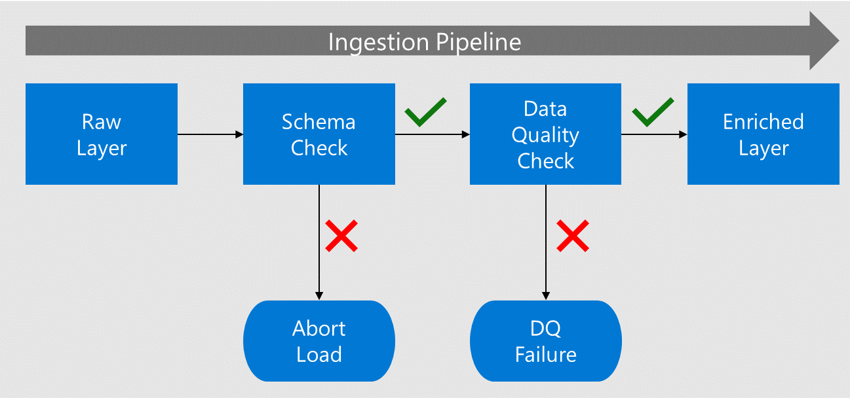
Before data is moved to the enriched layer, its schema and columns are checked against the metadata registered in the data catalog.
If the data contains errors, the load is stopped, and the data application team is notified of the failure.
If the schema and column checks pass, the data is loaded into the enriched layers with conformed data types.
Before you move to the enriched layer, a data quality process checks for compliance against the algorithms and rules.

Tip
Define data quality rules at both a global and domain level. Doing so allows the business to define its standards for every created data product and allows data domains to create additional rules related to their domain.
Data quality solutions
We recommend evaluating Microsoft Purview Data Quality as a solution for assessing and managing data quality, which is crucial for reliable AI-driven insights and decision-making. It includes:
- No-code/low-code rules: Evaluate data quality using out-of-the-box, AI-generated rules.
- AI-powered data profiling: Recommends columns for profiling and allows human intervention for refinement.
- Data quality scoring: Provides scores for data assets, data products, and governance domains.
- Data quality alerts: Notifies data owners of quality issues.
For more information, see What is Data Quality.
If your organization decides to implement Azure Databricks to manipulate data, then you should assess the data quality controls, testing, monitoring, and enforcement that this solution offers. Using expectations can capture data quality issues at ingestion before they affect related child data products. For more information, see Establish data quality standards and Data Quality Management With Databricks.
You can also choose from partners, open-source, and custom options for a data quality solution.
Data quality summary
Fixing data quality can have serious consequences for a business. It can lead to business units interpreting data products in different ways. This misinterpretation can prove costly to the business if decisions are based on data products with lower data quality. Fixing data products with missing attributes can be an expensive task and could require full reloads of data from several periods.
Validate data quality early and put processes in place to proactively address poor data quality. For example, a data product can't be released to production until it achieves a certain amount of completeness.
You can use tooling as a free choice, but ensure it includes expectations (rules), data metrics, profiling, and the ability to secure the expectations so that you can implement global and domain-based expectations.