Manage data quality with pipeline expectations
Use expectations to apply quality constraints that validate data as it flows through ETL pipelines. Expectations provide greater insight into data quality metrics and allow you to fail updates or drop records when detecting invalid records.
This article provides an overview of expectations, including syntax examples and behavior options. For more advanced use cases and recommended best practices, see Expectation recommendations and advanced patterns.
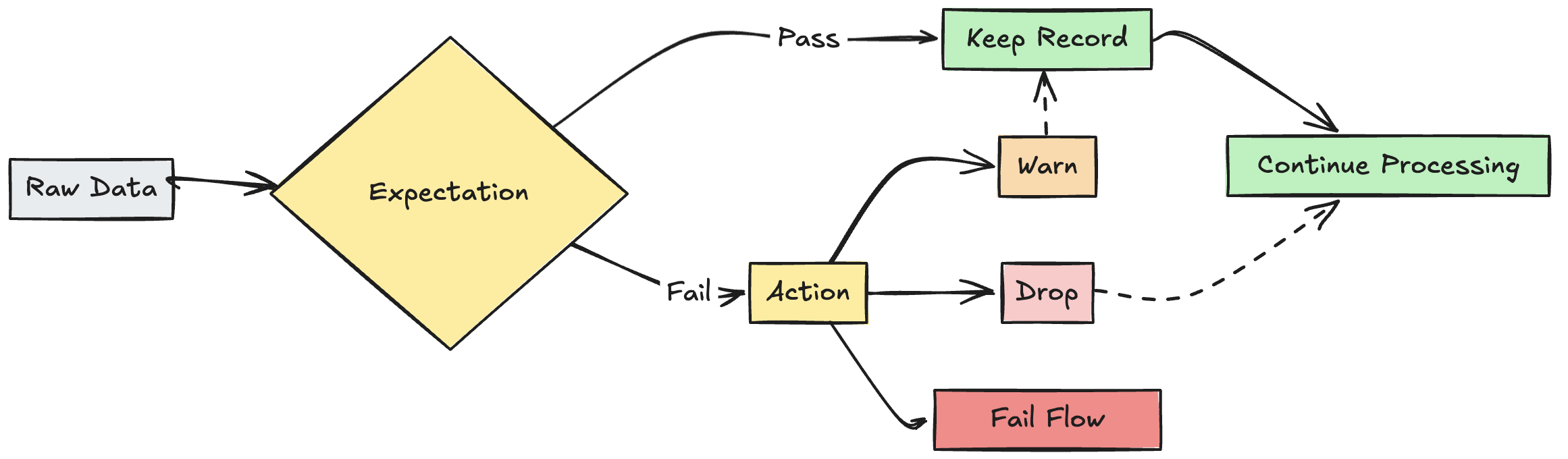
What are expectations?
Expectations are optional clauses in pipeline materialized view, streaming table, or view creation statements that apply data quality checks on each record passing through a query. Expectations use standard SQL Boolean statements to specify constraints. You can combine multiple expectations for a single dataset and set expectations across all dataset declarations in a pipeline.
The following sections introduce the three components of an expectation and provide syntax examples.
Expectation name
Each expectation must have a name, which is used as an identifier to track and monitor the expectation. Choose a name that communicates the metrics being validated. The following example defines the expectation valid_customer_age to confirm that age is between 0 and 120 years:
Important
An expectation name must be unique for a given dataset. You can reuse expectations across multiple datasets in a pipeline. See Portable and reusable expectations.
Python
@dlt.table
@dlt.expect("valid_customer_age", "age BETWEEN 0 AND 120")
def customers():
return spark.readStream.table("datasets.samples.raw_customers")
SQL
CREATE OR REFRESH STREAMING TABLE customers(
CONSTRAINT valid_customer_age EXPECT (age BETWEEN 0 AND 120)
) AS SELECT * FROM STREAM(datasets.samples.raw_customers);
Constraint to evaluate
The constraint clause is a SQL conditional statement that must evaluate to true or false for each record. The constraint contains the actual logic for what is being validated. When a record fails this condition, the expectation is triggered.
Constraints must use valid SQL syntax and cannot contain the following:
- Custom Python functions
- External service calls
- Subqueries referencing other tables
The following are examples of constraints that could be added to dataset creation statements:
Python
# Simple constraint
@dlt.expect("non_negative_price", "price >= 0")
# SQL functions
@dlt.expect("valid_date", "year(transaction_date) >= 2020")
# CASE statements
@dlt.expect("valid_order_status", """
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
""")
# Multiple constraints
@dlt.expect("non_negative_price", "price >= 0")
@dlt.expect("valid_purchase_date", "date <= current_date()")
# Complex business logic
@dlt.expect(
"valid_subscription_dates",
"""start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'"""
)
# Complex boolean logic
@dlt.expect("valid_order_state", """
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
""")
SQL
-- Simple constraint
CONSTRAINT non_negative_price EXPECT (price >= 0)
-- SQL functions
CONSTRAINT valid_date EXPECT (year(transaction_date) >= 2020)
-- CASE statements
CONSTRAINT valid_order_status EXPECT (
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
)
-- Multiple constraints
CONSTRAINT non_negative_price EXPECT (price >= 0)
CONSTRAINT valid_purchase_date EXPECT (date <= current_date())
-- Complex business logic
CONSTRAINT valid_subscription_dates EXPECT (
start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'
)
-- Complex boolean logic
CONSTRAINT valid_order_state EXPECT (
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
)
Action on invalid record
You must specify an action to determine what happens when a record fails the validation check. The following table describes the available actions:
| Action | SQL syntax | Python syntax | Result |
|---|---|---|---|
| warn (default) | EXPECT |
dlt.expect |
Invalid records are written to the target. The count of valid and invalid records is logged alongside other dataset metrics. |
| drop | EXPECT ... ON VIOLATION DROP ROW |
dlt.expect_or_drop |
Invalid records are dropped before data is written to the target. The count of dropped records is logged alongside other dataset metrics. |
| fail | EXPECT ... ON VIOLATION FAIL UPDATE |
dlt.expect_or_fail |
Invalid records prevent the update from succeeding. Manual intervention is required before reprocessing. This expectation causes a failure of a single flow and does not cause other flows in your pipeline to fail. |
You can also implement advanced logic to quarantine invalid records without failing or dropping data. See Quarantine invalid records.
Expectation tracking metrics
You can see tracking metrics for warn or drop actions from the pipeline UI. Because fail causes the update to fail when an invalid record is detected, metrics are not recorded.
To view expectation metrics, complete the following steps:
- Click DLT in the sidebar.
- Click the Name of your pipeline.
- Click a dataset with an expectation defined.
- Select the Data quality tab in the right sidebar.
You can view data quality metrics by querying the DLT event log. See Query data quality from the event log.
Retain invalid records
Retaining invalid records is the default behavior for expectations. Use the expect operator when you want to keep records that violate the expectation but collect metrics on how many records pass or fail a constraint. Records that violate the expectation are added to the target dataset along with valid records:
Python
@dlt.expect("valid timestamp", "timestamp > '2012-01-01'")
SQL
CONSTRAINT valid_timestamp EXPECT (timestamp > '2012-01-01')
Drop invalid records
Use the expect_or_drop operator to prevent further processing of invalid records. Records that violate the expectation are dropped from the target dataset:
Python
@dlt.expect_or_drop("valid_current_page", "current_page_id IS NOT NULL AND current_page_title IS NOT NULL")
SQL
CONSTRAINT valid_current_page EXPECT (current_page_id IS NOT NULL and current_page_title IS NOT NULL) ON VIOLATION DROP ROW
Fail on invalid records
When invalid records are unacceptable, use the expect_or_fail operator to stop execution immediately when a record fails validation. If the operation is a table update, the system atomically rolls back the transaction:
Python
@dlt.expect_or_fail("valid_count", "count > 0")
SQL
CONSTRAINT valid_count EXPECT (count > 0) ON VIOLATION FAIL UPDATE
Important
If you have multiple parallel flows defined in a pipeline, failure of a single flow does not cause other flows to fail.
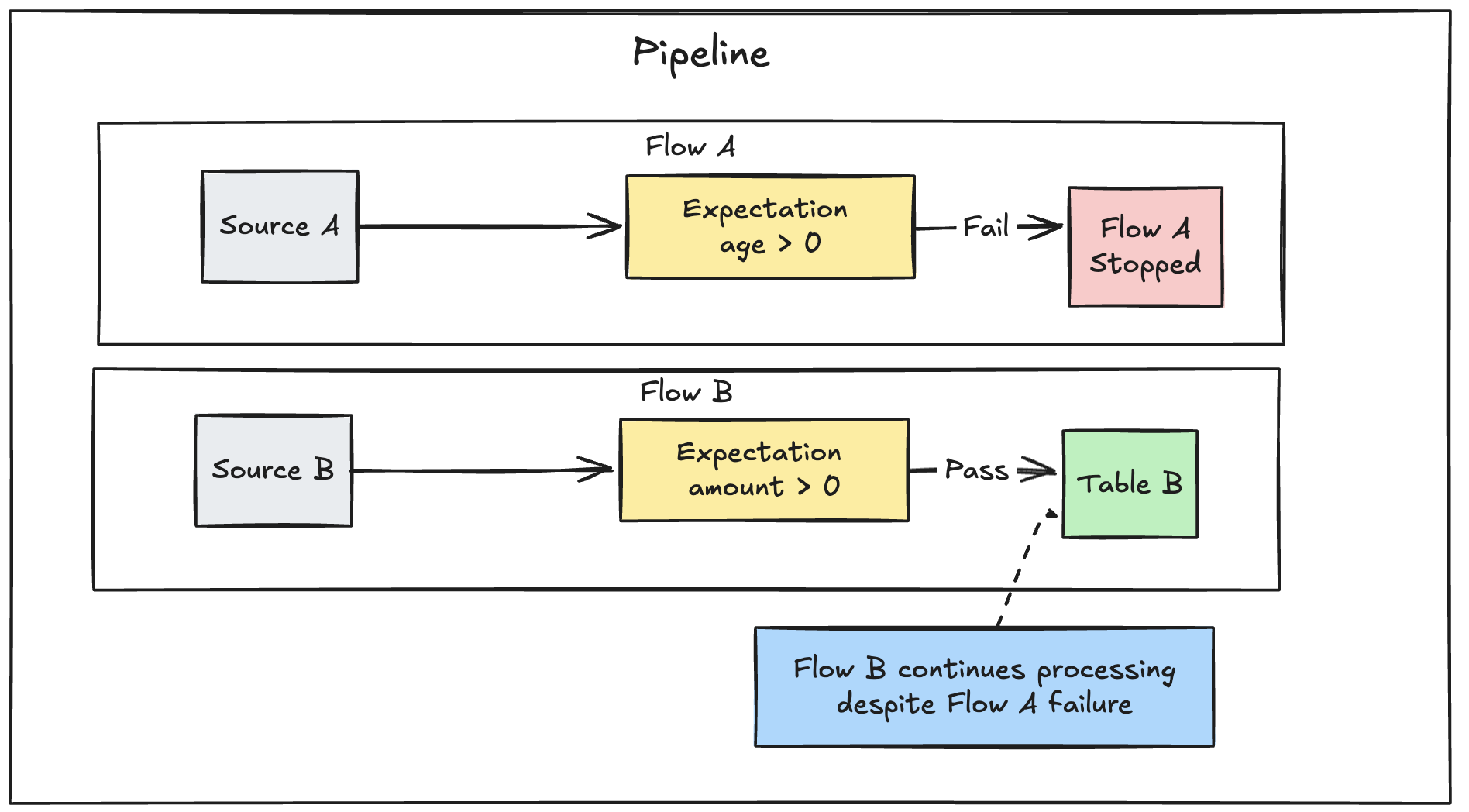
Troubleshooting failed updates from expectations
When a pipeline fails because of an expectation violation, you must fix the pipeline code to handle the invalid data correctly before re-running the pipeline.
Expectations configured to fail pipelines modify the Spark query plan of your transformations to track information required to detect and report violations. You can use this information to identify which input record resulted in the violation for many queries. The following is an example expectation:
Expectation Violated:
{
"flowName": "sensor-pipeline",
"verboseInfo": {
"expectationsViolated": [
"temperature_in_valid_range"
],
"inputData": {
"id": "TEMP_001",
"temperature": -500,
"timestamp_ms": "1710498600"
},
"outputRecord": {
"sensor_id": "TEMP_001",
"temperature": -500,
"change_time": "2024-03-15 10:30:00"
},
"missingInputData": false
}
}
Multiple expectations management
Note
While both SQL and Python support multiple expectations within a single dataset, only Python allows you to group multiple separate expectations together and specify collective actions.
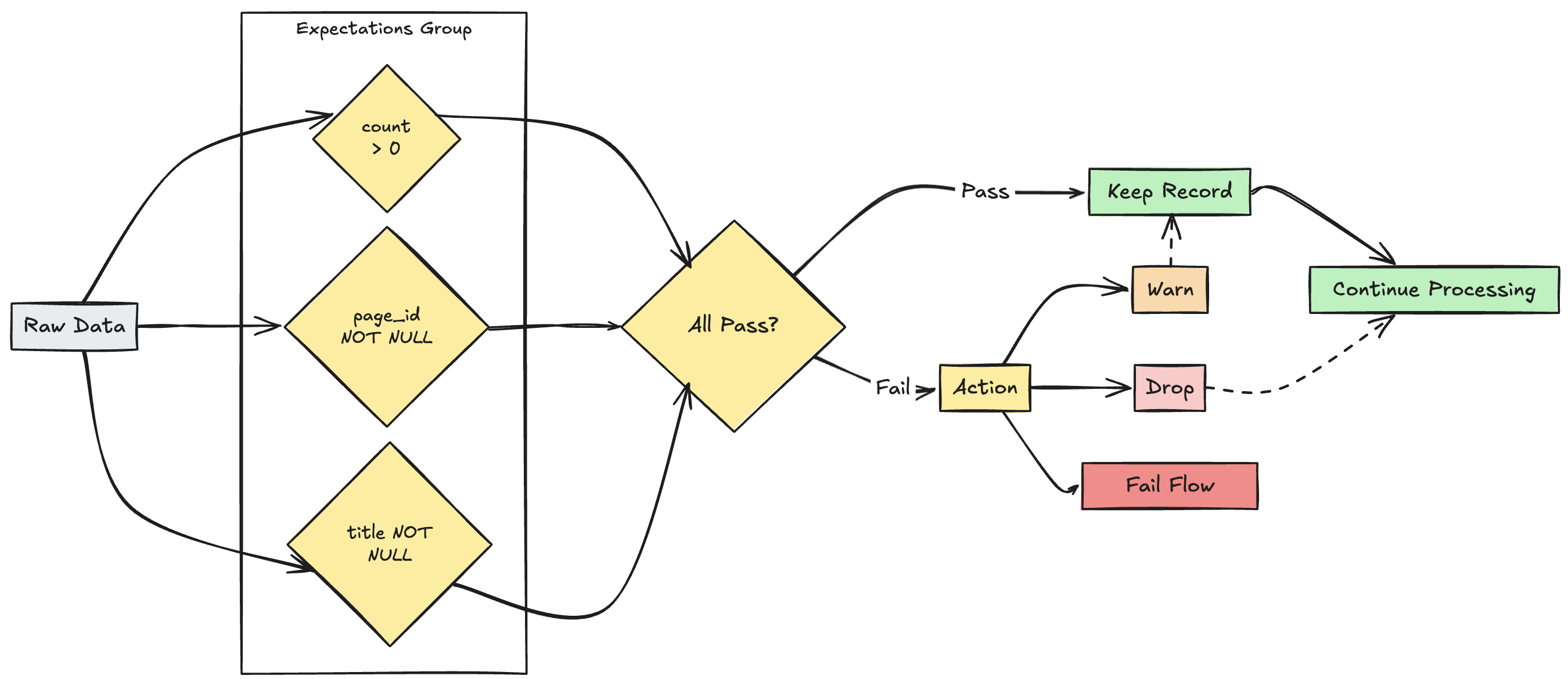
You can group multiple expectations together and specify collective actions using the functions expect_all, expect_all_or_drop, and expect_all_or_fail.
These decorators accept a Python dictionary as an argument, where the key is the expectation name and the value is the expectation constraint. You can reuse the same set of expectations in multiple datasets in your pipeline. The following shows examples of each of the expect_all Python operators:
valid_pages = {"valid_count": "count > 0", "valid_current_page": "current_page_id IS NOT NULL AND current_page_title IS NOT NULL"}
@dlt.table
@dlt.expect_all(valid_pages)
def raw_data():
# Create a raw dataset
@dlt.table
@dlt.expect_all_or_drop(valid_pages)
def prepared_data():
# Create a cleaned and prepared dataset
@dlt.table
@dlt.expect_all_or_fail(valid_pages)
def customer_facing_data():
# Create cleaned and prepared to share the dataset