Respuestas a las preguntas más frecuentes sobre la previsión en AutoML
SE APLICA A:  SDK de Python azure-ai-ml v2 (actual)
SDK de Python azure-ai-ml v2 (actual)
En este artículo se responden preguntas comunes sobre la previsión en el aprendizaje automático (AutoML). Para obtener información general sobre la metodología de previsión en AutoML, consulte el artículo Introducción a los métodos de previsión en AutoML.
¿Cómo empezar a crear modelos de previsión en AutoML?
Para empezar, lea el artículo Configuración de AutoML para entrenar un modelo de previsión de series temporales. También puede encontrar ejemplos prácticos en varios cuadernos de Jupyter:
- Ejemplo de recurso compartido sobre bicicletas
- Previsión mediante aprendizaje profundo
- Solución de muchos modelos
- Recetas de previsión
- Escenarios de previsión avanzados
¿Por qué AutoML es lento con mis datos?
Seguimos trabajando para que AutoML sea cada vez sea más rápido y escalable. Para trabajar como una plataforma de previsión general, AutoML realiza validaciones de datos extensas e ingeniería de características complejas y, además, busca en un espacio de modelos grande. Esta complejidad puede requerir mucho tiempo, en función de los datos y la configuración.
Un origen común del entorno de ejecución lento es entrenar AutoML con la configuración predeterminada en datos que contengan numerosas series temporales. El costo de muchos métodos de previsión se escala con el número de series. Por ejemplo, métodos como Exponential Smoothing y Prophet entrenan un modelo para cada serie temporal en los datos de entrenamiento.
La característica Muchos modelos de AutoML se escala a estos escenarios mediante la distribución de trabajos de entrenamiento en un clúster de proceso. Se ha aplicado correctamente a los datos con millones de series temporales. Para más información, consulte la sección del artículo muchos modelos . También puede leer sobre el éxito de Muchos modelos en un conjunto de datos de competición de alto perfil.
¿Cómo puedo hacer que AutoML vaya más rápido?
Vea la respuesta ¿Por qué AutoML es lento con mis datos? para comprender por qué AutoML podría ser lento en su caso.
Tenga en cuenta los siguientes cambios de configuración que podrían acelerar el trabajo:
- Bloquear modelos de serie temporal como ARIMA y Prophet.
- Desactivar características de búsqueda inversa, como retardos y ventanas graduales.
- Reduzca:
- El número de pruebas o iteraciones.
- El tiempo de espera de prueba o iteración.
- El tiempo de espera del experimento.
- El número de plegamientos de validación cruzada.
- Asegúrese de que la finalización anticipada está habilitada.
¿Qué configuración de modelado debería usar?
La previsión de AutoML admite cuatro configuraciones básicas:
| Configuración | Escenario | Ventajas | Desventajas |
|---|---|---|---|
| AutoML predeterminado | Es el que recomendamos si el conjunto de datos tiene un pequeño número de series temporales que tienen un comportamiento histórico similar. | - Fácil de configurar desde el código o SDK, o bien Estudio de Azure Machine Learning. - AutoML puede aprender entre series temporales diferentes porque los modelos de regresión agrupan todas las series en el entrenamiento. Para obtener más información, consulte Agrupación del modelo. |
- Los modelos de regresión podrían ser menos precisos si la serie temporal de los datos de entrenamiento tuviera un comportamiento divergente. - Los modelos de serie temporal podrían tardar mucho tiempo en entrenarse si hubiera un gran número de serie en los datos de entrenamiento. Para obtener más información, consulte la respuesta a Por qué AutoML es lento en mis datos. |
| AutoML con aprendizaje profundo | Se recomienda para conjuntos de datos con más de 1000 observaciones y, potencialmente, numerosas series temporales que presenten patrones complejos. Cuando se habilite, AutoML barrerá los modelos de redes neuronales convolucionales temporales (TCN) durante el entrenamiento. Para obtener más información, consulte Habilitación del aprendizaje profundo. | - Fácil de configurar desde el código o SDK, o bien Estudio de Azure Machine Learning. - Oportunidades de aprendizaje cruzado por los datos de los grupos de TCN en todas las series. - Una precisión potencialmente mayor debido a la gran capacidad de los modelos de red neuronal profunda (DNN). Para obtener más información, consulte Modelos de previsión en AutoML. |
- El entrenamiento puede tardar mucho más por la complejidad de los modelos de DNN. - Es poco probable que las series con pequeñas cantidades de historial se beneficien de estos modelos. |
| Varios modelos | Es lo que recomendamos si necesita entrenar y administrar un gran número de modelos de previsión de forma escalable. Para más información, consulte la sección del artículo muchos modelos . | - Escalable. - Una precisión potencialmente mayor cuando las series temporales tienen un comportamiento divergente entre sí. |
- Sin aprendizaje entre series temporales. - No se puede configurar ni ejecutar trabajos de Muchos modelos desde el Estudio de Azure Machine Learning. Actualmente solo está disponible la experiencia de código o SDK. |
| Serie temporal jerárquica (HTS) | Se recomienda si la serie de los datos tiene una estructura jerárquica anidada y necesita entrenar o realizar previsiones en niveles agregados de la jerarquía. Para más información, consulte la sección del artículo Previsión jerárquica de series temporales. | - El entrenamiento en niveles agregados puede reducir el ruido en la serie temporal del nodo hoja y, posiblemente, provocar modelos de mayor precisión. Se pueden recuperar previsiones para cualquier nivel de la jerarquía mediante la agregación o desagregación de previsiones del nivel de entrenamiento. |
- Debe proporcionar el nivel de agregación para el entrenamiento. AutoML no tiene actualmente un algoritmo para encontrar un nivel óptimo. |
Nota:
Se recomienda usar nodos de proceso con GPU cuando se habilite el aprendizaje profundo para aprovechar mejor la alta capacidad de DNN. El tiempo de entrenamiento puede ser mucho más rápido en comparación con los nodos con solo CPU. Para obtener más información, consulte el artículo Tamaños de máquinas virtuales optimizadas para GPU.
Nota:
HTS está diseñado para tareas en las que se requiere entrenamiento o predicción en niveles agregados en la jerarquía. En el caso de los datos jerárquicos que solo requieren entrenamiento y predicción de nodos hoja, use mejor Muchos modelos en su lugar.
¿Cómo puedo evitar el sobreajuste y la pérdida de datos?
AutoML usa procedimientos recomendados de aprendizaje automático, como la selección de modelos validados de manera cruzada, que mitigan muchos problemas de sobreajuste. Sin embargo, hay otras fuentes potenciales de sobreajuste:
Los datos de entrada contienen columnas de características derivadas del destino con una fórmula simple. Por ejemplo, una característica que es un múltiplo exacto del destino puede dar lugar a una puntuación de entrenamiento casi perfecta. Sin embargo, es probable que el modelo no se generalice en los datos fuera de muestra. Se recomienda explorar los datos antes del entrenamiento del modelo y quitar columnas que "filtren" la información de destino.
Los datos de entrenamiento usan características que no se conocen en el futuro hasta el horizonte de previsión. Actualmente, los modelos de regresión de AutoML asumen que todas las características se conocen en el horizonte de previsión. Le recomendamos que explore los datos antes del entrenamiento y quite las columnas de características que se conocen solo históricamente.
Existen diferencias estructurales significativas (cambios en el régimen) entre las partes de entrenamiento, validación o prueba de los datos. Por ejemplo, considere el efecto de la pandemia de la COVID-19 a petición de casi cualquier bien durante 2020 y 2021. Este es un ejemplo clásico de un cambio de régimen. El sobreajuste debido al cambio del régimen es el problema más difícil de abordar porque depende de un escenario muy alto y puede requerir un conocimiento profundo para identificar.
Como primera línea de defensa, intente reservar del 10 al 20 por ciento del historial total para la validación de datos o la validación cruzada de datos. No siempre es posible reservar esta cantidad de datos de validación si el historial de entrenamiento es corto, pero es un procedimiento recomendado. Para obtener más información, consulte Datos de entrenamiento y validación.
¿Qué significa si mi trabajo de entrenamiento logra puntuaciones de validación perfectas?
Es posible ver puntuaciones perfectas al ver las métricas de validación de un trabajo de entrenamiento. Una puntuación perfecta significa que la previsión y los datos reales del conjunto de validación son los mismos o casi iguales. Por ejemplo, tiene una raíz del error cuadrático medio igual a 0,0 o una puntuación de R2 de 1,0.
Una puntuación de validación perfecta generalmente indica de que el modelo está muy sobreajustado, probablemente debido a fugas de datos. La mejor forma de proceder es inspeccionar los datos en busca de fugas y eliminar las columnas que las causan.
¿Qué ocurre si mis datos de serie temporal no tienen observaciones espaciadas periódicamente?
Los modelos de previsión de AutoML requieren que los datos de entrenamiento tengan observaciones espaciadas periódicamente con respecto al calendario. Este requisito incluye casos como observaciones mensuales o anuales en los que el número de días entre observaciones puede variar. Es posible que los datos dependientes del tiempo no cumplan este requisito en dos casos:
Los datos tienen una frecuencia bien definida, pero faltan observaciones que crean brechas en la serie. En este caso, AutoML intentará detectar la frecuencia, rellenar nuevas observaciones para los huecos e imputar los valores de destino y características que falten. Opcionalmente, el usuario puede configurar los métodos de imputación a través de la configuración del SDK o a través de la interfaz de usuario web. Para obtener más información, consulte Caracterización personalizada.
Los datos no tienen una frecuencia bien definida. Es decir, la duración entre observaciones no tiene un patrón perceptible. Los datos transaccionales, como los de un sistema de punto de venta, son un ejemplo. En este caso, puede configurar AutoML para agregar los datos a una frecuencia elegida. Puede elegir una frecuencia regular que mejor se ajuste a los datos y a los objetivos de modelado. Para obtener más información, consulte Agregación de datos.
¿Cómo elegir la métrica principal?
La métrica principal es importante porque su valor en los datos de validación determina el mejor modelo durante el barrido y la selección. El error cuadrático medio normalizado (NRMSE) y el error medio normalizado absoluto (NMAE) suelen ser las mejores opciones para la métrica principal en las tareas de previsión.
Para elegir entre ellos, tenga en cuenta que NRMSE penaliza los valores atípicos en los datos de entrenamiento más que NMAE porque usa el cuadrado del error. El NMAE podría ser una mejor opción si desea que el modelo sea menos sensible a los valores atípicos. Para obtener más información, consulte la guía Métricas de regresión y previsión.
Nota
No se recomienda usar la puntuación R2 o R2 como métrica principal para la previsión.
Nota
AutoML no admite funciones personalizadas o proporcionadas por el usuario para la métrica principal. Debe elegir una de las métricas principales predefinidas que admite AutoML.
¿Cómo puedo mejorar la precisión de mi modelo?
- Asegúrese de configurar AutoML de la mejor manera para los datos. Para obtener más información, consulte la respuesta ¿Qué configuración de modelado debería usar?
- Consulte el cuaderno de recetas de previsión para obtener guías paso a paso sobre cómo crear y mejorar los modelos de previsión.
- Evalúe el modelo mediante pruebas inversas en varios ciclos de previsión. Este procedimiento proporciona una estimación más sólida del error de previsión y proporciona una base de referencia para medir las mejoras. Como ejemplo, consulte el cuaderno de pruebas.
- Si los datos son ruidosos, considere la posibilidad de agregarlos a una frecuencia más gruesa para aumentar la relación señal-ruido. Para obtener más información, consulte Frecuencia y agregación de datos de destino.
- Agregue nuevas características que puedan ayudar a predecir el destino. La experiencia en la materia puede ayudar considerablemente cuando seleccione datos de entrenamiento.
- Compare los valores de las métricas de validación y prueba, y determine si el modelo seleccionado infraajusta o sobreajusta los datos. Este conocimiento puede guiarle a una mejor configuración de entrenamiento. Por ejemplo, puede determinar que necesita usar más plegamientos de validación cruzada en respuesta al sobreajuste.
¿Seleccionará AutoML siempre el mismo modelo óptimo de los mismos datos de entrenamiento y la misma configuración?
El proceso de búsqueda de modelos de AutoML no es determinista, por lo que no siempre selecciona el mismo modelo de los mismos datos y configuración.
¿Cómo puedo corregir el error de memoria insuficiente?
Existen dos tipos de errores de memoria:
- Memoria RAM insuficiente
- Memoria insuficiente en el disco
En primer lugar, asegúrese de configurar AutoML de la mejor manera según sus datos. Para obtener más información, consulte la respuesta ¿Qué configuración de modelado debería usar?
Para la configuración predeterminada de AutoML, puede corregir errores de memoria insuficiente de RAM mediante el uso de nodos de proceso con más RAM. Una regla general es que la cantidad de RAM libre debe ser al menos 10 veces mayor que el tamaño de datos sin procesar para ejecutar AutoML con la configuración predeterminada.
Puede resolver los errores de memoria insuficiente del disco eliminando el clúster de proceso y creando uno nuevo.
¿Qué escenarios de previsión avanzada admite AutoML?
Damos soporte técnico en los siguientes escenarios de previsión avanzada:
- Previsión cuantil
- Evaluación sólida del modelo mediante previsiones graduales
- Previsión más allá del horizonte de previsión
- Previsión cuando haya un intervalo en el tiempo entre el entrenamiento y los períodos de previsión
Consulte el cuaderno de escenarios de previsión avanzados para obtener ejemplos y detalles.
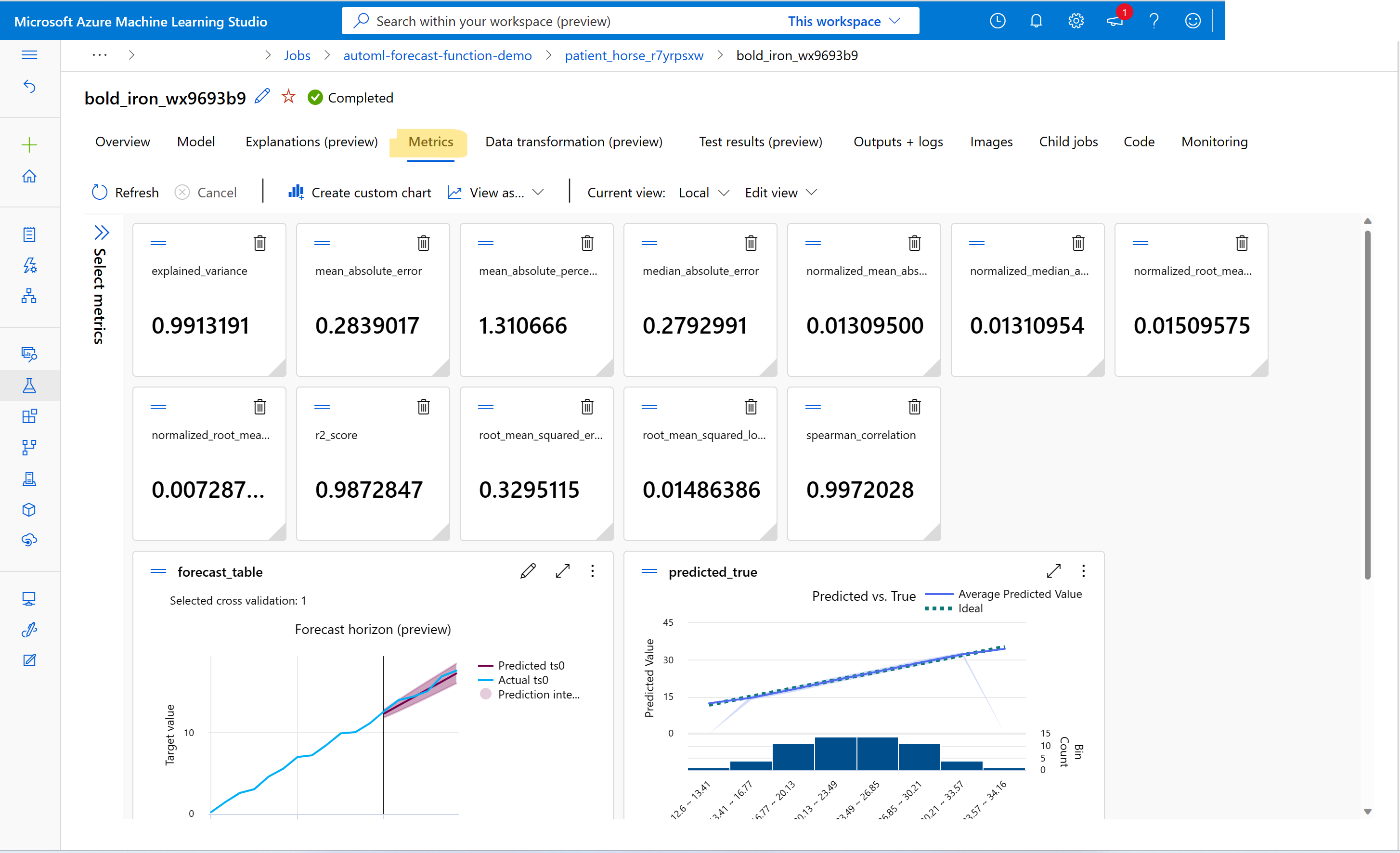
¿Cómo ver las métricas de los trabajos de entrenamiento de previsión?
Para buscar valores de métricas de entrenamiento y validación, consulte Ver información sobre trabajos o carreras en el estudio. Puede ver las métricas de cualquier modelo de previsión entrenado en AutoML; para ello, vaya a un modelo desde la interfaz de usuario del trabajo de AutoML en Studio y seleccione la pestaña Métricas.
¿Cómo errores de depuración con trabajos de entrenamiento de previsión?
Si se produjera un error en el trabajo de previsión de AutoML, un mensaje de error en la interfaz de usuario de Studio podría ayudarle a diagnosticar y corregir el problema. El mejor origen de información sobre el error más allá del mensaje de error es el registro del controlador para el trabajo. Para obtener instrucciones sobre cómo buscar registros de controladores, consulte Visualización de la información de trabajos o ejecuciones con MLflow.
Nota
Para un trabajo de HTS o Muchos modelos, el entrenamiento suele estar en clústeres de proceso de varios nodos. Los registros de estos trabajos están presentes para cada dirección IP del nodo. En este caso, deberá buscar registros de errores en cada nodo. Los registros de errores, junto con los registros de controladores, se encuentran en la carpeta user_logs de cada dirección IP del nodo.
¿Cómo se implementa un modelo de los trabajos de entrenamiento de previsión?
Se puede implementar un modelo a partir de la previsión de trabajos de entrenamiento de cualquiera de estas maneras:
- Punto de conexión en línea: compruebe el archivo de puntuación usado en la implementación o seleccione la pestaña Probar de la página del punto de conexión de Studio para comprender la estructura de la entrada que la implementación espera. Consulte este cuaderno para ver un ejemplo. Para obtener más información sobre la implementación en línea, consulte Implementación de un modelo de AutoML en un punto de conexión en línea.
- Punto de conexión por lotes: este método de implementación requiere que desarrolle un script de puntuación personalizado. Consulte este cuaderno para ver un ejemplo. Para más información sobre la implementación por lotes, consulte Uso de puntos de conexión por lotes para la puntuación por lotes.
En el caso de las implementaciones de interfaz de usuario, se recomienda usar cualquiera de estas opciones:
- Punto de conexión en tiempo real
- Punto de conexión por lotes
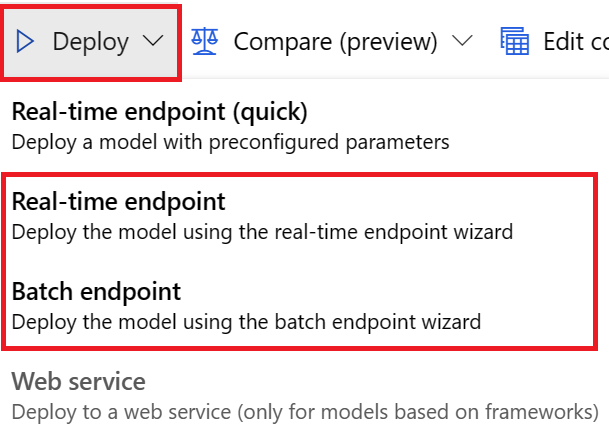
No use la primera opción, Punto de conexión en tiempo real (rápido).
Nota
A partir de ahora, no se admite la implementación del modelo MLflow a partir de los trabajos de entrenamiento de previsión a través del SDK, la CLI o la interfaz de usuario. Si lo intenta, obtendrá errores.
¿Qué es un área de trabajo, un entorno, un experimento, una instancia de proceso o un destino de proceso?
Si no está familiarizado con los conceptos de Azure Machine Learning, comience con los artículos ¿Qué es Azure Machine Learning? y ¿Qué es un área de trabajo de Azure Machine Learning?.
Pasos siguientes
- Más información sobre cómo configurar AutoML para entrenar un modelo de previsión de series temporales.
- Aprenda sobre las características del calendario para la previsión de series temporales en AutoML.
- Más información sobre cómo AutoML usa el aprendizaje automático para crear modelos de previsión.
- Obtenga información sobre la Previsión de AutoML para características con retardo.