Inferencia y evaluación de modelos de previsión
En este artículo se presentan conceptos relacionados con la inferencia de modelos y la evaluación en las tareas de previsión. Para obtener instrucciones y ejemplos para entrenar modelos de previsión en AutoML, consulte Configuración de AutoML para entrenar un modelo de previsión de series temporales con SDK y CLI.
Después de usar AutoML para entrenar y seleccionar el mejor modelo, el siguiente paso es generar previsiones. A continuación, si es posible, evalúe su precisión en un conjunto de pruebas extraído de los datos de entrenamiento. Para ver cómo configurar y ejecutar la evaluación de modelos de previsión en el aprendizaje automático automatizado, consulte Orquestación de la formación, la inferencia y la evaluación.
Escenarios de inferencia
En el aprendizaje automático, la inferencia es el proceso de generación de predicciones del modelo para los nuevos datos que no se usan en el entrenamiento. Hay varias maneras de generar predicciones en la previsión debido a la dependencia temporal de los datos. El escenario más sencillo es cuando el periodo de inferencia sigue inmediatamente al periodo de formación y se generan predicciones hasta el horizonte de previsión. En el siguiente diagrama, se ilustra este escenario:
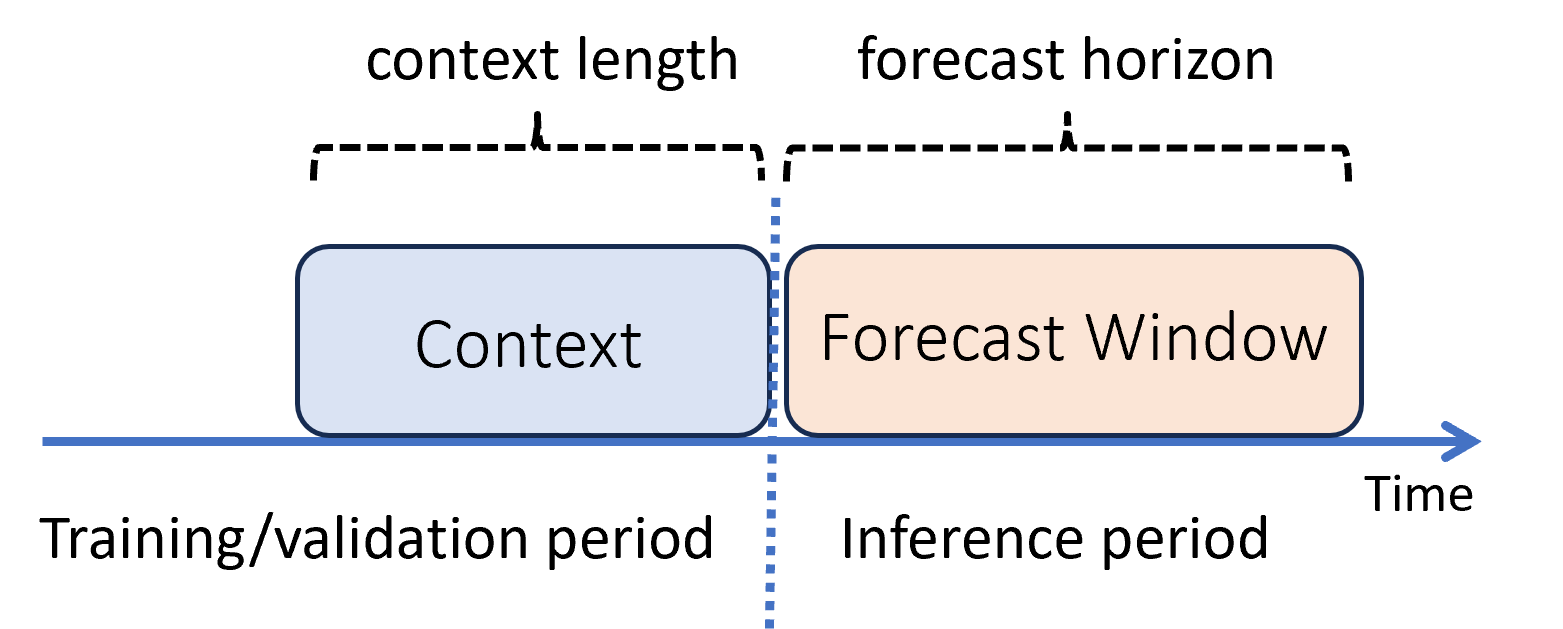
En el diagrama se muestran dos parámetros de inferencia importantes:
- La longitud del contexto es la cantidad de historial que el modelo requiere para realizar una previsión.
- El horizonte de previsión es la antelación con la que el pronosticador está capacitado para predecir.
Los modelos de previsión suelen usar cierta información histórica, el contexto, para realizar predicciones con antelación hasta el horizonte de previsión. Cuando el contexto forma parte de los datos de entrenamiento, AutoML guarda lo que necesita para realizar previsiones. No es necesario proporcionarlo explícitamente.
Hay otros dos escenarios de inferencia que son más complicados:
- Generación de predicciones más allá del horizonte de previsión
- Obtención de predicciones cuando hay una brecha entre los períodos de entrenamiento e inferencia
Las siguientes subsecciones revisan estos casos.
Predicción más allá del horizonte de previsión: previsión recursiva
Cuando necesite previsiones más allá del horizonte, AutoML aplica el modelo de forma recursiva durante el período de inferencia. Las predicciones del modelo se devuelven como entrada para generar predicciones para periodos de predicción posteriores. En el diagrama siguiente se muestra un ejemplo sencillo:
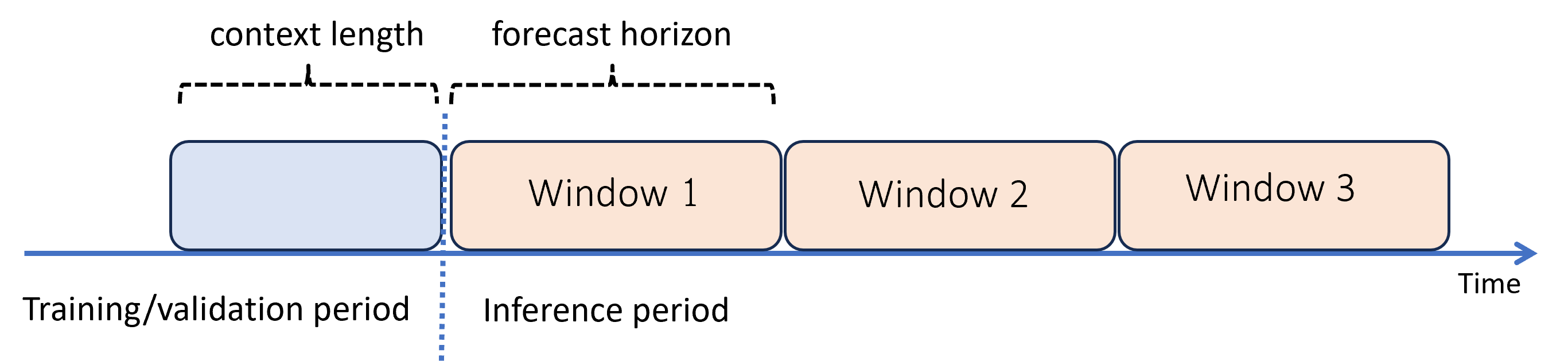
Aquí, el aprendizaje automático genera previsiones en un período tres veces la longitud del horizonte. Usa predicciones de una ventana como contexto para la ventana siguiente.
Advertencia
Errores de modelado de compuestos de previsión recursiva. Las predicciones se vuelven menos precisas más allá del horizonte de previsión original. Es posible que encuentre un modelo más preciso al volver a entrenar con un horizonte más largo.
Predicción con una brecha entre los períodos de entrenamiento e inferencia
Supongamos que después de entrenar un modelo, quiere usarlo para realizar predicciones a partir de nuevas observaciones que aún no estaban disponibles durante el entrenamiento. En este caso, hay un intervalo de tiempo entre los períodos de entrenamiento e inferencia:
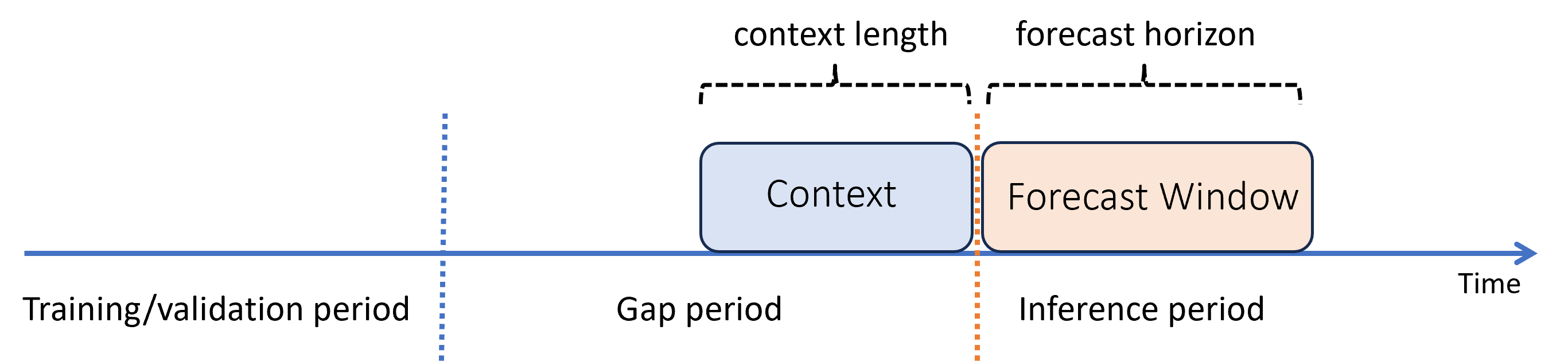
AutoML admite este escenario de inferencia, pero debe proporcionar los datos de contexto en el período de brecha, como se muestra en el diagrama. Los datos de predicción pasados al componente de inferencia necesitan valores para las características y los valores de destino observados en la brecha y los valores que faltan o valores NaN para el destino en el período de inferencia. En la tabla siguiente se muestra un ejemplo de este patrón:
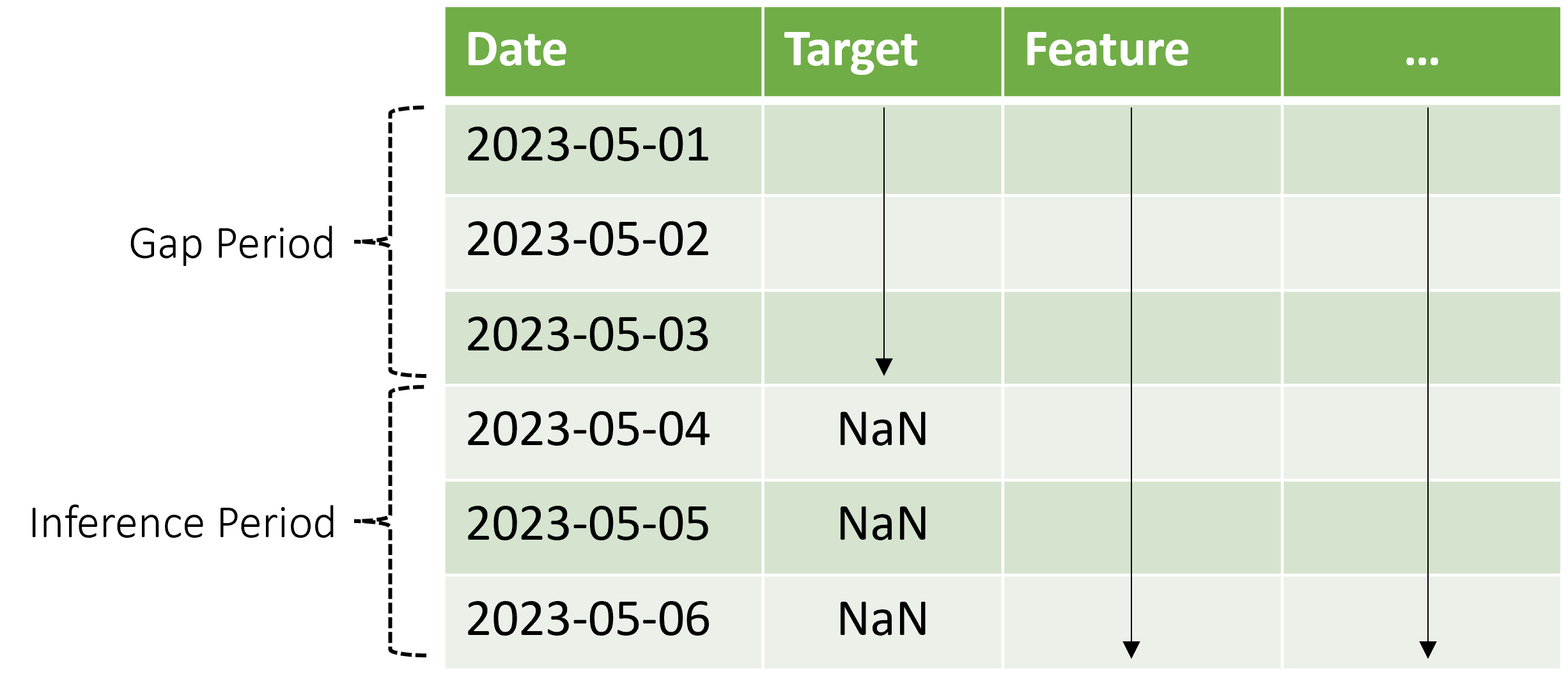
Los valores conocidos del destino y las características se proporcionan para 2023-05-01 a través de 2023-05-03. Los valores de destino que faltan a partir del 2023-05-04 indican que el período de inferencia comienza en esa fecha.
AutoML usa los nuevos datos de contexto para actualizar el retraso y otras características de búsqueda, y también para actualizar modelos como ARIMA que mantienen un estado interno. Esta operación no actualiza ni vuelve a ajustar los parámetros del modelo.
Evaluación del modelo
La evaluación es el proceso de generar predicciones en un conjunto de pruebas mantenido a partir de los datos de entrenamiento y las métricas informáticas de estas predicciones que guían las decisiones de implementación de modelo. En consecuencia, hay un modo de inferencia adecuado para la evaluación del modelo: una previsión gradual.
Un procedimiento óptimo para evaluar un modelo de predicción consiste en hacer avanzar en el tiempo el pronosticador entrenado sobre el conjunto de pruebas, haciendo un promedio de las métricas de error a lo largo de varias ventanas de predicción. A veces, este procedimiento se denomina backtest. Lo ideal es que el conjunto de pruebas para la evaluación sea largo en relación con el horizonte de previsión del modelo. De lo contrario, las estimaciones del error de previsión pueden ser estadísticamente ruidosas y, por tanto, menos confiables.
En el diagrama siguiente se muestra un ejemplo sencillo con tres ventanas de previsión:
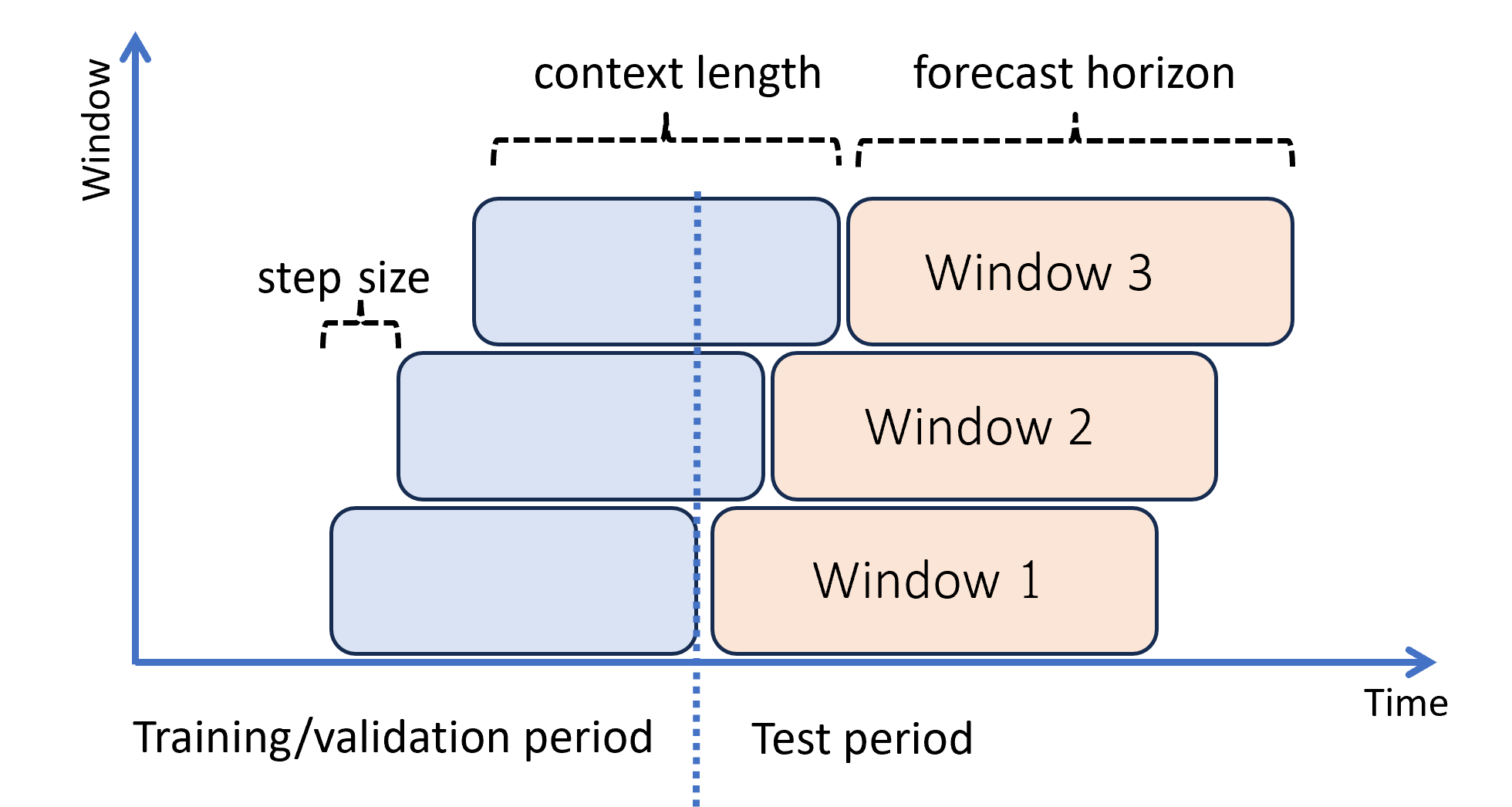
En el diagrama se muestran tres parámetros de evaluación graduales:
- La longitud del contexto es la cantidad de historial que el modelo requiere para realizar una previsión.
- El horizonte de previsión es la antelación con la que el pronosticador está capacitado para predecir.
- El tamaño del paso es lo que avanza con antelación la ventana gradual en cada iteración del conjunto de pruebas.
El contexto avanza junto con la ventana de previsión. Los valores reales del conjunto de pruebas se utilizan para hacer previsiones cuando entran dentro de la ventana contextual actual. La fecha más reciente de los valores reales usados para una ventana de previsión determinada se denomina hora de origen de la ventana. En la tabla siguiente se muestra una salida de ejemplo de la previsión gradual de tres ventanas con un horizonte de tres días y un tamaño de paso de un día:
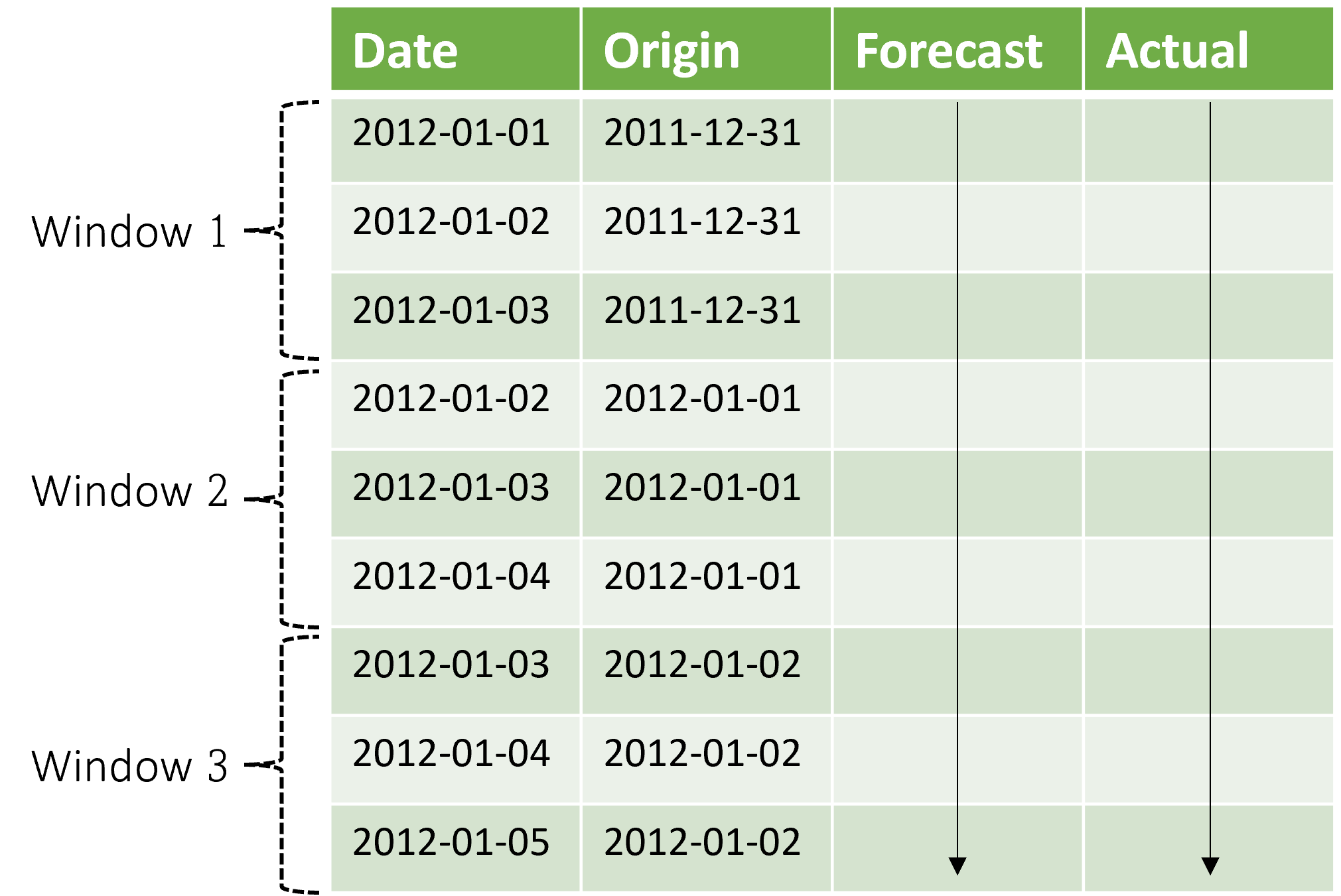
Con una tabla como esta, puede visualizar las previsiones frente a las métricas reales y de evaluación deseadas de proceso. Las canalizaciones de AutoML pueden generar pronósticos continuos sobre un conjunto de pruebas con un componente de inferencia.
Nota
Cuando el periodo de prueba tiene la misma duración que el horizonte de previsión, una previsión renovable ofrece una única ventana de previsiones hasta el horizonte.
Métricas de evaluación
El escenario empresarial específico suele impulsar la elección del resumen o la métrica de evaluación. Algunas opciones comunes incluyen los ejemplos siguientes:
- Gráficos de los valores objetivo observados frente a los valores previstos para comprobar que cierta dinámica de los datos que capta el modelo
- Error de porcentaje absoluto medio (MAPE) entre los valores reales y previstos
- Error cuadrático medio raíz (RMSE), posiblemente con una normalización, entre valores reales y previstos
- Error absoluto medio (MAE), posiblemente con una normalización, entre valores reales y previstos
Hay muchas otras posibilidades, en función del escenario empresarial. Es posible que tenga que crear sus propias utilidades posteriores al procesamiento para calcular las métricas de evaluación a partir de resultados de inferencia o previsiones graduales. Para más información sobre las métricas, consulte Métricas de regresión y previsión.
Contenido relacionado
- Más información sobre cómo configurar AutoML para entrenar un modelo de previsión de series temporales.
- Obtenga información sobre cómo AutoML usa el aprendizaje automático para crear modelos de previsión.
- Lea las respuestas a las preguntas más frecuentes sobre la previsión en ML automatizado.