¿Qué es el aprendizaje automático automatizado (AutoML)?
SE APLICA A:  SDK de Python azure-ai-ml v2 (actual)
SDK de Python azure-ai-ml v2 (actual)
El aprendizaje automático automatizado, también denominado ML automatizado o AutoML, es el proceso de automatizar las tareas lentas e iterativas del desarrollo de modelos de Machine Learning. Permite que los desarrolladores, analistas y científicos de datos creen modelos de aprendizaje automático con un escalado, eficiencia y productividad altos, al mismo tiempo que mantiene la calidad del modelo. El aprendizaje automático de Azure Machine Learning se basa en una innovación de la división Microsoft Research.
- Para clientes con experiencia en código, instala el SDK de Azure Machine Learning para Python. Comience con Tutorial: Entrenamiento de un modelo de detección de objetos (versión preliminar) con AutoML y Python.
¿Cómo funciona AutoML?
Durante el entrenamiento, Azure Machine Learning crea varias canalizaciones en paralelo que prueban distintos parámetros y algoritmos. El servicio recorre en iteración los algoritmos de ML que corresponden con las selecciones de características, de forma que cada iteración genera un modelo con una puntuación de entrenamiento. Cuanto mejor sea la puntuación de la métrica que quiere optimizar, mejor se ajustará el modelo a los datos. Se detendrá una vez que logre los criterios de salida definidos en el experimento.
Si usa Azure Machine Learning, puede diseñar y ejecutar sus experimentos de entrenamiento de Machine Learning automatizado mediante los siguientes pasos:
Identifica el problema de Machine Learning que quieres solucionar: clasificación, previsión, regresión, Computer Vision o NLP.
Elija si quiere obtener una experiencia orientada a la programación o una experiencia web de Studio sin código: los usuarios que prefieren una experiencia orientada a la programación pueden usar el SDK v2 de Azure Machine Learning o la CLI v2 de Azure Machine Learning. Comience con Tutorial: Entrenamiento de un modelo de detección de objetos con AutoML y Python. Los usuarios que prefieren una experiencia limitada o sin código pueden usar la interfaz web en Estudio de Azure Machine Learning en https://ml.azure.com. Comience con Tutorial: Creación de un modelo de clasificación con aprendizaje automático automatizado en Azure Machine Learning.
Especifique el origen de los datos de entrenamiento etiquetados: puede traer los datos a Azure Machine Learning de muchas maneras diferentes.
Configure los parámetros de aprendizaje de automático automatizado que determinan el número de iteraciones en diferentes modelos, las configuraciones de hiperparámetros, la caracterización y preprocesamiento de datos y las métricas que se deben observar para seleccionar al mejor modelo.
Envíe el trabajo de entrenamiento.
Revisa los resultados.
En el siguiente diagrama se muestra este proceso.
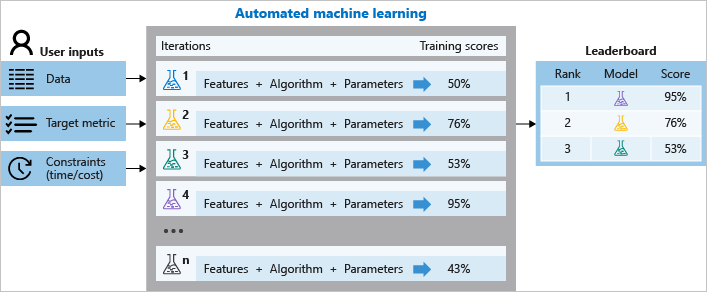
También puede inspeccionar la información de trabajo registrada, que contiene las métricas que se recopilan durante el trabajo. El trabajo de entrenamiento genera un objeto serializado de Python (archivo .pkl) que contiene el modelo y el preprocesamiento de los datos.
Aunque se automatiza la creación del modelo, también puede conocer las características importantes o pertinentes de los modelos generados.
Cuándo usar AutoML: clasificación, regresión, previsión y Computer Vision y NLP
Aplique aprendizaje automático automatizado cuando quiera que Azure Machine Learning entrene y ajuste un modelo automáticamente con la métrica de destino que especifique. El aprendizaje automático automatizado democratiza el proceso de desarrollo de modelos de Machine Learning y permite que los usuarios (independientemente de su experiencia en ciencia de datos) identifiquen una canalización de aprendizaje automático de un extremo a otro para cualquier problema.
Los profesionales y desarrolladores de ML de todos los sectores pueden usar el aprendizaje automático para:
- Implementar soluciones de ML sin grandes conocimientos de programación.
- Ahorrar tiempo y recursos.
- Aplicar procedimientos recomendados de la ciencia de datos
- Proporcionar soluciones ágiles a los problemas.
clasificación
La clasificación es un tipo de aprendizaje supervisado en el que los modelos aprenden a usar datos de entrenamiento y aplican lo que han aprendido a nuevos datos. Azure Machine Learning ofrece caracterizaciones específicas para estas tareas, como los caracterizadores de texto de red neuronal profunda para la clasificación. Para obtener más información sobre las opciones de caracterización, consulta Caracterización de datos. También puedes encontrar la lista de algoritmos que admite AutoML en Algoritmos admitidos.
El objetivo principal de los modelos de clasificación es predecir en qué categorías se incluyen los nuevos datos en función de lo aprendido de los datos de entrenamiento. Algunos ejemplos comunes de clasificación son la detección de fraudes, el reconocimiento de escritura a mano y la detección de objetos.
Consulte un ejemplo de clasificación y de aprendizaje automático automatizado en este cuaderno de Python: Bank Marketing.
Regresión
De forma similar a la clasificación, las tareas de regresión también son una tarea de aprendizaje supervisada común. Azure Machine Learning ofrece características específicas de los problemas de regresión. Más información sobre las opciones de caracterización. También puedes encontrar la lista de algoritmos que admite AutoML en Algoritmos admitidos.
A diferencia de la clasificación, donde los valores de salida pronosticados son categóricos, los modelos de regresión predicen valores de salida numéricos basados en predicciones independientes. En la regresión, el objetivo es ayudar a establecer la relación entre esas variables de predicción independientes mediante la estimación de cómo una variable afecta a las otras. Por ejemplo, el modelo podría predecir el precio de un automóvil según características como el rendimiento del combustible y la clasificación de seguridad.
Consulte ejemplos de regresión y aprendizaje automático automatizado para realizar predicciones en estos cuadernos de Python: Rendimiento del hardware.
Previsión de series temporales
La creación de previsiones es una parte integral de cualquier empresa, ya sea de los ingresos, los inventarios, las ventas o los clientes. Puede usar el aprendizaje automático automatizado para combinar las técnicas y enfoques y obtener una previsión recomendada y de alta calidad de series temporales. Puedes encontrar la lista de algoritmos que admite AutoML en Algoritmos admitidos.
Un experimento automatizado de series temporales se trata como un problema de regresión multivariante. Los valores de series temporales anteriores se "dinamizan" para convertirse en más dimensiones para el regresor junto con otros indicadores. Este enfoque, a diferencia de los métodos clásicos de series temporales, tiene la ventaja de incorporar de forma natural varias variables contextuales y su relación entre sí durante el entrenamiento. El aprendizaje automático automatizado aprende un modelo único (a menudo, internamente bifurcado) para todos los elementos en el conjunto de datos y horizontes de predicción. Por tanto, hay más datos disponibles para calcular los parámetros del modelo, y se hace posible la generalización hasta series totalmente nuevas.
La configuración de previsión avanzada incluye:
- Detección y caracterización de festividades
- Aprendizajes de series temporales y DNN (Auto-ARIMA, Prophet, ForecastTCN)
- Compatibilidad con gran cantidad de modelos mediante la agrupación
- Validación cruzada de origen variable
- Retrasos configurables
- Características de agregado en ventanas con desplazamiento
Consulte un ejemplo de previsión y aprendizaje automático automatizado en este cuaderno de Python: Demanda de energía.
Visión del equipo
La compatibilidad con las tareas de visión por ordenador permite generar fácilmente modelos entrenados con datos de imágenes para escenarios como la clasificación de imágenes y la detección de objetos.
Con esta funcionalidad, puede:
- Integrar sin problemas con la capacidad de etiquetado de datos de Azure Machine Learning.
- Usar datos etiquetados para generar modelos de imagen.
- Optimizar el rendimiento del modelo especificando el algoritmo de modelo y ajustando los hiperparámetros.
- Descargar o implementar el modelo resultante como un servicio web en Azure Machine Learning.
- Operacionalizar a gran escala, aprovechando las funcionalidades de MLOps y canalizaciones de ML de Azure Machine Learning.
La creación de modelos de aprendizaje automático automatizado para tareas de visión se admite a través del SDK de Python de Azure Machine Learning. Se puede acceder a los trabajos, modelos y salidas de experimentación resultantes desde la UI de Estudio de Azure Machine Learning.
Aprenda a configurar el entrenamiento de AutoML para modelos de Computer Vision.
 Imagen de: http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
Imagen de: http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
ML automatizado para imágenes admite las siguientes tareas de Computer Vision:
| Tarea | Descripción |
|---|---|
| Clasificación de imágenes de varias clases | Tareas en las que una imagen se clasifica con una sola etiqueta de un conjunto de clases; por ejemplo, cada imagen se clasifica como una imagen de un "gato", un "perro" o un "pato". |
| Clasificación de imágenes con varias etiquetas | Tareas en las que una imagen podría tener una o varias etiquetas de un conjunto de etiquetas; por ejemplo, una imagen podría etiquetarse con "gato" y "perro". |
| Detección de objetos | Tareas para identificar objetos en una imagen y localizar cada objeto con un rectángulo delimitador; por ejemplo, localizar todos los perros y gatos de una imagen y dibujar un rectángulo delimitador alrededor de cada uno. |
| Segmentación de instancias | Tareas para identificar objetos de una imagen en el nivel de píxel, dibujando un polígono alrededor de cada objeto de la imagen. |
Procesamiento del lenguaje natural (NLP)
La compatibilidad con tareas de procesamiento de lenguaje natural (NLP) en ML automatizado le permite generar fácilmente modelos entrenados en datos de texto para escenarios de clasificación de texto y reconocimiento de entidades con nombre. La creación automatizada ML modelos NLP entrenados se admite a través del SDK Azure Machine Learning Python. Se puede acceder a los trabajos, modelos y salidas de experimentación resultantes desde la UI de Estudio de Azure Machine Learning.
La funcionalidad NLP admite:
- Entrenamiento de NLP de red neuronal profunda de un extremo a otro con los modelos de BERT entrenados previamente más recientes
- Integración sin problemas con el etiquetado de datos de Azure Machine Learning
- Usar datos etiquetados para generar modelos NLP
- Compatibilidad multilingüe con 104 idiomas
- Aprendizaje distribuido con Horovod
Aprenda a configurar el entrenamiento de AutoML para modelos NLP.
Datos de entrenamiento, validación y prueba
Con la ML proporcionas los datos de entrenamiento para entrenar modelos de ML y puedes especificar qué tipo de validación de modelos se va a realizar. El ML automatizado realiza la validación del modelo como parte del entrenamiento. Es decir, el aprendizaje automático automatizado utiliza datos de validación para optimizar los hiperparámetros del modelo en función del algoritmo aplicado para encontrar la combinación que mejor se adapte a los datos de entrenamiento. Sin embargo, se usan los mismos datos de validación para cada iteración de optimización, lo que introduce el sesgo de evaluación del modelo, ya que el modelo sigue mejorando y ajustando los datos de validación.
Para ayudar a confirmar que este sesgo no se aplica al modelo recomendado final, el ML automatizado admite el uso de datos de prueba para evaluar el modelo final que el ML automatizado recomienda al final del experimento. Cuando se proporcionan datos de prueba como parte de la configuración del experimento de AutoML, este modelo recomendado se prueba de forma predeterminada al final del experimento (versión preliminar).
Importante
La característica para probar modelos con un conjunto de datos de prueba con el fin de evaluar los modelos generados está en versión preliminar. Esta capacidad es una característica experimental en versión preliminar y podría cambiar en cualquier momento.
Aprenda a configurar experimentos de AutoML para usar datos de prueba (versión preliminar) con el SDK o con Estudio de Azure Machine Learning.
Ingeniería de características
La ingeniería de características es el proceso de usar el conocimiento de dominio de los datos para crear características que ayuden a mejorar los algoritmos de ML. En Azure Machine Learning, se aplican técnicas de escalado y normalización para facilitar la ingeniería de características. En conjunto, estas técnicas y la ingeniería de características se conocen como caracterización.
En el caso de los experimentos de aprendizaje automático automatizado, la caracterización se aplica automáticamente, pero también se puede personalizar en función de los datos. Obtenga más información sobre qué caracterización se incluye (SDK v1) y cómo AutoML ayuda a evitar el sobreajuste y los datos desequilibrados en los modelos.
Nota:
Los pasos de la caracterización del aprendizaje automático automatizado (por ejemplo, la normalización de características, el control de los datos que faltan y la conversión de valores de texto a numéricos) se convierten en parte del modelo subyacente. Cuando se usa el modelo para realizar predicciones, se aplican automáticamente a los datos de entrada los mismos pasos de caracterización que se aplican durante el entrenamiento.
Personalización de la caracterización
También hay disponibles técnicas de ingeniería de características adicionales, como la codificación y las transformaciones.
Para habilitar esta configuración, realice lo siguiente:
Azure Machine Learning Studio: Habilite Automatic featurization (Características automáticas) en la sección View additional configuration (Ver configuración adicional) siguiendo estos pasos.
SDK de Python: especifique la caracterización en el objeto de trabajo de AutoML. Más información sobre cómo habilitar la ingeniería de características.
Modelos de conjuntos
El aprendizaje automático automatizado admite modelos de conjunto, que están habilitados de forma predeterminada. El aprendizaje de conjunto mejora los resultados del aprendizaje automático y su rendimiento predictivo mediante la combinación de varios modelos en lugar de usar modelos únicos. Las iteraciones de conjunto aparecen como las iteraciones finales del trabajo. El aprendizaje automático automatizado usa los métodos de conjunto de votaciones y apilamiento para combinar modelos:
- Votación: realiza la predicción en función de la media ponderada de las probabilidades de clase predichas (para tareas de clasificación) o de los destinos de regresión predichos (para tareas de regresión).
- Apilamiento: combina modelos heterogéneos y entrena un metamodelo basado en la salida de los modelos individuales. Los metamodelos predeterminados actuales son LogisticRegression para las tareas de clasificación y ElasticNet para las tareas de regresión y previsión.
El algoritmo de selección de conjunto de Caruana con inicialización de conjunto ordenado se utiliza para decidir qué modelos se van a utilizar en el conjunto. En un nivel alto, este algoritmo inicializa el conjunto con hasta cinco modelos con las mejores puntuaciones individuales y comprueba que estos modelos se encuentran en un umbral del 5 % de la mejor puntuación para evitar un conjunto inicial deficiente. A continuación, para cada iteración de conjunto, se agrega un nuevo modelo al conjunto existente y se calcula la puntuación resultante. Si un nuevo modelo ha mejorado la puntuación de conjunto existente, el conjunto se actualiza para incluir el nuevo modelo.
Consulte el paquete de AutoML para cambiar la configuración del conjunto predeterminado en el aprendizaje automático automatizado.
AutoML y ONNX
Con Azure Machine Learning, puede usar Machine Learning para generar un modelo de Python y convertirlo al formato ONNX. Una vez que los modelos están en formato ONNX, se pueden ejecutar en varias plataformas y dispositivos. Más información sobre la aceleración de los modelos de Machine Learning con ONNX.
Consulte cómo convertir al formato ONNX en este ejemplo de Jupyter Notebook. Aprenda cuáles son los algoritmos que se admiten en ONNX.
El entorno de ejecución de ONNX también es compatible con C#, por lo que puede usar el modelo creado automáticamente en sus aplicaciones de C# sin necesidad de volver a codificar o experimentar alguna de las latencias de red que presentan los puntos de conexión REST. Obtenga más detalles sobre el uso de un modelo AutoML de ONNX en una aplicación .NET con ML.NET y la creación de inferencias en modelos de ONNX con la API de C# del entorno de ejecución de ONNX.
Pasos siguientes
Hay varios recursos que le ayudarán a ponerse en marcha con AutoML.
Tutoriales y procedimientos
Los tutoriales son ejemplos de introducción de un extremo a otro de escenarios de AutoML.
Para obtener una experiencia orientada al código, sigue el Tutorial: Entrenamiento de un modelo de detección de objetos con AutoML y Python.
Para una experiencia sin código o con poco código, consulta Tutorial: Entrenamiento de un modelo de clasificación con aprendizaje automático automatizado sin código en Estudio de Azure Machine Learning.
Los artículos de procedimientos proporcionan más detalles sobre qué funcionalidad ofrece ML automatizado. Por ejemplo,
Configure de los experimentos de aprendizaje automáticos
Obtenga más información sobre cómo entrenar modelos de Computer Vision con Python.
Obtenga información sobre cómo ver el código generado desde los modelos ML automatizados (SDK v1).
Muestras de cuaderno de Jupyter
Revise los ejemplos de código y los casos de uso detallados en el repositorio del cuaderno de GitHub para obtener muestras de aprendizaje automático automatizado.
Referencia de SDK de Python
Profundice sus conocimientos sobre patrones de diseño y especificaciones de clases del SDK con la documentación de referencia de la clase de trabajo de AutoML.
Nota:
Las capacidades del aprendizaje automático automatizado también están disponibles en otras soluciones de Microsoft como,ML.NET, HDInsight, Power BI y SQL Server.